Resum [Resumen] [Abstract]
Els complements per a navegadors web (add-on) n'estan ampliant les funcionalitats. Entre aquests complements, es pot destacar l'aparició recent del LibX, una eina que permet la interacció entre l'OPAC d'una biblioteca i el web. En aquest article, s'estudien les limitacions d'aquesta eina, quant a la detecció automàtica de dades i l'automatització de tasques, amb l'objectiu de proposar un sistema (NextLib) que, mitjançant la combinació de diverses aplicacions, permeti de superar-les. Aquest sistema hauria d'estar format per una base de dades semàntica (LibX), un programa de detecció automàtica de dades (Data Detector) i un programa que aprèn a partir d'exemples (learning by example, LBE). La integració d'aquestes eines hauria de permetre una interacció més gran entre l'usuari i un lloc web, i també entre el web i un OPAC.
1 Introducció
"La Web Semántica es un conjunto de iniciativas, tecnológicas en su mayor parte, destinadas a crear una futura World Wide Web en la cual los ordenadores puedan procesar la información, esto es, representarla, encontrarla, gestionarla, como si los ordenadores poseyeran inteligencia"(Codina, 2003).
Com es pot interpretar d'aquesta definició, el web semàntic no és altra cosa que la suma de tècniques d'intel·ligència artificial aplicades a gestionar la informació continguda en les pàgines web. D'aquesta manera, en navegar per Internet, l'usuari hauria de poder recuperar aquesta informació amb més eficiència que actualment, ja que els programes usats haurien de ser capaços de raonar i d'aprendre per si mateixos.
Això significa que els sistemes de recuperació d'informació (motors de cerca, directoris, etc.) podrien respondre a preguntes de l'usuari, malgrat que la resposta no es trobés explícitament en la base de dades. Gràcies a una representació i manipulació eficient de la informació, podrien inferir una resposta.
Per aquestes raons i perquè els cercadors són aquests programes que permeten a l'usuari de fer preguntes i recuperar les pàgines web en què es pot trobar la informació que hi respongui, la majoria d'iniciatives cap al web semàntic s'han orientat a millorar-los i els han considerat com la peça clau del web.
Tanmateix, no solament s'haurien de tenir en compte els motors de cerca. Els navegadors (programes que permeten de visualitzar una pàgina web) han anat evolucionant fins a començar a proporcionar cada vegada més serveis i funcionalitats (Monistrol; Codina, 2007). Aquestes novetats (barres de tasques, eines específiques, etc.) estan ajudant a millorar la interactivitat de l'usuari que navega per Internet.1
En el camp de la informació i documentació, destaca l'aparició recent de les barres d'eines LibX, les quals permeten de fer cerques de termes seleccionats en una pàgina web en l'OPAC d'una biblioteca, i produir una relació usuari-informació-navegador-OPAC.
El LibX fa possible l'expansió dels serveis que una biblioteca pot oferir als usuaris a través d'Internet. És una manera d'apropar l'OPAC a l'usuari, sigui on sigui.
Malgrat els avantatges innombrables, es constaten certes limitacions. En aquest sentit, es pretén mostrar com es poden superar aquestes limitacions si s'apliquen certes tècniques d'intel·ligència artificial. Així doncs, els objectius d'aquest treball són els següents:
- Analitzar el funcionament del LibX per mostrar-ne les limitacions d'ús.
- Mostrar algunes tècniques d'intel·ligència artificial que podrien millorar les prestacions del LibX, i analitzar al seu torn les limitacions que tenen.
- Proposar una integració de totes les aplicacions, de manera que unes complementin les altres i formin el sistema anomenat NextLib.
En primer lloc, s'estudia la barra d'eines LibX: com apareix, els serveis que proporciona, les biblioteques que l'implementen, el funcionament i les restriccions d'ús.
En segon lloc, es presenten les aplicacions de detecció automàtica de dades com a via possible per solucionar algunes de les limitacions del LibX. Se n'estudia la incorporació en navegadors a través de les Smart Tags i l'AutoLink, i s'analitza aquest últim cas. S'indiquen també les limitacions que aquests programes tenen quant a semàntica, realització d'accions i aspectes ètics associats amb l'ús.
En tercer lloc, s'estudia l'ús de les bases de dades semàntiques com a eina que també pot solucionar les limitacions dels Data Detector. S'assenyala la conveniència de desenvolupar aquest tipus de bases de dades per aplicar-les en dominis concrets, mitjançant la construcció d'ontologies.
Finalment, després de mostrar dues aplicacions pioneres (Miro i Creo), es proposa, a partir d'aquestes investigacions, un sistema (NextLib) basat en l'ús combinat del LibX, el Data Detector, les bases de dades semàntiques i els programes que aprenen a partir d'exemples (learning by example, LBE). D'aquesta manera, es pot millorar el LibX i aconseguir una navegació més orientada a l'objectiu dels usuaris.
2 Material i mètodes
Per a l'anàlisi del LibX, s'ha baixat i instal·lat la versió que proporciona el Consorcio Madroño per al navegador Firefox, en concret la que correspon a la Biblioteca de la Universidad Complutense de Madrid, elegida aleatòriament entre la resta de les ofertes, que eren igualment vàlides per a aquest estudi.
Després de la instal·lació se n'ha comprovat el funcionament mitjançant la selecció d'una paraula a la mateixa pàgina web d'inici del navegador <http://www.google.es/firefox> i la consulta al catàleg de la Biblioteca de la Universidad Complutense de Madrid.
Per a l'anàlisi del Data Detector AutoLink, s'ha baixat la versió anglesa de la barra d'eines del Google en el navegador Internet Explorer. El funcionament s'ha analitzat a través de la detecció de l'ISBN després de la consulta d'una mateixa obra en el catàleg de la Universitat Politècnica de València i de la Biblioteca Nacional de España. L'elecció dels catàlegs esmentats ha estat motivada pel fet que cada un visualitzava l'ISBN de manera diferent.
Per a l'estudi de la base de dades semàntica ConceptNet, s'ha baixat el paquet complet des del web del projecte <http://web.media.mit.edu/~hugo/conceptnet/#download>.
Finalment, els estudis directes del Data Detector Miro i de l'LBE Creo no s'han pogut dur a terme, ja que els autors ens han comunicat que el programari no està disponible. L'estudi es basa, per tant, en els treballs publicats.
Totes aquestes tasques s'han completat durant el mes de maig de 2007.
3 Firefox Extension for Libraries (LibX)
El LibX és una eina desenvolupada el 2005 per la University Library i el Department of Computer Science de la Virginia Tech. Funciona com un complement del Firefox que permet un accés integrat als recursos d'una biblioteca des del navegador, com una barra d'eines (Bailey; Godmar, 2006).
Una de les motivacions principals d'aquest projecte van ser els resultats d'un estudi dut a terme per l'OCLC el 2005, titulat College students': perceptions of libraries and information resources (De Rosa, 2005), en què s'indicava que aproximadament el 89 % d'estudiants començava un procés de cerca (sobre un tema concret) mitjançant un motor de cerca, mentre que únicament un 2 % el començava a partir de l'OPAC d'una biblioteca.
Mentre que els motors de cerca proporcionen avantatges indubtables, com ara la velocitat, la facilitat d'ús i els costos baixos per a l'usuari; les biblioteques proporcionen una precisió i credibilitat més grans en els resultats de la cerca.
Així doncs, la idea era oferir una eina que fos capaç d'integrar tots aquests avantatges: la cerca en un catàleg d'una biblioteca des d'un navegador a través d'una barra d'eines.
Els serveis que proporciona són bàsicament els següents:
- Accés al catàleg de la biblioteca mitjançant una barra d'eines integrada al navegador.
- Cerques directes de termes seleccionats al Google Scholar.
- Possibilitat de crear equacions de cerca directament a la barra d'eines.
- Possibilitat de llegir múltiples OPAC simultàniament.
- Cerques mitjançant el servei XISBN (instal·lació addicional).
- Diverses possibilitats de selecció dels termes de cerca.
Actualment, prop de seixanta biblioteques (la majoria dels EUA), tant acadèmiques com públiques, ofereixen serveis del LibX i prop de noranta estan en període de prova.2
A Espanya, la iniciativa més gran l'ha adoptat el Consorcio Madroño, que ha desenvolupat una adaptació de la barra d'eines LibX per a les biblioteques que en formen part.
S'ofereix la possibilitat de baixar una barra d'eines comuna a totes les biblioteques del Consorcio, o bé una barra d'eines per a cada biblioteca. Amb l'objectiu de provar el servei, s'ha baixat la barra LibX corresponent a la Biblioteca de la Universidad Complutense de Madrid.
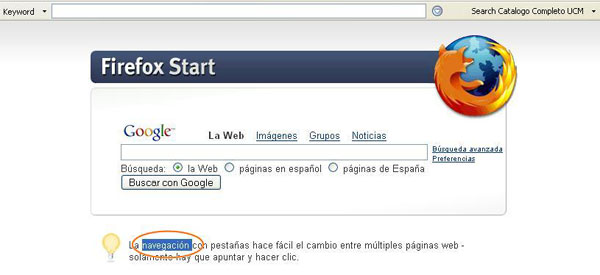
Figura 1. Selecció de text (font: elaboració pròpia)
En la part superior de la figura 1, hi ha la barra LibX, instal·lada i inserida correctament en el navegador.
L'usuari ha d'elegir quina paraula o frase desitja mitjançant la selecció directa amb el ratolí. En aquest cas, s'ha seleccionat la paraula navegación, que apareix a la pàgina inicial del Firefox en castellà. La selecció es pot fer des de qualsevol pàgina web que estigui consultant l'usuari.
L'elecció es pot dur a terme de dues maneres diferents:
- Mitjançant un clic amb el botó dret del ratolí.
- Seleccionant i arrossegant la paraula cap a les diferents zones de cerca de la barra ("Scholar", "Search Catálogo Completo UCM" o el quadre de cerca).
En el cas del quadre de cerca, s'ha d'escollir el tipus corresponent al text elegit. Per exemple, cal especificar si navegación es considera com a matèria, com a descriptor, etc. En aquest cas, la funció és prou òbvia, encara que si s'hagués escollit un nom de persona no ho seria tant.
Després de fer la selecció i prémer la tecla de retorn, el navegador obre automàticament el catàleg de laBiblioteca de la Universidad Complutense en una finestra nova (encara que es pot configurar de manera que l'obri en una pestanya nova o en la mateixa finestra), fa la cerca automàticament i en mostra el resultat.
A més, podem obrir tots els quadres de cerca que vulguem, de manera que l'equació de cerca sigui més completa, encara que de moment no permet operadors booleans (per defecte executa un "AND").
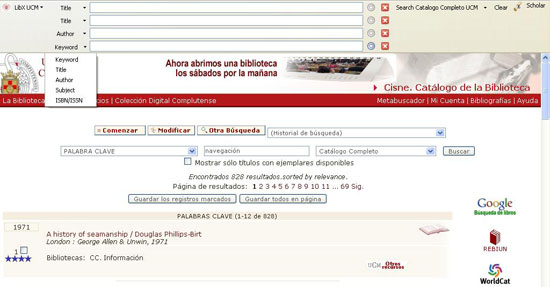
Figura 2. Quadre de cerca estès del LibX (font: elaboració pròpia)
Per a l'exemple anterior, obtenim la pantalla de resultats que es mostra en la figura 2: el sistema ha recuperat un resultat mitjançant la cerca a través de la matèria navegación. En la part superior es mostra l'aspecte que tenen els quadres de cerca, preparats perquè l'usuari hi introdueixi termes nous.
Si el terme elegit s'arrossega a la icona "Scholar", situada en la part superior dreta de la pantalla, el sistema fa una cerca automàtica del terme al Google Scholar.
A continuació, es mostra la pantalla de resultats que obtindríem per a navegación:
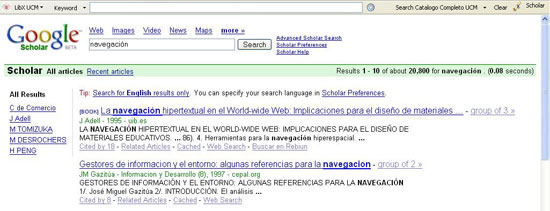
Figura 3. Cerca automàtica al Google Scholar (font: elaboració pròpia)
Com s'ha pogut observar, l'ús de les barres d'eines LibX permet de combinar la facilitat i la rapidesa de la navegació en el web, amb la precisió i la confiança que proporcionen les cerques dutes a terme en l'OPAC d'una biblioteca. La possibilitat de seleccionar una paraula o frase, i poder fer cerques en catàlegs o en altres llocs, obre una via per oferir una interactivitat més gran a l'usuari.
Tanmateix, malgrat els avantatges indubtables que ofereix, presenta una sèrie de limitacions:
- L'usuari ha d'elegir una paraula o frase concreta i decidir-ne el rol, cosa que provoca que certes accions resultin complexes, sobretot les que exigeixen la selecció d'un nombre de termes elevat.
- Les funcions són limitades i no ampliables sense programació.
- Les accions estan exclusivament relacionades amb recursos de l'OPAC.
- El sistema no recorda les accions de l'usuari.
Moltes de les limitacions del LibX es podrien resoldre mitjançant l'ús dels Data Detector. Ara bé, aquests programes presenten també una sèrie de problemes relacionats amb la semàntica i les accions dels usuaris.
4 Data Detector
Un Data Detector és un programa capaç de reconèixer estructures de dades i permetre la realització d'operacions múltiples. Té la funció de relacionar els tipus de dades detectades amb les accions particulars, a fi d'optimitzar el temps en què s'executen les accions rutinàries per a l'usuari i la usabilitat de les aplicacions.
El desenvolupament d'aquest tipus d'aplicacions va començar durant la dècada de 1990, i es va centrar en la quantitat de classes diferents de dades que es podien identificar i en la flexibilitat a l'hora de configurar accions coherents amb els tipus de dades seleccionades. Des de llavors fins a l'actualitat, els Data Detector han anat evolucionant, des del primer ús en l'escriptori i els documents de l'usuari, fins al salt recent al web.
Encara que la tecnologia que en fa possible el funcionament en l'actualitat està àmpliament superada, la implementació en els navegadors obre un món de possibilitats per descobrir, i converteix els Data Detector en la base per a la construcció d'interfícies web orientades als objectius dels usuaris.
Els Data Detector van arribar als navegadors guiats per les grans firmes del sector de la informàtica i Internet, com ara Microsoft, amb les Smart Tags, i Google, amb l'AutoLink. L'acceptació enorme que han tingut els usuaris pel que fa als productes comercials d'aquestes empreses va despertar les sospites i els recels dels desenvolupadors de llocs web, que veien en l'ús d'aquestes aplicacions un aprofitament indegut dels continguts web (Hugues; Carr, 2002).
Les Smart Tags, llançades el 2001 com a part del Windows XP, permetien a Microsoft d'inserir els seus enllaços a qualsevol pàgina web que es visualitzés a través del navegador Internet Explorer. Aquests enllaços apareixien amb un subratllat discontinu de color porpra, per diferenciar-los dels enllaços originals. Quan el cursor es col·locava sobre una paraula marcada com a Smart Tags, apareixia una llista d'enllaços relacionats. Davant les enormes crítiques rebudes, Microsoft va posar la tecnologia Smart Tags disponible per als usuaris que la volguessin, però no com a part del seu sistema operatiu. Alhora va desenvolupar una metaetiqueta que permetia als desenvolupadors web de deshabilitar la funció Smart Tags de les seves pàgines.
L'AutoLink, llançat el 2005, és capaç d'escanejar una pàgina web i de detectar tres tipus diferents de dades: adreces postals, identificadors de vehicles (VIN) i identificadors de llibres (ISBN).
Encara que en principi només funcionava per als EUA, a poc a poc les funcionalitats han anat augmentant, tot i que no es disposa encara de gaire informació sobre com funciona realment.
Malgrat que només és capaç de detectar tres tipus de dades, l'AutoLink té un interès especial per al documentalista, ja que pot detectar ISBN i associar-los una acció.
Un exemple d'ús en la detecció d'ISBN es mostra a continuació:
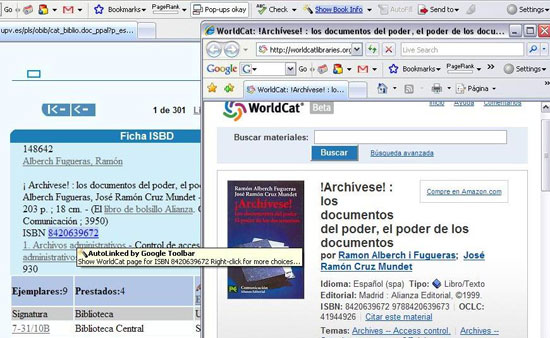
Figura 4. Exemple de l'AutoLink (font: elaboració pròpia)
En aquesta figura observem com, per a la cerca al catàleg de la Universitat Politècnica de València <http://www.upv.es/bib> de l'obra Archívese, en la part superior s'activa la funció de l'AutoLink que mostra el missatge: "Show book info". Després de fer-hi clic, detecta els ISBN escrits a la pantalla del navegador.
En aquest cas s'il·lumina l'ISBN corresponent a la fitxa catalogràfica. Si es col·loca el cursor sobre de l'ISBN, s'observa que s'ha transformat en un enllaç que apunta a un URL, en aquest cas al catàleg compartit WorldCat.
Si es clica l'enllaç, s'obre el catàleg WorldCat, en què el sistema ha dut a terme automàticament la cerca de l'ISBN, i se'n mostra el resultat.
Malgrat tot, aquest sistema presenta una sèrie d'inconvenients que impedeixen aconseguir una bona interactivitat amb els usuaris. Aquests inconvenients són els següents:
- Cerques predeterminades: l'usuari no pot afegir-hi enllaços nous.
- Algoritme de detecció d'ISBN no gaire eficient.
Vegem amb exemples aquests dos problemes:
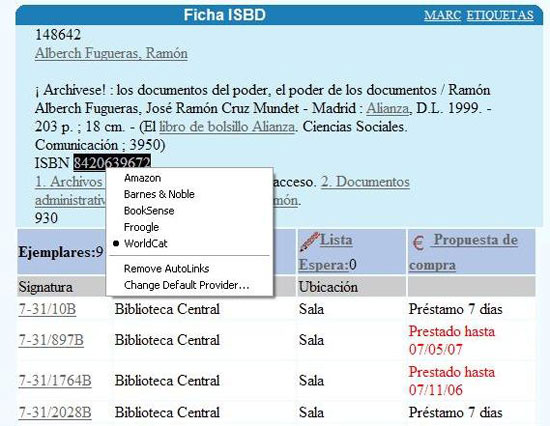
Figura 5. La detecció de l'ISBN de l'AutoLink (font: elaboració pròpia)
Per al mateix exemple anterior, es mostren les possibilitats que ofereix l'AutoLink. Com s'ha comentat, el funcionament està predeterminat per al WorldCat. L'usuari no pot modificar, en cap moment, aquesta opció, ni afegir-hi enllaços d'interès nous, de manera que la interactivitat és limitada.
Quant a l'algoritme de detecció, s'ha fet una cerca del mateix llibre al catàleg de la Biblioteca Nacional de España <http://www.bne.es>. En la figura 6, podem observar com l'ISBN no es mostra de la mateixa manera que abans (els deu números seguits), sinó que intercala guions per separar les quatre àrees del codi. L'AutoLink no detecta l'ISBN, i mostra el missatge "No items found".
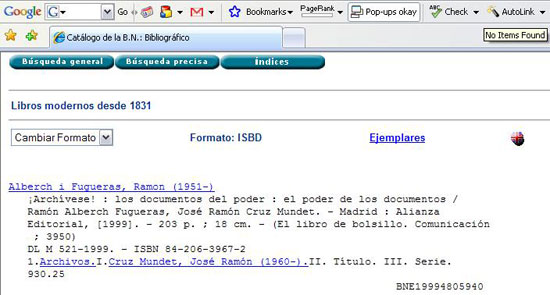
Figura 6. Catàleg de la Biblioteca Nacional de España (font: elaboració pròpia)
4.1 Limitacions
Els Data Detector presenten una sèrie de problemes relacionats directament amb les dues tasques principals que desenvolupen: la identificació d'estructures de dades i l'associació d'accions a cada una de les estructures. Les dues tasques estan programades des del principi, per la qual cosa són sistemes tancats. Tanmateix, la dificultat de programar a priori tots els tipus de dades que es voldran usar i totes les accions que es pretendran de dur a terme pot superar-se (en dominis delimitats) amb l'ús de tècniques d'intel·ligència artificial.
Les aplicacions LBE són sistemes d'aprenentatge que permeten de gravar seqüències d'accions associades amb l'objectiu de l'usuari i que es poden reproduir quan l'objectiu es repeteix. Permetrien de generalitzar accions d'usuari, encara que el problema principal que presenten és, justament, la generalització, que es va perfeccionant per l'evolució constant d'aquests sistemes i l'ús associat a bases de coneixement semàntic.
La detecció de les dades té com a obstacle l'ambigüitat del llenguatge. L'ús de bases de dades amb coneixement semàntic i la concreció a un camp més específic de coneixement pot expandir el nombre de dades recognoscibles i eliminar l'ambigüitat, respectivament.
5 Bases de dades semàntiques
Les bases de dades amb contingut semàntic intenten de representar les relacions que els humans estableixen entre les paraules, i procuren fer ontologies i controlar el vocabulari no només des del punt de vista lèxic, sinó també des del punt de vista conceptual.
De manera natural, l'ésser humà estableix relacions entre els conceptes que van més enllà de la forma sintàctica o gramatical d'una frase, relacions basades en l'experiència i en aspectes espacials, físics, temporals i psicològics del dia a dia. En l'àmbit de la intel·ligència artificial (Liu; Singh, 2004a), aquesta manera de concebre el món ha rebut el nom de coneixement del sentit comú (common sense knowledge), i és el que pretenen representar aquestes bases de coneixement.
Des de l'inici de la intel·ligència artificial, fa cinquanta anys, s'està intentant de representar la xarxa conceptual de l'ésser humà (Pitrat, 1998). El llenguatge és l'inconvenient principal que s'ha trobat a l'hora d'intentar que un ordinador imiti el comportament i la manera de pensar dels humans.
Es poden destacar tres projectes de bases semàntiques que aborden l'estudi i l'intent de representació de la xarxa conceptual de l'ésser humà: Cyc, WordNet i ConceptNet (Liu; Singh, 2004b). Encara que la finalitat és la mateixa, l'aproximació a la representació conceptual parteix de supòsits diferents: Cyc pretén representar el sentit comú en un marc formal i lògic; WordNet posa l'èmfasi en el lèxic i com es classifica, i ConcepNet intenta incloure el llenguatge natural i representar-ne la capacitat de fer inferències a través de les relacions establertes entre els termes.
5.1 Limitacions i problemes
Tot i que les bases de coneixement semàntic suposen grans avenços cap a l'ordinador "intel·ligent", hi ha un obstacle evident que planteja una sèrie de limitacions a les funcionalitats potencials: la impossibilitat d'incloure-hi tot el coneixement. Quant temps és necessari per "capturar" tota la realitat?, existeixen els mitjans tècnics per poder representar, aplicar i usar òptimament els milions de conceptes i relacions del coneixement del sentit comú?
En aquest sentit, Lluís Codina (2007) és força explícit:
"Insistir en que las ontologías permitirán razonar a los ordenadores y realizar inferencias sobre los contenidos, no de un dominio del conocimiento bien delimitado y para unas tareas específicas (como ya sucede), sino de la web en su conjunto y en todos los ámbitos del conocimiento y de la realidad, es, hoy por hoy, no querer ver precisamente la simple realidad. No existe ninguna evidencia empírica ni base conocida alguna para que esto pueda funcionar, ni a corto ni a medio plazo."
Per tant, es considera que, per a un ús adequat i funcional de les bases semàntiques, se n'hauria de restringir l'aplicació a un domini concret, en què els conceptes i les relacions que entressin en joc fossin limitats, i alhora més fàcilment representables.
6 Navigator's Extension Tool for Libraries (NextLib)
Un cop vista la interactivitat entre el web i l'OPAC d'una biblioteca gràcies al LibX, es considera que la integració amb les diverses aplicacions descrites anteriorment pot implicar una millora considerable.
6.1 Estudi previ
La primera gran experiència per combinar un Data Detector amb tècniques d'intel·ligència artificial per detectar dades al web data del 2006. Alexander Faaborg i Henry Lieberman van desenvolupar Creo (un LBE) i Miro (un Data Detector) per usar-los de manera combinada amb ConceptNet (Faaborg; Lieberman, 2006).
Gràcies a l'ús de la base de dades semàntica, Miro és capaç d'expandir els tipus de dades que detecta a un nombre infinit, en concret a tot el coneixement emmagatzemat a ConceptNet. Miro fa un mapatge dels termes i les frases que apareixen en la pàgina web que està visualitzant l'usuari i duu a terme generalitzacions gràcies a la base de dades semàntica. Aquestes generalitzacions les compara amb les fetes prèviament amb Creo, que descriuen tasques d'usuari. D'aquesta manera, és capaç d'associar la generalització d'un tipus de dada amb una acció, que en cap cas no és predeterminada, sinó que l'ordinador, gràcies a Creo, és capaç d'anar creant i aprenent segons les tasques que duu a terme un usuari.
Els resultats obtinguts per aquests investigadors fan presagiar que aquesta línia d'investigació pot proporcionar uns resultats molt interessants i servir com a base per aconseguir una interacció entre l'usuari i el web basada en els seus objectius.
6.2 El sistema NextLib
A partir de l'anàlisi prèvia i tenint en compte els avantatges i inconvenients de les eines que es volen usar, es proposa la integració del NextLib, un sistema format per LibX, un Data Detector, un LBE i una base de dades semàntica, cosa que permetria d'augmentar les prestacions del LibX (o d'una altra aplicació similar).
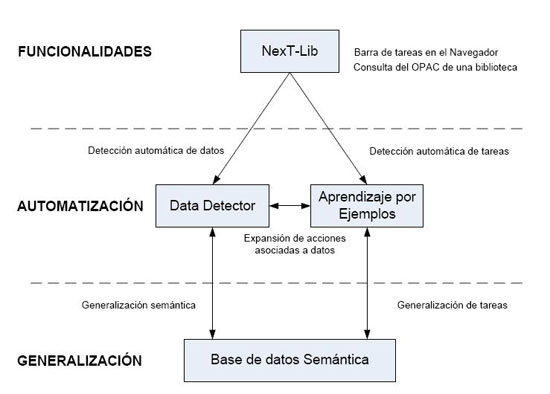
Figura 7. Model del NextLib (font: elaboració pròpia)
6.3 Components
El Data Detector permetria de seleccionar, en una pàgina web determinada, tots els conceptes que es corresponguessin o es relacionessin amb un tipus de dada concreta (autor, editor, títol, matèria o ISBN). Per tant, no caldria que l'usuari seleccionés la paraula i li indiqués el rol (encara que podria fer-ho). D'altra banda, només es podrien detectar els conceptes que integressin la base de dades de coneixement semàntic, consideració que resulta fonamental per comprendre el sistema.
L'LBE (no entra en els objectius del treball l'anàlisi completa d'aquest tipus d'aplicacions) afavoriria l'adaptació del sistema al gust de l'usuari i permetria de relacionar accions determinades als tipus de dades, gravant-les i ampliant la llista d'accions bàsiques que l'usuari volgués —per exemple, afegir enllaços d'interès a pàgines relacionades amb un concepte determinat.
L'ús de la base de dades de coneixement semàntic queda justificat per l'aplicació dels Data Detector i els LBE. Els dos programes depenen de les bases de dades de coneixement semàntic: es detecten els conceptes que pertanyen a una classe determinada (autor, títol, etc.) o s'hi relacionen, i s'associen les accions amb aquestes mateixes classes.
6.4 Funcionament
El NextLib podria dur a terme cerques en l'OPAC d'una biblioteca, o de diverses, a partir de paraules seleccionades o detectades en una pàgina d'un lloc web determinat, i executar accions i cerques noves amb conceptes relacionats.
La idea és aplicar el NextLib a un lloc web concret amb contingut especialitzat en un àmbit determinat del coneixement, cosa que permetria la construcció d'una base de dades semàntica (pretendre d'incloure un coneixement més general no seria viable) i que relacionaria automàticament els termes detectats amb l'OPAC d'una biblioteca, d'un centre de documentació, d'una llibreria, etc., amb fons de la temàtica esmentada.
Quan l'usuari navegués per aquest lloc web, podria posar en funcionament el NextLib i detectar automàticament els termes d'interès d'una pàgina web determinada (únicament els que fan referència a l'àmbit de coneixement en qüestió, no tots els continguts al web). Gràcies a la base de dades semàntica es podrien fer les generalitzacions apropiades, i oferir uns termes generals i unes accions associades, una de les quals podria ser la consulta en un OPAC determinat (cosa que ja fa el LibX).
Per exemple, si se suposa la navegació pel lloc web d'un museu i el desenvolupament corresponent d'una ontologia sobre art —una part de la qual podria ser la mostrada en la figura 8—, un usuari que navegués pel web esmentat podria seleccionar (o detectar) la paraula expresionismo abstracto —com ja fa el LibX. El Data Detector entraria en acció i consultaria la base de dades semàntica que, per inferència, arribaria a Lichtenstein (i a altres pintors), que és el node central, i oferiria accions possibles —de manera que milloraria el resultat del LibX:
- Cerca a la Viquipèdia.
- Cerca a l'OPAC, amb possibles variants:
- Pel terme, si existeix, com a node central (matèria, títol) en la base de dades semàntica.
- Pels termes inferits, és a dir, Lichtenstein i la resta d'artistes relacionats en la base de dades semàntica.
- Accions programades pel mateix usuari.
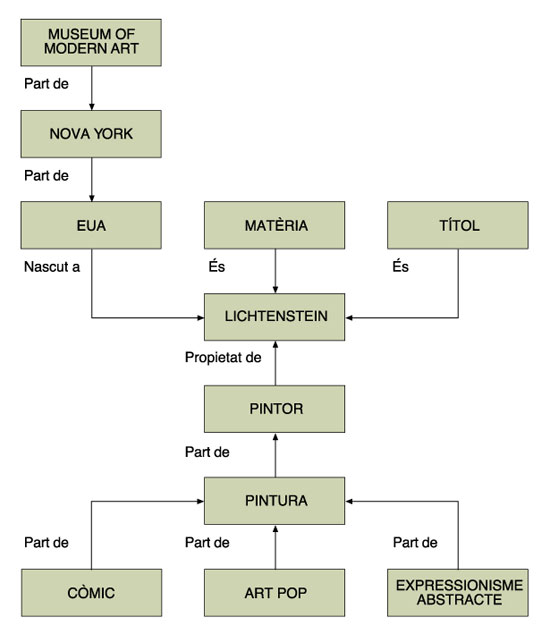
Figura 8. Relacions semàntiques sobre art modern (font: elaboració pròpia)
Escapa dels objectius d'aquest treball el disseny complet de les relacions que formarien aquesta xarxa semàntica. La figura anterior és tan sols un exemple, a tall orientatiu, de les relacions de ConceptNet.
Hem d'establir una diferència clara entre la base de dades bibliogràfica, accessible des de l'OPAC, que recull totes les dades relacionades amb una col·lecció, i la base de dades de coneixement semàntic, que estableix les relacions conceptuals entre els termes explícits i implícits que apareixen en un web determinat, amb contingut delimitat a una branca del coneixement concret.
Els propòsits i les funcions són diferents: la base de dades semàntica infereix dades i, a través del Data Detector i l'LBE, ofereix opcions de cerca; en canvi, la base de dades bibliogràfica, consultada des de l'OPAC, recupera registres bibliogràfics segons les opcions esmentades.
6.5 Avantatges
Els avantatges principals d'usar un sistema d'aquestes característiques serien els següents:
- L'ampliació dels serveis que una biblioteca (o llibreria) ofereix als usuaris d'un web especialitzat.
- Més interacció de l'usuari, a través del navegador, amb la informació especialitzada continguda en una pàgina web, cosa que afavoriria l'accés tant a altres webs (gràcies als enllaços) com a material disponible en determinades biblioteques (gràcies a les cerques en l'OPAC).
- Més facilitat de trobar informació dins el mateix lloc web. Els desenvolupadors podrien preconfigurar el NextLib amb enllaços interns entre conceptes importants.
- La possibilitat de cooperació entre webs d'una mateixa temàtica, atès que es comparteix una mateixa ontologia.
6.6 Limitacions
Malgrat els avantatges que suposaria aquest sistema, la implementació hauria de tenir en compte una sèrie de limitacions. Destaquen, entre d'altres:
- La detecció de l'ISBN: els algoritmes de detecció haurien de tenir en compte les maneres diferents en què apareixen representats els ISBN.
- La convergència OPAC-NextLib: les prestacions del NextLib haurien d'estar d'acord amb les de l'OPAC de la biblioteca, a fi d'evitar equacions de cerques al navegador impossibles d'executar en l'OPAC.
- Seria necessari un control del vocabulari en la redacció de continguts en les pàgines del lloc web, d'acord amb l'ontologia creada.
- Així com el LibX estén l'ús a qualsevol pàgina web, el NextLib s'hauria de circumscriure a un lloc web concret, ja que l'ús es limitaria a l'ontologia amb què es treballi.
- Només funcionaria en webs determinades amb continguts molt específics, en què es pogués elaborar una ontologia, com ara museus, portals temàtics, informacions científiques, etc.
7 Conclusions
Les eines com ara el LibX, elaborades per facilitar la interacció entre el web, l'usuari i l'OPAC de la biblioteca, són un primer acostament a les interfícies d'usuari orientades a objectius, aplicades al món de la documentació. Malgrat els avantatges, presenten limitacions en la detecció automàtica de dades i l'automatització de tasques, dificultats que podrien resoldre's amb l'aplicació dels Data Detector i programes LBE.
La implementació dels Data Detector al web (AutoLink i Smart Tags) ha suposat un repte en la detecció de noves tipologies de dades. L'anàlisi duta a terme d'aquestes eines n'ha mostrat la poca precisió a l'hora de detectar conceptes —i fins i tot codis (ISBN)— derivada de l'ambigüitat del llenguatge. Per aquest motiu, les bases de dades semàntiques tenen un paper indiscutible per afavorir les noves necessitats de detecció dels usuaris, ampliar-les i adequar-les, però delimitar-les a camps concrets del saber.
El NextLib és un sistema d'aplicacions, constituït per la combinació de projectes i programes informàtics que, aïlladament, resolen petites dificultats i, combinadament, formen un sistema potencialment més interactiu, eficient i orientat a l'usuari que els que hi havia fins ara.
Com a treball futur d'investigació, caldria un estudi directe del Data Detector Miro i de l'LBE Creo (i/o d'aplicacions similars) per poder contrastar el nostre plantejament, com també una anàlisi de la interacció entre el LibX i la resta de les aplicacions del sistema NextLib.
Així mateix, seria interessant disposar d'estudis sobre la dificultat que els usuaris utilitzin un sistema d'aquestes característiques, els quals prenguin com a base el treball de Faaborg i Lieberman amb Creo i Miro.
Els resultats exposats al llarg del treball evidencien les possibilitats que la recerca en aquesta línia ofereix tant a les biblioteques com als desenvolupadors de llocs web.
Bibliografia
Bailey, A.; Godmar, B. (2006). "LibX: a Firefox extension for enhanced library access". Library hi tech, vol. 24, no. 2, p. 290–304.
Cantera, J. M.; Hierro, J. J.; Romo, P. A. (2006). "Web semántica: tecnologías y arquitectura". Comunicaciones de telefónica I+D, n.º 39. <http://www.tid.es/documentos/revista_comunicaciones_i%2Bd/numero39.pdf >. [Consulta: 09/05/07].
Codina, L. (2003). "Internet invisible y web semántica: ¿el futuro de los sistemas de información en línea?". Tradumàtica,núm. 2. <http://www.fti.uab.es/tradumatica/revista/num2/articles/06/06central.htm>. [Consulta: 09/05/07].
Codina, L. (2007). "La web semántica y el vaporware del siglo xxi". Anuario thinkEPI 2008 [en prensa].
Dans, E. El blog de Enrique Dans. <http://www.enriquedans.com>. [Consulta: 09/05/07].
De Rosa, C. et al. (2005). "Perceptions of libraries and information resources: a report to the OCLC membership". Dublin (Ohio): OCLC. <http://www.oclc.org/reports/pdfs/Percept_all.pdf >. [Accessed: 09/05/07].
Dey, A.; Abowd, G.; Wood, A. (1998). "CyberDesk: a framework for providing self-integrating context-aware services". Proceedings of the International Conference on Intelligent User Interfaces (IUI 98). <ftp://ftp.cc.gatech.edu/pub/gvu/tr/1997/97-10.pdf>. [Accessed: 09/05/07].
Dix, A.; Beale, R.; Wood, A. (2000). "Architectures to make simple visualisations using simple systems". Proceedings of advanced visual interfaces (AVI 00).
Faaborg, A. (2005). "A goal-oriented user interface for personalized semantic search" [masters thesis]. Massachusetts Institute of Technology: Cambridge, USA. <http://agents.media.mit.edu/projects/semanticsearch>. [Accessed: 09/05/07].
Faaborg, A.; Lieberman, H. (2006). "A goal-oriented web browser". Proceedings of the SIGCHI conference on human factors in computing systems. Montréal, Québec, Canadá, p. 751–770. <http://alumni.media.mit.edu/~faaborg/files/thesis/draft/complete/CHI06_goalOrientedWebBrowser.pdf>. [Accessed: 09/05/07].
García Marco, F. J. (2007). "El nacimiento y el despegue de la investigación moderna sobre ontologías". Anuario thinkEPI 2008 [en prensa].
Hughes, G.; Carr, L. (2002). "Microsoft smart tags: support, ignore or condemn them?". Proceedings of the Thirteenth ACM Conference on Hypertext and Hypermedia. College Park: Maryland, USA. <http://eprints.ecs.soton.ac.uk/7351/01/gvh_smart_tags_ht02.pdf>. [Accessed: 09/05/07].
La flecha: tu diario de ciencia y tecnología. <http://www.laflecha.net>. [Consulta: 09/05/07].
LibX: a Firefox extension for libraries. <http://www.libx.org>. [Accessed: 09/05/07].
Liu, H.; Singh, P. (2004a). "ConceptNet: a practical commonsense reasoning tool-kit". BT technology journal, vol. 22, no 4. <http://web.media.mit.edu/~hugo/publications/papers/BTTJ-ConceptNet.pdf>. [Accessed: 09/05/07].
Liu, H.; Singh, P. (2004b). "Commonsense reasoning in and over natural language". Proceedings of the 8th International Conference on Knowledge-Based Intelligent Information & Engineering Systems (KES'2004). Wellington, New Zealand. September 22–24. Lecture notes in artificial intelligence, Springer. <http://web.media.mit.edu/~hugo/publications/papers/KES2004-csr-nl.pdf>. [Accessed: 09/05/07].
Madroño. <http://www.consorciomadrono.net>. [Consulta: 09/05/07].
Monistrol, M.; Codina, L. (2007). "Los navegadores de la web 2.0: Firefox, Opera y Explorer". El profesional de la información, vol. 16, n.º 3, p. 261–267.
Nardi, B., Miller, J.; Wright, D. (1998). "Collaborative, programmable intelligent agents". Communications of the ACM,vol. 41, no. 3. <http://portal.acm.org/citation.cfm?id=272331&coll=portal&dl=ACM>. [Accessed: 09/05/07].
Pitrat, J. (1998). "El nacimiento de la inteligencia artificial". Mundo científico, vol. 8, n.º 53, p. 1196–1209.
Pandit, M.; Kalbag, S. (1997). "The selection recognition agent: instant access to relevant information and operations". Proceedings of the International Conference on Intelligent User Interfaces (IUI 97). <http://portal.acm.org/citation.cfm?id=238285&coll=portal&dl=ACM>. [Accessed: 09/05/07].
Ros, M.; Marco, M. E. El documentalista Enredado. <http://www.documentalistaenredado.net>. [Consulta: 09/05/07].
The Concept Net Project [V.2.1]: a very-large semantic network of common sense knowledge. <http://web.media.mit.edu/~hugo/conceptnet>. [Consulta: 09/05/07].
Data de recepció: 05/09/2007. Data d'acceptació: 10/12/2007.
Notes
1 En l'URL següent es pot consultar la llista de complementsdisponibles actualment per al Firefox: <https://addons.mozilla.org/es-ES/firefox>. [Consulta: 12/10/07].
2 En data 07/08/07.