Resum [Resumen] [Abstract]
Un dels reptes que es plantegen els dipòsits institucionals és demostrar i quantificar amb dades objectives que els treballs disponibles en obert se citen i s'utilitzen més que la resta. Alguns dipòsits ja inclouen anàlisis d'ús dels seus documents. També existeixen projectes en l'àmbit internacional dedicats a l'elaboració d'índexs de citacions. De moment, aquestes iniciatives són aïllades. Per obtenir una avaluació precisa cal integrar els resultats de diferents institucions i disciplines tendents a obtenir indicadors globals que permetin la comparació entre autors, institucions, etc. En aquest treball es presenta una proposta d'arquitectura destinada a permetre la recopilació, la distribució i l'agregació de les dades necessàries per mesurar l'ús i l'impacte dels treballs emmagatzemats en dipòsits institucionals.
1 Introducció
La iniciativa d'accés obert (OAI) promou l'accés lliure a la literatura científica, sense cap tipus de restricció financera o tècnica, a través de la creació de revistes en accés obert i l'arxivament dels treballs publicats en dipòsits institucionals o temàtics (BOAI, 2001). Pressuposa que el fet d'eliminar les barreres financeres que limiten l'accés als documents científics permetria que aquests estiguessin a disposició d'un nombre més elevat de lectors potencials i, per tant, seria també més gran l'impacte que causarien en la comunitat científica. L'objectiu de l'accés obert, doncs, pot resumir-se d'aquesta manera: augmentar l'accés i, així, augmentar l'impacte dels treballs.
Per impacte, i en sentit ampli, es pot entendre qualsevol canvi, intencionat o no, de caràcter positiu o negatiu, que un treball causa en la comunitat científica a la qual pertany i que es materialitza en comentaris de la resta de col·legues, en noves publicacions que analitzen o es basen en la primera, etc. Com que les publicacions són l'objecte tangible utilitzat per quantificar l'impacte, l'obtenció d'indicadors fiables per mesurar-lo s'ha basat en el recompte de citacions, assumint que un treball serà millor com més citacions rebi.
La idea, inferida de l'objectiu de l'accés obert, que els documents en obert se citen més que els que no ho estan, s'ha convertit en un eslògan per motivar els autors a arxivar els seus treballs en dipòsits institucionals. Tanmateix, si bé s'han publicat nombrosos estudis que així ho proven (entre d'altres, Eysenbach, 2006; Lawrence, 2001; Lin, 2007), els autors fan poques contribucions als dipòsits. Aquests majoritàriament són buits de continguts científics actuals (Swan, 2008) i creixen gràcies a les aportacions fetes des de les biblioteques a base de tesis doctorals, materials històrics digitalitzats, recursos didàctics, etc. Per tant, per atreure els investigadors cap als dipòsits institucionals no n'hi ha prou a afirmar la importància de l'accés obert, ni a demostrar que els documents oberts se citen més que la resta. Cal fer entendre la utilitat, com a investigador individual, d'oferir els treballs en obert, que es concreta en la quantificació de l'augment de l'impacte. És necessari proporcionar serveis de valor afegit que demostrin quant, quan i com es baixen i se citen els documents. Per fer-ho, cal mesurar sistemàticament el trànsit de documents en els dipòsits. Ara bé, no es pot plantejar un mesurament efectiu de manera aïllada per a cada dipòsit institucional o temàtic, sinó que cal fer-ho des d'un àmbit superior d'agregació de dades, bé sigui per disciplines o per àrees geogràfiques, que permetin de contextualitzar i comparar resultats d'investigadors entre institucions. Això implica el desenvolupament d'una estructura que estigui per damunt del dipòsit i que integri, analitzi i extregui indicadors a partir de les dades que s'obtinguin de dipòsits institucionals diversos.
En aquest treball es presenta una proposta d'arquitectura destinada a permetre la recopilació, la distribució i l'agregació de les dades necessàries per mesurar l'ús i l'impacte dels treballs emmagatzemats en dipòsits institucionals. En l'apartat següent s'analitzen els diversos àmbits de mesurament. A continuació, els apartats 3 i 4 analitzen, respectivament, la problemàtica de la utilització de registres (logs) per tenir constància de l'ús i l'extracció de referències per mesurar l'impacte. L'apartat 5 proposa una arquitectura per integrar dades d'ús i de citacions.
2 Ús i impacte de documents en obert
Tenint en compte l'objectiu de l'accés obert d'augmentar l'accessibilitat (per augmentar l'impacte) podríem establir almenys dos àmbits de mesurament destinats a avaluar la utilitat d'arxivar els documents en obert:
- Ús: relacionat amb l'accessibilitat i destinat a quantificar la utilització dels documents. Per ús entenem el trànsit de documents des dels dipòsits fins als lectors. Al seu torn, podem mesurar l'ús tenint en compte els aspectes següents: a) el nombre de vegades que s'ha accedit a la descripció bibliogràfica del document al servidor web del dipòsit, i b) el nombre d'individus que han decidit de baixar-se el text complet del document, presumiblement perquè l'han considerat interessant. Per quantificar l'ús es poden utilitzar les dades recollides en el registre d'accés del servidor web del dipòsit.
- Impacte: per impacte entenem les referències que s'han establert a posteriori entre documents a través de les citacions. Aquí quantificarem els lectors que, després d'analitzar el treball, l'han considerat prou important per citar-lo en les seves publicacions posteriors. L'impacte es quantifica a través d'una anàlisi de citacions.
Cada vegada hi ha més dipòsits que inclouen un servei d'anàlisi d'ús dels seus documents. Tant l'EPrints com el DSpace ofereixen mòduls per a l'anàlisi local de registres. Diversos exemples concrets d'anàlisi amb indicadors del nombre de baixades i visites de la informació bibliogràfica de l'EPrints i del DSpace es poden veure en l'E-LIS <http://eprints.rclis.org/es/index.php?action=show_detail_eprint&id=7136> o al dipòsit de la University of Toronto <https://tspace.library.utoronto.ca/statistics>. Un pas més el constitueix el projecte Interoperable Repository Statistics (IRS) <http://irs.eprints.org>, finançat pel Joint Information Systems Committee (JISC), al Regne Unit, amb l'objectiu d'investigar la recollida i l'intercanvi de dades d'ús. S'ha materialitzat en el desenvolupament d'un paquet de programari, l'IRStats, que automatitza l'elaboració d'estadístiques en funció de múltiples indicadors. Tots aquests projectes es basen en dipòsits individuals i ens ofereixen una visió parcial de l'ús dels treballs, perquè només inclouen les vegades que algú hi ha accedit o que s'han baixat des del mateix dipòsit. Per aprofitar al màxim el potencial de les dades d'ús, cal que s'agrupin i s'explotin com a agregadors específics.
La quantificació de l'ús i l'impacte a través de dades procedents de diferents institucions planteja una sèrie de problemes. En primer lloc, cal determinar quin o quins són els objectes que s'han de quantificar i fer-ne una identificació. El directori OpenDOAR <http://www.opendoar.org> mostra que els dipòsits institucionals són plens de continguts que no són pròpiament documents d'investigació. La quantificació de l'ús d'aquests documents, encara que sigui interessant per als gestors del dipòsit, no presenta cap valor afegit des del punt de vista de l'accés obert. Per tant, l'objecte a analitzar haurien de ser exclusivament els eprints, que entenem com els documents d'investigació en la versió tant pre com post publicació, abans o després d'haver passat per un procés d'avaluació d'experts. Queden fora d'aquest àmbit els objectes populars però sense valor per a la recerca, com ara objectes d'aprenentatge, material audiovisual, fotografies, etc. Davant la bibliometria tradicional, que se centra en la revista com a objecte d'estudi, les dades recollides dels dipòsits ens permetran de descendir en la granularitat de l'objecte d'estudi i centrar-nos en treballs d'investigació pròpiament dits.
En segon lloc, cal tenir en compte que un mateix treball pot aparèixer en diverses versions i que una mateixa versió pot estar emmagatzemada en diversos dipòsits (si cada autor arxiva una còpia en la seva respectiva institució). A més, cada dipòsit pot tenir diverses representacions d'una versió en diferents formats: PDF, Word, etc. Per proporcionar resultats fiables sobre un treball, caldrà agregar les dades d'ús i de citacions de totes les versions, les localitzacions i els formats coneguts. Això implica la necessitat d'un sistema normalitzat de descripció i d'identificació dels treballs. Si bé es desenvolupen estàndards com ara l'OAI-ORE (OAI, 2007), que permetrà la integració d'objectes complexos, de moment la identificació correcta d'un treball requereix la utilització d'uns identificadors adequats i d'una descripció que utilitzi metadades completes. En els dipòsits s'utilitza una gamma heterogènia de sistemes d'identificació, entre els quals hi ha el Handle, el DOI, el PURL, etc.
3 Recopilació de dades d'ús a través de registres
Els usuaris interactuen amb el dipòsit institucional a través de la interfície web. Per tant, els registres d'accés als servidors web proporcionen una idea aproximada de l'activitat i la utilització dels diferents recursos que emmagatzemen.
Cada transacció que rep el servidor web queda reflectida en una o diverses entrades al fitxer de registre. Una consulta a una pàgina registrarà tantes entrades —o hits— com elements contingui aquesta pàgina. El W3C manté un format estàndard per a registres de servidors web (Hallam-Baker, 1996) que després ha estat ampliat i desenvolupat per diverses empreses. Una entrada de registre típica en un servidor web Apache seria la següent:
66.249.65.194 - - [18/Feb/2008:14:03:48 +0100] ''GET /s/2005/diwdiwvjh.html HTTP/1.1'' 304 - - ''Mozilla/5.0''
En què:
- 66.249.65.194. Adreça IP de la màquina que ha fet la petició. Des del punt de vista de la privacitat, és impossible fer una connexió web sense donar al servidor aquesta informació. No obstant això, és complicat associar una adreça IP amb una persona física concreta.
- - - Usuari i contrasenya. Únicament és rellevant quan s'accedeix a continguts tancats.
- 18/Feb/2008:14:03:48 +0100. Moment en què el servidor rep la connexió.
- ''GET /s/2005/diwdiwvjh.html HTTP/1.1''. Document o pàgina que s'ha sol·licitat.
- 304. Codi de resposta que ha tornat el servidor. En aquest cas es tracta d'un robot que ha fet una petició condicional, a la qual el servidor contesta que la pàgina no s'ha modificat. Habitualment el codi és 200 (s'ha servit la pàgina correctament) i va acompanyat del nombre de bytes transferits.
- ''Mozilla/5.0''. L'última part és l'agent d'usuari. Es refereix a qualsevol programa que el visitant ha usat per accedir a aquesta pàgina. Normalment és un navegador, però pot ser també un robot (com en aquest exemple), un client FTP, un verificador d'enllaços, etc.
La interpretació de dades extretes d'un registre com aquest s'hauria de fer amb precaució i tenint en compte una sèrie de limitacions:
- Les dades d'ús deduïdes a partir dels registres han de ser pràctiques, és a dir, han de servir al propòsit per al qual són generades: permetre'n l'agregació i així obtenir uns indicadors útils per als usuaris sobre la utilització dels treballs independentment del dipòsit en què estiguin emmagatzemats. A més, han de ser fiables, és a dir, el procés de recollida ha de ser al més consistent possible entre institucions. No existeix una normalització en l'àmbit internacional que garanteixi la fiabilitat de les dades. El projecte COUNTER ha desenvolupat un codi de bones pràctiques (COUNTER, 2005) per mesurar l'ús de bases de dades, de llibres, de revistes i d'obres de referència en format electrònic. S'hi especifiquen i s'hi defineixen els objectes que es mesuraran; el contingut i la forma dels informes per als usuaris; els requisits per processar les dades, etc. Seria recomanable que els dipòsits institucionals i proveïdors de serveis participessin en aquesta iniciativa amb vista a la creació d'un codi específic per cobrir totes les necessitats.
- Com que l'HTTP no és un protocol orientat a la sessió, cada entrada del registre és independent de les anteriors i posteriors, cosa que fa molt complicat que es puguin traçar totes les interaccions que ha fet un usuari amb el sistema durant una sessió de treball.
- És impossible associar una entrada del registre amb un individu concret. Sí que podem, però, arribar a deduir que alguna entitat, ja sigui una persona física o un agent de programari, ha fet una petició en un domini determinat. Aquesta entitat pot fer una altra petició més endavant amb una adreça IP diferent, i viceversa; dues entitats diferents poden fer peticions en dos moments diferents utilitzant la mateixa adreça IP.
- Per identificar els documents als quals s'accedeix, és imprescindible que el nostre servidor web deixi reflectit en el registre l'identificador, o bé directament o bé de manera que pugui ser deduït a posteriori. En aquest sentit, l'EPrints i el DSpace, els dos programes més populars per a la creació de dipòsits, utilitzen pàgines estàtiques l'adreça URL de les quals, tant per a la descripció bibliogràfica com per al text complet, conté l'identificador del document. Per exemple, la petició següent:
<http://cadmus.iue.it/dspace/bitstream/1814/8086/1/ECO-2008-15.pdf>
generarà una entrada en el registre del tipus
''GET /dspace/bitstream/1814/8086/1/ECO-2008-15.pdf''.
Com que el DSpace utilitza el sistema Handle per identificar els documents, es pot deduir que es demana el document amb identificador <http://hdl.handle.net/1814/8086/>.- L'activitat del servidor esdevé distorsionada per l'acció d'agents de programari que, sistemàticament, visiten el dipòsit i n'indexen les pàgines. En el registre apareixeran barrejades les peticions d'individus reals amb les de robots. El soroll produït per aquestes últimes pot alterar considerablement els resultats de l'anàlisi d'ús. És possible aplicar una sèrie de tècniques per intentar que el registre estigui com més net millor d'aquestes connexions, i així aproximar-nos a la utilització real. La neteja hauria d'assegurar almenys que s'esborressin les entrades procedents de les màquines següents:
- Les que hagin sol·licitat el fitxer "robots.txt", segons el protocol d'exclusió de robots.
- Les que hagin accedit a més del n % o la xarxa de les quals hagi accedit a més del y % del nostre lloc, on n i y són proporcionals al nombre de pàgines del dipòsit.
- Les procedents de dominis com ara <googlebot.com>, <inktomisearch.com>, etc., o que pertanyin a una llista coneguda de robots.
- Igualment s'haurien de descartar les connexions repetides per un mateix individu en un període de temps reduït, per exemple, quan davant una resposta lenta del servidor o algun problema a la xarxa local es clica diverses vegades seguides sobre el mateix enllaç. Ha de comptabilitzar-se un únic accés per cada adreça IP a un recurs determinat en un temps t. El COUNTER especifica que t = 10 segons, per a documents en HTML, i t = 30 segons, per a documents en PDF.
Amb l'aplicació d'aquestes regles s'arribaria a obtenir un registre prou fiable de la utilització del dipòsit. Per contra, es reduiria el volum d'accessos fins a un 75 %, cosa que han demostrat projectes com ara LogEc <http://logec.repec.org>.
4 Recollida de dades de citacions
El mesurament de l'impacte implica la creació d'un índex de citacions. Si bé les dades d'ús es generen automàticament al servidor, en el cas de les citacions és necessària una actuació expressa del gestor del dipòsit. És una operació costosa, ja que per obtenir uns graus acceptables de precisió cal dedicar-hi recursos humans i tècnics considerables. A causa precisament dels costos, seria recomanable dur a terme l'extracció de citacions en el proveïdor de serveis, i que un dipòsit d'àmbit nacional o disciplinari s'encarregués de recollir els documents i processar-los per a l'explotació i/o l'exposició pública. Per tant, tindríem un servei que, en termes del protocol OAI-PMH, actua indistintament de dipòsit i de proveïdor de dades.
Hi ha projectes consolidats en l'àmbit internacional dedicats a l'extracció i l'enllaç de referències de documents disponibles en dipòsits (Barrueco, 2002). Són el que Steven Lawrence va anomenar índexs de citacions autònoms, ja que en lloc de basar-se en el treball humà, l'encarregat de tot el procés d'elaboració de l'índex és un sistema informàtic. La importància de les citacions en l'àmbit científic també es manifesta en el fet que tant el Google Scholar com el seu competidor de Microsoft, el Live Search Academic, proporcionen una funcionalitat de visualització del nombre de vegades que s'han citat els documents que emmagatzemen.
Una anàlisi de citacions des de l'àmbit dels dipòsits serà útil en la mesura que es creïn nous serveis de valor afegit que millorin o diversifiquin els resultats de les iniciatives esmentades. Una opció de millora és integrar-hi altres dades disponibles als dipòsits; per exemple, dades d'ús amb identificació d'autors per crear serveis de personalització.
La descripció del procés de creació d'un índex de citacions autònom queda fora de l'abast d'aquest treball a causa dels diferents enfocaments des dels quals es pot abordar. Barrueco (2005) ja n'ha analitzat un. En general, aquest procés té tres etapes:
- Recollida. Cal definir l'entorn de dades sobre el qual es treballarà. No és possible fer un servei universal, sinó que s'ha de restringir el nombre de dipòsits que s'han d'analitzar, els tipus de documents que constituiran la base per a documents que citen i se citen, etc. En aquesta etapa, es monitora l'entorn de dades seleccionat per detectar canvis: documents nous, documents modificats, etc. L'entrada a l'índex la constitueixen les metadades recollides dels dipòsits. A partir d'aquestes, en un segon moment, es baixa el text complet i es converteix el format original en un format normalitzat que pugui ser analitzat. Per exemple, de PDF a ASCII o d'HTML a XML.
- Anàlisi. És el nucli del sistema. Es tracta de l'anàlisi del document per trobar la llista de referències. Una vegada delimitada la bibliografia, tracta d'identificar cada referència i els elements que la componen. Com un valor addicional es podria identificar el context de la citació, és a dir, aïllar la frase o les frases amb les quals l'autor s'ha referit a l'obra citada.
- Enllaç. A partir de cada referència tracta de comprovar si l'obra citada es troba disponible en format electrònic en l'entorn de dades definit. En cas afirmatiu, es fa un enllaç entre els identificadors del document que cita i el document que se cita.
5 Integració de dades de citacions i d'ús
En les dues seccions anteriors s'ha tractat la problemàtica i el procés de generació de dades d'ús i de citacions en els dipòsits institucionals. Per treure el màxim partit a aquestes dades, cal que s'integrin en agregadors de continguts que puguin dur a terme tècniques de mesurament, d'explotació i d'extracció d'indicadors.
Bollen i van de Sompel (2005) han proposat una arquitectura basada en el protocol OAI-PMH per intercanviar dades d'ús que es podria ampliar per incloure també dades de citacions. En aquesta arquitectura cal un format de metadades, que pugui ser expressat en XML, per representar tant les dades d'ús com de citacions. Una vegada que hi hagi aquesta representació en XML es podran recollir les dades a través del protocol OAI-PMH. Per a la representació de dades d'accés, proposen la utilització de ContextObject de la norma OpenURL (ANSI/NISO, 2004). En aquest cas, cada entrada del registre que hagi superat la fase de neteja, es convertirà en un registre ContextObject. Cal determinar almenys tres elements per a cadascuna d'aquestes entrades: qui ha fet la petició (adreça IP), quan i què ha sol·licitat. ContextObject és apropiat per representar aquesta informació, ja que cada registre ContextObject és una estructura de dades que conté, almenys, els elements següents:
- Identificador del registre ContextObject. Cal un codi que asseguri la identificació única del registre que s'està creant. El contingut no s'especifica en la norma OpenURL. Es pot utilitzar, per exemple, l'Universally Unique Identifier estandarditzat per la norma ISO/IEC 9834-8:2005 (ISO, 2005). L'UUID permet que sistemes descentralitzats generin identificadors únics sense necessitat de coordinar-ne els components.
- Referent. És un recurs referenciat a la xarxa i sobre el qual es crea el registre. En el nostre cas seria un identificador del document que s'ha sol·licitat o més. Un registre ha de contenir obligatòriament un element referent. La seva descripció es fa a través d'un identificador i a més, opcionalment, de metadades associades.
- Requester. És el recurs que sol·licita un servei que pertany al referent; per tant, el que fa la petició d'un document, identificat, en el nostre cas, per una adreça IP.
- ServiceType. És el tipus de servei que se sol·licita, és a dir, si ha estat el text complet del document, només el resum, etc. Encara que la norma especifica que un registre ContextObject pot tenir zero elements ServiceType o més, en el nostre cas seria obligatori especificar un sol servei. El tipus de dades no es descriu en la norma i exigeix un acord entre els participants quant als descriptors i el vocabulari emprat en cada element. En l'exemple s'inclou l'element full-text amb dos valors possibles: yes o no. A més, seria necessari incloure un referent o una identificació del recurs que genera el registre ContextObject per ajudar les parts a interpretar les dades.
Tenint en compte aquestes especificacions, una entrada en el registre del dipòsit E-LIS que sol·licités la pàgina
<http://eprints.rclis.org/archive/00012408/>
quedaria reflectida com a
158.42.184.226 - - [22/Feb/2008:11:19:47 +0100] ''GET /archive/00012408/ HTTP/1.0'' 200 3855 ''-'' ''Wget/1.10.2''
Seria convertida al registre ContextObject següent, i es recolliria utilitzant OAI-PMH:
<?xml version=''1.0'' encoding=''UTF-8''?>
<ctx:context-object
timestamp=''2008-02-22T11:19:47Z''
identifier=''urn:UUID:58f202ac-22cf-11d1-b12d-002035b29062''>
<ctx:referent>
<ctx:identifier>info:eprints.rclis.org:12408</ctx:identifier>
</ctx:referent>
<ctx:requester>
<ctx:identifier>urn:ip:158.42.184.226</ctx:identifier>
</ctx:requester>
<ctx:service-type>
<full-text>no</full-text>
</ctx:service-type>
</ctx:context-object>
</xml>En el cas de les referències i citacions, també cal un format de metadades que permeti de representar-les i que pugui ser expressat en XML per ser intercanviat via OAI-PMH. En aquesta representació hem de diferenciar entre referències, o cadenes de caràcters extretes de la bibliografia d'un treball, i que representen un altre document en què l'autor s'ha basat, i citacions, o relacions entre la referència i el document al qual representen. Assumint que considerem citacions exclusivament les relacions que s'estableixen entre dos objectes disponibles en el nostre entorn de dades, és a dir, entre dos objectes dels quals coneixem els identificadors en l'espai OAI, hi ha tres relacions que cal representar:
- "Cita", representada per una referència bibliogràfica o la seva descomposició en elements més l'identificador de l'objecte citat.
- "Referencia", representada per una referència bibliogràfica o la seva descomposició en elements. En aquest cas, l'objecte citat no es troba en el nostre espai, per la qual cosa no podem assignar-hi un identificador.
- "Citat per", representat per les metadades i/o l'identificador de l'objecte citant. Una obra és citada en una referència dins un document, per tant, en el cas ideal el sistema no solament hauria d'identificar el document citant sinó també la referència concreta.
Hi ha diversos formats de metadades que ens permeten de representar aquestes relacions. Per exemple, el Dublin Core ho fa recorrent, com en el cas anterior, a ContextObject (Apps, 2005). El problema d'aquesta opció és que exigeix un grau de granularitat en les dades que és difícil d'aconseguir mitjançant tècniques automàtiques d'extracció i enllaç. A més, exigeix que les referències i les citacions estiguin representades en el mateix registre Dublin Core que les metadades descriptives del document. Un altre format més flexible i que permet de separar la descripció del document de la representació de citacions i referències (Krichel, 2006) és l'Academic Metadata Format (AMF). S'hi s'utilitzen els elements següents:
- <references> per identificar la relació "cita". Consta de dos subelements <referencestring>, la referència bibliogràfica tal com ha estat extreta del text i un atribut ref, que conté l'identificador de l'objecte representat en la referència.
- <reference> per identificar la relació "referencia". Conté un element literal el contingut del qual és el text de la referència bibliogràfica.
- <isreferencedby> per representar la relació "citat per". Conté un element ref amb l'identificador del document que cita.
D'acord amb el que hem exposat, un exemple de registre de referències i citacions en AMF quedaria de la manera següent:
<amf xmlns=''http://amf.openlib.org''
xmlns:xsi=''http://www.w3.org/2001/XMLSchema-instance''
xsi:schemaLocation=''http://amf.openlib.org http://amf.openlib.org/2001/amf.xsd''
xmlns:acis=''http://acis.openlib.org/''>
<text ref=''RePEc:nbr:nberwo:9999''>
<references>
<acis:referencestring>Engen, Eric, William Gale, and John Karl
Scholz. 1996. The Illusory Effects of Saving Incentives on
Saving. Journal of Economic Perspectives 10 (4):113-138.
</acis:referencestring>
<text ref=''RePEc:aea:jecper:v:10:y:1996:i:4:p:113-38'' />
</references>
<reference>
<literal>Filer, Randall, and Marjorie Honig. 1998. A Model of
Endogenous Pensions in Retirement Behavior. Manuscript, Hunter College.</literal>
</reference>
<isreferencedby>
<text ref=''RePEc:dnb:wormem:752'' />
</isreferencedby>
<isreferencedby>
<text ref=''RePEc:fip:fedlwp:2003-038'' />
</isreferencedby>
<isreferencedby>
<text ref=''RePEc:dnb:mebser:2003-18'' />
</isreferencedby>
</text>
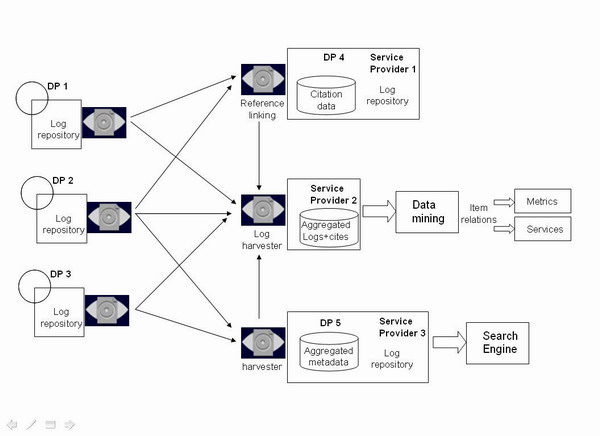
</amf>Una vegada que tenim tant les dades d'ús com de citacions representades mitjançant metadades en llenguatge XML, podrien ser recollides usant el protocol OAI-PMH per agregadors de continguts específics en una arquitectura similar a la que mostra la figura 1. En aquesta arquitectura tenim els elements següents:
Figura 1. Arquitectura per a la distribució de dades
- Tres proveïdors de dades (DP1, DP2 i DP3) que proporcionen metadades (Dublin Core) de documents i d'accessos a aquests documents (ContextObject) a través d'un dipòsit de registres nou.
- El paper del proveïdor de serveis s'ha diversificat i ara actua també com a proveïdor de dades addicionals. Dues entitats actuen com a PD i també com a PS. El proveïdor de serveis número 3 seria el proveïdor tradicional que recull metadades Dublin Core d'un dipòsit o de diversos per implementar un servei de cerca. Ara bé, al seu torn, genera dades d'ús dels documents recollits, per la qual cosa s'ha convertit en un dipòsit de registres (DP5).
- El proveïdor de serveis número 1 recull metadades Dublin Core per dur a terme una anàlisi de referències. Es converteix així en dipòsit (DP4) sobre informació de referències i citacions. Si, al seu torn, implementa un servei sobre aquestes, podria crear també un dipòsit de registres.
- El proveïdor de serveis número 2 és el més complet, ja que recull metadades Dublin Core de tots els dipòsits de documents. D'aquests, recull ContextObject que contingui dades d'ús. Dels DP4 i DP5 recull igualment dades d'ús mitjançant ContextObject. I, finalment, del DP4 recull informació de citacions mitjançant AMF. Amb tot això pot crear, a través de tècniques de mineria de dades, serveis nous, com ara rànquings d'autors per obres més citades o baixades, de documents més populars, etc., o indicadors nous de qualitat, d'utilització, etc., dels materials.
6 Bibliografia
ANSI/NISO (2004). ANSI/NISO z39.88-2004: The openurl framework for context-sensitive services. <http://www.niso.org/standards/standard_detail.cfm?std_id=783>. [Consulta: 23/02/2008].
Apps, A. (2005). Guidelines for encoding bibliographic citation information in Dublin Core metadata. <http://dublincore.org/documents/dc-citation-guidelines>. [Consulta: 23/02/2008].
Barrueco, J. M. (2002). "Reference linking: un nuevo concepto para facilitar el acceso a la literatura científica". El profesional de la información, vol. 11, nº. 4, p. 278–282.
Barrueco, J. M. (2005). "Building an autonomous citation index for grey literature". TGJ, an international journal on grey literature, vol. 1, no. 2, p. 91–97.
BOAI (2001). Budapest open access initiative. <http://www.soros.org/openaccess>. [Consulta: 23/02/2008].
Bollen, J.; Sompel, H. van de (2005). "A framework for assessing the impact of units of scholarly communication based on OAI-PMH harvesting of usage information". CERN workshop on innovations in scholarly communication (OAI4), Geneva (Switzerland). <http://eprints.rclis.org/archive/00006076/02/bollen.pdf>. [Consulta: 23/02/2008].
COUNTER (2005). Counter code of practice for journals and databases. <http://www.projectcounter.org/code_practice.html>. [Consulta: 26/02/2008].
Eysenbach, G. (2006). "Citation advantage of open access articles". PLoS biology, vol. 4, no. 5, p. 692–698.
Hallam-Baker, P. M.; Behlendorf, B. (1996). Extended log file format. <http://www.w3.org/TR/WD-logfile.html>. [Consulta: 23/02/2008].
ISO (2005). ISO/IEC 9834-8:2005 procedures for the operation of OSI registration authorities: generation and registration of universally unique identifiers (UUIDs) and their use as ASN.1 object identifier components. <http://www.itu.int/ITU-T/studygroups/com17/oid.html>. [Consulta: 23/02/2008].
Krichel, T. (2006). Syntax and vocabulary of the academic metadata format. <http://amf.openlib.org/doc/nagano.html>. [Consulta: 20/02/2008].
Lawrence, S. (2001). "Free online availability substantially increases a paper's impact". Nature, vol. 411, no. 6837, p. 521.
Lin, S. K. (2007). "Non-open access and its adverse impact on molecules". Molecules, no. 12, p. 1436–1437.
OAI (2007). Open archives initiative: object reuse and exchange. <http://www.openarchives.org/ore>. [Consulta: 23/02/2008].
Swan, A.; Carr, L. (2008). "Institutions, their repositories and the web". Serials review, vol. 34, no. 1. <http://eprints.ecs.soton.ac.uk/14965>. [Consulta: 26/02/2008].
Data de recepció: 15/02/2008. Data d'acceptació: 04/03/2008.