
[Versió catalana] [Versión castellana]
Danielle Kane
Research Librarian for Emerging Technologies
University of California, Irvine
Summary
Part 1 of this paper discusses how to create and manage an academic library chatbot, including the type of statistics that should be kept and the importance of regularly reviewing transcripts. Created in 2014, the chatbot in question has been developed to the point where, on average, it correctly answers library users’ questions 70% of the time. Part 2 is an analysis of over 10,000 user-submitted sentences (questions and statements). The analysis used UAM CorpusTool to create layers and code transcripts according to sentence structure, opening and closing statements, showing interest, and types of service and materials requested. While the library chatbot is clearly marked as being a computer program, a number of users regularly treat the chatbot as human and hold long non-library related conversations with it.
Resum
La primera part d’aquest article analitza com crear i gestionar un bot de conversa a biblioteques acadèmiques, incloent-hi el tipus d’estadístiques que s’haurien d’elaborar i la importància de revisar periòdicament les transcripcions. Creat l’any 2014, el bot de conversa en qüestió s’ha desenvolupat fins al punt en què, de mitjana, contesta correctament les preguntes dels usuaris de les biblioteques en un 70 % dels casos. La segona part és una anàlisi de més de 10.000 frases enviades pels usuaris (preguntes i afirmacions). L’anàlisi va emprar l’eina UAM CorpusTool per tal de crear capes i transcripcions de codi d’acord amb l’estructura de les frases, les afirmacions d’obertura i tancament, l’interès mostrat, així com els tipus de serveis i materials sol·licitats. Si bé el bot de conversa de les biblioteques està clarament identificat com un programa informàtic, una sèrie d’usuaris tracten habitualment el bot de conversa com si fos un ésser humà i hi mantenen llargues converses no relacionades amb les biblioteques.
Resumen
La primera parte de este artículo analiza cómo crear y gestionar un bot de conversación en bibliotecas académicas, incluyendo el tipo de estadísticas que deberían elaborarse y la importancia de revisar periódicamente las transcripciones. Creado en 2014, el bot de conversación en cuestión se ha desarrollado hasta el punto en que, de media, contesta correctamente las preguntas de los usuarios de las bibliotecas en un 70% de los casos. La segunda parte es un análisis de más de 10.000 frases enviadas por los usuarios (preguntas y afirmaciones). El análisis empleó la herramienta UAM CorpusTool para crear capas y transcripciones de código de acuerdo con la estructura de las frases, las afirmaciones de apertura y cierre, el interés mostrado, así como los tipos de servicios y materiales solicitados. Si bien el bot de conversación de las bibliotecas está claramente identificado como un programa informático, una serie de usuarios tratan habitualmente el bot de conversación como si fuera un ser humano y mantienen largas conversaciones no relacionadas con las bibliotecas.
1 Introduction
The 2019 Educause Horizon Report calculates that artificial intelligence has a time-to-adoption horizon of 2 to 3 years and states that “AI’s ability to personalize experiences, reduce workloads, and assist with analysis of large and complex data sets recommends it to educational applications” (Educause, 2019). One particular type of AI software, the chatbot, can be used to simulate conversation with a user by using Natural Language Processing. Chatbots can streamline interactions between services and people and enhance patrons’ experience of a library’s services. Machines are capable of reproducing the human processes of learning, reasoning and self-correction by using computer programs and code: they can learn by acquiring information and using pre-established rules to determine how to utilize that information; they can reason by using rules to reach approximate or even definite conclusions; finally, they can also self-correct or be corrected so that they do not give the user anomalous information.
By mimicking messaging applications, chatbots can interface with websites, mobile apps, hardware (e.g., Alexa skill), or even telephone trees. But no matter what type of application or system is chosen to create a chatbot, human intervention will be crucial. Humans will be needed to configure, train, and optimize the system. Proposed in April of 2013, our chatbot ANTswers (http://antswers.lib.uci.edu/) took approximately one year to develop. While we used open-source technology to create ANTswers it was not without cost, and took our programmers considerable time to create all of the necessary categories for the chatbot to function.
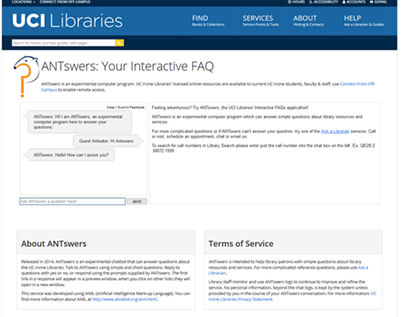
Figure 1. ANTswers graphical user interface
In our university context, reference departments have a long history of offering virtual reference services to remote and on-campus patrons. UCI Libraries offer email, QuestionPoint, IM and appointment-based research consultations using tools like Google+ Hangouts. McNeal & Newyear (2013) state that requests for specific materials, locations, hours, and policies predominate in chat and IM conversations. Since these are the types of requests for information that chatbots can answer well, they offer a self-service option for patrons. Using online tools allows us to meet the patrons where they are located and at the point of need. Chatbots enable librarians to push the limits of offering assistance and instruction 24/7 without adding to a suite of reference services that require in-person assistance. As staffing changes and new priorities are defined by the library, it can become difficult to staff reference services; by contrast, a chatbot can cost less staff time to manage.
2 Creating a chatbot
The University of California, Irvine (UCI) is a large public research university located in Irvine, California and one of the 10 campuses in the University of California system. UCI has an full-time equivalent count of over 11,000 faculty and staff with a student population of more than 35,000, while UCI Libraries has 59 librarians and 100 staff. UCI Libraries comprises four different libraries: the Langson Library, which supports research and teaching in the humanities and social science, the Science Library, the Grunigen Medical Library, and the Law library. We provide reference services at our Ask Us desk at the Langson Library along with in-person and online 30-minute research consultations. We also participate in email, phone and QuestionPoint 24/7 chat reference services. In the past year, UCI staff have answered over 12,000 reference questions.
As with any large project, the initial planning and organization are key in building a successful chatbot. In April of 2013, a proposal was submitted to UCI Libraries administration detailing what a chatbot was and the possible impact it could have on our reference services. The proposal reviewed the different types of chatbots and provided a recommendation which would best fit our libraries’ needs. This took the form of ANTswers, which was created as a web-based application using Program-O running on a remote server. Web-based chatbots offer more flexibility but require experience with HTML, PHP, CSS, JavaScript, and AIML (Artificial Intelligence Markup Language). Program-O (http://blog.program-o.com/) is an open-source AIML engine written in PHP with MySQL. While there are several freely available and open-source AIML engines available, UCI Libraries chose Program-O because of its features, which include a spell check, bot personality settings, a SRAI lookup feature, and the ability to add and edit botmaster accounts.
The emerging technologies team stated that a library chatbot could bridge a gap in the library reference services being offered at the time and generally augment those services. QuestionPoint is an excellent 24/7 service staffed by trained and knowledgeable library staff but it was considered to offer more than patrons actually need when they have a simple directional or factual question. For that type of situation, having to enter your contact information and name can be an unnecessary investment of time, and some patrons are also reticent about asking library staff questions. While chatbots “cannot replicate the complexity of human interaction, [they] can provide a cost-effective way to answer the majority of routine reference questions” (Vincze, 2017). In a nutshell, the chatbot offered us the opportunity to:
- enhance rather than replace available reference services;
- serve a large number of people at any one time of the day;
- serve a wide range of library patrons;
- serve as triage for library staff by answering basic, repetitive questions (“Where is the stapler?”, “How do I print?”, etc.).
Early in the process, a team of key stakeholders from the library was appointed and met regularly to consider such questions as whether the chatbot should only be programmed to field library-related consultations or whether it should be able to engage in more general “conversation”. Chatbots can be seen as a way to pass the time or as “a way to avoid loneliness or fulfill a desire for socialization” (Brandtzaeg and Følstad, 2017). Another question was, should the chatbot have a personality and, if so, what kind of personality? The team helped formulate how the chatbot should interact with our students. So while it is made extremely clear that ANTswers is a computer program, the team decided early on in the process to provide ANTswers with a personality based on the UCI mascot “Peter the Anteater”. With this in mind, ANTswers was fashioned as an anteater who loves ants and everything to do with UCI. Program-O makes it easy to develop a personality for a chatbot by providing an easy to fill out “form.”

Figure 2. Program-O’s bot personality interface
Program-O allows files to be added and removed from the system but not replaced. To deal with this system limitation, a file naming scheme was determined early in the process. The Artificial Intelligence Foundation (A.L.I.C.E – https://code.google.com/p/aiml-en-us-foundation-alice/) offers a number of open-source files for download. These files contain the bulk of the general conversation categories and have been extensively adapted and cleaned for use in an academic library setting. The files are available on GitHub (Kane, 2017a). Two bot files which contain the code to remember information about the chatbot and the chatter are prepended with the letter “b”. Six ready reference files give factual answers on general topics like science, history, and geography, and are prepended with “r.” Organized by service, location, or resource, the 20 library files are labeled “lib.” Finally, 66 subject files organized by Library of Congress classification contain resource recommendations for keywords and are prepended with “s”.
Many programs can be used to create and edit AIML files, including Notepad, Atom, Vim and Notepad++. For ANTswers we used Notepad++, which is a free, open-source editor for the Windows platform. Notepad++ provides some useful functionality, such as searches across files and within folders. While users with little programming experience may initially be apprehensive about learning AIML, it is actually a simple language that is easy to learn and can operate without relying on “the conventional wisdom from structured programming” (Wallace, 2003). The tags <category>, <pattern>, and <template> are the basic units of knowledge for AIML, where category is the unit of knowledge, pattern refers to the patron-submitted input represented by keywords, phrases, or sentences, and template contains the chatbot answer. A simple AIML expression can then be represented as follows:
<category><pattern>INPUT</pattern>
<template>OUTPUT</template></category>
Below is an example of a simple AIML category:
<category><pattern>I NEED HELP</pattern>
<template>Can you ask for help in the form of a question?</template></category>
AIML also allows the use of knowledge tags, which trigger the chatbot to save data, activate a different program or give a conditional response. UCI Libraries created a specific tag <antpac> to pull book records from our catalog, and the tag was updated when the library switched to Library Search in 2018. AIML also allows symbolic reductions, which is useful when a programmer accepts “don’t care” (wild-card) symbols. Using the symbol “*” as a wildcard gives us the examples of “keyword,” “* keyword,” “keyword *,” and “* keyword *.” Using symbolic reductions will increase the possibility that categories will be picked up and the correct answer will be provided.
Another tag, <that>, allows the programmer to connect certain categories, which is useful if the chatbot needs to ask the patron a follow-up question. For example, if the question asked is “I want more information on anteaters,” the chatbot returns a response asking the user if they are looking for books or articles. Typing that you want more information triggers a booksorarticles pickup line. Knowing if you want books or articles, combined with the “*” input, in this case, a subject or keyword, returns the appropriate response. A sourcetype value of books triggers a catalog search using the “*” input. Stating that you want articles, returns from one to three subject librarian recommendations. The first resource URL will open in the window below the chatbot. Resource recommendations also include a link to the subject guide, thereby linking users to more resources.
A more detailed account of the development of ANTswers can be found in the Role of Chatbots in Teaching and Learning in E-Learning and the Academic Library: Essays on Innovative Initiatives. Alternatively, the reader can do one of a number of tutorials that exist on AIML programing language and the tags that can be used, such as TutorialsPoint (https://www.tutorialspoint.com/aiml/aiml_introduction.htm).
3 Managing a chatbot
To successfully manage a chatbot like ANTswers requires continuous review and updating. When the chatbot was in beta, the transcripts were reviewed on a daily basis five days a week, statistics were completed for each transcript and changes were made to the code to resolve any issues found. The updated code was then uploaded back into Program-O at the end of each transcript review. Changes typically made to ANTswers include adding new categories or adding new terms to existing categories. Since UCI has a large international student body, the programmer needs to add new terms or phrases on a regular basis to ensure that ANTswers can respond to queries made in English that is grammatically incorrect.
Program-O could not be used to evaluate and track statistics for ANTswers because the program cannot mark transcripts as ‘read’ or add statistics to the system. Also, the program shows the oldest conversations first and there is no way to search for specific transcripts. It was determined that a back-end system was required. Using MySQL, a library programmer was able to pull transcripts from Program-O into an online database where statistics could be entered. The reviewed date is used as a visual note that the transcript has been reviewed and that any changes to the code has been made. Transcripts and statistics can be downloaded from the online database and pulled into other tools for analysis. When the chatbot was still new, reviewing transcripts and completing statistics took between five and six hours a week. As ANTswers categories grew and the answer percentage rate increased, the online database needed to be reviewed two or three times a week and now takes between one and three hours.
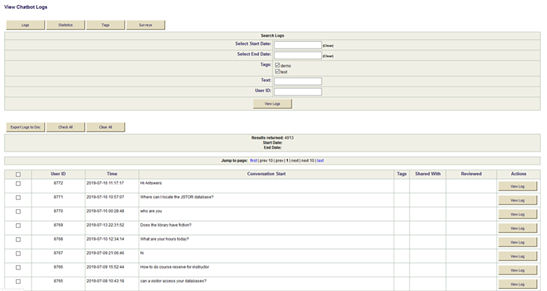
Figure 3. ANTSwers back-end management system
4 Analyzing a chatbot
4.1 General Statistics
Every chatbot transcript is reviewed via the back-end system. As part of this review, the following statistics are kept for each patron-submitted transcript:
- Date
- Time of day
- Academic quarter
- Week of the academic quarter
- Day of the week
- Total number of questions
- Number of library-related questions and answer rate percentage
- Number of general questions and answer rate percentage
- Context of the transcript – what patrons are asking for
- READ Scale
The data is downloaded to an Access database connected to Excel, where Pivot tables are used to create visualizations for each academic quarter (note that UCI operates on the quarter rather than tri-semester system). Since ANTswers was introduced, in 2014, a total of 12,202 questions have been asked, of which 7,770 (64%) are library-related. While it would be simpler to create and maintain a chatbot that only dealt with library-related questions, we also included the possibility of general responses for those patrons that just want to chat. Data is packaged by year and shared through the University of California’s online data publication service Dash. When ANTswers was first implemented as a beta test it had an average answered percentage rate of 39% for library-related questions. The work updating has helped to increase that rate.
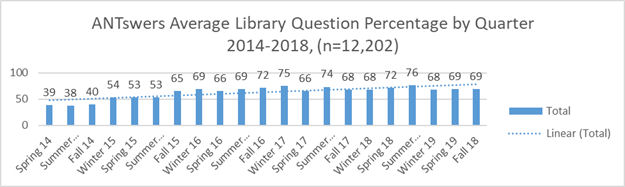
Figure 4. ANTswers average library-related question percentage by quarter in the period 2014–2018
These statistics help determine when ANTswers can be taken down for maintenance. For example, ANTswers is very frequently used during weeks 2 and 3 of each new quarter (note that there are approximately 10 weeks in each quarter). Patrons are more likely to ask questions Monday through Thursday and from 8 a.m. to 7 p.m., though it should be noted that patrons ask questions 24 hours a day 7 days a week. Generally speaking, the highest number of questions were asked during weeks 1, 2, and 3 of each quarter. Usage is highest Monday through Thursday, with Friday through Sunday seeing a drop of approximately 50%. During the last weeks of each quarter, the best time to conduct maintenance on the chatbot is early Friday morning, while more extensive updates and maintenance are reserved for the summer, when there are fewer students on campus. While usage has dropped since 2015, this has more to do with changes in the library website homepage, which pushed the chatbot link down to the bottom of the page (during the beta period the link occupied a prime location above the fold).
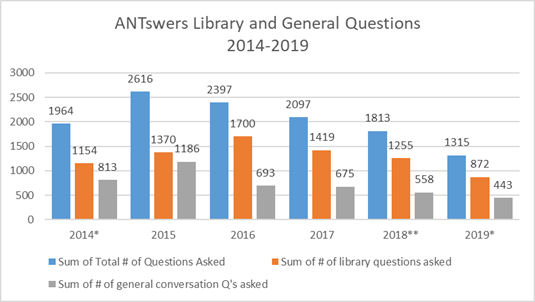
Figure 5. ANTswers library-related and general questions in the period 2014–2019
According to Christensen (2007), chatbots do not “steal” reference questions away from librarians; instead, they can be used to field simple reference and frequently ask questions about the following:
- navigating a website;
- links to other websites and documents;
- access to OPAC records;
- the basics of online library tasks;
- interlibrary loan materials;
- searching for materials in databases.
While an examination of UCI Libraries’ reference statistics might suggest that ANTswers did affect our overall statistics, a number of things have occurred since the chatbot went live in 2014. Over time, we have shortened our desk hours in response to decreased needs in the early and later hours of the day. At times, due to staffing constraints, we went from having the reference desk open on both Saturday and Sunday to opening on Sundays only and then to not having reference hours at all on the weekends. Our Access Services no longer records reference statistics either. During this period, we also switched to the six-point scale tool READ (Reference Effort Assessment Data) and found, after tracking the READ scale for each ANTswers transcript, that these were predominately directional and were therefore coded as 1, leaving very few in the scales from 2 to 6.
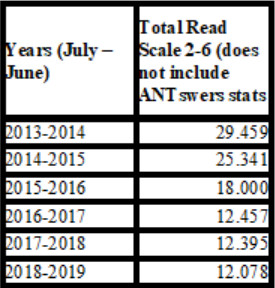
Figure 6. UC Irvine total reference numbers for READ scales 2–6 in the period 2013–2019.
4.2 Text-analysis of chatbot transcripts
An analysis of chat transcripts from the inception of ANTswers in March of 2014 through April of 2018 was conducted to determine how patrons were asking questions and what types of resources/services they were asking about. Each of the 7,924 chat transcripts collected was evaluated to determine whether it was a true (patron-submitted) transcript or else a test, demonstration of the system or spam. After the transcripts were reviewed, 2,786 transcripts were further reviewed for confidential information (such as the patron’s first name), and this information and ANTswers responses were removed before the transcripts were loaded into UAM CorpusTool (Version 3) by their associated user ID. The transcripts contained a total of 10,341 library user sentences (questions and statements). UAM CorpusTool can be used to create layers and so one was created to analyze how users were asking questions and another was developed to track what they were asking for.
The first layer created in the UAM CorpusTool analyzed how patrons were asking questions but also determined if they were using opening and closing phrases, and if they were showing interest in the chatbot. Greetings are considered a basic function of communication and common courtesy when starting a conversation, and it was found that patrons used some form of greeting in 460 (17%) of the 2,786 transcripts The most frequently used greetings were “hello” and “hi. ” On the other hand, closing phrases were only used in 5% of the transcripts, where the most common were “thank you” or “thanks.” A recent study by Xu et al. on customer service chatbots found that 40% of user requests are emotional rather than informational (Xu, 2017). Only 248 of the ANTswers transcripts included questions about ANTswers, and these mostly asked the chatbot its name, how it was and whether it was human.
Part of the first layer was also developed to track the type of questions patrons asked and determine whether the sentences they had keyed in were declarative, exclamatory, imperative or interrogative. In addition to sentence type, the use of profanity, URLs, and repetitive questions were tracked. Essentially, our goals were twofold: to better inform chatbot programming in the future and to share our findings with reference providers, especially those working in an online environment. It was found that most patrons’ sentences were interrogative or imperative. Interrogative sentences accounted for 50% of the patron-provided input (n=10,051 ) and imperative and declarative sentences accounted for 29%.
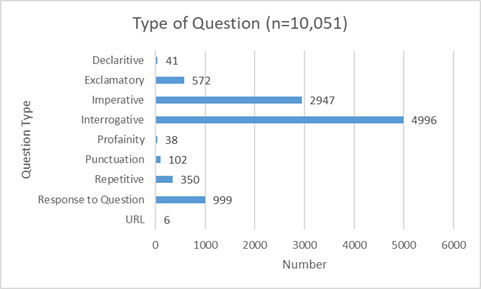
Figure 7. Types of sentences submitted by chatbot users
A second layer was created in UAM CorpusTool to evaluate the context of the types of sentences library patrons submitted. Using the UCI Libraries website as a model for the layer, services and requested items were organized into broad categories: About (the Library), About (UCI), Find, Services, and Subject. The broader categories were then further refined. For example, the category About (the Library) was made to include Hours, About us, Visit, News/events and Donate. Each sentence was placed in the appropriate broad category and then into the appropriate narrow category. Due to the complexity of our library system and the resources provided, some categories needed to be refined further. Our findings show that the highest number of requests were made in the Services category, specifically in Borrowing (699 requests or 20% of the total), and then in Computing (496 or 14% of the total). Next, the most frequently consulted categories were Find (Books/eBooks at 398 or 11%) and then Hours in About (the Library) (285 or 8%) (Kane, 2019).
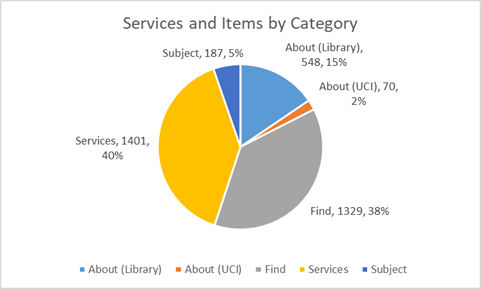
Figure 8. ANTswers services and items by category
A more detailed account of the analysis of ANTswers can be found in the paper Analyzing an Interactive Chatbot and its Impact on Academic Reference Services (Association of College and Research Libraries).
5 Conclusion
ANTswers data has already proved to be useful when making changes to the UCI Libraries’ website by providing supporting evidence of the highest number of requests for certain information, such as library hours. ANTswers data was used as the basis for a tagging system for a library-supported open-source search platform (Solr) that UCI used before implementing a federated search called Library Search in 2018. Regular statistics on how the chatbot is used, including the types of resources and services that library users request, is shared with public services staff on a regular basis and can provide librarians with valuable information on the resources that should be added to Research Guides. Insights into how library users utilize the computer program allows the chatbot programmer to continuously improve the system, which is necessary to ensure that the back-end database of categories continues to grow.
In the future, running the same analysis on the Libraries’ QuestionPoint service and then comparing this to ANTswers could provide valuable information on how the two systems compare and how we should approach in-person online reference services in the future. Other interesting studies could also include a sentiment analysis and an evaluation of the appropriateness of ANTswers responses.
Bibliography
Brandtzaeg P.B., and Følstad A., 2017. Why People Use Chatbots. In: Kompatsiaris I. et al. (eds) Internet Science. INSCI 2017. Lecture Notes in Computer Science, vol 10673.
Christenson, A., 2007. A Trend from Germany: Library Chatbots in Digital Reference. Digital Libraries a la Carte, Module 2.
Educause, 2019. Educause Horizon Report: 2019 Higher Education Edition. [Online] Available at: https://library.educause.edu/-/media/files/library/2019/4/2019horizonreport.pdf?la=en&hash=C8E8D444AF372E705FA1BF9D4FF0DD4CC6F0FDD1 [Accessed 28 June 2019].
Kane, D. A., 2016. The Role of Chatbots in Teaching and Learning. In: R. Scott & M. N. Gregor, eds. E-Learning and the Academic Library: Essays on Innovative Initiatives. s.l.: McFarland, pp. 131–147.
Kane, D., 2017a. ANTswers. [Online] Available at: https://github.com/UCI-Libraries/ANTswers
Kane, D., 2017b. UCI Libraries’ Chatbot Files (ANTswers). [Online] Available at: https://dash.lib.uci.edu/stash/dataset/doi:10.7280/D1P075
Kane, D., 2019. Analyzing an Interactive Chatbot and its Impact on Academic Reference Services. Cleveland, Association of College and Research Libraries (ACRL).
McNeal, M. and Newyear D., 2013. Introducing chatbots in libraries. Library Technology Reports, 49(8), pp. 5–10.
Vincze, J., 2017. Virtual reference librarians (Chatbots). Library Hi Tech News, 34(4), pp. 5–8.
Wallace, R., 2003. The Elements of AIML Style. [Online] Available at: http://www.alicebot.org/style.pdf [Accessed 3 July 2019].
Xu, A. et al., 2017. A New Chatbot for Customer Service on Social Media. New York, Proceedings of the ACM Conference on Human Factors in Computing Systems.
 Creative Commons licence (Attribution-Non-Commercial-No Derivative works). They may be consulted and distributed freely provided that the author and publisher are quoted (in accordance with the “Recommended citation” section in each of the articles). However, no derivative works (translation, change of format, etc.) may be made without the publisher’s permission. Therefore, it meets the definition of open access form the Budapest Open Access Initiative declaration. The journal allows the author(s) to hold the copyright without restrictions and to retain publishing rights without restrictions.
Creative Commons licence (Attribution-Non-Commercial-No Derivative works). They may be consulted and distributed freely provided that the author and publisher are quoted (in accordance with the “Recommended citation” section in each of the articles). However, no derivative works (translation, change of format, etc.) may be made without the publisher’s permission. Therefore, it meets the definition of open access form the Budapest Open Access Initiative declaration. The journal allows the author(s) to hold the copyright without restrictions and to retain publishing rights without restrictions.