
Rubén Alcaraz Martínez
EINA, Centre Universitari de Disseny i Art de Barcelona. Arxiu
Elisabet Vázquez Puig
Directora
Biblioteca Pública de Ripollet
Resum
Es descriuen les característiques principals de l'estàndard TEI (Text Encoding Initiative), un llenguatge basat en l'XML per codificar qualsevol tipus d'estructura textual, com ara novel·les, obres teatrals, poemes, discursos o articles científics, entre d'altres. Es mostren els diferents camps d'aplicació i es comenten diferents exemples de projectes representatius en l'àmbit de les humanitats digitals i les col·leccions patrimonials en línia.
Resumen
Se describen las principales características del estándar TEI (Text Encoding Initiative), un lenguaje basado en XML para codificar cualquier tipo de estructura textual como, por ejemplo, novelas, obras teatrales, poemas, discursos o artículos científicos, entre otros. Se muestran sus diferentes campos de aplicación y se comentan diferentes ejemplos de proyectos representativos en el ámbito de las humanidades digitales y las colecciones patrimoniales en línea.
Abstract
In this paper we describe the main features of the mark-up language developed by the Text Encoding Initiative (TEI), now the standard protocol for digitally encoding all types of text structure, from novels and plays to poetry, speeches and scientific articles. We examine different areas of application and look at examples of digital humanities projects and online heritage collections that use TEI.
1 Què és la TEI?
La Text Encoding Initiative (TEI) s'encarrega de desenvolupar un estàndard per representar textos en format digital, basat en el metallenguatge XML.
Els orígens de la iniciativa es remunten a l'any 1987, en el marc d'un projecte de cooperació internacional sota els auspicis de l'Association for Computers and the Humanities, l'Association for Computational Linguistics, i l'Association for Literary and Linguistic Computing, actual European Association for Digital Humanities. L'objectiu inicial d'aquest projecte no era altre que trobar un esquema de codificació comú per a estructures textuals complexes, que permetés reduir la diversitat de pràctiques existents en aquell moment, pel que fa a la codificació de textos digitals.
Des de l'any 2000, es tracta d'un projecte mantingut pel Consorci TEI, una organització sense ànim de lucre integrada per institucions acadèmiques i per projectes d'investigació i acadèmics individuals d'arreu del món.1 Els objectius d'aquest consorci són: desenvolupar les directrius TEI, promoure i difondre aquestes directrius, formar i divulgar en l'ús de l'estàndard, i crear i mantenir una comunitat d'investigadors entorn de la iniciativa.2
Per evitar confusions, cal tenir en compte que el terme TEI s'utilitza indistintament per fer referència a: la Text Encoding Initiative o el Consorci TEI, la documentació oficial coneguda com a TEI guidelines i el mateix llenguatge. En aquest article, emprarem la forma femenina del terme per referir-nos a la iniciativa, i parlarem de l'estàndard TEI per referir-nos al llenguatge en format XML desenvolupat i mantingut pel Consorci TEI.
2 En què consisteix la codificació de textos?
En el context que ens ocupa, Renear (2004) defineix la codificació de textos com "the practice of creating machine-readable texts to support humanities research". En aquest sentit, l'estàndard TEI ofereix un esquema que inclou i descriu un conjunt d'elements que permeten marcar les principals característiques estructurals, interpretatives i conceptuals de diferents tipologies de textos (literaris, periodístics, científics, etc.), amb l'objectiu de poder ser processades posteriorment (Baena Sánchez [et al.], 2014). La codificació de textos permet, doncs, facilitar la recuperació de la informació continguda en els documents, als quals es podrà accedir de manera sistemàtica com si es tractés, salvant les distàncies, d'una base de dades. També facilita les anàlisis informatitzades, com ara estudis estilomètrics per classificar textos o per determinar-ne l'autoria, anàlisis del contingut o estudis estadístics, entre d'altres.
3 Per què l'XML?
Des dels orígens, l'estàndard TEI s'ha creat sota la premissa de ser un llenguatge flexible i extensible, capaç de representar qualsevol tipus de text i d'adaptar-se a les necessitats específiques de cada centre o projecte d'investigació.3 L'ús, primer de l'estàndard SGML (Standard Generalized Markup Language) i, a partir de 2002, de l'XML (Extensible Markup Language), asseguren aquesta premissa.
El metallenguatge XML és un estàndard obert i internacionalment reconegut, que es caracteritza per la simplicitat, facilitat d'ús i flexibilitat, i en destaca la capacitat per assegurar la interoperabilitat entre aplicacions, plataformes i llenguatges informàtics (Allés Torrent, 2015).
L'XML no es presenta sol, sinó que ve acompanyat d'un bon grapat de tecnologies que el complementen. Entre d'altres, són:
- XSL (Extensible Stylesheet Language). Un llenguatge que, juntament amb els CSS (Cascading Style Sheets), permet definir la presentació, visualització i transformació dels documents XML en un mitjà específic com ara una pàgina web.
- XPath (XML Path Language). Pensat per accedir a parts concretes d'un document XML.
- XLink. Orientat a la creació de relacions internes i externes entre documents XML.
- XPointer. Pensat per identificar i fer referències a punts concrets o fragments que es troben dins d'un document XML.
- XQL (XML Query Language). Llenguatge de consulta que facilita l'extracció de dades des dels documents XML.
Les característiques pròpies de l'XML, combinades amb la resta de tecnologies que acabem de descriure, permeten que l'estàndard TEI presenti una gran capacitat d'adaptar-se constantment i evolucionar d'acord amb noves necessitats i reptes, i mantenir-ne, al mateix temps, els principis fonamentals (Romary, 2009). D'altra banda, tecnologies com ara l'XSL, i la parella XPath i XQL permeten garantir l'edició en diferents formats dels textos codificats, i faciliten l'explotació de les dades codificades, respectivament.
4 La infraestructura TEI
Les TEI Guidelines for electronic text encoding and interchange (TEI Consortium, 2016) són unes pautes que defineixen i documenten l'estàndard TEI. Aquestes directrius s'organitzen al voltant de diferents capítols en els quals s'aborden el sistema de classes i d'atributs, i els diferents mòduls que conformen l'esquema.
4.1 Els mòduls
L'esquema de codificació TEI es troba format per 21 mòduls independents en què es declaren els diferents elements i atributs XML disponibles. Aquesta manera d'estructurar l'esquema, fa que l'ús de la TEI sigui altament flexible i extensible, i que sigui extremament fàcil combinar i afegir diferents elements per confeccionar un esquema adequat als requeriments de cada tipus de projecte.
La combinació de mòduls és totalment lliure. Tanmateix, existeixen quatre mòduls obligatoris que haurien de ser presents en qualsevol combinació: tei, core, header i textStructure.
La llista completa de mòduls és la següent:
- analysis: pensat per associar anàlisis simples i interpretacions a elements textuals. Per exemple, per indicar el predicat d'una frase, el prefix o sufix d'un mot, o la seva categoria gramatical.
- certainty: permet indicar que aspectes determinats del text són problemàtics o incerts. Això es manifesta en forma de notes o d'aclariments en el text.
- core: es tracta d'un conjunt d'elements bàsics disponibles per a la codificació de qualsevol tipus de text, com ara paràgrafs, llistes, text emfatitzat, referències bibliogràfiques, etc.
- corpus: pensat per crear corpus lingüístics.
- dictionaries: hi trobem els elements necessaris per codificar qualsevol tipus de recurs lèxic, com ara diccionaris o glossaris.
- drama: dissenyat per codificar obres teatrals, guions cinematogràfics o radiofònics, entre d'altres.
- figures: orientat a descriure gràfics, taules, imatges, obres d'art, fórmules matemàtiques, etc., que formen part dels documents.
- gaiji: per codificar glifs i altres caràcters especials, tipus d'escriptures (vertical, horitzontal, de dreta a esquerra, etc.), etc.
- header: proporciona metadades descriptives sobre el recurs codificat (informació bibliogràfica, mencions de responsabilitat, informació sobre el projecte i investigadors i centres participants, informació d'aspectes no bibliogràfics com ara matèries o codis de classificació, l'historial de revisió de la codificació, etc.).
- iso-fs: permet representar les interrelacions entre peces d'informació, proporcionant-ne la instanciació en el marcatge, un metallenguatge per a representacions genèriques de les anàlisis i interpretacions fetes.
- linking: ofereix diferents elements que permeten representar relacions entre parts dels documents a partir d'identificadors i enllaços.
- msdescription: defineix elements pensats per proporcionar informació descriptiva detallada sobre qualsevol tipus de text manuscrit. Inicialment, va ser concebut per satisfer les necessitats dels catalogadors i acadèmics que treballaven amb manuscrits medievals de tradició europea, tot i que actualment se'n pot estendre l'ús a altres tradicions i materials.
- namesdates: un mòdul pensat per codificar dates, noms i altres identificadors de persones, llocs i organitzacions.
- nets: permet codificar representacions gràfiques emprades per visualitzar les relacions que s'estableixen entre unitats d'informació. Es preveu l'ús de grafs i mapes conceptuals.
- spoken: orientat a descriure transcripcions de qualsevol tipus de discurs oral.
- tagdocs: ofereix un conjunt d'elements que poden ser utilitzats per documentar els elements XML. Molt pensat per als projectes en els quals es personalitza o modifica el nucli o algun dels mòduls de l'estàndard.
- tei: conté les declaracions de tots els tipus de dades i les declaracions inicials de les classes d'atributs, models i les macros utilitzades per la resta de mòduls de l'esquema.
- textcrit: permet crear aparells crítics propis de la crítica textual.
- textstructure: un mòdul obligatori que conté l'estructura d'alt nivell per defecte de qualsevol document TEI.
- transcr: pensat per representar fonts primàries, com ara manuscrits, cartes o diaris.
- verse: dissenyat per codificar textos escrits totalment o parcialment en vers.
A continuació, es mostra un exemple comentat del marcatge d'un petit fragment de l'obra d'Oscar Wilde, The Importance of Being Earnest.4

Figura 1. Exemple de codificació d'un text dramàtic
4.2 El sistema de classes i atributs
Les declaracions dels 500 elements que formen l'esquema de la TEI també inclouen l'assignació a una classe o més d'elements que serveixen per expressar diferents tipus de relacions entre aquests. Quan dos elements o més comparteixen un atribut o més, s'organitzen sota la mateixa classe d'atribut (attribute class), mentre que si el que tenen en comú és la part del document on poden aparèixer, aleshores els trobarem dins d'una mateixa classe de model (model class). Per exemple, tots els elements que poden aparèixer dins d'un element <div> els trobarem a la classe "model.divPart". Les classes s'organitzen jeràrquicament, i donen lloc a les anomenades subclasses i superclasses. Els elements que comparteixen una mateixa branca de l'arbre hereten la possibilitat d'aparèixer en aquelles parts del document on també ho pot fer qualsevol dels elements de les seves superclasses superiors en la jerarquia.
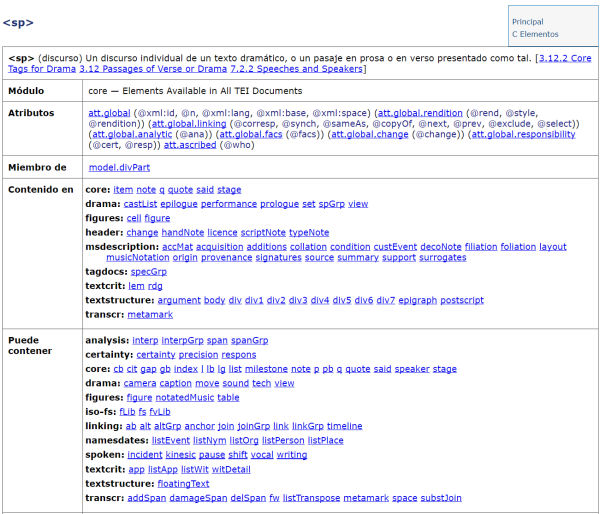
Figura 2. Fragment de la descripció de l'element <sp> (speech) a la versió en línia de les directrius TEI
5 Personalització de l'esquema de la TEI
L'estàndard TEI pretén cobrir un ampli ventall d'usos. Per poder acomplir aquesta premissa, resulta totalment necessari disposar d'un llenguatge flexible i extensible que permeti personalitzacions segons les necessitats de cada projecte. Això és possible gràcies a l'estructura basada en mòduls i classes presentada anteriorment, i a l'ús mateix de l'XML.
Al web de la TEI, trobem diferents exemples d'aquestes personalitzacions, basades en la combinació d'alguns dels mòduls "oficials".5 Per exemple, la TEI Lite incorpora els elements bàsics per codificar documents simples; la TEI Drama s'orienta a descriure obres teatrals, o el jTEI Article, una personalització enfocada a crear articles de revista, i utilitzada al Journal of the Text Encoding Initiative mantingut pel mateix Consorci TEI. Altres línies d'investigació han derivat en desenvolupaments com ara el CBML (Comic Book Markup Language) pensat per codificar còmics (Walsh, 2012).
Per facilitar la personalització de l'esquema, la TEI ofereix una eina anomenada Roma, un assistent que pas a pas i, a través de formularis senzills, ens permet generar el propi esquema. Les personalitzacions de l'estàndard TEI es coneixen informalment com a ODD (One Document Does it All).
Com acabem de comentar, l'ús de l'assistent és extremament fàcil. Només haurem de decidir a partir de quin conjunt d'elements volem començar a treballar: una versió mínima amb els quatre mòduls obligatoris, la TEI Lite, la TEI All amb tots els mòduls o, fins i tot, una versió personalitzada que podem carregar des del nostre ordinador.

Figura 3. Pantalla d'inici de l'eina Roma
A continuació, el sistema ens demanarà una sèrie de metadades: títol de l'esquema, nom del fitxer, espai de noms, nom de l'autor, etc.

Figura 4. Metadades necessàries per identificar l'esquema nou
La pestanya "Módulos" ens permet afegir i eliminar mòduls del nostre esquema. També és possible accedir a cadascun dels mòduls per tal d'incloure o excloure de l'esquema els diferents elements que el formen.

Figura 5. Selecció dels mòduls per a l'esquema nou
Una vegada triats els mòduls i elements disponibles, podem crear-ne de nous, en el cas que en necessitem. Per fer-ho, haurem d'associar cada element nou a una classe de model i a una d'atribut de les existents. Dit això, és important destacar que la incorporació d'un excés d'elements nous, comportarà treballar al marge de l'estàndard, pràctica que s'ha de limitar per tal d'assegurar la interoperabilitat entre projectes.
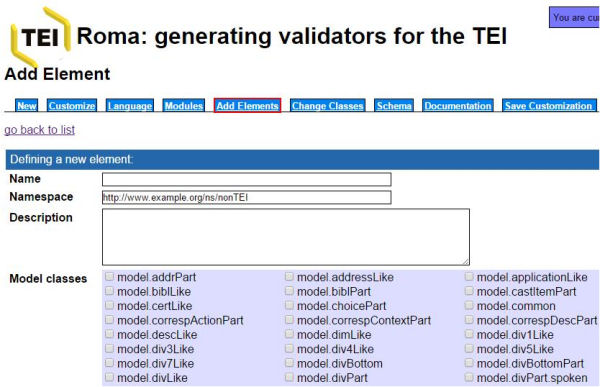
Figura 6. Creació d'elements nous per a l'esquema
Amb el nostre esquema personalitzat ja finalitzat, podem descarregar qualsevol dels sistemes de validació disponibles: Relax NG, Schematron, XML Schema o DTD (Document Type Definition).

Figura 7. Descàrrega del sistema de validació per a l'esquema XML personalitzat
Finalment, podem descarregar en diferents formats (HTML, Microsoft Word, LaTeX, etc.) la documentació del nostre esquema amb la descripció de cadascun dels elements i atributs que el conformen.
6 Camps d'aplicació i estudi de casos
L'estàndard TEI estén els usos als camps de les humanitats, les ciències socials i la lingüística, i en destaca principalment la utilització en centres d'investigació, biblioteques i arxius en l'edició de textos per desplegar col·leccions digitals i edicions crítiques; la descripció de manuscrits i cartes medievals; la creació de corpus lingüístics i diccionaris; el manteniment de dades estructurades per crear bases de dades per emmagatzemar llistes de personatges, cronologies o col·leccions d'objectes, o, fins i tot, per a usos editorials.
A continuació, es descriuen un parell de projectes representatius en aquestes àrees.
6.1 ReMetCa: repertorio métrico digital de la poesía medieval castellana
El ReMetCa és un repertori digital que recull poemes medievals amb l'objectiu de construir una eina per classificar, definir i delimitar el corpus poètic castellà (González, 2013). El projecte, finançat per la UNED, neix l'any 2011 a partir de la necessitat de crear un instrument d'estudi centrat en la mètrica de les primeres manifestacions líriques de l'edat mitjana. D'aquesta manera, els estudis sobre la mètrica medieval castellana se sumen als d'altres tradicions literàries que ja tenen des de fa anys repertoris mètrics digitals, com ara Galícia (MedDB), França (Nouveau Naetebus) o els Països Baixos (Dutch Song DB). De fet, ja fa alguns anys que es va començar a projectar un metacercador que, sota el nom de Megarep, pretén unificar els diferents repertoris mètrics nacionals per crear una eina a nivell europeu que hauria de permetre consultar, des d'un portal únic, tots aquests recursos (González; Seláf, 2013).
Pel que fa a l'apartat tècnic, el ReMetCa utilitza l'estàndard TEI per codificar els versos. En el cas concret d'aquest projecte, s'ha desenvolupat més àmpliament el mòdul "verse", amb etiquetes específiques per descriure els fenòmens mètrics (González [et al.], 2014). L'ús de l'estàndard TEI els ha permès desenvolupar un instrument potent per dur a terme una anàlisi detallada dels versos, així com de cerques que facilitaran posteriors estudis mètrics i literaris comparatius.
Finalment, cal remarcar que en aquest projecte, l'estàndard TEI funciona conjuntament amb un sistema de gestió de bases de dades MySQL encarregat de l'emmagatzematge i recuperació de la informació.
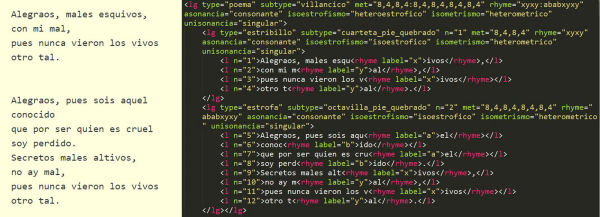
Figura 8. Fragment d'un dels poemes disponibles al ReMetCA. A la dreta es pot observar el text codificat amb l'estàndard TEI
6.2 The World of Dante
El The World of Dante és un projecte de l'Institute for Advanced Technologies in the Humanities de la University of Virginia, nascut amb la finalitat d'oferir tot un seguit d'eines multimèdia i interactives per aprofundir en l'estudi de La Divina Comèdia de Dante Alighieri.
A més de mapes interactius, línies de temps i galeries d'imatges relacionades amb l'obra, el portal ofereix una edició del poema etiquetada amb l'estàndard TEI que en permet la lectura en un entorn hipermèdia (Parker, 2001). La identificació i marcatge de diferents elements concrets dins de l'obra, com ara els personatges, llocs, criatures, deïtats o les estructures arquitectòniques, permeten recuperar ràpidament aquesta informació. D'aquesta manera, si el lector o l'investigador selecciona qualsevol d'aquests termes, apareixeran destacats tipogràficament en el text. Aquesta informació és de gran interès per analitzar detalladament el poema o per a estudis minuciosos sobre determinades figures concretes. Per exemple, es pot consultar en quins versos exactes del poema s'esmenta al personatge d'Alexandre el Gran o quines paraules, termes i expressions utilitza Dante per anomenar i descriure el Flegetonte, un dels rius de l'infern.
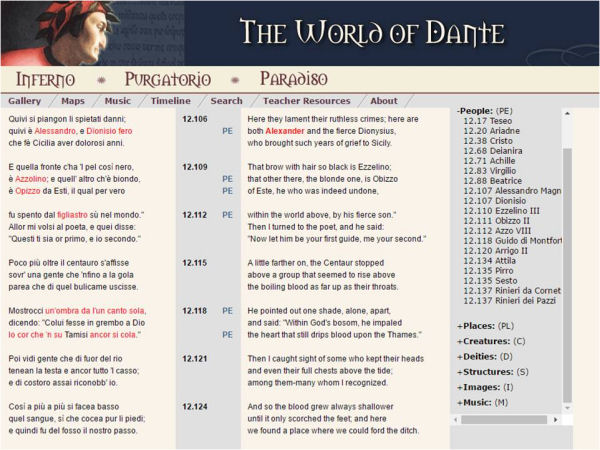
Figura 9. El marcatge dels personatges, llocs, criatures, etc. permet recuperar aquesta informació ràpidament
A més de la navegació pels diferents càntics de la Divina comèdia, el The World of Dante ofereix un cercador que permet recuperar els diferents càntics a partir de les categories abans esmentades. Gràcies al marcatge amb TEI, cada figura concreta incorpora informació addicional que permetrà afinar les cerques. Per exemple, en el cas de les persones es pot cercar per gènere, per l'origen del personatge (històric, mitològic o literari) o, fins i tot, per la seva afiliació política. La inclusió d'aquestes categories permet fer cerques afinadíssimes, per tal de dur a terme estudis molt concrets i detallats del text literari.
7 Aplicació en els repositoris i biblioteques digitals, i rol dels professionals de la informació
Tot i ser estudiades com dues realitats diferents per alguns autors (Siemens [et al.], 2011), és evident que molts dels projectes originats en l'àmbit de la biblioteconomia i la documentació poden etiquetar-se com a projectes d'humanitats digitals. La relació entre aquestes dues disciplines no es limita al camp d'actuació, sinó que el mateix perfil i competències pròpies dels professionals de la informació poden resultar molt interessants per a qualsevol institut o centre d'investigació en humanitats digitals, tant en tasques de suport a la investigació, com pel que fa al disseny i implementació dels projectes que se'n deriven (Rodríguez Yunta, 2013).
Pel que fa a l'aplicació de l'estàndard TEI a les biblioteques digitals, el mateix consorci TEI manté un document de treball que recull un conjunt de bones pràctiques per codificar textos en aquests tipus de projectes (Hawkins; Dalmau; Bauman, 2011). Aquestes directrius van ser creades per usar-se en projectes de digitalització de grans col·leccions bibliotecàries, però poden ser útils per a qualsevol treball de digitalització i codificació de documents. Entre altres informacions d'interès, inclouen un mapeig entre els elements de la capçalera d'un document TEI i les etiquetes MARC corresponents.
Un bon exemple de l'aplicació d'aquestes recomanacions el trobem en la incorporació de l'estàndard TEI als fluxos de treball per produir llibres digitals de la Biblioteca Virtual Miguel de Cervantes. Aquesta pràctica permet generar aquests llibres digitals en diferents formats a partir del document XML codificat amb TEI (Bia Platas; Sánchez Quero, 2001).
L'estreta relació entre la capçalera d'un document TEI i les dades d'un registre MARC també és protagonista de projectes com els de la biblioteca de la University of Michigan, on fins i tot van crear diferents scripts en el llenguatge de programació Perl per extreure de manera automatitzada els valors de les etiquetes MARC i traspassar-los als elements TEI corresponents (Marko; Powell, 2001).
Un altre exemple de l'ús de l'estàndard TEI en una biblioteca digital el trobem a la University of Virginia Library. En aquest cas, s'han integrat en el catàleg general de la biblioteca algunes col·leccions digitals marcades amb TEI. En el marc d'aquest projecte, el Digital Production Group de la biblioteca va desenvolupar unes directrius pròpies6 que són la base per al treball de codificació d'aquests recursos.

Figura 10. Edició digital de l'obra Adventures of Huckleberry Finn disponible al catàleg VIRGO de la University of Virginia Library
També destaca el treball que moltes biblioteques acadèmiques estan fent en l'ensenyament de l'estàndard TEI a la comunitat universitària. Un bon exemple el trobem a la University of California, on són els bibliotecaris mateixos els que ensenyen a professors i estudiants l'estàndard TEI, perquè puguin desenvolupar projectes d'investigació en l'àmbit de les humanitats digitals (Green, 2014). A demanda dels interessats, els bibliotecaris especialistes elaboren petits tallers i cursos a mida. Fruit d'aquesta col·laboració, s'han originat projectes dins la universitat com ara l'UCLA Encyclopedia of Egyptology.
8 Conclusions
Tot i que l'estàndard TEI fa gairebé tres dècades que s'aplica, l'apogeu de les humanitats digitals en els darrers anys ha renovat l'interès per aquest estàndard i d'altres entre estudiosos de les humanitats i professionals de la informació i la documentació (Zhang; Liu; Mathews, 2015). No obstant això, actualment són pocs els projectes de digitalització a Espanya que han optat per enriquir els seus objectes digitals amb un marcatge com el proposat pel Consorci TEI. En aquest sentit, tal com explica Rodríguez Yunta (2014), al nostre territori s'ha anteposat la quantitat per damunt de la qualitat, i s'han acumulat en els repositoris i biblioteques digitals, documents en format PDF sense estructurar o, simplement, arxius d'imatge sense, ni tan sols, una versió textual derivada d'un procés de reconeixement òptic de caràcters (OCR). Projectes com ara TESORO (Edición electrónica del Teatro Español del Siglo de Oro para la difusión del español y la formación a distancia) o la Biblioteca Virtual Miguel de Cervantes són l'excepció a la pràctica més estesa. La utilització d'aquests sistemes de marcatge augmentaria l'ús efectiu dels recursos disponibles als repositoris de biblioteques i arxius, en facilitar-ne el processament automatitzat, una de les principals línies de treball i investigació en l'àrea de les humanitats digitals (Schmidt, 2012).
Bibliografia
Allés Torrent, Susanna (2015). Introducción a la edición digital de textos: TEI-XML. <http://susannalles.github.io/Web-TEI/1.1.html>. [Consulta: 25/06/2016].
Bia Platas, Alejandro; Sánchez Quero, Manuel (2001). "Diseño de un procedimiento de marcado para la automatización del procesamiento de textos digitales usando XML y TEI". En: De-la-Fuente, Pablo; Pérez, Adoración (ed.). ii Jornadas bibliotecas digitales (Jbidi), Almagro, 19 y 20 de noviembre. Alicante: Biblioteca Virtual Miguel de Cervantes, p. 153–165. <http://www.biblioteca.org.ar/libros/142321.pdf>. [Consulta: 27/09/2016].
Baena Sánchez, Francisco [et al.] (2014). "Codificación y representación cartográfica de noticias: aplicación de las humanidades digitales al estudio del periodismo de la Edad moderna". El profesional de la información, vol. 23, n.º 5 (septiembre-octubre), p. 519–526.
González, Elena (2013). "Actualidad de las humanidades digitales y un ejemplo de ensamblaje poético en red: ReMetCa". Cuadernos hispanoamericanos, n.º 761 (noviembre), p. 53–67.
González, Elena [et al.] (2014). "Una propuesta de integración del sistema de formularios de bases de datos MySQL con etiquetado TEI: ReMetCa, Repertorio digital de la métrica medieval castellana". En: López Poza, Sagrario; Pena Sueiro, Nieves (ed.). Humanidades digitales: desafíos, logros y perspectivas de futuro. A Coruña: SIELAE-JANUS. <http://www.janusdigital.es/anexo.htm?id=5>. [Consulta: 25/06/2016].
González, Elena; Seláf, Levente (2013). "Megarep: a comprehensive research tool in medieval and renaissance poetic and metrical repertoires". En: Soriano, Lourdes [et al.] (ed.). Humanitats a la xarxa: món medieval = Humanities on the web: the medieval world. Bern [etc.]: Peter Lang, p. 333–344.
Green, Harriett E. (2014). "Facilitating communities of practice in digital humanities: librarian collaborations for research and training in text encoding". Library quarterly: information, community, policy, vol. 84, no. 2, p. 219–234.
Hawkins, Kevin; Dalmau, Michelle; Bauman, Syd (ed.) (2011). Best practices for TEI in libraries. Version 3.0 (October). <http://www.tei-c.org/SIG/Libraries/teiinlibraries/main-driver.htm>. [Consulta: 27/06/2016].
Marko, Lynn; Powell, Christina (2001). "Descriptive metadata strategy for TEI headers: a University of Michigan Library case study". OCLC systems & services: international digital library perspectives, vol. 17, no. 3, p. 117–121.
Nogales Flores, J. Tomás [et al.] (2003). "Una experiencia de aplicación de XML y TEI a obras teatrales del Siglo de Oro español". En: 8as Jornadas españolas de documentación. Los sistemas de información en las organizaciones: eficacia y transparencia. Barcelona, 6–8 de febrero. Barcelona: FESABID, p. 395–404. <http://hdl.handle.net/10016/906>. [Consulta: 26/06/2016].
Parker, Deborah (2001). "The World of Dante: a hypermedia archive for the study of the Inferno". Literary and linguistic computing: Journal of the Association for Literary and Linguistic Computing, vol. 16, no. 3, p. 287–297. <http://llc.oxfordjournals.org/content/16/3/287.abstract>. [Consulta: 26/06/2016].
Renear, Allen H. (2004). "Text Encoding". En: Schreibman, Susan; Siemens, Ray; Unsworth, John (ed.). A companion to digital humanities. Oxford: Blackwell, p. 218–239. <http://www.digitalhumanities.org/companion/>. [Consulta: 26/06/2016].
Rodríguez Yunta, Luis (2013). "Humanidades digitales, ¿una mera etiqueta o un campo por el que deben apostar las ciencias de la documentación?". Anuario ThinkEPI, vol. 7, p. 37–43. <http://hdl.handle.net/10261/77511>. [Consulta: 26/06/2016].
— (2014). "Ciberinfraestructura para las humanidades digitales: una oportunidad de desarrollo tecnológico para la biblioteca académica". El profesional de la información, vol. 23, n.º 5 (septiembre-octubre), p. 453–462.
Romary, Laurent (2009). "Questions & answers for TEI newcomers". Jahrbuch für Computerphilologie, nr. 10. <http://arxiv.org/abs/0812.3563>. [Consulta: 24/06/2016].
Schmidt, Desmond (2012). "The role of markup in the digital humanities". Historical social research, vol. 37, no. 3, p. 125–146. <http://nbn-resolving.de/urn:nbn:de:0168-ssoar-378369>. [Consulta: 27/06/2016].
Siemens, Lynne [et al.] (2011). "A tale of two cities: implications of the similarities and differences in collaborative approaches within the digital libraries and digital humanities communities". Literary and linguistic computing, vol. 26, no. 3, p. 335–348.
TEI Consortium (ed.) (2016). TEI P5: guidelines for electronic text encoding and interchange. Version 3.0.0. [S.l.]: Text Encoding Initiative Consortium. <http://www.tei-c.org/release/doc/tei-p5-doc/en/Guidelines.pdf>. [Consulta: 25/06/2016].
Walsh, John A. (2012). "Comic Book Markup Language: an introduction and rationale". Digital humanities quarterly, vol. 6, no. 1. <http://www.digitalhumanities.org/dhq/vol/6/1/000117/000117.html>. [Consulta: 25/06/2016].
Zhang, Ying; Liu, Shu; Mathews, Emilee (2015). "Convergence of digital humanities and digital libraries". Library management, vol. 36, no. 4–5, p. 362–377.
Notes
1 La llista completa de membres es pot consultar a: <http://members.tei-c.org/Directory>. [Consulta: 30/06/2016].
2 Disposeu de més informació al web de la TEI, a la secció "TEI: Goals and Mission". <http://www.tei-c.org/About/mission.xml>. [Consulta: 30/06/2016].
3 Aquesta voluntat ja es posa de manifest en el pròleg de la primera versió publicada de les directrius de l'estàndard l'any 1994.
4 Comentaris dels autors de l'article a partir dels exemples disponibles a: <http://teibyexample.org/>. [Consulta: 30/06/2016].
5 <http://www.tei-c.org/Guidelines/Customization/>. [Consulta: 30/06/2016].
6 <http://dcs.library.virginia.edu/digital-stewardship-services/tei-encoding-guidelines/>. [Consulta: 30/06/2016].

