Resumen [Abstract] [Resum]
Dentro de la estructura de enlaces de un sitio web se pueden distinguir dos tipos principales de enlaces, los de navegación y los semánticos. Los buscadores sólo tienen en cuenta el segundo tipo, ya que aporta valor semántico a través del texto de anclaje (anchor text). En sitios no académicos, los principales motivos de creación de estos enlaces semánticos son puramente comerciales y de marketing. Una subclase de enlace de marketing es la que podríamos llamar de enlaces fraudulentos, conocidos popularmente como (enlaces) spam. La creación masiva de este tipo de enlaces (granja de enlaces, o link farm) tiene como objetivo modificar el comportamiento del algoritmo PageRank. Google ha creado el algoritmo TrustRank con la finalidad de detectar granjas de enlaces.
1 Introducción
En el marco de la World Wide Web definimos el enlace como una conexión entre un elemento de un documento de hipertexto —ya sea una palabra, frase, símbolo o imagen— y otro elemento diferente situado en el mismo documento, en otro documento, en un archivo o en un script. Por regla general, la forma más común de enlace es una palabra o imagen resaltada que el internauta puede seleccionar, obteniendo la entrega y visualización inmediata de otro archivo de texto, video o audio. El objeto resaltado, conocido como ancla (anchor), junto al objeto al que se refiere, constituyen un enlace de hipertexto.
Estos enlaces y los textos utilizados como ancla que apuntan a una página están considerados como el recurso número uno del posicionamiento web, que podríamos definir como: “el conjunto de procedimientos que permiten colocar un sitio o una página web en un lugar óptimo entre los resultados proporcionados por un motor de búsqueda”. (Codina 2004).
Los principales procedimientos de posicionamiento web se pueden dividir en dos grupos de factores que dependen del control que puede ejercer el administrador sobre ellos. Los factores internos son aquellos que el administrador del sitio web puede optimizar: las palabras clave, tanto primarias como secundarias, los títulos y las meta etiquetas. Los factores externos son aquellos que dependen de terceros, de páginas a las que, en principio, el administrador no tiene un acceso directo. En este último grupo se deben tener en cuenta el número total de enlaces entrantes así como el texto de anclaje de estos enlaces. En un caso óptimo, las mismas palabras clave que conducen a una determinada página web deberían encontrarse en el texto que actúa como anclaje de la etiqueta de un enlace entrante; así, un enlace entrante óptimo para este artículo tendría la siguiente composición: <a href="http://bid.ub.edu/16gonza1.htm">Tipología y análisis de enlaces web: aplicación al estudio de los enlaces fraudulentos y de las granjas de enlaces</a>.
El objetivo de la manipulación y creación de enlaces es modificar el comportamiento de los algoritmos de los buscadores, principalmente el del algoritmo PageRank1 de Google, dado que para determinar los rangos de los resultados de las búsquedas, los motores usan medidas de popularidad de enlaces (cantidad de sitios “relacionados” o “autoritativos” que enlazan a una determinada web).
En este artículo analizaremos en detalle la composición de los enlaces web y su manipulación. En un primer bloque estudiaremos la composición de las llamadas redes sociales, sus unidades y características básicas, y a continuación nos centraremos en la perspectiva del Análisis de redes de enlaces (Hyperlink Network Analysis, más conocido por sus siglas HNA) y las diferentes herramientas analíticas para el estudio de las comunidades. Finalizaremos este primer bloque con la perspectiva webométrica, donde destacaremos los indicadores de conectividad y las medidas topológicas aplicadas a las estructuras de enlaces.
A continuación desarrollaremos un apartado centrado en los motivos de creación de enlaces, donde trataremos la motivación académica, derivada de los estudios de redes sociales, la motivación navegadora y la motivación de negocio, para acabar con la motivación relacionada con el posicionamiento web, que nos abrirá las puertas al estudio de las comunidades de enlaces fraudulentos (enlaces spam), conocidas popularmente como granjas de enlaces (link farms), y a un nuevo algoritmo de Google llamado TrustRank.
2 Grafos, enlaces y tipologías de estructuras
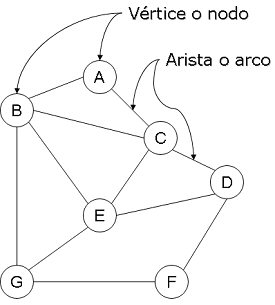
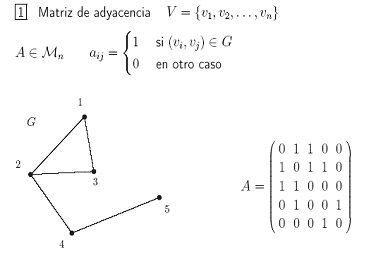
La estructura interna de un sitio web puede ser representada a través de un grafo dirigido2 G= (V, E), donde V es una colección de vértices o nodos y E es una colección de aristas o arcos en el sitio web. Los grafos finitos con n vértices, se representan como estructuras de datos por medio de una matriz de adyacencia: una matriz n-por-n cuyas entradas en la fila i y la columna j dan el número de aristas desde el vértice i-ésimo al j-ésimo.
Partes de un grafo Matriz de adyacencia de un grafo Gráfico 1. Estructura interna de un sitio web
Cada nodo posee tres atributos —ID, Concepto, Descripción— donde:
- “ID”: es el identificador de nodo.
- “Concepto”: es una palabra clave o frase que representa la categoría semántica de la página web.
- “Descripción”: es una lista de valores-nombre que describen los atributos del nodo, tales como su URL, si la página es un índice o una página de contenidos, etc.
Las aristas poseen cuatro atributos —Nodo fuente, Nodo objetivo, Tipo, Descripción— donde:
- “Nodo fuente”: es el nodo que contiene un enlace.
- “Nodo objetivo”: es el nodo apuntado por el enlace del nodo fuente.
- “Tipo”: puede ser semántico o de navegación.
- “Descripción”: es una lista de valores-nombre que describen los atributos del vértice, tales como el texto de anclaje del enlace, nombre del archivo, etc.
Dos nodos serán adyacentes si existe una conexión entre ellos, y un camino será una secuencia de nodos adyacentes, donde el primer nodo se llama origen y el segundo se llama destino. Estas conexiones entre origen y destino pueden clasificarse atendiendo a si existe una relación semántica entre los nodos, o si por el contrario su principal objetivo es el de facilitar la navegación interna del sitio.
Un enlace es de tipo semántico si las páginas conectadas poseen relaciones semánticas explícitas a través del texto de anclaje. Estas aristas o arcos que unen los conceptos de los textos de anclaje pueden dar lugar a dos tipos de relaciones semánticas: agregación o asociación de conceptos.
- La relación de agregación denota una relación jerárquica en la que el concepto de un nodo padre es más amplio que el de los nodos hijo. La relación de agregación es no-reflexiva, no-simétrica y transitiva.
- La relación de asociación es un tipo de relación horizontal en la que los conceptos están relacionados semánticamente el uno con el otro. La relación de asociación es reflexiva, simétrica y no-transitiva. Por extensión, dos nodos hijo tienen relación de asociación si ellos comparten el mismo nodo padre.
Por consiguiente, en una estructura de enlaces, un enlace es semántico si las páginas conectadas poseen una relación semántica explícita; en caso contrario se considera la arista como un enlace de navegación. Así, en una estructura tipo de directorio, los enlaces que apuntan hacia el propio sitio pueden ser clasificados dentro de los siguientes cinco grupos:
- Enlace ascendente: apunta hacia el nivel padre.
- Enlace descendente: apunta hacia un nivel inferior.
- Enlace vertical: enlace descendente específico que apunta hacia una página de un nivel inferior.
- Enlace hermano: enlaces cuya página objetivo está en el mismo nivel.
- Enlace diagonal: enlaces que apuntan hacia una página situada en otro nivel jerárquico.
Según la anterior clasificación, un enlace se considerará de navegación si responde a uno de los siguientes modelos:
- Enlace ascendente: a causa de la organización jerárquica del sitio, los enlaces ascendentes funcionan como enlaces para volver a la página anterior.
- Enlaces situados en una barra de navegación de nivel superior: cuando nos referimos a una barra de nivel superior, significa que el enlace en la barra de navegación no es un enlace descendente.
- Enlaces dentro de una lista de navegación común a las páginas web (noticias o productos recomendados): dado que el enlace no es específico de la página, sino que forma parte de un grupo de navegación, no existe relación semántica con la página que contiene el enlace.
Las estructuras de enlaces, una vez transformadas en grafos y matrices de adyacencia, permiten discernir los patrones estructurales del sitio. De esta forma las estructuras hipertextuales de un sitio web serán diferentes dependiendo de su funcionalidad dentro de la Red. Según sea la función del sitio web éste tendrá una estructura de enlaces determinada que compartirá con otros sitios similares. Amitay et al. (2003) clasificaron los diferentes tipos de sitios, según la estructura y patrones de enlaces, de la siguiente manera:
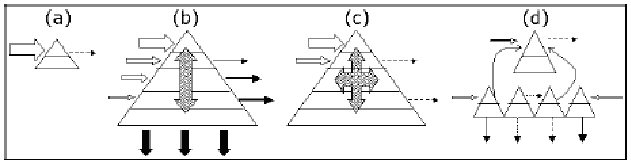
Gráfico 2. Tipología de sitios web según estructura de enlaces (Fuente: Amitay et al., 2003)
- Motores de búsqueda. Figura (a): Un motor de búsqueda aparecerá como un agujero negro en el ciberespacio, ya que, al igual que un agujero negro, un motor de búsqueda condensa en su base de datos una copia de gran parte de la Internet visible. Su sitio web es muy pequeño, la página de búsqueda y algunas pocas páginas con información corporativa o búsqueda avanzada; recibe un gran número de enlaces entrantes de otras páginas, ejerciendo una fuerte atracción gravitacional, y sus páginas contienen un número muy reducido de enlaces salientes.
- Directorios. Figura (b): Este tipo de sitios recogen una gran variedad de páginas en sus taxonomías y enlazan a su vez hacia los sitios incluidos en sus categorías. Cada nodo de la taxonomía está representado por una página web con enlaces salientes hacia cada una de las páginas que pertenezcan a esa categoría. Por tanto, los directorios tendrán miles de enlaces salientes organizados en forma de árbol taxonómico. De igual forma, los directorios también atraen muchos enlaces entrantes, tanto a su página principal como a páginas más profundas del sitio.
- Sitios corporativos. Figura (c): Los sitios corporativos normalmente poseen una robusta infraestructura interna de enlaces ya que muchas veces las páginas se crean usando una plantilla que tiene botones de enlaces ascendentes y hacia la página principal. Muchas de estas plantillas incluyen también barras navegacionales con enlaces diagonales entre diferentes ramas de la corporación. Su naturaleza comercial y corporativa hace que el número de sus enlaces salientes hacia otros sitios sea significativamente menor.
- Servicios de alojamiento (hosting) virtual. Figura (d): La estructura de enlaces interna es mucho menor en este caso. Normalmente no existe enlace entre la parte corporativa y las páginas principales (home) de los sitios hospedados. Los sitios de alojamiento web (host) pueden tener enlaces hacia el sitio de la empresa de acogida. Aleatoriamente, pueden aparecer enlaces diagonales entre sitios hospedados, si bien son superados en gran medida por el número de enlaces salientes hacia otros sitios externos. Los enlaces entrantes apuntan a los sitios hospedados y no hacia el sitio corporativo de la empresa alojadora.
- Universidades. Los sitios web de las universidades son híbridos entre sitios corporativos y servicios virtuales de alojamiento. Las partes administrativas de la universidad aparecen como un sitio corporativo, mientras que las páginas de las facultades y de los estudiantes están dispuestas de forma similar a los sitios de alojamiento web.
3 Análisis de redes de enlaces y Webometría
Han Woo Park y Mike Thelwall en su artículo titulado Hyperlink analyses of the World Wide Web: a review (2003) estudian las estructuras de enlaces desde dos perspectivas diferentes. La primera de ellas es el Análisis de redes de enlaces, que deriva a su vez de los Análisis de redes sociales, y una segunda perspectiva centrada en los estudios Webométricos, que derivan de la Ciencia de la información.
El primer acercamiento sugiere que los métodos de análisis de redes sociales pueden ser aplicados para entender la interacción entre los procesos de Comunicación Mediada por Ordenador (CMO).3 El marco teórico de este tipo de análisis (Jackson, 1997) estudia la representación e interpretación de los patrones comunicativos, partiendo de la base que las redes de enlaces son tipos de redes CMO donde los autores de sitios web están interconectados mediante enlaces. A través del análisis de la configuración de estos enlaces, se pueden discernir las “huellas digitales” de las relaciones sociales, ya sea entre personas o entre sitios web.
La “relación” (Garton et al., 1997) es la unidad fundamental de análisis de intercambios entre actores sociales y se caracteriza por los atributos de contenido, dirección y fuerza:
- El “contenido” se refiere al recurso que es intercambiado, tanto un fichero con información como el hecho de concretar una reunión.
- El tipo de relación según la “dirección” puede ser directa o indirecta (dar soporte social y recibirlo) así como simétrica o asimétrica (cuando uno de los agentes inicia más a menudo que el otro el acto de comunicación).
- La “fuerza” de la comunicación también puede variar según la intensidad y frecuencia del intercambio. Por ejemplo, los vínculos fuertes son los que se establecen a través de la provisión de servicios recíprocos o de contacto frecuente. Normalmente los pares que mantienen vínculos fuertes tienen más propensión a compartir los recursos que poseen.
3.1 Análisis de redes de enlaces
A diferencia del análisis tradicional de redes, el Análisis de redes de enlaces (ARE) tiene como fuente única de información los enlaces que extrae de los sitios web. De esta forma, el conjunto de datos extraídos de los enlaces se transforma en una matriz S simétrica n x n (conocida como 1-mode network matrix), donde n es el número de nodos en el análisis. En ARE los nodos son sitios web que representan actores sociales, y cada celda sij indica la ausencia o presencia de frecuencia de enlaces entre los nodos i y j. La fuerza de la relación puede ser expresada si cada celda representa cuántos enlaces existen entre dos nodos.
A partir de la información representada en forma de matrices, se pueden aplicar los siguientes métodos analíticos heredados del análisis de redes sociales:
- “Centralidad”. El indicador de centralidad mide la amplitud en que se desarrolla una red de enlaces organizada alrededor de los sitios web centrales. El nodo central se define como el sitio web que proporciona el mayor número de conexiones y/o las más cortas hacia los otros miembros del grupo; dependiendo de la posición de los sitios web se pueden identificar sus diferentes roles, tales como los de referenciador, broker de información, y autoridad o sitio de prestigio.
- “Densidad”. Este parámetro refleja cómo los sitios están conectados unos con otros en el conjunto de la red e indica el nivel global de integración de la misma. Para calcular el nivel de integración se extrae la proporción entre el número de relaciones o enlaces que realmente ocurren y el número de relaciones o enlaces teóricamente posibles. Así redes densamente entrelazadas poseen una considerable comunicación directa entre sus miembros, a diferencia de los de una red escasamente entrelazada.
- “Análisis de clúster”. El análisis de clúster identifica aquellos grupos de sitios web que mejor muestran sus relaciones de enlaces, generando grupos centrales y periféricos según densidades dentro del clúster.
- “Modelaje de bloques”. Este análisis descubre sitios web con similares posiciones conjuntas. Sitios web dentro del mismo bloque muestran patrones de enlaces similares hacia otros sitios. A través de esta técnica se pueden descubrir las estructuras de los diferentes roles a través del análisis de las relaciones. Con la yuxtaposición de múltiples indicadores de relación en matrices analíticas se logra colocar en un bloque todos aquellos que poseen una posición estructuralmente equivalente.
- “Escalado multi-dimensional”. Este tipo de análisis revela las posiciones que los nodos ocupan en el espacio, al transformar la matriz de conectividad de enlaces en coordinadas de dos o tres dimensiones que se pueden representar en un gráfico.
3.2 Webometría
La segunda perspectiva de Han Woo Park y Mike Thelwall (2003) a la hora de estudiar las estructuras de enlaces es la webometría. Esta visión parte de la aplicación de la bibliometría al campo de las estructuras web al establecer una analogía con la citación de artículos de revistas científicas (Larson, 1996; Rodríguez Gairín, 1997). La aplicación del análisis de citación al contexto Web pretende usar los enlaces como medida del alcance de comunicación en línea entre los propietarios de dos o más conjuntos de páginas web. Por extensión, otros investigadores han utilizado estos análisis como medidas del impacto en línea, siendo la calidad o el nivel de interés de sus contenidos las causas de la atracción de enlaces.4
Para medir e interpretar la estructura, tamaño y conectividad del web la webometría aplica diversas medidas. Pinto Molina et. al. (2003) nos muestran la definición de los diferentes indicadores utilizados en los estudios webométricos, de entre los cuales citamos los indicadores de conectividad y las medidas topológicas:
3.2.1 Indicadores de conectividad
- “Análisis hipertextual”. Este indicador tiene en cuenta el número de enlaces entrantes en un sitio web. Algunos autores hablan del concepto de popularidad entendido como el número de visitas que recibe un sitio web, y no lo diferencian del número de enlaces.
- “Densidad hipertextual”. Se define como la media aritmética del número de enlaces que tiene cada uno de los dominios o sedes. Este indicador es útil cuando se efectúan varias tomas de datos del mismo espacio en diferentes fechas. Otros autores utilizan, para analizar cada nodo, el término “densidad” como la ratio entre el tamaño de la página y el número de enlaces.
- “Índice de endogamia”. Este índice, también llamado índice de interconexión, valora los enlaces internos y muestra si los dominios se referencian básicamente a ellos mismos o si por el contrario tienen un nivel de conexión con otros dominios. Este índice utiliza la ratio entre el número de enlaces internos y el número total de enlaces; cuanto menor sea este valor, menos endogámicos serán los dominios.
- “Diámetro Web”. El diámetro es la distancia máxima para alcanzar un determinado documento dentro de un sitio web. Este indicador está relacionado con el nivel de profundidad que existe en el sitio, es decir, el número de niveles existentes en el teórico árbol jerárquico que constituiría un sitio web. El nivel de profundidad del sitio es una indicación de la posible existencia de zonas que puedan permanecer invisibles para el acceso, en el caso de existir una profundidad elevada.
- “Visibilidad”. El Web Impact Factor (WIF) (Ingwersen, 1998) es un parámetro para evaluar la visibilidad de un área de la web basada en el número de enlaces. La visibilidad es el resultado de dividir el número de citas aparecidas en el resto de sitios de la muestra por el número de páginas del sitio evaluado (ratio entre el nº de páginas que citan la sede y el nº total de páginas de la sede). El WIF se divide a su vez en WIF externo absoluto (número total de páginas externas que contienen un enlace a la página objetivo) y WIF externo relativo (el anterior dividido por las páginas del sitio objetivo).5
3.2.2 Medidas topológicas
La estructura de enlaces contiene información sobre las diferentes comunidades web. Las medidas topológicas se basan en la consideración del web como un grafo donde las páginas web se representan mediante los nodos y los enlaces se representan mediante los bordes dirigidos, denominados aristas o arcos. (Gráfico 1)
Esta perspectiva centrada en la naturaleza hipertextual del web analiza la evolución de sus dominios, calculando un conjunto de medidas que tienen en cuenta los enlaces que se dan entre las diferentes páginas web que conforman los dominios de estudio. Estas medidas pueden considerarse como medidas de similitud para los grafos, y además de obtener un valor único para cada uno de los grafos, permiten utilizar ese valor único para establecer comparaciones entre los valores de diferentes dominios. Los índices los podemos clasificar de la siguiente forma:
- “Índices de nodo”. Se valora la similitud de los nodos entre los dominios. Al obtener valores normalizados nos permite comparar los valores entre dos recogidas de datos, permitiendo así saber si son muy parecidos o no. Algunas de las medidas utilizadas son: grado de apertura, grado de entrada, status, contrastatus, prestigio, distancia convertida, centralidad y textura.
- “Índices de grafo”. Los índices de grafo permiten comparar los diferentes dominios entre sí y el mismo dominio entre diferentes recogidas de datos. Las medidas topológicas de grafo de “Compactación” y el “Stratum” permiten comparar la complejidad y conectividad de las estructuras hipertexto de los dominios web.
- “Compactación”. Un grafo que posee un alto valor de compactación indica que los diferentes nodos del grafo se pueden alcanzar o enlazar fácilmente mediante un amplio número de referencias cruzadas. Un índice de compactación bajo, cercano a cero, indica que hay una insuficiencia de enlaces y que posiblemente existan diferentes partes del grafo que se encuentran desconectadas, mientras que valores cercanos a 1 indican que la sede está totalmente conectada.
- “Stratum”. Este índice permite conocer si un sitio web se ha diseñado de una forma lineal, jerárquica, induciendo al usuario a seguir una navegación concreta o si, por el contrario, no existe una estructura jerárquica, y tampoco un orden de navegación preestablecido por el diseñador del sitio. Los valores de este índice van desde el valor 1, indicando una estructura hipertextual de tipo lineal, hasta el valor 0, que indica una estructura circular.
4 Motivos de creación de enlaces
Han Woo Park y Mike Thelwall (2003) centraron su estudio sobre enlaces en las comunidades académicas; la razón principal subyacente para la creación de enlaces en este tipo de comunidades es la cantidad de investigación que generan las organizaciones asociadas a los sitios. El ejemplo que analizan los autores es una muestra aleatoria de 414 enlaces entre universidades de GB (Wilkinson et al., 2003) en la que más del 90% tenía una motivación relacionada con la investigación o la docencia. En sus conclusiones, indican que desconocen si los patrones hallados para espacios académicos pueden ser usados para analizar otro tipo de comunidades no académicas.
En otro artículo centrado en el mundo académico, Mike Thelwall (2003) realizó una exploración cualitativa de 100 sitios web de universidades inglesas partiendo de las analogías existentes entre enlaces web y las citaciones de artículos. Gracias a esta exploración, el autor descubrió cuatro tipos de motivación para la creación de enlaces.
1) Enlaces de navegación general Son el punto de partida en la navegación para encontrar una amplia gama de información. Su utilidad deriva de la amplitud de información a la que se tiene alcance empezando a navegar desde este punto. Thelwall cita como ejemplo las revisiones bibliográficas ya que los lectores pueden usarlas como punto de partida para recuperar más artículos específicos sobre el tema.
2) Enlaces propiedad Los enlaces de propiedad, también llamados credit links, son definidos como aquellos que declaran autoría, coautoría, propiedad o copropiedad de un sitio web o de un proyecto asociado. En muchos de los casos los enlaces no son esenciales para la atribución de propiedad, ya que ésta puede ser inferida fácilmente por el texto, y se trata de enlaces para enfatizar la adscripción.
3) Enlaces sociales Son aquellos cuya razón primaria es la de reforzar lazos sociales. El autor cita el ejemplo de las páginas personales que enlazan con la página de un colaborador o un grupo de colaboradores. Sin función aparente, lo que hacen es estrechar lazos sociales a través de un cierto reconocimiento implícito en el enlace. Como el mismo autor cita, esta categoría de enlaces es que la tiene una motivación más tenue.
4) Enlaces gratuitos Los enlaces gratuitos son aquellos sin función comunicativa alguna. A pesar de que es posible imaginar un contexto en el que cualquier enlace puede ser útil, estos enlaces parecen estar ahí porque el autor de la página conoce que la organización tiene una web y decide incluirla aunque no vaya a ser útil para el que visita la página. Por tanto, el término enlace gratuito se usa para aquellos sin ninguna motivación comunicativa discernible en su creación. Thelwall añade que no se espera que estos enlaces sean usados y que no juegan ningún rol comunicativo identificable.
Cuadro 1. Tipo de motivación para crear hipervínculos (Fuente: Thelwall, 2003)
El autor reconoce la posibilidad de que las motivaciones se superpongan e incluso que en muchos casos no exista una motivación primaria clara. La informalidad y trivialidad de muchos de los enlaces, especialmente los de navegación y los gratuitos, podrían ser consideradas ruido de fondo que impediría la tentativa de aplicar con éxito técnicas bibliométricas a la web.
Por otro lado, la naturaleza de estos enlaces de navegación y gratuitos aparece mejor explicada a través en el artículo de Han Woo Park (2002), que muestra los resultados de una encuesta realizada a 64 administradores coreanos sobre motivaciones de enlace.6 Dado que son los administradores quienes deciden dónde enlazan sus sitios web, es la percepción de credibilidad de éstos la que nos interesa.
La encuesta a los administradores incluía un total de siete cuestiones:7 la primera, segunda y última de las cuestiones eran preguntas abiertas limitadas, mientras que el resto de respuestas debían ser cuantificadas en una escala donde 50 correspondía a un valor medio, mientras que 0 era un valor nulo. Siguiendo este baremo, a los administradores se les pidió que evaluasen los puntos que aparecen en la siguiente pregunta: “Cuando se decide crear un enlace con otro sitio web, ¿cómo de importante es su credibilidad en términos de veracidad, reputación, utilidad, puntualidad, competencia, seguridad y fiabilidad?”.
Los resultados de esta pregunta fueron los siguientes: veracidad 91,56; reputación 78,91; utilidad 105,81; puntualidad 85,94; competencia 90,31; seguridad 82,73 y fiabilidad 79,84. El punto más importante fue la utilidad, seguido de la veracidad y la competencia.
Además de los puntos anteriores, el autor estudió las respuestas a dos preguntas abiertas: 1) una razón para escoger un enlace con un determinado sitio web; y 2) la ventaja de los enlaces. Las respuestas a las preguntas abiertas fueron estudiadas partiendo de un análisis de frecuencias de palabras.
En las respuestas a la primera pregunta destacaron las siguientes: contents con 25 repeticiones por 20 de los administradores, relevance y similar usadas en 17 ocasiones por 17 administradores.8 Los resultados de la segunda pregunta mostraron que la palabra con mayor frecuencia era information que aparecía 14 veces y era citada por 13 (20.3 %) administradores, seguida por contents, 13 veces por 13 encuestados.9
A través de un análisis clúster de las respuestas a las preguntas abiertas de las encuestas, el autor destacó que para la primera pregunta aparecían seis grupos menores, junto a un grupo mayor de siete palabras que eran citadas por 14 administradores.
Clústers Término Interpretación Clúster 1 affiliation, relevance, topic, similar, business, type, contents Este clúster muestra que la mayoría de sitios proporciona enlaces a sus sitios afiliados. La similitud de contenidos influencia la afiliación entre sitios web. Los sitios web eligen a sus afiliados por el tipo de negocio.
Clúster 2 information, sharing, useful Este clúster identifica aquellos administradores cuyas respuestas delatan la preocupación por compartir información útil entre los sitios web.
Clúster 3 marketing, public, relations Este clúster sugiere que el intercambio de enlaces puede contribuir al aumento de oportunidades de marketing.
Clúster 4 connectedness, interface, quality, exchange, win Este clúster es un grupo que no muestra una clara interpretación.
Clúster 5 current, augmenting Éste muestra que los sitios web deciden sus enlaces para aumentar la información de sus páginas.
Clúster 6 mother company Esto significa que algunos sitios web cooperan sistemáticamente con otros sitios que pertenecen a la misma empresa madre. Estos sitios web normalmente son llamados sitios hermanos.
Clúster 7 revenue, banner, advertising Éste muestra que los anuncios localizados en sus páginas son una fuente de ingresos para los sitios web.
Tabla 1. Motivación de los enlaces (Fuente: Woo Park, 2002)
El análisis clúster para la segunda pregunta reveló que las 25 palabras con mayor frecuencia formaban un grupo mayor y siete menores:
Clústers Términos Interpretación Clúster 1 various, kinds, providing, convenience, relevant, information, exchange, contents Los administradores esperan los siguientes aspectos cuando deciden enlazar con otro sitio web: relevancia, información, intercambio de contenidos, e incremento del contenido actual.
Clúster 2 revenue, marketing, advertising Este clúster refleja el uso de un enlace como un nuevo vehículo de publicidad.
Clúster 3 current augmenting Este clúster muestra que los sitios web ofrecen enlaces a otros sitios para maquillar o expandir sus propios contenidos.
Clúster 4 increasing visitors Los enlaces a otros sitios pueden atraer (con engaño) visitantes a sus propios sitios.
Clúster 5 user, navigation, interface Términos relativos a diseño de sitios web. Una estructura de enlaces bien organizada puede mejorar la interfaz del usuario.
Clúster 6 trust transfer Seleccionando un enlace a un sitio de renombre aumenta la confianza del usuario.
Clúster 7 don’t know Este clúster muestra que los administradores no están seguros acerca de las ventajas de los enlaces.
Clúster 8 web site, pursuing, porta Esto indica que la ventaja de los enlaces está en proveer una amplia gama de información.
Tabla 2. Ventajas de los enlaces (Fuente: Woo Park, 2002)
Woo Park defiende que el número de enlaces existentes entre sitios web es un buen indicador de la calidad de los mismos. Como reflejan algunos de los clústers que acabamos de ver, el número de enlaces entrantes a un sitio web está correlacionado positivamente con la calidad y credibilidad del sitio. A partir de los resultados de esta encuesta se deduce que es posible medir la credibilidad de un sitio web basándonos en el análisis de enlaces entrantes. Sin embargo, en el siguiente apartado introducimos una nueva perspectiva en las motivaciones de creación de enlaces, recuperando así la perspectiva de posicionamiento web que vimos en la introducción. Desde el punto de vista del posicionamiento web comentaremos uno a uno estos clústers, complementando así la visión parcial que ha ofrecido esta encuesta a los administradores.
5 Posicionamiento web y motivación de enlaces
Desde el punto de vista de un buscador, o desde la perspectiva del posicionamiento web si se quiere, sólo las relaciones semánticas explícitas tienen importancia. Los enlaces internos de un sitio, en la mayor parte de los casos navegacionales, no se tienen en cuenta a la hora de calcular el ranking de los buscadores, ya que tales enlaces se eliminan durante los procesos de indexación. Los enlaces externos, los que se supone dotados de valor semántico, son tratados para ser convertidos en matrices, y los textos de anclaje, donde presumiblemente está la información de relación semántica, se incluyen en los cálculos de ranking.
Como apuntamos en la introducción del artículo, los enlaces pertenecen al grupo de los factores externos ya que el administrador, en principio, no tiene acceso a aquellas páginas que enlazan con su sitio. La solución a esta falta de accesibilidad ha sido la creación de páginas artificiales que apuntan hacia una página objetivo, páginas cuya acumulación ha creado verdaderas comunidades de enlaces fraudulentos, conocidas como granjas de enlaces.
Volviendo al artículo de Woo Park, éste señaló en sus conclusiones que los análisis clúster sugerían que las motivaciones y ventajas de los enlaces podían ser clasificadas en dos dimensiones: la de navegación y la relacionada con propósitos comerciales. Este segundo aspecto, el de los propósitos comerciales, es la principal —si no única— motivación en la creación de comunidades y páginas web mercenarias.
A continuación analizaremos las motivaciones anteriormente expuestas desde el punto de vista de los enlaces fraudulentos, intentando clasificarlo, si es posible, según las categorías aportadas por Thelwall y Woo Park.
De forma paralela a la exposición del apartado anterior, empezaremos con la tipología de enlaces que nos mostraba Thelwall (2003), aplicando su clasificación a la tipología de enlaces fraudulentos:
1) Enlaces de navegación general vs. enlaces fraudulentos En algunos casos los enlaces fraudulentos pueden servir como puertas de partida para encontrar una amplia gama de información. En muchos casos las comunidades de enlaces fraudulentos no sólo enlazan con las páginas objetivo sino que también lo hacen con páginas de calidad reconocida, para alcanzar así altas puntuaciones nodales para determinados algoritmos; sin embargo, éste no es su objetivo primordial. El clasificar algunos enlaces fraudulentos como enlaces de navegación general es un hecho puramente circunstancial, ya que los objetivos a optimizar suelen ser muy concretos, y sólo a efectos de “maquillaje” se enlaza con portales generales de reconocido prestigio.
2) Enlaces propiedad vs. enlaces fraudulentos Los enlaces fraudulentos pueden ser enlaces propiedad en aquellos casos en los que la página mercenaria es un duplicado de una original (por ejemplo tener registrado el mismo nombre dominio y/o variantes en diferentes dominios de primer nivel, top-level domains). En el caso de las granjas de enlaces ocurre lo contrario, ya que siempre se intenta evitar que sea reconocido el propietario de esta técnica fraudulenta de posicionamiento.
3) Enlaces sociales vs. enlaces fraudulentos Aunque, según Thelwall, están caracterizados por una motivación tenue, podríamos clasificar los enlaces fraudulentos como enlaces sociales. Siendo la razón primaria la de reforzar lazos sociales, los enlaces fraudulentos cumplen este propósito, si bien de forma no ética. Desde el punto de vista de los buscadores, los enlaces fraudulentos son puramente sociales, ya que cada uno de ellos pasa a reforzar, no ya el lazo social, sino la posición en el ranking de la página de un colaborador o un grupo de colaboradores.
4) Enlaces gratuitos vs. enlaces fraudulentos Los enlaces fraudulentos podrían ser clasificados dentro del conjunto de enlaces gratuitos, ya que —como aquéllos— no se espera que nadie los use. El rol comunicativo tampoco existe, siendo su única función de la sumar otro enlace entrante a la página objetivo en la base de datos de un buscador.
Cuadro 2. Tipología de enlaces y enlaces fraudulentos (Adaptación de Thelwall, 2003)
Al tratar la tipología de enlaces según Woo Park y su aplicación a los enlaces fraudulentos, analizaremos y glosaremos cada uno de los clústeres resultantes (en este apartado proporcionamos una traducción al castellano de los términos). Los siete clústeres de la primera pregunta (Tabla 1) eran los siguientes:
Clústers Términos Interpretación Clúster 1 afiliación, relevancia, tema, similar, negocio, tipo, contenidos Desde la perspectiva de los enlaces fraudulentos se da afiliación con el sitio objetivo, si bien no tiene porque haber ningún tipo de similaridad de contenidos.
Clúster 2 información, compartiendo, útil En el caso de las páginas y comunidades de enlaces fraudulentos, éstas también pueden llegar a ser útiles a los usuarios. Los directorios de enlaces fraudulentos a veces son fuentes nodales adecuadas si reúnen en una página enlaces relacionados con una categoría determinada. Los tres nombres asociados a esta categoría pueden ser aplicados a los enlaces fraudulentos.
Clúster 3 marketing, público, relaciones Aunque Woo Park mencionaba en este apartado que el “intercambio” de enlaces contribuía a incrementar las oportunidades de marketing en la web, desde el punto de vista de los enlaces fraudulentos, el intercambio debería ser sustituido por la palabra “creación”. El objetivo de crear oportunidades de marketing sigue siendo parte fundamental en los enlaces fraudulentos. Si llega a la una granja de enlaces a través de los resultados de un buscador, el usuario puede alcanzar el sitio objetivo, cumpliendo así el fin de oportunidad de marketing. Si por el contrario el enlace fraudulento no pertenece a una granja sino que está camuflado y mezclado con cientos de mensajes en un guestboard o en un blog, también cumple el fin de marketing al incrementar artificialmente la popularidad de su sitio objetivo.
Clúster 4 conectividad, interfaz, calidad, intercambio, ganancia Aunque para Woo Park este clúster no ofrecía una interpretación clara, desde la perspectiva de los enlaces fraudulentos alcanza un mayor sentido. Así, podríamos interpretar que los enlaces fraudulentos son oportunidades para “ganar dinero a través de una interfaz de calidad optimizada, y a través de la conexión a una gran red de enlaces o granjas de enlaces”.
Clúster 5 corriente aumentar En este caso, en vez de aumentar el caudal de información, nos referiríamos a aumentar la cantidad de enlaces entrantes hacia el sitio objetivo.
Clúster 6 madre compañía Este clúster da a entender la importancia de las relaciones fraternales entre sitios web y comunidades. Desde el punto de vista del spam podríamos entender que se trata de la posible colaboración entre dos granjas de enlaces sembradas por el mismo administrador, que puede vincular en el próximo rastreo (crawling) de algún buscador. También podríamos interpretar que “madre” se refiere a la página objetivo mientras que la “compañía” son los enlaces fraudulentos.
Clúster 7 ingreso, banner, publicidad Podríamos considerar esta razón como la más adecuada de todas las respuestas desde la perspectiva de los enlaces fraudulentos. El fin de cualquier práctica de posicionamiento fraudulento no es otro que el de publicitar una página web y generar así ingresos. Es de sobra sabido que detrás de la creación de comunidades artificiales para manipular los resultados de los buscadores hay un gran movimiento monetario. Desde el famoso Adwords o su versión Yahoo hasta la técnica más baja de la manipulación de resultados vía granjas de enlaces, todas ellas tienen el mismo objetivo, generar ingresos a través de la publicidad.
Tabla 3. Motivación de los enlaces y enlaces fraudulentos (Adaptación de Woo Park, 2002)
El análisis clúster para la segunda pregunta reveló que había un grupo mayor y siete menores (Tabla 2). No hemos añadido comentarios a los tres últimos clústeres dada la vaguedad de los términos:
Clústers Términos Interpretación Clúster 1 diversos, tipos, suministrar, conveniencia, relevante, información, intercambio, contenidos En el caso de los enlaces fraudulentos no siempre se ofrece información relevante, ya que la creación del enlace viene causada por una contrapartida monetaria. Tampoco se da intercambio de contenidos ni un aumento de los contenidos del sitio web.
Clúster 2 ingreso, marketing, publicidad Similar al clúster 7 de la tabla anterior, en este el clúster refleja que los enlaces son usados como un nuevo vehículo de publicidad. Si bien los enlaces fraudulentos no podrían ser considerados como vehículos de publicidad, un gran número de ellos si que podría aumentar el ranking de un sitio en concreto que actuase como vehículo publicitario.
Clúster 3 corriente aumentar Ver Clúster 5 de la tabla anterior.
Clúster 4 aumentar visitante Sinónimo de generar tráfico, esta respuesta está estrechamente relacionada con el segundo clúster. Los enlaces fraudulentos pueden generar visitas directamente -si una página de una granja de enlaces aparece en los resultados de un buscador-, o indirectamente -al aumentar el ranking de la página objetivo-.
Clúster 5 términos relativos a diseño de sitios web: usuario, navegación, interfaz. Para este clúster el comentario de Woo Park era: "una estructura de enlaces bien organizada puede mejorar la usabilidad”. Las páginas de enlaces fraudulentos, soporte de estos enlaces, también deben gozar de una buena usabilidad, no ya tanto enfocada hacia el usuario humano sino hacia el funcionamiento del robot de los buscadores. De esta manera, la estructura de la interfaz debe facilitar la navegación a través del sitio para que el robot indexe todas y cada una de las páginas que contienen los enlaces fraudulentos.
Tabla 4. Ventajas de los enlaces y enlaces fraudulentos (Adaptación de Woo Park, 2002)
6 Comunidades artificiales y granjas de enlaces
Los algoritmos usados para cuantificar la importancia de una página o comunidad web basados en la información extraída de los enlaces, son el objetivo primordial de los administradores de páginas de enlaces fraudulentos (spammers), y las granjas de enlaces su elemento mas representativo. La problemática que de esto se deriva ha transcendido hasta el mundo académico, donde el estudio de los enlaces fraudulentos se ha convertido en tema central de muchos artículos.
El artículo de García Molina y Gyöngyi (2004), titulado Web spam taxonomy, destaca por su claridad a la hora de exponer todas técnicas de enlaces fraudulentos que se usan hoy en día para manipular los resultados de los buscadores de Internet.10 De este artículo nos interesa la visión que dan los autores desde la perspectiva del optimizador fraudulento, el administrador de páginas de enlaces fraudulentos (en adelante “administrador fraudulento”), tanto en lo que se refiere a la tipología de páginas web como en lo referente a la optimización de enlaces.
Según García Molina y Gyöngyi, para un administrador fraudulento existen tres tipos de páginas en la web:
- “Inaccesibles”: son las páginas que el no puede modificar. Sus enlaces salientes están fuera de su alcance. Únicamente puede apuntarlas.
- “Accesibles”: páginas mantenidas por terceros, que pueden ser manipuladas de alguna manera por el administrador fraudulento. Se pueden agregar mensajes en un guestbook que contengan enlaces hacia el sitio de enlaces fraudulentos o incluirlos en k de referidos. Su número es limitado, aunque la revolución de los blogs ofrece grandes posibilidades.
- “Páginas propias”: páginas mantenidas por el administrador fraudulento, quien tiene control total sobre sus contenidos. El objetivo es impulsar una o más de sus páginas en el ranking. Hay un cierto coste de mantenimiento (registro de dominios y web hosting) por lo que el número total de páginas de enlaces fraudulentos depende del presupuesto del administrador fraudulento.
Las técnicas de enlaces fraudulentos basadas en enlaces pueden ser agrupadas dependiendo de si añaden enlaces salientes hacia páginas populares o si por contra recogen enlaces entrantes hacia una página objetivo o grupo de páginas:
- “Enlaces salientes”: Los administradores fraudulentos pueden añadir manualmente enlaces salientes hacia páginas populares con el objetivo de incrementar el ranking nodal de su página. El método más extendido para la creación de un número masivo de enlaces salientes es la clonación de directorios que listan sitios relevantes para diferentes temas y subtemas. Los administradores fraudulentos pueden replicar parte o la totalidad de las páginas de un directorio (DMOZ Open Directory, dmoz.org, o el Yahoo! directory, dir.yahoo.com) creando rápidamente estructuras masivas de enlaces salientes.
- “Enlaces entrantes”: Para incrementar el número de enlaces entrantes a una página o grupo de páginas, el administrador fraudulento puede adoptar alguna de las siguientes estrategias:
- Crear un tarro de miel (honey pot): un conjunto de páginas que proveen algún tipo de recurso útil (p.e., copias de páginas de documentación Unix), pero que también incluyen/esconden enlaces hacia la página objetivo de los enlaces fraudulentos. El tarro de miel hace que gente enlace hacia este sitio, aumentando así el ranking de la página objetivo.
- Infiltrarse en un directorio web: Algunos directorios web permiten a los administradores enviar enlaces a sus sitios bajo alguno de los temas del directorio. Si los editores de dichos directorios no verifican el contenido de estos enlaces, los administradores fraudulentos pueden haber incluido en el directorio enlaces que apunten hacia sus páginas objetivo. Ya que los directorios poseen altas puntuaciones, como la nodal y la de autoridad, esta técnica de enlaces fraudulentos es muy útil a la hora de aumentar tanto el PageRank como el grado de autoridad de las páginas objetivo.
- Incluir enlaces en tablones de anuncios o libros de visita: Si estos tipos de páginas carecen de control por parte de los administradores, el spammer puede incluir enlaces hacia sus páginas de enlaces fraudulentos bajo la inocente apariencia de simples mensajes.
- Participar en intercambio de enlaces: Algunas veces los spammers establecen intercambios de enlaces entre sus sitios.
- Crear su propia granja de enlaces: Hoy en día los administradores fraudulentos pueden controlar un gran número de sitios y crear arbitrariamente estructuras de enlaces que aumentarían el ranking de algunas páginas objetivo. Aunque este acercamiento era caro hace algunos años, en la actualidad es muy común dado que los costes de registro de dominio y de alojamiento han bajado drásticamente.
García Molina y Gyöngyi también mostraron los modelos óptimos de comunidades artificiales, en un artículo posterior titulado Link spam alliances (2005). En este artículo, su modelo de granja de enlaces se basa en las siguientes pautas:
- Cada granja de enlaces tiene una sola página objetivo. La página objetivo es aquella que pretende ser optimizada en una posición de “top10” por lo que el administrador fraudulento se concentra en aumentar el ranking de esta página
- Cada granja de enlaces posee un número fijo de páginas anzuelo (boosting) cuyo objetivo es el de mejorar el ranking de la página objetivo, posiblemente apuntando hacia ella. Estas páginas anzuelo están bajo el control absoluto del administrador fraudulento. Se asume que existe un límite en el tamaño de las granjas de enlaces derivado de los costes de mantenimiento.
- El administrador fraudulento ha acumulado enlaces de páginas externas a su granja de enlaces a través de directorios o libros de visitas, enlaces conocidos como “enlaces secuestrados” (hijacked links). El PageRank total de la granja de enlaces proveniente de estos enlaces es conocido como “filtración” (leakage). El spammer no tiene control total sobre estas páginas que contienen enlaces secuestrados; su único objetivo es conseguir cuantos más enlaces de este tipo mejor, y preferentemente de páginas que posean un alto PageRank.
La estructura óptima para una granja de enlaces con una única página objetivo consiste en k páginas boosting que apuntan directamente a la página objetivo, que a su vez apunta a cada una de las páginas de la granja y que recibe del exterior un número — de filtraciones.
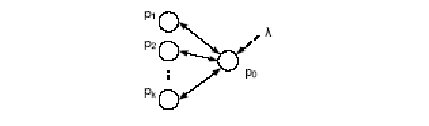
Gráfico 3. Estructura óptima de granja de enlaces (Fuente: García Molina y Gyöngyi, 2005)
García Molina y Gyöngyi destacan, en el mismo artículo, que las estructuras óptimas pueden ser fácilmente detectables por lo que los administradores fraudulentos pueden intentar evitar las mejores estructuras, a pesar de que los rankings de sus páginas objetivo puedan disminuir. Aún así, los administradores fraudulentos no se desviarán demasiado de estas estructuras óptimas, por lo que las estructuras reales se parecerán a las estudiadas en este artículo. Para finalizar, se muestra una estructura irregular que a pesar de su forma esconde una alianza de siete granjas de enlaces.
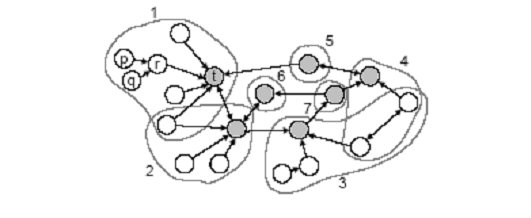
Gráfico 4. Estructura irregular de una granja de enlaces (Fuente: García Molina y Gyöngyi, 2005)
La aparición de este artículo generó automáticamente comentarios en los foros de optimización web sobre la incompatibilidad del modelo teórico con la realidad de la Web.11 Por ejemplo, se consideró improbable la unión de diversas granjas de enlaces mediante enlaces bidireccionales, ya que los administradores fraudulentos no enlazaban sus granjas de enlaces desde las páginas objetivo. En el comentario al artículo se muestra una visión más real de una granja de enlaces donde se combinan páginas legítimas y enlaces fraudulentos. Esta combinación consigue eludir el algoritmo PageRank a través de páginas legítimas y no legítimas que enlazan con la página objetivo, consiguiendo así disminuir el riesgo de ser capturadas como páginas de enlaces fraudulentos.
7 El algoritmo PageRank
Merlino-Santesteban (2003) divide en tres los tipos de algoritmos de ordenación por relevancia basados en conectividad: dependientes, cuasi-dependientes o independientes de la consulta del usuario. El algoritmo PageRank es el mejor ejemplo del tipo de algoritmos independientes de la consulta del usuario, los cuales asignan una puntuación a una página, independientemente de la búsqueda proporcionada. Estos algoritmos producen un ranking independientemente de la similitud consulta-documento, puesto que su objetivo principal es medir la calidad intrínseca de una página.
El PageRank de una página web no es influenciado por la página en sí misma o por alguna consulta potencial, sino que se basa solamente en determinaciones de importancia aportadas por los enlaces. PageRank parte de un grafo construido a priori, que utiliza la información de los enlaces entrantes para asignar valores de importancia global a cada una de las páginas de la Web. De este modo, PageRank calcula la importancia de una página otorgando a cada enlace que se dirige a ella un peso proporcional a la autoridad de la página que lo contiene. Para determinar la autoridad de la página citante, el PageRank es utilizado iterativamente unas 100 veces hasta que los valores convergen.
La fórmula del PageRank es la siguiente:
PR(A) = (1–d) + d (PR(T1) / C(T1) +... + PR(Tn) / C(Tn))
Los elementos que aparecen en ella son los siguientes:
- PR(A): es el PageRank de la página de referencia.
- d: es un factor de debilitación.
- (1-d): asegura que cualquier página, aunque no reciba ningún enlace, tendrá un PR mínimo de 0'15.
- PR(Ti)/C(Ti): es el PageRank (PR) de la página i-ésima que enlaza a la web de referencia, (Ti), dividido por todos los enlaces (C) que también salen de esa página Ti, es decir, el PR que transmite.
- i = 1,...,n: ya que se suponen n páginas que enlacen a la de referencia.
PageRank se basa en un mutuo refuerzo entre páginas: la importancia de una determinada página influencia y a la vez está siendo influenciada por la importancia de las otras páginas que contienen su enlace.
Según recientes análisis del algoritmo, García-Molina et al. (2004) han mostrado que la puntuación total de PageRank (“rtotal”) para un grupo de páginas depende de cuatro factores:
rtotal = rstatic + rin - rout - rsink
en donde “rstatic” es la puntuación obtenida de la puntuación de la distribución estática; “rin” es la puntuación que llega a las páginas a través de los enlaces entrantes desde páginas externas; “rout” es la puntuación que sale de las páginas a través de sus enlaces saliente hacia páginas externas; y “rsink” es la puntuación perdida a través de las páginas sin enlaces salientes (sink pages) del grupo. De la fórmula anterior se deriva la estructura óptima de enlaces que maximiza la puntuación de la página objetivo.
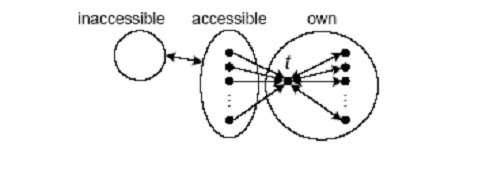
Gráfico 5. Estructura óptima para mejorar posicionamiento web de una página (Fuente: García Molina et. al., 2004)
Esta estructura facilita la accesibilidad a las páginas propias (Own) a través de las accesibles, cosa que también les abre las puertas a ser indexadas por los robots de los buscadores. Para maximizar el PageRank de la página objetivo (t) se pueden utilizar las siguientes estrategias:
- Usar todas las páginas propias disponibles de la granja de enlaces para maximizar la puntuación “rstatic”.
- Acumular el máximo número de enlaces entrantes desde las páginas accesibles A hacia la granja de enlaces, maximizando así la puntuación “rin".
- Suprimir los enlaces que apuntan hacia fuera de la granja de enlaces haciendo así que la puntuación “rout” tienda a cero.
- Evitar las páginas hundidas (sink pages) dentro de la granja, asegurándonos que cada página (incluyendo t) posee algún enlace saliente y consiguiendo así que “rsink” sea cero.
La estructura de enlaces que maximiza la puntuación de la página K debe seguir las siguientes reglas:
- Hacer que todas las páginas accesibles y propias apunten directamente a la página objetivo, maximizando así su puntuación entrante.
- Añadir enlaces desde t hacia todas las páginas propias. Sin estos enlaces, t perdería una parte importante de su puntuación, convirtiéndose en una página hundida, y las páginas propias permanecerían inalcanzables desde fuera de la granja de enlaces. La puntuación que sale de t “refluye” hacia ella misma a través de la granja de enlaces, a través del circuito cerrado formada por ella y la granja.
Esta es la teoría por la que se rigen los administradores fraudulentos a la hora de crear cantidades masivas de enlaces hacia sus páginas objetivo. A este respecto, Baeza-Yates et al. (2005) han elaborado un artículo centrado en el incremento de PageRank bajo diferentes tipologías de colusión, comprobando la debilidad del algoritmo ante un Sybil attack.12 Para beneplácito de los administradores fraudulentos, las conclusiones muestran que si bien cualquier grupo de nodos pueden incrementar su PageRank formando un “subgrafo” estrechamente conectado, el incremento de PageRank que obtienen está inversamente relacionado con el PageRank de partida, esto es, que nodos con un PageRank bajo que lleven a cabo este tipo de ataque verán mucho más incrementado su ranking.
8 El algoritmo TrustRank
Desde el punto de vista de los criterios internos de optimización, la simple acumulación de palabras clave en forma de texto oculto en una sola página se considera una técnica arcaica de optimización, que además puede ser fácilmente identificada y eliminada mediante un vector de análisis de términos. A raíz de su fácil detección, los administradores fraudulentos han perfeccionado otras técnicas para generar contenidos bien estructurados, focalizados temáticamente y ricos en palabras clave relevantes que encajan con los términos de búsqueda de los usuarios. Una vez “saturadas” las posibilidades de optimización interna, han apostado por los Sybil attacks y el efecto TKC13 (Tightly-Knit Communities) con el objetivo de modificar el ranking de los algoritmos comerciales a través de comunidades artificiales en las que cada una de sus páginas está estrechamente focalizada en alguna de palabra clave popular.
De esta manera, durante los últimos años la mayor preocupación de los administradores fraudulentos se ha centrado en el PageRank, que algunos consideran el principal criterio externo para la optimización. Recientemente han aparecido en el mundo del posicionamiento web noticias que advierten que la importancia del PageRank ha sido modificada y que hoy en día su valor es menor. Aún así, la preocupación por el PageRank y por su manipulación ha alcanzado al mundo académico, convirtiendo a la lucha contra los enlaces fraudulentos en protagonista de muchos artículos científicos.
De entre los artículos destaca el de García-Molina et al. (2004), que propone el algoritmo TrustRank para combatir los enlaces fraudulentos. Los autores señalan que la detección algorítmica de enlaces fraudulentos es muy difícil si no se cuenta con asistencia humana. Por este motivo, para la creación de su algoritmo contra los enlaces fraudulentos parten de un conjunto de páginas simiente (seed pages), clasificadas o no como basura por un editor humano. La premisa básica del TrustRank es que las páginas buenas normalmente apuntan hacia páginas buenas y raramente hacia páginas de enlaces fraudulentos. Tras la selección de un grupo de páginas buenas, se les asigna puntuaciones altas de confianza. A continuación siguieron un acercamiento similar al del PageRank, dado que las puntuaciones de confianza se propagan hacia otras páginas a través de sus enlaces salientes. Finalmente, tras la integración con los resultados de PageRank, las páginas con altas puntuaciones de confianza se consideraron como páginas buenas.
9 Conclusiones
Podemos considerar la estructura de enlaces de la web como una red semántica en la que las palabras o frases que aparecen en el texto de anclaje son nodos que establecen relaciones semánticas a través de las aristas. Sin embargo, a pesar del paralelismo entre la citación académica y los enlaces, éstos son radicalmente diferentes, ya que los enlaces carecen del formalismo de las citaciones en publicaciones académicas. La prueba más fehaciente de esta falta de formalismo es la motivación subjetiva de los administradores y además la aparición de comunidades artificiales cuyo único objetivo es el de impulsar a un determinado sitio web en el ranking.
El interés por las estructuras de enlaces y su repercusión sobre los algoritmos de los buscadores comerciales tiene su reflejo en toda la producción científica aparecida recientemente en la red. Es de esta misma documentación de la que se nutren los responsables del posicionamiento web, quienes conocen las debilidades de los principales algoritmos, así como las posibles soluciones de lucha contra los enlaces fraudulentos.
A modo de colofón nos gustaría destacar esta paradoja, y es el hecho de que el interés comercial y el académico se retroalimentan: los primeros creando comunidades artificiales, los segundos intentando encontrar soluciones a las técnicas de posicionamiento fraudulento, y dando así pistas a los administradores de páginas fraudulentas para mejorar sus modelos, que volverán a ser objeto de estudio por el mundo académico.
Bibliografía
Amitay, Einat et al. (2003). The connectivity sonar: detecting site functionality by structural patterns. <http://www.ht03.org/papers/pdfs/5.pdf>. [Consulta: 10/05/2006].
Baeza-Iots, Ricardo; Castell, Carlos; López, Vicente (2005). Pagerank increase under different collusion topologies. <http://airweb.cse.lehigh.edu/2005/baeza-yates.pdf>. [Consulta: 10/05/2006].
Codina, Lluís (2004). “Posicionamiento web: conceptos y ciclo de vida”. Hipertext.net, nº 2. <http://www.hipertext.net/web/pag216.htm>. [Consulta: 10/05/2006].
Garton, Laura; Haythornthwaite, Caroline; Wellman, Barry (1997). “Studying online social networks”. JCMC, vol. 3, no. 1 (June). <http://jcmc.indiana.edu/vol3/issue1/garton.html>. [Consulta: 10/05/2006].
García-Molina, Héctor; Gyöngyi, Zoltán (2005). “Web spam taxonomy”. En: First International Workshop on Adversarial Information Retrieval on the Web (AIRWeb’05), 10–14 Maig 2005, Chiba, Japan. <http://airweb.cse.lehigh.edu/2005/gyongyi.pdf>. [Consulta: 10/05/2006].
García-Molina, Héctor; Gyöngyi, Zoltán; Pedersen, Jan (2004). “Combating web spam with TrustRank”. En: Proceedings of the Thirtieth International Conference on Very Large Data Bases, Toronto, Canada, August 31 – September 3 2004. <http://www.vldb.org/conf/2004/RS15P3.PDF>. [Consulta: 10/05/2006].
García-Molina, Héctor; Gyöngyi, Zoltán (2005). Link spam alliances. March 2, 2005. Technical report. <http://blog.searchenginewatch.com/blog/pdf/linkalliance.pdf>. [Consulta: 10/05/2006].
Ingwersen, Peter (1998). “The calculation of web impact factors”. Journal of Documentation, vol. 54, no. 2, p. 236–243.
Jackson, M. H. (1997). “Assessing the structure of communication on the world wide web”. Journal of Computer-Mediated Communication, vol. 3, no. 1. <http://jcmc.indiana.edu/vol3/issue1/jackson.html>. [Consulta: 10/05/2006].
Larson, R. R. (1996). “Bibliometrics of the World Wide Web: an exploratory analysis of the intellectual structure of cyberspace”. En: Hardin, S. (ed.). Proceedings of the 59 th Annual Meeting, ASIS 96. Baltimore, pàg. 71–79. <http://sherlock.berkeley.edu/asis96/asis96.html>. [Consulta: 10/05/2006].
Lempel, R.; Moran, S. (2000). “The stochatic approach for link-structure analysis (SALSA) and the TKC effect”. En: Proceedings of the 9 th World Wide Web Conference (WWW9). <http://www.csd.uwo.ca/courses/CS868b/papers/salsa.pdf>. [Consulta: 10/04/2006].
Merlino-Santesteban, Cristian (2003). “Análisis de conectividad en la recuperación de información web”. Ciência dóna Informação, vol. 32, no. 3 (set./dez.), pàg. 113–119. <http://www.scielo.br/pdf/ci/v32n3/19030.pdf>. [Consulta: 10/05/2006].
Pinto Molina, María et al. (2003). “Visibilidad de la investigación de las Universidades españolas a través de sus páginas web en el ámbito del espacio europeo de enseñanza superior: análisis, evaluación y mejora de la calidad”. Programa de estudio y análisis para la mejora de la calidad de la enseñanza superior y profesorado universitario. Granada, 2003. <http://wwwn.mec.es/univ/html/informes/estudios_analisis/resultados_2003/EA2003-0012/VISIWEB.pdf>. [Consulta: 10/01/2006].
Rodríguez i Gairín, J. M (1997). “Valorando el impacto de la información en Internet: AltaVista, el ‘Citation Index’ de la red”. Revista española de documentación científica, vol. 20, nº 2, p. 175–181. <http://bd.ub.es/pub/rzgairin/altavis.htm>. [Consulta: 10/05/2006].
Thelwall, Mike (2002). “A comparison of sources of links for academic Web Impact Factor calculations”. Journal of Documentation, vol. 58, no. 1, pàg. 66–78. <http://www.scit.wlv.ac.uk/~cm1993/papers/2002_%20Sources_of_links_for_WIF_Calculations.pdf>. [Consulta: 10/05/2006].
Thelwall, Mike (2003). “What is this link doing here? Beginning a fini-grained process of identifying reasons for academic hyperlink creation”. Information research, vol. 8, no. 3 (April). <http://informationr.net/ir/8-3/paper151.html>. [Consulta: 10/05/2006].
Wilkinson, David et al. (2003). “Motivations for academic web site interlinking: evidence for the Web as a novel source of information on informal scholarly communication”. Journal of Information Science, vol. 29, no. 1, pàg. 49–56. <http://jis.sagepub.com/cgi/content/abstract/29/1/49>. [Consulta: 10/05/2006].
Woo Park, Han (2002). “Examining the determinants of who is hyperlinked to whom: a survey of webmasters in Korea”. First Monday, vol. 7, no. 11 (November 4th). <http://www.firstmonday.org/issues/issue7_11/park/>. [Consulta: 10/05/2006].
Woo Park, Han; Barnett, George A. (2002). “Hyperlink-affiliation network structure of top web sites”. Journal of the American Society for Information Science and Technology, vol. 53, issue 7 (July), pàg. 592–601.
Woo Park, Han; Thelwall, Mike (2003). “Hyperlink analyses of the World Wide Web: a review”. Journal of Computer-Mediated Communication, vol. 8, no. 4. <http://jcmc.indiana.edu/vol8/issue4/park.html>. [Consulta: 10/05/2006].
Fecha de recepción: 15/02/2006. Fecha de aceptación: 20/03/2006.
Notes
1 El PageRank (PR) es un valor entre 1 y 10 que depende de la cantidad y calidad de las webs que tengan enlaces hacia la web de referencia, así como de sus enlaces internos. El PR transmitido por los sitios depende a su vez del PR propio y del número de enlaces salientes que tenga esa página. La fórmula básica del PR es la siguiente: PR(A) = (1-d) + d (PR(T1)/C(T1) +...+ PR(Tn)/C(Tn)).
2 Los grafos pueden ser dirigidos cuando existe un sentido o dirección en la conexión entre ellos, como por ejemplo un enlace entrante o saliente, y cuando no se indica dirección se dice que el grafo es no dirigido.
3 Traducción de la versión inglesa Computer-Mediated Communication (CMC).
4 Éste es el razonamiento que aplican los motores de búsqueda a la hora de cuantificar la cantidad de enlaces entrantes de una página web.
5 Los problemas derivados de una correcta definición de área objetivo, así como los problemas en el cálculo del número de enlaces derivados de la inclusión de mirrors, ha dado lugar a una multiplicación de los parámetros según la densidad y el tamaño de los dominios (Thelwall & Smith, 2002). Los cuatro parámetros utilizados son los siguientes:
- Número total de enlaces.
- Número total de enlaces dividido por el número total de páginas del sitio(s) objetivo.
- Número total de enlaces dividido por el número total de páginas en el sitio(s) fuente.
- Número total de enlaces dividido por el número total de páginas en los sitios fuente y objetivo.
Han Woo Park y Mike Thelwall (2003) recomiendan el uso combinado de los cuatro parámetros ya que cada método aporta una perspectiva diferente de los datos. El primero aporta unan visión del total de enlaces en el conjunto, mientras que el último permite ver la tendencia subyacente de los enlaces al dividirlos por el tamaño. En el segundo parámetro, al dividir por el número de páginas objetivo, se muestra qué sitios atraen a más enlaces por página y de dónde provienen estos enlaces. Al dividirlo por el tamaño de la fuente tenemos un indicador sobre qué sitios albergan el mayor número de enlaces por página y los sitios que son su objetivo.6 Según el autor, cuando un sitio web se halla en un estado prematuro de desarrollo debe cuidar qué enlaces establece y con quién. Siendo el principal objetivo de cualquier sitio web el de acumular tráfico para su sitio, los enlaces que ofrece deben ser acordes con el mismo, ofreciendo enlaces externos hacia aquellos servicios de los que carece y que pueden ser de utilidad para sus potenciales usuarios.
7 1) La razón para escoger un enlace a un determinado sitio web. 2) La ventaja de los enlaces. 3) La fiabilidad de los sitios web enlazados. 4) La profesionalidad o experiencia de los sitios enlazados. 5) La seguridad de los sitios enlazados. 6) La valoración del incremento de la credibilidad de su sitio web al enlazarlo con otro de credibilidad mayor. 7) Afiliación de la información.
8 Las siguientes palabras con más frecuencia de aparición fueron: business, type, company, information, useful, topic y advertising. Además de éstas, también aparecieron frecuentemente términos tales como affiliation, augmenting, marketing, banner, mother, sharing, current, exchange, revenue, win, connectedness, interface, public, quality y relations.
9 Las siguientes palabras con mayor frecuencia fueron: augmenting, navigation, Web site, current, don’t, know, relevant, y convenience. También aparecieron con una frecuencia alta: increasing, interface, marketing, portal, pursuing, transfer, various, advertising, exchange, providing, trust, user, kinds, revenue y visitors.
10 Incluso los propios autores se permiten la licencia de utilizar en el formato pdf de su artículo palabras claves escondidas que ejemplifican la técnica de enlaces fraudulentos más rudimentaria.
11 <http://www.seomoz.org/articles/link-spam-alliances.php>.
12 “Sybil attack” es el intento de alterar un sistema de recomendación creando múltiples identidades, en nuestro caso, creando múltiples páginas apuntando a una sola página.
13 Lempel y Moran (2000) observaron que un efecto lateral en las propiedades del algoritmo HITS era que en un grafo que contiene múltiples comunidades, el algoritmo HITS fijará su atención sólo en una de ellas, dándole una alta posición en el ranking. Será aquella que contenga sus páginas centrales y su autoridad más estrechamente interconectadas. Estas partes más estrechamente conectadas de un grafo se conocen por las siglas TKC (Tightly-Knit Communities).