
[Versió catalana | English version]
Mireia Alcalá Ponce de León
Graduada en Información y Documentación
Universitat de Barcelona
Resumen
En los últimos años, la participación social a través de la red se ha convertido en esencial en algunos ámbitos. En este trabajo se hace referencia a este tipo de movimientos llamados “crowdsourcing” o de “abastecimiento participativo”, en la figura del voluntariado y en las motivaciones que le llevan a participar. Además, se muestra una recopilación de los principales proyectos de "crowdsourcing" sobre transcripciones masivas realizados en las instituciones de la memoria (bibliotecas, archivos, museos y las galerías) a nivel internacional. Mediante el análisis de estos proyectos, se revisan las características a través de unos indicadores creados especialmente para este tipo de iniciativas y, a partir de ahí, se proponen unas buenas prácticas que se deben de contemplar en el diseño de proyectos de transcripciones masivas.
Resum
En els últims anys, la participació social per mitjà de la xarxa ha esdevingut essencial en alguns àmbits. En aquest treball es fa referència a aquest tipus de moviment anomenat “crowdsourcing” o de “proveïment participatiu”, a la figura del voluntariat i a les motivacions que el porten a participar-hi. A més, es mostra un recull dels principals projectes de “crowdsourcing” sobre transcripcions massives realitzats a les institucions de la memòria (biblioteques, arxius, museus i les galeries) a nivell internacional. Mitjançant l’anàlisi d’aquests projectes, se’n revisen les característiques a través d’uns indicadors creats especialment per a aquests tipus d’iniciatives i, a partir d’aquí, es proposen unes bones pràctiques que cal preveure en el disseny de projectes de transcripcions massives.
Abstract
In recent years, the growth of web-based social participation and the open source movement have prompted a number of initiatives, including the movement known as crowdsourcing . This paper examines crowdsourcing as a volunteering phenomenon and considers what motivates individuals to participate in crowdsourcing. In addition, the paper reviews the main projects in mass transcription being made in memory institutions worldwide (libraries, archives, museums and galleries), briefly introducing each project and analyzing its main features. Finally, a selection of best practices is offered to guide institutions in the implementation of mass transcription projects.
1 Introducción
El aumento en los últimos años de las digitalizaciones por parte de las instituciones de la memoria ha venido propiciada por la consolidación y mejora de las Tecnologías de la Información y la Comunicación (TIC). Estas instituciones de la memoria englobadas por las bibliotecas, los archivos, los museos y las bibliotecas (conocidas en el mundo anglosajón como los GLAM, Galleries, Libraries, Archives and Museums) iniciaron estos grandes proyectos para ampliar el acceso a sus colecciones (servicio las 24 horas, con sesiones multiusuarios, etc.), transformar los servicios ofrecidos y aumentar la preservación y conservación de los documentos físicos (creándose unas directrices para proyectos de digitalización por parte de la IFLA y la ICA).1
Sin embargo, este panorama se ralentiza entre 2007 y 2008, con la crisis económica, cuando los recursos humanos y materiales empiezan a menguar.
No obstante, es en este momento en el que sobresale todo el movimiento open source y la participación social a través de la red; no sólo en el ámbito en el que tratamos sino a nivel global. Así pues, la aportación y colaboración mediante internet entre las grandes instituciones, así como entre éstas y sus usuarios hace que nazcan proyectos como los de crowdsourcing. El TERMCAT (2012) tradujo crowdsourcing como "abastecimiento participativo" y lo entiende como una llamada abierta para "proveerse de servicios, ideas o contenidos".
Las instituciones de la memoria también se han posicionado en este tipo de proyectos donde sobresalen iniciativas como las de transcripciones masivas, ya que resolvían ciertas limitaciones (coste y personal); mejoraban el acceso a las colecciones e involucraban a los usuarios creando comunidades.
2 Crowdsourcing o abastecimiento participativo
El término crowdsourcing apareció por primera vez en 2006 en la revista Wired de la mano del escritor Jeff Howe en su artículo "The rise of crowdsourcing". El término agrupa dos palabras independientes como son: crowd (que hace referencia a la multitud) y sourcing (que lo vincula con la fuente, la obtención de materia prima) y lo define como el acto en el que una organización traspasa una función que anteriormente realizaban los empleados hacia una amplia red de personas, en forma de desafío abierto, a cambio de una recompensa.
Aunque el término aparece en este momento, anteriormente ya existían diferentes acciones que se pueden relacionar. Pierre Lévy (1997) habla de cómo la inteligencia colectiva puede emerger en el mundo del ciberespacio; dos años más tarde, Tim Berners-Lee y Mark Fischetti (2000) apostaban por el término intercreatividad que buscaba la creación de elementos en la red mediante la intervención y colaboración de varias personas. En la misma línea, Howard Rheingold (2003) hablaba de las smart mobs o multitudes inteligentes como revolución social.
Existen diferentes clasificaciones de crowdsourcing pero una de las más consolidadas, tras realizar diferentes análisis de varias clasificaciones, es ésta propuesta por Estellés-Arolas y González-Ladrón-de-Guevara (2012).
![Clasificación de los diferentes tipos de crowdsourcing [Elaboración propia realizada a partir de Estellés-Arolas i González-Ladrón-de-Guevara (2012)]](https://bid.ub.edu/sites/bid.ub.edu/files/35/alcala1.jpg)
Figura 1. Clasificación de los diferentes tipos de crowdsourcing [elaboración propia realizada a partir de Estellés-Arolas y González-Ladrón-de-Guevara (2012)]
Los autores distinguen 5 grandes tipologías según el tipo de tarea que se realiza en cada una. En el crowdcasting se hace un llamamiento a resolver un problema ofreciendo una recompensa a quien lo resuelva antes o de la mejor manera posible. Por otra parte, en el crowdcontent la gente aporta su mano de obra y conocimiento para crear contenido. Se subdivide en crowdsearching (búsqueda masiva en internet sobre un tema concreto), crowdanalysing (variación del anterior donde la búsqueda se hace en documentación multimedia) y crowdproduction (creación de contenido de forma individual o colectiva. Los proyectos de transcripción masiva se incluyen aquí). En el crowdfunding se busca financiación mediante pequeñas aportaciones y en el crowdopinion se intenta conocer la opinión de la multitud sobre un tema o un producto nuevo. Finalmente, el crowdcollaboration es idéntico al crowdcontent exceptuando que no hay comunicación entre los individuos ni se ofrece ningún tipo de recompensa. Se subdivide en crowdstorming (lluvia de ideas) y crowdsupport (solución de dudas).
2.1 El voluntariado
Los proyectos de crowdsourcing no se pueden entender sin la figura del voluntariado. Caroline Haythornthwaite (2009) distingue dos patrones diferenciados no sólo en diferentes proyectos sino en el mismo. Los patrones son "multitud"(crowd) y "comunidad" (community). En cuanto a los primeros, comparten experiencias y el sentimiento de pertenencia tiene un plazo más corto o, incluso, sólo se vincula a un proyecto (sin poder esperar nada a posteriori). En cambio, la comunidad comparte valores, experiencias y objetivos a largo plazo; lo que conllevará una llamada mucho más efectiva.
Thomas Knoll (2011) captó las diferencias entre ambos patrones y se muestran en la siguiente tabla (tabla 1).
| Multitud (crowd) | Comunidad (community) |
|---|---|
| Motivación por orgullo | Motivación para fines |
| Se alimentan de la inspiración | Se alimentan de la influencia |
| Buscan beneficios | Buscar pertenecer |
| Necesitan sentirse conectados | Se impulsan a través de la colaboración |
| Necesitan conseguir alguna cosa | Les gusta aportar |
| Se sustentan en el servicio | Les gusta aportar |
Tabla 1. Principales diferencias entre multitud y comunidad según T. Knoll (elaboración propia)
3 Las transcripciones masivas
Tal y como se ha mencionado anteriormente, las transcripciones masivas se engloban dentro de la categoría de crowdcontent o creación de contenido.
Se entiende por transcripción masiva la acción de escribir un texto en otro formato como simple representación del mismo documento o como datos de investigación para ser introducidos en una base de datos. Muchos de los proyectos de transcripciones masivas se crean con el objetivo de generar información descriptiva y textual que pueda servir de punto de acceso rastreables en documentos históricos.
Los proyectos de transcripción masiva se pueden dividir según si se les aplica un reconocimiento óptico de caracteres (OCR), mediante software específico, o si no se les aplica este tipo de software.
En los primeros, el software identifica símbolos o caracteres que conforman un alfabeto determinado y crea un archivo de texto con los datos obtenidos. El voluntario corregirá los errores ortográficos que haya podido ocasionar el mal reconocimiento de los caracteres (símbolos extraños, letras no reconocidas, etc.).

Figura 2. Ejemplo de aplicación OCR con corrección de errores a Proofreaders. Fuente: Lardinois (2008)
En el segundo caso, el voluntario deberá transcribir el documento desde cero, ya que existe todo un abanico de documentos que, en estos momentos, todavía no se pueden someter al OCR como es la documentación manuscrita.
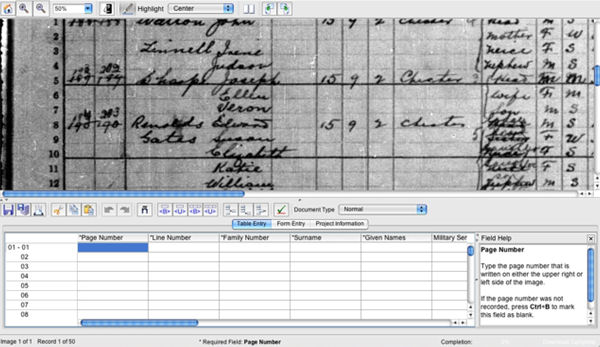
Figura 3. Ejemplo de transcripción desde cero a FamilySearch Indexing
3.1 Workflow en las transcripciones masivas
Muchos de los proyectos de crowdsourcing siguen el mismo workflow o mapa de procesos. Antes de empezar, es necesario que los manuscritos que queremos transcribir estén digitalizados y cargados en el repositorio digital de la institución para que las personas tengan acceso libre a través de la red.
El repositorio digital debe permitir la transcripción de los documentos y por ello, tiene que tener instalada una herramienta de transcripción (que puede ser de software libre o de pago). Esta herramienta permitirá que el voluntario interactúe con las imágenes a transcribir y, una vez éste finalice alguna de las transcripciones propuestas, la propia herramienta exportará ésta transcripción a un formato de archivo fácil de leer por máquina.
Estos metadatos serán validados o no por el personal encargado del proyecto y pasarán a formar parte del repositorio digital, como un elemento más que enriquecerá las búsquedas.
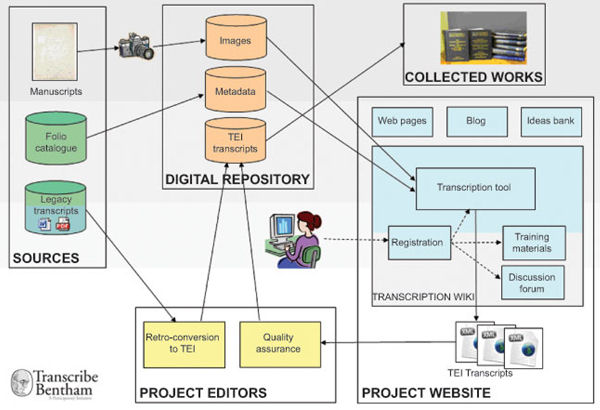
Figura 4. Mapa de los procesos realizados en un proyecto de transcripción masiva. Fuente: Moyle, Tonra y Wallace (2011)
4 Análisis de proyectos de transcripción masiva
En este apartado se muestra el análisis de 20 proyectos de transcripción masiva. Cada uno de los 20 proyectos analizados sigue el mismo esquema: una pequeña introducción al proyecto dónde se destacan ciertos elementos significativos (como podría ser el nombre del proyecto, la institución que lo realiza, entre otros) y, posteriormente, se realiza un análisis en base a diferentes indicadores creados a partir de las pautas propuestas por Codina (2000) y Barrueco et. al. (2014) y otras elaboradas de nuevo teniendo presente la particularidad de los proyectos a analizar.
La elección de estos 20 proyectos se basa principalmente en que se encuentran actualmente en activo y, por lo tanto, permitían testearlos en primera persona. Además, se buscaba que fueran de ámbito internacional y que tratara las transcripciones masivas desde temáticas variadas.
4.1 Proyectos
4.1.1 Distributed Proofreaders
En el año 2000 nace el proyecto Distributed Proofreaders vinculado a la biblioteca digital Project Gutenberg.2/sup>
Mediante una plataforma wiki y a través de una caja blanca (ver figura 5) los voluntarios deben corregir los textos digitalizados que se habían sometido al OCR pero que no habían alcanzado el nivel de calidad deseado.
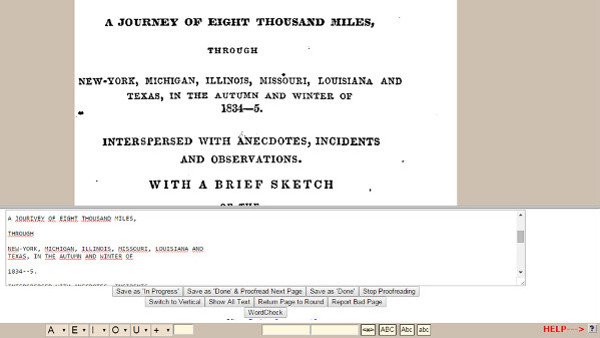
Figura 5. Muestra de la caja blanca para la corrección de textos en Proofreaders
En la pantalla de inicio se muestran los objetivos alcanzados hasta el momento y los que se quiere alcanzar (ver figura 6).

Figura 6. Muestra del progreso de documentos completados, en progreso y que se están procesando en Proofreaders
Otro elemento destacado es que se pone a disposición del voluntarios: unas directrices para corregir los documentos y tutoriales con pruebas de evaluación a realizar antes de iniciar la transcripción (ver figura 7).
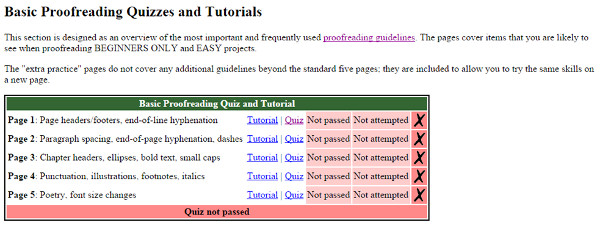
Figura 7. Tutoriales y pruebas de evaluación a Proofreaders
4.1.2 FamilySearch Indexing
En el año 2000 se crea FamilySearch Indexing para transcribir miles de registros genealógicos conservados y digitalizados porThe Genealogical Society of Utah.3 Mediante un software propietario de la institución podemos instalar el paquete de transcripción y empezar a transcribir según proyectos, idioma o nivel de los documentos (ver figura 8).
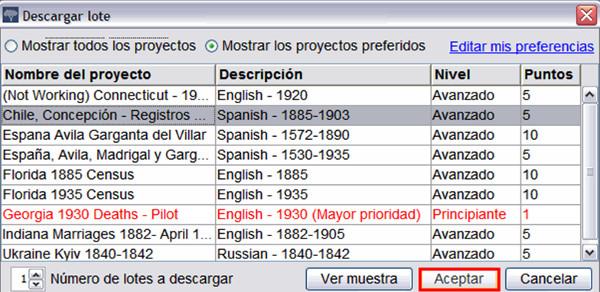
Figura 8. Panel de selección de lotes en FamilySearch Indexing
El tipo de transcripción es bastante guiada y con muchas herramientas de apoyo y formación de usuarios. Una vez transcrito el documento, el programa aplica un pequeño control de calidad en aquellas transcripciones que considera poco claras (ver figura 9).
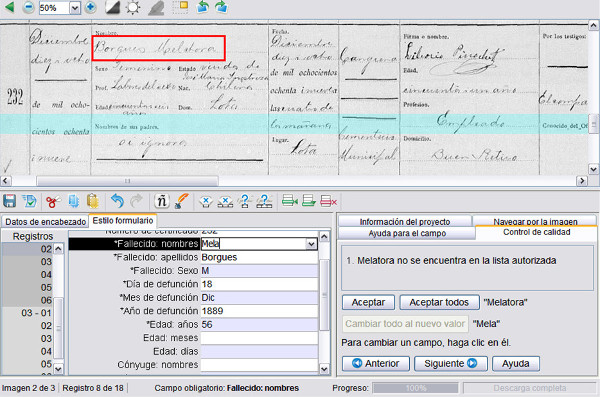
Figura 9. Muestra del control de calidad en FamilySearch Indexing
4.1.3 Australian Newspaper Digitization Program
La National Library of Australia creó en 2008 la plataforma web Trove, con API propia, con la finalidad de corregir las transcripciones resultantes de la aplicación del OCR en la prensa australiana digitalizada desde 1800.
La pantalla principal del proyecto muestra claramente la institución a la cual pertenece, que se puede encontrar y las diferentes maneras de contribuir (ver figura 10).
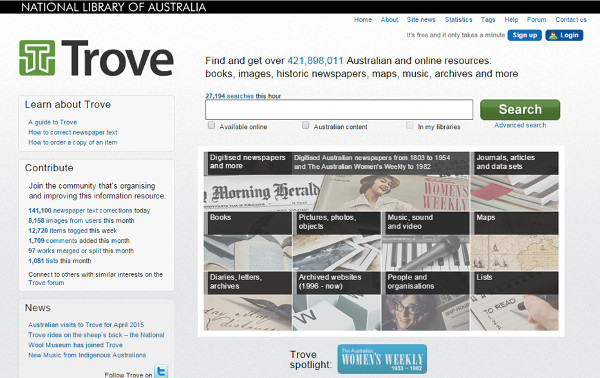
Figura 10. Pantalla principal del proyecto Australian Newspapers Digitalisation Program a Trove
La interfaz de corrección muestra la imagen digitalizada y el texto surgido del OCR. Mediante una caja blanca, el voluntario deberá corregir todos aquellos errores tipográficos que encuentre (ver figura 11).
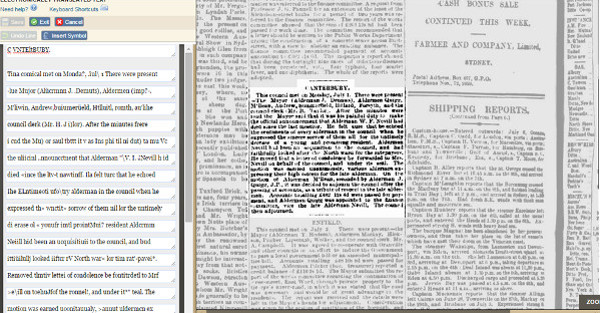
Figura 11. Interfaz de corrección de textos en Australian Newspapers Digitisation Program
4.1.4 Old Weather
Proyecto de digitalización y transcripción de los registros de a bordo de diferentes barcos americanos del siglo xix que fue lanzado en octubre de 2010 dentro de la plataforma Zooniverse.4
En cualquiera de los proyectos de la plataforma Zooniverse, antes de iniciar la transcripción es necesario realizar un pequeño tutorial para familiarizarse con la interfaz, la documentación, el tipo de transcripción, etc.
La transcripción es guiada, ya que nos muestra la página a transcribir y nos abre un cuadro de diálogo con los diferentes campos a transcribir (ver figura 12).
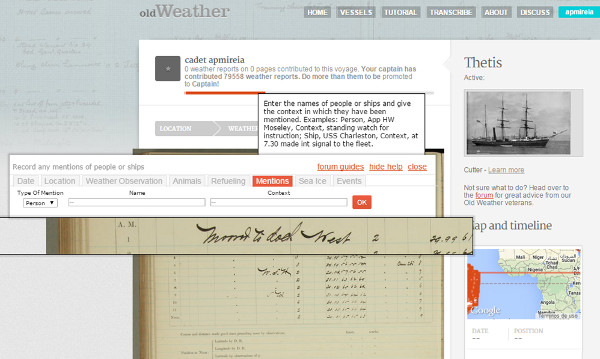
Figura 12. Muestra de la transcripción guiada en Old Weather
El registro del voluntario es obligatorio y esto permite consultar historiales de transcripción, suscribirse a newsletters, comentar en los foros del proyecto y que se otorguen categorías en función de la actividad de cada voluntario (ver figura 13).
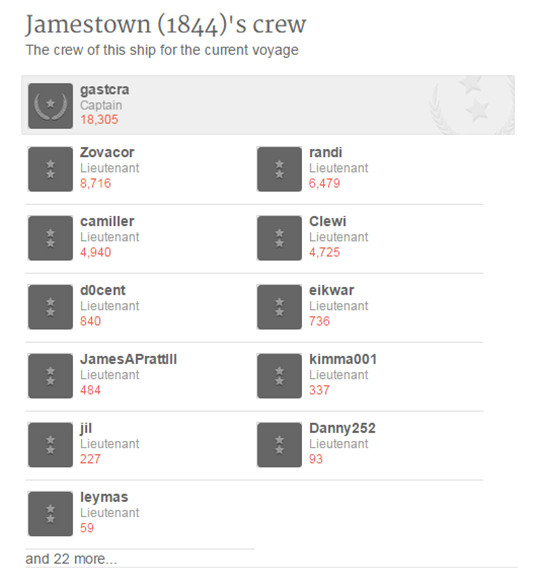
Figura 13. Muestra de las diferentes categorías según los documentos transcritos en Old Weather
4.1.5 Citizen Archivist Dashboard
Los National Archives and Records Administration (NARA) de EEUU crearon en 2011 una plataforma web, con una API propia, llamada Citizen Archivist Dashboard donde reunían diferentes proyectos de crowdsourcing. Los voluntarios podían etiquetar, transcribir o escribir nuevos artículos (ver figura 14).
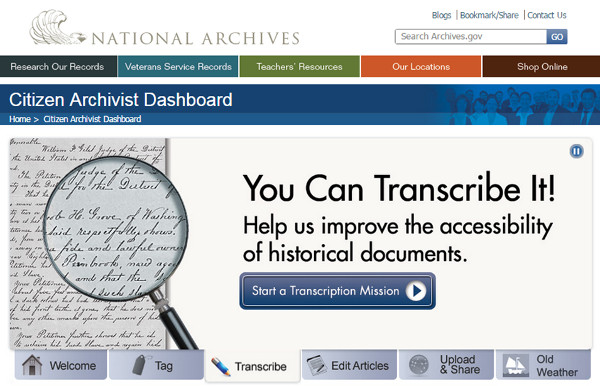
Figura 14. Slider de Citizen Archivist Dashboard con las diferentes acciones a realizar
4.1.6 What 's the Score at the Bodleian?
En 2011 la Bodleian Library and Radcliffe Camera de la University of Oxford creó este proyecto englobado en la plataforma Zooniverse. El objetivo era transcribir más de 4.000 partituras digitalizadas provenientes desde 1860.
El tipo de interfaz y de transcripción sigue el mismo patrón que todos los proyectos de Zooniverse. Como elemento destacado, en la pantalla principal, encontramos un elemento significativo como es la barra de progreso del proyecto (ver figura 15).

Figura 15. Pantalla de inicio del proyecto What's the Score at the Bodleian?
4.1.7 What's on the Menu?
A finales de abril de 2011 la New York Public Library (NYPL) pone en marcha el proyecto What's on the Menu? para transcribir platos, precios y geoetiquetar locales de más de 45.000 cartas de menús provenientes desde el 1840 hasta la actualidad (véase figura 16).
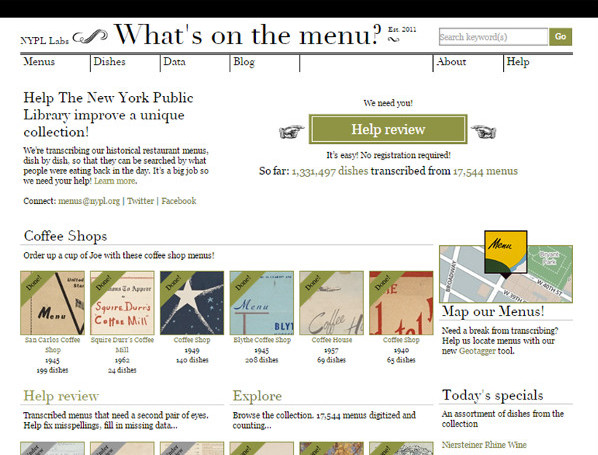
Figura 16. Pantalla de inicio de What's on the Menu? de la NYPL
El tipo de transcripción es parcialmente guiada, ya que ofrece una caja blanca para transcribir el texto pero también permite añadir el precio en otro campo (ver figura 17).
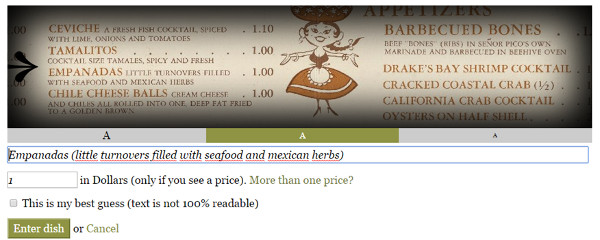
Figura 17. Muestra de la transcripción en What's on the Menu? de la NYPL
Destaca en este proyecto la sección "Today's specials" donde diariamente se hace una selección de recetas transcritas para compartirlas en las redes sociales.

Figura 18. Muestra de comunicación a través de redes sociales de los platos transcritos a What's on the Menu?
4.1.8 Transcribe Bentham
La University Collage of London con otras instituciones creó en 2010 este proyecto para transcribir los documentos manuscritos Jeremy Bentham, filósofo y político inglés.
La plataforma de acceso al proyecto se realiza mediante una wiki y se denomina Transcripción Desk. Aparte de la barra de progreso también encontramos el Benthamometer, que muestra las diferentes fases que se quieren alcanzar a nivel de escaneo, subida a la plataforma y de transcripción (ver figura 19).
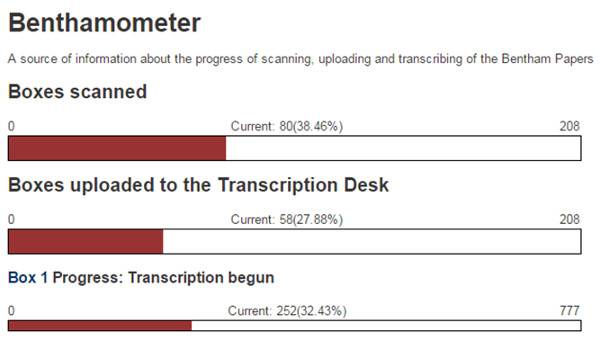
Figura 19. Muestra del Benthamometer sobre el estado del proyecto
En este proyecto los voluntarios van sumando puntos en función de las tareas realizadas y, de esta manera, van subiendo en el ranking de transcriptores (ver figura 20).
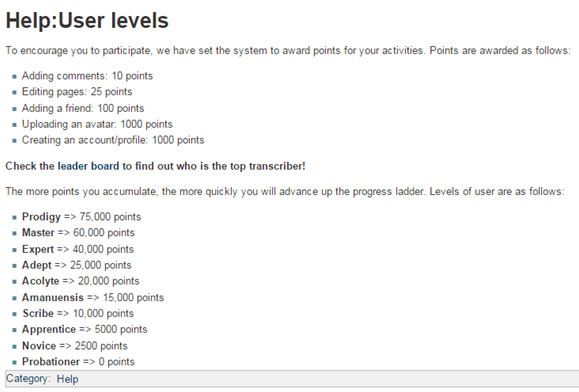
Figura 20. Puntos asociados a tareas a Transcribe Bentham
Otro de los puntos fuertes de este proyecto es la iniciativa de aprendizaje educativo asociado; es decir, los estudiantes, de diferentes niveles de edad, pueden aprender mediante la búsqueda en los manuscritos históricos originales (ver figura 21).

Figura 21. Página donde se muestra como estudiantes participan en el proyecto Transcribe Bentham
4.1.9 DIY History
DIY History surge de la ampliación del proyecto inicial de las University of Iowa Libraries que pretendían transcribir los diarios de guerra para la conmemoración del 150 aniversario de la Guerra Civil americana.
La plataforma ha sido creada con el software libre Omeka y engloba múltiples colecciones a transcribir. De este modo, es necesario mostrar de manera gráfica el progreso del proceso y podemos ver una barra de la colección y, a la vez, también de cada documento (ver figura 22).
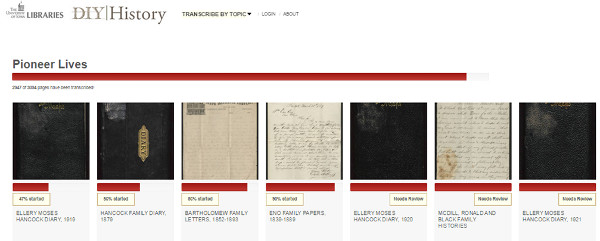
Figura 22. Barra de progreso de la colección y de los documentos en particular a DIY History
4.1.10 Ancient Lives
Ancient Lives forma parte de Zooniverse y tiene como objetivo la transcripción de miles de papiros griegos.
Debido a las propias características de dichos documentos, este proyecto tiene unas directrices y guías de transcripción y uso de la plataforma muy desarrolladas (ver figura 23).
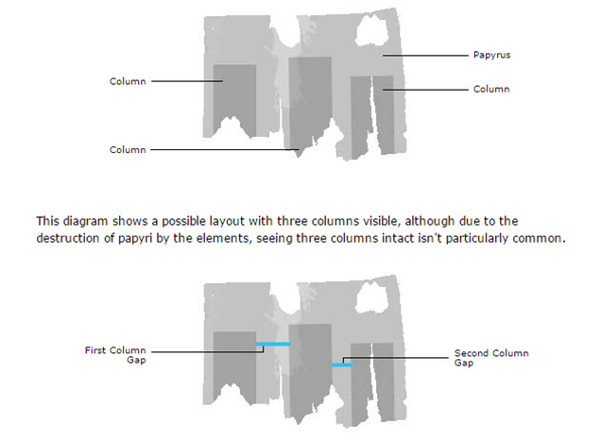
Figura 23. Muestra de cómo tomar las medidas en los papiros Ancient Lives
Del mismo modo, el tipo de transcripción es particular. Se muestra el papiro a transcribir y también un teclado con los diferentes caracteres para seleccionar directamente (ver figura 24).
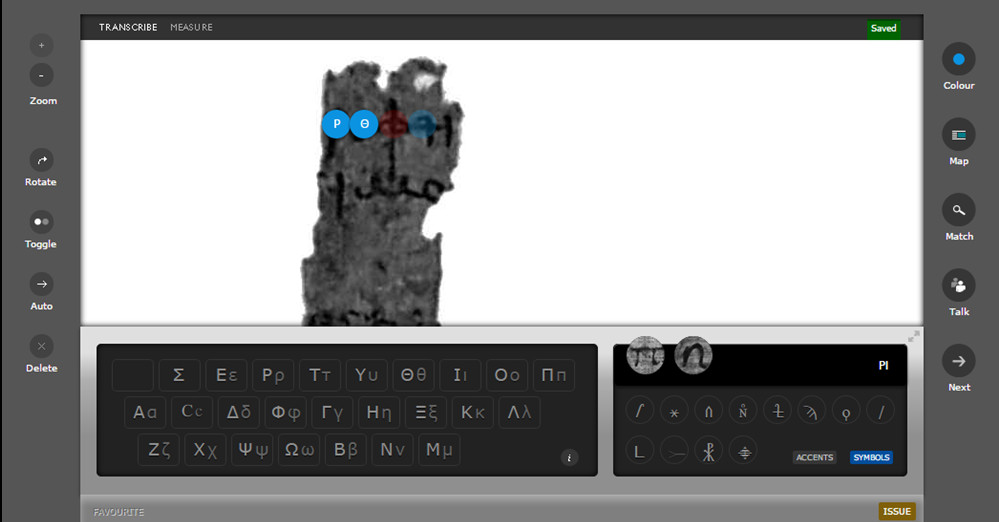
Figura 24. Muestra de la transcripción que se utiliza en Ancient Lives
También destaca la sección "Talk". Se trata de una especie de foro donde los diferentes voluntarios pueden compartir sus experiencias, pedir consejo, ayudar a otros, etc. (ver figura 25).
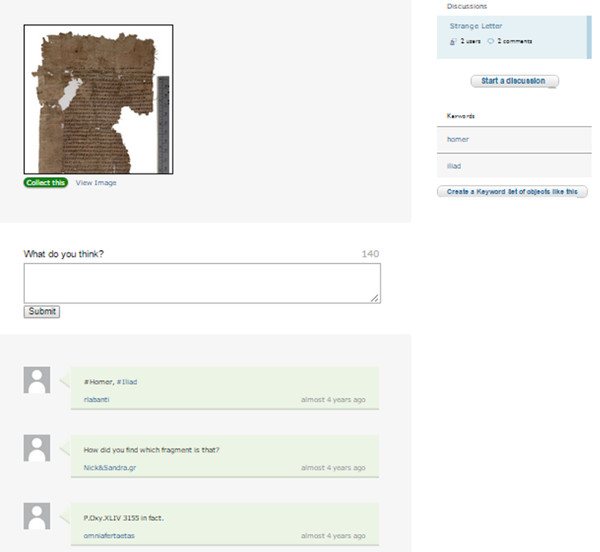
Figura 25. Muestra del foro "Talk" en Ancient Lives
4.1.11 Genealogy Vertical File Transcripción Project
Iniciativa surgida dentro del proyecto de North Carolina Family Records Online de la State Library and State Archives of North Carolina (EE.UU.) que pretendía poner a disposición del público diferentes materiales conservados en esta institución.
La particularidad de este proyecto es que usa la red social Flickr. Esta plataforma muestra las imágenes a transcribir y los voluntarios sólo deben añadir un comentario con el texto transcrito (ver figura 26).
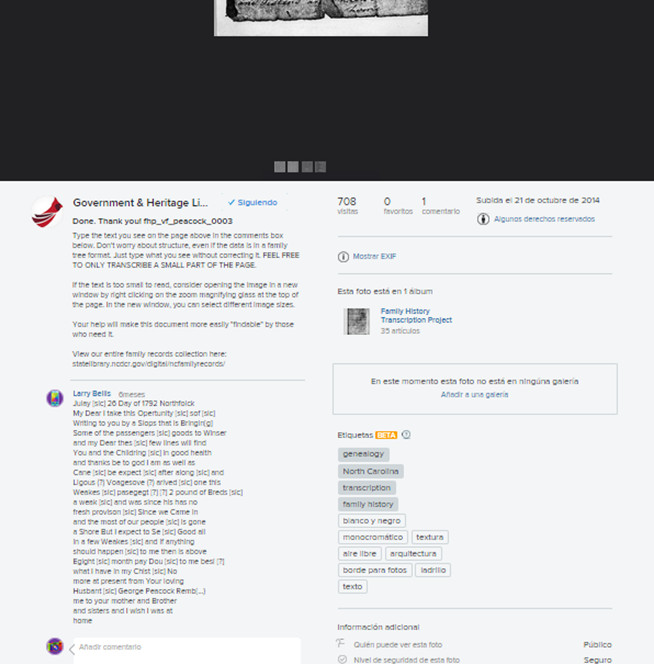
Figura 26. Muestra de la red social Flickr y las transcripciones mediante comentarios en Genealogy Vertical File Transcripción Project
4.1.12 Edvuard Munch s Writings
El Munch Museum’s project se creó en 2011 y quería poner a disposición del público unas 13.000 páginas correspondientes a documentación manuscrita que se conserva del pintor.
Se trata de un proyecto con muchas similitudes con el de Transcribe Bentham, ya que recibieron apoyo de este último.
Un elemento muy potenciado es el apartado de comunicaciones: tanto entre los administradores y los voluntarios, las redes sociales, los foros, etc. (ver figura 27).

Figura 27. Muestra de los diferentes canales de comunicación a Edvard Munch’s Writings
4.1.13 Transcribe ScotlandPlaces
En el año 2012 se lanzó Transcribe ScoltlandPlaces, un portal web que tenía como objetivo transcribir información de más de 150.000 páginas de documentación histórica, fechada entre 1645 y 1880, para identificar los sitios actuales y también localizar personajes de la historia de Escocia.
El voluntario debe registrarse y seleccionar las diferentes colecciones en las que quiere participar. Una vez transcurrido un período de 72 horas, los administradores dan acceso a la transcripción (ver figura 28). De esta manera se quiere conseguir un mayor control pero puede suponer una pérdida de voluntarios.
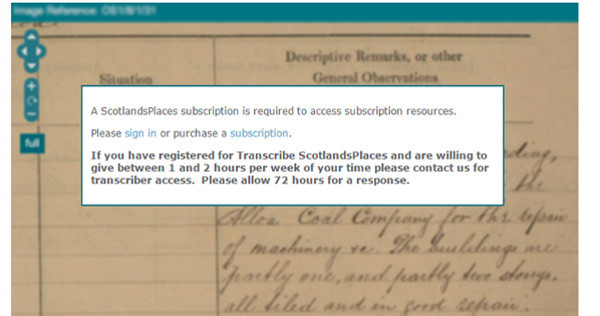
Figura 28. Muestra del mensaje de espera de 72 horas para empezar a transcribir
Sobresale el hecho de que se han realizado más de 50 charlas y talleres en toda Escocia para promover la participación de la gente.
4.1.14 The arcHive
Los National Archives of Australia dentro del proyecto National Archives 'labs environament5 creó una plataforma web llamada The archive, que tiene la finalidad de que los voluntarios les ayuden a hacer sus registros más accesibles.
Siguiendo el mismo esquema que en Trove —citado anteriormente—, se muestra una caja blanca para transcribir los documentos una vez se les ha aplicado el OCR.
La búsqueda y el filtrado documental tienen muchas posibilidades, ya que permite seleccionar la dificultad, el estado de progreso del documento o la colección a transcribir (ver figura 29).
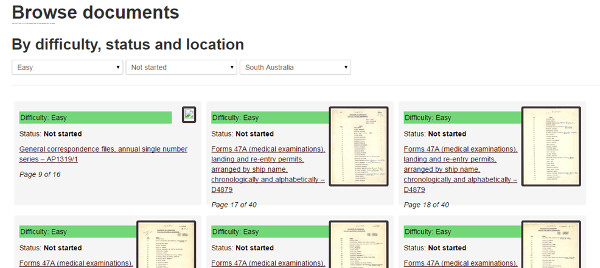
Figura 29. Muestra de las diferentes posibilidades de búsqueda en The arcHive
El registro del usuario es voluntario, aunque el hecho de registrarse conlleva que queden inventariadas las tareas realizadas y sumen puntos, tanto para el ranking de transcriptores como para poder intercambiarlo por una recompensa (ver figura 30).
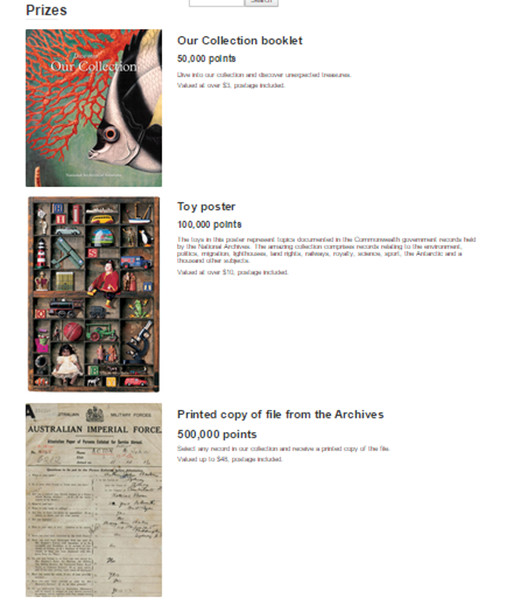
Figura 30. Recompensas en The arcHive
4.1.15 Smithsonian Digital Volunteer: Transcripción Center
En julio de 2013 se puso en marcha el Transcripción Center del Smithsonian Digital Volunteer. El proyecto quería transcribir miles de documentos provenientes de aproximadamente unas 30 colecciones de diferentes museos, archivos y bibliotecas de la Smithsonian Institution.6
Para seleccionar el documento a transcribir, se nos muestra una codificación de colores (verde, amarillo y rojo) en función del estado del documento y de la tarea que desee realizar el voluntario (ver figura 31).
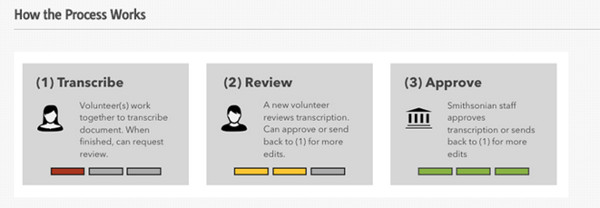
Figura 31. Estado del progreso del documento a Smithsonian
4.1.16 Ensemble
La New York Public Public Library for the Performing Arts inició en 2013 este proyecto para transcribir los diferentes elementos (nombre del teatro, la ubicación, el título, los personajes, etc.) que aparecen en los programas de teatro, danza o conciertos.
De este proyecto destaca el tipo de transcripción guiada, ya que con el documento a transcribir en pantalla, hay que seleccionar los diferentes elementos a transcribir y, una vez seleccionado, es necesario que indiquemos el campo que debería llenarse (ver figura 32 ). Además, una vez seleccionado el campo se nos ofrecen un listado de autoridades para un mayor control de la calidad.
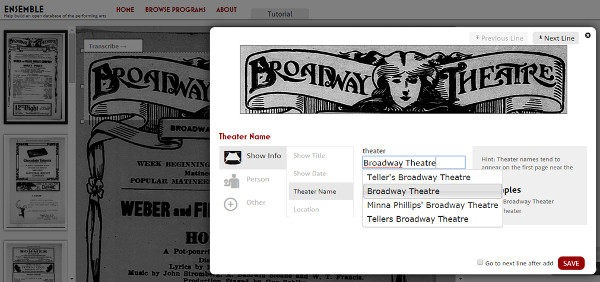
Figura 32. Muestra de transcripción guiada Ensemble
4.1.17 Transcriu-me!!
El año 2013 la Biblioteca de Cataluña con el Consorcio de Servicios Universitarios de Cataluña impulsan el proyecto Transcriu-me!! para mejorar el acceso a su documentación. Más adelante, de otras instituciones como Filmoteca de Cataluña o la Universidad de Barcelona también se suman al proyecto.
La transcripción se realiza mediante una caja blanca y se muestran las normas de descripción en la misma pantalla (ver figura 33).

Figura 33. Muestra de la tipología de transcripción y las directrices a Transcriu-me!!
4.1.18 Letters of 1916
Proyecto iniciado en 2013 por diferentes instituciones de Irlanda para recopilar y transcribir cartas provenientes de la época del Easter Rising.7
Los documentos a transcribir se muestran en diferentes colecciones según temáticas, sin determinar el porcentaje de documentos transcritos o la dificultad de nivel (ver figura 34).

Figura 34. Muestra de las diferentes colecciones en Letters of 1916
4.1.19 MicroPasts: Crowdsourcing
En octubre de 2013 nació el proyecto MicroPasts de la mano de la British Library, University College of London y el Arts and Research Council. A través de una plataforma libre y de código abierto (Pybossa) se quería recoger masivamente datos de calidad de diferentes temáticas como la arqueología, la historia o el patrimonio.
El tipo de transcripción es guiada, ya que hay que transcribir el documento mediante diferentes campos, se puede ver la imagen a mayor resolución mediante Flickr y permite geolocalizar las obras a través de un mapa de Google (ver figura 35).
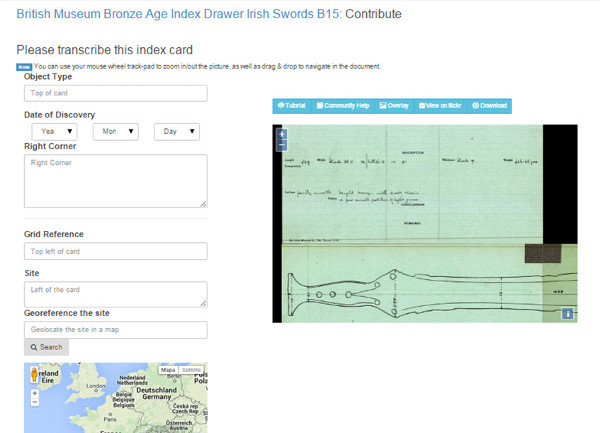
Figura 35. Muestra de la transcripción guiada de MicroPasts
4.1.20 Cynefin: Mapping Wales 'sin of Place
En 2014 se puso en marcha este proyecto para recoger información relevante de la localización de las ballenas en el Reino Unido.
Para seleccionar un documento, aparece un mapa y el voluntario puede escoger la zona del país donde quiere transcribir y geolocalizar los documentos (ver figura 36).
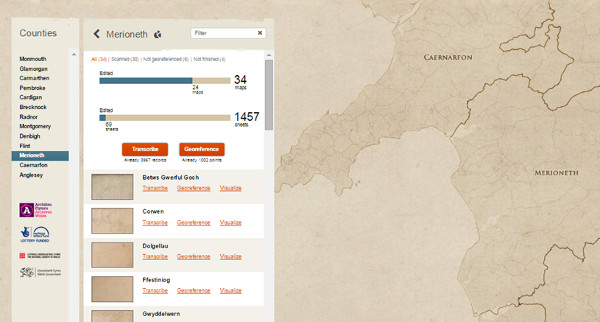
Figura 36. Muestra de los documentos a transcribir dentro de una colección en Cynefin
Destacar el hecho de que para agilizar el proceso de registro, el voluntario puede utilizar cualquiera de las principales redes sociales (ver figura 37).
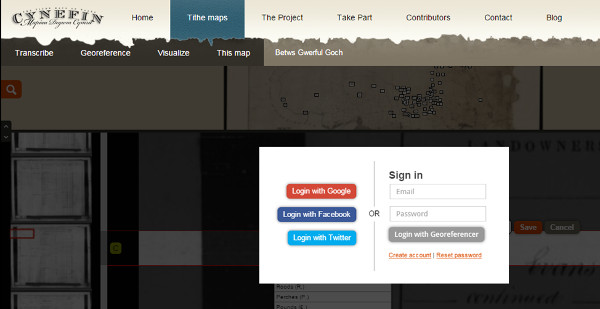
Figura 37. Muestra de la variedad de maneras de registrarse en Cynefin
1.4.21 Cuadro resumen
A continuación se muestra un cuadro resumen de los diferentes proyectos con la puntuación resultante para cada indicador.
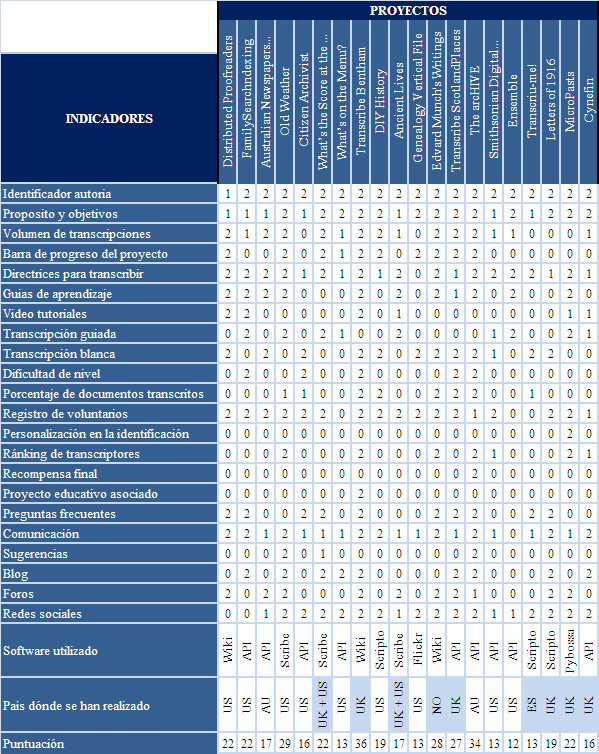
Tabla 2. Cuadro resumen de los diferentes proyectos analizados
En resumen, podemos comprobar como hay ciertos indicadores que se cumplen en casi todos los proyectos, como son: la identificación de la autoría que realiza el proyecto, así como los objetivos que se quieren conseguir. También el hecho de incluir en el proyecto las directrices de cómo transcribir y pedir a los voluntarios un registro para participar en el proceso. Finalmente, el uso de las redes sociales es básico para dar a conocer y hacer extensivo el proyecto.
Por otra parte, hay tres grandes grupos diferenciados en función del grado de cumplimiento de los indicadores estudiados. Teniendo presente que el máximo de puntuación que podía alcanzar cada proyecto era de 44 puntos, en la posición más alta, y con una puntuación de 36 y 34, respectivamente, encontramos a Transcribe Bentham y The arcHive. Posteriormente, en un escalón por debajo encontramos: Old Weather (con 29 puntos), Edvard Munch’s Writing (con 28 puntos) y Transcribe ScotlandPlaces (con 27 puntos). Y, finalmente, el resto de proyectos obtienen una puntuación igual o menor a 22 puntos.
Por tanto, podemos concluir que se están llevando a cabo muchos proyectos de transcripción masiva a nivel internacional, pero sólo unos pocos son la punta de lanza de este tipo de iniciativas.
5 Buenas prácticas en proyectos de transcripción masivas
Teniendo presente el cuadro resumen de los diferentes proyectos analizados, podemos determinar un conjunto de buenas prácticas que se deben contemplar en el diseño de un proyecto de transcripciones masivas.
- Descripción del proyecto, cómo se origina, a qué institución pertenece y que pretende conseguir. Fijar toda esta información aporta seguridad al voluntario y le permite tener una idea clara del que puede suponer su aportación.
- Muestra de una barra de progreso del proceso. Es un elemento que técnicamente no supone ningún tipo de complicación ni esfuerzo a la institución y puede ayudar a un voluntario dubitativo a determinar el participar o no en función de cuál sea el estado del proceso. Esta barra de progreso puede subdividirse en diferentes si el proyecto incluye diferentes colecciones.
- Fijación de directrices de transcripción y utilización de guías de aprendizaje y videotutoriales para adaptarse al entorno. Fiar unas directrices de transcripción, mostrándose de manera fácil a la hora de transcribir, puede ayudar al voluntario a resolver dudas en sus aportaciones. De todos modos, revisar una guía de aprendizaje o un vídeotutorial siempre es más agradecido que no tener que leer hojas textuales dónde se explicita como transcribir los documentos.
- Utilización fácil y sencilla de la herramienta para transcribir. Apostar por una interfaz sencilla hará que no haya fractura digital para el usuario principiante y permitirá una oportunidad de acceso a todo el mundo por igual.
- Apuesta por la transcripción guiada y determinar el nivel de dificultad de cada documento. Se debe apostar por la transcripción guiada en vez de la caja blanca ya que ayuda al voluntario a realizar la tarea más rápidamente y de manera más correcta. Además, la clasificación de los documentos en función del nivel de dificultad permitirá a los principiantes a empezar a transcribir aquellos documentos más adaptados a su nivel.
- Identificación del voluntario para personalizar el entorno. Aparte de la personalización, como las transcripciones quedan registradas puede ver su evolución y le permite mantener cierto compromiso con el proyecto.
- Creación de ránkings de participación y ofrecer una recompensa final. Se trata de fidelizar a los voluntarios y premiar su dedicación en la transcripción de documentos.
- Vinculación de las transcripciones a proyectos educativos. Se debe vincular este tipo de proyectos a otros de tipo más educativo para hacer entender la historia y el patrimonio de una manera más experimental.
- Uso de las redes sociales, los foros y los blogs para mantener la comunicación con los voluntarios. Es un elemento básico para fidelizar los usuarios, y a la vez, que estos pueden difundir aquello que van realizado. Esto puede ayudar a atraer otros nuevos usuarios.
Bibliografía
Barrueco Cruz, J. et al. (2014). Guía para la evaluación de repositorios institucionales de investigación [en línia]. 2a ed. Recolecta, FECYT–CRUE–REBIUN <http://recolecta.fecyt.es/sites/default/files/contenido/documentos/GuiaEvaluacionRecolecta_v.ok_0.pdf>. [Consulta: 21 maig 2015].
Berners-Lee, T.; Fischetti, M. (2000). Tejiendo la red: el inventor del world wide web nos descubre su origen. Madrid: Siglo XXI de España editores. ISBN 8432310409.
Codina, L. (2000). Evaluación de recursos digitales en línea: conceptos, indicadores y métodos. Revista española de documentación científica [en línia]. <http://redc.revistas.csic.es/index.php/redc/article/viewFile/315/479>. [Consulta: 5 maig 2015].
Estellés-Arolas, E.; González-Ladrón-de-Guevara, F. (2012). "Towards an integrated crowdsourcing definition". Journal of Information Science, vol. 38, no. 2, p. 189–200. <http://www.crowdsourcing-blog.org/wp-content/uploads/2012/02/Towards-an-integrated-crowdsourcing-definition-Estell%C3%A9s-Gonz%C3%A1lez.pdf>. [Consulta: 10 gener 2015].
Haythornthwaite, C. (2009). "Crowds and communities: Light and heavyweight models of peer production". System Sciences, 2009. HICSS'09. 42nd Hawaii International Conference on. IEEE. p. 1–10.
Howe, J. (2006). "The Rise of Crowdsourcing". Wired magazine, no. 14.06. <http://archive.wired.com/wired/archive/14.06/crowds.html>. [Consulta: 10 gener 2015].
Knoll, T. (2011). "Are Your Customers a Crowd or a Community? ". SXSW Interactive 2011. <http://lanyrd.com/2011/sxsw/scqyt/>. [Consulta: 23 maig 2015].
Lévy, P. (1997). Collective intelligence: Mankind's Emerging World in Cyberspace. New York and London: Plenum Press. ISBN 978-0-306-45635-0.
Rheingold, H. (2003). Smart mobs. De Boeck Supérieur, vol. 1, p. 75–87. ISSN 0765-3697. <http://www.cairn.info/resume.php?ID_ARTICLE=SOC_079_0075>. [Consulta: 5 maig 2015].
TERMCAT (2012). Crowdsourcing en català [en línia]. Generalitat de Catalunya. Departament de Cultura <http://www.termcat.cat/ca/Comentaris_Terminologics/Finestra_Neologica/142/>. [Consulta: 30 maig 2015].
Notas
* Este artículo tiene como origen un Trabajo Final de Grado de Información y Documentación de la Facultad de Biblioteconomía y Documentación de la Universidad de Barcelona, defendido en julio de 2015 bajo la tutorización de Ciro Llueca i Fonollosa.
1 Directrius per a projectes de digitalització de col·leccions i fons de domini públic, en especial els de biblioteques i arxius (2006) [en línea]. Barcelona: Col·legi Oficial de Bibliotecaris-Documentalistes de Catalunya. ISBN 8486972221. <http://www.cobdc.org/publica/directrius/sumaris.html>. [Consulta: 20 mayo 2015].
2 Institución sin ánimo de lucro fundada en 1971 por Michal S. Hart. Su objetivo era crear la biblioteca digital con textos completos de dominio público más grande del mundo y se mantiene mediante el esfuerzo de los voluntarios y el micromecenazgo.
3 Sociedad vinculada a la Iglesia de Jesucristo de los Santos de los Últimos Días, conocida como la Iglesia Mormona.
4 Zooniverse es un portal web de ciencia ciudadana creado y mantenido por Citizen Science Alliance. Los diferentes partners de esta alianza son: Adler Planetarium (EUA), Johns Hopkins University (EUA), University of Minnesota (EUA), National Maritime Museum (UK), University of Nottingham (UK), Oxford University (UK) y Vizzuality. El objetivo principal es crear proyectos de crowdsourcing que puedan promover una investigación científica a posteriori, en diferentes disciplinas como: la astronomía, la ecología, la biología celular, las humanidades o la climatología. El proyecto original fue Galaxy Zoo dónde los voluntarios clasificaban galaxias según sus características. Según datos de 2014, la comunidad de Zooniverse ya había superado el millón de usuarios registrados y había promovido más de 70 artículos científicos.
5 Laboratorio de entornos referentes en el National Archives of Australia. Para mejorar el acceso a la colección crean diferentes prototipos que pueden llegar a desarrollar servicios o pueden quedarse en el estado de prueba piloto.
6 Institución financiada por el Gobierno de los EUA que tiene como objetivo aumentar y difundir el conocimiento. Está conformada por 19 museos de diferentes ámbitos (artísticos, zoológicos o históricos, entre otros) y diferentes centros de investigación (archivos, institutos de investigación o bibliotecas).
7 Easter Rising, també conocida como la Rebelión de Pascua, fue un alzamiento del consejo militar de la Irish Republican Brotherhood (republicanos de Irlanda) durante la Pascua de 1916 para poner fin a la dominación británica y separarse del Reino Unido.
 licencia de Creative Commons de tipo "
licencia de Creative Commons de tipo "