Sumari
1. Introducció
2. Característiques de la informació estadística
2.1. Precisions terminològiques
2.2. Característiques de les dades estadístiques: la importància de la metadada / el context
2.3. Problemes de metodologia
3. Els productors: fonts o agències estadístiques
3.1. El concepte d'agència o font estadística
3.2. Sistema estadístic en un país concret: el cas d'Espanya
3.3. Sistema estadístic internacional
3.4. Redisseminació: el paper de les empreses privades
4. El producte: com es creen i difonen les estadístiques
4.1. Circuit estadístic: com es crea una estadística
4.2. Tipus de suports i sistemes de difusió
4.3. El preu de les dades
5. Els usuaris
5.1. El concepte d'alfabetització estadística (statistical literacy)
5.2. Identificar els usuaris
5.3. Què volen els usuaris?
6. Com cercar?
6.1. On cercar?
6.2. Interfícies: problemes de disseny
6.3. Mètodes de cerca
6.4. Metadades estadístiques
7. Dades agregades a les biblioteques
7.1. Quines dades per a quines biblioteques?
7.2. Què cal comprar?
7.3. Com difondre la informació i atendre els usuaris?
8. Microdades a les biblioteques
8.1. Dades base a les biblioteques
8.2. El problema del secret estadístic
8.3. Gratuïtat, pagament i arxius de dades socials
9. La investigació documental
10. Conclusions
11. Bibliografia
Resum [Abstract][Resumen]
Es presenta l'estat de la qüestió de les fonts d'informació estadística i el paper que les biblioteques poden tenir per difondre-les. Aquest sector està immers en un canvi accelerat fruit dels nous suports digitals i d'Internet, però alhora pateix la baixa alfabetització estadística de la majoria dels usuaris potencials. En primer lloc es fa una introducció a les dades estadístiques: característiques metodològiques; productors (fonts i agències); circuits de creació i distribució; necessitats dels usuaris; mètodes de cerca i interfícies. En segon lloc s'avalua el paper de les biblioteques en la compra, gestió i difusió d'aquest tipus de material, des de la referència bàsica fins a l'alta investigació.
1 Introducció
“Hi ha mentides, grans mentides i estadístiques.”
Citació atribuïda a Benjamin Disraeli, primer ministre anglès del s. XIX
La documentació ha dedicat poca atenció a les estadístiques com a font o tipus d'informació, com a mínim en comparació amb els estudis dedicats a la informació textual o audiovisual. És molt més fàcil trobar literatura professional dedicada a les estadístiques com a mètode d'avaluació, de gestió o de recerca.
La informació estadística té mala premsa. Per mostra, la citació que encapçala aquesta introducció i moltes altres que van en la mateixa línia.1 Això és irònic, ja que els mètodes quantitatius aspiren a mostrar la realitat de la manera més exacta i objectiva possible. Les raons d'aquesta desconfiança són múltiples, però una de les més importants és la deficient alfabetització matemàtica de bona part de la població.
Però Internet ha representat una democratització quasi total de la informació estadística. Tot just fa una dècada, la majoria de bases de dades numèriques només eren accessibles a especialistes. Avui en dia, en canvi, la majoria són accessibles a qualsevol persona amb una connexió a Internet. Per tant, tenim una contradicció aparent: un accés molt obert a una informació que no sempre s'entén.
En aquest context, quin és el paper de les biblioteques? Aquest article intenta respondre aquesta pregunta i alhora oferir una introducció als processos, als circuits de difusió, a les agències productores, etc. de les dades estadístiques. En resum, es pretén oferir un estat de la qüestió en un moment de canvi profund.
Aquest article es basa en diversos treballs duts a terme per al primer any del doctorat Informació i Documentació a l'Era Digital durant el curs 2003–04 i també en l'experiència professional acumulada a la Biblioteca de la Universitat Pompeu Fabra (UPF).
Abans de finalitzar aquesta introducció, cal agrair la col·laboració i l'ajuda de diverses persones: Elena Blanco (bibliotecària de la UPF, també especialitzada en dades estadístiques), Gemma Estrugas (bibliotecària de la Unitat d'Estadístiques de la UAB) i Roser Riera (bibliotecària de l'Institut d'Estadística de Catalunya). I molt especialment el professorat (i l'alumnat) de la UPF que, en exposar-nos les seves necessitats d'informació, també ens ha ensenyat tot el que calia saber sobre aquest món: Maia Güell, Javier Ramos, Francesc Pallarès, Walter García i un llarg etcètera.
2 Característiques de la informació estadística
2.1 Precisions terminològiques
“Experts need specialized terminology, but terminology can also serve as a barrier to finding or understanding the information”2
És important en tot treball definir, d'entrada, l'objecte d'estudi i els termes que s'utilitzaran. Encara més en aquest cas, ja que la terminologia no és gaire clara i abunda en termes directament traduïts de l'anglès.3 En primer lloc, el terme dades (en anglès data) és molt utilitzat, però també és ambigu. Dades significa simplement ‘fets' per contraposició a ‘interpretació' o ‘opinions', i també per diferenciar-lo de conceptes com ara informació o coneixement. Però en molts documents, especialment els escrits en anglès, acaba sent sinònim de dades estadístiques. En aquest sentit, el trobem en multitud de termes compostos anglesos: data file, data archive, social data, etc., que són traduïts al català (i semblantment en castellà) com a fitxer de dades, arxiu de dades i dades socials.
Dades estadístiques seria el terme més correcte i el que s'utilitza en aquest article de manera habitual. Segons la definició del Termcat (http://www.termcat.net/) és el “conjunt de dades recollides, classificades, analitzades d'acord amb mètodes matemàtics i interpretades, relatives a un conjunt d'elements”. Es tracta d'una paraula genèrica i que s'utilitza en el llenguatge corrent. Però estrictament parlant només serien estadístiques les dades tractades amb mètodes semblants. Per això en el context anglosaxó també s'utilitza l'expressió dades numèriques (en anglès numeric/al data). En teoria no són termes exactament sinònims, ja que numèric seria una mica més ampli que estadístic. Però s'utilitzen de manera força indistinta.
Utilitzarem el terme base de dades estadística per a les bases de dades d'aquest tipus d'informació. En anglès s'utilitza molt data bank, per contraposició a data base. Data bank o banc de dades seria per a les bases de dades no bibliogràfiques, i especialment les estadístiques. Però és un terme una mica ambigu, així és que base de dades estadística/numèrica resulta millor. Fitxer de dades (en anglès dataset o datafile) designaria, en canvi, un fitxer informàtic que conté informació estadística però sense programari de recuperació.
Al llarg de l'article i a mesura que es consideri necessari s'aniran definint altres termes més especialitzats.
2.2 Característiques de les dades estadístiques: la importància de la metadada / el context
“Without metadata, a number has no meaning”4
“Statistics are highly compressed forms of information. Standing alone, as individual numbers, they have little meaning. It is only within the context of their place in a particular table that meaning is provided. Column and row names provide important information about the meaning of the number. Additionally, one must know the units of measurement, the methods by which the data were collected and analyzed, and sometimes a particular number's relationship to others (such as in a time-series).”5
La informació numèrica és tan omnipresent en la societat, que solem oblidar que és molt diferent de la informació textual. Té característiques i dinàmiques pròpies que determinen des dels mètodes de cerca fins a les necessitats dels usuaris.
El principal tret definitori de la dada estadística és la seva dependència del context o metadada. Imaginem que tenim aquesta xifra: 1,29. Què vol dir en si mateixa? No res. En canvi, si va acompanyada de la frase “taxa de fertilitat a Espanya el 2003”, tot d'una pren significat. Aquest “context” de la informació numèrica normalment s'estructura en tres o quatre variables, que serien: a) tema, b) lloc, c) temps i d) unitat.
Per exemple:
Tema Lloc Temps Unitat 1,29 Fertilitat Espanya 2003 Taxa (mitjana) 23,090 PIB per càpita França 1998 Dòlars “internacionals” 76 Àrea forestal Finlàndia 1995 Tant per cent (%)
Si canviem qualsevol de les variables, obtenim una xifra diferent. Si tenim diverses xifres corresponents a diferents anys (o mesos, trimestres, etc.), disposem d'una sèrie temporal o sèrie estadística. A més a més, rarament una xifra és significativa per si sola. Si diem que el PIB espanyol ha crescut un 2,4 % el 2004, això és molt o poc? Doncs és una mica menys que el 2001 (2,8 %), però força més que el 2000 (2 %). I també ho podem comparar geogràficament: aquest 2,4 % de creixement d'Espanya és força més alt que a Itàlia (1,1 %), però més baix que als Estats Units (4 %) per al mateix any.
2.3 Problemes de metodologia
Per avaluar correctament una dada estadística és vital conèixer la metodologia que s'ha utilitzat per crear-la, la qual cosa implica també un bon coneixement de la terminologia. Per exemple, quanta gent coneix què és i com es calcula el PIB? I quina diferència hi ha amb el PNB? O com es calcula l'IPC? Malgrat tot, la majoria de la població confia en aquestes xifres.
Atès que les estadístiques serveixen bàsicament per fer comparacions, és vital que les dades siguin metodològicament comparables. Per exemple, si trobem que l'atur el 2004 al Regne Unit (4,7) és molt més baix que a França (9,7), abans hem d'estar segurs que estem parlant del mateix concepte. Si el Regne Unit i França compten els aturats de manera diferent, difícilment es podrà treure cap conclusió. En l'àmbit de l'estadística oficial (la que recull l'Administració pública) es pot dir que no hi ha gaires problemes de metodologia. Hi ha sistemes, protocols i acords en l'àmbit internacional que asseguren que les xifres es recullen de la mateixa manera. Per exemple, en el cas de l'atur, segons les normes de l'Oficina Internacional del Treball (OIT). O es comprova que les classificacions siguin equivalents entre si, com ara la classificació d'activitats econòmiques de l'ONU (ISIC, http://unstats.un.org/unsd/cr/registry/regcst.asp?Cl=27&Lg=1) respecte de la NACE europea (http://europa.eu.int/comm/eurostat/ramon/) i la Clasificación nacional de actividades económicas (CNAE, http://www.ine.es/inebase/cgi/um?M=/t40/cnae93rev1/&O=inebase&N=&L=0) espanyola.
Cal tenir en compte que, de vegades, hi ha diversos mètodes per quantificar la mateixa cosa. Així, per exemple, no sol ser el mateix l'atur registrat i el que es dedueix de les enquestes de treball o població activa. En el primer cas és un nombre força exacte que només recull els aturats que estan registrats en una oficina de col·locació o en una entitat o ens similars. En el segon es tracta d'una enquesta que es duu a terme sobre una mostra de ciutadans i que permet fer aflorar les persones sense feina, però que poden no estar apuntades en cap oficina. Aquest és el típic cas que desconcerta una persona sense coneixements de metodologia.
També hi ha la qüestió de la terminologia purament matemàtica. Així, una mateixa xifra es pot presentar de diferents maneres: total, taxa, tant per cent, mitjana, número índex. Una unitat tan simple com és la moneda nacional d'un país es pot expressar en nombres corrents o constants, segons si es té en compte o no la inflació acumulada.
En un món ideal els usuaris haurien de tenir uns coneixements mínims sobre aquestes qüestions. Però en el món real no sempre és així, i potser una de les funcions de la biblioteca és adreçar els usuaris a la font estadística adequada al seu nivell. Exemple: una base de dades econòmica mínimament complexa pot presentar el PIB calculat de tres o quatre maneres diferents. Però un usuari que només vulgui dur a terme una comparació entre països preferirà una font en la qual aquesta dada estigui presentada en dòlars i d'una manera simple.
3 Els productors: fonts o agències estadístiques
3.1 El concepte d'agència o font estadística
La producció d'estadístiques és un procés que no s'assembla al circuit editorial habitual. Enlloc d'autors o editorials, es basa en l'agència o font estadística (en anglès statistical source/agency). Què és una font o agència estadística? Es tracta d'una entitat que recull, processa i distribueix dades estadístiques. Es pot tractar d'entitats oficials plenament dedicades a aquesta funció —Eurostat, Instituto Nacional de Estadística (INE), Centro de Investigaciones Sociológicas (CIS), etc.—, entitats oficials que produeixen estadístiques encara que aquesta no sigui la seva activitat principal (Organización de Cooperación y Desarrollo Económicos —OCDE—, ONU, etc.), o bé entitats privades (associacions professionals, empreses de màrqueting, etc.). Font estadística és fins a cert punt sinònim d'agència estadística, encara que agència se sol aplicar més restrictivament a les fonts oficials.6
El concepte d'agència o font és important, ja que és la base de tot el sistema. Quan se cita o es reprodueix una estadística (per exemple, per acompanyar el text d'un article o llibre), se sol esmentar com a font l'entitat que l'ha produïda, i més secundàriament el títol de la publicació o base de dades d'on s'ha extret la informació. La citació de la font permet jutjar la fiabilitat de les dades i facilita a l'usuari la tasca de comprovar-les o actualitzar-les.
3.2 Sistema estadístic en un país concret: el cas d'Espanya
Hi ha fonts oficials i fonts no oficials, fonts d'àmbits internacional, nacional i local, i fonts generals i fonts temàtiques. Però les estadístiques més conegudes són les produïdes pels sistemes estadístics oficials de cada país. Aquest sistema és gestionat per i per a l'Administració, i la seva funció principal no és oferir informació al públic en general, sinó proporcionar al govern en un sentit ampli les dades que necessita per crear i posar en marxa polítiques públiques. D'on s'extreu aquesta informació? Ho veurem més a fons a l'apartat següent, però la immensa majoria de les dades tenen l'origen en els processos administratius. Quan aquests són insuficients, es fan servir enquestes. Tot el sistema es regula per mitjà de lleis, organigrames i programes a llarg termini. Així se sap quines dades cal recollir, amb quina metodologia i quina entitat ho ha de fer. Cal que sigui així a causa de la complexitat extrema de tot el procediment. El revers de la moneda és la rigidesa i la burocratització dels sistemes estadístics oficials.
La peça central del sistema és l'agència estadística central de cada país, en el nostre cas l'Instituto Estadístico de España (INE, http://www.ine.es/).7 L'INE és l'agència de l'Administració central dedicada exclusivament a recollir, gestionar i difondre dades estadístiques. També és l'enllaç d'Espanya (estadísticament parlant) amb altres agències similars però d'àmbit supranacional o internacional. No és l'única entitat oficial que recull estadístiques. Aquesta tasca està repartida a tota l'Administració mitjançant l'Inventario de Operaciones Estadísticas de la Administración Central del Estado (IOE, http://www.ine.es/ioe/ioeOrg.jsp?cod=00000000&L=0). Però l'INE és qui coordina tot el sistema i també és el punt central de difusió. Així, la seva base de dades INEBase inclou dades de tot l'IOE. Amb tot, les diverses entitats poden difondre les seves estadístiques pel seu compte, i de vegades amb un nivell de detall més elevat que no pas l'INE.
De la mateixa manera que hi ha diversos àmbits de l'Administració (estatal, autonòmica i local), hi ha diversos àmbits d'estadística oficial. L'INE recull dades en diferents àmbits de “desagregació territorial”: nacional, autonòmic, provincial, local. Però també delega algunes funcions en les agències estadístiques autonòmiques, les quals coordina. Actualment es pot dir que quasi totes les comunitats autònomes en tenen una. Duen a terme una feina important en oferir estudis especialitzats i dades en un nivell de desagregació més detallat que no pas l'INE. Un exemple seria l'Institut d'Estadística de Catalunya (IDESCAT, http://www.idescat.net/). Per acabar, les administracions locals són també importants. Per exemple, el padró és responsabilitat dels ajuntaments. Ara bé, només els ajuntaments més importants es poden permetre disposar d'un departament d'estadística o una unitat similar propis, com ara el Departament d'Estadístiques de l'Ajuntament de Barcelona (http://www.bcn.es/estadistica/catala/index.htm).
En un àmbit lleugerament diferent trobem el Centro de Investigaciones Sociológicas (CIS, http://www.cis.es/), que és l'entitat oficial encarregada de dur a terme, arxivar i difondre enquestes d'opinió i estudis similars. El seu web ho anomena l'estudi científic de la societat espanyola. Aquest tipus d'entitat s'anomena també arxiu de dades (en anglès data archive). Es tracta d'un servei que arxiva i permet cercar, difondre i accedir a dades estadístiques de tipus social, en especial enquestes. Una agència estadística pot ser també un arxiu de dades, però el terme s'aplica més aviat a centres que recullen dades provinents de diverses fonts. A Espanya, el CIS depèn de l'Administració, en concret del Ministerio de la Presidencia; en altres països aquests arxius solen estar vinculats a universitats o centres d'investigació.
Hi ha, però, moltes estadístiques que queden fora del sistema oficial. Sigui perquè l'Estat no disposa d'eines per recollir-les, sigui perquè tampoc no hi té gaire interès. Hi ha diversos nivells: a) entitats privades però sense ànim de lucre que duen a terme o financen enquestes socials; b) associacions sectorials i/o professionals que s'encarreguen de recollir dades dins del seu àmbit d'actuació; c) dades que les empreses generen com a part del seu negoci, com per exemple els comptes anuals d'empreses, i d) dades generades per empreses que es dediquen directament a això, com ara les de màrqueting.8
3.3 Sistema estadístic internacional
L'institut estadístic oficial de cada país transmet les dades a les agències internacionals de les quals el país forma part. Poden ser institucions regionals (en el sentit d'agrupar diversos països sobre una base geogràfica o cultural, com ara la Unió Europea o l'Asian Development Bank) o internacionals (com ara les Nacions Unides). Poden encarregar-se de tot tipus de dades o només de les d'una temàtica determinada. Aquestes agències no recullen les dades, ja que els sistemes estadístics nacionals els les proporcionen. El que sí que fan és harmonitzar-les, o sigui, tractar-les per tal que siguin comparables. Fet això, les difonen i ofereixen, així, fonts estadístiques excel·lents per a la comparació internacional.
En el nostre context, l'agència d'aquest tipus més important és Eurostat (http://epp.eurostat.cec.eu.int/), l'institut estadístic de la Unió Europea. Per sobre d'Eurostat no es pot dir que hi hagi una “agència estadística mundial”, encara que la Divisió Estadística de les Nacions Unides (http://unstats.un.org/unsd/) s'hi acosta bastant. Per a la resta tenim diverses associacions regionals (per exemple, l'OCDE) i tot un seguit d'entitats sectorials —com ara el Fons Monetari Internacional (FMI), l'Organització Mundial del Comerç (OMC), la Unesco, l'Organització Internacional del Treball (OIT), etc., que recopilen i difonen dades estadístiques del seu àmbit d'actuació.
3.4 Redisseminació: el paper de les empreses privades
En aquest context, hi ha empreses que comercialitzin estadístiques però no les produeixin? No són nombroses però n'hi ha, i es dediquen fonamentalment a dues funcions. La primera és la redisseminació: comprar dades a les agències oficials i revendre-les. Normalment això implica comprar dades a diverses agències i/o aplicar-hi un programari de recuperació que permeti una cerca millorada i conjunta.9 La segona funció és recopilar dades estadístiques molt detallades del sector privat, que les agències oficials no gestionen. Per exemple, les dades financeres, borsàries i de comptes d'empreses (un exemple en l'àmbit espanyol seria el SABI: Sistema de análisis de balances ibéricos).
En molts casos les dues funcions es combinen. S'ofereix un producte que inclou dades numèriques privades i públiques, juntament amb un programari de recuperació normalment complex (per exemple, les bases de dades Datastream o Compustat) i una actualització molt acurada. Les bases de dades resultants solen ser molt cares, a causa de dos factors. Primer, que crear i sobretot mantenir aquestes bases de dades requereix una inversió enorme i el preu està, lògicament, en proporció. El segon factor deriva del primer: aquestes empreses no tenen gaire competència. A més a més, la majoria dels seus clients (analistes financers, bancs i institucions financeres, grans empreses, etc.) s'ho poden permetre.
4. El producte: com es creen i difonen les estadístiques
4.1 Circuit estadístic: com es crea una estadística
La creació d'una estadística passa per tres fases: la recollida de les dades, el tractament i la difusió del resultat final.
Recollida de les dades
Les dades base de les estadístiques oficials es recullen mitjançant dos mètodes: procediments administratius i enquestes per mostra. En el primer cas es pot dir que es recullen a través de quasi totes les relacions que una persona, física o jurídica, manté amb l'Administració pública. En són exemples els registres (naixements, matrimonis, defuncions, entitats, etc.), els pagaments d'impostos, les taxes i les duanes, les altes i les baixes hospitalàries, etc.
Però hi ha moltes dades que no es poden recollir per aquesta via, i aleshores les agències oficials recorren a enquestes. Una enquesta consta d'un formulari amb una sèrie més o menys llarga de preguntes que es formulen a persones o entitats. Hi ha un tipus d'enquesta en la qual es pregunta a tots els habitants del país: el cens. És l'enquesta més completa que es pot fer i també el “retrat” estadístic més fiable d'una societat. Però organitzar-la i tractar-la és tan complex que només es fa cada deu anys. Per això la resta d'enquestes es fan sobre una mostra de la població. Es trien una sèrie de persones que representen, a escala, el total, i després els resultats s'extrapolen. L'ideal (com a mínim des del punt de vista dels investigadors socials) és que aquestes enquestes siguin longitudinals, o sigui, que es repeteixi la mateixa enquesta a la mateixa mostra de persones o a una de similar a intervals regulars.
Evidentment, les entitats privades que també creen dades estadístiques no tenen els recursos administratius de l'Estat. En alguns casos poden recollir certes dades de manera força automàtica (comptes d'empreses, altes i baixes, etc.), però en molts casos les seves dades provenen d'enquestes.
Tractament de les dades: dades no agregades o microdades
A les dades base se'ls apliquen diversos mètodes estadístics per crear les dades finals. Però el procés que explicarem aquí amb detall és el que se segueix en les enquestes, ja que els fitxers resultants tenen molta importància per als investigadors socials. Les dades que es recullen mitjançant les enquestes es traspassen a fitxers informàtics anomenats microdades (en anglès microdata). Les microdades són fitxers on es recullen les respostes individuals de cada persona entrevistada, codificades de manera numèrica. En brut tenen l'aspecte de llargues sèries numèriques:
100108622061123100000000570430110000
100108622060000000000000000000000000
100108622060444242000200414444490134
100108622060022222212212222222222222
Oberts amb un programari estadístic, el resultat és una taula on cada fila és una persona, i cada columna correspon a una pregunta. La resposta està codificada numèricament. Per exemple, el gènere de l'entrevistat: home = 1 i dona = 2.
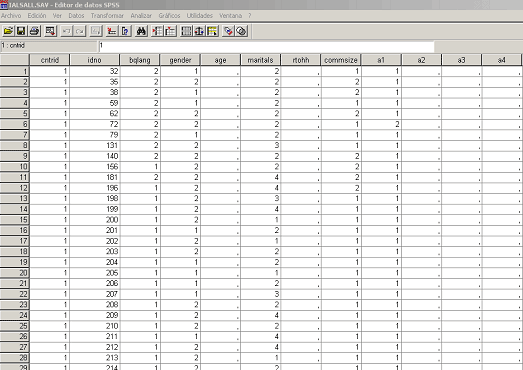
Figura 1. Fitxer de microdades visualitzat amb el programari SPSS.
Per poder interpretar el fitxer, doncs, necessitem el llibre de codis o qüestionari, on consten les preguntes i la codificació de les respostes.

Figura 2. Qüestionari d'un fitxer de microdades.
Aquests fitxers no són gaire coneguts pel públic en general, però tenen gran interès per a molts investigadors, ja que permeten dur a terme recerca social avançada. Les agències ho saben i els ofereixen amb algunes restriccions a causa de la confidencialitat de les dades personals.
Resultat final: dades agregades o estadístiques
Sobre la base d'aquests fitxers de microdades i registres administratius, les agències com ara l'INE generen els resultats agregats, que és el que normalment es coneix per dades estadístiques. El terme resultat agregat, molt tècnic, indica que els valors s'han agregat d'acord amb certes unitats col·lectives o grups. Per exemple, per conèixer l'atur femení s'agreguen totes les respostes individuals que estan codificades com a persones del sexe femení. Es poden agrupar sota múltiples variables: per exemple, dones casades, amb fills menors d'edat, en atur i amb residència a Catalunya. Els resultats s'introdueixen en una base de dades i ja es poden difondre mitjançant diversos canals que veurem a l'apartat següent.
4.2 Tipus de suports i sistemes de difusió
“Un estudiant de secundària té avui un millor accés a dades estadístiques bàsiques que no pas un alt funcionari fa només cinc anys.” (Katze, 1997)10
El procés de difusió de les estadístiques ha canviat moltíssim durant els darrers deu o vint anys i, de fet, potser és un dels sectors que ha passat més ràpidament i radicalment primer als nous suports digitals i després a Internet. La difusió tradicional es basava en la publicació en paper de revistes i monografies, la més típica de les quals era l'anuari estadístic. Aquestes publicacions es continuen editant, però ja no són el mètode de difusió principal.
El primer avenç fou la informatització de les agències, cosa que va permetre la consulta dels investigadors, in situ —a la mateixa agència— o per mitjà d'una teledocumentació primitiva. La segona revolució fou la dels disquets i CD-ROM. Va permetre que les bases de dades o una porció d'aquestes es poguessin consultar de manera electrònica fora de l'agència. Aquests suports electrònics van començar a acompanyar les publicacions en paper com a material d'acompanyament, i en alguns casos les substituïen.
Però la revolució definitiva ha estat Internet. Des de qualsevol ordinador es pot consultar l'estadística de qualsevol país o tema, encara que aquest ordinador estigui a l'altra punta del món. Només cal, evidentment, que l'agència estadística en faciliti l'accés per mitjà del seu web. Tot d'una, un tipus d'informació que fins fa poc era limitada per als especialistes s'ha posat a l'abast del públic en general.
El principal problema dels usuaris ha canviat: les dades ara són accessibles, però l'estructura i la cerca d'aquestes bases de dades no sempre són fàcils. En altres paraules, molts cops l'usuari pot aconseguir la informació, però o bé li costa de localitzar o bé no l'acaba d'entendre. És en aquest camp que es concentren la majoria d'esforços de la investigació documental.11
4.3 El preu de les dades
“Because the public has already paid for the information through taxes, it is argued that information should be made available at merely the reproduction cost”12
Aquestes dades ofertes per Internet són sempre d'accés lliure? Depèn de l'agència. La situació es podria resumir dient que les agències oficials nacionals solen oferir les dades en lliure accés; les agències internacionals, d'accés lliure o a preu polític, i les privades, a un preu elevat. Evidentment és una simplificació excessiva que amaga disparitats, però en línies generals és així.
La majoria d'agències oficials proporcionen com a mínim una part de les dades en lliure accés per Internet. Això és una derivació de l'etapa anterior, quan les publicacions en paper o CD-ROM ja solien tenir normalment un preu “polític” molt baix o fins i tot eren distribuïdes gratuïtament a universitats o biblioteques. La justificació és que aquestes dades s'han recopilat i tractat amb diners del contribuent i, per tant, aquest té dret a poder-les consultar amb un cost mínim. Aquesta idea, molt arrelada als països de tradició anglosaxona, s'ha anat estenent progressivament. Actualment, a Espanya les dades estadístiques oficials són d'accés lliure en la majoria de casos. En el cas de la Unió Europea (Eurostat), van ser de pagament fins a l'octubre de 2004, però ara ja són gratuïtes. En definitiva, és cada agència nacional la que fixa la política corresponent, però en general la gratuïtat s'està imposant en l'estadística oficial.
El cas de les microdades és diferent. Algunes agències les ofereixen gratuïtament (com l'INE des del juny de 2004), o bé a preus raonables (com el CIS), o bé a preus molt elevats (el cas d'Eurostat). També són dades públiques, però es considera que només interessen a un sector molt petit d'usuaris (investigadors) i, per tant, la idea de servei públic no és tan evident. A més, tenen problemes de protecció de dades personals que fan preferible en molts casos una difusió controlada.
Pel que fa a les agències supranacionals o internacionals, la tendència sembla l'accés lliure, sobretot per a les dades més bàsiques. Si les dades són de pagament, el preu sol ser polític, limitat a recuperar costos i amb importants descomptes “socials” (universitats, institucions sense ànim de lucre, països del tercer món, etc.).
Una altra cosa són, evidentment, les bases de dades de titularitat privada. En aquest cas, el tipus d'informació (financera o econòmica) i els seus clients habituals (bancs, institucions financeres, analistes de borsa) fan que els preus siguin molt més alts. Les institucions docents poden intentar aconseguir descomptes, però no sempre se n'ofereixen.
5 Els usuaris
“The challenge is to provide and share data on demand, internally and externally to power users, experts and decision makers; whilst ensuring access to information for novice users and a wider audience that will often include the general public”13
5.1 El concepte d'alfabetització estadística (statistical literacy)
Els darrers anys s'ha popularitzat el terme alfabetització informacional, traduït directament de l'anglès information literacy. En la mateixa línia, molts especialistes parlen d'alfabetització estadística (també anomenada matemàtica o quantitativa), ja que cada cop hi ha més accés a les dades numèriques, però molts usuaris no saben realment on cercar-les, com plantejar la cerca, la metodologia que hi ha al darrere, com valorar-les, etc.
Les mancances es troben en tres grans àmbits:
a) Una base matemàtica molt deficient.14
b) La terminologia, principalment l'econòmica. Així, molts usuaris no saben realment què és el PIB, el PNB, o el PPP. Tampoc no en coneixen els equivalents anglesos, quan l'anglès és l'idioma de cerca de la majoria de bases de dades estadístiques.
c) Coneixements de metodologia. Dit d'una altra manera, els usuaris no saben com es recullen i calculen les estadístiques i, per tant, no tenen, veritablement, eines per criticar-les.És un problema greu que retroalimenta la “mala fama” que té aquest tipus d'informació. Per exemple, si l'usuari no sap que hi ha dues maneres molt diferents de recollir les dades sobre l'atur (el registrat o per enquesta de població activa), quedarà molt desconcertat en trobar dues xifres diferents. El problema empitjora quan els mitjans de comunicació publiquen resultats de manera confusa o els polítics els utilitzen com a arma dialèctica. Hi ha un adagi estadístic per a aquest tipus d'ús: “He uses statistics as a drunken man uses lampposts —for support rather than for illumination”.15
Davant els crits d'alarma dels experts, han sorgit algunes iniciatives interessants. D'una banda, es multipliquen els llibres i llocs web que intenten fer de l'estadística una matèria, si no entretinguda, com a mínim una mica més digerible. En la mateixa línia o similar, diverses iniciatives exposen les “mentides estadístiques” dels mitjans o dels polítics, amb explicacions detallades i una dosi d'humor necessària. Per acabar, diversos projectes i publicacions intenten ajudar el professorat en la difícil tasca de la docència estadística.16 Per variar, els esforços provenen quasi exclusivament dels països anglosaxons.17
5.2 Identificar els usuaris
“There is a varied and unpredictable demand for European data”18
Les estadístiques no són un tema, sinó una manera de presentar la informació. Des d'aquest punt de vista, identificar-ne els usuaris és impossible. Evidentment, les estadístiques estan més lligades a certes àrees de coneixement: economia, sociologia, administració, etc. Però es pot trobar informació estadística de qualsevol tema: oci i espectacles, medicina, medi ambient, justícia, etc.
Malgrat tot, alguns estudis han intentat classificar els usuaris de les estadístiques oficials; valgui com a exemple el treball d'Hert/Marchionini,19 que va analitzar l'ús de diversos webs estadístics nord-americans. A grans trets se'n van identificar de vuit tipus:
- Sector privat: usuaris d'empreses privades que necessiten dades per al seu negoci.
- Universitats: investigadors, estudiants universitaris i personal en general.
- Mitjans de comunicació: periodistes.
- Públic en general: usuaris que busquen dades per raons privades i no de feina.
- Govern: funcionaris i polítics, per raons d'administració i política pública.
- Educació: professorat i alumnat no universitaris.
- Estadística: especialistes en el tema.
- Biblioteques, museus i altres entitats sense ànim de lucre.
Una altra manera de classificar els usuaris consisteix a identificar els nivells de demanda. Perquè no és el mateix un alumne de secundària sense coneixements d'estadística que un investigador universitari especialista en matemàtica. Identificar el nivell de complexitat permetrà també seleccionar el tipus de font estadística més adequada per a cada un:
- Demanda puntual i/o bàsica: feta per un usuari que no és especialista i que generalment només demana unes dades bàsiques i fàcilment comprensibles. Molts webs d'agències estadístiques solen tenir una secció de novetats, dades bàsiques, notes de premsa, etc., destinada a aquest tipus de demandes. En molts casos un anuari, un article o un manual que inclogui dades estadístiques serà més ben rebut que una base de dades complexa. També es demanaran unitats simples i fàcilment comparables. Per exemple, si es vol comparar el PIB per càpita de diferents països, és preferible que estigui tot en dòlars.
- Demanda de nivell mitjà: feta per un usuari amb uns coneixements matemàtics i/o de metodologia mínims. És la típica demanda per motius de docència (professorat) i aprenentatge (alumnat) en l'àmbit universitari. Els primers volen trobar dades que puguin utilitzar en les seves classes. Els darrers, dades per completar treballs de curs. Molts altres tipus d'usuaris, des de periodistes fins a metges, també poden necessitar dades en aquest nivell. En aquest cas, les millors fonts són les bases de dades “estàndard” —ja siguin de pagament, ja siguin d'accés lliure— de les agències estadístiques oficials.
- Demanda de recerca: feta per un usuari especialitzat i amb bons coneixements matemàtics i/o de metodologia. És el nivell més alt. Pot ser recerca universitària, però també estudis a fons sobre polítiques públiques de l'Administració o bé estudis de màrqueting del sector privat. Es necessiten bases de dades complexes, i també és el tipus d'usuari que fa un ús intensiu dels fitxers de microdades.
5.3 Què volen els usuaris?
No hi ha gaires estudis sobre què volen realment els usuaris. Aquesta manca de recerca es deu a diversos factors. La dispersió dels possibles usuaris i les diferències abismals de nivell fan que sigui difícil trobar un sistema que funcioni per a tothom. A més, fa relativament pocs anys que aquesta informació és accessible, així doncs, tampoc no hi ha hagut prou temps per fer-ne estudis. La majoria dels que hi ha s'han dut a terme en països anglosaxons. Per exemple, els de Hyland i Gould (1998), Hert i Marchionini (1998), Blakemore i McKeever (2001), Marchionini (2002), Denn i Haas (2003), etc. Les demandes dels usuaris es poden classificar en dos grans grups: les que es refereixen a les dades en si i les referents a l'accés.
Demandes dels usuaris referents a les dades en si
- Actualització de les dades: els usuaris desitgen que sigui al més ràpida possible. És una demanda raonable a primera vista, però no sempre és possible. Les dades segueixen un procés d'elaboració complex. Entre que es recullen, es processen i es difonen passa un temps. Si es tracta d'una entitat supranacional, hi ha un període suplementari fins que són enviades per les agències nacionals, i és possible que no hi hagi la mateixa actualització per a tots els països.
- Nivell de desagregació geogràfica: molts usuaris es queixen que les dades són bones en l'àmbit nacional i dels primers àmbits administratius, però més deficients en l'àmbit local. La queixa té una part de raó, però també cal tenir en compte que moltes dades es recullen per mitjà d'enquestes d'àmbit nacional. Això vol dir que se selecciona una mostra significativa i després s'extrapolen els resultats a tot el país. Però, evidentment, no es poden extrapolar els resultats en el cas d'unitats geogràfiques reduïdes. Així, per a segons quins temes, només es tenen dades cada deu anys, quan es fan censos complets a tots els habitants.
- Cobertura cronològica: els usuaris volen no solament dades ben actualitzades, sinó també dades al més antigues possible. Aquest tema s'està solucionant lentament, a mesura que les agències informatitzen els fons més antics. El problema és que, quan les dades no estan informatitzades, l'alternativa és directament el suport paper. I els usuaris odien “cordialment” el suport paper, ja que implica haver de recopilar les dades. Una altra demanda corrent és una periodicitat més bona de les dades, ja que sempre hi ha algun usuari que necessitaria una periodicitat més curta (per exemple, trimestral, quan les dades són anuals).
- Problemes amb algunes matèries: teòricament hi pot haver dades de qualsevol tema, però també hi ha problemes amb:
- Temàtiques de les quals no és possible recollir dades de manera oficial, com tampoc no és gaire factible recórrer a enquestes. Per exemple, el nombre mínimament exacte d'immigrants il·legals. En altres casos hi pot haver greus divergències entre les xifres administratives i les que es recullen sobre la base d'enquestes, fet que desconcerta els usuaris.
- Temes “nous”, atès que passa un temps entre que el fenomen es detecta i l'inici de la recollida de dades corresponent. Dos exemples: la incidència de la sida en els primers temps o la “nova” economia d'Internet.
- Temes dels quals es recullen dades però no al nivell de detall que l'usuari voldria.
- Documentació de les dades: els usuaris la volen completa i fàcilment accessible. Es tracta dels manuals, qüestionaris, llibres de codis, etc. que expliquen la metodologia utilitzada per recollir i processar les dades i molt especialment les microdades. Sense el llistat de preguntes i els codis de les respostes, les microdades no serveixen per a res. És sobre aquesta documentació adjunta que s'estan concentrant els esforços per crear un sistema de metadades estadístiques en l'àmbit internacional.
Demandes dels usuaris referents a l'accés a les dades
- Accés lliure/gratuït: és un dels efectes d'Internet, que ha acostumat molts usuaris a la gratuïtat total. És una demanda raonable a certs nivells. Per exemple, les dades nacionals són generalment d'accés lliure (una tendència en augment), però això es deu a la filosofia de servei públic d'aquestes agències. Però quan es tracta de dades d'agències supranacionals o privades, la cosa ja no està tan clara. Moltes agències internacionals difonen les dades de manera gratuïta, però algunes tenen problemes pressupostaris evidents (pensem en l'ONU) i no es poden permetre la gratuïtat total quan aquesta tasca els comporta despeses. Amb tot, el preu polític (preu quasi de cost) és la norma. El cas de les agències privades és radicalment diferent i esperar gratuïtat per aquesta banda és il·lusori.
- Llicències simples i accés ampli: si la gratuïtat total no és possible, els usuaris com a mínim volen sistemes de registre senzills i accessos col·lectius (tot el campus, en el cas de les universitats, per exemple). Els problemes tècnics per aquesta banda són els mateixos que amb qualsevol base de dades. Només els fitxers de microdades comporten problemes especials a causa de la confidencialitat de les dades.
- Format electrònic: els usuaris sempre volen aquest format. Les raons són simples: és una informació que molts cops s'ha de copiar, i fer-ho amb suport paper és llarg, pesat i sobretot obert a molts errors. A més a més, bona part dels usuaris treballarà aquestes dades amb programari estadístic. Per tant, cal poder-les copiar amb un format electrònic que, a més a més, sigui compatible amb el programa que utilitzen. Les agències s'hi han adaptat ràpidament i ofereixen no solament la possibilitat de copiar o baixar-se les dades, sinó també fer-ho en els formats més habituals.
- Interfícies: els usuaris volen que la base de dades sigui d'ús fàcil. I com més inexpert és l'usuari, més important és aquest punt. En això les agències estan invertint molts esforços des que Internet les ha obert al públic en general.
- Serveis de valor afegit: molts usuaris indiquen que estarien disposats a pagar per cerques a mida... fetes per la mateixa agència. Aquests usuaris no tenen ni temps ni ganes d'aprendre el funcionament d'aquestes bases de dades. El problema és que les agències són entitats de l'Administració que no solen oferir aquests serveis. En la mateixa línia, es constata que la formació d'usuaris només és apreciada per qui ha d'utilitzar les bases de dades de manera intensiva i a llarg termini.
En general, és més factible que s'atengui el segon tipus de demandes. Canviar el mètode d'accés és molt més fàcil que no pas haver de canviar la metodologia de les dades. Un exemple: una de les enquestes socials més utilitzades per als investigadors és el Panel de Hogares de la Unión Europea. Aquesta gran enquesta va tenir vuit edicions (anomenades waves, o sigui, ‘onades') entre 1994 i 2001. Però es va deixar de fer perquè es va considerar que el cost que tenia no compensava el profit quant a disseny de polítiques públiques. Els investigadors van protestar, ja que era una eina utilitzada en multitud de recerques en curs, però Eurostat no ha canviat d'opinió.20
6 Com cercar?
6.1 On cercar?
Al contrari del que es podria pensar, la cerca en si de les dades no té gaires complicacions. El que és complex és saber on cal cercar. Les dades estadístiques són publicades i difoses per les mateixes agències que les creen. Dit d'una altra manera, és l'usuari qui ha de saber que la font més bona per a dades espanyoles és l'INE, però que en l'àmbit europeu ha de cercar a Eurostat. O que per a les dades financeres internacionals, la més bona és l'FMI, i per a les d'agricultura, el FAOStat. Per això moltes “bibliografies” de dades estadístiques llisten les fonts més adequades per a cada temàtica concreta.
Hi ha una tendència general a la unificació d'estadístiques oficials provinents de diferents fonts. Per exemple, l'INE inclou en la seva base de dades estadístiques més de trenta entitats de l'Administració central. Una altra opció és oferir com a mínim una interfície de cerca conjunta. És l'oferta de FedStats (http://www.fedstats.gov/) als Estats Units, que dóna accés a més de setanta agències governamentals. Amb tot, aquests esforços només se solen fer en l'àmbit d'un sol país o d'una mateixa administració. Per trobar juntes les dades de diverses fonts que no tenen cap lligam orgànic que les interrelacioni, cal recórrer a les bases de dades privades.
6.2 Interfícies: problemes de disseny
“Public access information systems imply that most users will be first time users of the interface, and that they will have limited time and interest in learning the system”21
El disseny d'interfícies per a webs i bases de dades estadístiques és un tema d'actualitat dins la recerca documental. En això, les agències estadístiques oficials han dut a terme un gran esforç. Les primeres webs d'aquestes agències solien consistir, simplement, en les bases de dades ja existents amb l'afegit d'un motor de cerca més o menys afinat. Però de mica en mica la majoria han passat a un sistema de menú temàtic, més adequat per a usuaris no especialistes. Un exemple: Eurostat va passar d'una oferta basada en quatre bases de dades amb noms poc identificatius (New Cronos, Europroms, Comext, Regio) a una altra basada en deu àrees temàtiques.
També ha millorat la usabilitat de les pàgines. Fa uns anys no era estrany veure llocs web on la base de dades en si era difícil de trobar entre les publicacions, les notícies i la informació institucional. Actualment la situació és molt més bona, i en la majoria de casos la informació estadística és fàcil de localitzar. Una altra qüestió és si l'usuari troba les dades d'accés lliure o de pagament.
Marchionini (2002)22 va fer un interessant estudi longitudinal (cinc anys) del web del Bureau of Labor Statistics (BLS) dels Estats Units. A part d'analitzar els canvis de la interfície, també va incloure entrevistes i enquestes amb els treballadors del BLS. Una de les conclusions és que l'explosió d'Internet ha canviat els mètodes de treball dels funcionaris del BLS i els ha fet més receptius a les necessitats dels usuaris no especialitzats.
Per acabar, cal ressenyar que ja han aparegut programes informàtics especialitzats en la publicació i l'accés de dades numèriques a Internet. En són exemples Nesstar (http://www.nesstar.com/) d'UK Data Archive i del Norwegian Social Science Data Services, Beyond20/20 (http://www.beyond2020.com/), que utilitzen moltes agències internacionals (ONU, OCDE, etc.), o PCAxis (http://www.ine.es/prodyser/pcaxis/pcaxis.htm), que utilitza l'INE.
6.3 Mètodes de cerca
Una base de dades estadística sol combinar diferents mètodes de cerca, que poden ser complementaris o alternatius. Però no són els mateixos que en el cas de la informació textual.
Menús temàtics
El més habitual són els menús per temes. Es tracta d'una veritable classificació temàtica, en què l'usuari va obrint carpetes fins a arribar a la sèrie que desitja.
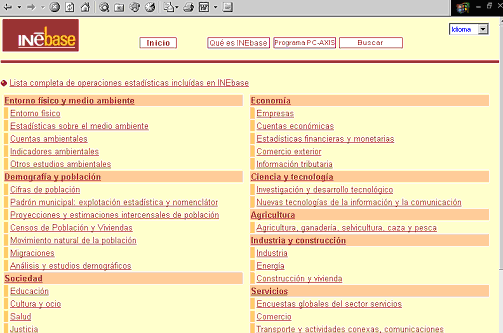
Figura 3. Menú temàtic d'INEBase (http://www.ine.es/inebase/index.html).
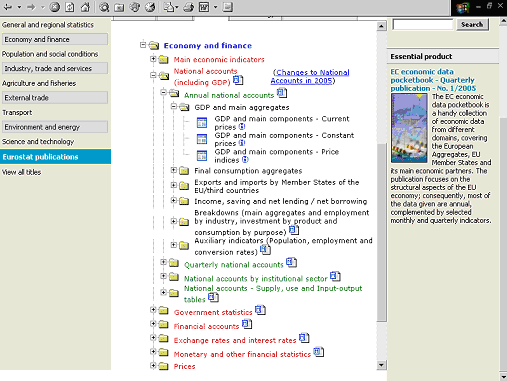
Figura 4. Menú temàtic de la secció “Economy and finance” d'Eurostat
( http://epp.eurostat.cec.eu.int/portal/page?_pageid=0,1136173,0_45570701&_dad=portal&_schema=PORTAL)
L'avantatge és que es tracta d'un sistema molt senzill d'utilitzar, que permet una bona classificació de la informació. En general és ideal per als usuaris novells. L'inconvenient és que, com totes les classificacions, és força rígid i pot ser confús pel que fa a temes sense una ubicació clara. L'usuari novell sol passar força estona obrint i tancant seccions de la classificació fins que troba la informació desitjada. En els casos en què una interfície agrupa dades provinents de diverses fonts, a més del menú temàtic, no és inusual oferir-ne un altre organitzat segons les agències participants.
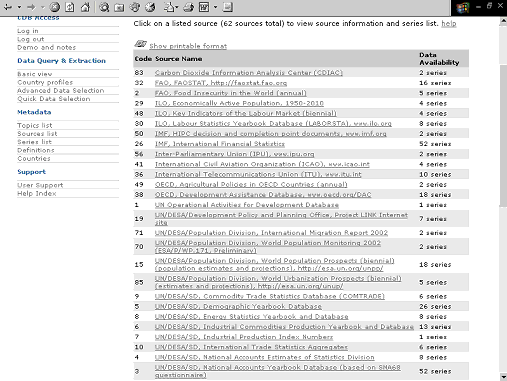
Figura 5. Menú de fonts estadístiques de United Nations Common Database (Nacions Unides)
Selecció múltiple
La selecció múltiple fa ús de les quatre variables més usuals de les dades estadístiques: el tema, el temps, el lloc i la unitat. Es tracta que l'usuari triï cada una de les variables, i el sistema dóna com a resultat una taula estadística. En tots els casos es tracta d'un procés lineal: tema + temps + lloc + unitat = resultat (amb variacions en l'ordre dels factors).
Aquesta selecció es pot presentar de diverses maneres:
a) Les quatre opcions dins la mateixa pantalla, en quadres de diàleg diferents (INE).
b) Les quatre opcions dins la mateixa pantalla però com a pestanyes diferents del sistema de cerca (Eurostat).
c) Les quatre opcions en pantalles successives (United Nations Common Database).
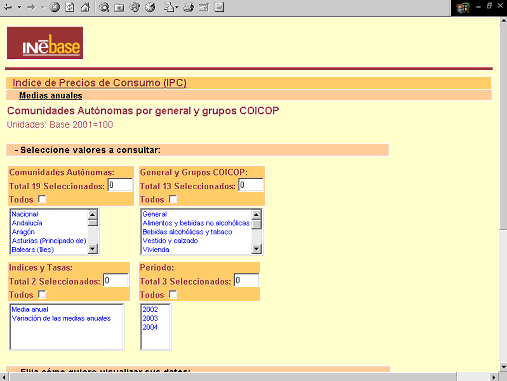
Figura 6. Exemple de selecció múltiple a INEBase (http://www.ine.es/inebase/index.html).
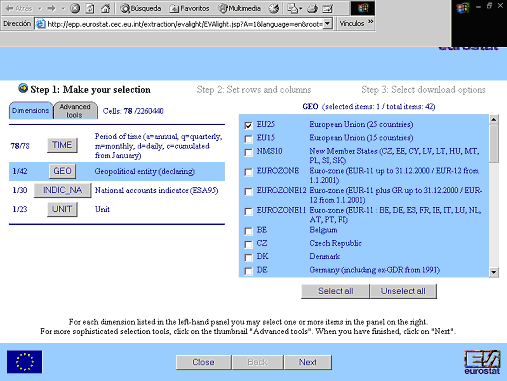
Figura 7. Exemple de selecció múltiple a la secció “Economy and finance” d'Eurostat,
( http://epp.eurostat.cec.eu.int/portal/page?_pageid=0,1136173,0_45570701&_dad=portal&_schema=PORTAL).
La selecció múltiple és el mètode de cerca més “típicament” estadístic, i és usual que es combini amb un sistema de menú temàtic. Per exemple, la base de dades INEBase (http://www.ine.es/inebase/index.html) de l'INE té un sistema de menús, però al final l'usuari sol trobar una selecció variable/temps/lloc/unitat. En altres casos la base de dades ofereix d'entrada la selecció múltiple, però la variable tema està organitzada en forma de menú. Vegeu, per exemple, el World development indicators del Banc Mundial.
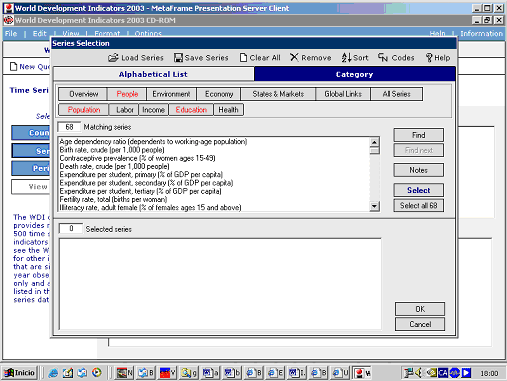
Figura 8. Exemple de selecció d'una sèrie estadística a World development indicators (Banc Mundial).
Aquest sistema té, bàsicament, tots els avantatges. Els inconvenients es poden donar amb usuaris novells que encara no dominen la terminologia utilitzada.
Cerques per paraula clau o índex de matèries
Aquest tipus de cerca, la típica de la informació textual, és secundària en el cas de les estadístiques. La raó és simple, l'únic “text” on es pot cercar són les descripcions de les sèries. Normalment s'ofereix com una ajuda suplementària, per al cas en què l'usuari no trobi el que busca pels mètodes anteriors. És molt útil, sobretot, quan l'usuari no està segur o bé de la terminologia que està utilitzant, o bé de si el que cerca es troba a la base de dades o no.
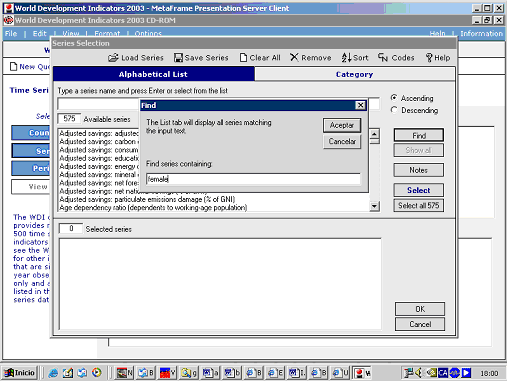
Figura 9. Cerca per paraula clau a World development indicators (Banc Mundial).
Una variant de la cerca per paraula clau és l'índex de matèries. És a dir, oferir alfabèticament tots els temes presents a la base de dades. Això permet un nivell de detall molt més gran que no pas amb un menú jeràrquic.
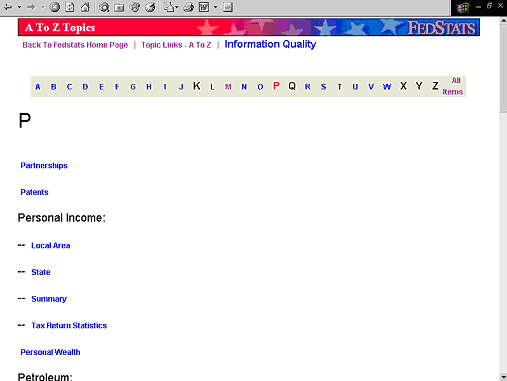
Figura 10. Índex de matèries de FedStats (http://www.fedstats.gov/cgi-bin/A2Z.cgi)
L'avantatge principal és que ofereix un mètode suplementari de localització de la informació, i l'inconvenient principal és que com a mètode principal és molt limitat.
Cerques per codi
Les cerques per codi són possibles perquè moltes bases de dades assignen un codi (alfa) numèric a les sèries estadístiques. Normalment el codi té un significat intrínsec, de manera similar al codi de la CDU. Si l'usuari està familiaritzat amb aquests codis, pot fer una cerca molt més directa i precisa. Evidentment aquest sistema només sol funcionar amb usuaris avançats, que treballen de manera intensiva amb la base de dades i, per tant, s'han arribat a aprendre el sistema de codificació. Per als usuaris novells o ocasionals, no té gaire interès.
En alguns casos els codis són assignats per la mateixa base de dades (cas de Datastream), però en d'altres són codis provinents de classificacions nacionals o internacionals com, per exemple, la CNAE. Les més usuals són les classificacions de productes, que s'utilitzen en dades de producció o comerç.
Per exemple, en la base de dades International statistical yearbook (ISY) (base de dades privada, diverses fonts, secció OCDE), el codi 685211K “vol dir”:
68: Suïssa
5211: Índex de preus al consum. Menjar (excloent-ne els restaurants)
K: Índex
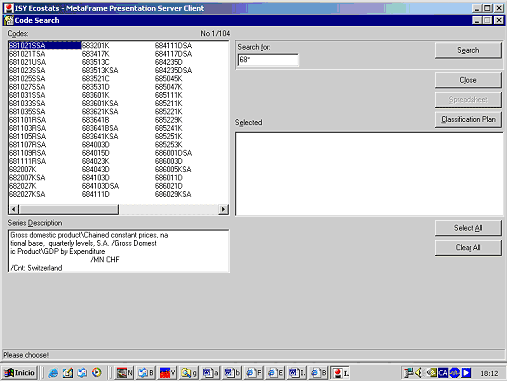
Figura 11. Cerca per codi a International statistical yearbook (ISY)
Format de les dades
Una altra qüestió és el format de sortida de la informació. La majoria de les bases de dades ofereixen, per una banda, un format de visualització en pantalla (html o Excel) perquè l'usuari pugui comprovar si són les dades que buscava. En molts casos l'usuari també pot triar els eixos de la taula; dit d'una altra manera, quina informació vol posar en les línies horitzontals i en les verticals. A continuació, o alternativament, la base de dades ofereix diversos formats de sortida. Els més habituals són les extensions .csv (SPSS) i .xls (Microsoft Excel), que tenen la virtut, a més a més, de ser molt compatibles amb qualsevol programa similar.
Microdades: fitxers sense programari de recuperació
Les microdades, estrictament parlant, no són bases de dades sinó fitxers de dades. Això vol dir que, malgrat incloure en alguns casos quantitats ingents d'informació, no porten incorporat un sistema de recuperació. Els usuaris copien aquests fitxers i els obren amb programari estadístic especialitzat (SPSS, Stata o, fins i tot, Microsoft Excel).
En el cas que una agència només tingui un nombre limitat de fitxers, un simple llistat és suficient (exemple de l'INE, http://www.ine.es/prodyser/microdatos.htm).23 Si, en canvi, tenim el que s'anomena un arxiu de dades socials, se sol crear una fitxa de cada fitxer (amb les característiques principals) i hi aplica un sistema de recuperació normal i corrent. Vegeu l'Inter-university Consortium for Political and Social Research (ICPSR, http://www.icpsr.umich.edu/access/index.html) o el CIS.
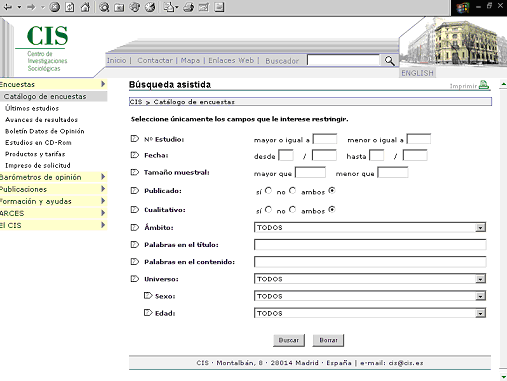
Figura 12. Formulari de cerca d'enquestes al Centro de Investigaciones Sociológicas, CIS (http://www.cis.es/Page.aspx?OriginId=380).
6.4 Metadades estadístiques
En les metadades estadístiques passa el mateix que en les dedicades a la informació textual: estrictament parlant no són res gaire nou. Sempre hi ha hagut sistemes per descriure i contextualitzar les dades, normalment desenvolupats per les mateixes agències. Però ara Internet ofereix un incentiu per desenvolupar estàndards internacionals: la cerca i la recuperació conjuntes.
Així doncs, s'han començat a crear sistemes de metadades estadístiques que aspiren a codificar totes les variables de les dades i, per tant, a crear sistemes de cerca precisos i compatibles entre si. Molts dels projectes es concentren en l'àmbit dels fitxers de microdades. La raó és simple: les microdades són, simplement, fitxers de dades i el que les defineix és la documentació adjunta, especialment el qüestionari i els codis. A més, les microdades són molts cops d'accés restringit, però en canvi la documentació sempre és d'accés lliure.
Les iniciatives de metadades proposen codificar tota aquesta documentació amb un estàndard internacional que faria possible la cerca conjunta. Dels projectes existents, un dels més importants és el Data Documentation Initiative (DDI, http://www.icpsr.com/DDI/). És promogut per l'Inter-university Consortium for Political and Social Research (ICPSR), que es considera l'arxiu de dades socials i microdades d'enquestes en l'àmbit internacional més bo i més complet. S'està començant a utilitzar en diverses institucions.24 Altres projectes interessants són: MetaDater (http://www.metadater.org/), projecte conjunt de diversos arxius de dades europeus per a la descripció d'enquestes socioeconòmiques, i MetaNet (http://www.epros.ed.ac.uk/metanet/), una xarxa de projectes europeus basats en les agències oficials. En general, es tracta de projectes dirigits per estadístics i no tant per documentalistes. El més orientat al món bibliotecari és el DDI, que és compatible amb el Dublin Core.
7 Dades agregades a les biblioteques
“[...] it is not enough for reference librarians to be able to identify the sources for successful data retrieval. In order to deliver accurate and complete data reference service, it is also essential that the reference librarian understand how the user intends to statistically manipulate the data retrieved”25
7.1 Quines dades per a quines biblioteques?
Tenint en compte el context, quin és el paper de la biblioteca? La resposta seria més aviat: depèn de la biblioteca. O, afinant encara més, depèn del nivell de complexitat de les demandes dels usuaris. Si aquests usuaris només demanen dades agregades simples de manera puntual, que és el cas de la majoria de biblioteques públiques, amb algunes publicacions en paper, amb les bases de dades en accés lliure per Internet i alguna de pagament n'hi ha més que suficient. En canvi, si el que tenim són investigadors d'alt nivell en sociologia, economia o epidemiologia, segurament necessitaran bones bases de dades i fitxers de microdades, i això implica un paper molt diferent per a la biblioteca.
Al nostre país tenim en contra la manca de tradició. Hi ha alguns exemples de seccions especials, com ara la Unitat d'Estadístiques de la Biblioteca de Ciències Socials de la UAB (http://www.bib.uab.es/socials/gestad.htm), però no són freqüents. En canvi, en països anglosaxons i especialment als Estats Units és corrent trobar data centers o data libraries en moltes universitats. Alguns exemples són: Edinburgh University Data Library (http://datalib.ed.ac.uk/index.html), University of Toronto Data Library Service (http://www.chass.utoronto.ca/datalib/) i GeoSpatial and Statistical Data Center de la University of Virginia Library (http://fisher.lib.virginia.edu/). En alguns casos hi ha un acord amb les agències estadístiques nacionals i aquestes data libraries serveixen també com a centres de disseminació de dades. Seria l'equivalent, quant a estadístiques, als centres de documentació europea. Vegeu, per exemple, l'State Data Center Program (http://www.census.gov/sdc/www/) de l'US Census Bureau. Per tant, al nostre país tenim encara molt camí per recórrer.
7.2 Què cal comprar?
Les biblioteques no tenen un pressupost il·limitat, i cal establir unes prioritats clares. Pel que fa a les dades estadístiques, això implica assegurar-se que el que es vol comprar no es pot trobar a Internet gratuïtament. Cal dir que aquesta comprovació no sempre és fàcil. Per raons de servei públic, les agències continuen publicant en paper dades que també difonen exactament igual pel web. De vegades l'única solució és comparar diverses sèries una a una. Conèixer la política de l'agència també ajuda, però cal tenir en compte que aquesta pot canviar de manera sobtada.26
Com a conseqüència, és recomanable que la biblioteca tingui les seves polítiques de desenvolupament de la col·lecció per a dades estadístiques. I, atès el canvi accelerat actual, no seria sobrer actualitzar-les cada un o dos anys. Això permet examinar els llocs webs de les agències i veure què hi ha d'accés lliure, què és de subscripció, etc. Així s'avalua la col·lecció de la biblioteca i es poden planificar les prioritats de compra.
Publicacions en suport paper i referència bàsica
Si analitzem un a un els possibles suports de la informació estadística, observarem que les monografies i publicacions periòdiques tradicionals van molt de baixa. Quina n'és la raó? Els usuaris són refractaris a tornar a copiar manualment les dades. Això no vol dir que el paper hagi perdut tota la vigència. L'experiència demostra que és un mitjà excel·lent per a usuaris novells i ocasionals. La clau resideix en el fet que “suport paper” en l'actualitat no vol dir simplement la taula estadística pura i dura, sinó un anuari on s'analitzen les dades, es donen llargues explicacions i s'inclouen gràfics i mapes molt visuals. Per a usuaris amb pocs coneixements de metodologia, aquest tipus de font és la més bona. Per dir-ho d'alguna manera, s'ha passat a un suport paper amb valor afegit. Però abans de comprar-la també cal comprovar que aquesta publicació en paper no sigui accessible de manera gratuïta en format pdf.
Per al cas de consultes molt bàsiques, de vegades la millor font no són les agències estadístiques, sinó els anuaris de referència bàsica. Són publicacions o llocs web que analitzen un tema a fons (amb dades estadístiques de suport) o donen informació resumida sobre els països (incloent-hi l'estadística). Són anuaris del tipus Estado del mundo o els seus equivalents a Internet, com ara el CIA World Factbook (http://www.cia.gov/cia/publications/factbook/), els Country studies (http://news.bbc.co.uk/1/hi/country_profiles/default.stm) de la BBC o el recurs NationMaster (http://www.nationmaster.com/). També són útils els anuaris de mitjans de comunicació que analitzen un any concret. El d'El País, per exemple, té un annex estadístic molt ben fet. I en certs casos un article de premsa d'una sola pàgina pot ser una bona font. Els periodistes molts cops duen a terme una tasca divulgadora: busquen la informació a les agències oficials i la transformen en una taula, un gràfic o un mapa adequats al públic en general. En aquest sentit, cal dir que és lamentable que algunes bases de dades de premsa (com ara MyNews) no incloguin les il·lustracions i els gràfics dels articles.
Per acabar, el suport paper és també important per a l'alta investigació en un àmbit molt concret: les dades molt antigues. Malgrat que la situació millora progressivament, moltes agències només posen a Internet les dades que ja tenien informatitzades en origen. Això deixa fora la informació estadística publicada en el segle xix i bona part del xx. S'han publicat alguns CD-ROM amb dades històriques, com per exemple l'United Nations Demographic Yearbook. Historical Supplement (1948–1997). Però en la majoria de casos s'ha de recórrer al paper en forma d'anuaris antics. Si no els tenim a la nostra biblioteca, cal cercar-ne un amb bons fons històrics i utilitzar el préstec interbibliotecari. Hi ha dos tipus de biblioteques especialment interessants: a) les biblioteques d'economia i b) les biblioteques de les mateixes agències estadístiques, que solen ser el dipòsit de les publicacions d'aquestes.27
Suports electrònics d'accés local
Els disquets i els CD-ROM van ser el mètode de difusió preferit per les agències mentre Internet no es va generalitzar. Es comercialitzaven per si sols o com a material d'acompanyament d'anuaris i revistes. Amb Internet això ha canviat i han estat substituïts en gran part per bases de dades d'accés lliure o de subscripció. Pot ser que en alguns casos continuï interessant un suport local. Ja sigui perquè és encara l'única manera d'adquirir-lo, ja sigui perquè així és més barat (les versions remotes de pagament solen ser més cares), ja sigui perquè ens arriba acompanyant una publicació en paper. Però el millor és posar els CD-ROM en xarxa o disponibles per préstec. Així, l'usuari pot treballar des d'on vulgui. Una base de dades d'accés totalment local dins la biblioteca només serà consultada si realment és imprescindible. En cas contrari és una compra inútil.
Internet: fonts de pagament
Per a les bases de dades d'accés remot però de pagament, només cal seguir els mateixos criteris que per a la resta de bases de dades: accessos al més amplis possibles (xarxa, campus, etc.) i bona selecció quan hi ha diverses opcions.28 En bases de dades similars, cal posar una atenció especial en la cobertura cronològica (al més àmplia possible), la facilitat d'ús de la interfície i el format de sortida de les dades (compatible amb els principals programes de programari estadístic).
Internet: fonts d'accés lliure
Les fonts d'accés lliure per Internet no haurien de comportar més problemes que una bona descripció dins el web, el catàleg o la guia temàtica de la biblioteca. Es tracta, simplement, de facilitar l'accés sobretot als usuaris que no coneixen les fonts i, per tant, necessiten una mica d'orientació. Cada vegada hi ha més dades gratuïtes, una tendència que facilita l'accés dels usuaris i permet a la biblioteca alliberar pressupost per a altres bases de dades. La nostra tasca és complementar i facilitar l'accés a Internet, no competir-hi.
7.3 Com difondre la informació i atendre els usuaris?
Tan important com la selecció i l'adquisició d'aquestes dades és la difusió que se'n faci. Molts cops a les biblioteques es fa poc màrqueting, i aquest és fonamental. Si es compra una base de dades però no se'n fa difusió, és com si no se'n tingués cap. Si es té un bon coneixement de les fonts però no se n'informa els usuaris, aquests no preguntaran. Si una base de dades que abans era de pagament passa a ser de lliure accés, això és una bona notícia que s'ha de difondre. En resum, la biblioteca ha de donar la sensació que domina tots els tipus de fonts estadístiques, sigui quin sigui el mètode per accedir-hi.
El primer nivell de difusió és tan simple com un bon posicionament al lloc web i una descripció acurada al catàleg de la biblioteca. Atès que les estadístiques són un tipus d'informació i no un tema, hi ha dues maneres d'incorporar-les als llocs web: com un apartat específic o inserides dins les diferents pàgines temàtiques. Cada centre decidirà què li va més bé. Sí que és important combinar sempre les fonts de pagament amb les gratuïtes.
Un segon nivell de difusió és la formació d'usuaris. Amb tot, cal anar amb compte, ja que no tots els usuaris volen ser formats. Si una persona necessita una dada puntual, el més adequat és dirigir-la a la font adequada i no anar més enllà. La formació, en canvi, pot interessar els usuaris que preveuen un ús intensiu i a llarg termini d'aquestes fonts. En l'àmbit universitari o especialitzat, pot ser una bona idea fer presentacions al professorat. Ja sigui de manera puntual en el cas de nous serveis, ja sigui una introducció general a les fonts disponibles per als usuaris que acaben d'arribar a la institució. Els destinataris de preferència seran investigadors, professors i doctorands. Però si es disposa del permís i la col·laboració del professorat, es poden fer també sessions introductòries per a l'alumnat de primer i segon cicles.
En el cas de les universitats, el procés de convergència a Bolonya i la renovació pedagògica que implica obre perspectives molt interessants. Per exemple, la possibilitat de crear “laboratoris estadístics” dins la biblioteca, similars als “laboratoris de llengües”. En aquests laboratoris hi hauria documentació metodològica, programes estadístics i la possibilitat d'organitzar cursos. Per exemple, impartir classes sobre programari estadístic.
Per acabar, si és necessari, cal anar a buscar els usuaris. En alguns casos és difícil, però en centres d'investigació o universitats és factible perquè algunes categories estan ben delimitades (per exemple, el professorat d'economia). Cal fer molta feina de relacions públiques, oferir els serveis de la biblioteca i proporcionar serveis de valor afegit. A tall d'exemple, es poden crear butlletins de novetats per correu electrònic, tot i que nou de cada deu butlletins d'aquest tipus acabaran directament a la paperera sense ser llegits. Això és normal i no hauria de desanimar. El que és important és que els usuaris entrin en contacte amb el servei.29
8 Microdades a les biblioteques
“People who will happily allow unknown corporations to track their Internet reading, electronic shopping behavior and spending patterns are worried that egg-heads like myself will try to find out where they live”30
8.1 Dades base a les biblioteques
La problemàtica que envolta les microdades s'ha deixat per al final a causa de la seva complexitat. Recordem que les microdades són fitxers on es recullen els resultats individualitzats de les enquestes socials o d'opinió. És un tipus de dades base que per regla general només es necessita per a la recerca, especialment de les ciències socials, o bé per a la docència, quan es tracta de formar els futurs investigadors.
És un tipus de fitxer que moltes vegades no es troba a les biblioteques simplement perquè no hi ha gaire tradició. Als Estats Units és més habitual, a causa dels data centers que moltes agències productores van instal·lar dins les biblioteques universitàries. Però a Espanya és tan inusual, que quan la Biblioteca de la UPF va intentar per primer cop adquirir microdades de l'INE (primavera de 2003), aquest es va mostrar reticent a causa, precisament, que es tractava d'una biblioteca (perquè l'assimilava a serveis d'accés lliure i sense restriccions).31
Al nostre país és més usual que els investigadors adquireixin les dades individualment o per grups de recerca, a compte d'ajuts i pressupostos del departament universitari al qual pertanyen. Això és pràctic per a ells, però implica molt poc control dels fitxers, perill de duplicació i, habitualment, manca de planificació. Podrien les biblioteques, especialment les universitàries o d'investigació, fer-se càrrec d'aquest material? La resposta és que sí. El problema és que les microdades estan subjectes a l'anomenat secret estadístic.
8.2 El problema del secret estadístic
Què és el secret estadístic? Segons l'INE, és “la prohibició de difondre estadístiques o dades en què no es preserva l'anonimat de cada unitat individual a la qual es refereix la informació”. El secret estadístic, doncs, no té res a veure amb el dipòsit legal, sinó amb la privadesa. Per entendre el problema imaginem una enquesta sobre opinions polítiques. Si algú arriba a saber qui és l'entrevistat número X, sabrà moltíssim sobre qüestions molt personals i delicades. Per això el secret estadístic no solament és un problema d'ètica professional d'estadístics i investigadors, sinó també un problema legal. Les lleis de protecció de dades personals imposen restriccions i càstigs severs, com a mínim en teoria.
Per tal de protegir la privadesa de les dades, hi ha dos tipus de mètodes: en origen i en destí. En origen es tractaria de difondre les dades sense els elements més identificadors. Per exemple, totes les microdades que s'utilitzen per a investigació estan anonimitzades: se n'han eliminat tots els noms, adreces, etc. Però això no és suficient en casos d'unitats geogràfiques petites o categories amb poques respostes. Imaginem que l'entrevistat és una dona, casada i amb dos fills, amb estudis superiors, que treballa d'administrativa i nascuda el 1960: aquesta descripció en una zona amb pocs habitants és suficient per identificar una persona. Per això moltes agències opten també per agrupar unitats o esborrar variables. Però són tècniques que no agraden als investigadors, que temen que els seus resultats se'n ressentin.
Si les dades no s'han pogut protegir prou en origen, es limita l'accés als usuaris finals. Les limitacions s'especifiquen en les llicències d'ús. Les condicions fixes són l'ús individual de les dades i la prohibició de difondre-les a qualsevol persona que no hagi signat la llicència. També és habitual que es demanin cada any llistats d'usuaris i llistats de publicacions dutes a terme sobre la base de les dades. Ja de manera menys freqüent, es pot prohibir o limitar severament la còpia de les dades, fins i tot per a ús personal. Es poden trobar fins i tot casos en què les microdades són gratuïtes (per a investigació), però igualment cal signar una llicència d'ús.
Les agències prenen aquestes precaucions perquè temen perdre la confiança del públic. Si les enquestes han de ser fiables, la gent ha de contestar-les sincerament, i no ho farà si creu (o sospita, encara que sigui sense fonament) que les seves respostes no són confidencials. Els investigadors poden estar d'acord en teoria, però discrepen quant a la severitat de les mesures. Argumenten que avui en dia, quan multitud de dades personals circulen per la xarxa o estan en mans d'empreses privades, preocupar-se excessivament per les dades que estan en mans d'economistes o sociòlegs és exagerat.32
8.3 Gratuïtat, pagament i arxius de dades socials
Una mica al marge d'aquest debat, les biblioteques dependran molt de quin mètode de seguretat s'ha fet servir. Si s'ha posat èmfasi en la restricció en origen, podem trobar microdades que són simplement d'accés lliure, igual que les dades estadístiques. Si la restricció s'ha de fer en destí, les biblioteques s'han de comprometre a restringir-ne l'accés. Per exemple, mitjançant xarxes restringides a usuaris individuals, com també les gestions que demani l'agència (manteniment de llistats d'usuaris, recollida de bibliografia produïda, etc.). És important que la biblioteca pugui difondre que disposa d'aquest material, sempre que se'n deixin molt clares les restriccions d'accés.33
De la mateixa manera que les dades estadístiques agregades, les microdades estan en evolució continuada. És difícil dir com serà l'accés d'aquí a uns anys. Però hi ha diverses possibilitats que no s'exclouen entre si:
- Accés lliure: és perfectament possible quan les dades han estat molt anonimitzades. Als Estats Units ja fa dècades que una part del cens s'ofereix lliurement per a recerca, docència i aprenentatge (el PUMS: Public Use Microdata Samples, http://www.census.gov/main/www/pums.html). Diferents agències nacionals ja s'acullen a aquesta possibilitat. Al nostre país, l'INE (http://www.ine.es/prodyser/microdatos.htm) s'ha decidit per l'accés lliure des del juny de 2005.34 En algunes agències es requereix un simple registre en línia de l'usuari, que sense comprovació de les dades és pràcticament igual que l'accés lliure. En aquest cas la biblioteca no intervindria excepte per aconsellar els usuaris.
- Accés restringit: l'accés es restringeix a determinades categories d'usuaris:
- Institucional en línia: per a universitats, centres de recerca, etc. El paper de la biblioteca seria similar al que tingui en qualsevol altra base de dades. Una variant cada cop més usual és fer-se soci de consorcis de dades socials (membership). És l'exemple d'ICPSR (http://www.icpsr.com/).
- Institucional en suport físic: les dades es lliuren en CD-ROM o s'envien per correu electrònic. És la institució qui n'ha de gestionar i limitar l'accés. En els dos casos la institució és legalment responsable de la protecció de les dades personals.
- Individual en línia o en suport físic: l'agència proporciona directament les dades a l'usuari si aquest n'ha justificat l'interès. L'usuari és individualment responsable.
9 La investigació documental
“There is a rich literature on information seeking, both in general and for specific contexts. However, little empirical evidence is available concerning how people seek and use statistics”35
Un estat de la qüestió sobre la recerca documental en dades estadístiques mereixeria un article a part. Així doncs, només n'exposarem les característiques, els mètodes i les temàtiques més rellevants.36
La primera constatació és que els treballs d'investigació en aquest tema no són gaire abundants, especialment si comparem amb la recerca dedicada a les bases de dades bibliogràfiques o la informació textual. Una cerca a LISA o Library Literature and Information Abstracts demostra que les estadístiques estan molt més previstes com a mètode que com a objecte específic d'estudi.
La segona és que delimitar la recerca estrictament documental no és fàcil. Bibliotecaris i documentalistes duen a terme recerca molt general que publiquen en revistes de fora del seu àmbit, mentre que en revistes de documentació apareixen treballs signats per professionals d'altres camps (matemàtics, estadístics, sociòlegs, informàtics, etc.). Aquesta darrera categoria d'autors pot arribar a representar fins a una tercera part de la recerca total. Per professions, són majoria el professorat d'universitat i l'alumnat de doctorat (no necessàriament en documentació), seguits de bibliotecaris d'universitats i centres especialitzats. Per nacionalitats, són majoria aclaparadora els autors provinents de països anglosaxons (en especial dels Estats Units i el Regne Unit), on es poden detectar diversos nuclis i grans projectes de recerca. Els més destacats serien:
- GovStat Project (http://www.ils.unc.edu/govstat/): projecte conjunt de la University of North Carolina Interaction Design Lab i la University of Maryland Human-Computer Interaction Lab, desenvolupat entre juliol de 2002 i juny de 2005. Està dirigit per alguns dels millors investigadors en el tema (o com a mínim els més prolífics): Gary Marchionini, Carol Hert, Stephanie W. Haas, Ben Shneiderman i Catherine Plaisant. Aquest projecte té com a objectiu la “integració de dades i interfícies per millorar la comprensió humana d'estadístiques governamentals”, resumit en el seu lema “find what you need, understand what you find”. Cal dir que compta amb el suport de l'Administració dels Estats Units, i que ha dut a terme nombrosos estudis i avaluacions dels webs estadístics oficials d'aquell país.
- Statistical Knowledge Network: encara per constituir, vol ser la continuació del projecte GovStat, però amb un èmfasi especial en disseny d'interfícies i sistemes de metadades.
- Project on the Use of Numeric Data in Learning and Teaching, 2001–02 (http://datalib.ed.ac.uk/projects/datateach.html): projecte conjunt d'Edinburgh University Data Library, EDINA, UK Data Archive, MIMAS i British Library of Political and Economic Science. Va avaluar l'ús de les dades estadístiques en la docència universitària del Regne Unit.
- Data Documentation Initiative (DDI, http://www.icpsr.umich.edu/DDI/): projecte de metadades de l'Inter-university Consortium for Political and Social Research (ICPSR, http://www.icpsr.umich.edu/). És el projecte de metadades estadístiques més destacat.
- MetaDater (http://www.metadater.org/): projecte conjunt de diversos arxius de dades europeus per a la descripció d'enquestes socioeconòmiques.
- MetaNet (http://www.epros.ed.ac.uk/metanet/): projecte similar, dut a terme entre el 2000 i el 2003, que volia coordinar diversos projectes de metadades generats per diverses agències estadístiques oficials europees.
Pel que fa als temes més usuals, es podrien dividir en tres grans eixos:
- Interfícies: estudis d'usabilitat, nous prototipus i programari de cerca, etc., incloent-hi les propostes de metadades.
- Usuaris: tipologies, mètodes de cerca, expectatives i queixes, necessitats, etc., com també els problemes legals de les microdades i la qüestió de l'alfabetització estadística.
- Reculls de fonts: el que en altres àmbits seria bibliografia.
Moltes vegades es troben recerques que combinen diferents temes.
En general, molts treballs repeteixen la mateixa idea: es tracta d'un àmbit molt nou, que en poc temps ha posat a l'abast del públic una quantitat ingent d'informació, però amb uns mètodes de cerca pensats per a especialistes i pocs coneixements sobre mètodes de cerca i les necessitats dels usuaris. D'aquí prové que l'augment de treballs de recerca segueixi de prop la mateixa explosió d'Internet i que hi hagi un interès especial en mètodes de cerca i recuperació adreçats a usuaris no especialistes. Alguns exemples: sistemes de metadades que facin més fàcil la cerca, estàndards de descripció compatibles entre si, formats de visualització (presentació de les dades) adaptats a persones amb pocs coneixements d'estadística, sistemes d'ajuda dinàmica, creació de gràfics i mapes simples i amigables, sistemes capaços de recordar les cerques més usuals i d'aprendre de l'usuari, etc.
De moment, però, molts d'aquests treballs són encara recerca descriptiva, amb un predomini clar d'enquestes i treballs d'usabilitat. Però amb la publicació creixent de treballs i la consolidació de projectes de recerca es preveu un bon futur a aquesta branca de la investigació documental.
10 Conclusions
Al llarg de l'article ja s'han anat exposant diverses conclusions. Potser la que podria cloure'l és molt simple: tot aquest àmbit està en un moment de canvi profund. El que avui és possible no ho era fa cinc anys, i segurament d'aquí a cinc anys més els canvis seran encara més grans. Les biblioteques poden sentir-se una mica desconcertades, ja que moltes dades que abans gestionaven ara són d'accés lliure. És important encarar aquests canvis com una oportunitat i no com una amenaça. I no hem de perdre de vista la nostra funció principal: facilitar l'accés a la informació. Moltes fonts són d'accés lliure, però no són fàcils de trobar ni de consultar. És important, doncs, que els usuaris trobin a les biblioteques totes les facilitats i personal expert. I cal no oblidar que algunes bases de dades estadístiques són tan cares, que molts usuaris només podran consultar-les si les biblioteques les compren. Tenim un paper per desenvolupar, i és important que els usuaris percebin que la informació estadística és part de l'oferta de la biblioteca.
11 Bibliografia
Bennet, Terrence B.; Nicholson, Shawn W. (2004). “Interactions between the academic business library and research data services”. Portal: libraries and the academy, vol. 4, no. 1, p. 105–122.
Blakemore, Michael; McKeever, Lucy (2001). “Users of official European Statistical data. Investigating information needs”. Journal of librarianship and information science, vol. 33, no. 2, p. 59–68.
Denn, Sheila; Haas, Stephanie W. (2003). “Statistical metadata during integration tasks”. En: DC-2003 (September 28 – October 2, 2003, Seattle, WA). http://www.siderean.com/dc2003/301_Paper50.pdf. [Consulta: 13/09/2005].
Estrugas Mora, Gemma; Riera Masgrau, Roser (2000). “Panoràmica de la producció catalana de fonts estadístiques en suport electrònic”. Item, núm. 26, p. 36–88.
Hert, Carol A.; Marchionini, Gary (1998). “Information seeking behavior on statistical websites. Theoretical and design implications”. En: Proceedings of the American Society for Information Science Annual Meeting (ASIS'98). Pittsburg: American Society for Information Science, p. 303–314.
Hyland, Peter; Gould, Ted (1998). “External statistical data: understanding users and improving access”. International journal of human-computer interaction, vol. 10, no. 1, p. 71–83.
Marchionini, Gary (2002). “Co-evolution of user and organizational interfaces: a longitudinal case study of WWW dissemination of national statistics”. Journal of the American Society for Information Science and Technology, vol. 53, no. 14, p. 1192–1209.
Marxhall, Gordon (ed.) (1998). A dictionary of sociology. Oxford: Oxford University Press.
Montanyà, Rosa; Pozuelo, Coro (2005). “Fitxers de microdades a la Biblioteca de la UPF”. 1r Espai CBUC d'Intercanvi de Coneixements i Experiències.
Roba Stuart, Óscar (2003). “Archivos de datos en línea para ciencias sociales”. El profesional de la información, vol. 12, nº 5, p. 400–410.
Salkind, Neil J. (2004). Statistics for people who (think they) hate statistics. 2nd ed. Thousand Oaks: Sage.
Tupek, A.; Dippo, C. (1997). “Quantitative literacy : new website for federal statistics provides research opportunities”. D-Lib magazine (Dec. 1997). http://www.dlib.org/dlib/december97/stats/12tupek.html. [Consulta: 13/09/2005].
Adreces d'Internet d'interès
- Data Documentation Initiative (DDI): http://www.icpsr.umich.edu/DDI/
- GovStat Project: http://www.ils.unc.edu/govstat/
- Instituto Nacional de 'Estadística (INE). Sistema Estadístico Nacional: http://www.ine.es/ine/sistestanac.htm
- Inter-university Consortium for Political and Social Research (ICPSR): http://www.icpsr.umich.edu/
- Project on the Use of Numeric Data in Learning and Teaching: http://datalib.ed.ac.uk/projects/datateach.html
- Statistical Literacy: http://www.statlit.org/
[Consulta: 13/09/2005]
Data de recepció: 15/09/2005. Data d'acceptació: 05/10/2005.
Notes
1 Algunes perles similars: “Torture the data long enough and they will confess to anything”, “Statistics: group of numbers looking for an argument”, “Statistics: fiction in its most uninteresting form” i “Statistician: a man who can go directly from an unwarranted assumption to a preconceived conclusion”.
2 Sheila Denn, Stephanie W. Haas, “Statistical metadata during integration tasks”. En: DC-2003 (September 28 – October 2, 2003, Seattle, WA), p. 7. http://www.siderean.com/dc2003/301_Paper50.pdf.
3 Per a les definicions s'han usat diverses fonts: ODLIS-Online Dictionary for Library and Information Science (http://www.wcsu.edu/library/odlis.html), Cercaterm del Termcat (http://www.termcat.net/) i Dictionary of Sociology, 2nd ed. (Oxford University Press, 1998).
4 A. Tupek, C. Dippo, “Quantitative literacy”, D-Lib magazine (Dec. 1997), http://www.dlib.org/dlib/december97/stats/12tupek.html.
5 Carol A. Hert, Gary Marchionini, “Information seeking behavior on statistical websites: theoretical and design implications”. En: Proceedings of the American Society for Information Science Annual Meeting (ASIS'98). (Pittsburg: American Society for Information Science, 1998), p. 304.
6 En anglès podem trobar alguns sinònims més o menys exactes: data center, ‘centre de dades', o bé statistical institute, ‘institut d'estadística' —aquest darrer, aplicat generalment als centres nacionals de cada país, com ara l'INE.
7 Un nom genèric per a aquest tipus d'agència oficial central és institut estadístic.
8 Un cas molt conegut són les empreses que duen a terme enquestes electorals: Demoscopia, Sofres, etc.
9 De fet, les empreses que es limitaven a recopilar dades sense millorar-ne la recuperació estan desapareixent, víctimes de l'accés lliure als webs estadístics oficials.
10 Citat per Michael Blakemore, Lucy McKeever, “Users of official European statistical data: investigating information needs”. Journal of librarianship and information science, vol. 33, no. 2 (June 2001), p. 60.
11 Durant els primers anys d'Internet la complexitat de les bases de dades estadístiques comportava també problemes. Amb connexions lentes, fer consultes complexes i baixar una gran quantitat de dades podia fer acabar la paciència de l'usuari. Però això s'ha solucionat de manera natural, a mesura que les connexions han millorat.
12 Michael Blakemore, Lucy McKeever, “Users of official European statistical data: investigating information needs”. Journal of librarianship and information science, vol. 33, no. 2 (June 2001), p. 66.
13 Mark Witter, “Nesstar: providing a data web by building web based data, sharing environments, portals, and observatories”, Burisa, no. 162 (Dec. 2004), p. 5.
14 Sobre això, és recomanable llegir l'entrevista al matemàtic Mogens Niss a “La Contra” de La vanguardia de 20 de maig de 2005 ( http://wwwd.lavanguardia.es/Vanguardia/Publica?COMPID=51185100396&ID_PAGINA=781&ID_FORMATO=9). Un exemple: “un diputado danés que explicó que el 68 % de la población no usaba librerías porque el 37 % de los hombres y el 31 % de las mujeres no las visitaba nunca”.
15 Citació d'Andrew Lang (1844–1912).
16 Es duu a terme un gran esforç docent adreçat especialment als estudiants universitaris. No hi ha gaires problemes amb els estudiants de matemàtiques o d'estadística. En canvi, molts estudiants de ciències socials (economia, sociologia, etc.) tenen dificultats serioses en els mètodes quantitatius.
17 Es pot trobar una selecció d'aquest material a la pàgina web “Estadística per a les ciències socials” (http://www.upf.edu/bib/guies/guies.htm?opcio=/bib/ccpp/sociologia/metstat.htm) de la Biblioteca de la Universitat Pompeu Fabra.
18 Michael Blakemore, Lucy McKeever, “Users of official European statistical data: investigating information needs”. Journal of librarianship and information science, vol. 33, no. 2 (June 2001), p. 62.
19 Carol A. Hert, Gary Marchionini, “Information seeking behavior on statistical websites: theoretical and design implications”. En: Proceedings of the American Society for Information Science Annual Meeting (ASIS'98). (Pittsburg: American Society for Information Science, 1998), p. 306.
20 Eurostat al final (estiu de 2005) ho ha canviat per una enquesta similar, però que no inclou les mateixes preguntes, cosa que en disminueix molt el valor per a la investigació.
21 Hyunmo Kang, Catherine Plaisant, Ben Shneiderman, “New approaches to help users get started with visual interfaces: multi-layered interfaces and integrated initial guidance”. Proceedings of the Digital Government Research Conference, Boston, MA. (May 2003).
22 Gary Marchionini, “Co-evolution of user and organizational interfaces: a longitudinal case study of WWW dissemination of national statistics”. Journal of the American Society for Information Science and Technology, vol. 53, no. 14 (2002), p. 1192–1209.
23 Els fitxers de microdades que pot crear una agència són pocs en comparació amb la quantitat de sèries estadístiques que en deriven.
24 Vegeu exemples d'institucions que empren Data Documentation Initiative (DDI) a l'adreça següent: http://www.icpsr.umich.edu/DDI/codebook/projects.html.
25 Terrence B. Bennet, Shawn Nicholson, “Interactions between the academic business library and research data services”. Portal: libraries and the academy, vol. 4, no. 1 (2004), p. 107.
26 Per exemple, Eurostat va decidir sobtadament posar en accés lliure totes les seves dades agregades l'octubre de 2004, i l'INE va donar accés a les seves microdades el juny de 2005. Totes dues decisions van comportar un canvi radical de política.
27 Si cal contactar amb una agència estadística, és millor fer-ho directament amb la seva biblioteca o el seu centre de documentació: la solidaritat professional funciona.
28 Algunes agències internacionals ofereixen les dades bàsiques o la consulta simple gratis, però les cerques voluminoses i/o la còpia de les dades requereixen una subscripció.
29 L'experiència de la UPF és positiva en aquest aspecte. No hi ha hagut peticions de baixa del servei, malgrat que l'opció és ben visible. I la quantitat de missatges amb preguntes, dubtes, etc. rebuts com a resposta del butlletí fan pensar que el servei és útil.
30 Citat per Alice Robbin, “The loss of personal privacy and its consequences for social research”. Journal of government information, vol. 28 (2001), p. 509.
31 El juny de 2005, en canvi, l'INE va posar aquests fitxers en accés totalment obert.
32 D'aquí prové la citació que encapçala aquest apartat.
33 Al contrari d'allò que es podria pensar, els usuaris entenen perfectament les restriccions. A més a més, cal tenir uns coneixements d'estadística força avançats per poder aprofitar les dades, cosa que limita el nombre d'usuaris de manera natural.
34 Cal dir que l'INE ha passat de ser refractari a vendre les microdades a biblioteques a oferir-les a tothom per mitjà del seu web. És un canvi de 180 graus en molt pocs anys!
35 Carol A. Hert, Gary Marchionini, “Information seeking behavior on statistical websites: theoretical and design implications”. En: Proceedings of the American Society for Information Science Annual Meeting (ASIS'98). (Pittsburg: American Society for Information Science, 1998), p. 304.
36 Aquesta secció es basa en el treball “La investigació en bases de dades numèriques/estadístiques”, per a l'assignatura Mètodes i tècniques en investigació documental del programa de doctorat Informació i Documentació en l'Era Digital (Universitat de Barcelona, curs 2003–04).