Resumen [Resum] [Abstract]
Entre los retos que tienen planteados los repositorios institucionales está el demostrar y cuantificar con datos objetivos que los trabajos disponibles en abierto se citan y se utilizan más que el resto. Algunos repositorios están incluyendo análisis del uso de sus documentos. También existen proyectos a nivel internacional dedicados a la elaboración de índices de citas. De momento estas iniciativas son aisladas. Para obtener una evaluación precisa será necesario integrar los resultados procedentes de distintas instituciones y disciplinas tendentes a obtener indicadores globales que permitan la comparación entre autores, instituciones, etc. En este trabajo se presenta una propuesta de arquitectura destinada a permitir la recopilación, distribución y agregación de los datos necesarios para llevar a cabo una medición del uso e impacto de los trabajos almacenados en repositorios institucionales.
1 Introducción
La Iniciativa de Archivos Abiertos (OAI) promueve el libre acceso a la literatura científica, sin ningún tipo de restricciones financieras o técnicas, a través de la creación de revistas en acceso abierto y el archivo de los trabajos publicados en repositorios institucionales o temáticos (BOAI, 2001). Presupone que eliminar las barreras financieras que limitan el acceso a los documentos científicos permitiría que estos estuvieran a disposición de un número mayor de lectores potenciales y por lo tanto sería también mayor el impacto que causarían en la comunidad científica. De esta forma el objetivo del acceso abierto puede resumirse en: aumentar el acceso para así aumentar el impacto de los trabajos.
Por impacto y en sentido amplio se puede entender cualquier cambio, intencionado o no, de carácter positivo o negativo, que un trabajo causa en la comunidad científica a la que pertenece y que se materializa en comentarios del resto de colegas, nuevas publicaciones que analizan o se basan en la primera, etc. Dado que las publicaciones son el objeto tangible utilizado para cuantificar el impacto, la obtención de indicadores fiables para su medición se ha basado en el recuento de citas entre las mismas, asumiendo que un trabajo será mejor cuantas más citas reciba.
La idea, inferida del objetivo del acceso abierto, de que los documentos en abierto se citan más que los que no lo están, se ha convertido en un eslogan para motivar a los autores a archivar sus trabajos en repositorios institucionales. Si bien se han publicado numerosos estudios que así lo prueban (entre otros, Eysenbach, 2006; Lawrence, 2001; Lin 2007), los repositorios tienen una baja tasa de contribución por parte de los autores. En su mayor parte están vacíos de contenidos científicos actuales (Swan, 2008) y crecen gracias a las aportaciones hechas desde las bibliotecas a base de tesis doctorales, materiales históricos digitalizados, didácticos, etc. Por lo tanto, para atraer a los investigadores hacia los repositorios institucionales no es suficiente con afirmar la importancia del acceso abierto, ni siquiera demostrar a nivel de disciplina que los documentos abiertos se citan más que el resto. Es necesario demostrar al nivel de investigador individual la utilidad de poner los trabajos en abierto, concretada en la cuantificación del aumento del impacto de los mismos. Es necesario proporcionar servicios de valor añadido que demuestren cuánto, cuándo y cómo se descargan y se citan los documentos. Para ello es necesario llevar a cabo una medición sistemática del tráfico de documentos en los repositorios. Ahora bien, una medición efectiva no puede plantearse de forma aislada para cada repositorio institucional o temático sino que será necesario plantearla desde un nivel superior de agregación de datos, bien sea por disciplinas o por áreas geográficas, que permitan contextualizar y comparar resultados de investigadores entre instituciones. Esto implica el desarrollo de una estructura a nivel superior al repositorio que integre, analice y extraiga indicadores a partir de los datos obtenidos de distintos repositorios institucionales.
En este trabajo se presenta una propuesta de arquitectura destinada a permitir la recopilación, distribución y agregación de los datos necesarios para llevar a cabo una medición del uso e impacto de los trabajos almacenados en repositorios institucionales. En la siguiente sección se analizan los diferentes niveles de medición. A continuación, las secciones tres y cuatro analizan, respectivamente, la problemática de la utilización de logs para la medición del uso y la extracción de referencias para la medición del impacto. La sección cinco propone una arquitectura para la integración de datos de uso y citas.
2 Uso e impacto de documentos en abierto
Teniendo en cuenta el objetivo del acceso abierto de aumentar la accesibilidad (para así aumentar el impacto) podríamos establecer al menos dos niveles de medición destinados a evaluar la utilidad de archivar los documentos en abierto:
- Uso: relacionado con la accesibilidad y destinado a cuantificar la utilización de los documentos. Por uso entendemos el tráfico de documentos desde los repositorios hasta los lectores. A su vez, el uso podemos medirlo a dos niveles: el número de veces que se ha accedido a la descripción bibliográfica del documento en el servidor web del repositorio; y el número de individuos que han decidido descargar el texto completo del documento, presumiblemente porque lo han considerado interesante. Para cuantificar el uso se pueden utilizar los datos recogidos en el registro de acceso o log del servidor web del repositorio.
- Impacto: por impacto entendemos las referencias que se han establecido a posteriori entre documentos a través de las citas. En este nivel cuantificaremos aquellos lectores que, tras analizar el trabajo, lo han considerado lo suficientemente importante como para citarlo en sus publicaciones posteriores. El impacto se cuantificará a través de un análisis de citas.
Cada vez son más los repositorios que están incluyendo un servicio de análisis de uso de sus documentos. Tanto E-Prints como DSpace ofrecen módulos para el análisis local de logs. Ejemplos concretos de análisis con indicadores del número de descargas y visitas a la información bibliográfica en E-Prints y DSpace se pueden ver en E-LIS <http://eprints.rclis.org/es/index.php?action=show_detail_eprint&id=7136> o en el repositorio de la University of Toronto <https://tspace.library.utoronto.ca/statistics>. Un paso más lo constituye el proyecto IRS (Interoperable Repository Statistics) <http://irs.eprints.org> financiado por Joint Information Systems Committee (JISC) en el Reino Unido con el objetivo de investigar la recolección e intercambio de datos de uso y que se ha materializado en el desarrollo de un paquete software IRStats que automatiza la elaboración de estadísticas en función de múltiples indicadores. Todos estos proyectos se basan en repositorios individuales y nos dan una visión parcial de uso de los trabajos al incluir solamente las veces que se han accedido o descargado desde el propio repositorio. Para aprovechar al máximo el potencial de los datos de uso es necesario su agrupación y explotación a nivel de agregadores específicos.
La cuantificación de uso e impacto a través de datos procedentes de distintas instituciones plantea una serie de problemas. En primer lugar habrá que determinar cuál o cuáles son los objetos sobre los que llevarla a cabo, así como la identificación de los mismos. El directorio OpenDOAR <http://www.opendoar.org> muestra que los repositorios institucionales están repletos de contenidos que no son propiamente documentos de investigación. La cuantificación de su uso, aunque interesante para los gestores del repositorio, no presenta ningún valor añadido desde el punto de vista del acceso abierto. Por lo tanto, el objeto a analizar deberían ser exclusivamente los eprints, entendiendo por tales, los documentos de investigación en su versión tanto de pre- como de post- publicación, antes o después de haber pasado por un proceso de peer review. Quedan fuera de este ámbito objetos populares pero sin valor para la investigación como objetos de aprendizaje, material audiovisual, fotografías, etc. Frente a la bibliometría tradicional que se centra en la revista como objeto de estudio, los datos recolectados de los repositorios nos permitirán descender en la granularidad de nuestro objeto de estudio y centrarnos en trabajos de investigación propiamente dichos.
En segundo lugar, habrá que tener en cuenta además que un mismo trabajo puede aparecer en varias versiones y una misma versión podrá estar almacenada en varios repositorios (si cada autor archiva una copia en su respetiva institución). Además, cada depósito podrá tener varias representaciones de una versión en diferentes formatos: PDF, Word, etc. Para proporcionar resultados fiables sobre un trabajo será necesario agregar los datos de uso y citas de todas las versiones, localizaciones y formatos conocidos del mismo. Ello implica la necesidad de un sistema normalizado de descripción e identificación de los trabajos. Si bien se están desarrollando estándares como OAI-ORE (OAI, 2007) que permitirá la integración de objetos complejos, por el momento la correcta identificación de un trabajo pasa por la utilización de unos identificadores adecuados y una descripción utilizando metadatos completos. En los repositorios se utiliza una gama heterogénea de sistemas de identificación, entre ellos, handles, DOI, PURL, etc.
3 Recopilación de datos de uso a través de logs
Los usuarios interactúan con el repositorio institucional a través de su interfaz web. Por lo tanto los registros de acceso a los servidores web nos dan una idea aproximada de la actividad y utilización de los distintos recursos que almacenan.
Cada transacción que recibe el servidor web queda reflejada en una o varias entradas en el fichero de registro o log. Una consulta a una página registrará tantas entradas o hits como elementos contenga dicha página. El W3C mantiene un formato estándar para registros de servidores web (Hallan-Baker, 1996) que luego ha sido ampliado y desarrollado por distintas empresas. Una entrada de registro típica en un servidor web Apache sería:
66.249.65.194 - - [18/Feb/2008:14:03:48 +0100] ''GET /s/2005/diwdiwvjh.html HTTP/1.1'' 304 - - ''Mozilla/5.0''
Donde:
- 66.249.65.194. Número IP de la máquina que ha realizado la petición. Desde el punto de vista de la privacidad, es imposible realizar una conexión web sin dar al servidor esta información. No obstante asociar una dirección IP con una persona física concreta es complicado.
- - - Usuario y password. Únicamente relevante cuando se accede a contenidos cerrados.
- 18/Feb/2008:14:03:48 +0100. Momento en que el servidor recibe la conexión.
- ''GET /s/2005/diwdiwvjh.html HTTP/1.1''. Documento o página que se ha solicitado.
- 304 Código de respuesta devuelto por el servidor. En este caso se trata de un robot que ha realizado una petición condicional a la cual el servidor contesta que la página no se ha modificado. Habitualmente el código será 200 (se ha servido la página correctamente) e irá acompañado del número de bytes transferidos.
- ''Mozilla/5.0''. La última parte es el agente de usuario. Se refiere a cualquier software que el visitante ha usado para acceder a esta página. Normalmente será un navegador pero puede ser también un robot (como en este ejemplo) un cliente FTP, un verificador de enlaces, etc.
La interpretación de datos extraídos de un registro como éste debería hacerse con precaución y teniendo en cuenta una serie de limitaciones:
- Los datos de uso deducidos a partir de los registros log deben ser prácticos, es decir, deben servir al propósito para el que son generados: permitir su agregación y así obtener unos indicadores útiles para los usuarios sobre la utilización de sus trabajos independientemente del repositorio donde se encuentren almacenados. Además deben ser fiables, su proceso de recopilación debe ser lo más consistente posible entre instituciones. No existe una normalización a nivel internacional que garantice la fiabilidad de los datos. El proyecto COUNTER ha desarrollado un código de buenas prácticas (COUNTER, 2005) para la medición del uso de bases de datos, libros, revistas, y obras de referencia electrónicos. En ellos se especifican y definen los objetos que se van a medir, contenido y forma de los informes a los usuarios, requisitos para procesar los datos, etc. Sería recomendable que los repositorios institucionales y proveedores de servicios participaran en esta iniciativa de cara a la creación de un código específico para sus necesidades.
- Dado que HTTP no es un protocolo orientado a sesión cada entrada en el registro es independiente de las anteriores y posteriores haciendo muy complicado el trazar todas las interacciones que ha tenido un usuario con el sistema durante una sesión de trabajo.
- Es imposible asociar una entrada en el registro con un individuo concreto. Lo que podemos llegar es a deducir que alguna entidad, ya sea persona física o agente software, en un dominio determinado ha realizado una petición. Esa entidad puede realizar otra petición más adelante con una IP diferente y viceversa, dos entidades diferentes pueden hacer peticiones en dos momentos distintos utilizando la misma IP.
- Para identificar los documentos a los que se está accediendo es imprescindible que nuestro servidor web deje reflejado en el registro el identificador de los mismos, bien directamente o bien de forma que pueda ser deducido a posteriori. En este sentido, E-Prints y DSpace, los dos softwares más populares para la creación de repositorios, utilizan páginas estáticas cuya dirección URL, tanto para la descripción bibliográfica como para el texto completo, contiene el identificador del documento. Por ejemplo, la petición:
<http://cadmus.iue.it/dspace/bitstream/1814/8086/1/ECO-2008-15.pdf>
generará una entrada en el registro del tipo
''GET /dspace/bitstream/1814/8086/1/ECO-2008-15.pdf''.
Dado que DSpace utiliza el sistema handle para identificar los documentos, se puede deducir que se está pidiendo el documento con identificador <http://hdl.handle.net/1814/8086/>.- La actividad del servidor se ve distorsionada por la acción de agentes software que sistemáticamente visitan el repositorio indizando sus páginas. En el registro aparecerán mezcladas las peticiones de individuos reales con aquellas de robots. El ruido producido por estas últimas puede alterar considerablemente los resultados del análisis de uso. Es posible aplicar una serie de técnicas para intentar que el registro esté lo más limpio posible de estas conexiones y así aproximarnos a la utilización real del mismo. La limpieza debería asegurar al menos el borrado de las entradas procedentes de máquinas:
- Que hayan solicitado el fichero /robots.txt, según el protocolo de exclusión de robots.
- Que hayan accedido a más del n% o cuya red haya accedido a más del y% de nuestro sitio. Siendo n e y proporcionales al número de páginas del repositorio.
- Procedentes de dominios como googlebot.com, inktomisearch.com, etc. o que pertenezcan a una lista conocida de robots.
- Igualmente deberían descartarse aquellas conexiones repetidas por un mismo individuo en un periodo de tiempo reducido, por ejemplo, cuando ante una respuesta lenta del servidor o algún problema en la red local clique varias veces seguidas sobre el mismo enlace. Habrá de contabilizarse un único acceso por cada dirección IP a un recurso determinado en un tiempo t. COUNTER especifica t=10 segundos para documentos en html y t=30 segundos para documentos en PDF.
Con la aplicación de estas reglas se llegaría a obtener un registro bastante fiable de la utilización de nuestro repositorio. Por contra se reduciría el volumen de accesos hasta en un 75 % como han demostrado proyectos como LogEc <http://logec.repec.org>.
4 Recopilación de datos de citas
La medición del impacto supone la creación de un índice de citas. Mientras los datos de uso se generan automáticamente en el servidor, en el caso de las citas es necesario una actuación expresa por parte del gestor del repositorio. Es una operación costosa puesto que para obtener unos niveles aceptables de precisión será necesario dedicar considerables recursos humanos y técnicos. Debido precisamente a los costes sería recomendable realizar la extracción de citas a nivel de proveedor de servicios, siendo un recolector a nivel nacional o disciplinar quien se encargara de la recolección de los documentos y su procesamiento para su explotación propia y/o su puesta en el dominio público. Por lo tanto tendríamos un servicio que, en términos del protocolo OAI-PMH, actúa indistintamente de recolector y de proveedor de datos.
Existen proyectos consolidados a nivel internacional dedicados a la extracción y enlace de referencias de documentos disponibles en repositorios (Barrueco, 2002). Es lo que Steven Lawrence denominó "índices de citas autónomos", puesto que en lugar de basarse en el trabajo humano, es un sistema informático el encargado de todo el proceso de elaboración del índice. La importancia de las citas en el ámbito científico también se manifiesta en el hecho de que tanto Google Scholar como su competidor de Microsoft, Live Search Academic, proporcionan una funcionalidad de visualización del número de veces que han sido citados los documentos que almacenan.
Llevar a cabo un análisis de citas desde el ámbito de los repositorios será útil en la medida que se creen nuevos servicios de valor añadido que mejoren o diversifiquen los resultados de las iniciativas mencionadas. Una opción de mejora viene dada por la integración con otros datos disponibles en los repositorios, por ejemplo, datos de uso con identificación de autores para crear servicios de personalización.
La descripción del proceso de creación de un índice de citas autónomo queda fuera del alcance de este trabajo debido a los diferentes enfoques desde los que se puede abordar. En Barrueco (2005) ya se ha analizado uno de ellos. En general dicho proceso tiene tres etapas:
- Recolección. Es necesario definir el entorno de datos sobre el que se va a trabajar. No es posible hacer un servicio universal sino que habrá que restringir el número de repositorios a analizar, tipos de documentos que constituirán la base para documentos citantes y citados, etc. La etapa de recolección es la encargada de monitorizar el entorno de datos seleccionado para detectar cambios: nuevos documentos, documentos modificados, etc. La entrada en el índice la constituyen los metadatos recolectados de los repositorios. A partir de ellos, en un segundo momento, se procederá a la descarga del texto completo y a la conversión del formato original a un formato normalizado que pueda ser analizado. Por ejemplo de PDF a ASCII o de HTML a XML.
- Análisis. Es el núcleo del sistema. Se trata del análisis del documento para encontrar la lista de referencias. Una vez acotada la bibliografía tratará de identificar cada referencia y los elementos que la componen. Como un valor adicional se podría identificar el contexto de la cita, es decir, aislar la frase o frases con las cuales el autor se ha referido a la obra citada en cuestión.
- Enlace. Por cada una de las referencias tratará de comprobar si la obra citada se encuentra disponible en formato electrónico dentro del entorno de datos definido. En caso afirmativo se realizará un enlace entre los identificadores del documento citante y del documento citado.
5 Integración de datos de citas y uso
En las dos secciones anteriores se ha tratado la problemática y el proceso de la generación de datos de uso y citas en los repositorios institucionales. Para conseguir el máximo partido a estos datos será necesario su integración en agregadores de contenidos que puedan llevar a cabo técnicas de medición, explotación y extracción de indicadores.
Bollen y van de Sompel (Bollen, 2005) han propuesto una arquitectura basada en el protocolo OAI-PMH para intercambiar datos de uso que podría ser ampliada para incluir también datos sobre citas. En esta arquitectura es necesario un formato de metadatos, que pueda ser expresado en XML, para representar tanto los datos de uso como de citas. Una vez que exista tal representación en XML será posible recolectar los datos a través del protocolo OAI-PMH. Para la representación de datos de acceso proponen la utilización de ContextObject de la norma OpenURL (ANSI/NISO, 2004). En este caso, cada una de las entradas log que hayan superado la fase de limpieza, se convertirá en un registro ContextObject. Es necesario determinar al menos tres elementos por cada una de esas entradas: quién ha realizado la petición (número IP), cuándo y qué ha solicitado. ContexObject es apropiado para representar esta información ya que cada registro ContexObject es una estructura de datos que contiene, al menos, los siguientes elementos:
- Identificador del registro ContextObject. Se trata de algún código que asegure la identificación única del registro que se está creando. Su contenido no está especificado en la norma OpenURL. Se puede utilizar por ejemplo el Universally Unique Identifier estadarizado por la norma ISO/IEC 9834-8: 2005 (ISO, 2005). UUID permite a sistemas descentralizados generar identificadores únicos sin necesidad de una coordinación entre sus componentes.
- Referent: un recurso que es referenciado en la red y sobre el cual se crea el registro. En nuestro caso sería uno o más identificadores del documento que se ha solicitado. Un registro debe contener obligatoriamente un elemento Referent. Su descripción se realiza a través de un identificador y además, opcionalmente, de metadatos asociados.
- Requester: El recurso que solicita un servicio que pertenece al Referent, por lo tanto, el que realiza la petición de un documento, identificado, en nuestro caso, por un número IP.
- ServiceType: Tipo de servicio que se solicita, es decir, si ha sido el texto completo del documento, solamente el abstract, etc. Aunque la norma especifica que un registro ContextObject puede tener cero o más elementos ServiceType, en nuestro caso sería obligatorio especificar un sólo servicio. El tipo de datos no está descrito en la norma y exige un acuerdo entre los participantes en cuanto a los descriptores y vocabulario empleado en cada elemento. En el ejemplo se incluye el elemento full-text con dos valores posibles: yes o no. Además sería necesario incluir un Referent o identificación del recurso que genera el registro ContextObject para ayudar a las partes a interpretar los datos.
Teniendo en cuenta estas especificaciones una entrada en el registro log del repositorio E-LIS que solicitara la página:
<http://eprints.rclis.org/archive/00012408/>
Quedaría reflejada como:
158.42.184.226 - - [22/Feb/2008:11:19:47 +0100] ''GET /archive/00012408/ HTTP/1.0'' 200 3855 ''-'' ''Wget/1.10.2''
Y sería convertida al siguiente registro ContextObject, para ser recolectada utilizando OAI-PMH:
<?xml version=''1.0'' encoding=''UTF-8''?>
<ctx:context-object
timestamp=''2008-02-22T11:19:47Z''
identifier=''urn:UUID:58f202ac-22cf-11d1-b12d-002035b29062''>
<ctx:referent>
<ctx:identifier>info:eprints.rclis.org:12408</ctx:identifier>
</ctx:referent>
<ctx:requester>
<ctx:identifier>urn:ip:158.42.184.226</ctx:identifier>
</ctx:requester>
<ctx:service-type>
<full-text>no</full-text>
</ctx:service-type>
</ctx:context-object>
</xml>En el caso de las referencias y citas también es necesario un formato de metadatos que permita representarlas y que pueda ser expresado en XML con objeto de ser intercambiado vía OAI-PMH. En esta representación debemos diferenciar entre referencias, o cadenas de caracteres extraídas de la sección de bibliografía de un trabajo y que representan otro documento en el que el autor se ha basado; y cita, o relación entre la referencia y el documento al que representa. Asumiendo que consideramos cita exclusivamente aquellas relaciones que se establecen entre dos objetos disponibles dentro de nuestro entorno de datos, es decir, entre dos objetos de los cuales conocemos sus identificadores en el espacio OAI, habría tres relaciones a representar:
- Cita a, representada por una referencia bibliográfica o su descomposición en elementos más el identificador del objeto citado.
- Referencia a, representada por referencia bibliográfica o su descomposición en elementos. En este caso el objeto citado no se encuentra dentro de nuestro espacio por lo cual no podemos asignarle un identificador.
- Citado por, representado por los metadatos y/o identificador del objeto citante. Una obra es citada en una referencia dentro de un documento, por lo tanto, en el caso ideal el sistema debería no sólo identificar el documento citante sino también la referencia concreta.
Existen varios formatos de metadatos que nos permiten representar estas relaciones. Por ejemplo el Dublin Core lo hace recurriendo, como en el caso anterior, a ContextObjects (Apps, 2005). El problema de esta opción es que exige un nivel de granularidad en los datos que es difícil de conseguir mediante técnicas automáticas de extracción y enlace. Además exige que las referencias y citas estén representadas en el mismo registro Dublin Core que los metadatos descriptivos del documento. Otro formato más flexible y que permite separar la descripción del documento de la representación de citas y referencias es AMF (Academic Metadata Format) (Krichel, 2006). En él se utilizan los elementos:
- <references> para identificar la relación "Cita a". Consta de dos subelementos <referencestring>, referencia bibliográfica tal y como ha sido extraída del texto y un atributo ref que contendrá el identificador del objeto representado en la referencia.
- <reference> para identificar la relación "Referencia a". Contendrá un elemento literal cuyo contenido será el texto de la referencia bibliográfica.
- <isreferencedby> para representar la relación "Citado por". Contendrá un elemento ref con el identificador del documento citante.
Con ello un ejemplo de registro de referencias y citas en AMF quedaría como sigue:
<amf xmlns=''http://amf.openlib.org''
xmlns:xsi=''http://www.w3.org/2001/XMLSchema-instance''
xsi:schemaLocation=''http://amf.openlib.org http://amf.openlib.org/2001/amf.xsd''
xmlns:acis=''http://acis.openlib.org/''>
<text ref=''RePEc:nbr:nberwo:9999''>
<references>
<acis:referencestring>Engen, Eric, William Gale, and John Karl
Scholz. 1996. The Illusory Effects of Saving Incentives on
Saving. Journal of Economic Perspectives 10 (4):113-138.
</acis:referencestring>
<text ref=''RePEc:aea:jecper:v:10:y:1996:i:4:p:113-38'' />
</references>
<reference>
<literal>Filer, Randall, and Marjorie Honig. 1998. A Model of
Endogenous Pensions in Retirement Behavior. Manuscript, Hunter College.</literal>
</reference>
<isreferencedby>
<text ref=''RePEc:dnb:wormem:752'' />
</isreferencedby>
<isreferencedby>
<text ref=''RePEc:fip:fedlwp:2003-038'' />
</isreferencedby>
<isreferencedby>
<text ref=''RePEc:dnb:mebser:2003-18'' />
</isreferencedby>
</text>
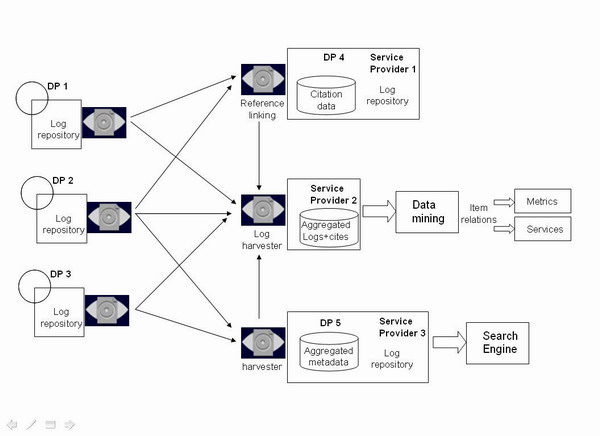
</amf>Una vez que tenemos tanto datos de uso como de citas representados mediante metadatos en lenguaje XML, podrían ser recolectados usando el protocolo OAI-PMH por agregadores de contenidos específicos en una arquitectura similar a la mostrada en la figura 1. En ella tenemos:
Figura 1. Arquitectura para la distribución de datos
- Tres proveedores de datos (DP1, DP2 y DP3) que proporcionan metadatos (Dublin Core) de documentos y de accesos a los mismos (ContextObjects) a través de un nuevo repositorio de logs.
- El papel del proveedor de servicios se ha diversificado actuando ahora también como proveedor de datos adicionales. Dos entidades actúan tanto como PD como PS. El proveedor de servicios número tres sería el proveedor tradicional que recolecta metadatos en Dublin Core de uno o varios repositorios para implementar un servicio de búsqueda. Ahora bien, a su vez está generando datos de uso de aquellos documentos recolectados por lo que se ha convertido en un repositorio de logs (DP5).
- El proveedor de servicios número uno recolecta metadatos en Dublin Core para llevar a cabo un análisis de referencias. Se convierte así en repositorio (DP4) sobre información de referencias y citas. Si a su vez implementa un servicio sobre los mismos podría crear también un repositorio de logs.
- El proveedor de servicios número dos es el más completo puesto que recolecta metadatos en Dublin Core de todos los repositorios de documentos. De los mismos recolecta ContextObject conteniendo datos de uso. De los DP4 y DP5 recolecta igualmente datos de uso mediante ContextObject. Y finalmente del DP4 recolecta información de citas mediante AMF. Con todo ello puede crear a través de técnicas de data mining nuevos servicios como rankings de autores por obras más citadas o descargadas, de documentos más populares, etc. o nuevos indicadores de calidad, utilización, etc. de los materiales.
6 Bibliografía
ANSI/NISO (2004). ANSI/NISO z39.88-2004: The openurl framework for context-sensitive services. <http://www.niso.org/standards/standard_detail.cfm?std_id=783>. [Consulta: 23/02/2008].
Apps, A. (2005). Guidelines for encoding bibliographic citation information in Dublin Core metadata. <http://dublincore.org/documents/dc-citation-guidelines>. [Consulta: 23/02/2008].
Barrueco, J. M. (2002). "Reference linking: un nuevo concepto para facilitar el acceso a la literatura científica". El profesional de la información, vol. 11, nº. 4, p. 278–282.
Barrueco, J. M. (2005). "Building an autonomous citation index for grey literature". TGJ, an international journal on grey literature, vol. 1, no. 2, p. 91–97.
BOAI (2001). Budapest open access initiative. <http://www.soros.org/openaccess>. [Consulta: 23/02/2008].
Bollen, J.; Sompel, H. van de (2005). "A framework for assessing the impact of units of scholarly communication based on OAI-PMH harvesting of usage information". CERN workshop on innovations in scholarly communication (OAI4), Geneva (Switzerland). <http://eprints.rclis.org/archive/00006076/02/bollen.pdf>. [Consulta: 23/02/2008].
COUNTER (2005). Counter code of practice for journals and databases. <http://www.projectcounter.org/code_practice.html>. [Consulta: 26/02/2008].
Eysenbach, G. (2006). "Citation advantage of open access articles". PLoS biology, vol. 4, no. 5, p. 692–698.
Hallam-Baker, P. M.; Behlendorf, B. (1996). Extended log file format. <http://www.w3.org/TR/WD-logfile.html>. [Consulta: 23/02/2008].
ISO (2005). ISO/IEC 9834-8:2005 procedures for the operation of OSI registration authorities: generation and registration of universally unique identifiers (UUIDs) and their use as ASN.1 object identifier components. <http://www.itu.int/ITU-T/studygroups/com17/oid.html>. [Consulta: 23/02/2008].
Krichel, T. (2006). Syntax and vocabulary of the academic metadata format. <http://amf.openlib.org/doc/nagano.html>. [Consulta: 20/02/2008].
Lawrence, S. (2001). "Free online availability substantially increases a paper's impact". Nature, vol. 411, no. 6837, p. 521.
Lin, S. K. (2007). "Non-open access and its adverse impact on molecules". Molecules, no. 12, p. 1436–1437.
OAI (2007). Open archives initiative: object reuse and exchange. <http://www.openarchives.org/ore>. [Consulta: 23/02/2008].
Swan, A.; Carr, L. (2008). "Institutions, their repositories and the web". Serials review, vol. 34, no. 1. <http://eprints.ecs.soton.ac.uk/14965>. [Consulta: 26/02/2008].
Fecha de recepción: 15/02/2008. Fecha de aceptación: 04/03/2008.