
[Versión castellana] [English version]
Danielle Kane
Investigadora bibliotecària en tecnologies emergents
University of California, Irvine
Resum
La primera part d'aquest article analitza com crear i gestionar un bot a biblioteques acadèmiques, incloent-hi el tipus d'estadístiques que s'haurien d'elaborar i la importància de revisar periòdicament les transcripcions. Creat l'any 2014, el bot en qüestió s'ha desenvolupat fins al punt en què, de mitjana, contesta correctament les preguntes dels usuaris de les biblioteques en un 70 % dels casos. La segona part és una anàlisi de més de 10.000 frases enviades pels usuaris (preguntes i afirmacions). L'anàlisi va emprar l'eina UAM CorpusTool per tal de crear capes i transcripcions de codi d'acord amb l'estructura de les frases, les afirmacions d'obertura i tancament, l'interès mostrat, així com els tipus de serveis i materials sol·licitats. Si bé el bot de les biblioteques està clarament identificat com un programa informàtic, una sèrie d'usuaris tracten habitualment el bot com si fos un ésser humà i hi mantenen llargues converses no relacionades amb les biblioteques.
Resumen
La primera parte de este artículo analiza cómo crear y gestionar un bot en bibliotecas académicas, incluyendo el tipo de estadísticas que deberían elaborarse y la importancia de revisar periódicamente las transcripciones. Creado en 2014, el bot en cuestión se ha desarrollado hasta el punto en que, de media, contesta correctamente las preguntas de los usuarios de las bibliotecas en un 70% de los casos. La segunda parte es un análisis de más de 10.000 frases enviadas por los usuarios (preguntas y afirmaciones). El análisis empleó la herramienta UAM CorpusTool para crear capas y transcripciones de código de acuerdo con la estructura de las frases, las afirmaciones de apertura y cierre, el interés mostrado, así como los tipos de servicios y materiales solicitados. Si bien el bot de las bibliotecas está claramente identificado como un programa informático, una serie de usuarios tratan habitualmente el bot como si fuera un ser humano y mantienen largas conversaciones no relacionadas con las bibliotecas.
Summary
Part 1 of this paper discusses how to create and manage an academic library chatbot, including the type of statistics that should be kept and the importance of regularly reviewing transcripts. Created in 2014, the chatbot in question has been developed to the point where, on average, it correctly answers library users' questions 70% of the time. Part 2 is an analysis of over 10,000 user-submitted sentences (questions and statements). The analysis used UAM CorpusTool to create layers and code transcripts according to sentence structure, opening and closing statements, showing interest, and types of service and materials requested. While the library chatbot is clearly marked as being a computer program, a number of users regularly treat the chatbot as human and hold long non-library related conversations with it.
1 Introducció
L'informe 2019 Educause Horizon Report estima que la intel·ligència artificial té un horitzó d'implantació d'entre dos i tres anys, i afirma que "AI's ability to personalize experiences, reduce workloads, and assist with analysis of large and complex data sets recommends it to educational applications" (Educause, 2019). Un tipus específic de programari d'IA, el bot, es pot emprar per simular converses amb un usuari tot utilitzant el processament de llenguatge natural. Els bots poden optimitzar les interaccions entre els serveis i les persones, i millorar l'experiència dels usuaris dels serveis d'una biblioteca. Les màquines són capaces de reproduir els processos humans d'aprenentatge, raonament i autocorrecció tot emprant programes i codis informàtics: poden aprendre mitjançant l'adquisició d'informació i l'ús de normes preestablertes per tal de determinar com utilitzar aquesta informació; poden raonar tot utilitzant les normes per tal d'arribar a conclusions aproximades o, fins i tot, definitives; per últim, també poden autocorregir-se o es poden corregir de manera que no donin informació anòmala a l'usuari.
Tot imitant les aplicacions de missatgeria, els bots poden comunicar-se amb llocs web, aplicacions mòbils, maquinari (per exemple, habilitats d'Alexa) o, fins i tot, xarxes telefòniques. Tanmateix, no importa quin tipus d'aplicació o sistema s'esculli per crear un bot: la intervenció humana serà sempre crucial. Caldran éssers humans per configurar, entrenar i optimitzar el sistema. Proposat l'abril de 2013, el nostre bot ANTswers (http://antswers.lib.uci.edu/) va tardar aproximadament un any a desenvolupar-se. Si bé vam emprar tecnologia de codi obert per crear ANTswers, el projecte va tenir un cost, i els nostres programadors van necessitar un període de temps considerable per tal de crear totes les categories necessàries perquè el bot funcionés.
Figura 1. Interfície gràfica d'usuari d'ANTswers
En el context de la nostra universitat, els departaments de referència compten amb una llarga trajectòria a l'hora d'oferir serveis de referència virtuals a usuaris remots i del campus. Les biblioteques d'UCI ofereixen correu electrònic, QuestionPoint, missatgeria instantània i consultes de recerca basades en cites tot emprant eines com Google+ i Hangouts. McNeal & Nayara (2013) afirmen que les sol·licituds de materials, ubicacions, horaris i polítiques específiques predominen a les converses de xat i missatgeria instantània. Com que són els tipus de sol·licituds d'informació que els bots poden contestar correctament, ofereixen una opció d'autoservei per als usuaris. L'ús d'eines en línia ens permet satisfer les necessitats dels usuaris sigui quina sigui la seva ubicació i en el moment en què sorgeix la necessitat. Els bots permeten als bibliotecaris anar més enllà dels límits a l'hora d'oferir ajuda i instrucció 24/7 sense incorporar un conjunt de serveis de referència que exigeixin l'assistència en persona. A mesura que el personal canvia i la biblioteca defineix noves prioritats, pot esdevenir complicat dotar de personal els serveis de referència; per contra, un bot pot suposar menys temps de personal per gestionar-lo.
2 Creació d'un bot
La University of California (UCI), a Irvine, és una gran universitat pública de recerca ubicada a Irvin (Califòrnia) i un dels deu campus del sistema de la University of California. L'UCI compta amb un total d'onze mil persones que treballen l'equivalent a jornada completa entre personal docent i acadèmic, amb una població estudiantil superior a 35.000, mentre que UCI Libraries té 59 bibliotecaris i 100 membres de personal. UCI Libraries comprèn quatre biblioteques diferents: Langson Library, dedicada a la recerca i l'ensenyament en humanitats i ciències socials; Science Library (biblioteca de ciències), Grunigen Medical Library (biblioteca mèdica) i Law Library (biblioteca legal). Oferim serveis de referència al nostre taulell Ask Us (Pregunta'ns) a Langson Library, juntament amb consultes de recerca en persona i en línia de 30 minuts. També oferim serveis de referència per correu electrònic, telèfon i xat 24/7 amb QuestionPoint. L'any passat, el personal de l'UCI va contestar més de 12.000 preguntes de referència.
Com en qualsevol projecte d'envergadura, la planificació inicial i l'organització són claus a l'hora de crear un bot reeixit. L'abril de 2013, es va enviar una proposta a l'administració d'UCI Libraries on s'explicava detalladament què era un bot i el possible impacte que podria tenir en els nostres serveis de referència. La proposta revisava els diferents tipus de bots i proporcionava una recomanació sobre quin podria donar millor resposta a les necessitats de les nostres biblioteques. Tot plegat va prendre la forma d'ANTswers, que es va crear com a aplicació web basada en Program-O en un servidor remot. Els bots basats en el web ofereixen més flexibilitat, però requereixen experiència en HTML, PHP, CSS, JavaScript i AIML (Artificial Intelligence Markup Language). Program-O (http://blog.program-o.com/) és un motor AIML de codi obert escrit en PHP amb MySQL. Si bé hi ha múltiples motors AIML gratuïts i de codi obert, UCI Libraries va escollir Program-O per les seves funcions, que inclouen un corrector ortogràfic, configuració de personalitat del bot, una funció de cerca SRAI, així com la possibilitat d'afegir i editar comptes de botmaster.
L'equip de tecnologies emergents va afirmar que un bot a les biblioteques podria emplenar un buit als serveis de referència de les biblioteques que s'ofereixen actualment i, en termes generals, podria augmentar aquests serveis. QuestionPoint és un excel·lent servei 24/7 amb personal bibliotecari capacitat i experimentat, però es va considerar que oferia més d'allò que necessiten actualment els usuaris quan tenen una pregunta direccional o fàctica senzilla. Per a aquest tipus de situacions, haver d'introduir la teva informació de contacte i el nom pot ser una inversió de temps innecessària, i alguns usuaris també són reticents a l'hora de formular preguntes al personal de la biblioteca. Si bé els bots "cannot replicate the complexity of human interaction, [they] can provide a cost-effective way to answer the majority of routine reference questions" (Vincze, 2017). En resum, el bot ens oferia l'oportunitat:
- de millorar més que substituir els serveis de referència disponibles;
- d'atendre a un major nombre de persones en qualsevol moment del dia;
- d'atendre a una àmplia varietat d'usuaris de les biblioteques;
- de servir com a filtre per al personal de les biblioteques tot contestant preguntes bàsiques i repetitives ("On està la grapadora?", "Com puc imprimir?", etc.).
En una fase primerenca del procés, es va designar un equip de parts interessades claus de la biblioteca, el qual es reunia periòdicament per analitzar qüestions com si el bot s'havia de programar únicament per recollir consultes relacionades amb les biblioteques o si havia de ser capaç de mantenir una "conversa" més general. Els bots es poden veure com una forma de passar el temps o com "a way to avoid loneliness or fulfill a desire for socialization" (Brandtzaeg and Følstad, 2017). Una altra qüestió que es van plantejar és si el bot havia de tenir una personalitat i, en cas afirmatiu, quin tipus de personalitat havia de ser. L'equip va ajudar a definir com el bot havia d'interaccionar amb els nostres estudiants. Per tant, si bé queda molt clar que ANTswers és un programa informàtic, en una fase primerenca del procés, l'equip va decidir atorgar una personalitat a ANTswers basant-se en la mascota de l'UCI "Peter the Anteater" (Peter, l'os formiguer). Amb això present, ANTswers es va dissenyar com un os formiguer a qui agraden les formigues i tot allò relacionat amb l'UCI. Program-O facilita desenvolupar una personalitat per a un bot, ja que proporciona un "formulari" fàcil d'emplenar.

Figura 2. La interfície de personalitat del bot de Program-O
Program-O permet afegir i eliminar fitxers del sistema, però no substituir-los. Per tal de fer front a aquesta limitació del sistema, es va definir un fitxer amb un esquema de paraules en una fase primerenca del procés. La fundació Artificial Intelligence Foundation (A.L.I.C.E - https://code.google.com/p/aiml-en-us-foundation-alice/) ofereix una sèrie de fitxers de codi obert disponibles per a la descàrrega. Aquests fitxers inclouen el gruix de les categories de conversa generals, i s'han adaptat i depurat àmpliament per a l'ús en un entorn de biblioteca acadèmica. Els fitxers estan disponibles a GitHub (Kane, 2017a). Els dos fitxers del bot que contenen el codi per recordar informació sobre el bot i la mateixa conversa tenen anteposada la lletra "b". Els sis fitxers de referència preparats donen respostes fàctiques sobre temes generals, com ara ciència, història i geografia, i tenen anteposada la lletra "r.". Organitzats per servei, ubicació o recurs, els 20 fitxers de la biblioteca estan marcats amb "lib.". Finalment, 66 fitxers temàtics organitzats segons la classificació de la Library of Congress contenen recomanacions de recursos per a paraules clau i tenen anteposada la lletra "s".
Es poden utilitzar diversos programes per crear i editar fitxers AIML, inclosos Notepad, Atom, Vim i Notepad++. En el cas d'ANTswers, vam emprar Notepad++, que és un editor gratuït de codi obert per a la plataforma Windows. Notepad++ ofereix algunes funcionalitats útils, com ara les cerques a tots els fitxers i dins de les carpetes. Si bé els usuaris amb poca experiència en programació poden ser inicialment recelosos sobre l'aprenentatge d'AIML, en realitat es tracta d'un llenguatge senzill que és fàcil d'aprendre i pot funcionar sense dependre de "the conventional wisdom from structured programming" (Wallace, 2003). Les etiquetes <category>, <pattern> i <template> són les unitats bàsiques de coneixement a AIML: category és la unitat de coneixement, pattern fa referència a l'entrada introduïda per l'usuaris representada mitjançant paraules clau, frases o oracions, i template conté la resposta del bot. Per tant, una expressió AIML simple es pot representar de la manera següent:
<category><pattern>TEXT INTRODUÏT</pattern>
<template>TEXT DE SORTIDA</template></category>
A continuació, trobareu un exemple d'una categoria AIML senzilla:
<category><pattern>NECESSITO AJUDA</pattern>
<template>Pots demanar ajuda en forma d'una pregunta?</template></category>
AIML també permet l'ús d'etiquetes de coneixement, les quals provoquen que el bot emmagatzemi dades, activi un programa diferent o doni una resposta condicional. UCI Libraries va crear l'etiqueta específica <antpac> per recuperar registres de llibres del nostre catàleg, i l'etiqueta es va actualitzar quan la biblioteca va canviar a Library Search l'any 2018. AIML també permet reduccions simbòliques, cosa que resulta útil quan un programador accepta símbols del tipus "no m'importa" (comodí). L'ús del símbol "*" com a comodí ens dona els exemples de "paraula clau", "* paraula clau", "paraula clau *" i "* paraula clau *". L'ús de reduccions simbòliques augmentarà la possibilitat que s'escullin categories i que es proporcioni la resposta correcta.
Una altra etiqueta, <that>, permet al programador connectar determinades categories, cosa que resulta útil si el bot ha de formular a l'usuari una pregunta de seguiment. Per exemple, si la pregunta formulada és "Vull més informació sobre ossos formiguers", el bot retorna una resposta preguntant a l'usuari si està buscant llibres o articles. Si escrivim que volem més informació, s'activa la línia de recollida booksorarticles (llibres o articles). Si el sistema sap si volem llibres o articles, en combinació amb la introducció del comodí "*", en aquest cas, un tema o una paraula clau, retorna la resposta pertinent. Un valor sourcetype (tipus de font) de llibres activa una cerca al catàleg utilitzant la introducció del comodí "*". Si afirmem que volem articles, el sistema retornarà entre una i tres recomanacions del bibliotecari sobre el tema. L'URL del primer recurs s'obrirà a la finestra de sota el bot. Les recomanacions de recursos també inclouen un enllaç a la guia temàtica i, per tant, connecten els usuaris amb més recursos.
Es pot trobar una anàlisi més detallada del desenvolupament d'ANTswers a Role of Chatbots in Teaching and Learning in E-Learning and the Academic Library: Essays on Innovative Initiatives. Com a alternativa, el lector pot accedir a una sèrie de tutorials que existeixen sobre el llenguatge de programació AIML i les etiquetes que es poden utilitzar, com ara TutorialsPoint (https://www.tutorialspoint.com/aiml/aiml_introduction.htm).
3 Gestió d'un bot
Per tal de gestionar correctament un bot com ANTswers, cal un procés continu de revisió i actualització. Quan el bot estava a la versió beta, les transcripcions es revisaven diàriament cinc dies a la setmana, s'elaboraven estadístiques per a cada transcripció i s'introduïen modificacions en el codi per tal de resoldre els problemes detectats. Posteriorment, el codi actualitzat es tornava a pujar a Program-O en finalitzar cada revisió de les transcripcions. Les modificacions típiques que es realitzaven a ANTswers incloïen afegir categories noves o afegir termes nous a les categories existents. Com que l'UCI té un cos estudiantil internacional gran, cal que el programador afegeixi nous termes o frases de forma periòdica per tal de garantir que ANTswers pugui respondre les consultes formulades en un anglès gramaticalment incorrecte.
No es va poder utilitzar Program-O per avaluar i realitzar un seguiment de les estadístiques d'ANTswers, ja que el programa no pot marcar les transcripcions com a "llegides" ni afegir estadístiques al sistema. A més, el programa mostra primer les converses més antigues i no hi ha manera de buscar transcripcions específiques. Es va determinar que calia un sistema dorsal (back-end). Mitjançant l'ús de MySQL, un programador de la biblioteca podia bolcar les transcripcions de Program-O en una base de dades en línia, on es podien introduir les estadístiques. La data revisada s'utilitza com a nota visual per indicar que la transcripció s'ha revisat i s'han introduït les modificacions necessàries al codi. Les transcripcions i les estadístiques es poden descarregar de la base de dades en línia, i es poden bolcar a altres eines per a l'anàlisi. Quan el bot encara era nou, revisar les transcripcions i elaborar les estadístiques suposava entre cinc i sis hores de feina a la setmana. A mesura que les categories d'ANTswers van anar creixent i va augmentar el percentatge de resposta, la base de dades en línia només s'havia de revisar dos o tres cops a la setmana i, actualment, suposa entre una i tres hores de feina.
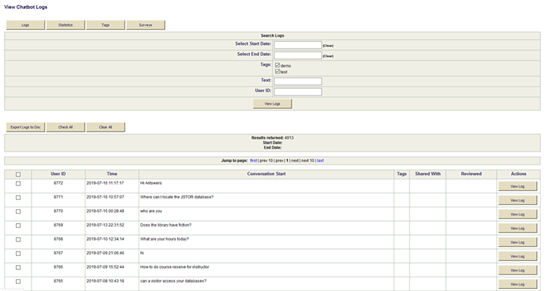
Figura 3. Sistema de gestió dorsal d'ANTswers
4 Anàlisi d'un bot
4.1 Estadístiques generals
Totes les transcripcions del bot es revisen a través del sistema dorsal. Com a part d'aquesta revisió, s'elaboren les estadístiques següents per a cada transcripció:
- Data
- Hora del dia
- Trimestre acadèmic
- Setmana del trimestre acadèmic
- Dia de la setmana
- Nombre total de preguntes
- Nombre de preguntes relacionades amb les biblioteques i percentatge de resposta
- Nombre de preguntes generals i percentatge de resposta
- Context de la transcripció: què pregunten els usuaris
- Escala READ
Les dades es descarreguen en una base de dades Access connectada amb l’Excel, on s'utilitzen taules dinàmiques per crear visualitzacions per a cada trimestre acadèmic (cal tenir en compte que l'UCI s'organitza per trimestres en lloc de per semestres). Des que ANTswers es va introduir l'any 2014, s'ha formulat un total de 12.202 preguntes, de les quals 7.770 (64 %) estan relacionades amb les biblioteques. Si bé hauria estat més senzill crear i mantenir un bot que únicament abordés preguntes relacionades amb les biblioteques, també hi vam incloure la possibilitat de respostes generals per a aquells usuaris que simplement volen xatejar. Les dades s'empaqueten per anys i es comparteixen a través de Dash, el servei de publicació de dades de la University of California. Quan ANTswers es va implementar per primer cop com a prova beta, tenia una mitjana de percentatge de resposta del 39 % de les respostes estaven relacionades amb les biblioteques. La feina d'actualització ha ajudat a augmentar aquest percentatge.
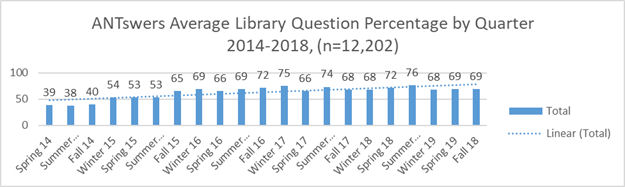
Figura 4. Mitjana de percentatge de resposta d'ANTswers per a preguntes relacionades amb les biblioteques per trimestre durant el període 2014–2018
Aquestes estadístiques ajuden a determinar quan es pot aturar ANTswers per realitzar-hi tasques de manteniment. Per exemple, ANTswers s'utilitza amb molta freqüència durant les setmanes 2 i 3 de cada nou trimestre (cal tenir en compte que cada trimestre té unes 10 setmanes). És més probable que els usuaris formulin preguntes de dilluns a dijous, entre les 8 del matí i les 7 de la tarda, si bé cal tenir en compte que els usuaris formulen preguntes les 24 hores del dia, 7 dies a la setmana. En termes generals, el nombre més elevat de preguntes es produeix durant les setmanes 1, 2 i 3 de cada trimestre. L'ús arriba al seu punt àlgid de dilluns a dijous, mentre que entre divendres i diumenge es produeix un descens del 50 % aproximadament. Durant les darreres setmanes de cada trimestre, el millor moment per dur a terme tasques de manteniment al bot són els divendres a primera hora del matí. Les actualitzacions i les tasques de manteniment més exhaustives es reserven per a l'estiu, quan hi ha menys estudiants al campus. Si bé l'ús ha disminuït des de 2015, aquesta circumstància és atribuïble més aviat als canvis realitzats a la pàgina d'inici del lloc web de la biblioteca, que va provocar que l'enllaç al bot es desplacés a la part inferior de la pàgina (durant la fase beta, l'enllaç ocupava una ubicació preeminent a la part superior de la pantalla).
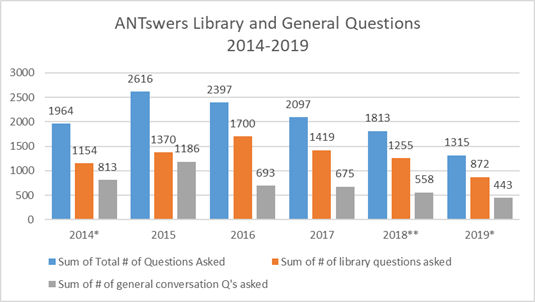
Figura 5. Preguntes generals i relacionades amb les biblioteques d'ANTswers durant el període 2014-2019
Segons Christensen (2007), els bots no "roben" preguntes de referència als bibliotecaris; per contra, es poden utilitzar per recollir preguntes de referència senzilles i preguntes freqüents sobre els temes següents:
- Navegació per un lloc web
- Enllaços a altres llocs web i documents
- Accés a registres d'OPAC
- Informació bàsica sobre tasques de les biblioteques en línia
- Materials de préstec entre biblioteques
- Cerca de materials a bases de dades
Si bé l'anàlisi de les estadístiques de referència d'UCI Libraries podria suggerir que ANTswers ha afectat les nostres estadístiques globals, s'ha produït una sèrie de fets des que es va llençar el bot l'any 2014. Amb el temps, hem escurçat les nostres hores de taulell com a resposta a la disminució de les necessitats a primera i última hora del dia. En ocasions, per escassetat de personal, hem passat de tenir obert el taulell de referència tant el dissabte com el diumenge a obrir només els diumenges i després no tenir ni tan sols hores de referència els caps de setmana. Els nostres serveis d'accés tampoc registren estadístiques de referència. Durant aquest període, també hem fet el salt a l'eina d'escala de sis punts READ (Reference Effort Assessment Data) i, després de fer un seguiment de l'escala READ per a cada transcripció d'ANTswers, vam detectar que les transcripcions eren eminentment discrecionals i, per tant, es codificaven com a 1, deixant molt poques transcripcions a les escales del 2 al 6.
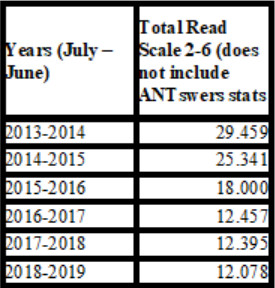
Figura 6. Nombre total de referències d'UC Irvine per a les escales READ 2–6 durant el període 2013–2019
4.2 Anàlisi textual de les transcripcions del bot
S'ha dut a terme una anàlisi de les transcripcions del xat des de la creació d'ANTswers el març de 2014 fins a l'abril de 2018 per tal de determinar com els usuaris formulen les preguntes i sobre quin tipus de recursos/serveis pregunten. S'ha avaluat cadascuna de les 7.924 transcripcions de xat per tal de determinar si eren transcripcions reals (enviades per un usuari) o proves, demostracions del sistema o contingut brossa. Un cop revisades les transcripcions, un total de 2.786 transcripcions es van revisar amb més profunditat per buscar la informació confidencial (com el nom del usuari), i aquesta informació i les respostes d'ANTswers es van eliminar abans de carregar les transcripcions a l'eina UAM CorpusTool (versió 3) per ID d'usuari associat. Les transcripcions contenien un total de 10.341 frases d'usuaris de biblioteques (preguntes i afirmacions). UAM CorpusTool es pot emprar per crear capes i, per tant, se'n va crear una per tal d'analitzar com els usuaris estaven formulant les preguntes i se'n va desenvolupar una altra per fer un seguiment d'allò que estaven preguntant.
La primera capa creada a UAM CorpusTool analitzava com els usuaris estaven formulant les preguntes, però també determinava si estaven utilitzant frases d'obertura i tancament, i si mostraven interès en el bot. Les salutacions es consideren una funció bàsica de la comunicació i un senyal de cortesia elemental en iniciar una conversa, i es va constatar que els usuaris havien emprat alguna mena de salutació en 460 (17 %) de les 2.786 transcripcions. Les salutacions més freqüents eren "hello" i "hi" (hola). D'altra banda, les frases de tancament només s'havien emprat en un 5 % de les transcripcions, i les més habituals eren "thank you" o "thanks" (gràcies). Un estudi recent dut a terme per Xu et al. sobre els bots per a serveis d'atenció al usuari va concloure que el 40 % de les sol·licituds d'usuaris són emocionals en lloc d'informatives (Xu, 2017). Només 248 de les transcripcions d'ANTswers incloïen preguntes sobre ANTswers, i majoritàriament preguntaven al bot quin era el seu nom, com es trobava i si era un humà.
Part d'aquesta primera capa també es va desenvolupar per fer un seguiment del tipus de preguntes que formulaven els usuaris i per determinar si les frases que havien teclejat eren declaratives, exclamatives, imperatives o interrogatives. A més del tipus d'oració, es va fer un seguiment de l'ús de blasfèmies, URL i preguntes repetitives. En essència, teníem un doble objectiu: oferir una millor informació a la programació del bot en el futur i compartir les nostres conclusions amb proveïdors de referència, especialment, aquells que treballen en un entorn en línia. Es va constatar que la majoria d'oracions dels usuaris eren interrogatives o imperatives. Les oracions interrogatives suposaven el 50 % del text introduït pels usuaris (n=10,051), mentre que les frases imperatives i declaratives suposaven el 29 %.
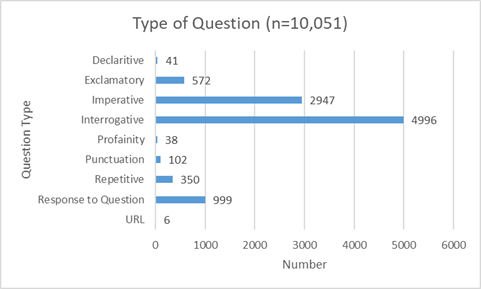
Figura 7. Tipus d'oracions enviades pels usuaris del bot
Es va crear una segona capa a UAM CorpusTool per tal d'avaluar el context dels tipus d'oracions enviades pels usuaris de les biblioteques. Mitjançant l'ús del lloc web d'UCI Libraries com a model per a aquesta capa, es van organitzar els serveis i els elements sol·licitats en categories àmplies: About (the Library)[Sobre (la biblioteca)], About (UCI) [Sobre (UCI)], Find[Cercar], Services [Serveis] i Subject[Tema]. A continuació, es van afinar més les categories àmplies. Per exemple, es va fer que la categoria About (the Library) inclogués Hours[Horari], About us [Sobre nosaltres], Visit[Visitar], News/events[Notícies/Esdeveniments] i Donate [Donatius]. Cada oració es va assignar a la categoria genèrica corresponent i, a continuació, a la categoria més limitada pertinent. A conseqüència de la complexitat del nostre sistema bibliotecari i els recursos proporcionats, algunes categories es van haver d'afinar encara més. Les nostres conclusions mostren que el nombre més elevat de sol·licituds es va produir a la categoria Services, concretament a Borrowing [Préstecs] (699 sol·licituds o el 20 % del total), seguida per Computing [Informàtica] (496 o el 14 % del total). A continuació, les categories consultades amb més freqüència són Find (Books/eBooks) [Cercar (llibres/llibres electrònics)] amb 398 o un 11 %) i després Hours a dins de la categoria About (the Library) (285 o un 8 %) (Kane, 2019).
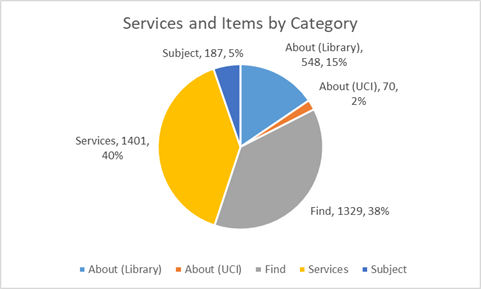
Figura 8. Serveis i elements d'ANTswers per categoria
Es pot trobar una anàlisi més detallada d'ANTswers en Kane (2019).
5 Conclusió
Les dades d'ANTswers ja han demostrat ser útils en realitzar modificacions al lloc web d'UCI Libraries, ja que han aportat proves materials del nombre més elevat de sol·licituds per a certa informació, com l'horari de les biblioteques. Les dades d'ANTswers es van emprar com a base per a un sistema d'etiquetatge per a una plataforma de cerca de codi obert compatible amb les biblioteques (Solr) que UCI va utilitzar abans d'implementar una cerca federada anomenada Library Search l'any 2018. Les estadístiques periòdiques sobre l'ús del bot, inclosos els tipus de recursos i serveis que sol·liciten els usuaris de les biblioteques, es comparteixen amb el personal d'atenció al públic de forma regular i poden aportar informació valuosa als bibliotecaris sobre els recursos que caldria afegir a les guies de recerca. La informació sobre com els usuaris de les biblioteques utilitzen el programa informàtic permet al programador del bot millorar el sistema de forma continuada, cosa necessària per garantir que la base de dades dorsal de categories continuï creixent.
En el futur, dur a terme la mateixa anàlisi al servei QuestionPoint de les biblioteques i comparar-ho després amb ANTswers podria aportar informació valuosa sobre com es relacionen els dos sistemes i com hauríem d'abordar els serveis de referència en línia i en persona en el futur. Altres estudis interessants també podrien incloure una anàlisi semàntica i una avaluació de la idoneïtat de les respostes d'ANTswers.
Bibliografia
Brandtzaeg P. B., and Følstad A., 2017. Why People Use Chatbots. A: Kompatsiaris I. et al. (eds) Internet Science. INSCI 2017. Lecture Notes in Computer Science, vol. 10673.
Christenson, A., 2007. A Trend from Germany: Library Chatbots in Digital Reference. Digital Libraries a la Carte, Module 2.
Educause, 2019. Educause Horizon Report: 2019 Higher Education Edition. [En línia]
Disponible a: https://library.educause.edu/-/media/files/library/2019/4/2019horizonreport.pdf?la=en&hash=C8E8D444AF372E705FA1BF9D4FF0DD4CC6F0FDD1 [Consulta: 28 de juny de 2019].
Kane, D. A., 2016. The Role of Chatbots in Teaching and Learning. A: R. Scott & M. N. Gregor, eds. E-Learning and the Academic Library: Essays on Innovative Initiatives. s.l.: McFarland, p. 131–147.
Kane, D., 2017a. ANTswers. [En línia]
Disponible a: https://github.com/UCI-Libraries/ANTswers
Kane, D., 2017b. UCI Libraries' Chatbot Files (ANTswers). [En línia]
Disponible a: https://dash.lib.uci.edu/stash/dataset/doi:10.7280/D1P075
Kane, D., 2019. Analyzing an Interactive Chatbot and its Impact on Academic Reference Services. Cleveland, Association of College and Research Libraries (ACRL).
McNeal, M. and Newyear D., 2013. Introducing chatbots in libraries. Library Technology Reports, 49(8), p. 5–10.
Vincze, J., 2017. Virtual reference librarians (Chatbots). Library Hi Tech News, 34(4), p. 5–8.
Wallace, R., 2003. The Elements of AIML Style. [En línia]
Disponible a: http://www.alicebot.org/style.pdf [Consulta: 3 de juliol de 2019].
Xu, A. et al., 2017. A New Chatbot for Customer Service on Social Media. New York, Proceedings of the ACM Conference on Human Factors in Computing Systems.
Kane, D., 2017b. UCI Libraries' Chatbot Files (ANTswers). [En línia]
Disponible a: https://dash.lib.uci.edu/stash/dataset/doi:10.7280/D1P075
Kane, D., 2019. Analyzing an Interactive Chatbot and its Impact on Academic Reference Services. Cleveland, Association of College and Research Libraries (ACRL).
McNeal, M. and Newyear D., 2013. Introducing chatbots in libraries. Library Technology Reports, 49(8), p. 5–10.
Vincze, J., 2017. Virtual reference librarians (Chatbots). Library Hi Tech News, 34(4), p. 5–8.
Wallace, R., 2003. The Elements of AIML Style. [En línia]
Disponible a: http://www.alicebot.org/style.pdf [Consulta: 3 de juliol de 2019].
Xu, A. et al., 2017. A New Chatbot for Customer Service on Social Media. New York, Proceedings of the ACM Conference on Human Factors in Computing Systems.

