
[Versió catalana][English version]
Danielle Kane
Bibliotecaria investigadora en tecnologías emergentes
University of California, Irvine
Resumen
La primera parte de este artículo analiza cómo crear y gestionar un bot en bibliotecas académicas, incluyendo el tipo de estadísticas que deberían elaborarse y la importancia de revisar periódicamente las transcripciones. Creado en 2014, el bot en cuestión se ha desarrollado hasta el punto en que, de media, contesta correctamente las preguntas de los usuarios de las bibliotecas en un 70% de los casos. La segunda parte es un análisis de más de 10.000 frases enviadas por los usuarios (preguntas y afirmaciones). El análisis empleó la herramienta UAM CorpusTool para crear capas y transcripciones de código de acuerdo con la estructura de las frases, las afirmaciones de apertura y cierre, el interés mostrado, así como los tipos de servicios y materiales solicitados. Si bien el bot de las bibliotecas está claramente identificado como un programa informático, una serie de usuarios tratan habitualmente el bot como si fuera un ser humano y mantienen largas conversaciones no relacionadas con las bibliotecas.
Resum
La primera part d’aquest article analitza com crear i gestionar un bot a biblioteques acadèmiques, incloent-hi el tipus d’estadístiques que s’haurien d’elaborar i la importància de revisar periòdicament les transcripcions. Creat l’any 2014, el bot en qüestió s’ha desenvolupat fins al punt en què, de mitjana, contesta correctament les preguntes dels usuaris de les biblioteques en un 70 % dels casos. La segona part és una anàlisi de més de 10.000 frases enviades pels usuaris (preguntes i afirmacions). L’anàlisi va emprar l’eina UAM CorpusTool per tal de crear capes i transcripcions de codi d’acord amb l’estructura de les frases, les afirmacions d’obertura i tancament, l’interès mostrat, així com els tipus de serveis i materials sol·licitats. Si bé el bot de les biblioteques està clarament identificat com un programa informàtic, una sèrie d’usuaris tracten habitualment el bot com si fos un ésser humà i hi mantenen llargues converses no relacionades amb les biblioteques.
Summary
Part 1 of this paper discusses how to create and manage an academic library chatbot, including the type of statistics that should be kept and the importance of regularly reviewing transcripts. Created in 2014, the chatbot in question has been developed to the point where, on average, it correctly answers library users’ questions 70% of the time. Part 2 is an analysis of over 10,000 user-submitted sentences (questions and statements). The analysis used UAM CorpusTool to create layers and code transcripts according to sentence structure, opening and closing statements, showing interest, and types of service and materials requested. While the library chatbot is clearly marked as being a computer program, a number of users regularly treat the chatbot as human and hold long non-library related conversations with it.
1 Introducción
El Educause Horizon Report (2019) estima que la inteligencia artificial tiene un horizonte de implantación de entre dos y tres años, y afirma que «AI’s ability to personalize experiences, reduce workloads, and assist with analysis of large and complex data sets recommends it to educational applications» (Educause, 2019). Un tipo específico de software de IA, el bot de conversación (en adelante, bot), se puede emplear para simular conversaciones con un usuario utilizando el procesamiento de lenguaje natural. Los bots pueden optimizar las interacciones entre los servicios y las personas, y mejorar la experiencia de los usuarios de los servicios de una biblioteca. Las máquinas son capaces de reproducir los procesos humanos de aprendizaje, razonamiento y autocorrección utilizando programas y códigos informáticos: pueden aprender mediante la adquisición de información y el uso de normas preestablecidas para determinar cómo utilizar esta información; pueden razonar utilizando las normas con el fin de llegar a conclusiones aproximadas o, incluso, definitivas; por último, también pueden autocorregirse o se pueden corregir para que no den información anómala al usuario.
Imitando las aplicaciones de mensajería, los bots pueden comunicarse con sitios web, aplicaciones móviles, hardware (por ejemplo, aplicaciones de Alexa) o, incluso, redes telefónicas. Sin embargo, no importa qué tipo de aplicación o sistema se escoja para crear un bot: la intervención humana será siempre crucial. Serán necesarios seres humanos para configurar, entrenar y optimizar el sistema. Propuesto en abril de 2013, nuestro bot ANTswers (http://antswers.lib.uci.edu/) tardó aproximadamente un año en desarrollarse. Si bien empleamos tecnología de código abierto para crear ANTswers, el proyecto tuvo un costo, y nuestros programadores necesitaron un periodo de tiempo considerable para crear todas las categorías necesarias para que el bot funcionara.
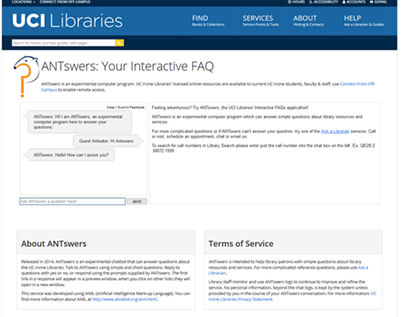
Figura 1. Interfaz gráfica de usuario de ANTswers
En el contexto de nuestra universidad, los departamentos de referencia cuentan con una larga trayectoria en la oferta de servicios de referencia virtuales a clientes remotos y del campus. Las bibliotecas de UCI ofrecen correo electrónico, QuestionPoint, mensajería instantánea y consultas de búsqueda basadas en citas utilizando herramientas como Google+ y Hangouts. McNeal & Nayara (2013) afirman que las solicitudes de materiales, ubicaciones, horarios y políticas específicas predominan en las conversaciones de chat y mensajería instantánea. Como son los tipos de solicitudes de información que los bots pueden contestar correctamente, ofrecen una opción de autoservicio para los clientes. El uso de herramientas en línea nos permite satisfacer las necesidades de los usuarios sea cual sea su ubicación y en el momento en que surge la necesidad. Los bots permiten a los bibliotecarios ir más allá a la hora de ofrecer ayuda e instrucción 24/7 sin incorporar un conjunto de servicios de referencia que exijan la asistencia en persona. A medida que el personal cambia y la biblioteca define nuevas prioridades, puede ser complicado dotar de personal los servicios de referencia; por el contrario, un bot puede suponer menos tiempo de personal para esa gestión.
2 Creación de un bot
La University of California (UCI), en Irvine, es una gran universidad pública ubicada en Irvine (California) y uno de los diez campus del sistema de la University of California. La UCI cuenta con un total de once mil personas que trabajan a jornada completa, entre personal docente y académico, para una población estudiantil superior a 35.000 personas, mientras que UCI Libraries cuenta con 159 profesionales, de los cuales 59 son bibliotecarios. UCI Libraries dispone de cuatro bibliotecas: Langson Library, dedicada a la investigación y la enseñanza en humanidades y ciencias sociales; Science Library (biblioteca de ciencias), Grunig Medical Library (biblioteca médica) y Law Library (biblioteca legal). Ofrecemos servicios de referencia en nuestro mostrador Ask Us (Biblioteca Responde) en Langson Library, junto con consultas de búsqueda, en persona y en línea, de 30 minutos. También ofrecemos servicios de referencia por correo electrónico, teléfono y chat 24/7 con QuestionPoint. El año pasado, el personal de la UCI contestó más de 12.000 preguntas de referencia.
Como en cualquier proyecto de envergadura, la planificación inicial y la organización son claves a la hora de crear un bot de éxito. En abril de 2013, se envió una propuesta a la administración de UCI Libraries donde se explicaba detalladamente qué era un bot y el posible impacto que podría tener en nuestros servicios de referencia. La propuesta revisaba los diferentes tipos de bot y proporcionaba una recomendación sobre cuál podría dar mejor respuesta a las necesidades de nuestras bibliotecas. Todo ello tomó la forma de ANTswers, que se creó como aplicación web basada en Program-O en un servidor remoto. Los bots basados en la web ofrecen más flexibilidad, pero requieren experiencia en HTML, PHP, CSS, JavaScript y AIML (Artificial Intelligence Markup Language). Program-O (http://blog.program-o.com/) es un motor AIML de código abierto escrito en PHP con MySQL. Si bien hay múltiples motores AIML gratuitos y de código abierto, UCI Libraries escogió Program-O por sus funciones, que incluyen un corrector ortográfico, configuración de personalidad del bot, una función de búsqueda SRAI, así como la posibilidad de añadir y editar cuentas de botmaster.
El equipo de tecnologías emergentes planteó que un bot en las bibliotecas podría compensar un vacío de los servicios de referencia que se ofrecen actualmente y, en términos generales, podría aumentar estos servicios. QuestionPoint es un excelente servicio 24/7 con personal bibliotecario capacitado y experimentado, pero se consideró que ofrecía más de lo que necesitan actualmente los clientes cuando tienen una pregunta direccional o fáctica sencilla. Para este tipo de situaciones, tener que introducir tu información de contacto y el nombre puede ser una inversión de tiempo innecesaria, y algunos usuarios también son reticentes a la hora de formular preguntas al personal de la biblioteca. Si bien los bots «cannot replicate the complexity of human interaction, [they] can provide a cost-effective way to answer the majority of routine reference questions» (Vincze, 2017). En resumen, el bot nos ofrecía la oportunidad de:
- mejorar, más que sustituir, los servicios de referencia disponibles;
- atender a un mayor número de personas en cualquier momento del día;
- atender a una amplia variedad de usuarios de las bibliotecas;
- servir como filtro para el personal de las bibliotecas, contestando preguntas básicas y repetitivas («¿Dónde está la grapadora?», «¿Cómo puedo imprimir?», etc.).
En una fase temprana del proceso, se designó un equipo de personas clave de la biblioteca, que se reunía periódicamente para analizar cuestiones como si el bot debía ser programado únicamente para consultas relacionadas con las bibliotecas, o si tenía que ser capaz de mantener una «conversación» más general. Los bots pueden ser vistos como una forma de pasar el tiempo o como «a way to avoid loneliness or fulfill a desire for socialization» (Brandtzaeg and Følstad, 2017). Otra cuestión que se plantearon es si el bot debía tener una personalidad y, en caso afirmativo, qué tipo de personalidad debía ser. El equipo ayudó a definir como debía interaccionar el bot con nuestros estudiantes. Por lo tanto, si bien queda muy claro que ANTswers es un programa informático, en una fase temprana del proceso, el equipo decidió otorgar una personalidad a ANTswers basándose en la mascota de la UCI «Peter the Anteater» (Peter, el oso hormiguero). Con esto en mente, ANTswers se diseñó como un oso hormiguero al que gustan las hormigas y todo lo relacionado con la UCI. Program-O facilita desarrollar una personalidad para un bot, ya que proporciona un «formulario» fácil de responder.

Figura 2. La interfaz de personalidad del bot de Program-O
Program-O permite añadir y eliminar archivos del sistema, pero no sustituirlos. Para hacer frente a esta limitación del sistema, se definió un fichero con un glosario en una fase temprana del proceso. La Artificial Intelligence Foundation (A.L.I.C.E – https://code.google.com/p/aiml-en-us-foundation-alice/) ofrece una serie de archivos de código abierto disponibles para la descarga. Estos archivos incluyen el grueso de las categorías de conversación generales, y se han adaptado y depurado ampliamente para el uso en un entorno de biblioteca académica. Los archivos están disponibles en GitHub (Kane, 2017). Los dos archivos del bot que contienen el código para recordar información sobre el bot y la misma conversación tienen antepuesta la letra «b». Los seis ficheros de referencia preparados dan respuestas fácticas sobre temas generales, tales como ciencia, historia y geografía, y tienen antepuesta la letra «r.». Organizados por servicio, ubicación o recurso, los 20 archivos de la biblioteca están marcados con «lib.». Finalmente, 66 archivos temáticos organizados según la clasificación de la Library of Congress contienen recomendaciones de recursos para palabras clave y tienen antepuesta la letra «s».
Se pueden utilizar varios programas para crear y editar archivos AIML, incluidos Notepad, Atom, Vim y Notepad ++. En el caso de ANTswers, empleamos Notepad ++, que es un editor gratuito de código abierto para la plataforma Windows. Notepad ++ ofrece algunas funcionalidades útiles, como las búsquedas en todos los archivos y carpetas. Si bien los usuarios con poca experiencia en programación pueden ser inicialmente recelosos en el aprendizaje de AIML, en realidad se trata de un lenguaje sencillo que es fácil de aprender y puede funcionar sin depender de «the conventional wisdom from structured programming» (Wallace, 2003). Las etiquetas <category>, <pattern> y <template> son las unidades básicas de conocimiento a AIML: category es la unidad de conocimiento, pattern se refiere a la entrada introducida por el usuario representada mediante palabras clave, frases u oraciones, y template contiene la respuesta del bot. Por lo tanto, una expresión AIML simple se puede representar de la siguiente manera:
<category><pattern>TEXTO INTRODUCIDO</pattern>
<template>TEXTO DE SALIDA</template></category>
A continuación, un ejemplo de una categoría AIML sencilla:
AIML también permite el uso de etiquetas de conocimiento, las cuales provocan que el bot almacene datos, active un programa diferente o dé una respuesta condicional. UCI Libraries creó la etiqueta específica
Otra etiqueta,
Se puede hallar un análisis más detallado del desarrollo de ANTswers en Kane (2016). Como alternativa, el lector puede acceder a una serie de tutoriales que existen sobre el lenguaje de programación AIML y las etiquetas que se pueden utilizar, como TutorialsPoint (https://www.tutorialspoint.com/aiml/aiml_introduction.htm).
3 Gestión de un bot
Para gestionar correctamente un bot como ANTswers es necesario un proceso continuo de revisión y actualización. Cuando el bot estaba en versión beta, las transcripciones se revisaban diariamente cinco días a la semana, se elaboraban estadísticas para cada transcripción y se introducían modificaciones en el código para resolver los problemas detectados. Posteriormente, el código actualizado se volvía a cargar en Program-O al finalizar cada revisión de las transcripciones. Las modificaciones típicas que se realizaban en ANTswers incluían añadir categorías nuevas o nuevos términos a las categorías existentes. Como la UCI tiene un cuerpo estudiantil internacional grande, es necesario que el programador añada nuevos términos o frases de forma periódica para garantizar que ANTswers pueda responder a las consultas formuladas en un inglés gramaticalmente incorrecto.
No se pudo utilizar Program-O para evaluar y realizar un seguimiento de las estadísticas de ANTswers, ya que el programa no puede marcar las transcripciones como «leídas» ni añadir estadísticas al sistema. Además, el programa muestra primero las conversaciones más antiguas y no hay manera de buscar transcripciones específicas. Se determinó que era necesario un sistema dorsal (back-end). Mediante el uso de MySQL, un programador de la biblioteca podía volcar las transcripciones de Program-O en una base de datos en línea, donde se podían introducir las estadísticas. La fecha revisada se utiliza como nota visual para indicar que la transcripción se ha revisado y se han introducido las modificaciones necesarias al código. Las transcripciones y las estadísticas se pueden descargar de la base de datos en línea, y se pueden volcar a otras herramientas para el análisis. Cuando el bot todavía era nuevo, revisar las transcripciones y elaborar las estadísticas suponía entre cinco y seis horas de trabajo a la semana. A medida que las categorías de ANTswers fueron creciendo y aumentó el porcentaje de respuesta, la base de datos en línea sólo debía revisarse dos o tres veces a la semana y, actualmente, supone entre una y tres horas de trabajo.
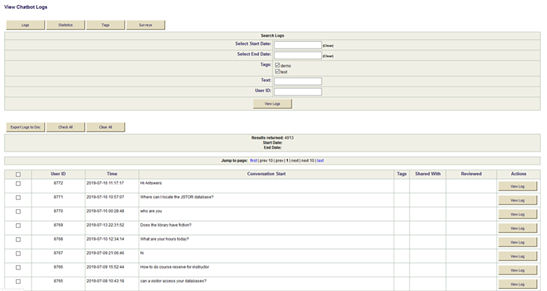
Figura 3. Sistema de gestión dorsal de ANTswers
4 Análisis de un bot
4.1 Estadísticas generales
Todas las transcripciones del bot se revisan mediante el sistema dorsal. Como parte de esta revisión, se elaboran las estadísticas siguientes para cada transcripción:
- Fecha
- Hora del día
- Trimestre académico
- Semana del trimestre académico
- Día de la semana
- Número total de preguntas:
- Número de preguntas relacionadas con las bibliotecas y porcentaje de respuesta
- Número de preguntas generales y porcentaje de respuesta
- Contexto de la transcripción: qué preguntan los clientes
- Escala READ (Reference Effort Assessment Data)
Los datos se descargan en una base de datos Access conectada con Excel, donde se utilizan tablas dinámicas para crear visualizaciones para cada trimestre académico (hay que tener en cuenta que la UCI se organiza por trimestres en lugar de por semestres). Desde que ANTswers se introdujo en el año 2014, se han formulado un total de 12.202 preguntas, de las cuales 7.770 (64%) están relacionadas con las bibliotecas. Si bien hubiese sido más sencillo crear y mantener un bot que únicamente abordara preguntas relacionadas con las bibliotecas, también incluimos la posibilidad de respuestas generales para aquellos usuarios que simplemente quieren chatear. Los datos se agrupan por años y se comparten a través de Dash, el servicio de publicación de datos de la University of California. Cuando ANTswers se implementó por primera vez en fase beta, el 39% de las respuestas estaban relacionadas con las bibliotecas. El trabajo de actualización ha ayudado a aumentar este porcentaje.
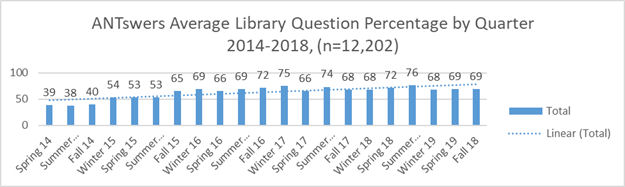
Figura 4. Porcentaje de respuesta de ANTswers para preguntas relacionadas con las bibliotecas por trimestre durante el periodo 2014-2018
Estas estadísticas ayudan a determinar cuando se puede detener ANTswers para realizar tareas de mantenimiento. Por ejemplo, ANTswers se utiliza con mucha frecuencia durante las semanas 2 y 3 de cada nuevo trimestre (hay que tener en cuenta que cada trimestre tiene unas 10 semanas). Es más probable que los usuarios formulen preguntas de lunes a jueves, entre las 8 de la mañana y las 7 de la tarde, si bien hay que tener en cuenta que los usuarios formulan preguntas las 24 horas del día, 7 días a la semana. En términos generales, el número más elevado de preguntas se produce durante las semanas 1, 2 y 3 de cada trimestre. El uso llega a su punto álgido de lunes a jueves, mientras que entre el viernes y el domingo se produce un descenso del 50% aproximadamente. Durante las últimas semanas de cada trimestre, el mejor momento para llevar a cabo tareas de mantenimiento en el bot son los viernes a primera hora de la mañana. Las actualizaciones y las tareas de mantenimiento más exhaustivas se reservan para el verano, cuando hay menos estudiantes en el campus. Si bien el uso ha disminuido desde 2015, esta circunstancia es más atribuible a los cambios realizados en la página de inicio del sitio web de la biblioteca, que provocó que el enlace al bot se desplazara a la parte inferior de la página (durante la fase beta, el enlace ocupaba una ubicación preeminente en la parte superior de la pantalla).
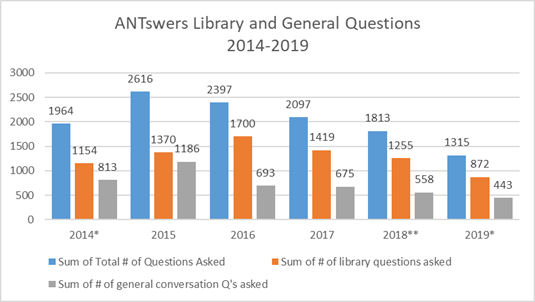
Figura 5. Preguntas generales y relacionadas con las bibliotecas de ANTswers durante el período 2014 a 2019
Según Christensen (2007), los bots no «roban» preguntas de referencia a los bibliotecarios; por el contrario, se pueden utilizar para las preguntas de referencia sencillas y preguntas frecuentes sobre los temas siguientes:
- Navegación por un sitio web
- Enlaces a otros sitios web y documentos
- Acceso a registros de OPAC
- Información básica sobre tareas de las bibliotecas en línea
- Materiales de préstamo entre bibliotecas
- Buscar materiales a bases de datos
Si bien el análisis de las estadísticas de referencia de UCI Libraries podría sugerir que ANTswers ha afectado a nuestras estadísticas globales, se han producido una serie de hechos desde que se lanzó el bot en 2014. Con el tiempo, hemos acortado nuestras horas de mostrador como respuesta a la disminución de las necesidades a primera y última hora del día. En ocasiones, por escasez de personal, hemos pasado de tener abierto el mostrador de referencia tanto el sábado como el domingo a abrir sólo los domingos y luego a no tener ni siquiera horas de referencia los fines de semana. Nuestros servicios de acceso tampoco registran estadísticas de referencia. Durante este periodo, también hemos dado el salto a la herramienta de escala de seis puntos READ (Reference Effort Assessment Data) y, después de hacer un seguimiento de la escala READ para cada transcripción de ANTswers, detectamos que las transcripciones eran eminentemente discrecionales y, por tanto, se codificaban como 1, dejando muy pocas transcripciones en los grados del 2 al 6.
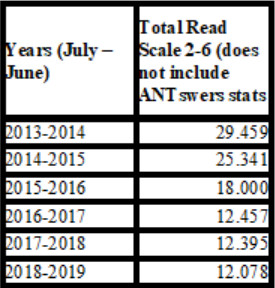
Figura 6. Número total de referencias de UC Irvine en la escala READ 2-6 durante el periodo 2013-2019
4.2 Análisis textual de las transcripciones del bot
Se ha llevado a cabo un análisis de las transcripciones del bot desde la creación de ANTswers en marzo de 2014 hasta abril de 2018 con el fin de determinar cómo los usuarios formulan las preguntas y sobre qué tipo de recursos/servicios preguntan. Se ha evaluado cada una de las 7.924 transcripciones de chat para determinar si eran transcripciones reales (enviadas por un usuario) o pruebas, demostraciones del sistema o spam. Una vez revisadas las transcripciones, un total de 2.786 transcripciones se revisaron con más profundidad para buscar la información confidencial (como el nombre del usuario), y esta información y las respuestas de ANTswers se eliminaron antes de cargar las transcripciones a la herramienta UAM CorpusTool (versión 3) por ID de usuario asociado. Las transcripciones contenían un total de 10.341 frases de usuarios de bibliotecas (preguntas y afirmaciones). UAM CorpusTool se puede emplear para crear capas y, por tanto, se creó una para analizar cómo los usuarios estaban formulando las preguntas y se desarrolló otra para hacer un seguimiento de lo que estaban preguntando.
La primera capa creada en UAM CorpusTool analizaba cómo preguntaban los usuarios, pero también determinaba si estaban utilizando frases de apertura y cierre, y si mostraban interés en el bot. Los saludos se consideran una función básica de la comunicación y una señal de cortesía elemental al iniciar una conversación, y se constató que los clientes habían empleado algún tipo de saludo en 460 (17%) de las 2.786 transcripciones. Los saludos más frecuentes eran «hello» y «hi» (hola). Por otra parte, las frases de cierre sólo se habían empleado en un 5% de las transcripciones, y las más habituales eran «thank you» o «thanks» (gracias). Un estudio reciente llevado a cabo por Xu et al. sobre los bot para servicios de atención al cliente concluyó que el 40% de las solicitudes de usuarios son emocionales en lugar de informativas (Xu, 2017). Sólo 248 de las transcripciones de ANTswers incluían preguntas sobre ANTswers, y mayoritariamente preguntaban al bot cuál era su nombre, como se encontraba y si era un humano.
Parte de esta primera capa también se desarrolló para hacer un seguimiento del tipo de preguntas que formulaban los usuarios y para determinar si las frases que habían tecleado eran declarativas, exclamativas, imperativas o interrogativas. Además del tipo de oración, se hizo un seguimiento del uso de blasfemias, URL y preguntas repetitivas. En esencia, teníamos un doble objetivo: ofrecer una mejor información a la programación del bot en el futuro y compartir nuestras conclusiones con proveedores de referencia, especialmente, aquellos que trabajan en un entorno en línea. Se constató que la mayoría de oraciones de los clientes eran interrogativas o imperativas. Las oraciones interrogativas suponían el 50% del texto introducido por los clientes (n=10.051), mientras que las frases imperativas y declarativas suponían el 29%.
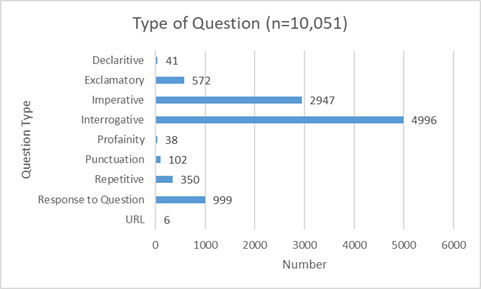
Figura 7. Tipo de oraciones enviadas por los usuarios del bot
Se creó una segunda capa a UAM CorpusTool para evaluar el contexto de los tipos de oraciones enviadas por los clientes de las bibliotecas. Mediante el uso del sitio web de UCI Libraries como modelo para esta capa, se organizaron los servicios y los elementos solicitados en categorías generales: About (the Library) [Sobre (la biblioteca)], About (UCI) [Sobre (UCI)], Find [Buscar], Services [Servicios] y Subject [Tema]. A continuación, se afinaron más las categorías genéricas. Por ejemplo, se hizo que la categoría About (the Library) incluyera Hours [Horario], About us [Sobre nosotros], Visit [Visitar], News/events [Noticias/Eventos] y Donate [Donativos]. Cada frase se asignó a la categoría general correspondiente y, a continuación, en la categoría más limitada pertinente. A consecuencia de la complejidad de nuestro sistema bibliotecario y los recursos proporcionados, algunas categorías se tuvieron que afinar aún más. Nuestras conclusiones muestran que el mayor número de solicitudes se produjo en la categoría Services, concretamente en Borrowing [Préstamos] (699 solicitudes o el 20% del total), seguida por Computing [Informática] (496 o el 14% del total). A continuación, las categorías consultadas con más frecuencia son Find (Books/eBooks) [Buscar (libros/libros electrónicos)] con 398 o un 11%) y después Hours dentro de la categoría About (the Library) (285 u 8 %) (Kane, 2019).
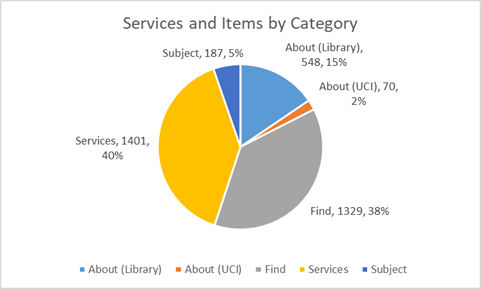
Figura 8. Servicios y elementos de ANTswers por categoría
Se puede hallar un análisis más detallado de ANTswers en el artículo Analyzing an Interactive Chatbot and its Impact on Academic Reference Services (Association of College and Research Libraries).
5 Conclusión
Los datos de ANTswers ya han demostrado ser útiles al realizar modificaciones en el sitio web de UCI Libraries, ya que han aportado pruebas materiales del número más elevado de solicitudes para cierta información, como el horario de las bibliotecas. Los datos de ANTswers se emplearon como base para un sistema de etiquetado para una plataforma de búsqueda de código abierto compatible con las bibliotecas (Solr) que UCI utilizó antes de implementar una búsqueda federada llamada Library Search en 2018. las estadísticas periódicas sobre el uso del bot, incluidos los tipos de recursos y servicios que solicitan los usuarios de las bibliotecas, se comparten con el personal de atención al público de forma regular y pueden aportar información valiosa los bibliotecarios sobre los recursos que habría que añadir a las guías de investigación. La información sobre cómo los usuarios de las bibliotecas utilizan el programa informático permite al programador del bot mejorar el sistema de forma continuada, algo necesario para garantizar que la base de datos dorsal de categorías continúe creciendo.
En el futuro, llevar a cabo el mismo análisis del servicio QuestionPoint de las bibliotecas, y compararlo después con ANTswers podría aportar información valiosa sobre cómo se relacionan los dos sistemas y cómo deberíamos abordar los servicios de referencia en línea y en persona en el futuro. Otros estudios interesantes también podrían incluir un análisis semántico y una evaluación de la idoneidad de las respuestas de ANTswers.
Bibliografía
Brandtzaeg P. B., and Følstad A., 2017. Why People Use Chatbots. En: Kompatsiaris I. et al. (eds) Internet Science. INSCI 2017. Lecture Notes in Computer Science, vol. 10673.
Christenson, A., 2007. A Trend from Germany: Library Chatbots in Digital Reference. Digital Libraries a la Carte, Module 2.
Educause, 2019. Educause Horizon Report: 2019 Higher Education Edition. [En línea] Disponible en: https://library.educause.edu/-/media/files/library/2019/4/2019horizonreport.pdf?la=en&hash=C8E8D444AF372E705FA1BF9D4FF0DD4CC6F0FDD1 [Consulta: 28 de juny de 2019].
Kane, D. A., 2016. The Role of Chatbots in Teaching and Learning. A: R. Scott & M. N. Gregor, eds. E-Learning and the Academic Library: Essays on Innovative Initiatives. s.l.: McFarland, p. 131–147.
Kane, D., 2017a. ANTswers. [En línea] Disponible en: https://github.com/UCI-Libraries/ANTswers
Kane, D., 2017b. UCI Libraries’ Chatbot Files (ANTswers). [En línea] Disponible en: https://dash.lib.uci.edu/stash/dataset/doi:10.7280/D1P075
Kane, D., 2019. Analyzing an Interactive Chatbot and its Impact on Academic Reference Services. Cleveland, Association of College and Research Libraries (ACRL).
McNeal, M. and Newyear D., 2013. Introducing chatbots in libraries. Library Technology Reports, 49(8), p. 5–10.
Vincze, J., 2017. Virtual reference librarians (Chatbots). Library Hi Tech News, 34(4), p. 5–8.
Wallace, R., 2003. The Elements of AIML Style. [En línea] Disponible en: http://www.alicebot.org/style.pdf [Consulta: 3 de juliol de 2019].
Xu, A. et al., 2017. A New Chatbot for Customer Service on Social Media. New York, Proceedings of the ACM Conference on Human Factors in Computing Systems.
 licencia de Creative Commons de tipo «Reconocimiento-NoComercial-SinObraDerivada«. Esto significa que se pueden consultar y difundir libremente siempre que se cite el autor y el editor con los elementos que constan en la opción «Cita recomendada» que se indica en cada uno de los artículos, pero que no se puede hacer ninguna obra derivada (traducción, cambio de formato, etc.) sin permiso del editor. En este sentido, se cumple con la definición de open access de la Declaración de Budapest en favor del acceso abierto. La revista permite al autor o autores mantener los derechos de autor y retener los derechos de publicación sin restricciones.
licencia de Creative Commons de tipo «Reconocimiento-NoComercial-SinObraDerivada«. Esto significa que se pueden consultar y difundir libremente siempre que se cite el autor y el editor con los elementos que constan en la opción «Cita recomendada» que se indica en cada uno de los artículos, pero que no se puede hacer ninguna obra derivada (traducción, cambio de formato, etc.) sin permiso del editor. En este sentido, se cumple con la definición de open access de la Declaración de Budapest en favor del acceso abierto. La revista permite al autor o autores mantener los derechos de autor y retener los derechos de publicación sin restricciones.