Resum [Abstract]
Objectius. Les relacions tenen uns efectes notables, però mal entesos, sobre com es representen, s'estructuren i es processen els objectes d'informació en ambients computacionals. Aquest article presenta una investigació preliminar i un enfocament innovador sobre el problema de les relacions en el context del discurs arxivístic.
Metodologia. S'examina com les eines ontològiques i tècniques d'anàlisi de continguts poden ser adaptades i millorades per ajudar els investigadors a identificar, captar i classificar les relacions expressades en les descripcions d'imatges. S'ofereix una visió addicional a partir de l'examen de les relacions des del punt de vista de tres contextos de descripció diferents: cercadors d'imatges, conservadors i catalogadors. S'analitza la naturalesa de les dades de la mostra, incloent-hi com es validen i com se'n determina la fiabilitat.
Resultats. Es tenen en compte les limitacions d'investigacions anteriors sobre relacions i s'introdueix una metodologia nova dissenyada per ajudar els investigadors a predir amb eficàcia les relacions que ocorren en les descripcions textuals.
1 Introducció
Aquest document presenta una investigació preliminar portada a terme com a part de la tesi doctoral de l'autor sobre el problema de les relacions. Es tracta d'un estudi de viabilitat dissenyat per avaluar els beneficis i les dificultats de l'ús de tècniques d'anàlisi de continguts i d'eines ontològiques per recollir exemples de relacions i després classificar-los en famílies de tipus de relacions.
Les relacions són associacions entre dues o més entitats o classes d'entitats (Green, 2001, p. 3). Són la cola que manté units els conceptes i els significats de les paraules. Tot i que les relacions tenen un paper important en la manera com els éssers humans expressen les seves idees, se sap molt poc sobre com cal recollir, representar, estructurar i processar eficaçment la informació sobre les relacions en contextos computacionals. Per tant, és raonable, en aquest moment, formular algun tipus de metodologia per descobrir i estructurar la informació sobre les relacions, sobretot si tenim en compte que cada cop es confia més en les màquines perquè llegeixin quantitats ingents d'informació mesurada en termes d'exabytes i zettabytes i hi donin sentit com si fossin éssers humans.
Aquest document s'adreça a dues audiències àmplies. En primer lloc, s'introdueixen les eines i una metodologia per a investigadors en biblioteconomia i documentació que estudiïn el problema de les relacions en les descripcions d'imatges. Tot i que el mètode aplicat no intenta implementar computacionalment cap tipus nou de maquinària descriptiva, proporciona el marc per construir un corpus de dades de tipus i d'exemples de relacions que condueix, d'una manera natural, al pas següent possible: una representació, basada en ontologies, de continguts d'imatges en sistemes basats en el coneixement. En segon lloc, la metodologia que es descriu es pot adaptar a altres àrees problemàtiques relacionades amb la comprensió del llenguatge natural i la representació basada en ontologies. Aquestes àrees podrien ser des d'una descripció arxivística general, fins a àmbits més confusos, com ara les cultures que creuen en déus del Sol. Sigui quin sigui el cas, aquest document emfatitza la utilitat de fer servir investigacions preliminars per solucionar els innombrables problemes en l'enfocament analític de continguts abans de començar el cos principal de la recerca.
Aquest document consta de set apartats, que segueixen aquesta introducció. En el primer, s'hi estudien les limitacions d'investigacions prèvies sobre relacions en la bibliografia de biblioteconomia i documentació. Els apartat següents expliquen la mostra de dades i la metodologia de la investigació aplicada, i la construcció d'un corpus de relacions. L'apartat 6 descriu com es validen les dades i com se'n determina la fiabilitat, i l'apartat 7 presenta conclusions i limitacions interessants de l'estudi. Finalment, en l'apartat 8 es presenten les conclusions finals.
2 Esforços previs
En aquest apartat s'exposa la interessant activitat intel·lectual evident en la bibliografia de biblioteconomia i documentació que tracta de les relacions i el paper que tenen en l'organització de la informació, especialment la informació visual expressada en les descripcions d'imatges. Hi ha molta bibliografia dedicada a anomenar i classificar atributs i primitius visuals, però molt pocs estudis empírics intenten explicar les relacions existents en les descripcions d'imatges, de manera que el potencial de les contribucions de la biblioteconomia i la documentació a aquest debat podria ser considerable.
La bibliografia més primerenca d'aquesta revisió bibliogràfica demostra que les relacions i la seva classificació són importants per crear associacions entre els documents i els conceptes dins dels documents. A partir de la dècada de 1980, Farradane (1980 a i 1980 b ) va presentar un esquema que consta de nou categories de relacions, que s'aplica a l'anàlisi de documents textuals. Tot i que dibuixava distincions importants entre els conceptes i les relacions, en general, no feia una distinció clara entre els problemes de processament del llenguatge natural i la noció de representació simbòlica. Això va donar lloc a problemes en la seva anàlisi respecte de com calia representar les ambigüitats dels termes, per exemple, els múltiples significats de la preposició anglesa of.
El passat ha estat testimoni de molts estudis sobre el problema de les relacions amb relació a les entitats externes a la semàntica del contingut del document. Shatford Layne va estudiar les relacions que hi ha entre els objectes en imatges en diferents formats i entre les imatges i els documents textuals relacionats. Alguns exemples inclouen les relacions entre les fotografies d'edificis, els plànols arquitectònics corresponents i les biografies dels arquitectes (Shatford, 1986; Shatford, 1994). Enser i McGregor (1993) van ser els primers investigadors a prestar l'atenció merescuda a les descripcions d'imatges tal com les expressa l'investigador d'imatges. El seu interès pel problema de les relacions, però, se circumscriu a les relacions entre els tipus d'usuaris i les relacions entre les categories generals d'imatges, que van definir com a úniques i no úniques.
Keister (1994) va fer l'observació crítica que les descripcions d'imatges riques semànticament que es troben en les consultes dels cercadors d'imatges, com ara "l'home assegut a la cadira amb la capsa al cap", no podien ser representades eficaçment pels catalogadors que usen sistemes d'indexació basats en paraules. Aquesta investigadora no va oferir solucions immediates a aquesta qüestió, però les seves observacions suggereixen, de manera evident, que el problema de les relacions fa referència, en part, a representacions i processos; és a dir, com podrien els catalogadors representar expressions semànticament riques en sistemes d'informació de manera que els investigadors poguessin trobar les imatges que volen. Malgrat aquestes revelacions, els investigadors van continuar considerant el paper de les relacions dins de l'estructura sintàctica de l'oració i van intentar recollir aquest significat en els sistemes d'indexació.
Es va produir un canvi important en el pensament quan Svenonius (2000) va plantejar la idea d'utilitzar les relacions per raonar els conceptes. Aquesta investigadora es va imaginar màquines capaces de llegir documents i determinar categories temàtiques (Svenonius, 2000, p. 49). Green (1996) i Bean i Green (2001) van compartir punts de vista similars i van començar a explorar com el raonament sobre les relacions podria millorar el procés de descobriment i permetre als usuaris descobrir informació que, altrament, passaria desapercebuda. Tanmateix, Green va argumentar que el nombre i la complexitat dels tipus de relacions feia impracticable aquesta tasca, i esperava que professionals de la informació poguessin aplicar d'una manera coherent i eficaç relacions en sistemes d'informació. Aquest estudi i altres de posteriors confirmen aquesta opinió.
En resum, la veritat és que se sap poc sobre la naturalesa i l'abast de les relacions expressades en contextos de descripció, recerca i recuperació d'imatges, o sobre els problemes intel·lectuals que comporten aquestes activitats. Sembla probable que una comprensió completa de les relacions representades en descripcions d'imatges haurà d'incloure les activitats de catalogadors, cercadors d'imatges i conservadors situats en l'entorn social dels arxius. Els objectius de la investigació preliminar, per tant, se centren a desenvolupar un mètode per predir ocurrències de relacions i representar-les d'una manera que comporti efectivament que es poden representar en un entorn de màquina.
3 Mostra de dades
Les dades utilitzades en aquest estudi consisteixen en descripcions textuals d'imatges obtingudes dels arxius de correspondència de la Pittsburgh Photographic Library (PPL). La PPL es va crear el 1950 a la University of Pittsburgh. La seva missió principal ha estat la mateixa en els últims anys: oferir als investigadors fotografies perquè les facin servir en articles de diaris i revistes, xerrades, fullets i altres publicacions que promoguin la història i la cultura de Pittsburgh. El 1961, la col·lecció es va traslladar de la universitat a la seva seu actual, la Carnegie Library of Pittsburgh. El març de 2000, el fons total estimat de la biblioteca ascendia a 57.008 còpies, 58.292 negatius, 1.234 diapositives, 310 plaques de llanterna màgica i 13.000 contactes fotogràfics (Pittsburgh Photographic, 2000).
La Pittsburgh Photographic Library manté un arxiu de correspondència en paper que data de 1963, que conté 1.673 documents. Dins d'aquest conjunt, hi ha un total de 180 documents relacionats específicament a sol·licituds de fotografies, que formen el corpus de dades d'aquest estudi. Es va seleccionar una mostra aleatòria de 45 casos per analitzar-los. Se'n van fer servir 9 en la investigació preliminar. La resta, 36 casos, s'analitzen en la tesi de l'autor.
Examinar tota la qüestió de les relacions a mesura que s'expressen naturalment en les transaccions de referències requereix que els límits entre el contingut de les imatges i el llenguatge es vegi amb claredat. En primer lloc, la persona que busca una imatge presenta una consulta en què descriu imatges conegudes, desconegudes a vegades, i, possiblement, que no existeixen. Se'n presenta una mostra en la figura 1.
Figura 1. Correspondència de la mostra d'un investigador visual que sol·licita fotografies a la Pittsburgh Photographic Library.
En segon lloc, els conservadors exerceixen el paper de mediadors, descrivint i interpretant el contingut de les imatges durant el procés de mediació. La figura 2 il·lustra un exemple de la correspondència en què el conservador ha de determinar el punt de vista d'un fotògraf col·locant una càmera "a l'escenari" que vegi "el públic des de l'escenari".
Figura 2. Correspondència de mostra del conservador de la Pittsburgh Photographic Library en resposta a la consulta de la persona que busca imatges.
Finalment, hi ha el catalogador, la funció del qual és descriure les fotografies en els registres del catàleg que són consultats durant la recerca i la recuperació del conservador i cercador d'imatges. Les descripcions dels catalogadors, com ara la que acompanya el contacte fotogràfic en la figura 3, no només tenen dimensions interpretatives i estètiques. També tenen significats complementats, en part, per normes de descripció i procediments de processament locals.
Figura 3. Lou Malkin. Carnegie Library. Director's Office, 17 de desembre de 1973. Del catàleg de fotografies de la Pittsburgh Photographic Library. (Reproduït amb permís.) Carnegie Library of Pittsburgh. Tots els drets reservats. Estan prohibits la reproducció o l'ús no autoritzats
La intenció de la investigació preliminar no era, necessàriament, analitzar com aquests grups descriuen les relacions de maneres diferents, encara que aquesta anàlisi es va dur a terme d'una manera limitada durant la investigació de la tesi. Més aviat, la intenció era provar la viabilitat d'aplicar l'anàlisi de continguts i l'anàlisi ontològica a múltiples contextos dins d'un àmbit. L'apartat 3 explica, en part, com l'investigador ho va dur a terme en l'espai discursiu dels arxius. L'enfocament està motivat per la creença que la descripció no és un acte solitari, sinó el resultat de pràctiques socials. Animem els investigadors que estudiïn altres àmbits problemàtics a codificar i analitzar els seus conjunts de dades en dimensions semblants, múltiples, a partir de diferents marcs de referència.
4 Metodologia de recerca
L'objectiu fonamental de la investigació era determinar els beneficis i les dificultats de l'ús de tècniques d'anàlisi de continguts i eines ontològiques per dur a terme la investigació sobre relacions. Els objectius de l'estudi eren tres: 1) desenvolupar i perfeccionar un llibre de codis i formularis per recollir les relacions que ocorren en les descripcions en llenguatge natural; 2) perfeccionar l'ús d'eines i de mètodes ontològics per predir exemples de relacions, i organitzar-los en famílies de tipus de relacions, i 3) provar la fiabilitat dins de la codificació i la validesa de l'instrument.
Perquè fossin útils en aquesta investigació, les eines d'anàlisi de continguts i ontològiques es van haver de perfeccionar per a tasques específiques i adaptar als problemes particulars, sobretot en el cas de l'ontologia. Si l'ontologia, en el sentit modern, s'ha de convertir en una eina útil en biblioteconomia i documentació, necessita un problema pràctic i específic per intentar resoldre'l.
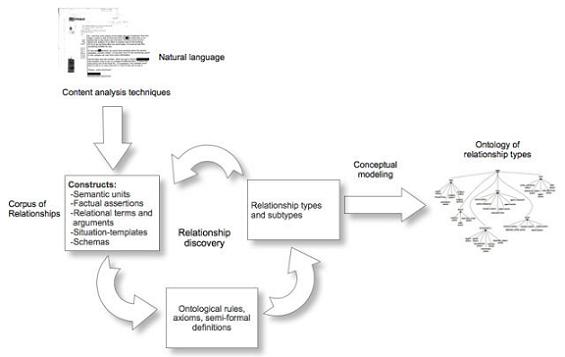
La figura 4 mostra l'enfocament metodològic desenvolupat durant la investigació preliminar i la tesi posterior. Els primers problemes que calia superar es mostren al principi del cicle de treball en el diagrama. El primer desafiament és com s'ha de fonamentar empíricament la identificació i captura de les relacions en les descripcions en llenguatge natural i després formalitzar-les en un llenguatge d'ordre superior perquè puguin ser utilitzades com a eines per respondre a les preguntes importants de recerca. La solució és començar amb l'anàlisi de continguts com una forma d'anàlisi del llenguatge natural en unitats cada vegada més petites fins a arribar al cor de la relació i, després, recollir aquestes conclusions en un corpus de relacions previstes.
Figura 4. Arquitectura del corpus i de la creació d'ontologies.
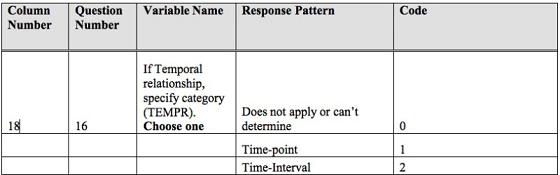
L'investigador comença utilitzant l'anàlisi de continguts per analitzar el llenguatge natural en proposicions més formals. Krippendorff (2004) defineix l'anàlisi de continguts com "a research technique for making replicable and valid inferences from texts (or other meaningful matter) to the contexts of their use" (p. 18). S'utilitzen instruccions de codificació i formularis d'anàlisi de continguts per codificar les dades de la mostra, tant en la investigació preliminar com en la tesi. La figura 5 mostra un extracte de les instruccions de codificació de relacions temporals.
Figura 5. Una part de les instruccions de codificació que il·lustra com es codifiquen les relacions temporals.
Els formularis de codificació es reuneixen en un corpus. Un corpus —que és, essencialment, un llibre de fulls de càlcul de mida tabloide— recull i registra els resultats de les anàlisis dels continguts. En l'apartat 6 es presenta una descripció més detallada del corpus.
Una bateria d'eines ontològiques ofereix definicions formals i semiformals que ajuden a predir i classificar exemples de relacions. Algunes de les eines principals utilitzades per a l'anàlisi ontològica dels tipus de relacions inclouen: l'anàlisi de Cooper de les preposicions angleses locatives (1968); l'anàlisi de Veda Storey de relacions de cas (1993); la biblioteca de relacions d'inclusió de classe d'IDEF5 (Perakath, 1994); la taxonomia de Winston, Chaffin i Herrmann de les relacions part-tot (1987); l'anàlisi ontològica de relacions de Wand, Storey i Weber (1999), i relacions de cas de Sowa (2000). Aquests recursos tenen un paper important en la construcció de l'entorn en què es porta a terme l'anàlisi. Ajuden a explicar com es determinen les relacions d'acord amb paraules clau que s'utilitzen per inferir les relacions.
L'anàlisi ontològica contribueix a determinar la categoria de relacions a què pertany un exemple particular. Durant la codificació i l'anàlisi de continguts de l'estudi preliminar es van aplicar a priori set tipus de relacions:
- Atribució
- Cas
- Inclusió
- Metonímia
- Espacial
- Sinonímia
- Temporal
Tot i que està fora de l'abast d'aquest document presentar els resultats de la tesi, és convenient assenyalar que durant l'anàlisi posterior, es van afegir algunes categories a la llista i se'n van treure d'altres. La categoria de sinonímia va desaparèixer. Tot i que els sinònims són relacions importants per al processament del llenguatge natural i de components lèxics semàntics, no tenen lloc en ontologies en què els conceptes no han de ser ambigus. La inclusió també va desaparèixer. Encara que el paper de la inclusió de classes en una ontologia és fonamental per construir taxonomies (subtipus estàndard i relacions de supertipus), l'anàlisi de les dades va demostrar que les relacions d'inclusió de classe no són un fenomen explícit en les descripcions d'imatges. Es va afegir el tipus de relació d'exemple per representar les relacions que associen exemples amb classes. Finalment, es va descobrir que les relacions de parentiu es produeixen sovint en l'àmbit de les descripcions d'imatges, de manera que el parentiu es va afegir a la llista com una nova categoria de tipus de relacions.
El procés de descobriment de relacions que es mostra en la figura 4 és circular, perquè la realitat és complicada. De vegades, una formalització no és clara, o no hi ha una regla que expliqui el tipus de relació que sorgeix. D'altres, la relació no és prototípica i, en aquest cas, l'investigador o bé assigna una relació a una categoria sabent perfectament bé que els atributs assignats a la categoria no s'apliquen en tots els casos, o bé crea una partició més nítida que permeti entendre els casos límit. Al final, l'investigador aconsegueix una ontologia de tipus de relacions.
En resum, s'elabora un conjunt bàsic d'eines i s'adapta a la investigació sistemàtica del problema de les relacions. Aquestes inclouen l'anàlisi de continguts, que s'utilitza per analitzar el llenguatge natural en afirmacions factuals més formals; un corpus que organitza i estructura l'àmbit d'interès, i una bateria d'eines ontològiques que s'utilitzen per analitzar i determinar els tipus de relacions.
5 Construcció del corpus
En aquest apartat s'explica amb més detall la naturalesa i el propòsit d'un corpus. Un corpus lingüístic es defineix com "the body of written or spoken material upon which linguistic analysis is based" (Oxford English dictionary online, març de 2011). El corpus recopilat en aquest estudi està dissenyat per a un propòsit molt concret: ajudar en l'anàlisi de les relacions expressades, com a part del discurs, en la PPL. El corpus es crea manualment i funciona a través de tres etapes d'anàlisi.
Primera etapa. En la primera etapa d'anàlisi, es fa una lectura acurada de tot el contingut de l'incident. Es determina quina part del text descriu el contingut de la imatge i després es grava com una unitat semàntica i s'hi assigna un número d'unitat semàntica.
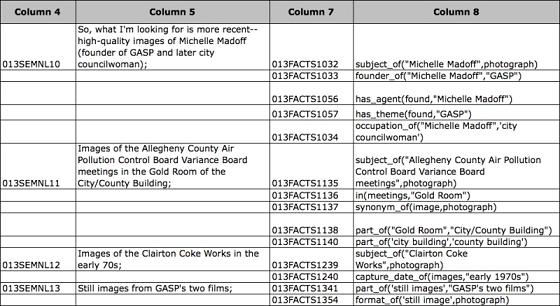
Segona etapa. La segona etapa de l'anàlisi consisteix a analitzar la unitat semàntica en les afirmacions factuals que representen les relacions. S'aplica una notació especial anomenada prefix de notació, que estableix el terme de relació al davant, de manera que es pot veure fàcilment. Llavors, els arguments de relació es col·loquen entre parèntesis separats per comes. La figura 6 és un extracte del corpus de relacions. Il·lustra les unitats semàntiques de la mostra, juntament amb les afirmacions factuals corresponents.
Figura 6. Mostra del corpus de relacions que il·lustra les unitats semàntiques originals de la correspondència del cercador d'imatges (columna 5) i les afirmacions factuals que es van analitzar a partir del llenguatge natural original (columna 8).
Tercera etapa. La tercera i última etapa d'anàlisi en el corpus de relacions consisteix a analitzar les afirmacions factuals per determinar quins tipus de relacions hi són presents i quins són els seus components (temes, objectes de referència, llocs, camins, subjectes, unitats temporals i, així, successivament).
S'estudia el Corpus theoretical paradox de Schmied (1990) adoptant un enfocament basat en processos cíclics. En general, la paradoxa de Schmied és un dilema del tipus l'ou o la gallina. El corpus de relacions resultant d'aquesta investigació hauria de ser representatiu de la llengua utilitzada en els arxius fotogràfics. El problema, però, és que per dur a terme aquesta tasca l'investigador ha de determinar aquestes variables empíricament per mitjà de l'anàlisi de resultats d'un corpus representatiu. Així, doncs, les preguntes són per on començar i quan parar.
El mètode per fer front a aquesta paradoxa adopta el punt de vista de Biber (1993, p. 256), segons el qual el disseny de corpus és un procés cíclic. L'estudi actual es va iniciar amb una investigació preliminar. Durant l'estudi pilot, es van documentar les millores cícliques, i es va ampliar i perfeccionar l'abast de les variables fins que no es van poder detectar varietats addicionals. Els criteris de detenció, segons el que descriuen Bauer i Aarts (2000, p. 32–34), determinen que, quan s'aconsegueix la saturació, és el moment d'aturar el procés cíclic. En l'estudi pilot, la saturació va arribar quan l'addició d'altres tipus i exemples de relacions, i les variables que les defineixen, va representar només una petita diferència respecte de les representacions addicionals de les unitats semàntiques i de les afirmacions factuals.
6 Validesa i fiabilitat
Se sap poc sobre com cal validar els models ontològics. És a dir, fins a quin punt un conjunt de compromisos ontològics representa fidelment un àmbit d'interès. La prova de la validesa de les relacions previstes en aquest estudi és el grau de precisió amb què un exemple de relació (afirmació factual) coincideix amb la naturalesa i les característiques de les relacions ontològiques definides en algun dels diversos recursos utilitzats. S'utilitzen diferents fonts per a la validació en aquest estudi (vegeu-ne la llista en l'apartat 4). Les definicions de relacions en aquests estudis ajuden a formar relacions d'un a un —una funció de mapatge— a partir de les variables expressades i codificades en el discurs dels cercadors, conservadors i catalogadors sobre els fenòmens que les relacions estan inferint.
Weber (1990) assenyala que, per fer inferències vàlides a partir d'un text, els procediments utilitzats per a la classificació han de ser fiables, estables i consistents. La fiabilitat d'aquest estudi es refereix a la consistència del mesurament, és a dir, el grau en què els individus codifiquen el mateix conjunt de dades de la mateixa manera cada vegada, utilitzant un conjunt d'instruccions de codificació en les mateixes condicions. En aquest estudi, l'investigador es va fer càrrec de tota la codificació, de manera que l'anàlisi de la fiabilitat d'intracodificació (en lloc d'intercodificació) en l'ús d'un llibre de codis i de formularis es va portar a terme mitjançant el model de fiabilitat prova i segona prova. El mesurament de la fiabilitat és el percentatge d'acord entre la codificació d'un conjunt de dades en una data i el procés repetit en una data posterior. Es van utilitzar estadístiques de Kappa, que assignar +1,0 si la codificació és perfectament fiable i –1,0 quan l'únic acord que hi ha és fruit de l'atzar (Wood, 2007; Stemler, 2001; Shrout; Fleiss, 1979).
Entre el juliol i l'agost de 2010, es va fer una avaluació de la fiabilitat d'intracodificació per mesurar l'acord en disset de les variables que es van mesurar en el formulari de codificació. El coeficient de correcció per atzar per a totes les variables oscil·la entre 0,394 i 1,0, un rang en què la concentració d'acord respecte dels coeficients de Kappa es considera entre just i gairebé perfecte.
7 Discussió
La investigació preliminar demostra que, una vegada perfeccionades amb l'objectiu concret de dur a terme una investigació sobre relacions, les eines ontològiques i les tècniques d'anàlisi de continguts són eficaces per identificar, recollir i classificar els exemples de relacions, que després es poden gravar en un corpus. Respecte de la possibilitat que investigacions anteriors no funcionessin per la seva dependència respecte dels models d'indexació de paraules, aquest estudi preliminar suggereix que un mètode de base empírica que utilitzi l'anàlisi de continguts i l'ontologia pot obtenir d'una manera més eficaç el significat de les relacions i la semàntica que hi ha rere l'estructura superficial de les paraules.
Tanmateix, les afirmacions que es poden fer durant la investigació preliminar són limitades. Entendre com els éssers humans expressen les relacions i les dificultats de captar i classificar els tipus de relacions és una tasca difícil. Moltes vegades els problemes es resolen. D'altres, sorgeixen problemes nous que només poden ser abordats en investigacions posteriors. En la discussió que segueix, l'investigador descriu quatre problemes que van sorgir durant la investigació inicial que es van convertir en àrees més especialitzades d'investigació en la tesi. Inclouen qüestions relacionades amb l'abast de l'anàlisi, la inferència pragmàtica, les relacions de cas i la previsió de relacions.
7.1 Abast i definició
El primer problema és un problema d'abast i de definició, és a dir, quines dades s'han de considerar adequades per a l'anàlisi de continguts. L'antropòleg visual Malcolm Collier (2001, p. 35) sosté que en el procés d'anàlisi de la informació visual es descobreixen fenòmens i relacions mai vistos abans més enllà dels límits del que va percebre inicialment el fotògraf i el tema de la imatge.
Durant les proves inicials de la tècnica d'anàlisi de continguts, només es va analitzar el text escrit a màquina. Durant la segona prova, la definició de l'àmbit d'interès es va ampliar per incloure-hi totes les dades visibles a la superfície del document, que incloïen, per exemple, inscripcions manuscrites, gargots i dibuixos, molts dels quals es van considerar rellevants i que requerien una identificació i classificació en el formulari de codificació.
Aquesta observació suggereix l'adopció d'un procés analític més visual per descriure les imatges, que consideri l'àmbit d'interès per incloure tant el text original com les inscripcions manuscrites en les còpies de les fotografies i altres documents relacionats. En termes més generals, això ens dóna una lliçó sobre el valor de les investigacions preliminars per classificar els problemes de codificació en mostres petites abans de fer front a grans conjunts de dades.
7.2 Inferència pragmàtica
El problema següent es refereix a la importància de la inferència pragmàtica i el paper que exerceix a l'hora d'analitzar continguts. La inferència és un tipus de raonament que manipula les proposicions conegudes per produir-ne de noves (Levesque; Lakemeyer, 2000). L'investigador va ampliar aquesta definició, tenint en compte el que signifiquen o impliquen les paraules en diferents contextos —la qual cosa es considera el costat pragmàtic de la inferència. L'anàlisi preliminar va mostrar que una gran quantitat del que es percep en el discurs de descripció d'una imatge, de fet, s'infereix i s'extreu a partir de coneixements previs que el parlant i l'oient tenen sobre els incidents de referència.
Per ajudar a situar el que s'entén per una descripció d'una imatge i com es poden inferir fets a partir de coneixements implícits, tingueu en compte la fotografia històrica que es mostra en la figura 7 i la descripció que l'acompanya.
Figura 7. Henry Fox Talbot. Part del Queen's College (Oxford). [The pencil of nature, part 1, pl. 1, s/d]. De les reproduccions de Larry J. Schaaf, de The pencil of nature, d'H. Fox Talbot, fax de l'aniversari (New York: Hans P. Kraus, Jr. Inc., 1989). Utilitzada amb permís.
Implícitament, s'entén que, quan Talbot, el fotògraf, escriu sobre la superfície de l'edifici i les marques deixades a les pedres, de fet, està parlant de la part exterior de l'edifici. Tot i que Talbot no diu explícitament que està parlant de la superfície exterior, les persones que llegeixen la descripció ho entenen així. Aquest és un exemple d'inferència pragmàtica.
En aquest cas, la lliçó és que l'anàlisi del contingut és efectiu per codificar i captar la informació textual, però cal desenvolupar altres eines i mètodes per generar i recollir el coneixement més indirecte, implícit, de fons. Durant el curs de la investigació de la tesi, es va desenvolupar un sistema per abordar aquesta qüestió a partir d'idees preexistents en intel·ligència artificial i lingüística. Això inclou els marcs de Minsky (1975, p. 212), descrits com a "data structures representing a stereotyped situation"; el raonament predeterminat de Fahlman (1979), amb excepcions, i, en lingüística, la semàntica de marcs de Fillmore (1976).
7.3 El cas de les relacions de cas
Un dels tipus de relacions més complexes recollides en aquest estudi, les relacions de cas, va posar de manifest dos problemes durant l'estudi preliminar. En primer lloc, els tipus i subtipus de relacions triats a priori per captar el significat no sempre reflectien el que els éssers humans expressaven en el món real. Els recursos de l'ontologia esmentats anteriorment en l'apartat 4 tractaven les relacions de cas com un conjunt tancat, però l'anàlisi duta a terme per aquest investigador va descobrir un conjunt molt més gran de relacions de cas que el recollit per investigadors anteriors. En segon lloc, la bibliografia no proporcionava un sistema de representació de relacions de cas com ara termes relacionals amb arguments similars als de les altres relacions registrades en el corpus. Aquest era un problema de representació que s'havia de resoldre abans de passar a la tesi.
Les relacions de cas, si bé són útils per descriure les experiències quotidianes, no formen part de les relacions estàndard utilitzades en biblioteconomia i documentació per estructurar vocabularis controlats. Les relacions de cas normalment són marcades en el llenguatge natural per l'ocurrència de frases verbals. Si reprenem, una vegada més, la descripció de la fotografia de Talbot de la figura 7, Talbot assenyala "the view is taken from the other side of the High Street, looking North" ('la fotografia està feta des de l'altre costat de High Street, mirant cap al nord'). La forma verbal taken ('feta') és el participi passat de take ('fer'), cosa que indica una activitat, i la forma verbal looking ('mirant') és el gerundi de look ('mirar') i assenyala un segon esdeveniment. Durant la tesi, l'investigador va desenvolupar un sistema per representar relacions de cas en notació de prefix (una notació introduïda anteriorment en l'apartat 6 i en la figura 6). Els dos esdeveniments descrits en la descripció de Talbot es poden interpretar com l'expressió de les afirmacions factuals següents:
- has_location(take,"other side of High Street")
[= tenen_ubicació(fer,"altre costat de High Street")]
- has_agent(take,photographer)
[= tenen_agent(fer,fotògraf)]
- has_PointInTime(take,"4 September 1843")
[= tenen_moment(fer,"4 de setembre de 1843")]
- has_instrument(look,camera)
[= tenen_instrument(mirar,càmera)]
- has_direction(look,North)
[= tenen_direcció(mirar,nord)]
- has_reference_object(look,"Church of St. Peter's")
[= tenen_referència_objecte(mirar,"Església de St. Peter's")]Els dos primers es poden llegir com "the take action has a location on the other side of High Street" ('l'acció feta té una ubicació a l'altre costat de High Street') i "the take action has an agent who is a photographer" ('l'acció feta té un agent que és un fotògraf'). Story (1993) ofereix una síntesi útil de les interpretacions de diversos investigadors sobre les relacions de cas. No obstant això, el conjunt de cinc relacions de cas que adopta aquesta autora no capten l'essència d'esdeveniments com els que es produeixen en les descripcions d'imatges.
La solució que s'ofereix també serveix com un marc per abordar el problema que s'ha presentat en el subapartat 7.3, és a dir, com es pot recollir el coneixement previ que no s'indica explícitament en la descripció de la fotografia. Les relacions de cas descrites més amunt es poden utilitzar com un heurístic per completar aquesta informació de fons. Per exemple, una pregunta formulada per un investigador d'una imatge que diu "the photograph was taken on 24 September 1951" ('la fotografia es va fer el 24 de setembre de 1951') podria ampliar-se en un entorn de màquina buscant construccions gramaticals que expressin coses com ara accions que retraten els fotògrafs, ubicacions espacials, objectes de referència i punts de vista, i així successivament.
En resum, la investigació preliminar va donar proves empíriques que suggerien que les relacions de cas formen un conjunt obert. Això va originar revisions en el formulari d'anàlisi de continguts per captar marcs de situació i el que probablement seria un conjunt obert de relacions de casos. A més, la investigació preliminar va obligar l'investigador a resoldre un problema de representació de les relacions de cas, que, al seu torn, va comportar la creació d'un sistema per generar i captar coneixement previ implícit.
7.4 Predir relacions
Finalment, a mesura que avançava el projecte de recerca principal, van néixer expectatives que coneixements nous proporcionarien maneres noves de mirar dades concretes. Per exemple, calia comprovar si el conjunt de condicions necessàries i suficients de Cooper (1968) podria predir de manera exhaustiva expressions espacials en descripcions d'imatges. El seu enfocament sobre el problema de la relació espacial no tenia en compte l'ús de les preposicions en la descripció d'altres camps semàntics. Per exemple, aquests tres casos extrets de la mostra de dades fan servir preposicions espacials en expressions no espacials:
- The old symphony, founded in 1895. [la preposició in indica moment, i no pas contingent (contained by)]
- Photo by [Clyde] Hare. [la preposició by indica autoria, i no proximitat (near o next to)]
- Horse car in operation. [la preposició in denota l'estat del cotxe de cavalls, i no pas contingent (contained by the operation)]
Les solucions no va aparèixer fins que no es va analitzar la mostra més gran. Finalment, l'investigador es va inclinar cap a la lingüística i la hipòtesi de relacions temàtiques de Gruber (1965), explicada per Ray Jackendoff (1983). Gruber va descobrir que patrons gramaticals similars s'estenen a través de camps semàntics relacionats. Per exemple, la semàntica de l'expressió locativa in ('en', ' a'), d'acord amb Jackendoff, suggereix un pseudoespai unidimensional, o línia de temps, en l'expressió temporal "founded in 1895". En altres paraules, la ment s'adapta als camps no espacials de què la maquinària ja disposa per reconèixer espais (Jackendoff, 1983, p. 188–189).
En resum, aquest apartat mostra que els investigadors podrien ser capaços de fer prediccions utilitzant els axiomes i les normes ontològiques existents en analitzar mostres petites, però quan es traslladen a grans conjunts de dades, la varietat i el nombre d'entitats que requereixen una explicació poden augmentar i requerir una anàlisi més profunda. En el cas de tenir regles per a preposicions que defineixen expressions espacials, però no temporals, l'investigador simplement va classificar aquests últims casos com a "no explicables" durant la investigació preliminar. Com que no s'analitzen els problemes "no explicables" durant la investigació preliminar, el conjunt de relacions de "no explicables" va sortir de mare durant la tesi i, al final, va caler fer marxa enrere, revisar el formulari d'anàlisi de continguts i tornar a començar amb l'anàlisi de dades.
8 Conclusió
Aquest document revela els resultats d'un estudi preliminar que investiga el problema de les relacions en la descripció d'imatges. Els objectius de l'estudi eren tres: 1) desenvolupar i perfeccionar un llibre de codis i uns formularis per captar les relacions que ocorren en les descripcions en llenguatge natural; 2) perfeccionar l'ús d'eines i de mètodes ontològics per preveure exemples de relacions, i organitzar-los en famílies de tipus de relacions, i 3) provar la fiabilitat d'intracodificació i la validesa de l'instrument.
La investigació demostra que el reconeixement de relacions semàntiques en l'anàlisi de descripcions d'imatges no és ni directe ni senzill, de manera que hi ha una amenaça constant que les instruccions de codificació detallades no puguin garantir les relacions que estan representades amb precisió. L'anàlisi de continguts requereix una gran quantitat de petits passos, sistemàtics, que interrelacionin les observacions de fets explícits i el coneixement inferencial. Identificar un exemple d'un tipus de relació particular en un text no és una tasca trivial i exigeix una classe d'inferència, del tipus o... o..., sobre la pertinença de classe.
Mentre que les enquestes i entrevistes estructurades ofereixen als participants opcions predefinides que són fàcils de tabular, aquest treball ha demostrat que, quan s'utilitzen transaccions de referències de la vida real com a conjunt de dades, és difícil controlar o suprimir el que probablement serien variacions molt desestructurades, poc flexibles, en el formulari. Això és un reflex del fet que la gent normal —conservadors i usuaris d'arxius— busca, presenta preguntes i es comporta de maneres diferents.
S'ha assenyalat que els estudis preliminars de vegades responen a preguntes i d'altres plantegen preguntes noves. En aquesta línia, el document aclareix quatre problemes específics que van sorgir: 1) l'abast de les anàlisis de continguts futures hauria de ser ampliat per incloure inscripcions pertinents a mà trobades al marge dels documents de text; 2) gran part del coneixement sobre descripcions d'imatges és implícit i requereix que l'analista utilitzi la inferència pragmàtica per captar coneixements previs; 3) l'anàlisi ha d'anar més enllà de l'estructura superficial de la gramàtica i la sintaxi, i explorar relacions que a priori van més enllà del conjunt de relacions ontològiques triat originalment per validar els tipus de relacions, i, finalment, 4) la tasca de preveure les relacions es fa difícil pels múltiples significats associats a les preposicions. Això requereix usar anàlisis que no es limiten a complir les condicions necessàries i suficients en el context d'un camp semàntic.
Malgrat aquests desafiaments, les proves suggereixen que per investigar en l'àmbit de l'anàlisi de les relacions calen investigacions preliminars que vagin més enllà de l'esquema simple prova i segona prova. Això és especialment cert a l'hora d'adaptar i de perfeccionar tècniques d'anàlisi de continguts i eines i mètodes ontològics. A més, sembla que hi ha arguments contundents per aplicar l'anàlisi de continguts i eines i mètodes ontològics com a marc per analitzar i estructurar la recopilació de dades. El resultat és un conjunt de relacions i conceptes rics semànticament recollit en un corpus d'exemples de relacions.
Allen C. Benson és director de la Biblioteca i professor de l'Escola Naval de Guerra dels Estats Units. Les opinions aquí expressades són personals i no reflecteixen les de la Marina o el govern dels Estats Units.
Bibliografia
Bauer, M.; Aarts, B. (2000). "Corpus construction: a principle for qualitative data collection". In: M. Bauer; G. Gaskell (Eds.), Qualitative researching with text, image and sound (19-37). London: Sage.
Bean, C. A. (1996). "Analysis of non-hierarchical associative relationships among medical subject headings (MeSH): Anatomical and related terminology". Advances in Knowledge Organization. 5, p. 80-86.
Bean, C. A.; Green, R. (Ed.). (2001). Relationships in the Organization of Knowledge. Dordrecht, The Netherlands: Kluwer Academic Publishers.
Biber, D. (1993). "Representativeness in corpus design". Literary and Linguistic Computing. 8(4), 243-257.
Carnegie Library of Pittsburgh, "Pittsburgh Photographic Library (PPL) Preliminary Inventory". (2000). [Unpublished manuscript].
Chaffin, R.; Herrmann, D. J. (1984). "The similarity and diversity of semantic relations". Memory & Cognition. 12(2), p. 134-141.
Chaffin, R.; Herrmann, D. J. (1987). "Relation element theory: A new account of the representation and processing of semantic relations". In: D. S. Gorfein; R. R. Hoffman (Eds.), Memory and learning (221-245). Hillsdale, NJ: Lawrence Erlbaum Associates.
Cooper, G. S. (1968). A semantic analysis of English locative prepositions (Bolt, Beranek, & Newman, Report No. 1587). Springfield, VA: Clearing House for Federal, Scientific, and Technical Information. <http://handle.dtic.mil/100.2/AD666444>. [Accessed: 14/03/2010].
Enser, P. G. B.; McGregor, C. G. (1993). Analysis of visual information retrieval queries. British Library R&D Report 6104. The British Library Board.
Fahlman, S. E. (1979). NETL: A System for Representing and Using Real-World Knowledge. Cambridge, Massachusetts: MIT Press.
Farradane, J. (1980a). "Relational indexing, Part I". Journal of Information Science. 1, p. 267-276.
Farradane, J. (1980b). "Relational indexing, Part II". Journal of Information Science. 1, p. 313-324.
Fillmore, C. J. (1976). "Frame semantics and the nature of language". Annals of the New York Academy of Sciences: Conference on the Origin and Development of Language and Speech, 280, 20-32.
Graesser, A. C.; Goodman, S. M. (1985). "Implicit knowledge, question answering, and the representation of expository text". In: B. K. Britton; J. B. Black (Eds.), Understanding expository text: a theoretical and practical handbook for analyzing explanatory text. Hillsdale, NJ: Lawrence Erlbaum Associates.
Gruber, J. S. (1965). "Studies in lexical relations". Doctoral Dissertation, MIT, Cambridge; Indiana University Linguistics Club, Bloomington, Ind. Reprinted as part of Lexical structures in syntax and semantics, North-Holland, Amsterdam, 1976.
Jackendoff, R. (1983). Semantics and cognition. Cambridge, Mass.: MIT Press.
Keister, L. H. (1994) "User types and queries: Impact on image access systems". In: R. Fidel et al. (Eds.), Challenges in indexing electronic text and images, (7-22). Medford, NJ: Learned Information.
Krippendorff, K. (2004). Content analysis: an introduction to its methodology. Thousand Oaks, CA: Sage Publications.
Minsky, M. (1974). "A framework for representing knowledge." Artificial Intelligence Memo No. 306. Cambridge, MA: Massachusetts Institute of Technology A.I. Laboratory.
Oxford English Dictionary Online. March 2011. Oxford University Press. <http://www.oed.com/view/Entry/41873?redirectedFrom=corpus>. [Accessed: 28/04/2011].
Perakath C. B. [et al.] (1994). IDEF5 Method Report. Knowledge Based Systems, Inc.
Pittsburgh Photographic Library (PPL) Preliminary Inventory, Revision 19. (March 23, 2000). <http://216.183.184.20/exhibit/ppl_plan.html>. [Accessed: 12/04/2009].
Proposal for the Establishment of the Civic Photographic Center under the Sponsorship of the Allegheny Conference on Community Development. (December 1949, revised February 20, 1950). Archives Service Center, University of Pittsburgh, Box 56, Folder File 1, A. W. Mellon Education and Charitable Trust, Pgh., PA Records 1930-1980.
Rothkegel, R.; Wender, K. F.; Schumacher, S. (1998). "Judging spatial relations from memory". In: C. Freska, C. Habel; K.F. Wender (Eds.), Spatial cognition: An interdisciplinary approach to representation and processing of spatial knowledge (p. 79-105). Berlin: Springer-Verlag.
Schmied, J. (1990). "Corpus linguistics and non-native varieties of English". World Englishes. 9(3), p. 255-268.
Shatford, S. (1986). "Analyzing the subject of a picture: A theoretical approach". Cataloging & Classification Quarterly. 6(3), p. 39-62.
Shatford, S. (1994). "Some issues in the indexing of images". Journal of the American Society for Information Science. 45(8), p. 583-586.
Shrout, P. E.; Fleiss, J. L. (1979). "Intraclass correlations: uses in assessing rater reliability". Psychological Bulletin. 86(2), p. 420-428.
Stemler, S. (2001). "An overview of content analysis". Practical Assessment, Research & Evaluation, 7(17). <http://PAREonline.net/getvn.asp?v=7&n=1>. [Accessed: 15/01/2010].
Story, V. C. (1993). "Understanding semantic relationships". VLDB Journal. 2, p. 455-488.
Svenonius, E. (2000). The intellectual foundation of information organization. Cambridge, Mass.: MIT Press.
Talbot, William Henry Fox. (1968). The pencil of nature. New York, NY: Da Capo Press. (First edition of The Pencil of Nature was published in London between 1844 and 1846 in six separate fascicles.)
Wand, Y.; Storey, V.; Weber, R. (1999). "An ontological analysis of the relationship construct in conceptual modeling". ACM Transactions on Database Systems. 24 (4), p. 494-528.
Weber, R. P. (1990). Basic content analysis. Newbury Park, CA: Sage Publications.
Winston, M.; Chaffin, R.; Herrmann, D. (1987). A taxonomy of part-whole relations. Cognitive Science. 11, p. 417-444.
Wood, J. M. (2007). "Understanding and computing Cohen's Kappa: a tutorial". WebPsychEmpiricist. <http://wpe.info/papers_table.html>. [Accessed: 14/05/2010].
Data de recepció: 02/05/2011. Data d'acceptació: 11/07/2011.



![Henry Fox Talbot. Part del Queen's College (Oxford). [The pencil of nature, part 1, pl. 1, s/d]. De les reproduccions de Larry J. Schaaf, de The pencil of nature, d'H. Fox Talbot, fax de l'aniversari (New York: Hans P. Kraus, Jr. Inc., 1989). Utilitzada amb permís](benson7.jpg)