
Disseny d'un motor de recuperació de la informació per a ús experimental i educatiu
[versión castellana]
Carlos G. Figuerola
Facultad de Documentación
Universidad de Salamanca
figue@gugu.usal.esJosé Luis Alonso Berrocal
Facultad de Documentación
Universidad de Salamanca
berrocal@gugu.usal.esÁngel Francisco Zazo Rodríguez
Facultad de Documentación
Universidad de Salamanca
afzazo@gugu.usal.es
Resum
En aquest article es descriu el disseny i el funcionament d'un motor de recuperació d'informació basat en el model vectorial, que té la finalitat de servir de base d'experimentació en tasques d'investigació i com a recurs per a la docència. No obstant això, el motor és completament operacional i es pot utilitzar en entorns documentals. Construït sobre una base de dades relacional, facilita l'observació i la manipulació d'estructures i resultats intermedis; fa les operacions fonamentals a partir de sentències SQL, la qual cosa permet modificar-ne fàcilment el funcionament intern i, en conseqüència, l'experimentació.
1 Introducció
La recuperació de la informació és una disciplina d'interès creixent, a causa de l'augment de la disponibilitat de documents en suport electrònic i de la necessitat consegüent d'obtenir en cada moment els que satisfan una determinada necessitat d'informació. L'abast i els objectius de la disciplina han estat definits diverses vegades des de fa temps: se'n pot trobar una definició a l'obra de Rijsbergen (1979). El fet que hagi estat inclosa, d'una manera o altra, en els currículums dels titulats en Ciències de la Documentació, i el fet de tenir un perfil evident com a camp d'investigació, fan que sigui aconsellable tenir eines que permetin, d'una banda, facilitar-ne l'ensenyament i, de l'altra, possibilitar el disseny i la realització d'experiments com a part de treballs d'investigació.
Aquests motius ens han portat a la construcció d'un petit però robust motor de cerca que pugui servir per a diverses finalitats. Els objectius bàsics a l'hora de dissenyar-lo han estat:
a) Disposar d'un programa que implementés alguns dels models teòrics més difosos sobre recuperació de la informació.
b) Disposar d'un programa que permetés examinar fàcilment els resultats de certes operacions internes, com ara el càlcul de pesos dels termes.
c) Tenir la possibilitat de discriminar camps en els documents i de valorar-los de manera diferent.
d) Tenir la possibilitat de modificar fàcilment la mecànica interna d'operació del programa, aplicant criteris diversos i sistemes de càlcul de pesos i similituds, amb la finalitat d'observar l'efecte d'aquestes modificacions.
e) Tenir la possibilitat d'implementar coneixement lingüístic, adaptant les possibilitats de recuperació a les característiques pròpies d'un idioma determinat.Encara que, com es pot veure, els objectius prioritaris eren dissenyar una eina per a la docència i la investigació, i no pas un motor de cerca operacional, el resultat és prou robust per ser utilitzat amb èxit en determinats entorns documentals. Així, encara que el codi no està optimitzat i pot ser una mica lent, ja que està escrit pensant que havia de ser fàcil de comprendre i de modificar, té uns temps de resposta acceptables: no més d'1 segon per a una col·lecció de 15.000 documents, en un Pentium II (266 MHz) amb 64 Mb de RAM, per a una consulta de 10 paraules.
El nostre motor de cerca documental, que hem anomenat Karpanta, adopta el conegut model de l'espai vectorial (Salton i McGill, 1983). Breument, segons aquest model, cada document és representat mitjançant un vector de n elements, i n és igual al nombre de termes indexables que hi ha a la col·lecció documental. Hi ha, doncs, un vector per a cada document, i, en cada vector, un element per a cada terme o paraula susceptible d'aparèixer en el document. Cada un d'aquests elements és cobert o ocupat amb un valor numèric. Si la paraula no està present en el document, aquest valor és igual a 0. En cas contrari, el valor es calcula tenint en compte diversos factors, ja que una paraula determinada pot ser més significativa o menys (tant en general com, sobretot, en el document en concret): aquest valor s'anomena pes del terme en el document.
Sempre d'acord amb el model de l'espai vectorial, les consultes són representades també per mitjà d'un vector de les mateixes característiques que els dels documents (però variant els valors numèrics de cada element segons les paraules que formin part de la consulta, és clar). Això permet calcular fàcilment una funció de similitud donada entre el vector d'una consulta i els de cada un dels documents. El resultat d'aquest càlcul mesura la semblança entre la consulta i cada un dels documents, de manera que aquells que en teoria s'ajustin més a la consulta formulada produiran un índex més alt de similitud. Naturalment, s'assumeix que la consulta es formula en llenguatge natural (podria ser, fins i tot, un document de mostra per recuperar els que se li assemblin), i de tot això es dedueix que el resultat de la consulta consisteix en una llista de documents ordenada en ordre decreixent segons la similitud que tingui amb la consulta.
En aquest model de recuperació hi ha diversos factors que es poden modificar. Així, entre altres, el sistema de càlcul de pesos: els esquemes habituals es basen, d'una manera o altra, en les freqüències d'aparició de la paraula de la qual es vol calcular el pes. D'aquesta manera, molts sistemes utilitzen algun mecanisme basat en la multiplicació de la IDF (inverse document frequency) del terme per la freqüència que té en el document en qüestió. La mateixa IDF té diverses versions, en general basades en una funció inversa del nombre de documents en què apareix el terme en qüestió (Harman, 1992a; Salton i Buckley, 1988). El nostre motor de cerca es dissenyà pensant en la substitució fàcil d'una fórmula de càlcul per qualsevol altra; però també en la identificació, mitjançant l'etiquetatge, de parts del document, de manera que les paraules integrants de zones marcades poguessin pesar-se de manera diferent (en funció de l'etiquetatge). Així, per exemple, es podria voler adjudicar un pes més gran a les paraules que apareguessin en els títols dels documents.
De la mateixa manera, també es pot substituir fàcilment l'equació de càlcul de similitud. Una de les més utilitzades és la coneguda com a fórmula del cosinus (Salton, 1989), però es pot substituir fàcilment per qualsevol altra.
El concepte mateix de terme indexable és flexible en dos sentits: en primer lloc, definint una llista de paraules buides. Aquesta llista pot ser modificada en qualsevol moment i, atès que Karpanta ofereix la possibilitat d'examinar la freqüència de paraules en la col·lecció, és possible utilitzar directament aquesta informació per construir o modificar la llista de paraules buides (Wilbur i Sirotkin, 1992). En segon lloc, les paraules indexables han de ser normalitzades, i això s'aconsegueix en Karpanta mitjançant la lematització (Hull, 1996). Karpanta incorpora un s-stemmer, però, atès que es tracta d'una funció autònoma, és fàcil substituir-la per un algoritme diferent. Cal tenir en compte que la lematització també es pot portar a terme mitjançant un preprocessament extern dels documents, o limitar-la únicament a les consultes (Kraaij i Pohlmann, 1996). Diferents estudis mostren que aquest és un dels elements en els quals les peculiaritats lingüístiques tenen un paper important (Harman, 1991; Popovic i Willet, 1992).
2 Arquitectura
Bàsicament, Karpanta es basa en dos mòduls: un d'indexació, que construeix els vectors dels documents, i un altre de consulta, que calcula la similitud amb una consulta donada. Tant els documents com els vectors resultants, i també els productes intermedis i auxiliars, s'emmagatzemen en una base de dades relacional. Tot i que els sistemes de gestió de bases de dades relacionals han patit un cert descrèdit en el passat pel que fa a la seva utilització en entorns documentals (Trigueros Díaz i Higuera Matas, 1997; Moya Anegón, 1995, 111-112; Codina, 1994), creiem que constitueixen un mitjà idoni per a aquesta tasca. Als avantatges genèrics ja coneguts d'aquest tipus de sistemes (prevenció contra la redundància i la inconsistència, facilitat de modificació d'estructures, flexibilitat d'utilització, estandardització, etc.), cal afegir el fet que actualment han superat alguns dels inconvenients que se'ls atribuïen tradicionalment: possibilitat de camps de mida variable (els coneguts camps memo), possibilitat d'emmagatzemar dades binàries (imatges, so, referències a objectes externs), i, sens dubte, camps repetibles (encara que sempre ha estat possible tenir camps repetibles amb una base de dades relacional; de fet, aquesta és una de les seves raons de ser [Date, 1983]). Addicionalment, sistemes de gestió de bases de dades relacionals (amb els corresponents llenguatges estàndard de manipulació de dades i interrogació) corren avui en dia de manera àgil i sense problemes pels ordinadors personals.
En el nostre cas, vam escollir l'SGBD Microsoft Access. A part de la fàcil disponibilitat del programa, són importants per a nosaltres, tenint en compte els objectius d'aplicació a la docència i a la investigació plantejats a l'hora de dissenyar Karpanta, la transparència d'aquest sistema i la possibilitat d'accedir a les taules i veure-les (modificar-les, quan calgui), amb els productes intermedis de la indexació. D'aquesta manera, es poden mostrar (a un alumne, per exemple) els termes i els pesos de cadascun, obtenir-ne els de pes més gran o més petit, i qüestions similars. En el mateix sentit, és fàcil modificar manualment qualsevol vector, o tots els vectors, i observar-ne el resultat. Atès que s'utilitzen prestacions estàndard, es pot portar el sistema a un altre SGDB (per exemple, per a un altre sistema operatiu, com ara l'Unix) sense problemes.
D'altra banda, la major part de les operacions es porten a terme mitjançant el llenguatge estàndard en les bases de dades relacionals, SQL (Date, 1983). Això implica, sens dubte, una portabilitat garantida entre sistemes, però, sobretot, i des del nostre punt de vista, una gran facilitat de modificació d'aspectes com ara el càlcul de pesos o de similitud; qualsevol d'aquestes operacions no requereix sinó canviar una sola línia de codi. La utilització d'SQL per implementar sistemes basats en el model de l'espai vectorial fou plantejada ja fa alguns anys (Grossman i altres, 1995; Grossman i altres, 1996). SQL destaca per la senzillesa i la precisió conceptual, però, des d'un punt de vista pràctic, en el passat tal vegada era massa costós pel que fa a la capacitat de procés i els recursos de màquina. Actualment, tanmateix, amb l'augment creixent de la velocitat dels processadors i el reduït preu de les memòries, l'SQL ha esdevingut perfectament àgil i operatiu en qualsevol ordinador personal.
En la mateixa línia, les sentències SQL s'han de redactar en algun llenguatge amfitrió i, de la mateixa manera, cal utilitzar algun llenguatge de programació per portar a terme determinades operacions, com ara la separació o la segmentació dels documents en paraules. Actualment, Karpanta fa aquestes operacions mitjançant Visual Basic (sí, Visual Basic), però no seria gaire diferent si ho fes mitjançant algun altre llenguatge (per exemple, Perl, si es porta a un sistema Unix).
Karpanta emmagatzema inicialment els documents en un camp de tipus memo en una taula que té un altre camp addicional per proporcionar una clau a cada document; observeu que no hi ha res que impedeixi establir camps addicionals (per exemple, la data del document); gràcies a la senzillesa de l'SQL, és molt fàcil crear filtres addicionals a les consultes per a aquests nous camps. Les paraules considerades a priori buides s'emmagatzemen en una altra taula, amb un únic camp destinat a aquesta finalitat. Durant el procés d'indexació, Karpanta construirà un fitxer invertit, amb cada aparició o ocurrència de cada terme, juntament amb la clau del document en què apareix, que emmagatzemarà en una altra taula, a partir de la qual, mitjançant la sentència SQL adient, Karpanta calcularà les IDF de cada terme, i el pes de cada terme en el document.
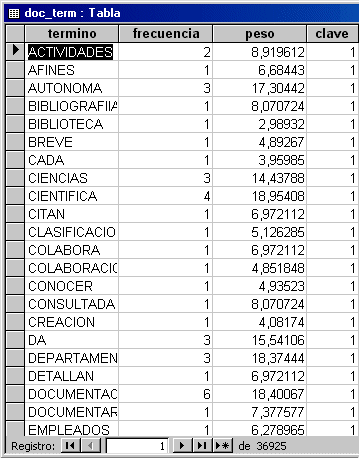
Il·lustració 1. Taula amb termes, punter a documents, freqüència en el document i pes
L'arquitectura del mòdul d'indexació és, bàsicament, la següent:
a) Processament dels documents (mitjançant un llenguatge de programació convencional, com ara VB).
- Obtenció de paraules de cada document.
- Filtratge i eliminació de paraules buides.
- Normalització de caràcters (majúscules, minúscules, accents, etc.).
- Lematització. Actualment, Karpanta aplica un s-stemmer modificat lleugerament per al castellà.
- Emmagatzemament en una taula de cada terme resultant, amb la referència o clau dels documents en què apareix.
b) Càlcul de freqüències de termes, IDF i pesos, mitjançant sentències SQL, i emmagatzemament de resultats en una taula.
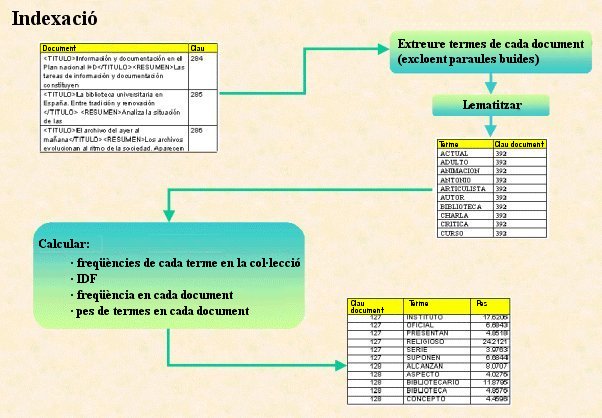
Il·lustració 2. Procés d'indexació
El mòdul de consulta encara és més senzill. Atès que una consulta en llenguatge natural ha de ser tractada com qualsevol altre document, requereix les mateixes operacions:
a) Processament del text de la consulta (obtenció de paraules, eliminació de paraules buides, normalització de caràcters, lematització, etc.).
b) Càlcul de pesos dels termes de la consulta, utilitzant les dades d'IDF emmagatzemades en una taula en l'operació d'indexació.
c) Càlcul de similitud entre consulta i cada un dels documents, mitjançant una simple sentència SQL.
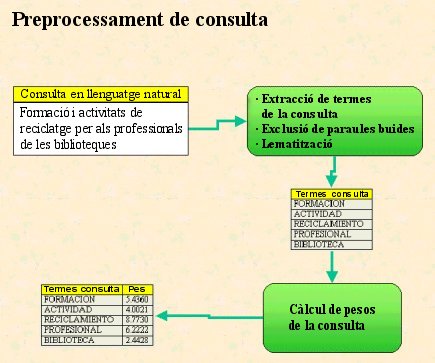
Il·lustració 3. Esquema de preprocessament d'una consulta
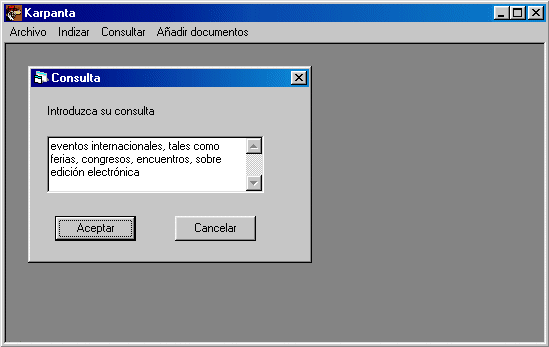
Il·lustració 4. Demo de Karpanta: consulta en llenguatge natural

Il·lustració 5. Esquema de resolució d'una consulta
3 Realimentació de consultes
A partir d'aquesta arquitectura, implementar la realimentació de les consultes és senzill. Una bona exposició de les qüestions que planteja l'expansió de les consultes per mitjà de la realimentació es pot trobar a Harman (1992b) i Buckley i altres (1994). Per a una expansió simple, n'hi ha prou d'afegir al text original de la consulta el text dels documents amb els quals es vol realimentar, ja sigui que l'usuari faci la selecció, ja sigui agafant de manera automàtica els n primers recuperats per la consulta original: després d'això, només caldrà tornar a executar la consulta amb els afegits que s'hi ha fet.
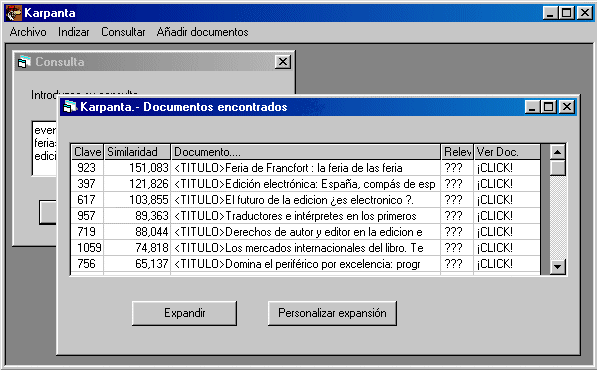
Il·lustració 6. Demo de Karpanta: llistat de documents recuperats després d'una consulta
Un enfocament més elaborat pot requerir un reajustament dels pesos de termes, especialment si es té en compte, entre els documents recuperats per la consulta original, casos positius i casos negatius; és a dir, documents recuperats que s'han d'utilitzar per realimentar (exemples positius) i documents que explícitament s'han d'utilitzar com a exemples negatius (és a dir, que no es volen documents com aquests). L'aproximació més freqüent és la utilització del conegut algoritme de Rocchio (Rocchio, 1971). La implementació d'aquest algoritme en Karpanta requereix algun sistema perquè l'usuari, després d'examinar els documents obtinguts en una primera consulta, determini quins són els exemples positius i quins els negatius. Naturalment, aquesta qüestió es resol a través de la interfase amb l'usuari. El càlcul posterior dels pesos es fa mitjançant una simple sentència SQL (Grossman, 1997); això possibilita l'ajustament manual dels coeficients que cal aplicar (tant positius com negatius) sense que calgui alterar el codi del programa.
4 Accions futures
Atesos el caràcter i els objectius plantejats en el moment de dissenyar Karpanta, és evident que no es tracta d'un projecte tancat. Si bé la senzillesa i la flexibilitat amb què se l'ha dotat sacrifiquen lleument l'operativitat, permeten l'addició de noves prestacions. Podem dir, d'alguna manera, que es dissenyà així precisament per aquest motiu.
Entre les accions més immediates previstes hi ha la implementació d'un algoritme de lematització específic per a la llengua castellana, més eficient. Actualment, Karpanta porta incorporat un s-stemmer modificat, després que es descartessin altres algoritmes d'ús freqüent en el cas de l'anglès després d'haver-ne comprovat experimentalment el poc abast (Gómez Díaz, 1998). Actualment, un lematitzador flexional per al castellà és pràcticament a punt per ser utilitzat, i s'està treballant en l'elaboració d'un lematitzador derivatiu; sembla que no admet cap dubte que la lematització flexiva produeix millores importants en la recuperació, sobretot pel que fa a l'exhaustivitat i sembla que també en la precisió (Krovetz, 1993; Kraaij i Pohlmann, 1996), encara que en el cas concret del castellà caldrà provar-ho experimentalment. Quant a la lematització derivacional, es tracta d'un tema controvertit, i més encara depenent de quina sigui la profunditat de la lematització. Es tracta d'una bona oportunitat de veure'n els efectes i treure'n les conclusions pertinents.
D'altra banda, també es treballa en la implementació de la capacitat multilingüe. En un primer estadi, amb un esquema de consultes en castellà contra documents en anglès; encara que el plantejament teòric es pugui aplicar a qualsevol parella de llengües, és evident que una implementació requereix que el sistema tingui un coneixement lingüístic important i específic, des de la utilització de lèxics i equivalències en les dues llengües, fins a eines específiques de desambiguació que permetin seleccionar de manera automàtica les accepcions correctes en cada cas.
Il·lustració 7. Pàgina web de Karpanta a http://milano.usal.es/karpanta, d'on se'n pot descarregar una demo
5 Conclusions
S'ha dissenyat un programa de recuperació de la informació que aplica el model de l'espai vectorial, prou obert i flexible per ser utilitzat en la docència i en la investigació. La senzillesa de la seva arquitectura permet tant la fàcil observació de resultats i estructures intermèdies com la modificació i l'afegiment de nous mòduls i, consegüentment, l'experimentació. De fet, s'està utilitzant en la docència d'algunes matèries relacionades directament amb la recuperació automatitzada de la informació, i també en diversos treballs d'investigació. Així, s'utilitza per comprovar l'efecte en la recuperació de nous sistemes de lematització per al castellà, que actualment dissenyen membres del nostre departament; i és la base sobre la qual s'implementarà un sistema de recuperació multilingüe (castellà-anglès) sobre el qual estem treballant actualment.
Tot i que aquests són els objectius prioritaris perseguits en l'elaboració del sistema, el programa té prou prestacions per resultar útil en entorns operacionals, ja que es pot adaptar senzillament a diverses necessitats. Un exemple és la base dades especialitzada en ciències de la documentació Datatheké (http://milano.usal.es/dtt.htm), que es pot consultar a través del web i que, de manera interna, utilitza Karpanta com a motor de recuperació.
Bibliografia
Buckley, C.; Salton, G.; Allan, J. (1994). «The effect of adding relevance information in a relevance feedback environment». En: Proceedings of the Seventeenth Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, p. 292-300.
Codina, L. (1994). «Bases de datos relacionales: qué son y qué aportan a la gestión documental». Information World en español, núm. 29 (1994), p. 18-19.
Date, C. J. (1983). An introduction to database systems. Reading (MA): Addison-Wesley.
Gómez Díaz, R. (1998). La recuperación de la información en español: evaluación del efecto de las peculiaridades lingüísticas. Treball de grau (tesina), Universidad de Salamanca, Departamento de Informática y Automática.
Grossman, D. A.; et al. (1995). «Integrating structured data and text: a relational approach». JASIS, vol. 46 (1995).
Grossman, D. A.; et al. (1996). «Improving accuracy and run-time performance for TREC-4». TREC-4, NIST Special Publication, núm. 500-236 [en línia] <http://trec.nist.gov/pubs/trec4/papers/gmu.ps.gz> [Consulta: 14 febr. 2000].
Grossman, D. A.; et al. (1997). «Using relevance feedback within the relational model for TREC-5». TREC-5, NIST Special Publication, núm. 500-238 [en línia] <http://trec.nist.gov/pubs/trec5/papers/gmu.trec5.ps.gz> [Consulta: 14 febr. 2000].
Harman, D. (1991). «How effective is suffixing?». JASIS, vol. 42, núm. 1 (1991), p. 7-15.
Harman, D. (1992a). «Ranking algorithms». En: Information retrieval: data structures and algorithms. Englewood Hills (NJ): Prentice-Hall, p. 363-392.
Harman, D. (1992b). «Relevance feedback and others query modification techniques». En: Information retrieval: data structures and algorithms. Englewood Hills (NJ): Prentice-Hall.
Hull, D. (1996). «Stemming-algorithms - a case study for detailed evaluation». JASIS, vol. 47, núm. 1 (1996).
Kraaij, W.; Pohlmann, R. (1996). «Viewing Stemming as Recall Enhancement». En: ACM SIGIR 96. Konstanz (DE), ACM, p. 40-48.
Krovetz, R. (1993). «Viewing morphology as an inference process». En: Proceedings of ACM-SIGIR 93, p. 191-203.
Moya Anegón, F. de (1995). Los sistemas integrados de gestión bibliotecaria. Madrid: ANABAD, 1995.
Popovic, M.; Willet, P. (1992). «The effectiveness of stemming for natural-language access to slovene textual data». JASIS, vol. 43, (1992) p. 384-390.
Rijsbergen, C. J. van. (1979). Information retrieval. London: Butterworths.
Rocchio, J. J. (1971). «Relevance feedback in information retrieval». En: Salton, G. (ed.). The SMART retrieval system. Englewood Hills (NJ): Prentice-Hall, p. 313-323.
Salton, G. (1989). Automatic text processing: the transformation, analysis, and retrieval of information by computer. Reading (MA): Addison-Wesley.
Salton, G.; Buckley, C. (1988). «Term-weighting approaches in automatic text retrieval». Information processing & management, vol. 24, núm. 5, (1988) p. 513-523.
Salton, G.; McGill, M. (1983). Introduction to modern information retrieval. New York: McGraw-Hill.
Trigueros Díaz, J. L.; Higuera Matas, R. (1997). «Bases de datos relacionales versus bases de datos documentales». Boletín de la Asociación Andaluza de Bibliotecarios, vol. 13, núm. 49, (1997) p. 43-57.
Wilbur, J.; Sirotkin, K. (1992). «The automatic identification of stop words». Journal of information science, vol. 18, (1992) p. 45-55.
Glossari
Incloem a continuació una breu explicació d'alguns conceptes que hem utilitzat en aquest treball, per facilitar-ne la comprensió als lectors que no estiguin familiaritzats amb aquests temes:
Algoritme de Rocchio: quan s'expandeix de manera automàtica una consulta feta per un usuari, es pot realimentar utilitzant els documents recuperats per la consulta inicial que l'usuari assenyala com a rellevants. En aquests casos, cal recalcular els pesos o la importància dels termes de la nova consulta, o consulta expandida. L'anomenat algoritme de Rocc