
Silvana Temesio
Profesora del Instituto de Información
Facultad de Información y Comunicación
Universidad de la República de Uruguay
Resumen
Objetivo: analizar los metadatos de datos abiertos en boga desde la perspectiva de su adecuación a los objetivos de recuperación y uso.
Metodología: se plantea la extensión de Data Catalog Vocabulary (DCAT) a una nueva clase que modele el nivel del dato y su semántica. La extensión se analiza en un caso de datos abiertos específico para un proceso de convenios de caminería rural en Uruguay.
Resultados: el desarrollo se implementa en la publicación de un conjunto de datos abiertos en el marco de descripción de recursos (RDF) en el portal de datos abiertos de Uruguay que ejemplifica la utilidad.
Resum
Objectiu: analitzar les metadades de dades obertes en voga des de la perspectiva de la seva adequació als objectius de recuperació i ús.
Metodologia: es planteja l’extensió de Data Catalog Vocabulary (DCAT) a una nova classe que modeli el nivell de la dada i la seva semàntica. L’extensió s’analitza en un cas de dades obertes específic per a un procés de convenis de camineria rural a l’Uruguai.
Resultats: el desenvolupament s’implementa en la publicació d’un conjunt de dades obertes en el marc de descripció de recursos (RDF) al portal de dades obertes de l’Uruguai que n’exemplifica la utilitat.
Abstract
This paper analyses metadata for the growing trend in open data, from the perspective of whether they meet the objectives of data recovery and use. We propose an extension of the Data Catalog Vocabulary (DCAT) to a new class that would model the level of the data and its semantics. The extension is analyzed in the case of specific open data for a process of agreements on rural road networks in Uruguay. The utility of the development is illustrated by its implementation in a set of open data in resource description framework (RDF), published on Uruguay’s open data portal.
1 Introducción
Las aplicaciones informáticas en una organización gubernamental son las principales encargadas de gestionar los datos crudos. Los datos crudos son datos fuente o primarios recopilados en los procesos de la organización y en sus actividades. Estos datos son en general atómicos, no están agrupados. De acuerdo con la diversidad de procedimientos que los involucran, son de dominios variados: texto, numéricos, imágenes, geográficos, etc. y se presentan en formatos diferentes. Si bien se puede usar el término crudos para datos no validados provenientes de dispositivos de recogida de datos electrónicos, en este documento se utiliza el término en el sentido de datos primarios y atómicos.
Estos datos crudos de las instituciones públicas normalmente se almacenan en bases de datos, separados en esquemas y a los que se accede de acuerdo con un sistema de permisos, roles y privilegios por distintas aplicaciones. El principio de las bases de datos relacionales de modelar los datos sin redundancia opera de modo que cada categoría de datos tiene un esquema en el que existe un responsable de la actualización del dato que proporciona derechos de lectura a todos los que lo usan. De este modo se utilizan los datos dentro de la organización, un escritor responsable del dato o varios responsables de distintas facetas del dato y muchos lectores consumidores de este. Una práctica recomendable es que haya consumidores de datos que accedan por medio de un servicio web, una prestación especial que ofrece los datos que van a ser utilizados en otras aplicaciones informáticas, de esta manera se modela el acoplamiento de forma sencilla.
Las aplicaciones informáticas que utilizan bases de datos no son las únicas que gestionan datos crudos, pero sí son las que lo hacen de forma sistemática y global con trazabilidad y seguridad. Son las que normalmente registran las actividades que se realizan dentro de la organización y, en ese sentido, son una fuente de información auditable de las tareas y los procedimientos que lleva a cabo una institución por medio de sus datos (Temesio, 2013).
La costumbre de trabajar los datos de forma aislada, sin conexión con otras actividades relacionadas, solapando acciones, sin alimentar un repositorio global de datos —la base de datos— es una costumbre que, si bien todavía persiste en algunas tareas, está siendo cada vez más desterrada como modalidad de trabajo en los organismos públicos con el advenimiento de las buenas prácticas del gobierno electrónico.
Dentro de los organismos públicos, de acuerdo con la ley de acceso a la información pública —que tiene diversas expresiones muy similares en Iberoamérica, en este caso se referencia a la ley de Uruguay—, se tiene que establecer si la información es pública o no.1 Si la información es pública, podrá publicarse como dato abierto; en caso contrario, estará accesible para las personas que se designen por el dueño de los datos —normalmente quien ocupe un puesto de alto nivel jerárquico— con el fin de realizar tareas específicas.
Publicar los datos abiertos persigue los fines del gobierno electrónico de dar acceso a quien pueda y quiera reutilizar los datos, realizar aplicaciones que sean de interés y transparentar la administración (OECD, 2014).
Para lograr estos fines, el dato tiene que llegar a quien lo busca, de modo que el descubrimiento y la búsqueda tienen que ser operaciones claras, sencillas y comprensibles. En este sentido puede pensarse en los datos abiertos con un abordaje desde las ciencias de la información. Un dataset de datos abiertos, o conjunto de datos abiertos, es un paquete de información que requiere explicitarse y puede ser catalogado con un estándar de metadatos general como lo es Dublin Core. De esta manera el conjunto de datos provee información sobre sí mismo, sobre su origen, sobre los aspectos administrativos y su contenido. El conjunto de datos es un objeto digital que puede asimilarse a un libro y por tanto los metadatos aportados tienen una analogía con la descripción bibliográfica. Podría señalarse otra analogía con la archivología viendo el dato como una pieza documental simple o compuesta y su registro como una descripción archivística. Este símil, aunque forzado, sirve para apoyar la idea de que este tipo de objeto digital, al igual que en los ejemplos, cumple con las necesidades de cualquier recurso de información que se gestione por los profesionales de la información: ser buscado y encontrado de acuerdo con criterios de descripción que permitan rápidamente identificar si cumple con las necesidades de la búsqueda.
La calidad en los datos abiertos, tanto en su contenido como en su descripción, contribuye a potenciar el principio de transparencia, pues facilita una participación ciudadana por medio de criterios de relevancia, usabilidad y calidad. La usabilidad de los datos abiertos se expresa en la capacidad de estos de autoexplicarse. Cuanto más detalladamente se describan, mayor es la probabilidad de ser descubiertos, analizados y reusados, ya sea en aplicaciones que brinden un servicio que no sea prestado por el gobierno, en el análisis de investigaciones periodísticas o como insumo para la decisión de llevar a cabo una intervención tanto desde el ámbito del gobierno como de la sociedad civil o de las empresas.
2 Metadatos en datos abiertos
Se realizó una investigación de las normas usadas en la descripción de datos y experiencias en la región. Se revisaron los siguientes portales de datos abiertos:
- Uruguay <http://datos.gub.uy/>
- Chile <http://datos.gob.cl/>
- España <http://datos.gob.es/>, <https://www.zaragoza.es/ciudad/risp/>
- Colombia <http://datosabiertoscolombia.cloudapp.net/frm/buscador/frmBuscador.aspx>
- Argentina <http://datospublicos.gov.ar/>
- Brasil <http://dados.gov.br/>
- Perú <http://lima.datosabiertos.pe/home/>
CKAN es una aplicación de software libre muy usada en los portales de datos abiertos en América Latina. Permite la ingesta de colecciones de datos y sus metadatos por medio del permiso y rol específico, luego expone estos conjuntos de datos y permite su búsqueda a través de los metadatos. Si la búsqueda arroja resultados de interés, entonces el usuario tiene la posibilidad de descargar el conjunto de datos. En cierto sentido es una aplicación del tipo repositorio, pero aquí lo que se ingresa son conjuntos de datos en vez de recursos digitales.
CKAN trabaja con una serie de metadatos, algunos obligatorios y otros opcionales: título descriptivo, frecuencia de actualización, cobertura espacial, sistema de referencia usado, cobertura temporal, descripción de los datos, etiquetas, licencia, organismo, visibilidad, y además información adicional, como el responsable de los datos y el responsable de la actualización en el catálogo de acuerdo con la frecuencia señalada.
Existe una propuesta de metadatos específicos, Data Catalog Vocabulary (DCAT), que tiene su origen en una iniciativa de normalización del World Wide Web Consortium (W3C) y que ha tomado en cuenta otros conjuntos de metadatos relacionados estableciendo la necesidad del uso de taxonomías para los ítems que puedan normalizarse. DCAT tiene un nivel de descripción a nivel de portal y otro nivel a nivel del conjunto de datos.
DCAT, de acuerdo con su especificación (DCAT, 2014), «es un vocabulario RDF diseñado para facilitar la interoperabilidad entre catálogos de datos publicados en la web».
El propósito expuesto es que al describir conjuntos de datos con DCAT se facilite el descubrimiento y la facilidad de uso de las aplicaciones en el consumo de datos de múlztiples catálogos.
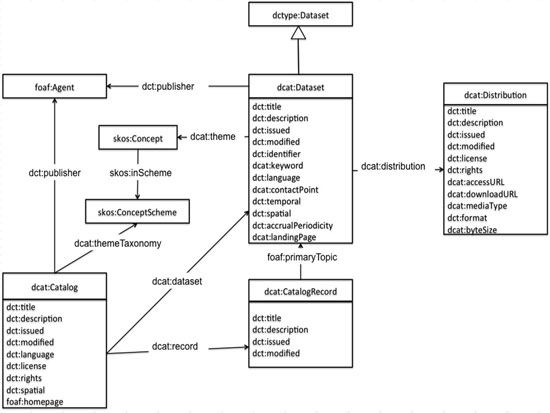
Figura 1: Diagrama UML de la especificación DCAT
Tenemos las siguientes clases:
- Catálogo («dcat:CatalogRecord»)
- Conjunto de datos («dcat:Dataset»)
- Distribución («dcat:Distribution»)
El conjunto de datos puede estar en varios formatos o estar disponible por medio de una aplicación web (API), en cuyo caso la aplicación sería una instancia de «dcat:Distribution».
El catálogo tiene múltiples conjuntos de datos y cada uno de ellos es una entrada en él que es descrita por la clase «dcat:CatalogRecord», mientras que «dcat:Dataset» describe el conjunto de datos específicamente.
Este conjunto de datos tiene uno o varios temas asociados que se registran en un sistema taxonómico y, dentro de este, corresponden a un concepto.
Tiene también un responsable de publicación que se corresponde con un valor en el esquema FOAF (FOAF, 2000), con lo cual queda normalizada la institución o la persona que publica —una especie de identificación de autor o normalización del nombre del productor, como analogía en los ámbitos bibliotecológico o archivístico—, realizando un acoplamiento con un valor en FOAF.
DCAT usa términos de otros estándares y vocabularios como Dublin Core (Dublin Core Metadata Initiative), SKOS (W3C SKOS, 2009) o FOAF, con lo cual aprovecha y reutiliza los conceptos existentes y se concentra en el diseño específico de catálogos y conjuntos de datos abiertos.
El uso de RDF (W3C RDF) no es prescriptivo, aunque si se usa permite consultas semánticas a través de endpoints SPARQL (W3C SPARQL, 2008). Estos endpoints son puntos de búsqueda en un repositorio de datos que al ser almacenados en RDF tienen semántica y pueden ser interrogados con un lenguaje de consulta —SPARQL— que permite buscar en un grafo de triplas RDF.
CKAN permite la exportación de registros en formato DCAT y también permite recolectar registros de otros catálogos en este formato. Es posible que DCAT pueda constituirse en el formato de intercambio de metadatos tal como Dublin Core es el conjunto de metadatos de recolección con el protocolo OAI-PMH (Open Archives Initiative – Protocol for Metadata Harvesting).
Otra iniciativa destacable en este ámbito es VoID (W3C Describing Linked Datasets with the VoID Vocabulary, 2011), que puede ser usada en conjunción con DCAT. VoID es un vocabulario RDF para expresar metadatos de los conjuntos RDF con el objetivo de mediar entre los que publican los datos y los que los usan, desde los procesos de descubrimiento, catalogación y archivo. Se basa en Dublin Core.
Un aspecto de gran interés de VoID es que permite la descripción de los enlaces RDF entre distintos conjuntos de datos, y permite vincular conjuntos de datos distintos. Estos enlaces RDF habilitan la navegación entre conjuntos de datos diferentes pero ligados semánticamente. Normalmente usan el predicado «owl:sameAs», que vincula conceptos iguales con nombres diferentes.
VoID modela las materias sobre las que versan los conjuntos de datos por medio de la propiedad «dcterms: subject». Cada conjunto RDF usa uno o más vocabularios u ontologías OWL (W3C OWL, 2012).
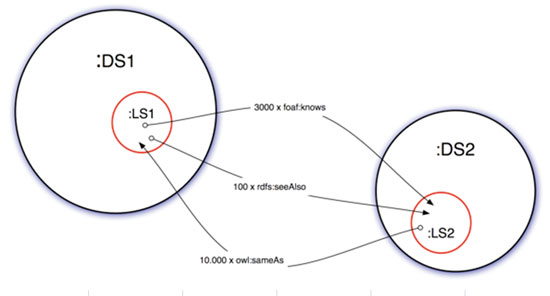
Figura 2. Vinculación en VoID
.
En la figura se muestran dos conjuntos de datos (DS1, DS2) que están en RDF y se vinculan a través de los vínculos (LS1, LS2). El vínculo se realiza a través de una subclase de void («void:linkset»). En cada tripla (sujeto, predicado, objeto) de la vinculación, el sujeto es un recurso alojado en un conjunto de datos (v. g. DS1) y el objeto un recurso de otro conjunto (v. g. DS2).
VoID entonces permite establecer las concordancias entre conjuntos de datos en esquemas diversos. Un ejemplo de uso de DCAT y VoID es el caso de los datos abiertos de Zaragoza en donde así lo explicitan.2
El uso de ontologías en la descripción de datos abiertos es una práctica que se implementa en el portal de datos abiertos brasileño y constituye una instancia de la preocupación de normalizar y consensuar los aspectos semánticos de los conjuntos de datos que es muy importante. En el caso específico de datos de presupuesto federal brasileño se encontró una ontología en OWL poblada con datos presupuestarios y un endpoint SPARQL para realizar consultas.3
En el portal de datos abiertos de Zaragoza también se encuentra un endpoint SPARQL para consultas que permite realizar consultas sobre los datos enlazados RDF.
El uso de ontologías permite no solamente relacionar conceptos y conjuntos de datos sino establecer un idioma común consensuado que permita la interoperabilidad semántica en la vinculación.
3 Usabilidad semántica de los datos abiertos
En los diversos casos analizados hay aspectos que no son considerados y en especial puede destacarse la ausencia de una semántica de los datos. Esto último se considera fundamental para la interpretación y el correcto uso de los datos. Por tanto se plantea incorporar estos aspectos en el conjunto de metadatos que acompañan los datos abiertos.
El enfoque se puede ver en el portal de datos abiertos de Uruguay.4 Allí, el Ministerio de Transportes y Obras Públicas (MTOP) publicó un conjunto de datos en el que propone una serie de metadatos basados en Dublin Core, realizando algunas extensiones:5
- Quién es el responsable de la actualización de los datos. Si bien en DCAT está la frecuencia de actualización («AccrualPeriodicity») y puede inferirse que la organización que publica es la responsable de la actualización, se entiende que la explicitación ayuda a la localización del contacto específico, lo que a veces no es una tarea sencilla.
- Si los datos provienen de una aplicación informática, consignar en ese caso cuál es la aplicación. La aplicación es una fuente sobre el procedimiento o actividad desarrollada para la producción del dato y da comprensión y contexto para poder interpretar adecuadamente el valor. DCAT indica que la API puede ser definida como una instancia de la distribución pero sin llegar a la definición de una clase específica. Sin embargo, se considera que la especificación expresa constituye un elemento de trazabilidad y calidad del dato que merece señalarse en forma específica.
- Si los datos están georreferenciados. Si el dato está georreferenciado es posible disponerlo como capa en un mapa. Cuando lo que se busca es este tipo de visualización, la indagación en cada conjunto de datos para determinar si dispone de las coordenadas geográficas es una tarea que puede simplificarse. La explicitación de este metadato permitiría buscar rápidamente la condición, lo cual es de gran utilidad y se presume que tendrá un uso incremental en la medida en que la territorialización de los datos se incrementa.
- Si los datos están disponibles en una base de datos. Este hecho indica un nivel de tratamiento sistemático y la posible actividad coordinada de múltiples actores que trabajan sin redundancia y con consistencia. Si bien se considera que si los datos se presentan mediante una aplicación estarán almacenados en una base de datos, puede ocurrir que el formato de presentación no sea a través de una salida de la aplicación y en ese caso no se sabrá si los datos provienen o no de una base de datos.
- Descripción granular de los datos en sí y su estructuración. Esta sería una nueva clase, ya que no se aplicaría al conjunto de datos. Para los aspectos de usabilidad e interoperabilidad del dato este tercer nivel de descripción que atañe no ya al conjunto sino a cada elemento de datos del conjunto permite entender qué significa cada dato y cómo está estructurado.
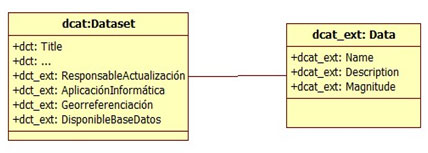
Figura 3: Extensión propuesta para DCAT
El conjunto de datos es un recurso formado por elementos atómicos. Está formado por atributos, y estos atributos a su vez tienen que ser identificados para que el conjunto sea comprensible y usable en términos aceptables. Por tanto, en el caso de un recurso de este tipo, se propone una especificación explícita sobre cada uno de los atributos y también sobre su estructuración.
El dato tiene un nombre generalmente autoexplicativo, pero para trabajar con datos no alcanza con un nombre, debe darse una descripción clara de lo que significan los valores que contiene para que puedan desarrollarse aplicaciones que usen el dato y que den resultados correctos.
Si tomamos como ejemplo el nombre de un campo «estado de la ruta» y vemos su dominio de valores (bueno, regular o malo), esto no nos indica nada sobre qué indicadores se tomaron en cuenta para construir estos valores. Subyace al valor una definición de trabajo que dirá que la ruta se considera en buen estado si tiene un valor en un rango determinado del índice de estado superficial. Esta definición («dcat_ext: Description») será necesaria para poder generar una aplicación que muestre los estados de las carreteras en Latinoamérica porque deberá tenerse en cuenta que los valores que se pongan de Brasil sean análogos a los de Uruguay, por ejemplo.
Por otra parte el dominio de valores tiene que quedar claro cuando no está indicado de otra forma, un atributo «distancia» se puede expresar en metros, kilómetros, etc. Si el nombre del atributo tiene por valor «monto en dólares» no es necesario expresar la magnitud, pero un atributo «monto» es ambiguo.
El otro aspecto de gran interés para el reúso de los datos es su estructuración, la manera como se vinculan unos atributos con otros. Normalmente los datos que se almacenan en una base de datos relacional están normalizados y se asocian por medio de relaciones. La mejor manera de ver esta estructura es un diagrama de entidad-relación.
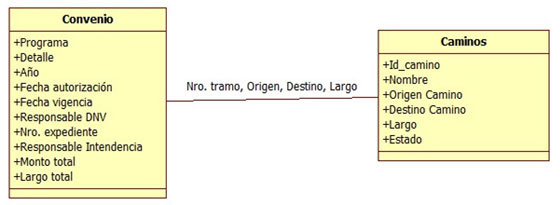
Figura 4. Diagrama de entidad-relación conjunto de datos de convenio
El diagrama visibiliza que hay dos elementos y un vínculo:
- los convenios con sus datos
- los caminos con sus datos
- los caminos asignados a cada convenio con sus respectivas porciones (no todo el camino puede involucrar al convenio)
El formato RDF visibiliza estas relaciones y por esta razón un conjunto de datos «rdfizado» constituye un mayor nivel de calidad de los datos.
En el caso planteado de los datos de convenios del Ministerio de Transportes y Obras Públicas, los atributos son agrupados con un criterio horizontal en el conjunto de datos, pero subyace a esta agrupación un esquema de vinculación que tiene que ser explícito para ser comprensible. Al presentar los datos en formato RDF, se logra una visión sobre la estructuración interna de los datos. Es así como se aprecia la vinculación de un convenio con los elementos del convenio en el formato RDF, tal como se detalla en el apéndice.
RDF modela el vínculo en que cada convenio tiene asociados determinados caminos. También se puede ver mediante un diagrama de grafos.
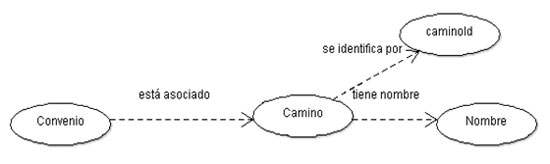
Figura 5. Grafo de convenio
Si además enlazamos los datos con conjuntos de datos ya publicados, estamos realizando una autopista para navegar en la red semántica. En el caso de este conjunto de datos esto todavía no se ha realizado, pero, por ejemplo, si el atributo que identifica el camino pudiera enlazarse con un conjunto de datos consensuado sobre la identificación de los caminos, todos los que se refirieran a los caminos podrían reutilizarlos y de esta manera se lograría la vinculación de datos con diversos actores —el Ministerio de Transportes, la Intendencia Departamental— y con facetas distintas, información sobre convenios, información departamental, información sobre obras realizadas en los caminos, información sobre evaluación de estado de los caminos, etc. En todos los casos mencionados se utilizaría la identificación del camino de esa fuente consensuada, digamos el «FOAF» del camino, y podríamos navegar semánticamente sobre aspectos totalmente diversos, sabiendo que se trata de ese camino y todos lo denominamos igual.
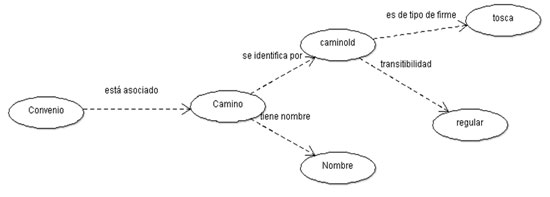
Figura 6. Grafo de convenio extendido
No obstante, el aspecto de comprensibilidad del dato en sí no se contempla por esta vía sino a través de definir el significado del dato, el diccionario de datos del dato. Ambos aspectos son fundamentales: la explicitación del dato y su estructuración.
El diccionario de datos de los datos tiene dos aspectos:
- La identificación del conjunto de valores sobre el que mapea. Por ejemplo, la transitabilidad (buena, regular, mala).
- La definición de trabajo del atributo que permitirá establecer el valor, de acuerdo con un criterio conocido que pueda ser entendido y comparado, por ejemplo, la definición de transitabilidad.
Los portales de datos abiertos funcionan como repositorios de estos objetos especiales que son los datos, y tienen, por un lado, las mismas necesidades de un repositorio digital de tipo genérico para dar soluciones apropiadas a la búsqueda de información. Por otro lado, la especificidad de los objetos almacenados en estos repositorios requiere metadatos granulares para dar un uso a los datos en forma consistente y con calidad. Podríamos llamar a estos metadatos de «tercer nivel» si consideramos los metadatos del portal de datos como un primer nivel y los metadatos generales del conjunto de datos como un segundo nivel; entonces los metadatos de los atributos constituirían un tercer nivel. Estos metadatos de tercer nivel deben tener un criterio de normalización o establecerse la información básica requerida. Ellos son clave para la reutilización de los datos de forma correcta, no operan en el nivel de recuperación de información en forma directa pero son esenciales para la reutilización adecuada, lo cual, en definitiva, es una operación secuencial a la búsqueda y recuperación y es un objetivo primordial de la visibilización de este tipo de información.
4 Conclusiones
Los datos de una organización son un elemento más en un entramado de otros objetos de información. Para que la información de una organización pueda acoplarse e interoperar es necesario estandarizar, sistematizar y documentar claramente estos datos en la gestión interna de la organización. Esta tarea también se debe realizar hacia fuera, interactuando con otros organismos gubernamentales y permitiendo el flujo de información interinstitucional. Un nivel superior es el uso de los datos de gobierno por parte de la ciudadanía, los periodistas u otros actores de la sociedad civil (Ciudadanía/Cidadania 2.0).
Los datos requieren un nivel de precisión mayor que otros recursos de información, respecto a su significado, el dominio de valores y la forma como se estructuran para poder ser utilizados en forma correcta y sencilla.
La integración de datos puede realizarse con mayor calidad y sencillez si se aportan los metadatos propuestos en el momento de la publicación. El productor de los datos conoce estos aspectos, por lo que se estima no presupone un gran esfuerzo aportarlos en el momento de su publicación y este esfuerzo tiene un impacto muy significativo en la calidad y legibilidad de los datos y, por ende, una mayor adecuación en su reúso.
El ámbito del gobierno electrónico permite una recomendación institucional en este sentido, porque es de interés poder navegar por la información tanto dentro de la institución como a nivel interinstitucional.
En el caso implementado de los datos de los convenios, se establece una identificación del camino rural por medio de una URI (cadena de caracteres corta) que permite que otros actores, como las intendencias departamentales, aporten otra información y vayan construyendo un grafo navegable que modele la articulación de la información entre distintas instituciones.
Este primer nivel de conexión y estandarización permite aventurar la construcción de ontologías institucionales que puedan irse vinculando. Cuando una intendencia departamental use la identificación del camino, podrá establecer que se trata de la misma identificación que usa el Ministerio de Transportes («owl:sameAs»).
Otro aspecto que debe tomarse en cuenta en los conjuntos de datos es la necesidad de tener una política de preservación digital, y en ese sentido los metadatos arrojan información sobre los formatos, pero también modelan un encapsulamiento descriptivo de su propia semántica.
La información del gobierno electrónico forma parte de un sistema más amplio que crece, se influencia y cambia constantemente. Este vasto ecosistema puede navegarse a través de los flujos y atracar en las islas o repositorios que se encuentren a lo largo del trayecto, pero hay que construir una brújula certera que marque rumbos confiables. Esta brújula es una combinación de elementos: metadatos que describan apropiadamente, terminología que permita comprender y acoplar, tesauros, ontologías, grafos RDF y datos enlazados.
Los profesionales de la información tienen la visión y la formación para participar en equipos de trabajo multidisciplinarios que modelen corrientes seguras en el ámbito del gobierno electrónico.
Bibliografía
Ciudadanía/Cidadania 2.0. <http://www.ciudadania20.org/>. [Consulta: 25/11/2014].
Dublin Core Metadata Initiative (DCMI). <http://dublincore.org/>. [Consulta: 25/11/2014].
FOAF: 2000–2014+, Friend of a friend. <http://www.foaf-project.org/>. [Consulta: 25/11/2014].
OECD (2014). «Recommendation of the Council on Digital Government Strategies». <http://www.oecd.org/gov/public-innovation/recommendation-on-digital-government-strategies.htm>. [Consulta: 25/11/2014].
Open Archives Initiative Protocol for Metadata Harvesting. <http://www.openarchives.org/pmh/>. [Consulta: 25/11/2014].
Temesio, Silvana (2013). «Interoperabilidad de la información en el gobierno electrónico». Acervo: Revista do arquivo nacional, vol. 26, no. 2. <http://www.revistaacervo.an.gov.br/seer/index.php/info/article/view/615>. [Consulta: 25/11/2014].
W3C, Data Catalog Vocabulary (DCAT) (2014). <http://www.w3.org/TR/vocab-dcat/>. [Consulta: 25/11/2014].
W3C, Describing Linked Datasets with the VoID Vocabulary (2011). <http://www.w3.org/TR/void/>. [Consulta: 25/11/2014].
W3C, Guía breve linked data. <http://www.w3c.es/Divulgacion/GuiasBreves/LinkedData>. [Consulta: 25/11/2014].
W3C, OWL: web ontology language. <www.w3.org/2004/OWL>. [Consulta: 25/11/2014].
W3C, Resource Descripcion Framework (RDF). <http://www.w3.org/RDF/>. [Consulta: 25/11/2014].
W3C (2008). Sparql query language for RDF. <http://www.w3.org/TR/rdf-sparql-query/>. [Consulta: 25/11/2014].
W3C (2009). SKOS Simple Knowledge Organization System. <http://www.w3.org/2004/02/skos/>. [Consulta: 25/11/2014].
W3C (2012). OWL 2: Ontology Web Language. <http://www.w3.org/TR/2012/REC-owl2-overview-20121211/>. [Consulta: 25/11/2014].
Notas
1 La ley de Uruguay puede consultarse en: <http://www.impo.com.uy/informacionpublica>.
2 <https://www.zaragoza.es/ciudad/risp/vocabulario-dcat.htm#ftn2>.
3 Para visualizar el modelo ontológico de las categorías de gasto del presupuesto federal puede consultarse: <http://vocab.e.gov.br/2013/09/loa>.
El endpoint SPARQL para realizar consultas está disponible en: <http://dados.gov.br/dataset/orcamento-federal/resource/6971c6c1-109e-4462-9463-7a4fee2cd702>.
4 El portal de datos abiertos de Uruguay puede consultarse en: <http://datos.gub.uy/>.
5 El conjunto de datos puede consultarse en: <https://catalogodatos.gub.uy/dataset/convenios>.
Apéndice. Parcial del archivo RDF: Convenios caminería rural – MTOP
<https://catalogodatos.gub.uy/dataset/convenios/resource/32d942b3-6977-4b0f-ae65-a78d66095a2d>
<?xml version=»1.0″ encoding=»UTF-8″?>
<rdf:RDF xmlns:rdf=»http://www.w3.org/1999/02/22-rdf-syntax-ns#«>
<rdf:Description rdf:about=»http://dnv.mtop.gub.uy/0«>
<rdf:type rdf:resource=»http://dnv.mtop.gub.uy/convenios«/>
<convenioid xmlns=»http://dnv.mtop.gub.uy/» rdf:datatype=»http://www.w3.org/2001/XMLSchema#int«>4.0</convenioid>
<conveniodepto xmlns=»http://dnv.mtop.gub.uy/«>COLONIA </conveniodepto>
<ConvenioPrograma xmlns=»http://dnv.mtop.gub.uy/«>370</ConvenioPrograma>
<ConvenioDetalle xmlns=»http://dnv.mtop.gub.uy/«></ConvenioDetalle>
<ConvenioAño xmlns=»http://dnv.mtop.gub.uy/» rdf:datatype=»http://www.w3.org/2001/XMLSchema#int«>2014.0</ConvenioAño>
<ConvenioAutorizacion xmlns=»http://dnv.mtop.gub.uy/» rdf:datatype=»http://www.w3.org/2001/XMLSchema#dateTime«>Wed Apr 30 00:00:00 GMT-03:00 2014</ConvenioAutorizacion>
<ConvencioVigencia xmlns=»http://dnv.mtop.gub.uy/» rdf:datatype=»http://www.w3.org/2001/XMLSchema#dateTime«>Wed Dec 31 00:00:00 GMT-03:00 2014</ConvencioVigencia>
<ConvenioResponsable xmlns=»http://dnv.mtop.gub.uy/«>GUSTAVO MIERES</ConvenioResponsable>
<ConvenioExpediente xmlns=»http://dnv.mtop.gub.uy/» rdf:datatype=»http://www.w3.org/2001/XMLSchema#int«></ConvenioExpediente>
<ConvenioResponsableIntendencia xmlns=»http://dnv.mtop.gub.uy/«>ING. HECTOR ANZALAS</ConvenioResponsableIntendencia>
<ConvenioMontoTotal xmlns=»http://dnv.mtop.gub.uy/» rdf:datatype=»http://www.w3.org/2001/XMLSchema#double«>1.8876565E7</ConvenioMontoTotal>
<ConvenioLargoTotal xmlns=»http://dnv.mtop.gub.uy/» rdf:datatype=»http://www.w3.org/2001/XMLSchema#double«>682.3</ConvenioLargoTotal>
<rdf:type rdf:resource=»http://dnv.mtop.gub.uy/Caminos«/>
<CaminoId xmlns=»http://dnv.mtop.gub.uy/» rdf:datatype=»http://www.w3.org/2001/XMLSchema#int«>427.0</CaminoId>
<CaminoNombre xmlns=»http://dnv.mtop.gub.uy/«>Beltramo</CaminoNombre>
<CaminoNombreIntendencia xmlns=»http://dnv.mtop.gub.uy/«></CaminoNombreIntendencia>
<CaminoNroTramo xmlns=»http://dnv.mtop.gub.uy/«>463</CaminoNroTramo>
<CaminoOrigen xmlns=»http://dnv.mtop.gub.uy/«>Ruta 21, 230k000</CaminoOrigen>
<CaminoDestino xmlns=»http://dnv.mtop.gub.uy/«>Al Este, Est. Sr. Beltramo</CaminoDestino>
<CaminoLargoKm xmlns=»http://dnv.mtop.gub.uy/» rdf:datatype=»http://www.w3.org/2001/XMLSchema#double«>3.0</CaminoLargoKm>
</rdf:Description>
 licencia de Creative Commons de tipo «Reconocimiento-NoComercial-SinObraDerivada«. Esto significa que se pueden consultar y difundir libremente siempre que se cite el autor y el editor con los elementos que constan en la opción «Cita recomendada» que se indica en cada uno de los artículos, pero que no se puede hacer ninguna obra derivada (traducción, cambio de formato, etc.) sin permiso del editor. En este sentido, se cumple con la definición de open access de la Declaración de Budapest en favor del acceso abierto. La revista permite al autor o autores mantener los derechos de autor y retener los derechos de publicación sin restricciones.
licencia de Creative Commons de tipo «Reconocimiento-NoComercial-SinObraDerivada«. Esto significa que se pueden consultar y difundir libremente siempre que se cite el autor y el editor con los elementos que constan en la opción «Cita recomendada» que se indica en cada uno de los artículos, pero que no se puede hacer ninguna obra derivada (traducción, cambio de formato, etc.) sin permiso del editor. En este sentido, se cumple con la definición de open access de la Declaración de Budapest en favor del acceso abierto. La revista permite al autor o autores mantener los derechos de autor y retener los derechos de publicación sin restricciones.