
Análisis de consultas a un buscador y su aplicación a la jerarquización de páginas web1
Ricardo Baeza-Yates, Felipe Saint-Jean
Depto. de Ciencias de la Computación
Universidad de Chilerbaeza@dcc.uchile.cl, fsaint@dcc.uchile.cl
Resumen [Abstract] [Resum]
Existen diversas fuentes de información en la web. Una de ellas es la información que deja el usuario mientras usa un buscador. Es posible utilizar esta información para complementar el resultado de algoritmos de jerarquización tradicionales, de manera de agregar conocimiento humano al resultado. Dentro de este concepto, en el presente trabajo se muestra una visión global del análisis del registro de los accesos al buscador TodoCL, mostrando de forma general qué es lo que buscan los usuarios en la web chilena. Luego se expone una aplicación práctica de los datos, al ver los resultados de la implementación de un algoritmo que determina relevancia y jerarquía de documentos basándose en las búsquedas y documentos seleccionados por los usuarios.
1 Introducción
Del amplio espectro de datos existentes en la web que pueden ser analizados para extraer información, los datos de uso de la web son de los más interesantes, pues representan los intereses actuales de la comunidad de usuarios de un sitio. Existen numerosos trabajos sobre análisis de datos de navegación en un sitio y su uso para el rediseño del mismo, pero no sobre uso de servicios específicos, como por ejemplo, buscadores de la web. El texto de Beeferman y Berger (2000) constituye una excepción.
En este estudio se detalla el análisis realizado de las acciones del usuario al utilizar un buscador, en nuestro caso un buscador de la web chilena: TodoCL (www.TodoCL.cl). Esto es interesante desde dos puntos de vista. Por una parte, mejora la calidad del sitio dando una mejor experiencia de búsqueda al usuario del buscador. Por otra parte, el usuario tiene una alta comprensión semántica de los recursos y de las consultas involucradas, por lo que su navegación y utilización deja conocimiento que puede ser utilizado en los procesos de búsqueda y jerarquización de documentos.
Para nuestro análisis usamos 777.351 consultas realizadas en agosto y septiembre del 2001, las cuales contenían 738.390 palabras, con un vocabulario único de 465.021 palabras. Es decir, en promedio, sólo se usan 1,05 palabras por consulta. En la bitácora o diario (log) de consultas, el buscador también registra la navegación que se realiza, en particular las páginas escogidas por los usuarios. La mayoría de las personas refina su consulta agregando o eliminando palabras, pero en promedio sólo inspecciona 1,15 páginas de resultados. Estudios similares han sido realizados con datos de Altavista (Silverstein et al, 1999) y Excite (Wolfran, 2000 y Spink et al, 2002). En nuestro caso, agregamos un análisis de variabilidad de las consultas y también usamos nuestros resultados para mejorar la jerarquización (ranking) de páginas, experimentando con un algoritmo recientemente propuesto (Zhang, 2002).
En la siguiente sección presentamos el análisis de consultas, incluyendo palabras más buscadas, su distribución y variabilidad, las opciones de consulta y la relación de las consultas y las páginas en la web chilena. En el apartado 3 usamos un algoritmo que permite mejorar el ranking de páginas relacionadas con la consulta usando las páginas escogidas por los usuarios. En la sección final entregamos nuestras conclusiones y extensiones futuras.
2 Navegación en el buscador
Los usuarios, al acceder al sitio, dejan su huella en los registros o bitácoras de acceso. A partir de ellos es posible reconstruir el camino seguido por cada usuario. La reconstrucción no es tan directa como aparenta, ya que el caché del navegador hace que ciertos pasos del usuario sean omitidos de las bitácoras. Por ejemplo, es posible que el usuario haya escrito la URL directamente en el navegador (no siguiendo un enlace) y que el caché del navegador cargue la página sin pedirla al servidor. En general, se consideró que el caso en que el usuario ingresa la URL directamente es menor, por lo que la mayoría de los pasos de navegación siguen la estructura del sitio.
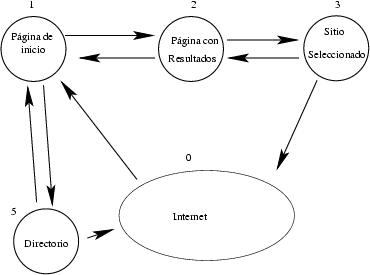
Figura 1. Mapa de navegación del sitio del buscador TodoCL
Una forma de representar la navegación es planteándola como un grafo, que es conocido como el mapa de navegación del sitio. La forma en que los usuarios navegan por éste, es una fuente de datos que nos enseña el uso que éstos dan al buscador. Para el caso del buscador TodoCL, el mapa de navegación del sitio se muestra en la figura 1, indicando los estados posibles.
El análisis de los registros de accesos genera el diagrama de la figura 2. Las transiciones entre estados (nodos) representan la porción de usuarios que al salir del nodo de origen fueron hacia el nodo de destino. Este número es una estimación de la probabilidad de que, dado que un usuario está en el origen del arco, vaya hacia el destino de éste. Dentro de cada estado está la probabilidad de que un usuario esté en esa página.
Hay tres observaciones que se pueden obtener de la figura 2:
- Los usuarios no usan las opciones avanzadas (menos del 1%).
- Es común el refinamiento de la consulta.
- Sólo el 9% de las personas usa el directorio de sitios.
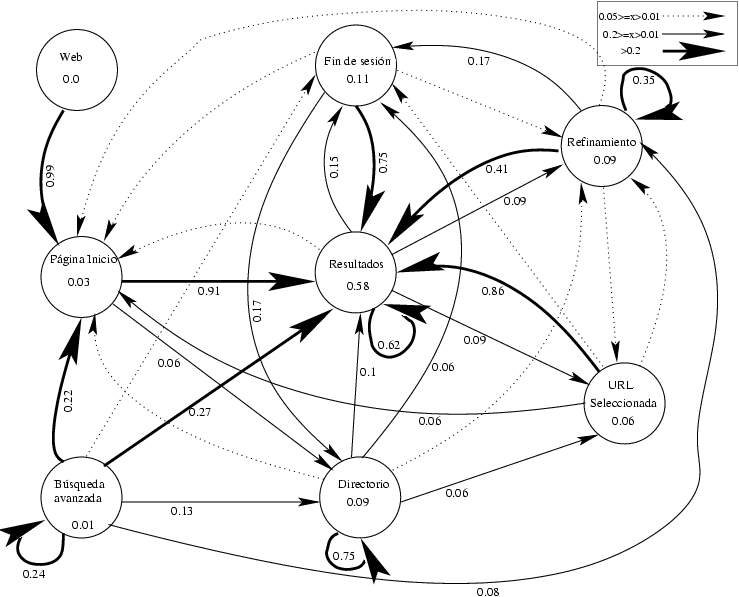
Figura 2. Navegación de los usuarios por TodoCL
Lo anterior indica que los usuarios, como método de búsqueda, utilizan la información del despliegue de los resultados. Es decir, un método más cercano a prueba y error que a una búsqueda más precisa, que sería el caso de la opción de búsqueda avanzada. Además, al observar el gráfico vemos que la probabilidad de que un usuario se encuentre en la página con resultados es mucho mayor que la probabilidad de que un usuario se encuentre en la URL seleccionada. Esto indica que los usuarios visitan relativamente pocas de las páginas del resultado como se mencionó anteriormente.
3 Análisis de consultas
En este apartado también agregamos el análisis de consultas de un buscador español que estuvo en funcionamiento durante el año 2001, Buscopio (www.Buscopio.com). Los datos utilizados son del periodo que va de febrero a julio de 2001. Esto permite ver las similitudes y diferencias entre dos buscadores basados en el mismo idioma principal.
3.1 Frecuencia de palabras y consultas
Las palabras más consultadas en TodoCL y en Buscopio en los periodos estudiados se presentan en la tabla 1. Las consultas simples están compuestas por palabras y operadores; este tipo de consultas será el que analizaremos, dado que son el caso más común.
La figura 3 muestra la frecuencia de las palabras consultadas para TodoCL. Se observa claramente que siguen una distribución de tipo Zipf. La distribución de Zipf generalizada cumple que la frecuencia de la k-ésima palabra más frecuente es proporcional a k-α. El parámetro α en este caso es aproximadamente 1.
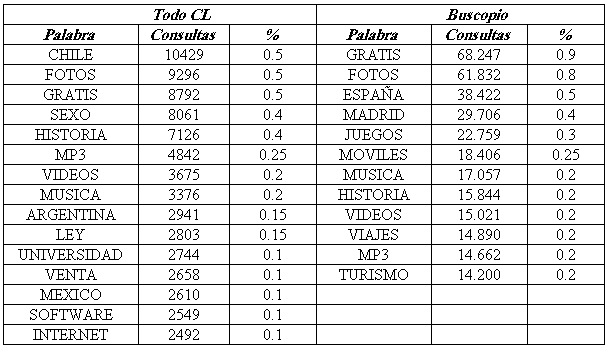
Tabla 1. Palabras más consultadas en TodoCL y Buscopio
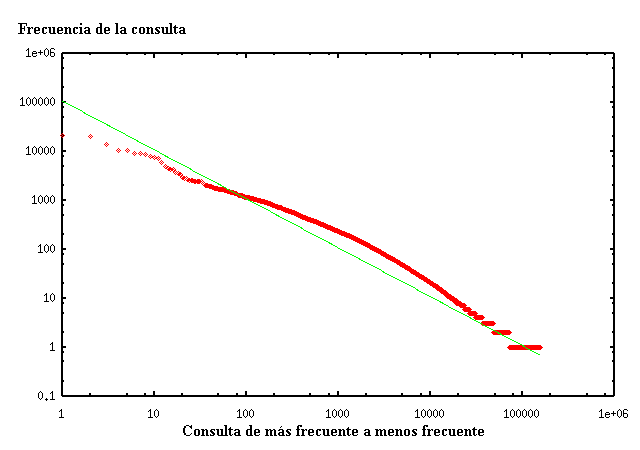
Figura 3. Frecuencia de las palabras consultadas en TodoCL
3.2 Variabilidad de la frecuencia de consultas
Con el objetivo de ver cuánto varían las frecuencias de las palabras consultadas, se estudió la desviación de tales frecuencias. Así, se podría determinar si existen picos en las consultas de algunas palabras.
El gráfico de la figura 4 muestra la desviación estándar de la frecuencia de las palabras consultadas en TodoCL. De este gráfico notamos que la desviación estándar de la frecuencia de las palabras consultadas en TodoCL sigue una distribución similar a una distribución de Zipf con parámetro α=0,65.
Las palabras de mayor desviación estándar en TodoCL son, en orden de variabilidad: “Chile”, “boliviano”, “fotos”, “historia”, “invierno”, “gratis”, “ley” y “MP3”. Es interesante notar la similitud entre las palabras más consultadas de la tabla 1 y de mayor desviación. De hecho, el valor de la correlación entre ambos estimadores es de 0,98, es decir, están altamente correlacionados. En la figura 5 se puede ver la relación lineal entre la desviación estándar de la frecuencia diaria y la frecuencia total en el período, que se puede aproximar por el modelo x=3y/2.
Algunas palabras tienen comportamientos particulares. Fuera del margen del gráfico en la figura 4 hay palabras que se salen de la escala por mucho, y se mantienen en la línea del modelo. Estas palabras son “de”, “en”, y “la”. Otra característica que es observable, es que aparecen algunas palabras de relativamente alta desviación pero baja frecuencia, por ejemplo, “boliviano” e “invierno”. “Invierno” es interesante ya que se trata de una palabra claramente estacional, lo que justifica su baja frecuencia y alta desviación (en particular en el conocido fenómeno del invierno boliviano).
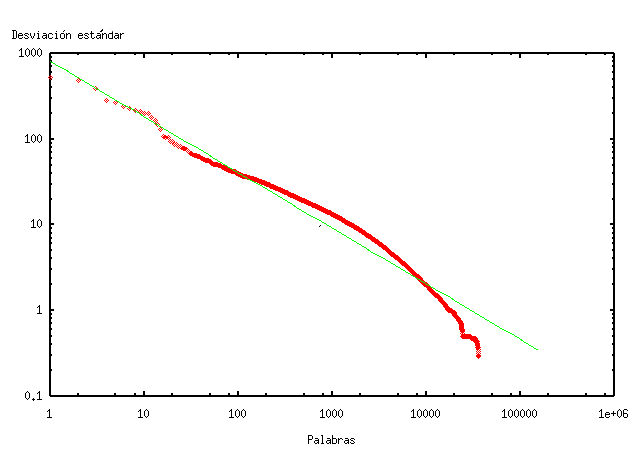
Figura 4. Desviación estándar de la frecuencia de las palabras consultadas en TodoCL
Para Buscopio, los resultados fueron similares, tanto en el gráfico de frecuencia de consultas como en la relación de qué consultas de alta variabilidad eran muy frecuentes. Las preguntas con mayor varianza fueron: “britishairways” (sic), “gratis”, “españa”, “madrid”, “viajes”, “arpanet”, “juegos” y “minis”.
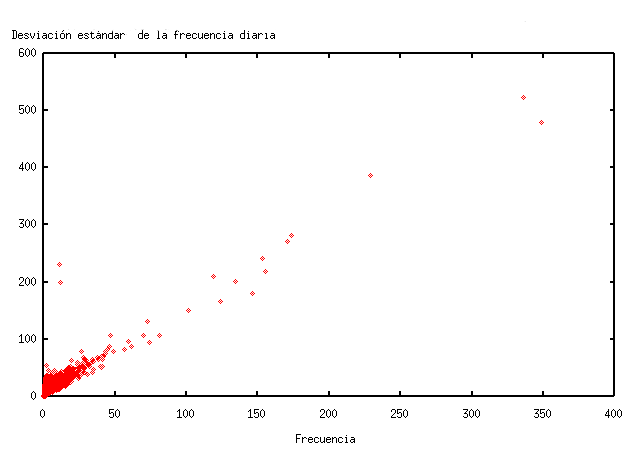
Figura 5. Frecuencia de consulta v/s desviación estándar en TodoCL
3.3 Opciones de consulta
Al utilizar un buscador es posible alterar los parámetros bajo los cuales se realizará la consulta. Los parámetros existentes en el modo de búsqueda simple, son:
- Operador con valores AND, OR o FRASE. El valor AND busca documentos que tengan todas las palabras, OR documentos con alguna palabra, FRASE documentos que contengan la frase exacta.
- Considerar o no acentos en la consulta.
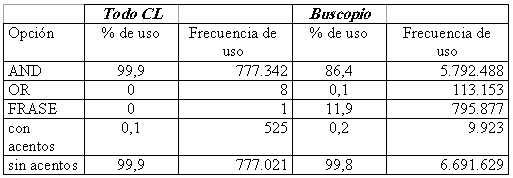
Tabla 2. Uso de opciones de búsqueda en TodoCL (izquierda) y Buscopio (derecha)
En la tabla 2 se pueden ver los niveles de utilización de cada opción en TodoCL y Buscopio. Los valores más altos son los valores por omisión. Esto le da una tremenda importancia a las opciones por omisión, ya que su elección será determinante, en una gran cantidad de casos, para el buen resultado de las consultas. Es interesante que la búsqueda de frases es mucho más usada en Buscopio. Una posible razón es que la web española es más grande y entonces la consulta necesita ser más precisa para obtener páginas más relevantes.
3.4 Palabras consultadas en el contenido
Las palabras consultadas y las que aparecen en las páginas siguen distribuciones similares. Surge la pregunta sobre su relación. En el gráfico de la figura 6 se ve la relación entre documentos relevantes y cantidad de consultas de las palabras. Lo más común son palabras con pocos documentos relevantes y pocas consultas. Hay palabras con pocos documentos y muchas consultas, ejemplos de esto son “Hentai”, “México”, “DivX”, “carátulas” y “melodías”. Las palabras con muchos documentos relevantes y pocas consultas son, en general, palabras funcionales (llamadas palabras vacías o stopwords). Por ejemplo, preposiciones, pronombres y artículos como “pero”, “otros”, “este”, etc. Las palabras con mucho contenido y muchas consultas, en general, son también stopwords como “y”, “de”, “el” y “la”; pero aparece de forma interesante “Chile” como palabra muy consultada y que aparece en muchas páginas. Las palabras poco consultadas y con poco contenido no son interesantes, ya que son muchas. La relación entre las palabras consultadas y las del contenido no es clara, pero su correlación es baja.
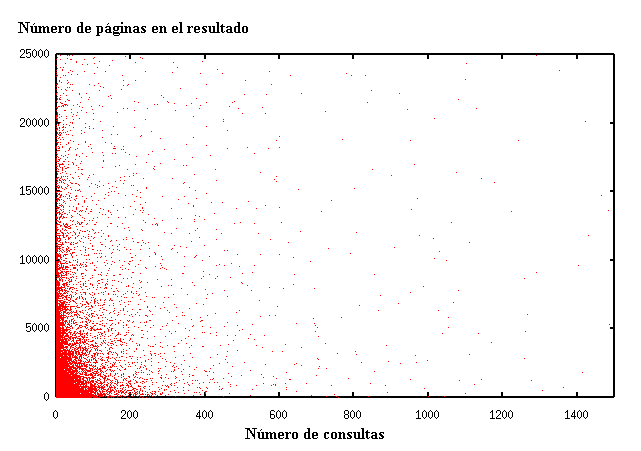
Figura 6. Cantidad de consultas v/s documentos relevantes para las palabras
4 Jerarquización de páginas
En Zhang (2002) se propone un algoritmo para mejorar los resultados de un buscador, basándose en las consultas hechas por los usuarios. El algoritmo propuesto es llamado MASEL (Matrix Analysis on Search Engine Log). Este algoritmo propone un método que relaciona consultas, usuarios y URLs seleccionadas por los usuarios. MASEL es propuesto para un buscador de multimedios, donde la comparación entre el documento y la consulta es de un nivel de precisión muy bajo.
4.1 El algoritmo MASEL
La idea básica es obtener recomendaciones de usuarios que quedan reflejadas en los logs de acceso del buscador, ya que en ellos está la dirección IP del usuario, las consultas que hizo y las URLs que eligió. Es discutible cuanto identifica la dirección IP al usuario, pero se consideró que, por un periodo corto de tiempo, detrás de una IP está siempre el mismo usuario en la mayor parte de los casos.
El algoritmo considera simultáneamente consultas, usuarios y documentos, bajo una definición recurrente sobre estos tres elementos. Los buenos usuarios harán buenas consultas, las buenas consultas retornan buenos documentos y los buenos documentos son seleccionados por buenos usuarios.
Dada una consulta q*, el algoritmo aplica cuatro etapas para obtener un conjunto de resultados:
- Primero se obtiene el conjunto de todos los usuarios que han consultado q* recientemente, conjunto al que llamaremos U. Esta información se encuentra en los logs de acceso del buscador.
- Luego se obtiene el conjunto de todas las consultas realizadas recientemente por los usuarios en U, conjunto al que llamaremos Q. También en los logs de acceso del buscador está esta información.
- A continuación se obtiene, mediante técnicas tradicionales de recuperación de información (por ejemplo, usando el mismo buscador), el conjunto de documentos relevantes al conjunto de consultas Q. Este conjunto lo llamaremos R.
- Finalmente se calcula, mediante un proceso iterativo, los valores numéricos que permiten jerarquizar consultas, usuarios y documentos. Este proceso iterativo será explicado más adelante.
Al referirse a recientemente se está hablando del intervalo [t-T, t] donde t es el presente y T es un parámetro del algoritmo. Sean m=|U|, s=|R| y n=|Q|, además sean ui el valor que representa la calidad del usuario i, qj la calidad de la consulta j y rk la calidad del documento k (luego se explicará cómo se obtienen estos valores). Utilizaremos valores normalizados, es decir
∑U ui = ∑Q qj = ∑R rk = 1,
lo que no afecta los resultados, ya que nos interesa el orden de ellos, y no los valores mismos de calidad. Esta normalización debe realizarse luego de cada iteración.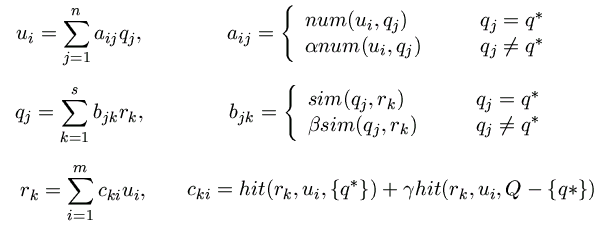
Figura 7. Fórmulas para MASEL
Definimos los pesos para los usuarios según sus buenas consultas en la figura 7 (primera línea), donde num(i,j) representa cuántas veces el usuario ui realizó la consulta qj recientemente y 0< α <1 es un peso para quitar relevancia a las consultas distintas a q*.
Definimos las buenas consultas según recuperen buenos documentos en la segunda línea de la figura 7, donde sim(qj , ) es la similitud entre el documento rk y la consulta qj y 0< β <1 es un peso para quitar relevancia a las consultas distintas a q*.
Finalmente definimos los buenos documentos según la preferencia de los buenos usuarios en la tercera línea de la figura 7, donde hit(rk, ui, S) es la cantidad de veces que el usuario ui eligió el documento rk al hacer una consulta en el conjunto S y 0< γ <1 es un peso para quitar relevancia a las consultas distintas a q*. En forma matricial tenemos u=Aq, q=Br , r=Cu lo que implica que u=Aq=A(Br)=A(B(Cu))=(ABC)u, q=Br=B(Cu)=B(C(Aq))=(BCA)q, y r=Cu=C(Aq)=C(A(Br))=(CAB)r
Esto define un método iterativo para calcular u, q y r. Es decir, podemos obtener los mejores usuarios, consultas y documentos.
El parámetro T, que define la ventana de tiempo en la cual miramos las bitácoras o registros de accesos, es fundamental en la efectividad del algoritmo. Si T es muy grande, el conjunto de consultas extendido comienza a abarcar demasiados elementos no relevantes a la consulta inicial. Por otro lado, si T es muy chico, estamos desperdiciando información. Lo complejo de la determinación del parámetro T es que su valor debe depender de la frecuencia de la consulta (que ya vimos que sigue una distribución de Zipf). Además, un parámetro T mayor hace las matrices más grandes y el algoritmo más lento.El método operó bien en TodoCL, dando resultados relevantes a las consultas. En general el resultado tiende a un par de documentos con calificación mucho mayor que el resto, lo que hace de MASEL un buen algoritmo para utilizarlo como una ayuda paralela a los resultados del buscador entregando al usuario sitios populares relacionados a su consulta. Por ejemplo, se consultó por “autos” con T=24 horas y T=48 horas. Con T=24 horas las URLs más recomendadas fueron:
- http://www.chileautos.cl/link.asp
- http://www.chileautos.cl/personal.htm
- http://www.autoscampos.cl/frmencabau.htm
- http://rehue.csociales.uchile.cl/publicaciones/moebio/07/bar02.htm
Las primeras tres páginas son relevantes, pero la cuarta no. Con T=48 horas las URLs más recomendadas fueron:
- http://www.mapchile.cl/
- http://fid.conicyt.cl/acreditacion/normas.htm
- http://www.clancomunicaciones.cl/muni_vdm/consejo.htm
donde la segunda y tercera URL no son relevantes, pero la primera es relevante sin contener la palabra autos, al ser un sitio de mapas que se puede considerar útil para un automovilista. Esto muestra la capacidad del algoritmo de relacionar semánticamente recursos de la web. Podemos ver en este ejemplo la muy alta dependencia del método respecto del parámetro T.
4.2 Análisis de precisión
Se aplicó el algoritmo anterior a palabras de distinto nivel de frecuencia de consulta para distintos valores del parámetro T. En la figura 8 se ve la precisión del algoritmo para las consultas “software”, “bancos” y “empresas”. Las tres palabras son frecuentemente consultadas. “Software” es bastante más consultada que las otras dos palabras, y vemos que el algoritmo comienza a obtener buenos resultados para valores de T menores. “Banco”, para T=72, obtiene una excelente precisión, que decrece al aumentar T. Es claro que para un buen funcionamiento del algoritmo, T debe depender de la frecuencia de consulta de la palabra, y no ser constante como propone el trabajo original. Cabe mencionar que donde la precisión es 0 es porque el algoritmo no retornó resultados.
Una observación interesante es que en algunas de las consultas realizadas entre los resultados surgía un tema secundario con gran cantidad de documentos relevantes. Por ejemplo, para la consulta “banco”, muchos de los documentos no relevantes se referían a “venta de casas”. Además la precisión baja pues “banco” tiene otros significados en contextos no comerciales. Esto indica que esta heurística funciona sólo con el significado principal de una palabra. Otro ejemplo es que en la consulta “software” surgió como materia secundaria el reciclaje de vidrios, siendo casi todos los documentos no relevantes relacionados a este asunto. Este fenómeno se llama desplazamiento temático (topic drifting) en recuperación de información en la web cuando se usa información de enlaces entre páginas.
Para consultas aún más populares los tamaños de las respuestas fueron lo suficientemente grandes como para hacer imposible el análisis de los datos en forma manual, por lo que no se pudo determinar la relevancia de los resultados. Este fue el caso de las consultas “audio” y “moda”. Si la frecuencia de la consulta no es alta, no es posible usar esta técnica, por ejemplo para la consulta ropa no surgieron documentos relevantes, y para “traductor” se recuperaron siempre los mismos dos documentos, ambos no relevantes.
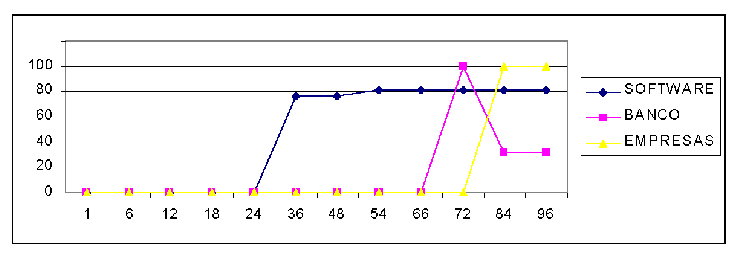
Figura 8. Parámetro T v/s precisión del algoritmo
Para la consulta “chile”, en pocas de las páginas Chile era el asunto principal, siendo en casi todas ellas un tema relacionado. Por otro lado, la temática principal en todas las otras páginas fue relativo a celebridades o deportes en Chile, lo que es interesante ya que al hacer una búsqueda por “Chile” no aparece ningún resultado relativo a estos asuntos en los primeros 30 resultados. Para valores de T mayores a 48 la cantidad de documentos recuperados fue enorme.
5 Conclusiones
Hemos presentado un análisis de consultas de un buscador chileno, que da información de los internautas en Chile. También hemos incluido resultados de un buscador español, Buscopio. Resumiendo, podemos decir que las consultas no son sofisticadas y no aprovechan todo el potencial de un buscador. Por otra parte, es necesario ahondar en el análisis y descubrir si hay patrones en las consultas. Por ejemplo, palabras permanentes, palabras con una cierta periodicidad y palabras transitorias. Nuestro análisis de varianza no permitió distinguir entre las palabras permanentes y transitorias, al parecer porque la frecuencia de estas últimas es muy baja. Una comparación entre las web de Chile y España que complementa este estudio se puede encontrar en Baeza-Yates (2002).
Respecto al uso de las consultas para ranking, es necesario definir la dependencia de T en la frecuencia de la palabra, de manera de obtener buenos resultados a partir de todas las consultas, ya que el algoritmo es poco eficaz para valores muy pequeños de T y poco eficiente (además de poco eficaz) para valores muy grandes de T. Un análisis más detallado podría dar un modelo aproximado para la dependencia de T con respecto a la frecuencia.
Por el tipo de resultados del algoritmo es recomendable su utilización como ayuda complementaria a una búsqueda con métodos más estables de recuperación de documentos, debido a que para muchas consultas poco populares recupera pocos o ningún documento. También como ya mencionamos sólo sirve para el significado más frecuente. En términos de interfaz de usuario, además de los resultados tradicionales de la búsqueda, se recomienda agregar un cuadro lateral que mencione recursos populares entre los usuarios con los mejores resultados de MASEL frente a la consulta realizada.
Nuestros resultados indican que el problema de generalización del tema o desplazamiento del mismo (topic drifting) también aparece al usar información de navegación. En nuestro caso es posible que su aparición pueda ser controlada mediante la reducción de los valores fijados para los parámetros α, β y γ.
Los resultados también podrían ser mejorados detectando distintas sesiones para el mismo número IP, las que pueden indicar distintos usuarios. Sin embargo, detectar sesiones en forma precisa es uno de los problemas más difíciles del análisis de registros de accesos.
Referencias
Baeza-Yates, Ricardo (2002). “La web de España”. Novática, nº 157 (2002), p. 45-46. Publicado en versión en inglés: http://www.upgrade-cepis.org/issues/2002/3/upgrade-vIII-3.html.
Beeferman, Doug; Berger, Adam (2000). “Agglomerative clustering of a search engine query log”. En: Conference on Knowledge Discovery and Data Mining (2000: Boston). KDD-2000: proceedings, August 20-23, 2000, Boston, Massachusetts, USA : the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: Association for Computing Machinery, c2000, p. 407-416.
Silverstein Craig; Henzinger, Monika; Marais, Hannes; Moricz, Michael (1999). “Analysis of a very large AltaVista query log”. SIGIR forum, vol. 33, no. 3, (1999).
Spink Amanda; Jansen, Bernard J.; Wolfram, Dietmar; Saracevic, Tefko (2002). “From e-sex to e-commerce: web search changes”. IEEE Computer, vol. 35, no. 3 (2002), p. 107-109.
Wolfram, Dietmar (2000). “A query-level examination of end user searching behaviour on the Excite search engine”. Canadian Association for Information Science. Conference (28ª: 2000: Edmonton, Alberta). Dimensions of a global information science: CAIS 2000, 28th Annual Conference of the Canadian Association for Information Science to be held with the Congress for the Social Sciences and Humanities of Canada at the School of Library & Information Studies University of Alberta Edmonton, Alberta, Canada May 28-30, 2000. http://www.slis.ualberta.ca/cais2000/wolfram.htm.
Zhang, Dell; Dong, Yisheng. “A novel web usage mining approach for search engine”. Computer Networks, [próxima publicación]
Fecha de recepción: 25/02/2003 Fecha de aceptación: 05/03/2003.
Notas
1 Parcialment financiat per Proyecto Fondecyt 1020803, Chile.