
[Versió catalana | English version]
Andreu Sulé
Profesor de la Facultad de Biblioteconomía y Documentación
Universidad de Barcelona
Resumen
Se describen las principales características de Schema.org, el vocabulario creado en 2011 por Google, Bing, Yahoo! y Yandex para marcar el contenido de las páginas web y, de este modo, hacer reconocibles y comprensibles sus datos a los buscadores. Se expone su principal aplicación a día de hoy, el enriquecimiento de la información que muestran los buscadores de cada página web en sus resultados, así como los fundamentos de su estructura (entidades, propiedades, valores, etc.) y de los formatos de codificación que acepta. También se explica cómo marcar el contenido de una página web con Schema.org, quién usa actualmente este vocabulario, y quién lo mantiene y desarrolla. Por último, se valora brevemente la conveniencia o no de utilizar Schema.org, así como las posibles aplicaciones de este vocabulario para mejorar las búsquedas y los resultados de los buscadores (más precisión, más funcionalidades, etc.), en el desarrollo de la web semántica e, incluso, en el posicionamiento de las páginas web en los buscadores (SEO).
Resum
Es descriuen les principals característiques de l’Schema.org, el vocabulari creat el 2011 per Google, Bing, Yahoo! i Yandex per marcar el contingut de les pàgines web i, d’aquesta manera, fer recognoscibles i comprensibles les seves dades als cercadors. Se n’exposa la principal aplicació avui dia, l’enriquiment de la informació que mostren els cercadors de cada pàgina web en els seus resultats, així com els fonaments de la seva estructura (entitats, propietats, valors, etc.) i dels formats de codificació que accepta. També s’explica com marcar el contingut d’una pàgina web amb l’Schema.org, qui fa servir avui dia aquest vocabulari, i qui el manté i desenvolupa. Finalment, es valora breument la conveniència o no d’utilitzar l’Schema.org, així com les possibles aplicacions d’aquest vocabulari en la millora de les cerques i dels resultats dels cercadors (més precisió, més funcionalitats, etc.), en el desenvolupament del web semàntic i, fins i tot, en el posicionament de les pàgines web en els cercadors (SEO).
Abstract
In this article, we describe the main characteristics of Schema.org, the vocabulary developed in 2011 by Google, Bing, Yahoo! and Yandex to mark up webpage content and thus make data recognizable and understandable to search. We present the main application of Schema.org today, which is to enhance information about a webpage that is displayed in a search engine’s results. We then look at the main principles of the structure of Schema.org (classes, properties, values, etc.) and the coding formats that it accepts. In addition, we explain how to mark up webpage content with Schema.org, and describe who uses, maintains and develops this vocabulary today. Finally, we briefly assess the advantages of using Schema.org, as well as the potential applications of this vocabulary in the improvement of searches and search engine results (greater accuracy, more functionalities, etc.); the development of web semantics; and the area of website ranking (search engine optimization, SEO).
1 ¿Qué es y para qué sirve Schema.org?
¿Quién no quiere que aumente el número de visitas a sus páginas web? ¿Quién no desea que los usuarios que buscan en Google, Yahoo!, Bing o Yandex1 escojan su sitio web entre los resultados que obtienen con sus búsquedas? ¿A quién no le gustaría poder mostrar más datos en las entradas de los resultados de una búsqueda en Google, para así poder informar mejor a los usuarios del contenido de sus páginas web? Pues bien, todo esto es lo que, directa o indirectamente, Google, Yahoo!, Bing y Yandex dicen que pasará si se codifica el contenido HTML de las páginas web con Schema.org, el vocabulario creado y mantenido por estos grandes motores de búsqueda desde 2011.
Por ejemplo, si se busca «apple pie recipe» en Google.com probablemente se encontrarán resultados similares a estos:
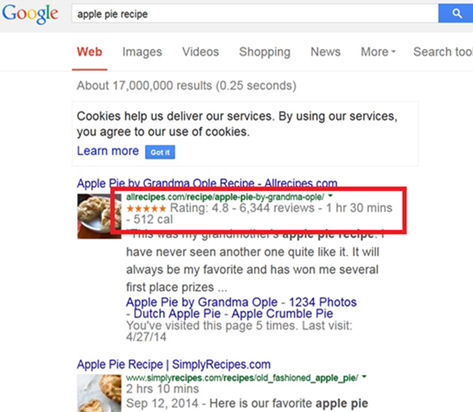
Figura 1. Entrada con datos enriquecidos en los resultados de la búsqueda «apple pie recipe» en Google
Tal como puede verse destacado en rojo, las entradas de algunos resultados han sido enriquecidas con datos (rich snippets) que Google ha extraído del mismo contenido HTML de las páginas web y que las hacen más atractivas. ¿Y cómo puede Google identificar estos datos dentro del código HTML de las páginas web? Pues porque este contenido ha sido codificado por el administrador del web (u otro responsable) con el vocabulario Schema.org que Google reconoce y entiende.
Simplificándolo mucho (más tarde se expone con más detalle y rigor), en los dos recuadros siguientes se puede ver de manera comparativa qué significa codificar el contenido de una página web con Schema.org y cómo de fácil lo tiene Google para identificar los datos con que enriquecerá la información de la entrada en los resultados. En el primer recuadro se muestra parte del contenido de la página web2 del primer resultado de la búsqueda anterior sin codificar con Schema.org:

Figura 2. Contenido de la página web sin codificar con Schema.org
Mientras que en el segundo se muestra el mismo contenido codificado con Schema.org:

Figura 3. Contenido de la página web codificado con Schema.org
Como puede comprobarse, en el segundo caso las diferentes partes del contenido están identificadas semánticamente con unos atributos HTML específicos (itemscope, itemprop, etc.) y unos valores de estos atributos (ratingValue, reviewCount, cookTime, etc.) que permiten al Google «entender» el significado de los datos y, por tanto, poder elegir los que quiere emplear para enriquecer la entrada de la página web en los resultados de la búsqueda. Así de complejo y así de simple.
2 Schema.org un poco más en detalle
La propuesta de Google, Yahoo!, Bing y Yandex se basa en una colección de vocabularios (o esquemas de metadatos) que definen las propiedades con las que se puede codificar el contenido de las páginas web. Por ejemplo, en Movie se pueden encontrar las propiedades para describir películas, como actor, director, duration, etc.
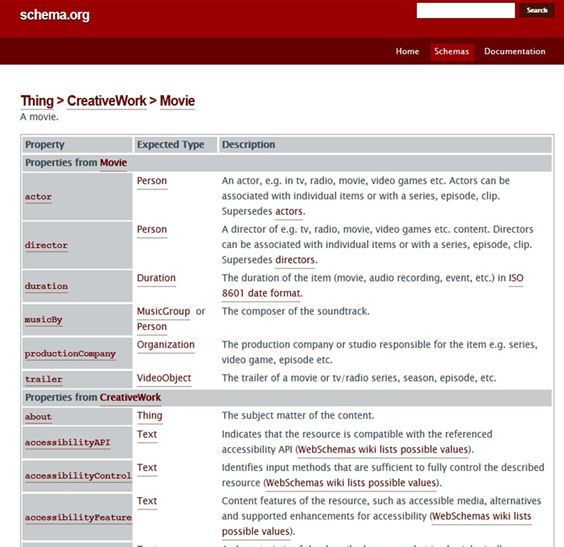
Figura 4. Propiedades de Movie
En el año 2014 había cuatrocientas veintiocho entidades (tipo de cosas, en un sentido amplio, físicas y no físicas) y quinientas ochenta y una propiedades (Tort; Olivé, 2014), cifras que no dejan de crecer año tras año y que dan una idea del grado de detalle con que Schema.org permite marcar el contenido de las páginas web.
Para facilitar la identificación de las propiedades, Schema.org las agrupa según la entidad que se quiere representar y las organiza de manera jerárquica:
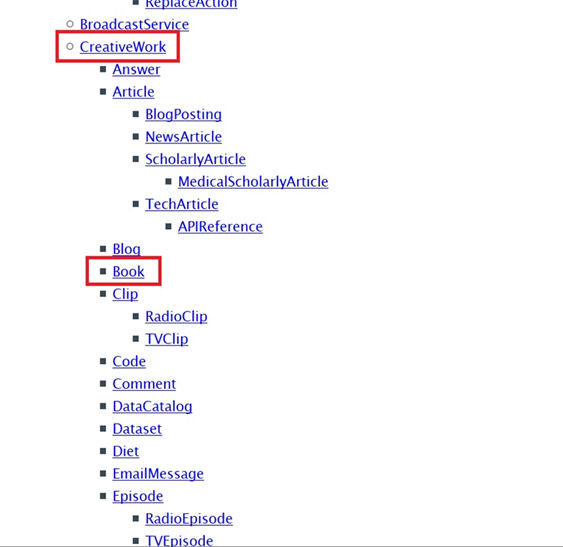
Figura 5. Presentación jerárquica de las entidades de Schema.org
Así, se puede encontrar, por ejemplo, que el vocabulario para libros, Book, es una subcategoría del vocabulario CreativeWork y éste, a su vez, de Thing, que es la entidad más genérica dentro de Schema.org.
Esta estructura jerárquica implica que las entidades hereden las propiedades de las entidades jerárquicamente superiores. Aplicado al caso anterior, esto significa que para la codificación de los datos de un libro contenidos en una página web se pueden emplear tanto las propiedades del tipo Book, como las de CreativeWork o las de Thing.
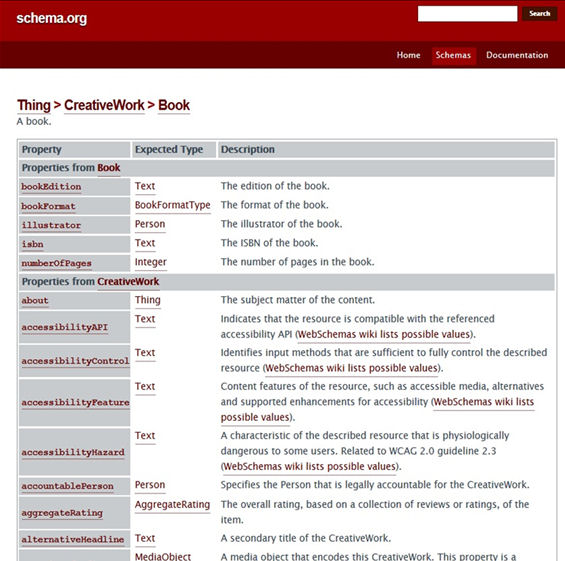
Figura 6. Propiedades de Book
En cuanto a los criterios de aplicación de las propiedades o a la naturaleza de sus valores, en líneas generales, Schema.org no es muy concreto. De hecho, de cada propiedad únicamente establece el tipo de dato que puede contener (Expected Type) y su alcance (Description).
Los tipos de datos que puede contener una propiedad pueden ser un valor, una enumeración o una entidad. Los tipos de valores están definidos en DataType (Boolean, Date, DateTime, Number, Text, Time, etc.). Las enumeraciones (Enumeration) son listas cerradas de valores autorizados que en algunos casos contienen subcategorías (por ejemplo, Anesthesia es una subcategoría de MedicalSpecialty). Más singular es la posibilidad que el contenido de una propiedad sea una entidad. Por ejemplo, en el vocabulario Festival encontramos la propiedad Organizer que permite codificar la información sobre la persona o la empresa que organiza el festival. Schema.org indica que el tipo de dato que admite esta propiedad puede ser la entidad Organization o la entidad Person.

Figura 7. Propiedad Organizer en la entidad Festival
De este modo, para codificar la información sobre el organizador de un festival se pueden emplear todas las propiedades de la entidad Organization o de la entidad Person. Por ejemplo, la codificación de la información de la empresa Mas i Mas (nombre, teléfono, fax y correo electrónico), organizadora del 12è San Miguel Mas i Mas Festival Agost’14, quedaría de la siguiente forma:

Figura 8. Codificación de la información del 12è San Miguel Mas i Mas Festival Agost’14 organizado por la empresa Mas i Mas
Como puede comprobarse, el nombre, teléfono, fax y correo electrónico de la empresa Mas i Mas quedan agrupados dentro de la codificación correspondiente a la entidad Organization (<div itemprop = «organizer» itemscope itemtype = «http: // schema .org / Organization «>).
Tal y como se ha explicado anteriormente, la segunda información que Schema.org proporciona de cada propiedad es su alcance (Description). Aquí, a veces, además de la definición de la propiedad se pueden encontrar criterios de aplicación, como pueden ser sintaxis morfológicas (por ejemplo, la norma ISO 8601 para endDate y la norma IETF BCP 47 para inLanguage, ambas propiedades del tipo TVSeries) o listas de valores autorizados (por ejemplo, WebSchemas/Accessibility para la propiedad accessibilityControl del tipo Artícle).
3 ¿Con qué formatos se codifica Schema.org?
Tal como se establece en su web, actualmente Schema.org puede ser codificado con Microdata, RDFa y JSON-LD. Cada uno de ellos tiene sus puntos fuertes y sus puntos débiles, dependiendo del escenario de aplicación.
Microdata (el primer formato promovido por Schema.org y el empleado en los ejemplos de este artículo) y RDFa son ambos especificaciones de atributos de HTML (por ejemplo, <span itemprop en Microdata o <span property en RDFa). Microdata es menos complejo que RDFa, pero esta misma complejidad permite a RDFa ofrecer más funcionalidades, como la combinación de diferentes vocabularios en un mismo documento. Otra diferencia son las instituciones que han creado y mantienen cada uno de los dos formatos, Web Hypertext Application Technology Working Group (también promotor de HTML5) en el caso de Microdata y W3C en el caso de RDFa, lo que, en principio, daría un grado de estandarización más grande a este último, si bien algunos estudios parecen mostrar un uso progresivo de Microdata (Bizer [et al.]2013; Meusel; Petrovski; Bizer, 2014).
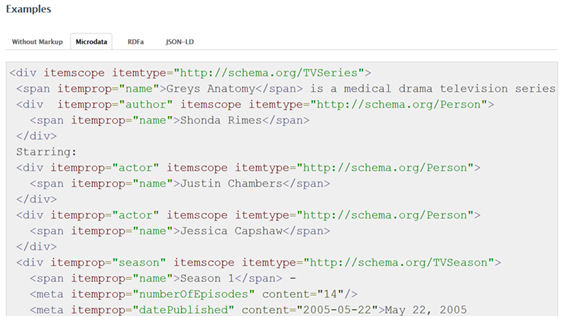
Figura 9. Ejemplo de codificación con Microdata de la entidad TVSeries
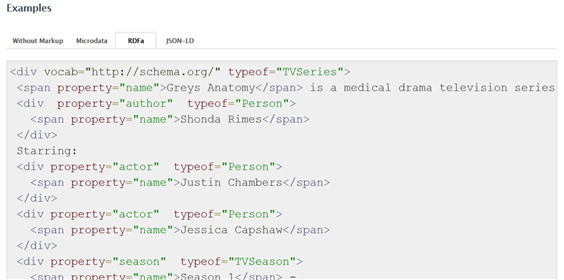
Figura 10. Ejemplo de codificación con RDFa de la entidad TVSeries
JSON-LD, por el contrario, no codifica el contenido de las páginas web como parte del contenido de HTML, sino con sintaxis JavaScript. El uso del lenguaje de programación más popular de la web facilita la reutilización de los datos codificados para muchas otras aplicaciones web (por ejemplo, exportar los datos de un evento a un calendario).
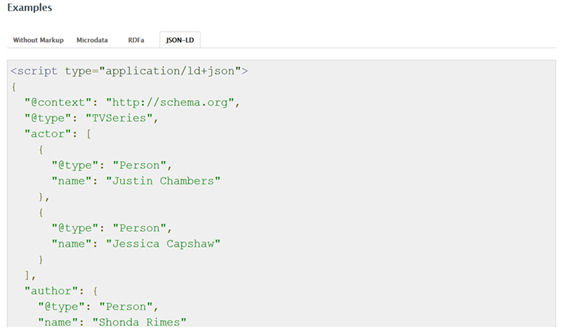
Figura 11. Ejemplo de codificación con el JSON-LD de la entidad TVSeries
4 ¿Existen herramientas similares a Schema.org?
Antes de la aparición de Schema.org ya existían vocabularios que permitían dar valor semántico al contenido de las páginas web y algunos todavía se utilizan. Uno de ellos es Data-Vocabulary.org que, en muchos aspectos, es considerado el predecesor de Schema.org.
Data-Vocabulary.org, como Schema.org, está compuesto por clases (item type) y cada clase por propiedades. Son ejemplos de clases Person, Product, Organization, Review, etc. A pesar de que en su momento llegó a ser el vocabulario más utilizado para marcar el contenido web (Bradley, 2013), actualmente ha sido sustituido de facto por Schema.org. De hecho, en la página web de Data-Vocabulary.org sólo hay referencias y enlaces a Schema.org.
Un segundo vocabulario para marcar el contenido de las páginas web es Microformats. Se trata de un proyecto de desarrollo comunitario, iniciado en 2005, que exhibe su simplicidad, especialmente frente a otras alternativas más complejas, como XML. Uno de los rasgos principales de esta simplicidad es el uso de elementos HTML (especialmente el atributo class) para codificar las propiedades. Microformats es un conjunto de vocabularios, cada uno de los cuales contiene las propiedades necesarias para marcar un tipo concreto de contenido. Por ejemplo, h-card para personas y organizaciones; h-evento para eventos; h-review para críticas, etc. En conjunto, sin embargo, Microformats contiene un número menor de vocabularios que Schema.org.
En un estudio de 2012 (Bizer [et al.] 2013; Meusel; Petrovski; Bizer, 2014), Microformats era el vocabulario de marcado de contenido web más utilizado, por delante de Data-Vocabulary.org y de Schema.org, aunque esta situación puede variar en un futuro debido al apoyo explícito de Google al uso de Schema.org.
5 En la práctica, ¿cómo se marca el contenido de una página web con Schema.org?
A pesar de ser cierto que Schema.org es un vocabulario conceptualmente sencillo en cierto modo, no lo es menos que codificar a mano, directamente en el código fuente, la información contenida en un sitio web, con decenas o cientos de páginas web, puede llegar a ser muy caro en concepto de horas de trabajo. Es por ello que, en la práctica, esta codificación se hace de manera automática, ya sea a través de plantillas específicas de los mismos sistemas de gestión de contenidos con los que se crean las páginas web, ya sea por la conversión de los datos a Schema.org, en el caso de las páginas web dinámicas generadas a partir de una petición de un usuario a una base de datos. También es cierto, igualmente, que de manera habitual no se marcan todos los datos contenidos en una página web, sino únicamente aquellos que el responsable de la web considera más importantes que aparezcan como enriquecidos en la visualización de los resultados de las búsquedas (Schema.org, a diferencia de Microformats, no establece ninguna propiedad obligatoria para ninguna entidad).
En el primer caso tenemos los ejemplos de sistemas de gestión de contenidos como Drupal, WordPress o Joomla. Los tres han desarrollado módulos específicos para el marcaje del contenido de las páginas con Schema.org.
Un ejemplo de codificación dinámica es WorldCat. Desde 2012, OCLC está añadiendo a las páginas web de los registros bibliográficos los datos descriptivos codificados con Schema.org (Murphy, 2012). En el ejemplo siguiente se puede ver el registro bibliográfico del libro Harry Poter and the deathly hallows codificado con Schema.org (pestaña desplegable «Linked Data» al final de la página):
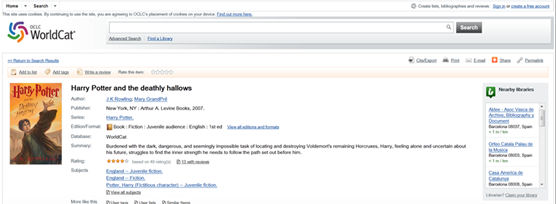
Figura 12. Registro bibliográfico del libro Harry Poter and the deathly hallows de WorldCat codificado con Schema.org
Además de estas herramientas, en el web también se pueden encontrar asistentes en línea que facilitan la codificación con Schema.org mediante sencillas plantillas. Son ejemplos el Asistente para el etiquetado de datos estructurados, Schema Creator y Schema.org Generator | Microdata Generator. Son herramientas de manejo muy sencillo, muy tutorizadas, pero que sólo son útiles en caso de tener que marcar el contenido de unas pocas páginas web.
Finalmente, debe mencionarse que Google mantiene la página web Promote Your Content with Structured Data Markup donde se puede encontrar mucha información relacionada con Schema.org, así como recomendaciones para el marcado y las características de las principales entidades.
6 ¿Quién usa Schema.org hoy en día?
Si bien es cierto que actualmente el número de páginas web con el contenido marcado con Schema.org es poco significativo con relación a la totalidad de páginas existentes en Internet (Homoceanu [et al.] 2013; Schema.org…, 2014), no lo es menos que importantes organizaciones y empresas, líderes en sus respectivos sectores, están marcando sus sitios web con Schema.org. A continuación se presentan algunos ejemplos:
- Catálogos de bibliotecas: WorldCat
- Comercio electrónico: eBay, Sears, Mango, Macy’s
- Música: Last.fm, Myspace
- Películas y vídeos: IMDb, FilmAffinity, YouTube
- Portales de búsqueda de empleo: Indeed, SimplyHired, Monster.com
- Prensa: The Wall Street Journal, The New York Times, The Guardian, BBC, Fox News, ABC News, CBSSports.com, Los Angeles Times
- Restaurantes: Allmenus.com, Urbanspoon
- Venta de entradas de espectáculos: Ticketmaster, Eventful
- Redes sociales: Meetup.com, Google+
Así pues, sean muchas o pocas las páginas actualmente codificadas, la relevancia de las entidades que sí utilizan Schema.org hace prever que su nivel de implementación seguirá creciendo en cantidad y en importancia en un futuro inmediato.
7 ¿Quién mantiene y desarrolla Schema.org?
Los promotores de Schema.org (Microsoft, Yahoo!, Google y Yandex) han dejado claro desde un principio que las entidades incluidas en el vocabulario son elegidas siguiendo una lógica empresarial. Es decir, actualmente no se pueden codificar todas las cosas. Sin embargo, vale la pena destacar que Schema.org es un vocabulario vivo, en constante expansión, y que este desarrollo lo lleva a cabo en muchos casos en estrecha colaboración con organizaciones e instituciones de prestigio en cada uno de los sectores, tales como:
- GoodRelations para el desarrollo y mantenimiento de todos aquellos vocabularios relacionados con el comercio electrónico.
- BBC and International Press Telecommunications Council (a través de su norma SportsML) para la mejora de la codificación de información sobre atletas, organizaciones y eventos deportivos.
- Schema Bib Extend Community Group para la mejora del marcado de descripciones bibliográficas.
- Learning Resource Metadata Initiative para la descripción de recursos educativos.
- United States Office of Science and Technology Policy para el desarrollo del tipo JobPosting.
También puede ayudar a dar una idea del grado de implicación de las grandes corporaciones saber que en el «Panel: Schema.org» de la Semantic Technology & Business Conference de 2012 asistieron representantes del W3C, de la New York Times Company, de Disney Interactive Media Group y de Microsoft.
Además de estas colaboraciones institucionales, Schema.org permite que cualquiera, si lo desea, pueda opinar, preguntar, o colaborar en el desarrollo y mantenimiento de los vocabularios a través del portal Schema.org Community Group o de la lista de discusión public-vocabs@w3.org (http://lists.w3.org/Archives/Public/public-vocabs/).3 Adicionalmente, tiene dos wikis públicos en el marco del consorcio W3C: el WebSchemas y el GitHub schemaorg, donde puede consultarse el estado de las propuestas de ampliación y mejora de los vocabularios.
Por último, conviene tener en cuenta que también en el campo del Linked Data los responsables de Schema.org están trabajando para adaptar los vocabularios a la web semántica. Muestra de ello es la adopción de RDFa Lite como formato para la codificación (Brickley, 2011). RDFa Lite es la versión simplificada de RDFa, la sintaxis de marcado de contenido de las páginas web propuesta por el W3C. El web What is Schema.RDFS.org? también sigue la misma línea de facilitar la interoperabilidad de datos; en él puede encontrarse información sobre Linked Data, así como herramientas (lenguajes de programación, editores, etc.) y tablas de equivalencia con otros vocabularios de la web (DBpedia, Dublin Core, FOAF, GoodRelations, SIOC, Bibliographic Ontology y WordNet).
8 ¿Qué posibilidades de futuro tiene Schema.org?
Aunque en la página oficial de Schema.org se menciona como principal beneficio de su uso la mejora de la visualización de los resultados de las búsquedas, existen ciertos indicios que en un futuro no muy lejano (sino ya presente) el marcado del contenido de las páginas web tendrá otras aplicaciones.
Wail (2011) y CodexM (2011) ya apuntaban desde los inicios de Schema.org el hecho que los motores de búsqueda entendieran la información de las páginas web podría emplearse para mejorar la experiencia de búsqueda de los usuarios: mejora de la precisión de los resultados al poder identificar el significado de los datos; incorporación de filtros para limitar las búsquedas (se puede ver una demostración aplicada a las recetas de cocina en Slice and dice your recipe search results), establecimiento de nuevos criterios de ordenación de los resultados (por ejemplo, por votación de los usuarios), etc.
Una segunda proyección de futuro es la vinculación con la web semántica al facilitar a las máquinas (no sólo a los motores de búsqueda) la comprensión del contenido de los webs. La aceptación de RDFa como sintaxis de codificación, el trabajo conjunto con W3C y los esfuerzos para el desarrollo y uso de Schema.org en el paradigma del Linked Data son pruebas más que evidentes.
Y, finalmente, vale la pena destacar que, aunque Google niega cualquier relación entre Schema.org y el ranking de las páginas web, un gran número de empresas, publicaciones y portales de SEO (Higher Visibility, Moz, iProspect, Search engine Journal, etc.) están dedicando muchos recursos a conocer y difundir los beneficios del nuevo vocabulario en el posicionamiento en buscadores.
9 Conclusiones
Después de lo expuesto hasta ahora, parece evidente que Schema.org es un vocabulario que los profesionales del sector deben tener muy presente. Quizá para algunos la mejora de la visualización de los resultados es un beneficio demasiado exiguo que no justifica el sobrecoste del marcaje del contenido de las páginas web. Sin embargo, hay que evaluar Schema.org no sólo por lo que representa hoy en día, sino también por lo que puede convertirse en un futuro, un devenir que quizá no responderá a criterios estrictamente técnicos, sino de apoyo, y más concretamente, en el papel que Google tenga en el desarrollo, el uso y la aplicación de Schema.org. Guste o no, hoy en día todo lo relacionado con Google debe interesar a los profesionales de la información y la documentación.
Bibliografía
Bizer, Christian [et al.] (2013). “Deployment of RDFa, microdata, and microformats on the web: a quantitative analysis”. En: The Semantic Web – ISWC 2013: 12th International Semantic Web Conference, Sydney, NSW, Australia, October 21–25, 2013, Proceedings, Part II. Berlin: Springer, p. 17–32. <http://hannes.muehleisen.org/Bizer-etal-DeploymentRDFaMicrodataMicroformats-ISWC-InUse-2013.pdf>. [Consulta: 05/03/2015].
Bradley, Aaron (2013). Basic vocabulary for schema.org and structured data. SEOSkeptic. <http://www.seoskeptic.com/basic-vocabulary-for-schema-org-and-structured-data/>. [Consulta: 05/03/2015].
Brickley, Dan (2011). Using RDFa 1.1 Lite with Schema.org. Schema blog. <http://blog.schema.org/2011/11/using-rdfa-11-lite-with-schemaorg.html>. [Consulta: 05/03/2015].
CodexM (2011). Schema.org and Microdata Markups for SEO. Seochat. <http://www.seochat.com/c/a/search-engine-optimization-help/schema-org-and-microdata-markups-for-seo/>. [Consulta: 05/03/2015].
García-Marco, Francisco-Javier (2012). «Schema.org: la catalogación revisitada». Anuario ThinkEPI, v. 7, p. 169–172. <http://www.thinkepi.net/schema-org-catalogacion-revisitada>. [Consulta: 05/03/2015].
Homoceanu, Silviu [et al.] (2013). «Any suggestions? Active Schema Support for Structuring Web Information». En: International Conference on Database Systems for Advanced Applications. Database systems for advanced applications: 19th International Conference, DASFAA 2014: proceedings, part II. Berlin: Springer, p. 251–265. <http://www.ifis.cs.tu-bs.de/sites/default/files/DASFAA14_conference_105.pdf>. [Consulta: 05/03/2015].
Meusel, Robert; Petrovski, Petar; Bizer, Christian (2014). «The WebDataCommons Microdata, RDFa and microformat data set series». En: The Semantic Web – ISWC 2014: 13th International Semantic Web Conference, Riva del Garda, Italy, October 19–23, 2014. Proceedings, Part I. Berlin: Springer, p. 277–292.
Murphy, Bob (2012). OCLC adds Linked Data to WorldCat.org. OCLC.org <http://www.oclc.org/news/releases/2012/201238.en.html>. [Consulta: 05/03/2015].
Pastor Sánchez, Juan Antonio (2012). «Prospectiva de la web semántica: divergencia tecnológica y creación de mercados Linked Data». Anuario ThinkEPI, v. 6, p. 269–275. <http://www.thinkepi.net/prospectiva-de-la-web-semantica-divergencia-tecnologica-y-creacion-de-mercados-linked-data>. [Consulta: 05/03/2015].
Ronallo, Jason (2012). «HTML5 Microdata and Schema.org». Code4Lib Journal, Issue 16. <http://journal.code4lib.org/articles/6400>. [Consulta: 05/03/2015].
Schema.org in Google search results. Searchmetrics, 2014. <http://pages.searchmetrics.com/rs/searchmetricsgmbh/images/Searchmetrics_Schemaorg_Study_2014.pdf>. [Consulta: 05/03/2015].
Tort, Albert; Olivé, Antoni (2014). «A computer-guided approach to website Schema.org design». En: Conceptual Modeling: 33rd International Conference, ER 2014, Atlanta, GA, USA, October 27-29, 2014. Proceedings. Springer International Publishing, p. 28–42. Doi 10.1007/978-3-319-12206-9_3.
Use structured data for rich search results. Google, 2015. <https://support.google.com/webmasters/topic/4598337?hl=en&ref_topic=3309300>. [Consulta: 05/03/2015].
Wailes, Pete (2011). Semantic data, Schema.org & the future of search. Strategy Digital. <http://www.strategydigital.co.uk/blog/semantic-data-schema-org-the-future-of-search/>. [Consulta: 05/03/2015].
Notas
1 Yandex es el motor de búsqueda más importante en Rusia.
2 Consulta realizada el 23/02/2015.
3 En el momento de elaborar este artículo, en la lista se está discutiendo cómo dar las fechas aproximadas de los recursos (por ejemplo, el año de publicación aproximado de un manuscrito).
 licencia de Creative Commons de tipo «Reconocimiento-NoComercial-SinObraDerivada«. Esto significa que se pueden consultar y difundir libremente siempre que se cite el autor y el editor con los elementos que constan en la opción «Cita recomendada» que se indica en cada uno de los artículos, pero que no se puede hacer ninguna obra derivada (traducción, cambio de formato, etc.) sin permiso del editor. En este sentido, se cumple con la definición de open access de la Declaración de Budapest en favor del acceso abierto. La revista permite al autor o autores mantener los derechos de autor y retener los derechos de publicación sin restricciones.
licencia de Creative Commons de tipo «Reconocimiento-NoComercial-SinObraDerivada«. Esto significa que se pueden consultar y difundir libremente siempre que se cite el autor y el editor con los elementos que constan en la opción «Cita recomendada» que se indica en cada uno de los artículos, pero que no se puede hacer ninguna obra derivada (traducción, cambio de formato, etc.) sin permiso del editor. En este sentido, se cumple con la definición de open access de la Declaración de Budapest en favor del acceso abierto. La revista permite al autor o autores mantener los derechos de autor y retener los derechos de publicación sin restricciones.