
The NewsAgent alerting service
[versió catalana]
Clara Baiget
LITC, South Bank University
baigetc@sbu.ac.uk
Abstract
NewsAgent for library and information professionals is an Internet-based Selective Dissemination of Information (SDI) service for library and information professionals alerting them of news relevant to their professional interests.
1 Introduction
There is now almost too much information on the Internet confronting potential users with alarming difficulties in locating relevant information and thus effectively overwhelming them. The NewsAgent <http://newsagent.sbu.ac.uk> Project was based on the simple idea of creating a system which could filter information on behalf of end users so as to avoid information overload and provide more focus to their information discovery, i.e. it is an SDI (Selective Dissemination of Information) service.
From the outset the NewsAgent concept was specifically designed to address the needs of library and information professionals. Users are able to set up a profile describing their professional interests and the NewsAgent system will automatically search for relevant news and/or scholarly items and post alerts to their email account at a user defined frequency. The system was established two years ago and there has been further refinement since then; it now has a user base of 800.
The initial development was through a research project funded by the UK government under the Electronic Libraries Programme <http://www.ukoln.ac.uk/services/elib/> (eLib). It has become established as a viable service as demonstrated by user opinion: the project is now reaching its final phase where its future viability and continuity will need to be analysed. In principle the project partners want to continue its operation - however the financial basis for this is still unclear.
Two of the major project themes of NewsAgent have been experimentation with intelligent agents or harvesting software with search and retrieve systems.
2 eLib Programme
eLib was a JISC (Joint Information Systems Committee) programme. JISC itself is funded by the Higher Education Funding Councils for England, Scotland and Wales to “promote the innovative application and use of information systems and information technology in Higher and Further education across the UK” <http://www.jisc.ac.uk>.
eLib was set up in 1994, as FIGIT, in order to support libraries as they adopted IT. In 1999 the programme officially finished (no more new projects started), though those already approved continued to work into 2001. eLib was involved in more than 70 projects eLib <http://www.ukoln.ac.uk/services/elib/projects/>, costing in excess of £20M. These had to have a finite funded life of up to 3 years, after which time they had to become self-sustaining. In the case of NewsAgent we are still studying the available funding options.
3 NewsAgent project
3.1 Aim
Designed to combat information overload, NewsAgent's aim was to build an information filtering service which would accurately match user interests and news, new publications etc. Information would be gathered automatically using a harvesting system to select and classify the content automatically. The results of that process were then to be stored in a database and subsequently emailed to the user desktop through standard email service.
Though NewsAgent is primarily an alerting service, a retrospective databank of resources discovered can also be searched.
3.2 Phases
First phase – 1st April 1996 to 31st March 1998The first phase involved:
- deciding what the project had to be,
- evaluation by eLib programme
- and obtaining the economic support to finance it.
A consortium was created to distribute tasks, and the main institutions involved in its development were:
- LITC <http://www.sbu.ac.uk/litc/>, South Bank University, Londres.
Project co-ordinator and content provider
- Centre for Research in Library and Information Management (CERLIM) <http://www.mmu.ac.uk/h-ss/cerlim/>, Manchester Metropolitan University.
Evaluation
- Dept. of Information and Library Studies <http://www.dil.aber.ac.uk/>, University of Wales, Aberystwyth.
Editorial co-ordinator
- Fretwell-Downing Informatics Ltd. <http://www.fdgroup.co.uk/fdi/company/>, Sheffield.
Technical development
- UKOLN <http://www.ukoln.ac.uk/> (UK Office for Library and Information Networking).
Technical development, networking, content providerConstant evaluation characterised this period, defining the service and requirements, based on the user needs. The consortium took part in concertation activity concerning metadata developments, which were considered very important for the project.
In July 1998 the project was approved, and then began the interim phase.
Interim phase – 1st April 1998 to 31st July 1998The service started as soon as was approved, with real users, but there was a warning displayed to those accessing the service saying “this is a trial service that is currently under development”.
During this period the intention was to identify all problems that could appear during the second phase. Technical aspects, such as Boolean query formulation and Web-based profile editing, were solved. But other problems persisted – for example, users that got alerts twice while others did not get any. This problem appeared to be related to maintenance procedures of the system's Oracle database.
The aim was to begin the second phase in August 98 as far as possible at full steam. But because of the lack of funding for full technical support from Fretwell-Downing Informatics Ltd, it was not possible to determine the full nature of the problem or to effect a solution, and service to the pilot trial users (less than 200 individuals) was unavoidably affected adversely.
A key decision taken was to drop the creation of a Z39.50-based, fully Distributed Virtual Content Store (VCS) from the NewsAgent for Libraries project. The limited funding available, which was less than had been requested, was a major reason for the decision. However, it was also felt that such work was unnecessary for the foreseeable commercial environment for LIS alerting services, and likely to divert valuable effort away from higher priority development tasks.
In making the decision, it was recognised that Fretwell-Downing might nevertheless choose to develop such a capability for their own commercial reasons, or for other alerting projects. The project also recognised that it should be able to simplify authentication/authorisation and administration by using a single content store, which could be managed on a distributed basis. Furthermore, it seemed likely that it could be able to develop a Z39.50 robot or data gathering capabilities so that data such as new book titles held in remote Z39.50 servers could be made accessible to the NewsAgent store. This meant that services such as BUBL could be integrated with NewsAgent without development of a network of fully distributed servers which might add to management costs.
Second phase – 1st August 1998 to 31st March 2001A full Business Plan was prepared and submitted to eLib for the second phase, containing financial information and a risk assessment. Detailed planning has been revised annually, to reflect at least financial, technical and commercial circumstances.
Although the project had JISC funding, its commercial potential was also identified in the project. The desirability of, and prospects for, attracting commercial sponsorship and marketing assistance were examined, since it was felt that the project could well face steep competition in the marketplace for information in the future. As such, a collaborative venture was considered as having a better chance of success.
After the interim phase the focus shifted to how to improve the service, mainly by targeting technical aspects. Examples are: an analysis of mechanisms that allow information providers to specify which files are visited by the NewsAgent robot, and enhancement of the Web interface to emphasise registration and profile modification functions.
The number of users did not increase during the first 20 months, but since April 2000 it has been constantly rising. In just one month user numbers went from 110 to 240, and then to 600 in October. Currently there are more than 800 users.
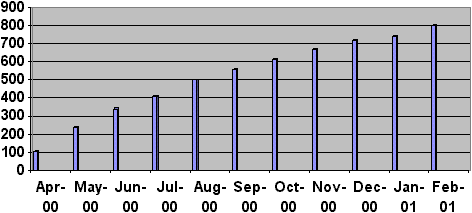
Graphic 1: User evolution
There has not been any marketing campaign to promote the service, but it has been reported in a few mailing lists, among them, IweTel <http://www.rediris.es/list/info/iwetel.html>. Although news items are in English, interest is not limited to the Anglo-Saxon world.
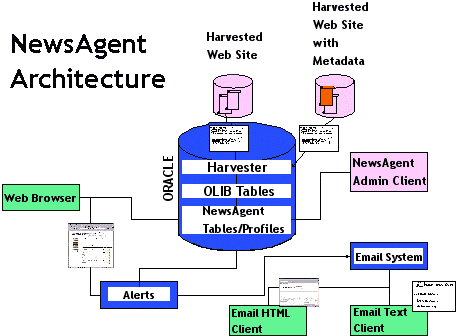
3.3 Structure of the system
To fully address the aim of the project, a complex technical structure was designed. The harvester, originating in Edinburg University, is the tool used for automatically identifying new material, processing it, sending it out and adding it to the NewsAgent database. The system administrator defines which sites for it to visit and how deeply into them to search.
Nightly, the harvester checks to see if there has been new material added, and if so, it reports back to the administrator with formatted information. It harvests the title of the page as the title for the resource. And if there is appropriately formatted metadata, e.g. about the author or the subject matter of the page, it too is harvested. Thus interesting sites can be regularly monitored, and if the metadata is available, it can be put into the NewsAgent database and the news —matched to users' profiles— sent.
Fretwell Downing installed NewsAgent on a Sun server housed at South Bank University. The backend database is SQL (Oracle) and most of the software is written in Perl.
Aberystwyth originally designed the metadata and the controlled vocabulary.
The NewsAgent system consists of five main parts:
- Harvesting of defined web sites
- Email harvester
- Html client web view
- VDX windows admin client
- Mail alert
3.4 Formats
News alerts consist of two types of items: web resources from the Internet and emails from mailing lists. The management process varies according to the item's format. Material is obtained from:
3.4.1 Web resources
- Harvested web sites from a directory (web resources)
- Manually added web resources
- Subscribed to mailing lists (emails)
Web resources are identified as “World Wide Web (WWW) Page” on the web site. These include articles, reports, news, etc.
A list of URLs were selected as permanent interesting resources. These were to be monitored continuously by NewsAgent, which would be programmed to harvest them.
By means of an agreement with the information providers, the web pages of articles have metadata tags in the 'head' HTML section, classified according the NewsAgent Metadata Design. The Classification Scheme was designed and maintained by Aberystwyth University until 31st March 1998 only. After that time, content management was carried out entirely by LITC.
The 1998 pilot included the following journals as permanent information sources: Program, Vine, Library Technology, Ariadne, and the Journal of Librarianship and Information Science. Additional news and briefing materials (from organisations such as The Library Association, UKOLN, the British Library, and LITC) were included in the latest version of NewsAgent that began signing up users in February 2000.
Daily, harvested web sites were temporarily stored in a file which contained metadata describing the news picked up (theoretically with some keywords added): title, abstract, author, publication (title of the journal), keywords and type of resource (it is always www pages). The file could be modified through a telnet connection (to add keywords if necessary, to add news, to delete duplicates, etc.), managed by the Unix System. Then this information was filtered by the system during the night, and subsequently sent to users.
Harvesting information automatically proved unsuccessful: partly because very few sites provide sufficient metadata; partly because information providers do not always keep new items as a single page with its own metadata. If material is added to one long page, the harvester sees that the page has changed but cannot pick up subject metadata. Inefficiencies were also noted in the implementation of the harvester; it registered as new pages items that had only been edited, or slightly amended by the publisher. This led to the system pulling pages that had not changed. Harvesting was not always very effective therefore. Running the system certainly requires considerable manual intervention.
NewsAgent started as a research project, but in the end, it has prioritised the service and its functionality, to provide a quality service. In October, after months of getting news that was not very relevant (such as old material or the same news picked up every day for a week, etc.) it was decided to stop harvesting and to perform the selection of all news items manually. That would be the most effective way to select them from the Internet, because the harvesting system did not reduce work, but rather generated more. This decision was also affected by the lack of sufficient technical support and budget at that moment.
This change did not modify the structure of the system. The way to select Internet resources became manually, and it is still the way we are doing it. We are subscribed to Mind-it <http://mindit.netmind.com/>, a “personal web assistant” that notifies you of relevant changes to the web sites that you are interested in. This is an easy way to know when a new journal issue appears that we index for NewsAgent as well as for institutional web sites that have news or press releases. Resources that we normally describe in our alerts are listed at our web site <http://newsagent.sbu.ac.uk> (see “Help”, “Resources”).
This important change was followed by the acquisition of Arachnophilia 4.0 to facilitate the description process of Internet news items. Previously the administrator had had to use Unix's utility to edit data files, which is scarcely user friendly. The Unix System is quite inflexible and it works with many commands, while Arachnophilia 4.0 is used as word processing software, and allows greater flexibility.
3.4.2 EmailsAll emails sent through NewsAgents are from mailing lists.
Dealing with email news was quite manual, and in consequence, the result was more accurate. Subscriptions to mailing lists were with the server account, but before news items were sent to users, there was the possibility of modifying them or deleting those messages greeting or thanking people through VDX software.
All daily messages were processed by the system, and converted into web pages. But VDX (from Fretwell-Downing) was inconvenient in that it was not possible to view the whole message, just the first line, and this made selection difficult. In order to see the text of the message, the emails had to be opened from Macromedia Dreamweaver 3.0 (which deals with emails as web pages).
To improve on this, in September it was decided to move all subscriptions to a new email account that would work as an intermediate step to select relevant emails. This is the way that emails are currently processed. These are downloaded in Netscape, where it is possible to read the whole text. Only the interesting ones are then sent to the server account.
Forwarded emails result in a poor presentation, which is why the preferred method is to send them is by copying and pasting. Messages are sent as plain text (there is an option to predetermine it) to reduce the resulting “gibberish” which could appear at the top of the Web page (and description). If sent as HTML, it links up all of the URLs on the email submitted within the generated Web page.
The Subject field from the original email is cut and pasted as the subject of the new message, but if the original title is not clear, or does not use the NewsAgent controlled vocabulary, some keywords are added in brackets. The text messages of the new email starts with the information relating to the original message -- Date, From, To – followed by the message itself.
Finally, URLs in the plain text message have to be coded into an HTML format to activate them as Web pages using: <a href=“URL”>URL</A>
3.5 Retrieval information
NewsAgent for library and information professionals is mainly an SDI service where users periodically receive news according their profile, but it is also possible to search on news that has been stored as a database accessible from our web site. 3.5.1 Getting the alerts by email
News alerts are sent to users by emails, consisting of lists of resources classified under topics defined by the users in their profiles. All resources have a title (with emails the subject line becomes the title of the record) a URL and a description (first few lines of the message with emails).

3.5.2 Searching the databaseInternet resources are stored indefinitely in our database, and are searchable from our web site. Emails are stored just for 30 days, after which they are deleted from the database (to create space in the server's memory), and are not retrievable any longer.
All issues processed and sent have keywords added manually, using the NewsAgent controlled vocabulary to ensure precision of retrieval. That is why we strongly recommend users to use our vocabulary when describing their profile or searching in our database.
Searches are possible under the following fields: title, URL, keywords, record type, and import date.
Another important aspect when searching in our database is to use both title and keyword fields, because the only method of searching email messages is through their title, but with web resources it can be by title (less recommended) or keyword.
Finally, Boolean commands consist of “begin with”, “contains”, “is”, “is not”. The most recommended one is “contains”, because it keeps the search from being too narrow.
4 Evaluation
This project has been an interesting opportunity to experiment with intelligent agents or harvesting software with search and retrieve systems, metadata and in general with how to run an information alerting service. By looking at other news services, we learned much about what type of system is possible/desirable, even though we did not have the financial resources to put it into effect.
From the content angle, it has been very interesting to discuss the scope that the news had to cover and to identify relevant information resources, as well as mailing lists. Every day there is an avalanche of information –such as journals that are constantly setting up new issues-- and we receive an average of nearly 200 emails per day. Then, confronted by this overload of news and with time restrictions of time (just 4 hours per day destined to the service), relevant information has to be selected and processed.
The concept of NewsAgent is good: users feel overloaded with information and want relevant information delivered to their desktop. The service offers a flexible system of carefully structured controlled channels, with self constructed searches.
Without much promotional activity (we didn't want to get a massive user base which would then be disappointed if, say, we started charging for the service) 800 people joined, and are by all appearances enthusiastic about it. Many users mail us to say that NewsAgent is a very useful service. In fact, there have been several messages sent to mailing lists recommending NewsAgent. Recently CERLIM sent a questionnaire to users to evaluate the service (as part of the conclusion of the project), but the results are not yet available.
Although alerting was to be the main priority, in reality the database of past items is a valuable tool, too.
But there are two fundamental obstacles to running NewsAgent optimally. The first one is related to metadata. Most sites do not put much metadata on their material. They do not have a new page for each new item (for example, they may present a list of full text press releases all on a single page). This prevents Newsagent from harvesting it. A lot of data entry was manual, which had not been intended. It was hoped that we could encourage news providers to add metadata in a suitable form to their services but clearly this is very difficult to do.
The second obstacle is that we could not bring the software to the level of usability and reliability necessary to sustain a service. Being based on Unix/Oracle — rather than local standards—high level skills were required to maintain it.
The intention of phase two of the project was to take NewsAgent on to be a self-funding service. Although there was interest in banner advertising and sponsorship on a small scale, we are still investigating what level of service can be sustained from these funds. The alternative was to sell subscriptions. Our research suggested that there would not have been enough subscribers to sustain the service - partly because there are so many free services on the Web. We also lacked the technical infrastructure to administer access control.
NewsAgent is a good example of an information service using IT. It is very useful when it works, and seems to confirm the assertion that librarians should have IT skills in order to become more self-sufficient.
5 Bibliography
— NewsAgent reports— Internet resources
- Annual Report 1997 to eLib: NewsAgent for Libraries, April 1996-July 1997, July 1997.
- Butters, G. Evaluation Questionnaire, November 2000.
- Cox, A. NewsAgent for library and information professionals annual report 2000, December 2000.
- Lewis, E.; Butters, G. Nicholls, P. NewsAgent for libraries annual report 1999: a report covering August 1998 to July 1999, September 1999.
- NewsAgent Topic Classification Scheme [online], February 1998 <http://users.aber.ac.uk/emk/topics.htm> [Consulted: February 2001]
- Paschoud, J.; Neal, K. Personal Information Environments and Push Technology, 2000.
- Proposed metadata elements [online] <http://www.ukoln.ac.uk/metadata/newsagent/metadata/> [Consulted: February 2001]
- Yeates, R. Phase 1 final report: a report covering April 1996 to March 1998, July 1998.
- Yeates, R. NewsAgent for libraries annual report 1998: a report covering August 1997 to July 1998, July 1998.
— For more information on metadata
- DNER Programme [online] <http://www.jisc.ac.uk/dner/> [Consulted: February 2001]
- eLib Programme [online] <http://www.jisc.ac.uk/elib/history.html> [Consulted: February 2001]
- Powell, A. “NewsAgent for libraries: notes on the use of Dublin Core” [online], February 1998. [Consulted: February 2001] <http://www.ukoln.ac.uk/metadata/newsagent/dcusage.html>
- Rusbridge, C. "Towards the Hybrid Library" [online], D-Lib Magazine, July/August 1998 <http://mirrored.ukoln.ac.uk/lis-journals/dlib/dlib/dlib/july98/rusbridge/07rusbridge.html> [Consulted: February 2001]
- Rusbridge, C. "After eLib" [online], Ariadne, Issue 26, January 2001. <http://www.ariadne.ac.uk/issue26/chris/> [Consulted: February 2001]
- Dublin Core [online] <http://dublincore.org/> [Consulted: March 2001]
- UKOLN Web site with projects, resources, initiatives and registries [online] <http://www.ukoln.ac.uk/metadata/> [Consulted: March 2001]
- The Metadata Engine Project (METAe) [online] <http://meta-e.uibk.ac.at/> [Consulted: March 2001]