Resum [Abstract] [Resumen]
Objectiu. Analitzar les propostes de recuperació de la informació dels arxius que han posat a disposició dels usuaris els seus fons documentals a Internet, per reflexionar sobre els canvis de paradigma dels arxius físics als arxius digitals.
Metodologia. Identificació i anàlisi dels llocs web d'arxius que permeten als usuaris diversos plantejaments per a la recuperació de la informació. Valoració de la implementació de les bones pràctiques en la recuperació de la informació en l'arquitectura del lloc web.
Resultats. L'evolució de les tecnologies de la informació i la comunicació permet implementar instruments de recuperació de la informació eficaços en els arxius que posen a disposició dels usuaris els seus catàlegs en línia. L'anàlisi permet reflexionar sobre les pràctiques de la recuperació de la informació en els arxius físics, i de la seva evolució, i de les possibilitats d'aplicar-ho al web i al web 3.0.
1 Introducció
Ha estat bastant habitual, quan s'esmenten les funcions que ha de realitzar un arxiver, fins i tot en l'entorn de l'administració electrònica, no destacar entre les seves tasques els aspectes relacionats amb la recuperació de la informació. Karen Dawley Paul, en els anys 80, incidia en què els gestors documentals tenien les funcions de planificació, i incloïa els aspectes de creació, utilització, protecció i eliminació final, després de l'avaluació, dels documents electrònics en un sistema d'informació, que abraçava fins i tot aspectes com els serveis de reprografia, els processadors de textos, el processament de dades, el correu electrònic, el reconeixement òptic de caràcters, les telecomunicacions, la micrografia, la gestió de documents i arxius, i també els serveis bibliotecaris, i esmentava que la gestió eficaç de tot això jugava un paper important en l'establiment de l'estructura d'informació de les organitzacions i que això afectaria la informació que es conservava i que seria accessible per a futures investigacions (Paul, 1988, p. 37).
La teoria arxivística espanyola va centrar les seves investigacions, en els anys 80, en aspectes relacionats amb la classificació, la descripció, la valoració, les tipologies documentals, l'autenticitat, o el cicle vital dels documents generats per les organitzacions, però es va centrar poc sobre la "cerca" o la recuperació de la informació d'aquests en els arxius. En part, això té certa explicació. Els professionals, com per exemple Antonia Heredia (1988), en el llibre Arxivística general, teoría y práctica, es centraven en els aspectes que més preocupaven els arxivers en un entorn de mancances tecnològiques amb el qual treballen la majoria. Els estudis realitzaven una visió de conjunt i sistematitzaven els coneixements arxivístics, donaven a conèixer, fins i tot, les novetats en l'automatització dels arxius. Els temes que es tractaven feien referència a les ciències auxiliars de l'arxivística, la història dels arxius, les característiques dels documents d'arxiu, les transferències, la valoració documental, l'administració d'arxius, la classificació i l'ordenació, la descripció i els instruments de descripció (guies, inventaris i catàlegs), consideraven les fitxes índex com els instruments auxiliars de descripció, els tesaurus, les llistes alfabètiques o els llibres de registre, l'accessibilitat documental i el servei de documents. Si en els manuals d'arxivística dels anys 80 i 90 no hi ha un capítol destinat a la recuperació de la informació, no és perquè no interessi el tema, sinó perquè l'entorn físic i l'absència d'implementació tecnològica és bastant generalitzada (tret d'algunes excepcions, com el cas de l'automatització del Archivo General de Indias), i la recuperació de la informació es contempla des d'un altre enfocament.
Abans de l'entorn tecnològic (fonamentalment bases de dades, Internet i intranets) la recuperació de la informació, és a dir, trobar els documents després d'una petició, es basava en una bona organització de l'arxiu i en uns bons instruments de descripció, per aquest motiu no hi ha capítols específics dedicats a aquesta faceta en la nostra literatura arxivística, ja que la resposta es trobava implícita en la bona gestió dels documents arxivístics. Una altra qüestió és l'aparició d'Internet, i traslladem aquest mateix assumpte a l'arquitectura de la informació del lloc web, i a les seves funcionalitats (els OPAC).
L'interès pel procés de "cerca de documents" no és nou. Ja el 1835, en una memòria realitzada per Jorge García sobre el Archivo del Reino de Valencia, es va dedicar un capítol titulat "De la busca de documentos". Segons aquesta memòria: la busca pues, de los documentos depende en la actualidad o de les noticias ciertas y circunstanciadas que suministren los interesados, o de les que arrojen los índices que se mencionarán, o de la luz que el archivero y oficiales puedan dar a beneficio de sus observaciones y experiencias. Malgrat l'antiguitat d'aquestes apreciacions, destaquem els aspectes que ens semblen que transcendeixen a l'actualitat. Per a la recuperació de la informació en els arxius caldria, doncs, tenir en compte el següent, segons els paràmetres del segle xix:
- El vocabulari i els termes de la consulta.
- L'anàlisi documental i la indexació.
- La tecnologia en la cerca.
La literatura arxivística més recent no ha contemplat aquests aspectes. És més, algunes obres que han estat molt positives en alguns aspectes, en altres han impregnat una opinió, des del nostre punt de vista, errònia. És el cas de les afirmacions d'Elio Lodolini (1993, p. 207-208 i p. 213-214), que tanta influència ha tingut en alguns arxivers espanyols. Segons aquest autor, la descripció individualitzada dels documents d'arxiu i la seva anàlisi documental, el que s'entén per catàleg, no s'ha de realitzar als arxius:
En efecto, no tendría sentido preguntar, en un archivo, ¿qué hay sobre tal tema? y ¿qué hay sobre tal personaje? (como, por desgracia, bastante a menudo hacen los que se dirigen a un archivo sin una suficiente preparación específica). Es necesario, por el contrario, preguntar cuál era, en los diversos momentos, la oficina competente para tratar el tema que interesa y qué procedimientos usaba, es decir, cómo producía y organizaba sus propios documentos, o bien, cómo un personaje ha tenido contactos con la autoridad pública (si la investigación se desarrolla en un archivo público), en calidad de juez, de acusado [.]
El inventario es, pues, un instrumento compuesto; el único medio que permite realizar la búsqueda en un archivo. Del todo inútil sería, por el contrario, un catálogo de documentos, entre otras cosas carente de sentido [.] sin poner de relieve el aspecto fundamental, archivístico, de los documentos mismos, es decir, su interdependencia [.]
En aquest context, alguns autors espanyols han considerat que el catàleg era el menys recomanable de tots els instruments de descripció, des d'un punt de vista pràctic i de servei, a causa de les mancances de mitjans materials i humans existents a la majoria dels arxius. En conseqüència, seguint el plantejament de Lodolini, l'absència de descripció individualitzada i anàlisi documental dels documents impossibilita la cerca específica, atès que no hi ha indexació ni descripció individual del document. Aquestes opinions del segle xx, curiosament, contrasten amb la consideració de l'arxiver de 1835, que tenia molt clar que les fitxes índex (on hi havia també la descripció individualitzada dels documents) eren un dels pilars bàsics per a la "cerca" dels documents. De fet, en molts arxius espanyols es van realitzar en el segle xix i principis del xx moltes fitxes índex, que han servit reiteradament als historiadors.
En aquest context, la producció teòrica en arxivística en altres països s'ha preocupat per la indexació i la recuperació de la informació en els arxius? Richard J. Cox (1992) ja va assenyalar que davant de la definició tradicional de gestió documental —entesa com l'ús del control sistemàtic i científic de tota la informació registrada que una organització necessita en la seva activitat empresarial— l'aparició en els darrers anys —anys 80— del concepte de gestió de recursos d'informació, en anglès information resources management (IRM), era alguna cosa més: la informació és un recurs institucional, que necessita de la tecnologia per ser gestionada, i necessita de persones per tractar eficaçment ambdues coses. La gestió de recursos d'informació inclou l'esforç de tenir el control de la total diversitat de recursos d'informació, maquinari i programari, equipament de telecomunicacions, equipament d'automatització de l'oficina i dels aparells de reprografia, així com de la informació transmesa a través d'aquesta infraestructura i de les persones. La gestió de recursos d'informació inclou, també, una varietat de tècniques que són molt semblants a aquelles utilitzades pels gestors documentals i creades al voltant del concepte de cicle de vida. Aquestes afirmacions les va assenyalar Richard Cox quan encara no havia nascut Internet, tal i com ho coneixem ara. Posteriorment, Michael Cook i Margaret Procter (2000) van assenyalar l'existència de diferents estratègies de recuperació de la informació per part dels usuaris. Les tres principals estratègies utilitzades pels usuaris (incloent-hi el propi personal de l'entitat com a usuaris) per localitzar els documents arxivístics més rellevants per a la seva recerca són: la identificació directa, el fullejat i la cerca o exploració. La identificació directa es dóna quan l'usuari sap una o més de les característiques d'identificació dels documents (per exemple, un nom específic, una data o un codi de referència). Per això el requisit principal és que les dades que pertanyen a cada entitat han de ser clarament identificables. En l'estratègia de fullejar, els usuaris llegeixen les pàgines de l'assistent de cerca per seleccionar qualsevol informació o tema que considerin útil. Aquesta estratègia s'utilitza amb descripcions arxivístiques de text lliure, com ara la història administrativa, la custòdia o les àrees d'abast i contingut. En l'estratègia de cerca o exploració, l'objectiu de la recuperació ha d'estar més o menys ben definit. L'acció de cerca o exploració es basa en l'ús de paraules clau. Cal tenir present que els usuaris demanen una certa rapidesa en la presentació dels resultats —estan habituats als resultats de Google—. En aquesta estratègia es requereix un OPAC correctament construït. Hi sol haver un cert grau de conflicte entre la configuració del lloc web i l'estructura de la base de dades o OPAC més convenient per a cada modalitat de recuperació de la informació, per això és important que s'estableixin formes d'ajuda apropiades per a cada estratègia, i separar les que es refereixen al fullejat de la cerca o exploració.
També Cook i Procter (2000) han assenyalat la importància de la indexació en els arxius com a part de la recuperació de la informació. Opinen que la creació dels índexs és una part essencial d'una descripció arxivística i que són punts d'accés necessaris en un sistema de recuperació de la informació. La importància dels índexs en la descripció arxivística ha augmentat en aquests darrers anys. El vocabulari dels índexs ha d'estar fet amb temps, i han de ser una part d'un sistema integrat de suport a la recuperació de la informació. Els usuaris han de disposar d'accés directe als índexs. Els índexs són ajudes secundàries de la recuperació. Això permet portar els usuaris de forma precisa a les descripcions que estan indexades en el sistema, i permeten recuperar directament els documents que es desitgen. Es recomana que els índexs siguin paraules clau en els assistents de cerca.
2 Instruments que tenim al nostre abast per a la recuperació de la informació
Actualment disposem de diversos instruments al nostre abast per resoldre de la forma més eficient la recuperació de la informació en els arxius que han decidit posar els seus fons a disposició de qualsevol usuari, o a usuaris d'una comunitat específica. Aquests instruments es basen en programari i maquinari, així com en l'aplicació d'estàndards. No parlarem del maquinari ni del programari específic, sinó de forma genèrica del que ens ofereixen les TIC per optimitzar la gestió, i per tant, la recuperació de la informació.
Hem de deixar clar que tot el treball que es realitza en l'administració dels arxius i en la gestió dels documents convergeix en una sola finalitat: poder consultar els documents després d'una petició. Els documents es classifiquen, s'ordenen, es descriuen, se'n garanteix la seva òptima conservació, per poder resoldre una consulta en un moment determinat.
Entre els instruments que tenim al nostre abast destaquem les bases de dades, la descripció arxivística i la interoperabilitat, com veurem a continuació.
2.1 Bases de dades
Les bases de dades i els sistemes de gestió de bases de dades han revolucionat la gestió dels documents. És, en definitiva, la convergència d'un sistema de gestió basat en mobles amb calaixos que contenen fitxes descriptives (ordenades tradicionalment per llocs, dates, o assumptes) amb un sistema de gestió electrònica on identifiquem els camps en els quals s'emmagatzemen les dades o la informació.
Mentre que les bases de dades són un conjunt o una col·lecció de dades, un sistema de gestió de bases de dades —a partir d'ara SGBD— és un programari que permet la creació, manteniment i explotació de les bases de dades (Abadal; Codina, 2005, p. 18-19). Una base de dades és una col·lecció organitzada de dades per a un o més propòsits, i que en general, en les darreres dècades, la trobem en forma digital. El terme base de dades s'aplica a les dades i estructures de dades, i no al SGBD que requereix d'un programari per a gestionar-les, atès que l'estructura d'una base de dades sol ser massa complexa per ser manejada sense el seu SGBD. La base de dades SQL disposa de l'estàndard ISO/IEC 9075 —Information technology, Database languages, SQL— actualitzat amb freqüència.
2.2 Descripció arxivística
La normalització en la descripció arxivística —estàndards com la ISAD (G), ISAAR-CPM, EAD o EAC-CPF— permet estructurar la descripció de la informació i la descripció dels seus productors. Això suposa un altre gran avanç perquè ha obert la possibilitat de fer interoperables diferents bases de dades. L'aplicació dels estàndards permet —igual que a les biblioteques ho va permetre la ISBD o els diferents formats MARC— interrelacionar les bases de dades amb els camps definits per a la descripció i l'anàlisi documental. Volem recalcar les tres parts que caracteritzen la descripció arxivística, per les quals s'ha de poder realitzar la recuperació de la informació.
- Descripció del context. Són camps destinats a descriure el productor de la documentació arxivística, especialment mitjançant les normes ISAAR-CPF o l'EAC-CPF. Segons l'opinió de la comissió que va elaborar la ISAAR-CPF, amb això s'aconsegueix al mateix temps facilitar la recuperació de la informació de les descripcions arxivístiques, així com que la recuperació de la informació es vegi millorada per l'ús de punts d'accés (o termes índex), i que els punts d'accés funcionin millor quan estan estandarditzats mitjançant un registre d'autoritat (Thibodeau, 1995). L'interès per descriure el context en la documentació arxivística és alguna cosa més: per saber que l'expedient és autèntic hi ha d'haver identificat el seu productor en el món, s'ha d'especificar el sistema que el gestiona, s'han de nomenar els seus creadors i els processos pels quals s'identifica. La descripció del context, a partir de les metadades generades, contribueix a garantir la seva autenticitat (Cumming, 2007). Des del punt de vista de la recuperació de la informació és molt més rellevant descriure el productor en un arxiu que recull documentació de molts productors, que en un arxiu d'un únic productor, ja que una petició de cerca pot ser la recuperació dels documents produïts per un productor determinat. Des del punt de vista de l'autenticitat i les mesures de conservació cal descriure el productor.
- Descripció de la unitat arxivística. Tant si parlem d'una unitat d'informació, com d'una unitat arxivística, en aquest apartat s'entenen com una unitat de descripció, tal i com ho defineix la norma ISAD (G), és a dir, com un document o conjunt de documents, sigui quina sigui la seva forma física, és tractat com un tot i que com a tal constitueix la base d'una única descripció. La norma identifica 26 elements per descriure qualsevol unitat (fons, sèrie, unitat documental composta o simple, etc.). La translació dels elements a camps d'una base de dades fa possible la seva recuperació automatitzada, amb totes les característiques que puguin oferir aquests camps: numèrics (per processar números, màscares de bits, dates o hores) o alfanumèrics. Igualment, els etiquetats de l'EAD serveixen per ser traslladats a les bases de dades.
- Indexació. Utilitzada en els arxius, almenys des de l'època medieval, de forma progressiva es va incorporar a les bases de dades arxivístiques. A principis del segle xxi eren escasses, en l'entorn espanyol, les bases de dades que havien incorporat la indexació (ja fos amb llenguatge documental o bé amb llenguatge lliure) com a camps per a la recuperació de la informació. Hem de subratllar la diferència que hi ha entre índex i productor. El primer com un de tants punts d'accés a la informació registrada en certs camps de la base de dades, on s'aconsella la utilització d'un llenguatge documental, que l'utilitzen tant les biblioteques com els arxius per indicar llocs, matèries, organismes o persones. Mentre que el del productor en els arxius és un concepte més ampli —com hem indicat anteriorment— i disposa de la seva norma específica per descriure aquest context.
2.3 Interoperabilitat
Entenem la interoperabilitat com la propietat d'un producte o d'un sistema que és capaç d'aconseguir la utilització de programari per diferents sistemes informàtics (sistemes operatius i aplicacions de programari), interconnectats per diferents tipus de xarxes, per a l'intercanvi d'informació o de dades. En els arxius, inicialment —anys 70 i 80—, la introducció de programari i maquinari va ser per a l'automatització de diferents unitats de descripció en bases de dades, moltes vegades amb la realització d'índexs, per afavorir la recuperació de la informació. Primer es va introduir en xarxes locals (Bell, 1975), posteriorment va aparèixer l'interès de compartir aquesta informació en línia (Arad; Bell, 1977-1978), com passava a les biblioteques i, finalment, l'automatització va contemplar la totalitat de la gestió en una organització (Vázquez de Parga, 1986). Des de la perspectiva de la recuperació de la informació ens interessa destacar la interoperabilitat des de dos aspectes:
- Intercanvi de dades. L'intercanvi de dades i informació s'efectua principalment mitjançant una estructura de dades (els camps de les bases de dades, o mitjançant scripts creats per a la transferència de les dades). A nivell europeu, el programa IDA (Intercanvi de Dades entre Administracions) ha estat una gran iniciativa que, des de 1998, ha generat experiències, estàndards i aplicacions per fer possible la interoperabilitat de les xarxes telemàtiques transeuropees destinades a l'intercanvi de dades entre administracions (Unión Europea, 1998), amb això s'ha aconseguit que els arxius siguin interoperables (Klischewski, 2004). A Espanya, el 2010, comença a regular-se l'Esquema Nacional d'Interoperabilitat en l'àmbit de l'Administració Electrònica (España, 2010). Tanmateix, en els arxius històrics que han decidit posar a disposició dels usuaris els seus fons, diferents sistemes de xarxes i programari ja existents han permès, des de fa més d'una dècada, l'intercanvi complet de dades i informació a Internet.
- Dades enllaçades o vinculades. En l'entorn d'aconseguir el web semàntic, l'aparició el 1999 de l'especificació RDF —Resource Description Framework— del World Wide Web Consortium (W3C) va ser l'inici que va permetre posar dades o metadades al web per al seu processament, i proporcionar interoperabilitat entre aplicacions que intercanvien informació llegible per màquina al web. Tim Berners-Lee (2006) va encunyar més tard el concepte de Linked Data, i assenyalava que amb les dades vinculades es poden trobar al web altres dades relacionades. No es tracta del Web Hipertext, sinó de la definició d'una sintaxi abstracta basada en RDF, que serveix per vincular la seva sintaxi concreta a la seva semàntica formal i inclou, entre d'altres, el tractament de referències URI (Universal Resource Identifier).
3 Anàlisi a partir de casos
La recuperació de la informació dels arxius que han posat a disposició dels usuaris la descripció dels seus continguts en línia s'ha de poder realitzar tant interrogant el productor —ISAAR (CPF) o EAC (CPF)—, com interrogant els camps de la descripció —principalment els estàndards ISAD (G) o EAD—, com interrogant la seva indexació —llenguatges documentals, especialment tesaurus, per a les matèries, geogràfics, entitats o persones— com sondejant la seva interoperabilitat —especialment a partir de les metadades RDF—.
3.1 Interrogació sobre el productor
En els arxius es descriu el productor —ja siguin institucions, persones o famílies— amb la finalitat de controlar el context que ha produït un fons documental. No té sentit invertir esforços a descriure productors que no s'enllacen, o que no s'enllaçaran, amb les descripcions dels fons documentals. Tampoc té sentit descriure en gran mesura un productor —la qual cosa esdevé gairebé una investigació científica d'història de les institucions— si aquesta informació no serveix directament per identificar el context i per recuperar la informació dels fons documentals arxivístics. Amb la identificació i descripció del productor garantirem també l'autenticitat i, si apliquem, per exemple, un OAIS —Open Archival Information System (ISO 14721, 2003)— aconseguim també la conservació de la documentació en el nostre sistema de gestió documental.
A Espanya la principal base de dades que utilitza la ISAAR (CPF), i alhora la EAC-CPF, està disponible en el Censo Guía de Archivos de España e Iberoamérica. Conté un total de 4.324 descripcions, i es poden fer cerques per persones, famílies o institucions. Les descripcions també es poden visualitzar segons la codificació EAC-CPF.
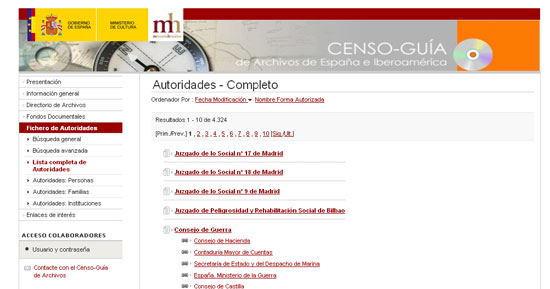
Figura 1. Descripció d'autoritats en el Censo-Guía (España)
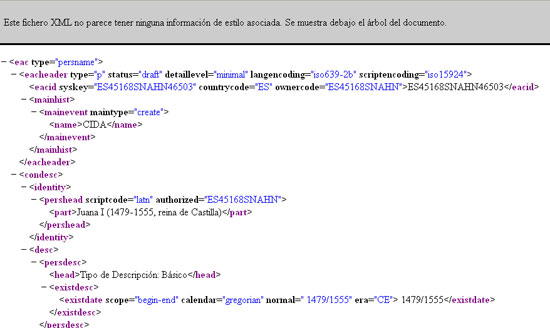
Figura 2. Visualització codificada EAC
En aquesta base de dades cal millora la unificació de criteris en algunes descripcions d'entitats, considerem escasses per exemple el cas del Consejo de Aragón i el Consejo Supremo de Aragón, ja que ens referim al mateix productor i cal disposar, en conseqüència, d'un identificador i no de dos identificadors (ES28079MCU193 i ES.8019.ACA/2). Però la millora més destacada que s'hauria de fer està relacionada amb la mateixa finalitat de la descripció del productor, recuperar els fons que aquest ha produït. En aquest sentit, tret d'algunes excepcions, la identificació del productor no enllaça amb la base de dades que descriu els fons documentals.
A nivell internacional, un dels projectes més interessants és SNAC (Social Networks and Archival Context Project). S'aprofita de l'estàndard EAC-CPF i de la tecnologia digital per "desbloquejar" les descripcions de les persones des de les fonts secundàries i integrar-les en noves utilitats, d'una banda, per crear eines de codi obert eficients que permetin els arxivers separar el procés de descriure les persones del de descriure els documents o unitats de descripció; i, d'altra banda, per crear un prototip integrat dels recursos històrics i sistemes d'accés que permetrà l'enllaç mutu de les descripcions de les persones amb les descripcions realitzades en els arxius, biblioteques i museus. Aquest prototip ja es troba en funcionament i permet efectuar cerques per persones, famílies o institucions, i enllaça amb les descripcions de les institucions en línia que disposen d'aquests fons documentals.
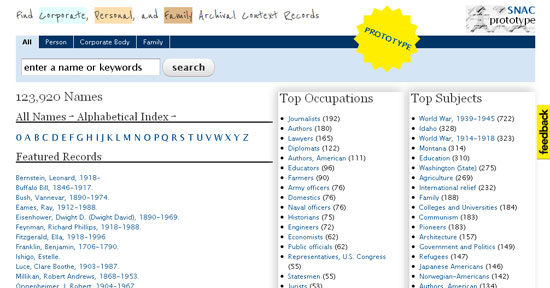
Figura 3. Prototip SNAC

Figura 4. Prototip SNAC. Exemple de descripció d'institució i enllaç amb les unitats de descripció relacionades
3.2 Interrogació sobre els camps de descripció
En els arxius, els camps de les unitats de descripció es regulen principalment pels estàndards ISAD (G) o per les EAD. Un dels principals avantatges d'aquests estàndards és que permeten la descripció multinivell. Una altra qüestió diferent és que el programari que ho suporta sigui capaç d'integrar la descripció multinivell a la seva base de dades. L'altre avantatge dels estàndards és que, finalment, s'ha aconseguit als arxius quelcom que ja passava a les biblioteques, i és fer possible la interoperabilitat de dades, ja que s'ha consensuat una estructura única de camps, i definir la funció d'aquests camps —com a les biblioteques el format MARC—. Qualsevol alteració del nombre dels camps o de la funció d'aquests romp amb un dels objectius d'aquests estàndards, que és fer possible la creació de xarxes entre arxius, o la interconnexió entre diferents bases de dades.
A Espanya, el Portal de Archivos Españoles (PARES) és el lloc web més important pel volum d'unitats de descripció realitzades i, com a valor afegit, per la disposició de documents digitalitzats en obert. La utilització dels estàndards ha facilitat la interconnexió entre els diferents arxius espanyols que hi ha en aquesta xarxa. La cerca avançada no permet individualitzar la interrogació per tots els camps de la ISAD (G), però disposa de suficients caixes de cerca per al rastreig de les paraules seleccionades en el llenguatge natural utilitzat en la descripció, o per al rastreig en els camps data, o fins i tot permet realitzar la cerca en arxius específics de la xarxa.
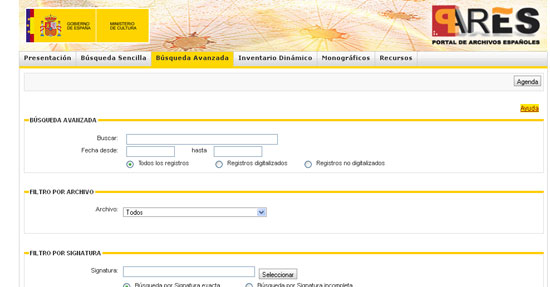
Figura 5. Portal de Archivos Españoles (PARES)
Com a exemples estrangers, el Archivo Nacional de Colombia, en el seu lloc web de consulta documental, permet fer una consulta per qualsevol camp de la ISAD (G) mitjançant la selecció en la casella "camp", i recuperar per diversos camps i segons els nivells de descripció i fons seleccionats. Aquest és un exemple del major aprofitament o integració dels camps ISAD (G), que hi ha a la base de dades, amb els camps de recuperació de la informació, que hi ha a l'OPAC.
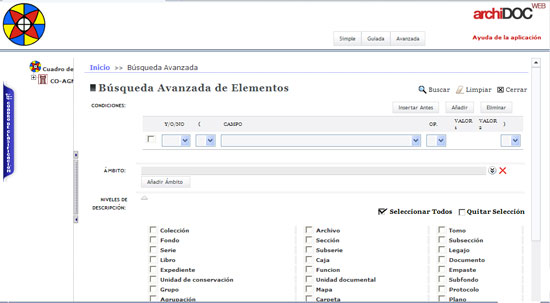
Figura 6. Archivo Nacional de Colombia. Cerca avançada
3.3 Interrogació per la indexació
De la mateixa forma que en els arxius històrics existeixen o existien les fitxes índex, ordenades alfabèticament per un vocable referit a la regesta de la unitat de descripció, en un sistema de gestió documental també és possible i convenient indexar les descripcions d'aquestes unitats. A les biblioteques és bastant freqüent utilitzar una llista com a llenguatge documental que controla el vocabulari de la indexació, tanmateix, en els arxius la pràctica que té més garanties d'eficàcia és la utilització de tesaurus com a llenguatge documental per a la indexació de matèries, entitats o institucions, geografia o persones (encara que aquest darrer, atesa l'escassa importància de la jerarquia, moltes vegades s'utilitza el mateix programari per al seu control, però s'exclou la jerarquia). Per a la indexació dels arxius produïts per les organitzacions s'estan creant tesaurus específics, com l'EUROVOC per a la documentació de la Unió Europea, utilitzat també per algunes administracions autonòmiques, i altres tesaurus per a arxius històrics (Giménez; Escrig, 2011).
Un bon exemple d'utilització del tesaurus per a les descripcions amb la ISAD (G) és AIM25. És un lloc web que proporciona accés en línia a les descripcions realitzades en els arxius de més de cent institucions, tant d'educació superior, com de societats científiques, organitzacions culturals o empreses que estan situades a l'àrea metropolitana de Londres. Aquestes institucions descriuen la seva documentació en diferents nivells, però AIM25 només recull les descripcions a nivell de col·lecció o fons. És un projecte amb més de deu anys que creix contínuament. Aquesta interconnexió entre AIM25 i les respectives entitats —més de 100— és possible perquè mantenen l'estructura dels camps de la ISAD (G) i la seva funcionalitat. Però, a més, han aconseguit incorporar un tesaurus únic que controla el vocabulari dels registres catalogràfics de totes les institucions, estructurat per noms de persones, matèries, geogràfics i entitats. El lloc web permet navegar pel vocabulari controlat dels tesaurus, a més d'accedir per la institució que té dipositat l'arxiu. Aquest sistema d'indexació i anàlisi documental permet recuperar la documentació pertinent.
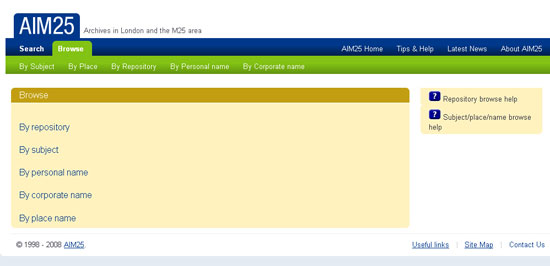
Figura 7. AIM25. Navegació per paraules clau
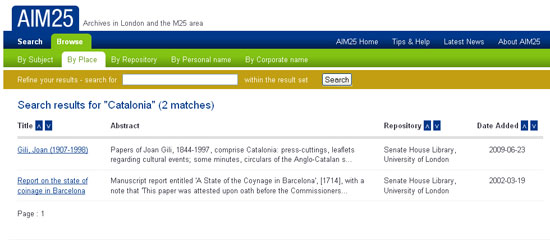
Figura 8. AIM25. Exemple de resultats indexats per "Catalonia"
A Espanya, el lloc web PARES també disposa d'un instrument per a la cerca per la indexació. Tanmateix, el seu funcionament indica que els diferents arxius espanyols estan utilitzant el llenguatge natural per a la indexació. No hi ha referències en el lloc web que disposin d'un llenguatge documental. La utilització del llenguatge natural indueix a la sinonímia, ja que no es dóna la univocitat dels descriptors. En un sistema de gestió documental, per bases de dades, impossibilita la recuperació total dels documents pertinents. Per exemple, el concepte Morisco el trobem indexat com "MORISCOS", "Morisco", "Moriscos de Marbella", "Moriscos" o "Bandolerismo. Moriscos de Marbella" —en aquest darrer terme s'han unit tres conceptes, dues matèries ("Bandolerismo" i "Moriscos") i un geogràfic ("Marbella")—. Això impossibilita la recuperació de la informació pertinent, atès que el sistema no dóna els mateixos resultats, per exemple, per a "Moriscos" que per a "Bandolerismo. Moriscos de Marbella". Per solucionar el problema cal que hi hagi un llenguatge controlat i que s'utilitzi en tot el sistema.
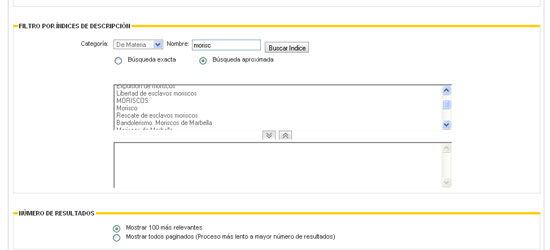
Figura 9. PARES. Cerca per índexs
3.4 Interoperabilitat web
Ens referim al web semàntic. Ja disposem d'instruments que fan possible la interoperabilitat de dades a Internet, simplement manquen les bones pràctiques i l'ús d'aquests instruments per fer possible que recuperem informació a partir de dades vinculades —Linked Data— de les unitats de descripció. Per això disposem d'uns mecanismes específics destinats a les màquines (Álvarez, 2008) amb els següents objectius: per evitar l'ambigüitat en la identificació (URI), per descriure els recursos (RDF), per modelar antologies (OWL), per realitzar cerques a bases de dades (SPARQL), i per expressar les regles i el seu intercanvi (RIF) —aquestes especificacions es poden trobar en aquesta pàgina web—.
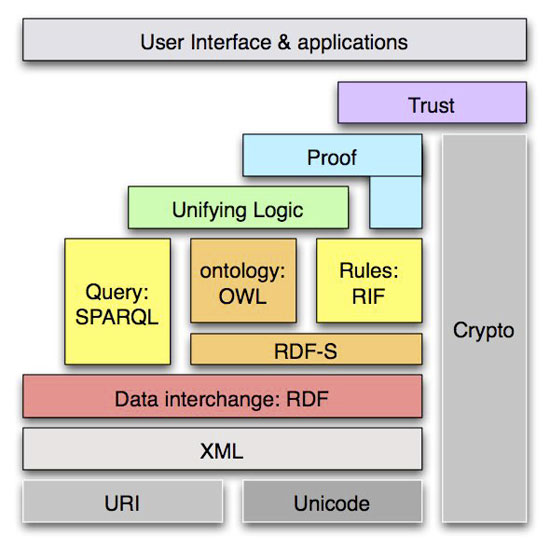
Figura 10. Imatge d'Álvarez (2008) sobre els mecanismes específics per a la interoperabilitat semàntica al web
Desconeixem si existeix algun arxiu que hagi implementat els mecanismes per a la interoperabilitat web. El que sí sabem és que s'està portant a terme en institucions documentals o bibliotecàries i, evidentment, l'utilitzen també per a la documentació procedent d'arxius que estan dipositada en aquesta. El projecte més interessant, en què participen institucions espanyoles, és Europeana. A Europeana es poden fer cerques en els fons d'unes 1.500 institucions col·laboradores. La interoperabilitat implementada permet a les persones explorar els recursos digitals existents a les institucions com museus, biblioteques, arxius i col·lecciones audiovisuals d'Europa, tot això en una xarxa multilingüe. Es poden trobar més de 15 milions d'articles, entre els quals s'inclouen imatges —pintures, dibuixos, mapes, fotos i imatges d'objectes de museu—, textos —llibres, premsa, cartes, diaris i documents d'arxiu—, àudios —música i paraula parlada en cilindres, cintes, discos i emissions de ràdio— i vídeos —pel·lícules, noticiaris i programes de TV—. Aquesta diversitat de documents i formats es pot recuperar des d'una única plataforma, gràcies a les bones pràctiques en el treball de descripció realitzat i a la implementació dels instruments d'interoperabilitat i web semàntic.
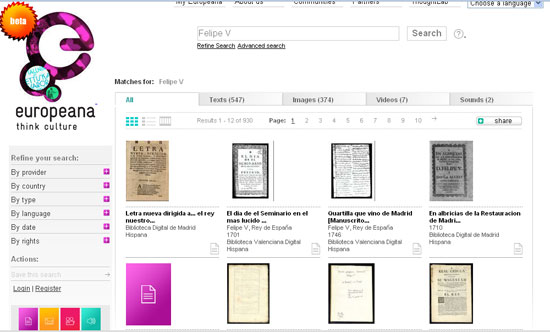
Figura 11. Europeana. Exemple de recuperació de la informació mitjançant el vocable "Felipe V": 547 textos, 374 imatges, 7 audiovisuals i 2 àudios
4 Conclusions
La feina que s'ha fet de forma tradicional en els arxius, per poder trobar els documents requerits per una petició, es pot traslladar perfectament a l'entorn web. Ara bé, l'èxit d'una eficaç recuperació de la informació a partir dels OPAC dels arxius dependrà fonamentalment de dos factors: de les bones pràctiques en la gestió de documents —podem destacar unes correctes classificacions per a la navegació multinivell, i unes correctes descripcions e indexacions per a la recuperació de la informació pertinent— i de l'ús de les TIC, amb especial èmfasi en l'adaptació al web semàntic —és el futur, que condicionarà la presència d'unes organitzacions o la seva omissió a Internet—. Això suposa un canvi de paradigma, ara centrat en l'usuari, qui imposa als arxivers el disseny dels sistemes d'accés a la informació i a la creació de serveis orientats als diversos perfils d'usuaris en el marc del web (Sebastià, 2009).
L'ús de les TIC no només és important per a l'entorn d'Internet, sinó també per a qualsevol organització que estigui gestionant documents en intranets. De fet, la major part de les organitzacions, en la seva eAdministració, no només tindran la necessitat de dipositar documents digitals en els seus servidors o sistemes d'emmagatzematge, sinó també de dissenyar l'arquitectura de la informació i el sistema de recuperació de la informació. No és cap descobriment si diem que, igual que en els arxius físics, el que no es descriu no es recupera —encara que utilitzem un o un altre dels mecanismes més costosos per recuperar allò que volem—, i unes pràctiques deficients en la descripció documental dificulten o impossibiliten la recuperació dels documents desitjats. Disposem de suficients instruments tecnològics, inclosos els recents estàndards de la W3C, i de prou instruments científics per aplicar-los a les nostres organitzacions, perquè no continuï passant el següent: les organitzacions dipositen grans volums de documents (físics o digitals) sense els instruments adequats per a la recuperació de la informació.
Si guardem els documents, i realitzem diversos treballs tècnics, és per poder recuperar-los davant les peticions. Si la recuperació de la informació no funciona d'una forma eficaç per a l'organització o els usuaris —en pertinència i rapidesa— tota la feina feta esdevé inútil.
Bibliografia
Abadal, E; Codina, Ll. (2005). Bases de datos documentales: características, funciones y método. Madrid: Síntesis.
Álvarez Espinar, M. (2008). "Interoperabilidad semántica en la Web". Congreso Nacional de BPMS. Madrid: W3C. <http://www.w3c.es/Presentaciones/2008/0220-semanticaBPMS-MA/ >. [Consulta: 18/09/2011].
Arad, A., Bell, L. (1977-1978). "Descripción Archivística. Un sistema general". Boletín ADPA, vol. 2, nº 2-3, pág. 35-42.
Bell, L. (1975). "Una investigación sobre el Tratamiento de Datos Archivísticos". Boletín ADPA, vol. 1, nº 3, pág. 15-26.
Berners-Lee, T. (2006). Linked Data. <http://www.w3.org/DesignIssues/LinkedData.html >. [Consulta: 9/09/2011].
Cook, M.; Procter, M. (2000). Manual of archival description. Vermont: Gower
Cox, Richard J. (1992). Managing institutional archives: Foundational Principles and Practices. Connecticut: Greenwood press
Cumming, Kate (2007). "Purposeful data: the roles and purposes of recordkeeping metadata". Records Management Journal, Vol. 17 Iss: 3, pp.186-200
EAC-CPF, Encoded Archival Context - Corporate Bodies, Persons, and Families. <http://eac.staatsbibliothek-berlin.de/ >. [Consulta: 5/09/2011].
España (2010). "Real Decreto 4/2010, de 8 de enero, por el que se regula el Esquema Nacional de Interoperabilidad en el ámbito de la Administración Electrónica". Boletín Oficial del Estado, nº 25, 29 de enero de 2010, pág. 8139-8156.
Giménez, V; Escrig, M. (2011). "Designing a Thesaurus to Give Visibility to the Historical Archives in the Archivo del Reino in Valencia". Knowledge Organization, 38, Nº 2, p. 153-166.
Heredia Herrera, A. (1988). Archivística General, Teoría y Práctica. Sevilla: Diputación Provincial.
ISO 14721:2003 Space data and information transfer systems - Open archival information system - Reference model. <http://www.iso.org/iso/catalogue_detail.htm?csnumber=24683 >. [Consulta: 17/09/2011].
Klischeswski, R. (2004). "Information Integration or Process Integration? How to Achieve Interoperability in Administration". Lecture Notes in Computer Science, 2004, Vol. 3183, pp. 57-65.
Lodolini, Elio (1993). Archivística. Principios y problemas. Madrid: Anabad.
Paul, K.D. (1988). "Archivist and Records Management". Managing archives and archival institutions. Chicago: The University of Chicago Press.
Sebastià Salat, M. (2009). "La transformación de los archivos y de la Archivística". Tabula, Nº 12, pp. 17-30.
SNAC, Social Networks and Archival Context Project. <http://socialarchive.iath.virginia.edu/index.html >. [Consulta: 17/09/2011].
Thibodeau, S. (1995). "Archival Context as Archival Authority Record: The ISAAR (CPF)". Archivaria 40, p. 75-85. <http://journals.sfu.ca/archivar/index.php/archivaria/article/view/12097/13084 >. [Consulta: 5/09/2011].
Unión Europea (1998). Propuesta de decisión del Consejo por la que se adopta un conjunto de acciones y medidas al objeto de garantizar la interoperabilidad de las redes telemáticas transeuropeas destinadas al intercambio de datos entre administraciones (IDA), así como el acceso a las mismas, Diario Oficial n° C 054 de 21/02/1998 p. 0012. <http://eur-lex.europa.eu/LexUriServ/LexUriServ.do?uri=CELEX:51997PC0661%2802%29:ES:HTML >. [Consulta: 9/09/2011].
Vázquez de Parga, M. (1986)."El P.I.A.: Plan de Informatización de Archivos". Boletín ANABAD, vol. 36 (1-2), pág. 79-83.
W3C (1999). Resource Description Framework (RDF) Model and Syntax Specification. <http://www.w3.org/TR/1999/REC-rdf-syntax-19990222/ >. [Consulta: 9/09/2011].
Data de recepció: 30/09/2011. Data d'acceptació: 01/11/2011.
Notes
1 Aquest treball ha estat realitzat en el projecte Infoscopos (La nova ecologia de la informació i la documentació en la societat del coneixement: desenvolupament d'una mètrica sistèmica, planificació d'un observatori per al seu seguiment i identificació de tendències bàsiques i reptes estratègics) és un projecte I+D subvencionat pel Ministerio de Ciencia e Innovación (CSO2009-0761).