Abstract [Resum]
Objectives. Relationships have powerful, but poorly understood, effects on how information objects are represented, structured, and processed in computational environments. This paper describes a preliminary investigation and innovative approach to the relationship problem in the context of archival discourse.
Methodology. It examines how ontological tools and content analysis techniques can be adapted and refined to help researchers identify, capture, and classify relationships expressed in image descriptions. Additional insight is offered by examining relationships in light of three describing contexts: image searcher, curator, and cataloger. The nature of the sample data is discussed, including how data is validated and reliability determined.
Results. Limitations of previous relationship research are considered and a new methodology is introduced that is designed to assist researchers in effectively predicting relationships occurring in textual descriptions.
1 Introduction
This paper reports on a preliminary investigation carried out as part of the author's dissertation research into the relationship problem. It is a feasibility study designed to test the benefits and difficulties of using content analysis techniques and ontological tools for capturing instances of relationships and then classifying these instances into families of relationship types.
Relationships are associations between two or more entities or classes of entities (Green 2001, p. 3). They are the glue that holds together concepts and word senses. While relationships play important roles in how humans express ideas, little is known about how to effectively capture, represent, structure, and process relationship information in computational environments. It is therefore reasonable, at this point in time, to formulate some kind of a methodology for discovering and structuring relationship information, especially when one considers the growing reliance on machines to read and make human-like sense of staggering amounts of information measured in terms of exabytes and zettabytes.
This paper is directed towards two broad audiences. First, it introduces tools and a methodology for researchers in LIS (Library and Information Science) who study the relationship problem in image descriptions. While the method applied here does not attempt computational implementation of a new kind of descriptive machinery, it provides the framework for building a corpus data set of relationship instances and types that naturally leads to the next step possible —ontology-based representation of image content in knowledge-based systems. Second, the methodology described here can be adapted to other problem areas concerned with natural language understanding and ontology-based representation. This could include archival description in general, or more obscure domains such as cultures that believe in sun gods. Whatever the case may be, this paper stresses the usefulness of using preliminary investigations to sort out countless problems in the content analytic approach before beginning a main body of research.
This paper has seven sections following this one. In the first, the limitations of previous relationship research in LIS literature are considered. Sections explaining the data sample, the research methodology applied, and construction of a Corpus of Relationships follows this. Section 6 describes how data is validated and reliability determined and Section 7 presents interesting findings and limitations of the study. Conclusions are presented in Section 8.
2 Previous efforts
This section lays down the interesting intellectual activity evident in the LIS literature that addresses relationships and their role in organizing information, especially visual information expressed in image descriptions. There is a significant literature devoted to naming and categorizing attributes and visual primitives, but few empirical studies try to account for relationships in image descriptions, so the potential for LIS contributions to this debate could be substantial.
The earliest literature in this review demonstrates that relationships and their classification are important for building associations between documents and concepts within documents. Beginning in the 1980s, Farradane (1980a & 1980b) introduced a schema consisting of nine relationship categories, which he applied to the analysis of textual documents. While he drew important distinctions between concepts and relationships in general, he did not clearly distinguish between natural language processing problems and the notion of symbolic representation. This led to problems in his analysis concerning how to account for ambiguities among terms, for example, the multiple meanings of the preposition ‘of.'
The past has seen many studies of the relationship problem as it relates to entities outside the semantics of document content. Shatford Layne studied the relationships that exist between image objects in different formats and between images and related textual documents. Examples include the relationships between photographs of buildings, their corresponding architectural blueprints, and architects' biographies (Shatford, 1986; Shatford Layne, 1994). Enser and McGregor (1993) were the first researchers to give serious attention to image descriptions as expressed by the image researcher. Their interest in the relationship problem, however, was limited to relationships among user types and relationships between general categories of images they termed unique and non-unique.
Keister (1994) made the critical observation that semantically rich image descriptions found in image searchers' queries, such as "the man sitting in the chair with the box on his head," could not effectively be represented by catalogers using word-based indexing systems. She offered no immediate solutions, but her observations strongly suggested that the relationship problem partially concerned representation and process —that is, how could catalogers represent semantically rich expressions in information systems so researchers could find the images they want. In spite of these revelations, researchers continued to consider the role of relationships within the syntactic structure of the sentence and attempted capturing this meaning in indexing systems.
A major shift in thought emerged when Svenonius (2000) considered the notion of using relationships to reason over concepts. She envisioned machines capable of reading documents and determining subject categories (Svenonius, 2000, p. 49). Green (1996) and Bean & Green (2001) shared similar viewpoints and began exploring how reasoning over relationships might enhance the discovery process and enable searchers to find information that would otherwise go unnoticed. Green, however, argued that the number and complexity of relationship types made it an impractical task expecting information professionals to consistently and effectively apply relationships in information systems. The study reported on here and subsequent dissertation research test this contention.
To summarize, it remains that little is known about the nature and scope of relationships expressed in the contexts of describing, searching, and retrieving images, or the intellectual problems posed by these activities. It seems likely that a complete understanding of relationships represented in image descriptions must include the activities of catalogers, image searchers, and curators situated in the social milieu of archives. The goals of the preliminary investigation, therefore, focus on developing a method for predicting occurrences of relationships and representing them in a manner that effectively leads to their representation in a machine environment.
3 Data sample
The data used in this study consists of textual descriptions of images collected from the correspondence files of the Pittsburgh Photographic Library (PPL). The PPL was established in 1950 at the University of Pittsburgh. Its central mission has remained the same over the years, to provide researchers with photographs for use in newspaper and magazine stories, talks, pamphlets and other publications promoting Pittsburgh's history and culture. In 1961, the collection moved from the University to its current home at the Carnegie Library of Pittsburgh. In March 2000, the estimated total holdings for the Library numbered 57,008 prints, 58,292 negatives, 1,234 slides, 310 lantern slides and 13,000 contact prints (Pittsburgh Photographic, 2000).
The Pittsburgh Photographic Library maintains a paper-based correspondence file dating back to 1963 that contains 1,673 documents. Within this set there are a total of 180 documents related specifically to photograph requests, which form the Corpus Data Set for the current study. A random sample of 45 incidents were selected for analysis. Nine of these were used in the preliminary investigation. The remaining 36 incidents are analyzed during the author's thesis research project.
Examining the whole question of relationships as they are naturally expressed during reference transactions requires that the boundaries between image content and language be viewed with a fresh eye. First, there is the searcher who presents a query describing known, sometimes unknown, and possibly non-existent images. A sample is presented in Figure 1.
Figure 1. Sample correspondence from visual researcher requesting photographs from Pittsburgh Photographic Library.
Second, curators play the role of mediator, describing and interpreting image content during the process of mediation. Figure 2 illustrates an example of correspondence where the curator must determine a photographer's point of view placing a camera "on the stage area" viewing the "audience from the stage."
Figure 2. Sample correspondence from Pittsburgh Photographic Library curator in response to image searcher's query.
Finally, there is the cataloger whose role is to describe photographs in catalog records that are consulted during search and retrieval by the curator and image searcher. Catalogers' descriptions, such as the one accompanying the contact print in Figure 3, not only have interpretive and aesthetic dimensions. They also have meanings cued in part by description standards and local processing procedures.
Figure 3. Lou Malkin. Carnegie Library – Director's Office, December 17, 1973. From the Pittsburgh Photographic Library Picture Catalog. (Reprinted with permission.) Carnegie Library of Pittsburgh. All Rights Reserved. Unauthorized reproduction or usage prohibited.
It was not the intention of the preliminary investigation to necessarily analyze how these groups describe relationships differently, although this analysis was carried out on a limited basis during the dissertation research. Rather, the intentions were to test the feasibility of applying content analysis and ontological analysis to multiple contexts within a domain. Section 3 explains in part how the researcher carried this out in the discursive space of archives. The approach is motivated by the belief that description is not a solitary act, but the result of social practices. Researchers approaching other problem domains are encouraged to code and analyze their data sets along similar, multiple dimensions from different frames of reference.
4 Research methodology
The focus of the investigation was to determine the benefits and difficulties of using content analysis techniques and ontological tools for carrying out relationship research. The goals of the study were threefold: 1) develop and refine a codebook and forms for capturing relationships occurring in natural language descriptions, 2) refine the use of ontological tools and methods for predicting relationship instances and organizing them into families of relationship types, and 3) test intra-coding reliability and instrument validity.
To be useful in this investigation, the content analytic and ontological tools had to be honed for specific tasks and adapted to particular problems, especially in the case of ontology. If ontology in the modern sense is going to become a useful tool in LIS, it needs a practical and specific problem it attempts to solve.
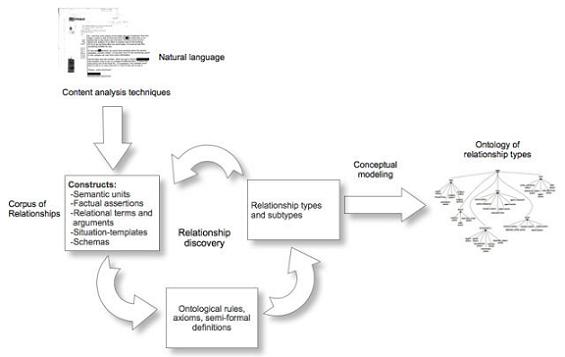
Figure 4 illustrates the methodological approach developed during the preliminary investigation and subsequent dissertation research. The first problems to overcome are shown at the beginning of the workflow in the diagram. The first challenge is how to empirically ground the identification and capture of relationships in natural language descriptions and then formalize these into some higher order language so they can be used as tools to answer important research questions. The solution offered here is to begin with content analysis as a way of parsing natural language into smaller and smaller units until arriving at the heart of the relationship, then recording these findings in a corpus of predicted relationships.
Figure 4. Architecture of the Corpus and Ontology Construction.
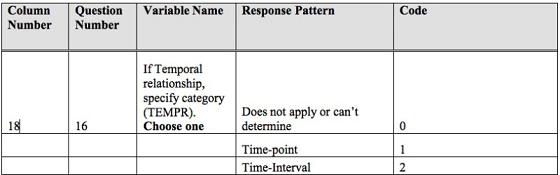
The researcher begins by using content analysis to parse the natural language into more formal propositions. Krippendorff (2004) defines content analysis as "a research technique for making replicable and valid inferences from texts (or other meaningful matter) to the contexts of their use" (p.18). Content analysis coding instructions and forms are used for coding the sample data set in both the preliminary investigation and dissertation study. An excerpt from the coding instructions for temporal relationships is pictured in Figure 5.
Figure 5. A portion of the coding instructions illustrating how temporal relationships are coded.
The coding forms are assembled into a corpus. A corpus —what is essentially a book of tabloid-sized spreadsheets— captures and records the results of the content analysis. A more detailed description of the corpus is presented in Section 6.
A battery of ontological tools offers formal and semi-formal definitions to aid in predicting and classifying instances of relationships. Some of the key tools used for ontological analysis of relationship types include Cooper's analysis of English locative prepositions (1968), Veda Storey's analysis of case relationships (1993), IDEF5's class inclusion relationship library (Perakath, 1994), Winston, Chaffin, and Herrmann's taxonomy of part-whole relations (1987), Wand, Storey, and Weber's ontological analysis of relationships (1999), and Sowa's case relations (2000). These resources play a role in constructing the environment in which analysis takes place. They help explain how relationships are determined based on particular words that are used to infer the relationships.
Ontological analysis assists in determining the category of relationships in which a particular instance belongs. Seven a priori relationship types were applied during the preliminary study's content analysis and coding:
- Attribution
- Case
- Inclusion
- Meronymy
- Spatial
- Synonym
- Temporal
While it is outside the scope of this paper to present the results of the dissertation research, it is useful to point out that during subsequent analysis, certain categories were added and taken away from this list. The synonym category was dropped. While synonyms are important relations for natural language processing and semantic lexicons, there is no place for them in ontologies where concepts must be unambiguous. Inclusion was also dropped. While the role of class inclusion in an ontology is fundamental for building taxonomies (standard subtype and supertype relationships), the data analysis showed that class inclusion relationships are not explicitly stated phenomena in image descriptions themselves. An instance relationship type was added to account for relationships that associate instances with classes. Lastly, it was discovered that kinship relationships occur often in the domain of image descriptions, so kinship was added to the list as a new category of relationship types.
The relationship discovery process shown in Figure 4 is circular because reality is messy. Sometimes a formalization is unclear, or there is no rule that explains the kind of relationship that emerges. Other times the relationship is non-prototypical, in which case the researcher either assigns a relationship to a category knowing full well that the attributes assigned to the category do not apply in every instance, or the researcher creates a finer-grained partition that will enable others to understand the fringe instances. Eventually the researcher acquires an ontology of relationship types.
To summarize, a basic set of tools are refined and adapted to the systematic investigation of the relationship problem. These include content analysis, which is used to parse natural language into more formal factual assertions; a corpus organizes and structures the domain of interest; and a battery of ontological tools are used for analyzing and determining relationship types.
5 Corpus construction
This section discusses in more detail the nature and purpose of a corpus. A linguistic corpus is defined as "The body of written or spoken material upon which linguistic analysis is based" (Oxford English Dictionary Online, March 2011). The corpus being compiled in this study is designed for a narrowly defined purpose: to aid in the analysis of relationships expressed as part of the discourse in the PPL. The corpus is manually constructed and proceeds through three stages of parsing.
Stage One: In the first stage of parsing, a careful reading is made of the entire content of the incident. A determination is made regarding what portion of text describes image content and then recorded as a semantic unit and assigned a semantic unit number.
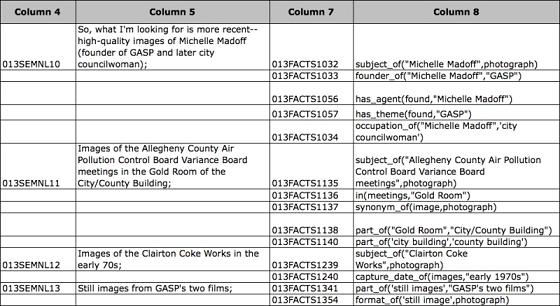
Stage Two: The second stage of parsing involves analyzing the semantic unit into factual assertions representing relationships. A special notation is applied called prefix notation that sets the relational term out in front where it can be easily seen. The relationship arguments are then placed inside parentheses separated by commas. Figure 6 is an excerpt from the Corpus of Relationships. It illustrates semantic units taken from the sample along with their corresponding factual assertions.
Figure 6. Sample from the Corpus of Relationships illustrating original semantic units from image searcher's correspondence (Column 5) and the factual assertions that were parsed from the original natural language (Column 8).
Stage Three: The third and final stage of parsing in the Corpus of Relationships involves analyzing factual assertions to determine what types of relationships are present and what are their component parts (themes, reference objects, places, paths, subjects, temporal units, and so on).
Schmied's (1990) Corpus theoretical paradox is addressed by adopting a cyclical process approach. In general, Schmied's paradox is a chicken or the egg dilemma. The Relationship Corpus resulting from this investigation should be representative of the language used in photograph archives. The problem, however, is that in order to accomplish this task the researcher must first determine these variables empirically through analysis of results from a representative corpus. So the questions are where to begin and when to stop.
The method for addressing this paradox adopts Biber's view that corpus design is a cyclical process (Biber, 1993, p. 256). In the current study it began with a preliminary investigation. The cyclical improvements made during the pilot study were documented, extending and refining the scope of variables until no additional varieties could be detected. The stopping criteria as described by Bauer and Aarts (2000, p. 32-34) determines that once saturation is reached it is time to stop the cycling process. Saturation occurred in the pilot study when adding further relationship types and instances and the variables defining them made only a small difference with regard to additional representations of semantic units and factual assertions.
6 Validity and reliability
Little is known about how to validate ontological models. That is, to what degree a set of ontological commitments faithfully represent a domain of interest. The test for validity of predicted relationships in this study is the degree of accuracy with which a relationship instance (factual assertion) matches the nature and characteristics of ontological relationships defined in one of several resources. Several different sources are used for validation in this study. (See listing in Section 4). The relationship definitions in these studies assist in forming one-to-one relationships —a mapping function— from the variable expressed and coded in searchers', curators', and catalogers' discourse to the phenomena the relationships are inferring.
Weber (1990) notes that in order to make valid inferences from text, the procedures used for classification must be reliable, stable, and consistent. Reliability in this study is concerned with consistency of measurement —that is, the degree to which individuals code the same data set the same way each time using a set of coding instruction under the same conditions. In the current study, the researcher performed all of the coding, so analysis of intra-coding reliability (as opposed to inter-coding) on the use of a codebook and forms is performed using test-retest reliability model. The measure of reliability is the percent of agreement between coding a data set on one date and then repeating the process at a later date. Kappa statistics were used, which approaches +1.0 as coding is perfectly reliable and goes to -1.0 when there is no agreement other than what is expected by chance (Wood, 2007; Stemler, 2001; Shrout; Fleiss, 1979).
Intra-coder reliability assessment was conducted during July-August 2010 measuring agreement on 17 of the variables being measured in the coding form. The coefficient for all variables corrected for chance ranges between 0.394 and 1.0 —a range where strength of agreement for Kappa coefficients is considered fair to almost perfect.
7 Discussion
The preliminary investigation demonstrates that once ontological tools and content analysis techniques are properly honed for the specific purpose of carrying out relationship research, they are effective in identifying, capturing, and classifying relationship instances, which can then be recorded in a corpus. Where earlier research failed because of its dependence on word indexing models, this preliminary study suggests that an empirically grounded method using content analysis and ontology can more effectively get at the meaning of relationships and the semantics that lie beneath the surface structure of words.
There are limits, however, to the claims that can be made during this preliminary investigation. Understanding how humans express relationships and the difficulties of capturing and classifying relationship types is difficult work. Many times problems are solved. Other times new problems arise that can only be addressed in subsequent research. In the discussion that follows, the researcher describes four problems that arose during the initial investigation that evolved into more specialized areas of research during the dissertation study. These include issues pertaining to scope of analysis, pragmatic inference, case relations, and predicting relations.
7.1 Scope and definition
The first problem is a problem of scope and definition —that is, what data should be considered suitable for content analysis. Visual anthropologist Malcolm Collier maintains that in the process of analyzing visual information, previously unseen phenomena and relationships are discovered beyond the boundaries of what was initially perceived by the photographer and subject in the image (Collier, 2001, p. 35).
During initial testing of the content analytic technique, only typewritten text was analyzed. During retesting, the definition of the domain of interest was expanded to include all data visible on the surface of the document, which included, for example, handwritten inscriptions, scribbles, and drawings, many of which were considered relevant and requiring identification, sorting, and classifying in the coding form.
This observation suggests adopting a more visual analytic process for image descriptions, one that considers the domain of interest to include both the original text and handwritten inscriptions on photographic prints and other associated records. More generally, this provides a lesson in the value of preliminary investigations for sorting out coding problems on small samples before jumping into large data sets.
7.2 Pragmatic inference
The next problem concerns the importance of pragmatic inference and the role it plays in conducting content analysis. Inference is a type of reasoning that manipulates known propositions to produce new ones (Levesque; Lakemeyer, 2000). The researcher expanded on this definition, taking into consideration what words mean or imply in different contexts —what is considered the pragmatic side of inference. The preliminary analysis showed that a great amount of what is perceived in image description discourse is in fact inferred and drawn from background knowledge that the speaker and listener bring to the reference incident.
To help situate what is meant by an image description and how facts can be inferred from implicit knowledge, consider the historic photograph shown in Figure 7 and the description that accompanies it.
Figure 7. Henry Fox Talbot. Part of Queen's College, Oxford. [The Pencil of Nature, Part 1, pl. 1] n.d. Taken from the reproductions in Larry J. Schaaf, H. Fox Talbot's The Pencil of Nature; Anniversary Facsimile (New York: Hans P. Kraus, Jr. Inc., 1989). Used with permission.
It is implicitly understood that when Talbot, the photographer, writes about the surface of the building and the marks left on stones, he is in fact talking about the outside of the building. Even though Talbot does not explicitly say he is talking about the outside surface, persons reading the description understand this to be the case. This is an example pragmatic inference.
The lesson here is that content analysis is effective for coding and capturing textual information, but other tools and methods must be developed for generating and capturing the more oblique, implicit background knowledge. During the course of the dissertation research, a system was developed for addressing this issue building on preexisting ideas in Artificial Intelligence and linguistics. This included Minsky's frames, which he describes as "data structures representing a stereotyped situation" (1975, p. 212); Fahlman's (1979) default reasoning with exceptions, and in linguistics, Fillmore's (1976) frame semantics.
7.3 The case with case relationships
One of the more complex relationship types captured in this study, case relationships, brought to light two problems during the preliminary study. First, the a priori relationship types and subtypes chosen for capturing meaning did not always reflect what humans express in the real world. The ontology resources cited earlier in Section 4 treated case relationship types as a closed set, but the analysis carried out by this researcher uncovered a significantly larger set of case relations than reported on by previous researchers. Second, the literature did not provide a system for representing case relationships as relational terms with arguments similar to all of the other relationships recorded in the corpus. This was a representation problem that had to be solved before moving on to the dissertation study.
Case relations, while useful for describing everyday experiences, are not part of the standard relations used in LIS for structuring controlled vocabularies. Case relations are usually marked in natural language by the occurrence of verb phrases. Returning once again to Talbot's photograph description in Figure 7, Talbot states, "The view is taken from the other side of the High Street —looking North." The verb ‘taken' is the past participle of ‘take,' which signals one activity, and the verb ‘looking' is the present participle of ‘look' and signals a second event. During the dissertation study, the researcher developed a system for representing case relationships in prefix notation (a notation introduced earlier in Section 6 and in Figure 6). The two events described in Talbot's description can be interpreted as expressing the following factual assertions:
- has_location(take,"other side of High Street")
- has_agent(take,photographer)
- has_PointInTime(take,"4 September 1843")
- has_instrument(look,camera)
- has_direction(look,North)
- has_reference_object(look,"Church of St. Peter's")
The first two can be read as "The take action has a location on the other side of High Street," and "The take action has an agent who is a photographer." Story (1993) provides a useful synthesis of several researchers' interpretations of case relations. However, the set of five case relations she adopts do not capture the essence of events like these occurring in image descriptions.
The solution offered here also serves as a framework for addressing the earlier problem introduced in Section 7.3 —that is, how to capture background knowledge not stated explicitly in a photograph description. The case relations described above could be used as a heuristic to fill in background. For example, a question phrased by an image researcher that states, "The photograph was taken on 24 September 1951," could be expanded in a machine environment by seeking out grammatical constructions that express things such as take events have photographers, spatial locations, reference objects, and points of view, and so on.
To summarize, the preliminary investigation provided empirical evidence suggesting that case relationships form an open set. This led to revisions in the content analysis form for capturing situation frames and what would likely be an open set of case relationships. Furthermore, the preliminary investigation forced the researcher to work out a representation problem for case relations, which in turn led to a system for generating and capturing implicit background knowledge.
7.4 Predicting relationships
Finally, as the main research project unfolded, there were expectations that new insights would provide new ways of looking at certain data. For example, it remained to be seen whether Cooper's (1968) set of necessary and sufficient conditions could exhaustively predict spatial expressions in image descriptions. Her approach to the spatial relationship problem did not account for the use of prepositions in describing other semantic fields. For instance, these three examples taken from the data sample use spatial prepositions in non-spatial expressions:
- The old symphony, founded in 1895. [Here the preposition in indicates a point in time, not contained by.]
- Photo by [Clyde] Hare. [Here the preposition by indicates the creator of a work, not near or next to.]
- Horse car in operation. [Here the preposition in denotes the state of the horse car, not that the horse car is contained by the operation.]
Solutions did not surface until the larger sample was analyzed. Eventually, the researcher turned to linguistics and Gruber's (1965) Thematic Relations Hypothesis as explained by Ray Jackendoff (1983). Gruber discovered that similar grammatical patterns extend across unrelated semantic fields. For example, the semantics of the locative expression in suggest, according to Jackendoff, a one-dimensional pseudospace, or timeline, in the temporal expression "founded in 1895." In other words, the mind adapts to non-spatial fields the machinery it already has in place for spatial cognition (Jackendoff, 1983, p. 188-189).
To summarize, this section showed that researchers may be able to make predictions using existing ontological rules and axioms when analyzing small samples, but when moving to larger data sets, the variety and number of entities that demand explanation can grow requiring deeper analysis. In the case of having rules for prepositions defining spatial expressions, but not temporal, the researcher simply categorized the later instances as "cannot explain" during the preliminary investigation. By not analyzing the "cannot explain" problems during the preliminary investigation, the set of "cannot explain" relationships grew out of hand during the dissertation research and eventually required backtracking, revising the content analysis form, and starting over with the dissertation data analysis.
8 Conclusion
This paper reported on the results of a preliminary study investigating the relationship problem in image descriptions. The goals of the study were threefold: 1) develop and refine a codebook and forms for capturing relationships occurring in natural language descriptions, 2) refine the use of ontological tools and methods for predicting relationship instances and organizing them into families of relationship types, and 3) test intra-coding reliability and instrument validity.
The research shows that recognizing semantic relationships in image description analysis is neither straight nor simple, so there is a continuous threat that detailed coding instructions cannot guarantee relationships are accurately represented. Content analysis demands a lot of small, systematic steps, weaving together observations from explicit facts and inferential knowledge. Identifying an instance of a particular relationship type in text is a non-trivial task demanding an either/or-type of inference about class membership.
Whereas surveys and structured interviews offer participants predefined choices that are easy to tabulate, this paper has shown that when using real life reference transactions as the data set, it is difficult to control or suppress what might likely be highly unstructured, unwieldy variations in form. This is a reflection of the fact that ordinary people —curators and archives users— search for and present questions and behave in different ways.
The claim was made that preliminary studies sometimes answer questions and other times raise new questions. In line with this, the paper sheds light on four specific problems that surfaced: 1) The scope of future content analysis should be expanded to include relevant hand inscriptions found in the margins of textual documents; 2) A significant amount of knowledge surrounding image descriptions is implicit and requires the analyst to use pragmatic inference for capturing background knowledge; 3) Analysis must go deeper than the surface structure of grammar and syntax and explore relationships that go beyond the a priori set of ontological relationships originally chosen for validating relationship types; and finally, 4) The task of predicting relationships is made difficult by the multiple meanings associated with prepositions. This requires using analytics that are not restricted to meeting necessary and sufficient conditions in the context of one semantic field.
In spite of these challenges, the evidence suggests that preliminary investigations going beyond simple test/retest are required for research in the field of relationship analysis. This is especially true when adapting and fine-tuning content analysis techniques and ontological tools and methods. Furthermore, there appears to be a strong case for applying content analysis and ontological tools and methods as the framework for analyzing and structuring data collection. The result is a semantically rich set of relations and concepts recorded in a Corpus of Relationship instances.
Allen C. Benson is Library Director and Professor at the U.S. Naval War College. The views expressed here are his own and do not reflect those of the Navy or the U.S. government.
Bibliography
Bauer, M.; Aarts, B. (2000). "Corpus construction: a principle for qualitative data collection". In: M. Bauer; G. Gaskell (Eds.), Qualitative researching with text, image and sound (19-37). London: Sage.
Bean, C. A. (1996). "Analysis of non-hierarchical associative relationships among medical subject headings (MeSH): Anatomical and related terminology". Advances in Knowledge Organization. 5, p. 80-86.
Bean, C. A.; Green, R. (Ed.). (2001). Relationships in the Organization of Knowledge. Dordrecht, The Netherlands: Kluwer Academic Publishers.
Biber, D. (1993). "Representativeness in corpus design". Literary and Linguistic Computing. 8(4), 243-257.
Carnegie Library of Pittsburgh, "Pittsburgh Photographic Library (PPL) Preliminary Inventory". (2000). [Unpublished manuscript].
Chaffin, R.; Herrmann, D. J. (1984). "The similarity and diversity of semantic relations". Memory & Cognition. 12(2), p. 134-141.
Chaffin, R.; Herrmann, D. J. (1987). "Relation element theory: A new account of the representation and processing of semantic relations". In: D. S. Gorfein; R. R. Hoffman (Eds.), Memory and learning (221-245). Hillsdale, NJ: Lawrence Erlbaum Associates.
Cooper, G. S. (1968). A semantic analysis of English locative prepositions (Bolt, Beranek, & Newman, Report No. 1587). Springfield, VA: Clearing House for Federal, Scientific, and Technical Information. <http://handle.dtic.mil/100.2/AD666444>. [Accessed: 14/03/2010].
Enser, P. G. B.; McGregor, C. G. (1993). Analysis of visual information retrieval queries. British Library R&D Report 6104. The British Library Board.
Fahlman, S. E. (1979). NETL: A System for Representing and Using Real-World Knowledge. Cambridge, Massachusetts: MIT Press.
Farradane, J. (1980a). "Relational indexing, Part I". Journal of Information Science. 1, p. 267-276.
Farradane, J. (1980b). "Relational indexing, Part II". Journal of Information Science. 1, p. 313-324.
Fillmore, C. J. (1976). "Frame semantics and the nature of language". Annals of the New York Academy of Sciences: Conference on the Origin and Development of Language and Speech, 280, 20-32.
Graesser, A. C.; Goodman, S. M. (1985). "Implicit knowledge, question answering, and the representation of expository text". In: B. K. Britton; J. B. Black (Eds.), Understanding expository text: a theoretical and practical handbook for analyzing explanatory text. Hillsdale, NJ: Lawrence Erlbaum Associates.
Gruber, J. S. (1965). "Studies in lexical relations". Doctoral Dissertation, MIT, Cambridge; Indiana University Linguistics Club, Bloomington, Ind. Reprinted as part of Lexical structures in syntax and semantics, North-Holland, Amsterdam, 1976.
Jackendoff, R. (1983). Semantics and cognition. Cambridge, Mass.: MIT Press.
Keister, L. H. (1994) "User types and queries: Impact on image access systems". In: R. Fidel et al. (Eds.), Challenges in indexing electronic text and images, (7-22). Medford, NJ: Learned Information.
Krippendorff, K. (2004). Content analysis: an introduction to its methodology. Thousand Oaks, CA: Sage Publications.
Minsky, M. (1974). "A framework for representing knowledge." Artificial Intelligence Memo No. 306. Cambridge, MA: Massachusetts Institute of Technology A.I. Laboratory.
Oxford English Dictionary Online. March 2011. Oxford University Press. <http://www.oed.com/view/Entry/41873?redirectedFrom=corpus>. [Accessed: 28/04/2011].
Perakath C. B. [et al.] (1994). IDEF5 Method Report. Knowledge Based Systems, Inc.
Pittsburgh Photographic Library (PPL) Preliminary Inventory, Revision 19. (March 23, 2000). <http://216.183.184.20/exhibit/ppl_plan.html>. [Accessed: 12/04/2009].
Proposal for the Establishment of the Civic Photographic Center under the Sponsorship of the Allegheny Conference on Community Development. (December 1949, revised February 20, 1950). Archives Service Center, University of Pittsburgh, Box 56, Folder File 1, A. W. Mellon Education and Charitable Trust, Pgh., PA Records 1930-1980.
Rothkegel, R.; Wender, K. F.; Schumacher, S. (1998). "Judging spatial relations from memory". In: C. Freska, C. Habel; K.F. Wender (Eds.), Spatial cognition: An interdisciplinary approach to representation and processing of spatial knowledge (p. 79-105). Berlin: Springer-Verlag.
Schmied, J. (1990). "Corpus linguistics and non-native varieties of English". World Englishes. 9(3), p. 255-268.
Shatford, S. (1986). "Analyzing the subject of a picture: A theoretical approach". Cataloging & Classification Quarterly. 6(3), p. 39-62.
Shatford, S. (1994). "Some issues in the indexing of images". Journal of the American Society for Information Science. 45(8), p. 583-586.
Shrout, P. E.; Fleiss, J. L. (1979). "Intraclass correlations: uses in assessing rater reliability". Psychological Bulletin. 86(2), p. 420-428.
Stemler, S. (2001). "An overview of content analysis". Practical Assessment, Research & Evaluation, 7(17). <http://PAREonline.net/getvn.asp?v=7&n=1>. [Accessed: 15/01/2010].
Story, V. C. (1993). "Understanding semantic relationships". VLDB Journal. 2, p. 455-488.
Svenonius, E. (2000). The intellectual foundation of information organization. Cambridge, Mass.: MIT Press.
Talbot, William Henry Fox. (1968). The pencil of nature. New York, NY: Da Capo Press. (First edition of The Pencil of Nature was published in London between 1844 and 1846 in six separate fascicles.)
Wand, Y.; Storey, V.; Weber, R. (1999). "An ontological analysis of the relationship construct in conceptual modeling". ACM Transactions on Database Systems. 24 (4), p. 494-528.
Weber, R. P. (1990). Basic content analysis. Newbury Park, CA: Sage Publications.
Winston, M.; Chaffin, R.; Herrmann, D. (1987). A taxonomy of part-whole relations. Cognitive Science. 11, p. 417-444.
Wood, J. M. (2007). "Understanding and computing Cohen's Kappa: a tutorial". WebPsychEmpiricist. <http://wpe.info/papers_table.html>. [Accessed: 14/05/2010].



![Henry Fox Talbot. Part of Queen's College, Oxford. [The Pencil of Nature, Part 1, pl. 1] n.d. Taken from the reproductions in Larry J. Schaaf, H. Fox Talbot's The Pencil of Nature; Anniversary Facsimile (New York: Hans P. Kraus, Jr. Inc., 1989). Used with permission](benson7.jpg)