
Rubén Alcaraz Martínez
EINA, Centre Universitari de Disseny i Art de Barcelona. Arxiu
Resumen
Se presentan las principales características de CollectiveAccess, un sistema de gestión y difusión de colecciones digitales para museos, archivos y bibliotecas. Se describen sus principales componentes, el proceso de instalación, la estructura interna del sistema y se muestran algunos ejemplos de casos de uso. Las versiones analizadas del sistema son la 1.4 de Providence y la 2.0 de Pawtucket.
Resum
Es presenten les característiques principals del CollectiveAccess, un sistema de gestió i difusió de col·leccions digitals per a museus, arxius i biblioteques. Se'n descriuen els components principals, el procés d'instal·lació, l'estructura interna del sistema i es mostren alguns exemples de casos d'ús. Les versions analitzades del sistema són la 1.4 del Providence i la 2.0 del Pawtucket.
Abstract
This paper describes the main features of CollectiveAccess, a collections management and presentation system for the digital collections of museums, archives and libraries. The paper describes the main features of the system and explains how to install and configure the package. It also examines CA’s internal structure and gives examples of how it can be used. The system analyzed in the paper uses Version 1.4 of the core cataloguing application Providence and Version 2.0 of the public web-access tool Pawtucket.
1 Introducción
CollectiveAccess (en adelante CA) es un sistema de gestión y difusión de colecciones de museos, archivos y bibliotecas. El programa ha sido desarrollado y es mantenido por la empresa Whirl-i-Gig, con la colaboración de diferentes instituciones asociadas de los Estados Unidos y de Europa como el Institute of Museum and Library Services, el National Endowment for the Humanities, el New York State Council for the Arts o el Kulturstiftung des Bundes, entre otros. El origen de la aplicación se remonta al año 2003, aunque su primera versión estable no se liberó hasta 2007, primero bajo el nombre de OpenCollection, hasta que en 2008 cambió por el actual CollectiveAccess. Desde su aparición se ha implementado en más de cien proyectos en diferentes ámbitos como las bellas artes, la historia oral, los fondos de archivo institucionales o diversas colecciones especiales de diferentes tipologías de unidades de información. CA es software libre que se distribuye bajo una licencia GNU GPL v3.1
En este artículo se analizan las versiones 1.4 de Providence y la versión 2.0 de Pawtucket, las últimas versiones estables disponibles de los dos componentes principales del sistema en el momento de escribir este artículo.
2 Componentes
Como acabamos de avanzar, CA se encuentra formado por dos componentes de software independientes: Providence y Pawtucket, encargados respectivamente de la parte de gestión y de difusión de los contenidos.
2.1 Providence
Providence es la parte central y más importante de CA. Lo forman una base de datos, un entorno de trabajo capaz de gestionar los principales formatos de archivos digitales2 y una interfaz de usuario para la catalogación, búsqueda y gestión de las colecciones y los objetos digitales del repositorio. Cualquier instalación de CA necesita, como mínimo, disponer de una instancia de Providence. El resto de componentes del sistema, incluido Pawtucket, son opcionales y requieren la existencia de este componente para funcionar.
Las principales características del módulo de gestión de CA son:
- Interfaz de catalogación altamente configurable a partir de diferentes perfiles de metadatos.
- Posibilidad de crear listas y vocabularios controlados asociados a campos de los esquemas de metadatos y a otras funciones del sistema.
- Categorización y etiquetaje de contenidos.
- Geolocalización de objetos.
- Motor de búsqueda configurable (MySQL o Solr).
- Herramientas administrativas orientadas a gestionar la colección (adquisiciones, préstamos, lotes de objetos, localización, estados de conservación, etc.).
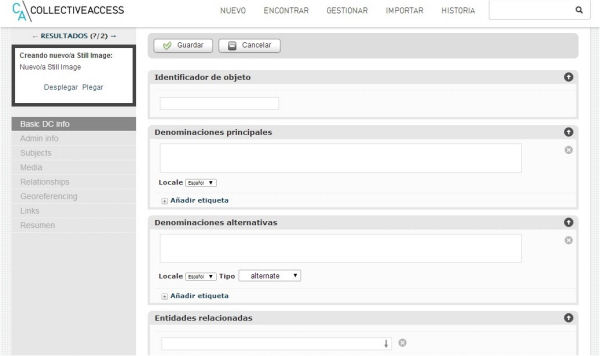
Figura 1. Fragmento del formulario de catalogación disponible en una instalación con el perfil de metadatos Dublin Core
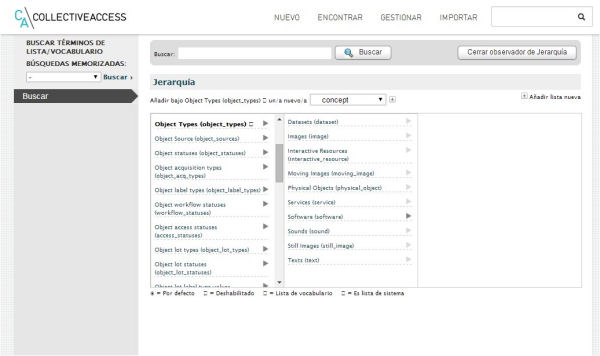
Figura 2. Editor de listas y vocabularios de CA
Los servicios subyacentes a estas funcionalidades y a otras disponibles out of the box son los de:
- Google Maps para la generación de mapas y la traducción de direcciones formateadas en coordenadas mediante la API de codificación geográfica de este servicio.
- El servicio de nombres geográficos GeoNames que integra búsquedas sobre esta base de datos geográfica y permite enlazarlos con los registros de CA.
- El motor de búsqueda Apache Solr, que se puede utilizar en lugar del motor de búsqueda basado en MySQL configurado por defecto.
- Los servicios web de la Library of Congress Subject Headings.
- Integración con Amazon S3 storage para replicar el almacenaje.
- Etc.
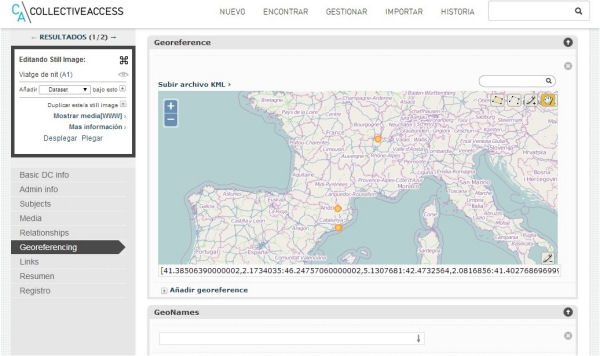
Figura 3. Servicio de georeferenciación y vínculo con GeoNames
CA también permite recolectar y exponer metadatos mediante el protocolo OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting).
2.2 El Pawtucket
Pawtucket es el componente encargado de proporcionar un frontend o interfaz pública al sistema. La plantilla por defecto es muy simple, pero adaptativa y totalmente personalizable mediante los archivos CSS y PHP.
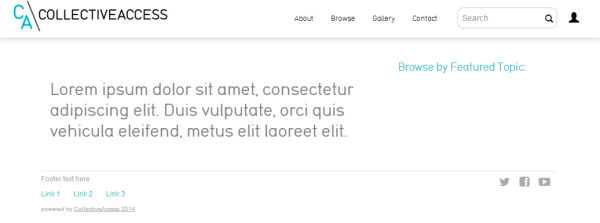
Figura 4. Página de inicio de la plantilla por defecto acabada de instalar
Como alternativa a Pawtucket se podría utilizar cualquier frontend capaz de obtener información de la base de datos del sistema.3 Prácticamente no existen experiencias en este campo más allá de un módulo para el sistema de gestión de contenidos Drupal,4 sólo compatible con versiones de CA anteriores a la 1.3, o algunos ejemplos de uso de Omeka como frontend para la aplicación. Un buen ejemplo de la convergencia CA/Drupal lo encontramos en el James Ensor Online Museum. En el caso de Omeka encontramos un par de ejemplos en los repositorios Religieus Erfgoed Online del Centrumvoor Religieuze Kunst en Cultuur de Bélgica y en el Het Virtual Land del Centrum Agrarische Geschiedenis del mismo país. Más allá de la integración con terceras aplicaciones, también se conocen experiencias con desarrollos propios, un buen ejemplo de las cuáles es el Philaplace de la Historical Society of Pennsylvania.
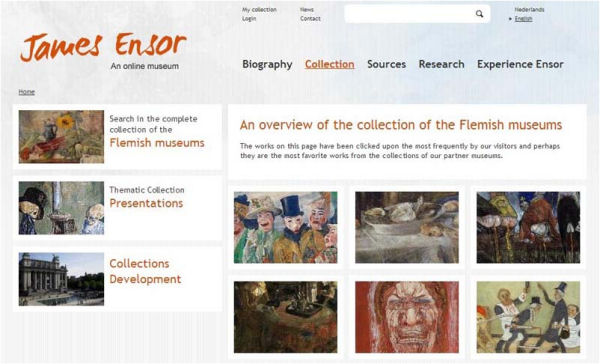
Figura 5. Página de inicio del James Ensor Online Museum

Figura 6. Página de inicio del Religieus Erfgoed Online
3 Instalación y requerimientos mínimos
3.1 Requerimientos mínimos
- Servidor HTTP Apache 1.3, 2.0 o 2.2.
- PHP 5.3.6 o superior (con los módulos mbstring, JSON, mysql, iconv, zlib, libXML, DOM, PCRE y Process Control).
- MySQL 5.0, 5.1 o 5.5 con soporte para tablas InnoDB.
3.2 Instalación y componentes adicionales
CA es un software multiplataforma desarrollado en PHP y que requiere de un entorno AMP (Apache, MySQL i PHP) para funcionar. Por tanto, en primer lugar debemos crear una base de datos MySQL y un usuario con todos los permisos en nuestro servidor. A continuación, podemos descargar el paquete de Providence desde el web oficial de CA o desde su perfil en GitHub. En la raíz de la aplicación encontramos un archivo llamado setup.php-dist que nos permitirá conectar nuestra aplicación con la base de datos que hemos creado anteriormente (véase la figura 7). Lo abrimos y editamos como mínimo las líneas 25, 29, 33 i 37, que se corresponden con el nombre de nuestro host, el nombre del usuario de la base de datos, la contraseña para este usuario y el nombre de la base de datos respectivamente. También podemos modificar la zona horaria (línea 84) o el idioma de la instalación (línea 116), entre otros aspectos. Una vez hemos editado el archivo, lo guardamos con el nombre de setup.php, subimos el paquete a nuestro servidor y cargamos el proceso de instalación accediendo al URL donde se encuentra la aplicación.
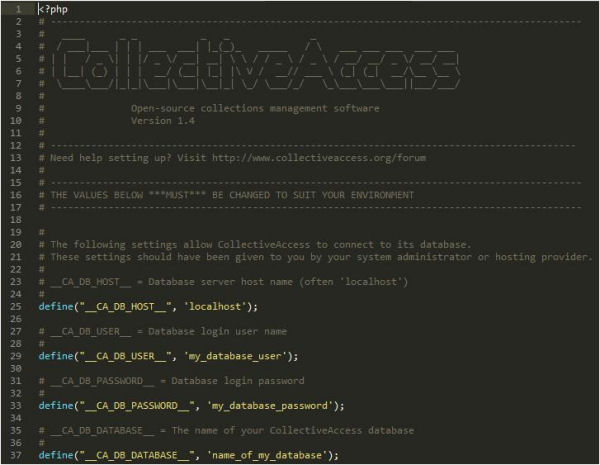
Figura 7. Detalle del archivo setup.php-dist
Después de finalizada la instalación, conviene eliminar el directorio install por motivos de seguridad.
Según el tipo de archivos con los que se quiera trabajar, CA necesitará otras bibliotecas de software o herramientas de soporte adicionales. Por ejemplo, si queremos trabajar con imágenes nuestro servidor deberá contar con ImageMagick o GDlibrary; en el caso que nuestro repositorio esté formado por archivos de audio o vídeo, necesitaremos FFmpeg; si queremos trabajar con PDF, quizá necesitemos herramientas como Ghostscript o PDFT o Text. La lista completa de bibliotecas que puede necesitar CA se encuentra en el wiki del proyecto.5
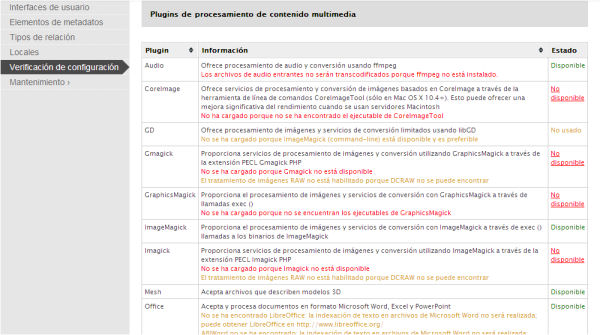
Figura 8. Desde la interfaz del sistema podemos ver qué bibliotecas tenemos disponibles en el servidor
Para instalar Pawtucket es necesario disponer previamente de una instancia de Providence. Una vez descargada la aplicación, debemos crear un subdirectorio dentro de Providence donde subiremos Pawtucket. Entre los archivos que forman esta otra aplicación, encontramos uno con el nombre setup.php-dist, como en el caso de Providence. También, como en el caso anterior, debemos editarlo, indicando los valores de nuestra base de datos. Las dos aplicaciones utilizan la misma base de datos y usuario. Una vez editado el archivo, ya podemos acceder a la interfaz pública a partir del nombre del directorio donde hayamos instalado Pawtucket (tipo: http://www.el-meu-web.cat/pawtucket). Para que Pawtucket pueda tener acceso a los archivos contenidos en el directorio media de Providence, debemos crear un enlace simbólico entre los directorios media de ambas aplicaciones.
4 Catalogación y estándares de metadatos
Los desarrolladores de CA prefieren definir su programa como un framework altamente configurable para la catalogación, ante otras definiciones como la de sistema de gestión de colecciones digitales. I es que CA nos permite escoger entre un amplio abanico de esquemas de metadatos o, incluso, crear uno completamente nuevo desde cero, así como definir los tipos de objetos digitales que formarán nuestro repositorio. Durante la instalación de Providence debemos escoger uno de los diferentes perfiles de instalación disponibles. Un perfil de instalación no es más que un conjunto de valores preconfigurados en un archivo XML, según las necesidades particulares de cada centro o tipo de proyecto. En el web de CA, en la sección Configuration Library, encontramos una selección de perfiles de instalación aportados por diferentes instituciones.6 No todos los perfiles disponibles pueden considerarse como modelos de buen diseño sino que, en muchos casos, se trata de configuraciones que responden a las necesidades de migración desde otro software o a unos requerimientos muy específicos que quizá no sean aplicables a otras situaciones. No obstante, estos archivos nos pueden servir para entender mejor la estructura y la sintaxis de este elemento tan importante. Si optamos por escoger uno de los estándares disponibles por defecto (Dublin Core, DACS, PB Core, SPECTRUM, etc.) simplemente tendremos que seleccionarlo en el momento de la instalación (véase la figura 9). En cambio, tanto si decidimos utilizar uno de los perfiles de ejemplo disponibles en el web de CA, como si creamos uno nuevo, lo deberemos importar al directorio install/profiles/xml, para que esté disponible en el momento de la instalación. Un perfil de instalación nos permite establecer, entre otros:
- Los elementos del esquema de metadatos, es decir, los diferentes campos de nuestro esquema (título, autor, fecha, etc.). Se pueden definir también los tipos de campo (texto, numérico, etc.) o el método de entrada de datos (formulario de texto, desplegable con una lista de valores, etc.), entre otros.
- Los tipos de objetos digitales y ocurrencias disponibles en el sistema.
- Los tipos de relaciones que se pueden establecer entre los diferentes objetos digitales (documentos, personas, lugares, etc.).
- Las interfaces de usuario que necesitamos para entrar los datos.
- Las listas y los vocabularios que nos permiten definir las listas controladas del sistema asociadas a los diferentes campos, los valores permitidos, etc.
Entre los perfiles disponibles actualmente encontramos algunos de los estándares de metadatos más comunes, como Dublin Core, SPECTRUM, VRA Core, PB Core, PREMIS o DACS, entre otros.
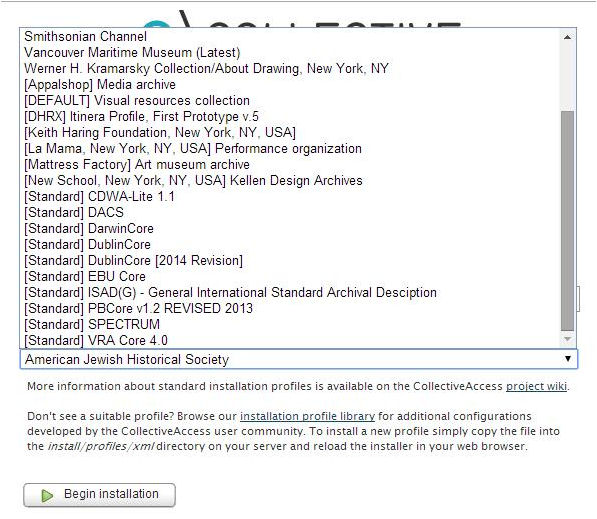
Figura 9. Perfiles de instalación disponibles con el paquete Providence 1.4
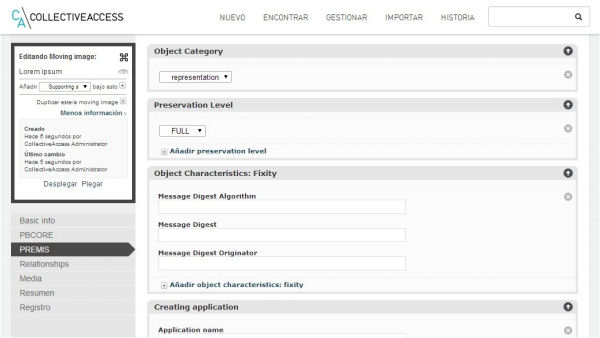
Figura 10. Formulario de entrada de datos del perfil de instalación de la Academy of Motion Picture Arts &Sciences de Hollywood, con los estándares de metadatos PB Core y PREMIS
Como hemos visto hasta ahora, CA se caracteriza por su gran flexibilidad a la hora de escoger la estructura de datos del sistema. La estructura general de la base de datos de CA presenta catorce entidades, aunque es posible añadir otras según nuestras necesidades (por ejemplo, para gestionar procesos internos como diferentes tipos de préstamo, restauraciones, etc.). Las entidades por defecto que encontramos en CA son:
- Los objetos digitales (objects) o ítems del repositorio (documentos de texto, imágenes, recursos interactivos, grabaciones sonoras, de vídeo, etc.).
- Las entidades (entities) o personas y organizaciones responsables de la creación, publicación, etc., de los objetos de la colección. Se pueden reutilizar en diferentes objetos, colecciones, etc.
- Lugares (places) o localizaciones físicas que se pueden reutilizar como las entidades.
- Ocurrencias (ocurrences) o eventos como exposiciones, publicaciones, estrenos, etc.
- Colecciones (collections) o grupos de objetos que comparten unas características comunes.
- Lotes (lots) que permiten agrupar conjuntos de objetos con características comunes, normalmente relacionadas con su procedencia, fecha de recepción, etc.
- Conjuntos (sets) o grupos de objetos definidos para un propósito específico. A diferencia de las colecciones que responden a grupos relacionados intelectualmente, en este caso se utilizan con propósitos operacionales como, por ejemplo, un grupo de objetos seleccionados para una exposición.
- Elementos de conjunto (set items) o registros asignados a un conjunto determinado que permiten añadir datos catalográficos adiciones.
- Representaciones (representations). Son archivos de imagen, de vídeo, de audio, PDF, etc., asociados a los objetos digitales. Un mismo objeto puede tener asociadas diversas representaciones o archivos.
- Lugares de almacenaje (storage locations). Las ubicaciones físicas donde se encuentran los objetos de la colección. Se pueden jerarquizar y tener asociadas restricciones de acceso, coordenadas y otro tipo de información.
- Listas (lists) que se puede utilizar para restringir el valor de un atributo, como vocabularios controlados asociados a los objetos, entidades, etc., y como listas del sistema, los valores de las cuales nos permiten personalizar CA.
- Elementos de las listas (list items). Cada una de las entradas que forman una lista.
- Eventos de los objetos (object events). Un evento en el ciclo de vida de un objeto (movimientos, acciones relacionadas con su conservación, préstamos, etc.).
- Eventos de los lotes (lot events). Un evento en el ciclo de vida de un lote.
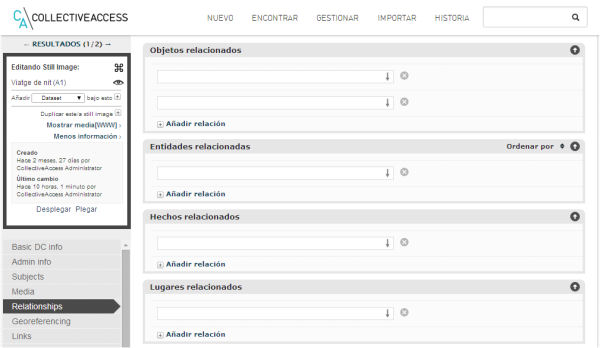
Figura 11. Formulario para establecer relaciones entre objetos, entidades, eventos y lugares
5 Gestión de usuarios
CA dispone de un interesante sistema de gestión de perfiles de usuario que permite establecer los permisos de cada tipo de usuario con un alto nivel de granularidad. Como administradores podemos crear tantos usuarios como sea necesario. Cada usuario puede pertenecer a uno o más grupos, que podemos crear de manera personalizada según nuestras necesidades. Cada grupo tiene asociado un perfil de acceso diferente, desde el cual se puede establecer qué acciones puede o no puede hacer (por ejemplo, configurar elementos de metadatos, exportaciones, crear nuevos grupos de usuarios, editar listas y vocabularios, etc.), y cuáles son los permisos (lectura, lectura y escritura o sin permisos) relacionados con los diferentes elementos de los esquemas de metadatos asociados a los objetos, las entidades, los lugares, las colecciones, los préstamos, etc.
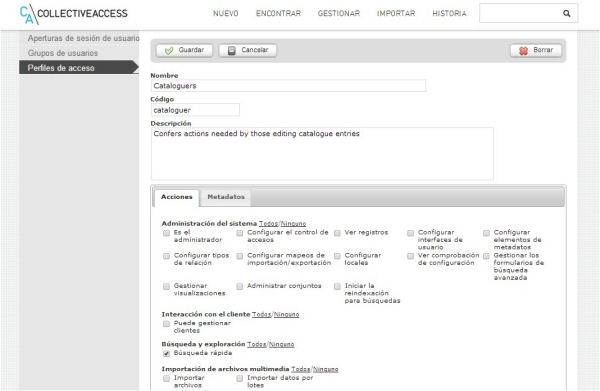
Figura 12. Fragmento de las acciones asociadas al perfil de acceso del grupo de usuarios "Cataloguers"
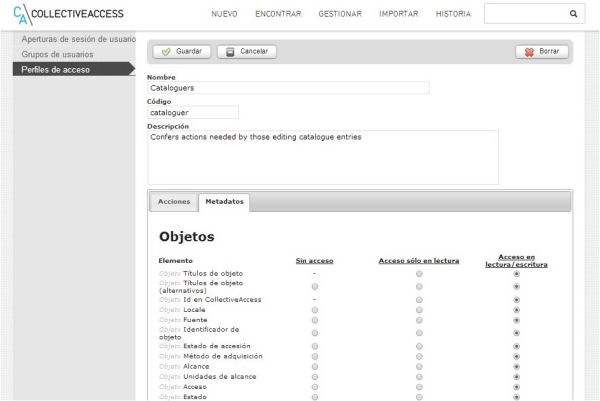
Figura 13. Fragmento de los permisos asociados a los elementos del esquema de metadatos
Desde esta misma interfaz, también podemos determinar las acciones disponibles para los usuarios que se registran en el sistema desde la interfaz pública, en el caso que utilicemos Pawtucket como frontend. Algunas de las acciones disponibles son la posibilidad o no de descargar archivos, compartir objetos a través del correo electrónico o las redes sociales, etc.
CA también permite establecer un control de acceso archivo a archivo desde la interfaz de catalogación del sistema (véase la figura 14).
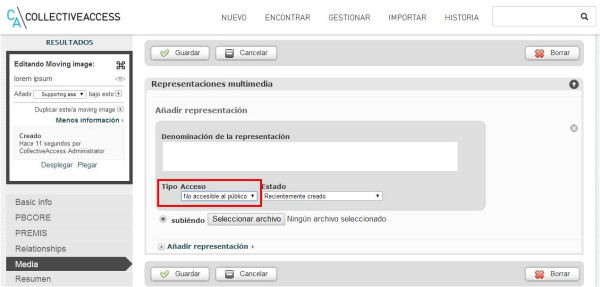
Figura 14. Cada archivo asociado a un objeto digital puede tener un tipo de acceso diferente
6 Localizaciones
Actualmente, CA se encuentra disponible en diferentes idiomas. La versión en inglés y la traducción al alemán son oficiales y están mantenidas por el equipo de traductores de Whirl-i-Gig. El resto de traducciones disponibles, entre las cuales el español, son obra de diferentes miembros de la comunidad de usuarios de CA y no están sometidas al mismo nivel de revisión. De momento no hay una traducción disponible en catalán. No obstante, abordar la traducción de la aplicación es relativamente fácil y no son necesarios demasiados conocimientos técnicos. Para disponer de una interfaz en catalán para Providence, debemos crear una carpeta con el nombre del nuevo idioma según la ISO-639-1 (ca, en el caso del catalán) bajo el directorio /app/locale. Para no empezar desde cero, podemos utilizar como modelo el archivo messages.po disponible en el idioma en_US. Mediante un programa de edición de archivos PO, como por ejemplo, Poedit, sólo tendremos que traducir cada una de las cadenas de texto disponibles. Una vez finalizada la traducción, guardaremos este archivo en el directorio citado anteriormente con el nombre de ca.po. También deberemos actualizar la línea 116 del archivo setup.php como se ha comentado en el apartado 3.2. Si lo que queremos es actualizar o mejorar la traducción al español, sólo deberemos acceder al fichero messages.po del directorio app/locale/es_ES y actualizarlo como hemos explicado anteriormente.
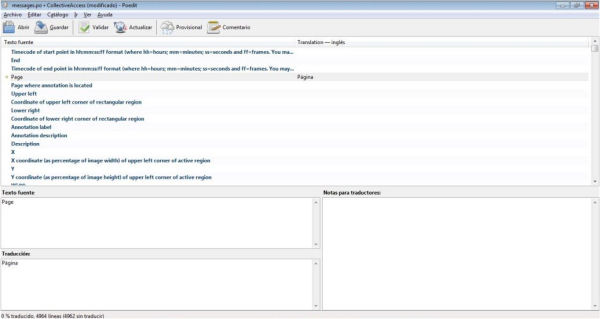
Figura 15. Interfaz de Poedit
Desde la sección Manage>Administration>Locales de CA, podemos activar el nuevo idioma para que esté disponible para calificar los valores de cada uno de los elementos del esquema de metadatos que utilicemos (por ejemplo,<dc:creatorxml:lang="ca">Nombre del autor</dc:creator>).
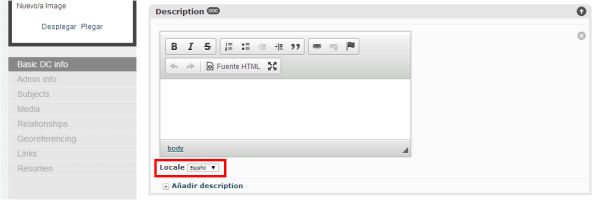
Figura 16. Una vez activados los diferentes idiomas desde la administración del sistema, los podremos seleccionar en las instancias de cada elemento del esquema de metadatos
7 Sitios web que utilizan CollectiveAccess
Entre los usuarios de CA encontramos principalmente instituciones norteamericanas. Algunos ejemplos representativos son el Queens Memory Project de la Queens Library de Nueva York, el New Museum's Digital Archive del New Museum y el Parrish Eastend Stories del Parrish Art Museum de la misma ciudad, el Van Alen Institute's Design Archive del Van Alen Institute, o el repositorio del Jewish Museum de Praga.
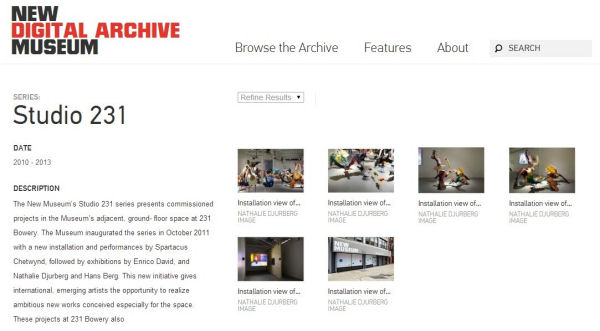
Figura 17. New Museum's Digital Archive

Figura 18. Página dedicada a Mary Abbott en el Parrish East end Stories
En nuestro territorio encontramos la Kutxateka, de la Obra Social de la Kutxa, como ejemplo más representativo. Se trata de un portal que recoge los diferentes fondos fotográficos de la entidad, así como algunas obras de arte. De momento, se pueden consultar los fondos fotográficos de Fotocar y Marín, dos colecciones que reflejan el desarrollo social, político y cultural de Guipúzcoa desde principios del siglo xx hasta nuestros días.
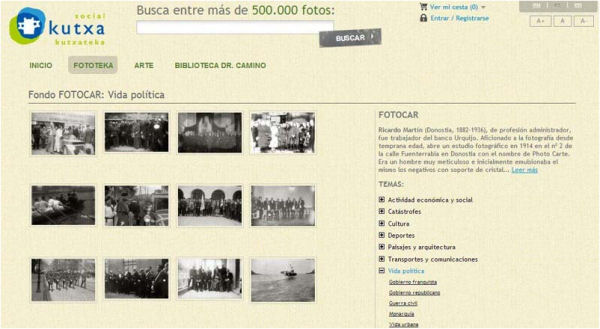
Figura 19. Detalle de la colección Fotocar de la Kutxateka
En la sección Clients dentro del web de CA encontramos una lista de más de cien ejemplos de implementaciones, organizada según el tipo de institución (museos, bibliotecas, instituciones académicas, etc.).
8 CollectiveAccess y sus competidores
Actualmente disponemos de una gran cantidad de soluciones de software libre para gestionar colecciones digitales y crear repositorios y portales para difundir el patrimonio de archivos, museos y bibliotecas. Dejando a un lado las soluciones propietarias, destacan Dspace, Eprints e Invenio en el ámbito de los repositorios institucionales, ICA-AtoM (o el actual AtoM)7 y Archon por lo que respecta a los fondos y colecciones de archivo, Fedora Commons y sus derivados (Islandora e Hydra) para repositorios que requieren un alto grado de exigencia y personalizaciones y, finalmente, un conjunto de aplicaciones centradas especialmente en la comunicación de las colecciones y la creación de productos de valor añadido, entre las que destaca Omeka.
CA se encuentra a medio camino entre algunas de estas aplicaciones. Por sus características, su competidor principal en el ámbito de las bibliotecas y los museos lo encontraríamos en Omeka y, en el caso de las instituciones de archivo, en ICA-AtoM. La posibilidad de integrar cualquier esquema de metadatos y su capacidad para gestionar diferentes tipos de archivo, hace que el sistema sea interesante para cualquier tipo de proyecto o institución, incluso para aquellas que disponen de diferentes colecciones especiales y necesitan un sistema que les permita describir cada tipo de fondo según su propia normativa, pero ofreciendo un punto de acceso único. Esto supone un modelo mucho más integrador que el que estamos acostumbrados a ver en los proyectos de nuestro territorio (Estivill, 2008).
En comparación con Omeka, resulta relativamente más fácil integrar diferentes esquemas de metadatos en el sistema. En parte, porque los ficheros de configuración de los lenguajes principales ya están disponibles. La gestión de usuarios y la posibilidad de personalizar la aplicación también son superiores. Por su parte, Omeka presenta una curva de aprendizaje menos pronunciada para el usuario administrador y ofrece un mayor conjunto de herramientas para crear nuevos productos documentales como por ejemplo, exposiciones virtuales, líneas de tiempo o mapas, módulos que, además, resultan más fáciles de instalar.
Por lo que respecta a ICA-AtoM, se trata de un sistema centrado en la descripción y acceso fondos y colecciones de archivo. El hecho de tratarse de una aplicación tan especializada limita su mercado, pero a la vez, la puede hacer más atractiva para instituciones de archivo que quieren una aplicación de estas características y no cuentan con los conocimientos necesarios para personalizar CA.
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
History and New Media, Department of History and Art History de la George Mason University. |
|
|
|
|
|
|
|
|
|
|
|
|
|
Búsquedas facetadas de serie. |
|
|
|
|
Exportación en EAD, DC, MODS i SKOS. |
Otros esquemas a través de plugins que requieren desarrollos propios. |
|
|
|
|
|
|
|
Exportación: XML, MARC21 y CSV |
|
Exportación: XML, JSON, Atom y RSS2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Tabla 1. Comparativa entre CA, AtoM y Omeka
9 Conclusiones
CA destaca por su gran flexibilidad a la hora de diseñar un sistema a medida para gestionar nuestras colecciones digitales. Salvando las distancias y con otras tecnologías en su arquitectura, nos recuerda a Fedora Commons por la capacidad de integrar diferentes esquemas de metadatos, tipos de objetos, relaciones, usuarios, etc. Esta gran flexibilidad también supone un mayor tiempo de configuración previo a la instalación y puesta en marcha del sistema y requiere de unos conocimientos mínimos de XML y de la estructura interna de la aplicación. Es importante destacar, eso sí, que por defecto encontramos muchas configuraciones disponibles que pueden servir perfectamente a la mayoría de centros de nuestro entorno.
Por lo que respecta a los requerimientos, CA se trata de un sistema interesante tanto para pequeñas instituciones, como para las grandes ya que, en la línea de otras aplicaciones como Omeka, resulta fácil de instalar y mantener pero, al mismo tiempo, es suficientemente escalable como para abordar grandes proyectos.
Bibliografía
CollectiveAcess documentation (2014). <http://docs.collectiveaccess.org/>. [Consulta: 28/05/2014].
Estivill, Assumpció (2008). "Els fons i les col·leccions d'arxiu a les biblioteques: models per al seu control i accés". BiD: textos universitaris de biblioteconomia i documentació, núm. 21 (desembre). <https://bid.ub.edu/21/estiv2.htm>. [Consulta: 26/06/2014].
Higgins, Jessica [et al.] (2012). "Enhancing educational access to art". 2012 Conference on Digital Libraries. <http://hdl.handle.net/2249.1/57161>. [Consulta: 25/06/2014].
Pedersen, Isabel; Baarbé, Jeremiah (2013)."Archiving the 'Fabric of Digital Life'". IEEE International Symposium on Mixed and Augmented Reality - Arts, Media, and Humanities (ISMAR-AMH).
Rehberger, Dean (2013). "Getting oral history online: collections management applications". Oral history review, vol. 40, no. 1 (Winter-Spring), p. 83–94.
Spiro, Lisa (2009). Archival management software: a report to the Council on Library and Information Resources. Washington, D.C.: Council on Library and Information Resources. <http://www.clir.org/pubs/resources/reports/spiro2009.html>. [Consulta: 24/05/2014].
Notas
1 GNU General Public Licence. Version 3, 29 June 2007. <http:/ /www.gnu.org/copyleft/gpl.html>. [Consulta: 23/05/2014].
2 La lista completa de formatos de archivo admitidos se puede consultar en: http://docs.collectiveaccess.org/wiki/Supported_Media_File_Formats.
3 En la sección Getting data de la documentación oficial se explican los diferentes métodos para acceder a la base de datos: http://wiki.collectiveaccess.org/index.php?title=API:Getting_Data.
4 Se puede descargar desde: https://drupal.org/project/collectiveaccess.
5 Lista completa de bibliotecas adicionales: http://wiki.collectiveaccess.org/index.php?title=Installation_(Providence).
6 Disponible en: http://www.collectiveaccess.org/configuration.
7 AtoM (Access to Memory) es un sistema de gestión de fondos de archivo desarrollado por Artefactual Systems, los mismos responsables de ICA-AtoM, a partir de les primeras versiones de esta aplicación. Más información en: https://www.accesstomemory.org/es/.
 licencia de Creative Commons de tipo "
licencia de Creative Commons de tipo "