
Alicia García-García, Alberto Pardo-Ibáñez
Universidad Católica de Valencia
alicia.garcia@ucv.es, alberto.pardo@ucv.es
Antonia Ferrer Sapena, Fernanda Peset
Universitat Politècnica de València
anfersa@upv.es, mpesetm@upv.es
Luis M. González-Moreno
Universitat de València
Resum
Els mapes de coneixement són instruments que ajuden a visualitzar informació. Si prenen com a base de l'anàlisi dades de naturalesa bibliogràfica es converteixen en una forma senzilla de proporcionar l'estat de la qüestió d'una àrea o un tema molt concret. Aquest treball se centra en la utilització d'informació científica bibliogràfica per produir un mapa, i presenta les eines per construir-los. Bibexcel s'usa per analitzar les dades extretes de la base de dades Web of Science i Pajek, per representar visualment els resultats. El treball descriu els passos necessaris per utilitzar aquestes aplicacions, especialment quan no mostren un dibuix adequadat a causa d'un nombre excessiu de dades.
Resumen
Los mapas de conocimiento son instrumentos que ayudan a visualizar información. Si toman como base del análisis datos de naturaleza bibliográfica se convierten en una forma sencilla de proporcionar el estado de la cuestión de un área o tema muy concreto. Este trabajo se centra en la utilización de información científica bibliográfica para producir un mapa, presentando las herramientas para construirlos. Bibexcel es utilizado para analizar los datos extraídos de la base de datos Web of Science y Pajek para representar de forma visual los resultados. El trabajo describe los pasos necesarios para utilizar estas aplicaciones, especialmente cuando no son adecuadamente dibujados por contar con un número excesivo de datos.
Abstract
Knowledge maps are tools that help visualize information. If they take bibliographical data as the basis for network analysis they become a simple means of getting to the crux of highly specific areas or subjects. This paper focuses on the use of scientific bibliographic information to produce a knowledge map and describes the tools that can do this. Bibexcel is used to analyze the data extracted from Web of Science and Pajek is used to visually represent the results. The paper describes the various steps in the procedure, focusing on what to do when visualization is hampered by too many data.
1 Concepte
Els mapes de coneixement són representacions gràfiques que mostren visualment l'estat d'una qüestió determinada. "The visual representations take advantage of the human eye's broad bandwidth to allow users to understand abstract information in an intuitive way. In this sense, among the most common visual representations are maps" (Pino-Díaz et al., 2012). Proporcionen una visualització de les dades amb les relacions jeràrquiques i equivalents entre els conceptes, i representen les idees principals sobre un sector o un tema en concret d'una manera ràpida i molt intuïtiva. Per construir aquests mapes calen dades, que poden residir en persones o en fonts externes.
La representació de dades en mapes de coneixement procedeix de les disciplines que estudien la gestió del coneixement, és a dir, les lligades a la gestió d'empresa i a la gestió de la informació, com ara la documentació. En el cas de les empreses "One of the most challenging problems in decision analysis is capturing information that resides in decision-makers and experts. […] The knowledge we have about any uncertain event is composed of many fragmented pieces of information that are relevant to the event in question. The fragments of information may exist in one person or among several people" (Howard, 1989). Els mapes de coneixement en aquest àmbit, per tant, resulten de gran ajuda per identificar i representar els recursos de coneixement de què disposa una organització (Alós, 2003). Entenem aquests recursos com un conjunt dispers de capacitats, competències, documents, procediments, tecnologies, etc. que necessitem conèixer per poder-los gestionar eficaçment de manera que donin suport a la idea de negoci de l'organització (González, 2013).
En el camp de la documentació, la gestió del coneixement es vincula a l'anàlisi de la informació i també als instruments que s'empren per dur-la a terme, com els tesaurus i les ontologies. "Si los tesauros se proponen controlar el vocabulario y limitar el sentido de los términos para facilitar la recuperación [de la información] por la semejanza entre petición y representación o para sugerir términos de búsqueda [,] los mapas conceptuales presentan la estructura conceptual de una disciplina mediante una representación gráfica de la significación de los conceptos" (Hernández Quintana, 2006).
Atès que la gestió del coneixement és una disciplina de caràcter social, el resultat el determina la formació i cultura del subjecte que descriu o recupera la informació. Aquesta singularitat, ja demostrada en camps com l'etnografia, es pot superar des de postures filosòfiques que incloguin un cert relativisme cultural (Sánchez Durá, 2013) o amb l'ajuda de tècniques objectives de processament de dades, com és el text mining.Per totes aquestes raons, en l'entorn de la gestió de la informació l'explotació de dades s'ha convertit en un dels grans protagonistes de l'anàlisi estratègica, per exemple, dels sectors cientificotècnics. Mitjançant tècniques de mineria de textos sobre dades bibliogràfiques es mostra l'estat d'una àrea de coneixement, un grup d'organismes o llocs (Herrero i Moya, 2009; Peset et al., 2013; Valenciano et al., 2010; Leydesdorff, 2013; Aleixandre et al., 2013; Robinson et al., 2013; Ardanuy, 2014); es generen indicadors cientificotècnics (Ruas i Pereira, 2014), o s'experimenten amb tècniques per conèixer les necessitats dels usuaris (Torres Salinas et al., 2014).
El nostre treball s'insereix en aquest context, la representació del coneixement d'un sector, amb la intenció de proporcionar una guia clara per analitzar dades procedents d'una font bibliogràfica i representar les seves relacions en una xarxa de termes. L'anàlisi de dades mitjançant tècniques de text mining i la seva visualització recentment s'ha convertit en una disciplina consolidada (Tsai, 2012; Nualart-Vilaplana et al., 2014). La denominació del tema que presentem varia des del nom escollit per nosaltres, mapes de coneixement, fins a xarxes de col·laboració, mapes de la ciència, grafs, etc.
2 Funció
A l'inici de tot procés d'investigació —especialment si es tracta d'una àrea aliena a la nostra experiència— es duu a terme una tasca de documentació centrada en la recerca de la bibliografia adequada, de la qual s'extreu l'estat d'una qüestió, el que tradicionalment (Tarrats Pons, 2012) es produïa mitjançant "sucesivas inmersiones del investigador en las fuentes documentales […]. El proceso de búsqueda consumía mucho tiempo, y era difícil de replicar dados los juicios subjetivos implicados" (Börner; Chen; Boyack, 2003).
Les bases de dades sobre articles de revista en què se cerca aquesta informació de qualitat, estructurada i fiable s'erigeixen, a més, en fonts de dades per a un altre tipus d'anàlisi. Segons Pino et al. (2012), "Swanson (1986, 1987) showed the potential of bibliographic databases for knowledge discovery, in particular by using a text-mining tool of concept linkage. […] Co-word analysis (Callon, Law, & Rip, 1986; Michelet, 1988; Courtial & Michelet, 1990) is a method used in knowledge discovery in bibliographic databases". Atès el muntant d'informació científica que es produeix, les tècniques tradicionals d'extracció de coneixement, com la lectura, deixen pas a altres formes d'anàlisi (Filippov, 2014). L'evolució tecnològica hi ha ajudat amb noves formes d'enfocament i capacitats per a la ciència, com la col·laboració entre grups de recerca o altres tècniques d'anàlisi d'informació (López-Borrull; Canals, 2013).
Per exemple, el text mining pot fer càlculs matemàtics i estadístics sobre alguns camps dels articles per revelar els seus patrons o l'estructura interna, així com l'evolució d'una determinada disciplina. Aquesta metodologia augmenta l'objectivitat de les conclusions que es deriven de la interpretació d'aquests mapes. El recompte de l'aparició dels termes, ja siguin autors o paraules clau, s'usa massivament en els núvols d'etiquetes gràcies a senzilles utilitats en el web. Wordle o Tagxedo presenten una figura en la qual amb diferents mides de lletra destaquen les etiquetes més repetides en la col·lecció. Encara que per a un recompte més precís que indiqui, per exemple, la quantitat de repeticions, s'han d'utilitzar funcionalitats més específiques. Algunes s'ofereixen des de les mateixes bases de dades Web of Science —WoS— (Web of Science®, Thomson Reuters, New York, USA) i Scopus (Elsevier Properties, Netherlands), tot i que també existeixen eines generades per a elles, com ara HistCite (HistCite Programari LLC, New York, USA) o Bibexcel (Olle Persson, Umeå University, Umeå, SWE).
Enfront dels recomptes, més o menys senzills, una anàlisi complexa de la manera en què es relacionen els termes, les coocurrències, la coautoria o el coword, llança conclusions més interessants. L'estudi de xarxes i la seva visualització en forma de mapa o xarxa de relacions socials es basa en la teoria de grafs, una branca de les matemàtiques. De fet, "desde el momento en el que un texto es fragmentado en palabras y se establece algún tipo de relación entre dichas palabras, disponemos de una representación en forma de grafo" (Cruz Mata et al., 2006). La representació d'una xarxa social també mitjançant un graf amb nodes (individus) connectats per mitjà de línies (relacions) aborda altres recomptes, que manifesten conceptes com el de centralitat, determinada pel grau de connexions d'un node amb d'altres (Del-Fresno-García, 2014).
3 Eines per generar mapes de coneixement
Hi ha diverses eines per construir xarxes i representar les relacions entre termes, com ara Text2mindmap (www.text2mindmap.com/) o Mindmeister (www.mindmeister.com/es), que són d'ús lliure i permeten crear mapes més o menys senzills introduint manualment la informació.
Però construir mapes de coneixement que provinguin de fonts externes i a més tinguin en compte certs indicadors —recompte de freqüència d'aparició junt amb les relacions entre els termes— requereix utilitzar eines específiques. En el camp de la bibliometria s'han generat nombroses aplicacions (Cobo et al., 2011). En aquest text explicarem el funcionament bàsic de dos programes gratuïts: Bibexcel en combinació amb Pajek (versió 3.14, 12 de novembre de 2013, Batagelj and Mrvar, University of Ljubljana, Ljubljana, Slovenia).
Per il·lustrar aquest treball farem una consulta a la Col·lecció principal (p. ex. Core Collection; http://accesowok.fecyt.es) de WoS amb el terme Knowledge maps al camp "Tema", restringida a l'àrea de Ciències de la Informació i Ciències Bibliotecàries.1 Els registres obtinguts es guarden amb el nom "savedrecs.txt" en un arxiu que constituirà la font de dades necessària per construir el mapa de coneixement. L'opció es troba a "Guardar en otros formatos de archivo" i ho hem de fer amb les especificacions següents:
- En contingut del registre: registre complet i referències citades per a usos posteriors
- En format de l'arxiu: text sense format
Si el resultat de la recerca és de cinc-cents registres o més, s'han de descarregar de cinc-cents en cinc-cents i després unir-los en un sol arxiu, ja sigui amb un programa per editar text pla (WordPad) o des de Bibexcel (menú "File > Append one file to another").
Bibexcel és un programa versàtil que extreu camps, analitza les freqüències de termes i construeix les relacions dels termes per generar les matrius i els vectors que representen aquest tipus d'anàlisi. Per crear un mapa de coneixement a partir del fitxer obtingut de WoS cal seguir els passos següents: preparar les dades exportades des de WoS, extreure el camp que s'ha d'analitzar, calcular les seves freqüències, analitzar-ne les coocurrències i preparar la matriu. Després, els resultats obtinguts es dibuixen amb el programa Pajek, que permet representar xarxes socials (Bonacich, 2008).
Les instruccions, absolutament exactes, per aconseguir un mapa de coneixement es detallen en els paràgrafs següents. Si en les múltiples finestres de diàleg que emergeixen a Bibexcel s'introdueixen opcions diferents de les indicades no s'obtindran els mateixos resultats.
Un cop instal·lat el programa (www8.umu.se/inforsk/Bibexcel/) cal carregar l'arxiu amb les dades exportades des de WoS i preparar-les per a Bibexcel. Segons indiquen Peset i González (2012), després d'executar Bibexcel, a la finestra "Select file here" cal navegar fins a la carpeta corresponent i seleccionar l'arxiu "savedrecs.txt" prement-hi dues vegades el botó esquerre del ratolí (vegeu la figura 1).
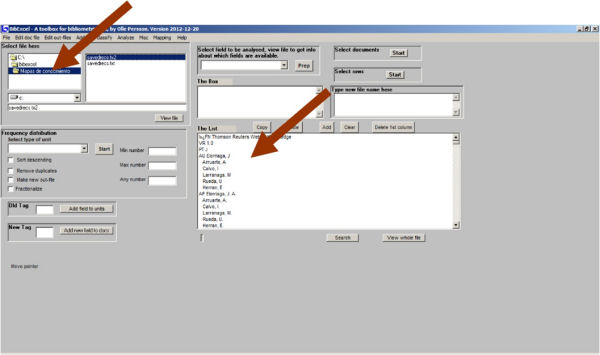
Figura 1. Interfície de Bibexcel i exemple de registre tipus. Les fletxes assenyalen els llocs on se selecciona el fitxer i el lloc on apareixen els registres
L'arxiu original de l'exportació es mostra correctament a "The list" després de fer les dues accions següents: introduir els salts de paràgraf i inserir la barra finalitzadora de camp. Així, en el menú superior s'ha de seleccionar "Edit doc-file > Replace line feed with carriage return" i en les finestres de diàleg que apareixen s'ha de respondre "Yes > Yes" per conservar el TXT original i produir un TX2.
Per reconèixer el format WoS, se selecciona el fitxer TX2, al menú superior s'ecull "Misc. > Convert to dialog-format > Convert from WoS" i en la finestra de diàleg es respon "Accept".
D'aquesta acció resulta un nou fitxer, que serà el definitiu, anomenat "*.doc" l'aparença del qual és similar al fitxer original però amb el retorn en cada camp i un finalitzador de línia i de fitxer. Es recomana guardar-ne una còpia en un lloc segur, ja que cada vegada que Bibexcel executa una acció es generen noves extensions de fitxer, que poden substituir l'original. En aquest punt cal assenyalar que el DOC no és exactament un document de Word. Es tracta d'un document en text pla al qual el programa assigna la mateixa extensió que utilitza el Word. Es pot modificar, amb fins de normalització, per exemple, però sempre s'ha de desar com a text pla.
Seguidament, per analitzar un camp se n'ha d'extreure el contingut. Una de les dades més adequades per generar un mapa de coneixement és la que conté les paraules clau, ja que en estar normalitzades indicarà els temes de manera més precisa que els camps de llenguatge lliure, com ara títol o resum, que requereixen un preprocessament més complex. Per extreure'n la informació s'ha d'escriure a la finestra "Old tag" l'etiqueta que ve assignada per WoS, en aquest cas DE, i a la finestra "Select field to be analysed" escollir l'opció del desplegable anomenada "Any; separated field". Finalment, es prem el botó "Prep" i en les finestres de diàleg es triarà la seqüència: "Accept > No".
Aquesta acció genera un fitxer OUT2 que indica en dues columnes el número de registre on apareix cadascuna de les paraules. Aquestes mateixes operacions cal fer-les per extreure qualsevol altre camp. Per exemple, pot ser d'interès el camp títol, que també inclou contingut semàntic sobre els articles encara que està redactat en llenguatge natural. Per extreure el camp de títol, caldria executar una seqüència similar d'accions escrivint en aquest cas l'etiqueta TI en el camp "Old tag" i seleccionant l'opció "Blank-separated words (e. g. title)".
A continuació es calcula el nombre de vegades que apareix un terme en el conjunt de documents seleccionats. Des de la pantalla principal, amb el fitxer OUT seleccionat, s'introdueixen aquests paràmetres: finestra "Frequency Distribution > Whole string > Start (amb sort descending) > Accept.
Aquesta acció genera un fitxer CIT que mostra a la finestra "The list" dues columnes amb els resultats: la primera correspon a la freqüència d'aparició i la segona a la paraula quantificada. Per utilitzar les dades cal copiar i enganxar la informació en un full de càlcul o en el processador de textos per maquetar la taula (d'aquí el nom de Bibexcel, per la gran compatibilitat de formats entre el programa bibliomètric i el full de càlcul Excel).
Com hem mostrat en l'apartat anterior, fins aquí podríem haver-ho fet amb altres eines, cosa que resulta impossible per calcular les coocurrències o relacions entre els temes. La coocurrència indica el nombre de vegades que dues cadenes de caràcters coincideixen en més d'un document. Per tant, ens permet una anàlisi sofisticada que estableix les relacions entre termes i les recompta. Per calcular coocurrències amb Bibexcel cal seleccionar l'arxiu OUT, triar al menú superior "Analyze > Co-occurrence > Make pairs via ListBox" i en els quadres de diàleg prémer "No > Accept.Aquesta acció genera un fitxer COC que indica en tres columnes el nombre de vegades que les dues paraules clau apareixen juntes en diferents documents.
Aquest fitxer COC que conté les coocurrències necessita un últim pas perquè el pugui llegir el programa Pajek. Un cop seleccionat el fitxer cal buscar el menú "Mapping > Create net file for Pakej, etc.", que genera un fitxer NET.
Aquest fitxer NET conté la matriu numèrica de dades que reflecteix les relacions establertes perquè puguin dibuixar-se posteriorment. Bibexcel guarda els vèrtexs i la seva relació (edges) en forma de fitxer de text, disposant primer la informació dels vèrtexs i després les relacions entre vèrtexs i la seva intensitat. A la taula 1 es pot veure un exemple de fitxer a punt per ser representat. Com s'observa, immediatament sota edges es mostra la relació entre dos vèrtexs (1 "Data mining", 2 "New product development", primera i segona columna d'edges, respectivament) i nombre de vegades que apareix aquesta coocurrència (2 vegades, tercera columna), format que Pajek accepta.
| * Vèrtexs 820 1 "Data mining" 2 "New product development" 3 "Neural networks" 4 "causal knowledge" 5 "fuzzy cognitive map" 6 "Apriori algorithm" 7 "Clustering analysis" 8 "navigation" 9 "usability" … 820 "Conceptual frame" * Edges 1 2 2 1 3 2 4 5 2 6 7 2 6 1 2 8 9 2 10 11 2 … |
Taula 1. Exemple de xarxa de coocurrències preparada per llegir-se en Pajek
Per visualitzar el mapa cal descarregar el programari des de http://pajek.imfm.si/doku.php?id=download, i obrir la matriu des de l'opció "Networks" utilitzant el botó de la icona de carpeta i buscant el fitxer NET. A la figura 2 es visualitza l'aspecte de la pantalla d'entrada d'aquest programari.
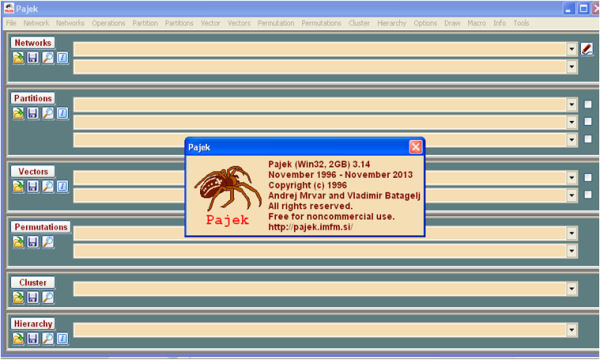
Figura 2. Interfície principal de Pajek
Des del menú superior, l'opció "Draw > Network" dibuixarà el graf de relació entre els termes en una xarxa circular. En realitat, atesa la profusió de termes és una figura difícil d'interpretar, de manera que la separarem utilitzant el menú "Layout > Energy > Kamada-Kawai > Separated components" (vegeu la figura 3).
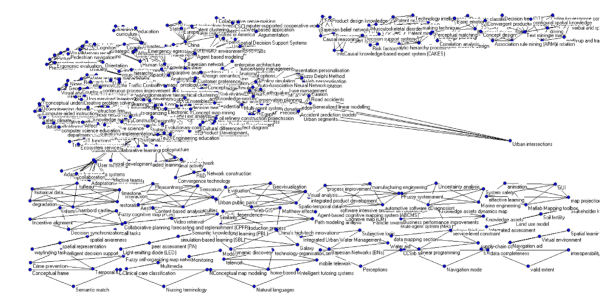
Figura 3. Xarxa separada amb tots els termes dels registres recuperats
Aquesta visualització permet arrossegar un dels termes per ressaltar-lo, però segueix resultant confusa a causa de la quantitat de nodes representats. Per millorar-ne la interpretació, cal reduir el nombre de relacions, tal com s'explica en l'apartat següent.
4 Millora de resultats i obtenció dels paràmetres de centralitat
Un cop vistos els requeriments mínims per dibuixar el mapa amb dades acadèmiques, és possible millorar-ne la visualització de manera senzilla amb les opcions que s'expliquen a continuació.
4.1 Reducció del nombre de relacions per interpretar millor el gràfic
Podem restringir el nombre de coocurrències que es visualitzen. L'avantatge de fer-ho amb Pajek és que es pot visualitzar la reducció mentre es fa; no obstant això, ho explicarem en Bibexcel perquè el procés és més senzill i ràpid.
A Bibexcel, amb el fitxer COC seleccionat s'afegeix el llindar mínim desitjat (2 en el nostre cas) a "Min number", que apareix a "Frequency distribution" de la pantalla principal. Després, escollint des del menú superior "Edit out-file > Delete low frequencies" es genera un MIN. Amb aquest fitxer es crea de nou la xarxa NET des del menú "Mapping > Create net-file for Pajek, etc." indicant en les finestres de diàleg: "Accept> No > No".
Aquest últim fitxer generat es carrega de nou a Pajek de la manera vista en l'apartat anterior. En aquesta ocasió el resultat és un mapa (vegeu la figura 4) més fàcilment interpretable en incloure un nombre menor de nodes i haver-lo separat utilitzant el menú "Layout > Energy > Kamada-Kawai > Separated components".
4.2 Nodes proporcionals a la freqüència
Fins ara el mapa només reflectia les relacions entre termes. Per visualitzar el recompte d'aparició d'un terme s'ha de crear un vector amb les freqüències. Per fer-ho, se selecciona a Bibexcel el fitxer CIT que contenia les freqüències calculades de paraules, es mapeja escollint al menú superior "Mapping > Create Vec-file" i es genera un fitxer VEC.
El fitxer NET s'obre amb Pajek des de l'opció "Networks" utilitzant la icona de carpeta i el fitxer VEC de la mateixa manera des de l'opció "Vectors".Finalment, des del menú superior s'utilitza "Draw > Network +First vector" per dibuixar la xarxa circular, que podem separar utilitzant el menú "Layout > Energy > Kamada-Kawai > Separated components".
D'aquesta manera es visualitzen des de Pajek els arxius NET i VEC alhora en una xarxa amb els nodes ponderats per la seva freqüència (vegeu la figura 4). La mida del node expressa la freqüència d'aparició, no el nombre de relacions. Si escollim al menú de la imatge del graf "Options > Lines > Mark Lines > with Values (Ctrl+V)", es mostrarà el nombre de relacions sobre les línies.
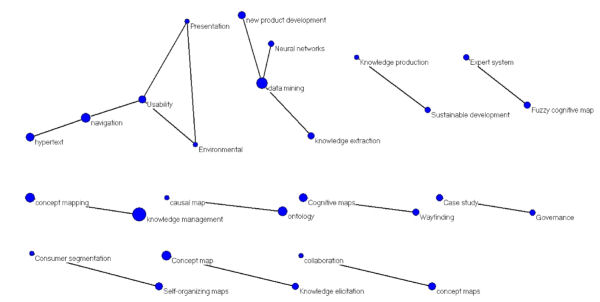
Figura 4. Mapa de coocurrència amb un llindar mínim de 2 i mida dels nodes proporcional a la seva freqüència d'aparició
4.3 Ús d'un altre programa de visualització de xarxe
Vosviewer (versió 1.5.5, Nees Jan van Eck i Ludo Waltman, de la Rijksuniversiteit Leiden) presenta mapes de freqüències i de coocurrències amb una altra aparença ja que, a més d'utilitzar visualitzacions més sofisticades, introdueix una anàlisi de probabilitats amb l'algoritme matemàtic anomenat Kernel (pestanya "Density View"). L'aplicació d'aquest algorisme, juntament amb el procés iteratiu que aplica, proporciona no només el recompte sinó que, a diferència de Pajek, també aporta el significat de la proximitat dels termes. Per exemple, si un terme està representat al costat d'un altre, reflecteix que tots dos estan associats sota algun criteri de relació, de manera que la distància en aquest tipus de mapes és significativa. També representa altres aspectes com l'agrupació per clústers i la mida dels nodes segons la freqüència d'aparició dels termes.
El programa es descarrega gratuïtament des de www.vosviewer.com/download i permet carregar xarxes generades per Bibexcel o bé crear-les des del mateix programa, encara que aquesta última opció treballa únicament amb els camps de títol i resum.
Aquesta tècnica de mineria de text, per tant, és més avançada que el pur recompte i permet interpretacions més sofisticades del mapa, com mostra la pestanya "Density View", que genera una visualització amb les tres variables següents. A la figura 5 s'aprecien les agrupacions per colors segons la intensitat de la freqüència Així mateix, representa la variació de la mida de la font i de l'ombrejat, i com a última variable presenta la diferent proximitat entre els termes. També pot carregar-se la mateixa presentació per clústers calculats a través d'un mètode k-means, pestanya "Cluster Density View".
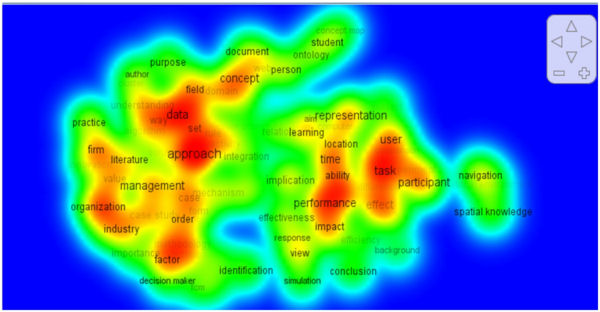
Figura 5. Mapa de densitat generat per Vosviewer
Les instruccions per aconseguir les dues representacions són molt senzilles i intuïtives. Un cop executada l'aplicació escollirem al menú de la part esquerra l'opció "Create > Create a map based on a network".Després de prémer en "Next" triarem la pestanya "Pajek" i immediatament buscarem el fitxer NET que hem creat amb anterioritat amb Bibexcel. A les preguntes següents respondrem "Yes > Next > Finish".
A partir d'haver generat el mapa, automàticament el programari ens permet visualitzar els resultats de cinc formes diferents ("label", "density", "cluster", "cluster density" i "scatter").En definitiva, Vosviewer ha fet automàticament els càlculs necessaris per generar aquestes representacions. Per descomptat, l'usuari pot guardar tant els mapes com les dades calculades de manera senzilla en el submenú "Save".
4.4 Càlcul de paràmetres de centralitat
Finalment, volem posar l'accent en una qüestió que se sol oblidar: l'obtenció de paràmetres de centralitat. Si bé aquest article explica com obtenir mapes de coneixement, cal reflexionar sobre la utilitat d'aquest tipus d'anàlisi de dades.
A priori, la visualització de mapes de coneixement ofereix a l'investigador l'oportunitat de fer anàlisis exploratòries de tipus qualitatiu, ja que la interpretació del que es visualitza es realitza a través de processos intuïtius. Podríem dir que l'observació d'un mapa de coneixement aportarà una informació similar a la contemplació d'un quadre, en què les conclusions seran més o menys encertades en funció de l'experiència i la perícia de l'observador.
Per generar un coneixement més objectiu i desvinculat del grau de coneixement de l'investigador, haurem de fer càlculs que quantifiquin de manera objectiva el que estem visualitzant. Aquest tipus d'anàlisi està basada en la teoria de grafs, que requereix, com a mínim, que l'investigador tingui coneixements bàsics de matemàtiques. No obstant això, la interpretació dels paràmetres de centralitat d'un graf es pot realitzar des d'un punt de vista profà.
Són molts els valors que es poden calcular en un graf, però la taula 2 en presenta alguns dels més usuals en l'anàlisi de xarxes bibliomètriques.
|
|
|
|
|---|---|---|
| Input degree (grau d'entrada) |
Nombre d'enllaços que entren en el vèrtex i. |
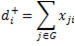 |
| Output degree (grau de sortida) |
Nombre d'enllaços que surten del vèrtex i. |
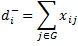 |
| Degree all (grau total) |
Nombre total d'enllaços connectats al vèrtex i. |
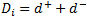 |
| Closeness all (proximitat) |
Un vèrtex que es considera important està relativament tancat per altres vèrtexs. Aquest paràmetre indica la quantitat de nodes que s'han de recórrer des de la part externa del graf fins a arribar al node que estem calculant. |
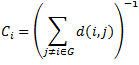 |
| Betweenness (intermediació) |
Un vèrtex que es troba en vies de comunicació pot controlar el flux de la comunicació, i, per tant, és important. La centralitat per intermediació compta el nombre de camins més curts entre i i k que passen per l'actor j. |
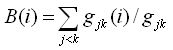 On gjk(i) = nombre de connexions geodèsiques sobre i, i gjk = nombre de connexions geodèsiques entre els vèrtexs jk.
|
Taula 2. Paràmetres de centralitat d'un graf, descripció qualitativa i matemàtica
Per obtenir els valors de centralitat la millor opció és emprar Pajek, ja que en tenir implementades les equacions descrites en la taula 2 permet calcular-los de manera senzilla. Un cop carregat el fitxer NET a Pajek busquem al menú superior l'opció "Network > Create vector > Centrality" per seleccionar alguna de les mesures de centralitat descrites en la taula o qualsevol altra amb la qual estiguem familiaritzats. Els resultats d'aquesta acció s'emmagatzemen en forma d'un vector de longitud igual que el nombre de nodes que té la nostra xarxa. Per consultar els valors de centralitat de cada un dels nodes, en la part esquerra de la pantalla utilitzarem el botó "Vectors" per guardar el vector. Aquest vector pot visualitzar-se amb qualsevol processador de text o full de càlcul que permet fer càlculs posteriors.
5 Conclusions
En definitiva, aquest text ha proporcionat els coneixements pràctics mínims per començar a utilitzar programes que han demostrat un gran potencial per a l'anàlisi de registres bibliogràfics. Bàsicament aborda els passos necessaris per representar la coocurrència de termes, ja que en tractar-se d'una anàlisi sofisticada no es pot dibuixar utilitzant aplicacions senzilles. Per finalitzar, volem destacar que aquestes mateixes tècniques poden usar-se amb textos procedents d'altres fonts, sempre que se'n respectin els requeriments mínims: treballar amb text pla i que els fitxers tinguin una estructura comprensible perquè els pugui computar Bibexcel. Sota el nostre punt de vista, qualsevol persona que segueixi aquestes instruccions podrà explorar la resta d'opcions per si mateixa, i descobrir noves aplicacions que van més enllà de la bibliometria.
Bibliografia
Aleixandre Benavent, Rafael; González de Dios, Javier; Alonso Arroyo, Adolfo; Bolaños Pizarro, Máxima; Castelló Cogollos, Lourdes; González Alcaide, Gregorio; Vidal Infer, Antonio; Navarro Molina, Carolina; Coronado Ferrer, Silvia; González Muñoz, M.; Málaga Guerrero, Serafín (2013). "Coautoría y redes de colaboración científica de la pediatría española (2006-2010)". Anales de Pediatría: Publicación Oficial de la Asociación Española de Pediatría (AEP), vol. 78, no. 6, p. 410.
Alòs-Moner, Adela d' (2003). "Mapas del conocimiento, con nombre y apellido". El profesional de la información, vol. 12, no. 4, p. 314–318.
Ardanuy Baró, Jordi (2014). "Análisis de los estudios bibliométricos en Cataluña". BiD: textos universitaris de biblioteconomia i documentació, juny, núm. 32 <https://bid.ub.edu/es/32/ardanuy2.htm>. [Consulta: 03/11/2014].
Bonacich, Phillip (2008). "Exploratory social network analysis with Pajek". Sociological Methods & Research, vol. 36, no. 4, p. 563–564.
Cobo, Manuel J.; López Herrera, Antonio G.; Herrera Viedma, Enrique; Herrera, Francisco (2011). "Science mapping software tools: Review, analysis, and cooperative study among tools". Journal of the American Society for Information Science and Technology, vol. 62, no. 7, p. 1382–1402.
Cruz Mata, Fermín; Troyano Jiménez, José Antonio; Enríquez de Salamanca Ros, Fernando; Ortega, F. Javier (2006). "TextRank como motor de aprendizaje en tareas de etiquetado". Procesamiento del lenguaje natural, núm. 37, p. 33–42. <http://dialnet.unirioja.es/servlet/ejemplar?codigo=196647>. [Consulta: 03/11/2014].Del-Fresno-García, Miguel (2014). "Haciendo visible lo invisible: visualización de la estructura de las relaciones en red en Twitter por medio del análisis de redes sociales". El profesional de la información, mayo–junio, vol. 23, no. 3, p. 246–252. <http://dx.doi.org/10.3145/epi.2014.may.04>. [Consulta: 03/11/2014].
Filippov, Sergey (2014). "Mapping Text and Data Mining In academic and Research Communities in Europe". Lisbon Council special briefing, no. 16. <http://www.lisboncouncil.net/publication/publication/109-mapping-text-and-data-mining-in-academic-and-research-communities-in-europe.html>. [Consulta: 03/11/2014].
González, Néstor (2013). Mapas de conocimiento. <http://www.innoemotion.com/2013/06/mapas-de-conocimiento/>. [Consulta: 03/11/2014].
Hernández Quintana, Ania R. (2006). "Principios ergonómicos aplicados a los mapas de conocimiento: ventajas y desventajas de las nuevas formas de representación de la información". Acimed, vol. 14, no. 3. <http://bvs.sld.cu/revistas/aci/vol14_3_06/aci07306.htm>. [Consulta: 19/11/2014].
Herrero Solana, Víctor; Moya Anegón, Félix (2009). "Redes de coautoría del Departamento de Biblioteconomía y Documentación de la Universidad de Granada (1982-2006)". En: García Caro, Concepción; Vílchez Pardo, Josefina (coord.). Homenaje a Isabel de Torres Ramírez: estudios de documentación dedicados a su memoria, Granada: Universidad de Granada, p. 323–332.
Howard, Ronald A. (1989). "Knowledge maps". Management science, vol. 35, no. 8, p. 903–922.
Leydesdorff, Loet; Wagner, Caroline S.; Park, Han-Woo; Adams, Jonathan (2013). "International collaboration in science: the global map and the network". El profesional de la información, January–February, vol. 22, no. 1, p. 87–94.
López Borrull, Alexandre; Canals, Agustí (2013). "La colaboración científica en el marco de nuevas propuestas científicas: Open Science, e-Science y Big Data". En: Agulló Calatayud, Víctor; González Alcaide, Gregorio; Gómez Ferri, Javier (coord.). La colaboración científica: una aproximación multidisciplinar.Valencia: Nau Llibres,p. 91–100.
Nualart-Vilaplana, Jaume; Pérez-Montoro, Mario; Whitelaw, Mitchell (2014). "How we draw texts: a review of approaches to text visualization and exploration". El profesional de la información, mayo–junio, vol. 23, no. 3, p. 221–235. <http://dx.doi.org/10.3145/epi.2014.may.02>. [Consulta: 03/11/2014].
Peset, F.; Ferrer-Sapena, A.; Villamón, M.; González, L. M.; Toca-Herrera, J. L.; Aleixandre-Benavent, R. (2013). "Scientific literature analysis of Judo in Web of Science®". Archives of budo, vol. 9, no 2. <http://eprints.rclis.org/21008/>.
Peset, Fernanda; González, Luís-Millán (2012). Construcción de redes de colaboración con Bibexcel, Pajek, Vosviewer y GPSVisualizer. <http://personales.upv.es/mpesetm/>. [Consulta: 19/10/2014].
Pino-Díaz, José; Jiménez-Contreras, Evaristo; Ruíz-Baños, Rosario; Bailón-Moreno, Rafael (2012). "Strategic Knowledge Maps of the Techno-Scientific Network (SK Maps)". Journal of the American society for information science and technology, vol. 63, no. 4, p. 796–804.
Robinson García, Nicolás; Rodríguez Sánchez, Rosa; García, J. A.; Torres Salinas, Daniel; Fernández Valdivia, Joaquín (2013). "Análisis de redes de las universidades españolas de acuerdo a su perfil de publicación en revistas por áreas científicas". Revista española de documentación científica, vol. 36, no. 4, 16 p.
Ruas, Terry Lima; Pereira, Luciana (2014). "Como construir indicadores de Ciência, Tecnologia e Inovação utilizando Web of Science, Derwent World Patent Index, Bibexcel e Pajek? Perspectivas em Ciência da Informação, vol. 19, no. 3, p. 52–81.
Sánchez-Durá, Nicolás (2013). "Actualidad del relativismo cultural". Desacatos, num. 41, enero–abril 2013, p. 29–48
Tarrats Pons, Elisenda (2012). "Sitkis: una herramienta bibliométrica para el desarrollo del estado de la cuestión". BiD: textos universitaris de biblioteconomia i documentació, núm. 28. <https://bid.ub.edu/28/tarrats2.htm>. [Consulta: 19/10/2014].
Torres Salinas, Daniel; Jiménez Contreras; Evaristo; Robinson García, Nicolás (2014). "Tendencias en mapas de la ciencia: co-uso de información científica como reflejo de los intereses de los investigadores". El profesional de la información, vol. 23, no. 3, p. 253–258.
Tsai, Hsu-Hao (2012), "Global Data Mining: An Empirical Study of Current Trends, Future Forecasts and Technology Diffusions". Expert Systems with Applications, vol. 39, no. 9, p. 8172–8181.
Valenciano Valcárcel, Javier; Devís Devís, José; Villamón, Miguel; Peiró Velert, Carmen (2010). "La colaboración científica en el campo de las Ciencias de la Actividad Física y el Deporte en España" Revista española de documentación científica, vol. 33, no. 1, p. 90–105.
Notes
1 Tema: (Knowledge maps) Refinat per: categories de Web of Science: (INFORMATION SCIENCE LIBRARY SCIENCE) Període de temps: tots els anys. Índexs: SCI-EXPANDED, SSCI, A & HCI, CPCI-S, CPCI-SSH, CCR-EXPANDED, IC.
2 Cal recordar que Bibexcel cada vegada que executem una acció genera un document nou amb una extensió nova. És habitual que per acabar tot el procés s'hagin de generar més de deu fitxers. No obstant això, tots, independentment de l'extensió, són fitxers de text pla que es poden obrir i modificar.

