
Anàlisi de consultes en un cercador i l'aplicació a la jerarquització de pàgines web1
Ricardo Baeza-Yates, Felipe Saint-Jean
Depto. de Ciencias de la Computación
Universidad de Chilerbaeza@dcc.uchile.cl, fsaint@dcc.uchile.cl
Resum [Abstract] [Resumen]
En la web hi ha diverses fonts d'informació. Una d'aquestes és la informació que deixa l'usuari mentre utilitza un cercador. És possible utilitzar aquesta informació per complementar el resultat d'algoritmes de jerarquització tradicionals, de manera d'agregar coneixement humà al resultat. Dins aquest concepte, en aquest treball es mostra una visió global de l'anàlisi del registre dels accessos al cercador TodoCL, i es mostra de manera general què és el que cerquen els usuaris en la web xilena. Després s'exposa una aplicació pràctica de les dades, en veure els resultats de la implementació d'un algoritme que determina rellevància i jerarquia de documents basant-se en les cerques i els documents seleccionats pels usuaris.
1 Introducció
De l'ampli espectre de dades que hi ha en la web que es poden analitzar per extreure informació, les dades d'ús de la web són de les més interessants, perquè representen els interessos actuals de la comunitat d'usuaris d'un lloc. Hi ha nombrosos treballs sobre anàlisis de dades de navegació en un lloc i l'ús per redissenyar-lo, però no sobre l'ús de serveis específics, com ara cercadors de la web. El text de Beeferman i Berger (2000) en constitueix una excepció.
En aquest estudi es detalla l'anàlisi de les accions de l'usuari en utilitzar un cercador, en aquest cas, un cercador de la web xilena: TodoCL (www.TodoCL.cl). Això és interessant des de dos punts de vista. D'una banda, millora la qualitat del lloc i dóna una experiència de cerca més bona a l'usuari del cercador. D'altra banda, l'usuari té una gran comprensió semàntica dels recursos i de les consultes involucrades, per la qual cosa la navegació i la utilització deixa un coneixement que pot ser utilitzat en els processos de cerca i jerarquització de documents.
Per fer l'anàlisi vam utilitzar 777.351 consultes dutes a terme durant l'agost i el setembre de 2001, que contenien 738.390 paraules, amb un vocabulari únic de 465.021 paraules. És a dir, de mitjana, només s'utilitzen 1,05 paraules per consulta. En el bitàcola o diari (log) de consultes, el cercador també enregistra la navegació que duu a terme, particularment les pàgines que escullen els usuaris. La majoria de les persones refinen la consulta mitjançant l'agregació o l'eliminació de paraules, però de mitjana només inspecciona 1,15 pàgines de resultats. S'han dut a terme estudis similars amb dades d'Altavista (Silverstein et al, 1999) i Excite (Wolfran, 2000 i Spink et al, 2002). En el nostre cas, agreguem una anàlisi de variabilitat de les consultes i també utilitzem els nostres resultats per millorar la jerarquització (rànquing) de pàgines, experimentant amb un algoritme proposat recentment (Zhang, 2002).
En la secció següent presentem l'anàlisi de consultes, incloent-hi paraules més buscades, la distribució que se n'ha fet i la variabilitat, les opcions de consulta i la relació de les consultes i les pàgines en la web xilena. En l'apartat 3 utilitzem un algoritme que permet millorar el rànquing de pàgines relacionades amb la consulta utilitzant les pàgines escollides pels usuaris. En la secció final en lliurem les conclusions i les extensions futures.
2 Navegació en el cercador
Els usuaris, en accedir al lloc, deixen la seva empremta en els registres o bitàcoles d'accés. A partir d'aquests és possible reconstruir el camí que ha seguit cada usuari. La reconstrucció no és tan directa com sembla, ja que la memòria cau del navegador fa que certs passos de l'usuari siguin omesos dels bitàcoles. Per exemple, pot ser que l'usuari hagi escrit la URL directament en el navegador (no a través d'un enllaç) i que la memòria cau del navegador carregui la pàgina sense demanar-la al servidor. En general, es va considerar que el cas en què l'usuari ingressa la URL directament és més petit, fet pel qual la majoria dels passos de navegació segueixen l'estructura del lloc.
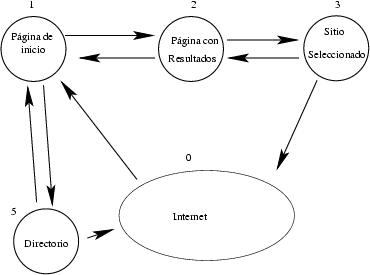
Figura 1. Mapa de navegació del lloc del cercador TodoCL
Una manera de representar la navegació és si es planteja com un graf, que es coneix com el mapa de navegació del lloc. La manera en què els usuaris naveguen pel lloc, és una font de dades que ens ensenya l'ús que donen al cercador. Per al cas del cercador TodoCL, el mapa de navegació del lloc es mostra en la figura 1, i n'indica els estats possibles.
L'anàlisi dels registres d'accessos genera el diagrama de la figura 2. Les transicions entre estats (nodes) representen la porció d'usuaris que en sortir del node d'origen van cap al node de destinació. Aquest nombre és una estimació de la probabilitat que, si un usuari està en l'origen de l'arc, vagi cap a la destinació d'aquest. Dins de cada estat hi ha la probabilitat que un usuari estigui en aquesta pàgina.
De la figura 2 es poden obtenir tres observacions:
- Els usuaris no utilitzen les opcions avançades (menys de l'1 %).
- El refinament de la consulta és comú.
- Només el 9 % de les persones utilitza el directori de llocs.
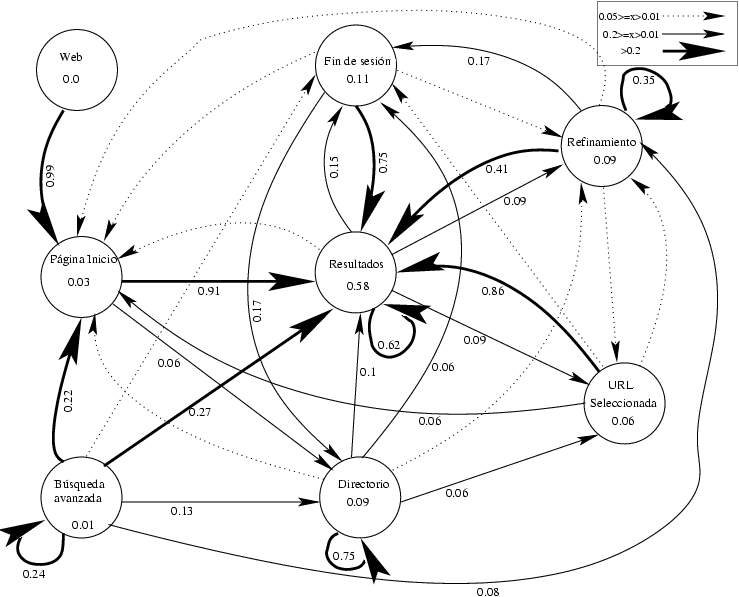
Figura 2. Navegació dels usuaris per TodoCL
Això vol dir que els usuaris, com a mètode de cerca, utilitzen la informació del desplegament dels resultats. És a dir, un mètode més pròxim a prova i error que a una cerca més precisa, que seria el cas de l'opció de cerca avançada. A més, en observar el gràfic veiem que la probabilitat que un usuari es trobi en la pàgina amb resultats és molt més gran que la probabilitat que un usuari es trobi en la URL seleccionada. Això significa que els usuaris visiten relativament poques pàgines de les del resultat, com s'ha dit més amunt.
3 Anàlisi de consultes
En aquest apartat també agreguem l'anàlisi de consultes d'un cercador espanyol que va estar en funcionament durant l'any 2001, Buscopio (www.Buscopio.com). Les dades utilitzades són del període que va de febrer a juliol de 2001. Això permet veure les similituds i diferències entre dos cercadors basats en el mateix idioma principal.
3.1 Freqüència de paraules i consultes
Les paraules més consultades en TodoCL i en Buscopio en els períodes estudiats es presenten en la taula 1. Les consultes simples estan formades per paraules i operadors; analitzarem aquest tipus de consultes, atès que constitueixen el cas més comú.
La figura 3 mostra la freqüència de les paraules consultades per a TodoCL. S'observa clarament que segueixen una distribució de tipus Zipf. La distribució de Zipf generalitzada compleix que la freqüència de la k-èsima paraula més freqüent és proporcional a k-α. El paràmetre α en aquest cas és aproximadament 1.
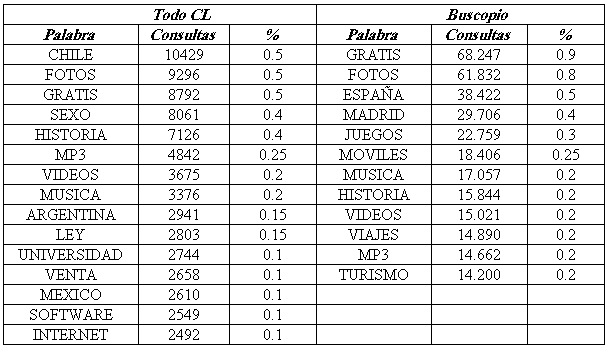
Taula 1. Paraules més consultades a TodoCL i Buscopio
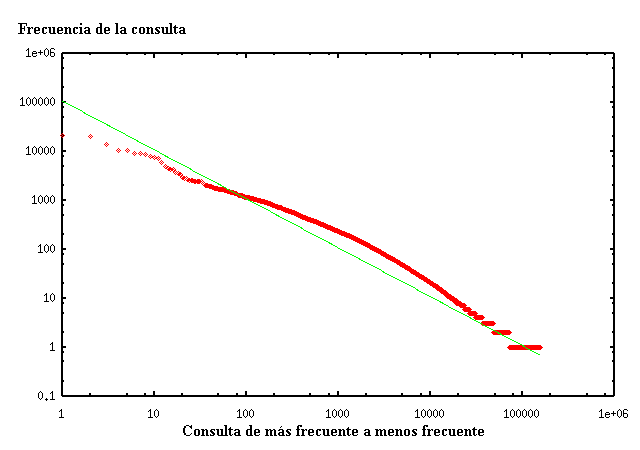
Figura 3. Freqüència de les paraules consultades en TodoCL
3.2 Variabilitat de la freqüència de consultes
Amb l'objectiu de veure quant varien les freqüències de les paraules consultades, es va estudiar la desviació d'aquestes freqüències. Així, es podria determinar si hi ha pics en les consultes d'algunes paraules.
El gràfic de la figura 4 mostra la desviació estàndard de la freqüència de les paraules consultades en TodoCL. D'aquest gràfic vam notar que la desviació estàndard de la freqüència de les paraules consultades en TodoCL segueix una distribució semblant a una distribució de Zipf amb paràmetre α=0,65.
Les paraules de més desviació estàndard a TodoCL són, en ordre de variabilitat, “Chile”, “boliviano”, “fotos”, “historia”, “invierno”, “gratis”, “ley” i “MP3”. És interessant notar la similitud entre les paraules més consultades de la taula 1 i de més desviació. De fet, el valor de la correlació entre ambdós estimadors és de 0,98, és a dir, estan altament correlacionats. En la figura 5 es pot veure la relació lineal entre la desviació estàndard de la freqüència diària i la freqüència total en el període, que es pot aproximar pel model x = 3y/2.
Algunes paraules tenen comportaments particulars. Fora del marge del gràfic, en la figura 4, hi ha paraules que surten molt de l'escala i es mantenen en la línia del model. Aquestes paraules són “de”, “en” i “la”. Una altra característica que és observable és que apareixen algunes paraules de relativament alta desviació però baixa freqüència, com ara “boliviano” i “invierno”. “invierno” és interessant perquè es tracta d'una paraula clarament estacional, la qual cosa justifica la baixa freqüència i l'alta desviació que té (particularment en el conegut fenomen de l'hivern bolivià).
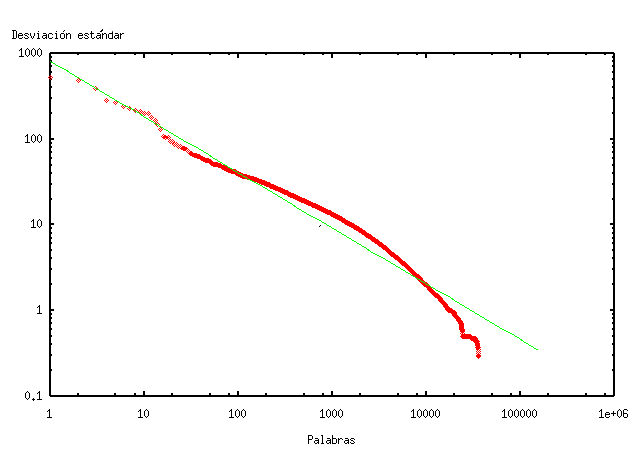
Figura 4. Desviació estàndard de la freqüència de les paraules consultades en TodoCL
Per a Buscopio, els resultats van ser semblants, tant en el gràfic de freqüència de consultes com en la relació de les consultes d'alta variabilitat que eren molt freqüents. Les preguntes amb més variació van ser “britishairways” (sic), “gratis”, “españa”, “madrid”, “viajes”, “arpanet”, “juegos” y “minis”.
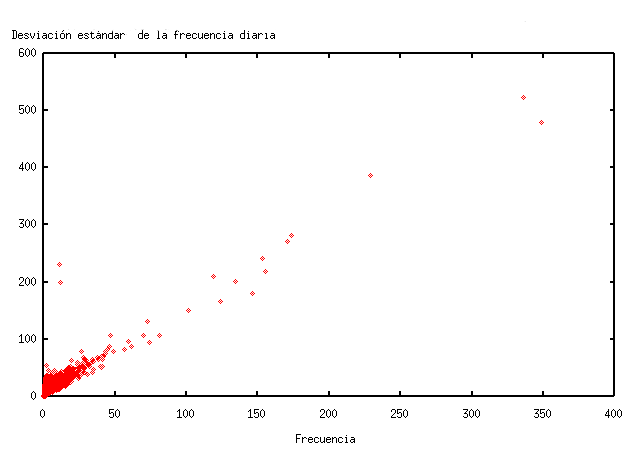
Figura 5. Freqüència de consulta vs desviació estàndard en TodoCL
3.3 Opcions de consulta
En utilitzar un cercador és possible alterar els paràmetres sota els quals es durà a terme la consulta. Els paràmetres que hi ha en el tipus de cerca simple són:
- Operador amb valors AND, OR o FRASE. El valor AND busca documents que tinguin totes les paraules; OR, documents amb alguna paraula; FRASE, documents que continguin la frase exacta.
- Considerar o no accents en la consulta.
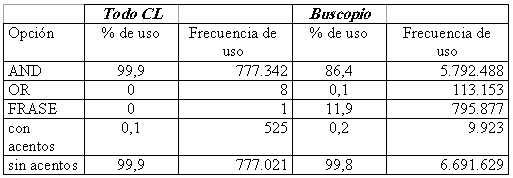
Tabla 2. Ús d'opcions de cerca en TodoCL (esquerra) i Buscopio (dreta)
En la taula 2 es poden veure els nivells d'utilització de cada opció en TodoCL i Buscopio. Els valors més alts són els valors per omissió. Això dóna una gran importància a les opcions per omissió, ja que la seva elecció serà determinant, en molts casos, per al bon resultat de les consultes. És interessant veure que la cerca de frases és molt més usada en Buscopio. Una raó possible és que la web espanyola és més gran i aleshores cal que la consulta sigui més precisa per obtenir pàgines més rellevants.
3.4 Paraules consultades en el contingut
Les paraules consultades i les que apareixen en les pàgines segueixen distribucions semblants. Sorgeix la pregunta sobre la relació que tenen. En el gràfic de la figura 6 es veu la relació entre els documents rellevants i la quantitat de consultes de les paraules. El més comú són paraules amb pocs documents rellevants i poques consultes. Hi ha paraules amb pocs documents i moltes consultes; en són exemples “Hentai”, “México”, “DivX”, “carátulas” y “melodías”. Les paraules amb molts documents rellevants i poques consultes són, en general, paraules funcionals (anomenades paraules buides o stopwords). Per exemple, preposicions, pronoms i articles com ara “pero”, “otros”, “este”, etc. Les paraules amb molt contingut i moltes consultes, en general, són també stopwords com ara “y”, “de”, “el” i “la”; però apareix de manera interessant “Chile” com a paraula molt consultada i que apareix en moltes pàgines. Les paraules poc consultades i amb poc contingut no són interessants, ja que n'hi ha moltes. La relació entre les paraules consultades i les del contingut no és clara, però la seva correlació és baixa.
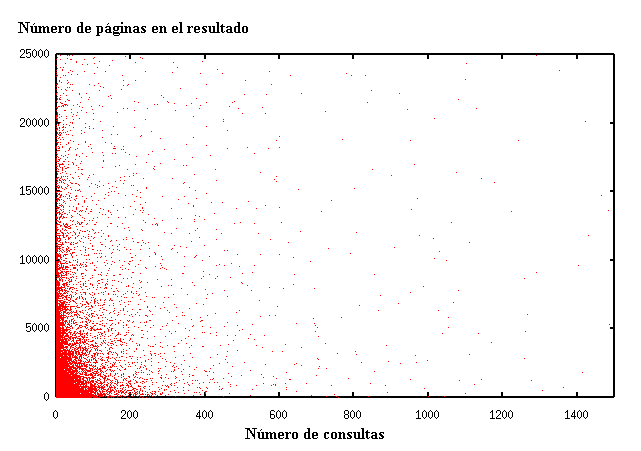
Figura 6. Quantitat de consultes vs documents rellevants per a les paraules
4 Jerarquització de pàgines
A Zhang (2002) es proposa un algoritme per millorar els resultats d'un cercador, basant-se en les consultes fetes pels usuaris. L'algoritme proposat s'anomena MASEL (Matrix Analysis on Search Engine Log). Aquest algoritme proposa un mètode que relaciona consultes, usuaris i URL seleccionades pels usuaris. MASEL és proposat per a un cercador de multimedis, en què la comparació entre el document i la consulta és d'un nivell de precisió molt baix.
4.1 L'algoritme MASEL
La idea bàsica és obtenir recomanacions d'usuaris que queden reflectides en els logs d'accés del cercador, perquè és on hi ha l'adreça IP de l'usuari, les consultes que ha fet i les URL que ha escollit. És discutible quant identifica l'adreça IP a l'usuari, però es va considerar que, durant un període curt de temps, darrere d'una IP hi ha sempre el mateix usuari en la majoria dels casos.
L'algoritme considera simultàniament consultes, usuaris i documents, sota una definició recurrent sobre aquests tres elements. Els bons usuaris faran bones consultes, les bones consultes retornen bons documents i els bons documents són seleccionats per bons usuaris.
Donada una consulta q*, l'algoritme aplica quatre etapes per obtenir un conjunt de resultats:
- Primer s'obté el conjunt de tots els usuaris que han consultat q* recentment, conjunt que anomenarem U. Aquesta informació es troba en els logs d'accés del cercador.
- Després s'obté el conjunt de totes les consultes dutes a terme recentment pels usuaris en U, conjunt a què anomenarem Q. També en els logs d'accés del cercador hi ha aquesta informació.
- A continuació s'obté, mitjançant tècniques tradicionals de recuperació d'informació (per exemple, usant el mateix cercador), el conjunt de documents rellevants al conjunt de consultes Q. Aquest conjunt l'anomenarem R.
- Finalment es calcula, mitjançant un procés iteratiu, els valors numèrics que permeten jerarquitzar consultes, usuaris i documents. Aquest procés iteratiu serà explicat més endavant.
En referir-se a recentment s'està parlant de l'interval [t-T, t] on t és el present i T és un paràmetre de l'algoritme. Siguin m=|U|, s=|R| i n=|Q|, a més ui valor que representa la qualitat de l'usuari i, qj la qualitat de la consulta j i rk la qualitat del document k (després s'explicarà com s'obtenen aquests valors). Utilitzarem valors normalitzats, és a dir ∑U ui = ∑Q qj = ∑R rk = 1, la qual cosa no afecta els resultats, ja que ens interessa el seu ordre , i no els valors mateixos de qualitat. Aquesta normalització s'ha de dur a terme després de cada iteració.
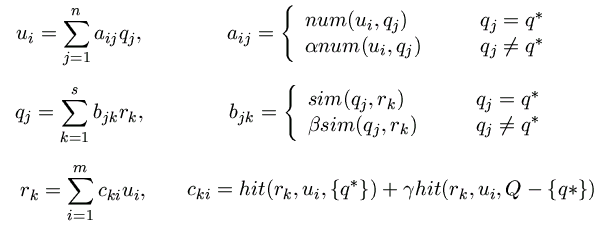
Figura 7. Fórmules per a MASEL
Definim els pesos per als usuaris segons les seves bones consultes en la figura 7 (primera línia), on num(i,j) representa quantes vegades l'usuari ui va efectuar la consulta qj recentment i 0< α <1 és un pes per treure rellevància a les consultes distintes a q*.
Definim les bones consultes segons recuperen bons documents en la segona línia de la figura 7, on sim(qj , ) és la similitud entre el document rk i la consulta qj i 0< β <1 és un pes per treure rellevància a les consultes distintes a q*.
Finalment definim els bons documents segons la preferència dels bons usuaris en la tercera línia de la figura 7, on hit(rk, ui, S) és la quantitat de vegades que l'usuari ui va escollir el document rk en fer una consulta en el conjunt S i 0< γ <1 és un pes per treure rellevància a les consultes distintes a q*. En forma matricial tenim u=Aq, q=Br , r=Cu cosa que implica que u=Aq=A(Br)=A(B(Cu))=(ABC)u, q=Br=B(Cu)=B(C(Aq))=(BCA)q, y r=Cu=C(Aq)=C(A(Br))=(CAB)r
Això defineix un mètode iteratiu per calcular u, q i r. És a dir, podem obtenir els millors usuaris, consultes i documents.
El paràmetre T, que defineix la finestra de temps en la qual vam mirar les bitàcoles o registres d'accessos, és fonamental en l'efectivitat de l'algoritme. Si T és molt gran, el conjunt de consultes estès comença a abraçar massa elements no rellevants a la consulta inicial. D'altra banda, si T és molt xic, estem malgastant informació. El complex de la determinació del paràmetre T és que el seu valor ha de dependre de la freqüència de la consulta (que ja vam veure que segueix una distribució de Zipf). A més, un paràmetre T més gran fa les matrius més grans i l'algoritme més lent.
El mètode va operar bé en TodoCL, i va donar resultats rellevants a les consultes. En general, el resultat tendeix a un parell de documents amb qualificació molt més gran que la resta, la qual cosa fa de MASEL un bon algoritme per utilitzar-lo com una ajuda paral·lela als resultats del cercador mentre lliura a l'usuari llocs populars relacionats amb la seva consulta. Per exemple, es va consultar per “autos” amb T = 24 hores i T = 48 hores. Amb T = 24 hores les URL més recomanades van ser:
- http://www.chileautos.cl/link.asp
- http://www.chileautos.cl/personal.htm
- http://www.autoscampos.cl/frmencabau.htm
- http://rehue.csociales.uchile.cl/publicaciones/moebio/07/bar02.htm
Les primeres tres pàgines són rellevants, però la quarta no. Amb T = 48 hores les URL més recomanades van ser:
- http://www.mapchile.cl/
- http://fid.conicyt.cl/acreditacion/normas.htm
- http://www.clancomunicaciones.cl/muni_vdm/consejo.htm
en què la segona i tercera URL no són rellevants, però la primera és rellevant tot i que no conté la paraula “autos”, perquè és un lloc de mapes que es pot considerar útil per a un automobilista. Això mostra la capacitat de l'algoritme de relacionar semànticament recursos de la web. Podem veure en aquest exemple la gran dependència del mètode respecte del paràmetre T.
4.2 Anàlisi de precisió
Es va aplicar l'algoritme anterior a paraules de diferent nivell de freqüència de consulta per a diferents valors del paràmetre T. En la figura 8 es veu la precisió de l'algoritme per a les consultes “software”, “bancos” i “empresas”. Les tres paraules són consultades freqüentment. “Software” és força més consultada que les altres dues paraules, i veiem que l'algoritme comença a obtenir bons resultats per a valors de T menors. “Banco”, per a T = 72, obté una precisió excel·lent, que decreix en augmentar T. És clar que per a un bon funcionament de l'algoritme, T ha de dependre de la freqüència de consulta de la paraula, i no ha de ser pas una constant, com proposa el treball original. Cal dir que on la precisió és 0 és perquè l'algoritme no va retornar resultats.
Una observació interessant és que en algunes de les consultes dutes a terme, entre els resultats sorgia un tema secundari amb una gran quantitat de documents rellevants. Per exemple, per a la consulta “banco”, molts dels documents no rellevants es referien a “venta de casas”. A més, la precisió baixa perquè “banco” té altres significats en contextos no comercials. Això mostra que aquesta heurística funciona només amb el significat principal d'una paraula. Un altre exemple és que en la consulta “software” va sorgir com a matèria secundària el reciclatge de vidres, i gairebé tots els documents van esdevenir no rellevants en relació amb aquest assumpte. Aquest fenomen s'anomena desplaçament temàtic (topic drifting) en recuperació d'informació en la web quan s'utilitza informació d'enllaços entre pàgines.
Per a consultes encara més populars, les grandàries de les respostes van ser prou grans com per fer impossible l'anàlisi de les dades manualment, per la qual cosa no es va poder determinar la rellevància dels resultats. Aquest va ser el cas de les consultes “àudio” i “moda”. Si la freqüència de la consulta no és alta, no és possible usar aquesta tècnica; per exemple, per a la consulta roba no van sorgir documents rellevants, i per a “traductor” es van recuperar sempre els mateixos dos documents, tots dos no rellevants.
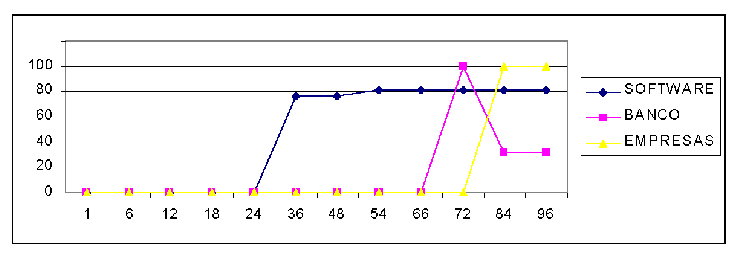
Figura 8. Paràmetre T vs precisió de l'algoritme
Per a la consulta “chile”, en poques de les pàgines Xile era l'assumpte principal, i era gairebé en totes les pàgines un tema relacionat. D'altra banda, la temàtica principal en totes les altres pàgines estava relacionat a celebritats o esports de Xile, la qual cosa és interessant perquè en fer una cerca per “Chile” no apareix cap resultat relacionat amb aquests assumptes en els primers 30 resultats. Per a valors de T més grans de 48 la quantitat de documents recuperats va ser enorme.
5 Conclusions
Hem presentat una anàlisi de consultes d'un cercador xilè, que dóna informació dels internautes de Xile. També hem inclòs resultats d'un cercador espanyol, Buscopio. En resum, podem dir que les consultes no són sofisticades i no aprofiten tot el potencial d'un cercador. D'altra banda, cal aprofundir en l'anàlisi i descobrir si hi ha patrons en les consultes. Per exemple, paraules permanents, paraules amb una certa periodicitat i paraules transitòries. La nostra anàlisi de variació no va permetre distingir entre les paraules permanents i les transitòries, sembla que perquè la freqüència d'aquestes darreres és molt baixa. Es pot trobar una comparació entre les webs de Xile i Espanya que complementa aquest estudi a Baeza-Yates (2002).
Respecte a l'ús de les consultes per a rànquing, cal definir la dependència de T en la freqüència de la paraula, com a manera d'obtenir bons resultats a partir de totes les consultes, ja que l'algoritme és poc eficaç per a valors molt petits de T i poc eficient (a més de poc eficaç) per a valors molt grans de T. Una anàlisi més detallada podria donar un model aproximat per a la dependència de T respecte a la freqüència.
Pel tipus de resultats de l'algoritme n'és recomanable la utilització com a ajuda complementària a una cerca amb mètodes més estables de recuperació de documents, pel fet que per a moltes consultes poc populars recupera pocs documents o cap. També, com ja hem esmentat, només serveix per al significat més freqüent. En termes d'interfície d'usuari, a més dels resultats tradicionals de la cerca, es recomana agregar un quadre lateral que esmenti recursos populars entre els usuaris amb els millors resultats de MASEL enfront de la consulta duta a terme.
Els nostres resultats mostren que el problema de generalització del tema o de desplaçament (topic drifting) també apareix en usar informació de navegació. En el nostre cas és possible que la seva aparició pugui ser controlada mitjançant la reducció dels valors fixats per als paràmetres α, β i γ.
Els resultats també es podrien millorar si es detectessin diverses sessions per al mateix número IP, que poden indicar diferents usuaris. Tanmateix, detectar sessions de manera precisa és un dels problemes més difícils de l'anàlisi de registres d'accessos.
Referències
Baeza-Yates, Ricardo (2002). “La web de España”. Novática, nº 157 (2002), p. 45-46. Publicat en versió en anglès: http://www.upgrade-cepis.org/issues/2002/3/upgrade-vIII-3.html.
Beeferman, Doug; Berger, Adam (2000). “Agglomerative clustering of a search engine query log”. En: Conference on Knowledge Discovery and Data Mining (2000: Boston). KDD-2000: proceedings, August 20-23, 2000, Boston, Massachusetts, USA : the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: Association for Computing Machinery, c2000, p. 407-416.
Silverstein Craig; Henzinger, Monika; Marais, Hannes; Moricz, Michael (1999). “Analysis of a very large AltaVista query log”. SIGIR forum, vol. 33, no. 3, (1999).
Spink Amanda; Jansen, Bernard J.; Wolfram, Dietmar; Saracevic, Tefko (2002). “From e-sex to e-commerce: web search changes”. IEEE Computer, vol. 35, no. 3 (2002), p. 107-109.
Wolfram, Dietmar (2000). “A query-level examination of end user searching behaviour on the Excite search engine”. Canadian Association for Information Science. Conference (28ª: 2000: Edmonton, Alberta). Dimensions of a global information science: CAIS 2000, 28th Annual Conference of the Canadian Association for Information Science to be held with the Congress for the Social Sciences and Humanities of Canada at the School of Library & Information Studies University of Alberta Edmonton, Alberta, Canada May 28-30, 2000. http://www.slis.ualberta.ca/cais2000/wolfram.htm.
Zhang, Dell; Dong, Yisheng. “A novel web usage mining approach for search engine”. Computer Networks, [propera publicació]
Data de recepció: 25/02/2003 Data d'acceptació: 05/03/2003.
Notes
1 Parcialmente financiado por Proyecto Fondecyt 1020803, Chile.