
Aina Giones-Valls
Documentalista
Nubilum
Ferran Giones
Investigador
La Salle – Universitat Ramon Llull
Resumen
Objetivos: este artículo reflexiona sobre el surgimiento de los fenómenos lifelogging y quantified self como una forma de vivir a través de los datos personales generados por el propio usuario. Se analizan la perspectiva social y tecnológica haciendo énfasis en la gestión de los datos, y se describe cómo los principios de la inteligencia de datos (big data) permiten entender las oportunidades y complejidades que generan estos fenómenos.
Metodología: se ha revisado la bibliografía publicada sobre los fenómenos lifelogging y quantified self desde su aparición hasta nuestros días. La búsqueda bibliográfica se ha realizado en bases de datos bibliográficas para los artículos y mediante buscadores generalistas para la información de los productos y aplicaciones, así como para las noticias de actualidad aparecidas en la prensa local e internacional.
Resultados: el resultado es una taxonomía de usos, aplicaciones y herramientas de lifelogging y quantified self. Se concluye que un factor determinante en su evolución será la capacidad de generar información de «calidad» a partir de los datos generados por el usuario. En ambos casos se ve necesario establecer estándares y protocolos que permitan una estructuración, gestión y análisis de los datos con el fin de optimizar los potenciales impactos positivos que puede generar el fenómeno del quantified self a la sociedad.
Resum
Objectius: aquest article reflexiona sobre el sorgiment dels fenòmens lifelogging i quantified self com una forma de viure a través de les dades personals generades pel mateix usuari. S’analitza la perspectiva social i tecnològica fent èmfasi en la gestió de les dades, i es descriu com els principis de les dades massives (big data) permeten entendre les oportunitats i complexitats que generen aquests fenòmens.
Metodologia: s’ha revisat la bibliografia publicada sobre els fenòmens lifelogging i quantified self des de la seva aparició fins als nostres dies. La recerca bibliogràfica s’ha fet mitjançant bases de dades bibliogràfiques pels articles i cercadors generalistes per a la informació dels productes i aplicacions, així com per les notícies d’actualitat aparegudes a la premsa local i internacional.
Resultats: el resultat és una taxonomia d’usos, aplicacions i eines de lifelogging i quantified self. Es conclou que un factor determinant en la seva evolució serà la capacitat de generar informació de «qualitat» a partir de les dades generades per l’usuari. En els dos casos es veu necessari establir estàndards i protocols que permetin una estructuració, gestió i anàlisi de les dades per tal d’optimitzar els potencials impactes positius que pot generar el fenomen del quantified self a la societat.
Abstract
Objectives: This paper uses data generated by users to reflect on the emergent paradigm of lifelogging or quantified self as a lifestyle. It analyses the social and technological aspects of this phenomenon, focusing on data management, and it describes how the principles of big data enable us to understand the opportunities and complexities that quantified self is responsible for.
Methodology: The paper revises the bibliography published on lifelogging and quantified self from its beginnings to the present. The bibliographic search was completed using bibliographic databases for the articles and general search engines for information on products and applications and for news articles in the local and international press.
Results: The result is a taxonomy of uses, applications and tools for lifelogging and quantified self. The researchers conclude that the ability to generate quality information from user-generated data will be key in the development of this paradigm. It will also be necessary to establish standards and protocols to organize, manage and analyse the data so that the potentially positive impact of quantified self on society can be optimized.
Ya no se trata tanto sobre small data o big data sino sobre nuestros datos.
Gary Wolf
1 Introducción
La humanidad, a lo largo de su historia, ha realizado importantes esfuerzos para conservar datos, documentos y efectos personales como testimonio de su trayectoria vital. En la actualidad, la tecnología ha favorecido que el volumen de los datos, especialmente en formato digital, se haya disparado al mismo tiempo que lo ha hecho la capacidad de compartir, almacenar y explotar estos datos, pudiendo generar inferencias sobre nuestra trayectoria vital.
Esta forma generalizada de capturar datos e información multimodal se define como lifelogging (Dodge; Kitchin, 2007). El fenómeno del lifelogging se caracteriza por ser un proceso de recogida de datos realizado por sensores que capturan datos ambientales y del usuario, que pasa a tener un rol pasivo en el proceso de recogida y conservación de los datos. Los sensores son incorporados, por ejemplo, en relojes, gafas o ropa que el usuario lleva y que registran su actividad vital.
Vinculado al lifelogging ha aparecido el movimiento quantified self (Wolf, 2010a), término que agrupa tanto el registro de datos como su explotación con una finalidad concreta (por ejemplo, generar una síntesis de las principales actividades realizadas durante un día), con el objetivo de identificar patrones de comportamiento, tanto a escala individual como en comparación con otros usuarios o pautas de referencia.
El artículo se estructura en tres bloques principales: primero se describe la perspectiva desde los datos masivos (big data) de estos nuevos fenómenos; después se presenta en detalle el concepto de quantified self y un grupo de sus aplicaciones analizadas; se finaliza con una descripción de los retos de futuro que estos fenómenos nuevos plantean.
2 El lifelogging y el quantified self: los principios de los datos masivos aplicados al individuo
Viktor Mayer-Schönberger decía en una entrevista que los datos masivos serían una fuente de riqueza: el nuevo oro.1 Se consideran datos masivos cuando el volumen, la veracidad, la velocidad y la variedad de los datos (las cuatro V de los datos masivos)2 superan la capacidad establecida por los mecanismos tradicionales de capturar, gestionar y procesar datos en un tiempo razonable.
- Volumen: hace referencia a las cantidades masivas de datos que automáticamente se almacenan gracias a los sensores incorporados en teléfonos móviles o relojes que monitorizan la actividad de un individuo.
- Veracidad: la incertidumbre de los datos también está presente en su recopilación en el lifelogging o quatified self; toda la información derivada de la monitorización de los sentimientos del individuo (sentiment analysis) o las medidas automáticas de los sensores GPS pueden no ser completamente fiables.
- Velocidad: los datos de entrada se generan de forma continuada; por ejemplo, las aplicaciones que miden y almacenan en tiempo real las pulsaciones y movimientos de un usuario.
- Variedad: las herramientas de lifelogging y quantified self integran diferentes tipos y fuentes de datos, y combinan datos de múltiples sensores con datos generados por el usuario.
Por consiguiente, los fenómenos de quantified self o lifelogging son una fuente de datos masivos a pequeña escala en el ámbito personal, donde el usuario deviene responsable de sus datos. La popularización de estos fenómenos o movimientos ha generado posiciones enfrentadas. Mientras hay grupos que defienden estas actividades como un reflejo de la curiosidad humana (Wolf, 2010a), hay otros que los ven como una tendencia egocentrista que pone de relieve los riesgos como la exposición permanente a la red, la vulnerabilidad de los menores de edad, la pérdida de control del uso de la información privada de cada individuo, etc. (Gordo López; De Rivera; López Losada, 2013). En este último caso, se llega a plantear qué pasará con la capacidad memorística natural y dónde queda la privacidad de las personas cuando los datos dejan el ámbito individual para pertenecer y ser gestionados por terceros (Gordo López; De Rivera; López Losada, 2013).
3 El quantified self
Mientras el lifelogging se centra en la capacidad de incrementar el registro de datos, el movimiento quantified self (QS) hace referencia no sólo al registro de datos sino también a su explotación con la finalidad de identificar patrones de conducta. El QS es una forma avanzada de recoger datos de un individuo utilizando aplicaciones y herramientas tecnológicas para una finalidad concreta (Wolf, 2010b). Los datos recogidos son tanto inputs vinculados a acciones del usuario (ingesta de comida, agua, etc.) como estados de ánimo (alegría, inquietud, tristeza, etc.).
La aparición del termino quantified self se vincula al nacimiento del blog de Gary Wolf y Kevin Kelly en 2007 («The quantified self…», 2012; Wolf, 2010b). Alrededor de este blog se creó una comunidad meetup3 para organizar encuentros periódicos de interesados en desarrollar proyectos dentro de este ámbito y en la que se podían compartir metodologías relacionadas con los datos personales. El QS nació en San Francisco (EUA) y se extendió gracias a la evolución tecnológica tanto de los sensores que capturan los datos como de las aplicaciones que permiten un análisis y su visualización. Uno de los ejemplos más destacados de este potencial de análisis y visualización de los datos son los anuarios de infografías que Nicolas Felton ha ido recopilando desde el 2005 a partir de aplicaciones del QS y de sus notas manuscritas.4 Los orígenes del QS se remontan a la motivación personal de cuantificarse y recoger datos, para tener una información que permita substituir las intuiciones por certezas y mejorar la toma de decisiones del individuo (Wolf, 2010a). Gracias a la popularización de este movimiento y a la incorporación de sensores de bajo coste, el QS se ha convertido en la forma ideal de analizar datos de uno mismo de forma continuada (Swan, 2012).
En 2010 Wolf explicaba qué era el QS en un TED5 y lo describía como un juego con el que se distraían los early adopters; esta comunidad creía interesante monitorizarse, rastrearse y analizarse a partir de los patrones de datos que medían. Lo que empezó como un juego rápidamente evolucionó con contribuciones destacadas como la de Dave Asprey, propietario de Bulletproof, que creó una comunidad para cuidar del bienestar físico individual y que aconseja sobre temas de salud; o la de Gordon Bell, que capitanea MyLifeBits, proyecto que utilizando los datos registrados en el ordenador puede llegar a analizar el comportamiento global en Internet; o, finalmente, pero no menos importante, las aportaciones del ya mencionado Nicholas Felton en el ámbito de la visualización de grandes conjuntos de datos. Este movimiento minoritario en sus inicios se ha convertido en una tendencia social global hasta el punto de tener un impacto revolucionario en áreas como la salud o la educación (Lee, 2013; Swan, 2013). A pesar de la rápida evolución y adopción de sensores no siempre se ha visto acompañada de un desarrollo equivalente en las capacidades de análisis y generación de información a escala colectiva, y el QS ha quedado limitado principalmente al autoconsumo de información (Swan, 2013). Actualmente ya existen soluciones basadas en el quantified self presentes en nuestro quehacer diario como la incorporación de sensores en vehiculos6 que permiten conocer los patrones de movilidad y ofrecer a los conductores seguros de automóvil adaptados7 a sus necesidades. Se trata de aplicaciones y herramientas que ayudan a cuantificar los datos generados por nuestra actividad cotidiana.
3.1 Aplicaciones y herramientas de quantified self
A partir de la revisión bibliográfica y de la identificación de una selección de aplicaciones QS existentes en estos momentos en el mercado, los autores proponen una taxonomía de las aplicaciones más populares y originales basados en el quantified self. En función de las actividades cotidianas del usuario, los datos recogidos son distintos. A continuación se detallan los tipos de datos recogidos dentro de cada actividad de las aplicaciones analizadas:
- Hábitos lectores: contabilizan la cantidad y el tipo de libros que ha leído un usuario.
- Actividad física: recogen datos como el tiempo que se dedica a la actividad física (ir en bicicleta, correr, nadar, etc.).
- Ciclos nocturnos: monitorizan las horas de sueño.
- Alimentación: sugieren platos o establecimientos que cumplen con los gustos alimentarios personales o los platos que la aplicación ya sabe que han gustado al usuario.
- Acciones financieras: permiten llevar un control monetario de los ingresos y gastos de un individuo.
- Sentiment analysis: ayudan a saber cómo se siente alguien mediante preguntas referentes a su estado de ánimo.
- Gestión del tiempo: permiten contabilizar las horas que se dedican a cierta actividad.
- Geolocalización: mediante un GPS se recoge la ubicación del usuario.
- Datos cardíacos: miden la frecuencia cardíaca cuando se hace ejercicio.
A continuación se presenta un mapa conceptual en el que, imitando un mapa de metro, se dibuja una muestra de las aplicaciones de QS presentes en el mercado. Unidas por un mismo color se destacan las que forman parte de una misma categoría y destacadas con un punto amarillo las que capturan datos de dos categorías que interseccionan.
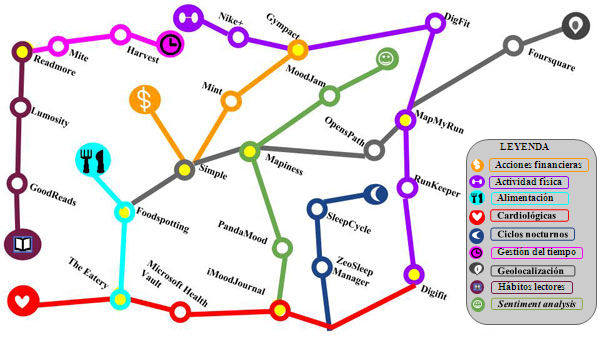
Figura 1. Mapa conceptual de las aplicaciones presentes en el mercado actualmente
En todas las aplicaciones presentes en el mapa, el usuario toma un rol de agente activo cuando voluntariamente es el emisor, o de agente pasivo cuando los datos vienen dados por el entorno. Así mismo, hay que destacar la proliferación de iniciativas que proponen hacer un uso socialmente responsable de los datos generados a través del quantified self. La plataforma DataDonors permite a los usuarios ceder sus datos sobre su estilo de vida o sobre su estado de salud para futuras investigaciones médicas o de la ciencia en general. Esta plataforma se compromete a no vender la información y a hacer un uso ético de los datos. El uso de datos de salud privados para posibles estudios es un tema que genera polémica; por ejemplo la Consejería de Sanidad de Cataluña ha visto frenada por el Parlamento de Cataluña su iniciativa de cesión a terceros de los datos sanitarios privados de los usuarios.8
3.2 Aplicaciones y herramientas del quantified self
Las aplicaciones y herramientas para cuantificarse son tan variadas como los datos que genera una persona en su día a día. A partir de la taxonomía del apartado anterior, se ha escogido una muestra de herramientas y aplicaciones de las que se ha analizado el ciclo de sus datos: qué tipos de datos recogen (cardiológicos, patrones de sueño, etc.), cómo se recogen (con una aplicación o un sensor), cómo se almacenan los datos, cómo se transmite la información y, finalmente, cómo es el formato de salida, visualización y publicación que utilizan.
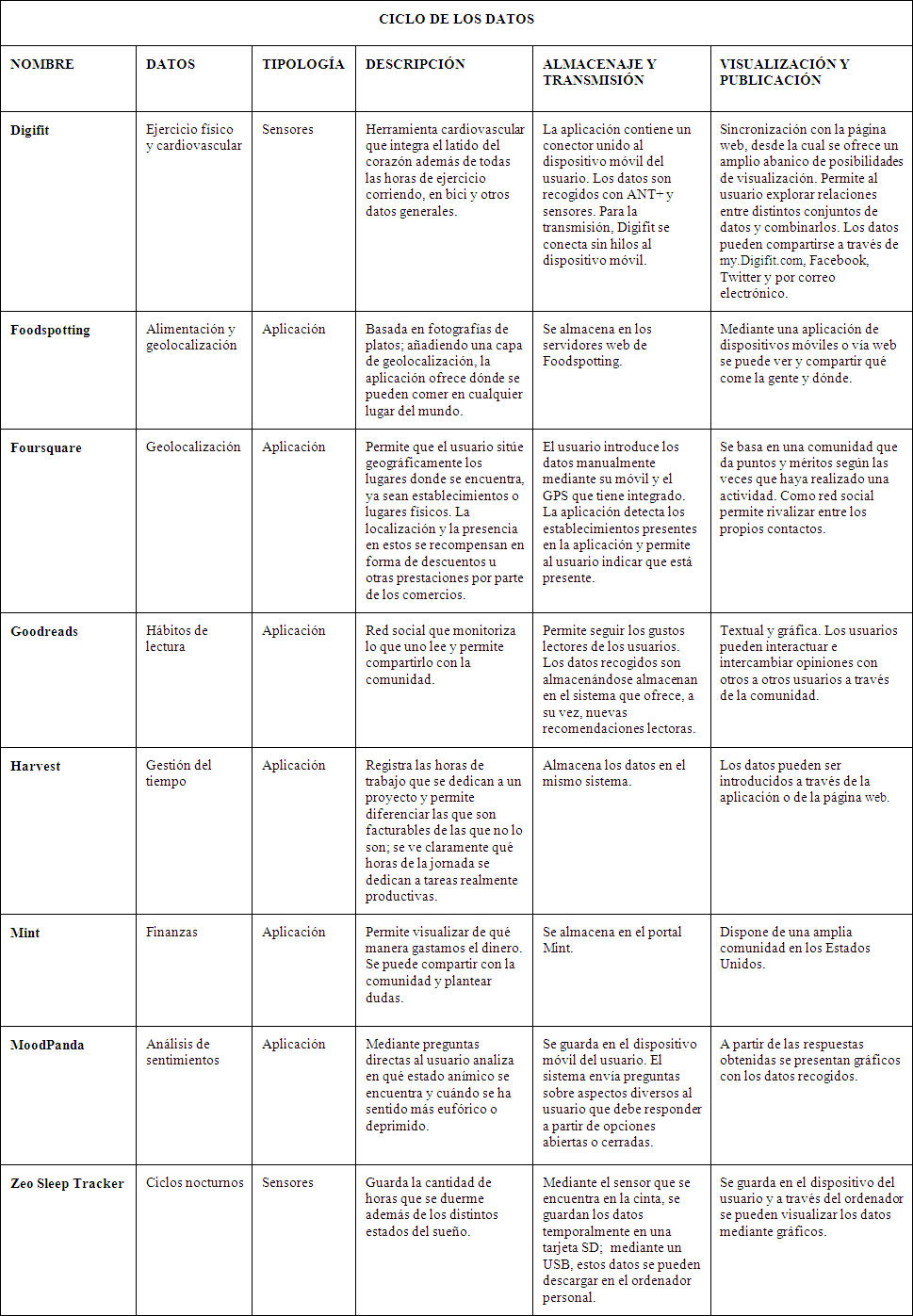
Tabla 1. Descripción del ciclo de datos de diferentes aplicaciones
3.3 Precauciones en clave de futuro del quantified self como datos masivos personales
Aunque el fenómeno del quantified self surge a partir de un perfil de usuario que conscientemente controla el proceso de recogida y análisis de los datos, su rápida evolución en los últimos años y las perspectivas de futuro hacen prever que una de las amenazas más importantes será la que afecta también a los datos masivos.
El hecho que la mayoría de QS funcionen como servicios digitales (que por otra parte facilita la adopción de estas herramientas) expone a los usuarios (y su histórico de datos) a vulnerabilidades que quedan relativizadas en los entornos digitales. A continuación se detallan diferentes fuentes de riesgo habituales cuando se usan las herramientas y aplicaciones QS:
- Navegadores: nuestro historial de navegación es un dato muy preciado para aquellos que se dedican a la minería de datos. Para dar respuesta a esta problemática se pueden utilizar navegadores no convencionales como Tor o Startpage, o incluso, activar el modo incógnito del navegador que puede reducir la utilización de nuestros datos por parte de terceros.
- Almacenamiento en la nube: es sabido que hay «granjas» de servidores interconectados que se dedican a hacer backlogs de nuestros archivos. Se aconseja que si se utiliza algún servicio de los que también integran el correo electrónico, se usen opciones como SpiderOak, Tresorit o DocumentClou.
- Paquetes de privacidad: para proteger la privacidad existen herramientas como Disconect, que ofrece una navegación privada y segura para menores de edad, o Freedome, que permite una navegación móvil más fiable.
- Redes sociales: empresas como Facebook, Tuenti, Twitter o MySpace ofrecen servicios gratuitos a cambio de nuestros datos. Para aprovechar al máximo estos servicios los usuarios tienden a ajustar la identidad digital a la real para que las empresas puedan realizar un perfil más ajustado de los usuarios. Con la idea de ofrecer otras redes sociales con sistemas que deben cruzar menos nodos (menos jerarquizados y libres de vigilancia comercial), aparecen redes sociales como Diaspora, gestionada por una comunidad que se describe como descentralizada, distribuida y respetuosa, que permite a los usuarios tener un mayor control de sus datos.
4 Retos de futuro para la explotación de datos personales en el quantified self
A pesar de hallarnos todavía en una fase inicial y de crecimiento del quantified self, existe la expectativa de que se convierta en una fuente de inteligencia colectiva aunque están alterándose aspectos que configuraron en su inicio el núcleo de este movimiento. Gracias a los datos generados por los early adopters, los sistemas y las aplicaciones tendrán cada vez más una programación más avanzada y nos ayudarán a una mejor toma de decisiones. Para llegar a este punto no sólo tendrán que avanzar los sistemas (y nosotros con ellos) sino que también será necesario solucionar y reflexionar sobre diferentes aspectos que afectan al QS, como son las fugas de información, los usos no controlados de los datos masivos o la vulnerabilidad de la privacidad de los datos, que no son propios del QS.
4.1 Datos masivos
Los análisis de datos que realizan actualmente las aplicaciones de cuantificación son simples. Existen pocas aplicaciones que integren los datos captados y los datos de los sensores que tiene un mismo usuario. Actualmente, las aplicaciones disponibles en el mercado se limitan a reproducir los datos, sin que exista un análisis y una correlación real que, a día de hoy, todavía debe realizarla el propio usuario dado que apenas existen protocolos para el intercambio de datos.
4.2 Fugas y privacidad de la información
Por lo que se refiere a la gestión de la información privada de los usuarios, el reglamento de 1995 de la Unión Europea no da respuesta a la situación actual. Es por esta razón que, desde el 2012, la Unión Europea trabaja en un nuevo reglamento que se prevé finalizar el 2016 para que sea aplicable a partir de 2018.9 En esta línea, se abre un mundo de posibilidades para explorar y discutir. ¿Quién es el propietario de los datos personales, el usuario o la aplicación? ¿Los desarrolladores de la aplicación pueden usar la información recogida sobre el usuario? ¿Puede hacerse negocio en base a los datos que el mismo usuario ha registrado «gratuitamente» al usar la aplicación? Todas estas cuestiones aún no están resueltas.
El tema de las fugas de información afecta nuestro día a día en tanto que usuarios de entornos digitales. Los medios de comunicación han hecho públicas noticias sobre como las empresas pierden información personal de sus clientes, ya sea en el caso de las aplicaciones, como en los sistemas operativos o en los dispositivos móviles: Dropbox,10 Gmail,11 Windows,12 Apple,13 o Android14 son ejemplos recientes.
4.3 Interoperabilidad
La falta de protocolos estándares para el intercambio de datos, aumenta la complejidad en la interoperabilidad entre sistemas en el ciclo de datos. La mayoría de aplicaciones de quantified self no se han concebido para integrarse con sistemas externos como el historial médico en un hospital o en los buscadores. No obstante, grandes empresas tecnológicas han prometido recientemente cambiar esta situación. Por ejemplo, Apple ha anunciado últimamente que el HealthKit se integrará en los sistemas de la Clínica Mayo,15 hecho que abre posibilidades inimaginables hasta hoy. El QS proporciona una información contextual rica y actual a la hora de recuperar la información. Probablemente, los nuevos motores de búsqueda contextuales se basarán en información en tiempo real y en datos almacenados del usuario, para satisfacer mejor sus necesidades informativas.
La actual falta de homogenización y estandarización hace que los datos, a menudo, no estén vinculados entre ellos y, por tanto, que en muchos casos la información que ofrecen sea de poco valor para el usuario final. En el momento en que se empiecen a cruzar los datos de diferentes fuentes, se podrá generar un análisis más complejo y, probablemente, se modificará la percepción del usario respecto a la validez y confianza de las recomendaciones que genera la aplicación. No obstante, este mismo potencial positivo puede ser susceptible de atraer a terceros a utilizar estos datos enriquecidos, hecho que puede acarrear consecuencias no siempre positivas para el usuario.
5 Conclusiones
Este artículo plantea cómo el lifelogging y, en concreto, el quantified self son fenómenos que están transformando la gestión de los datos en el ámbito personal. Utilizando la perspectiva de los datos masivos, el artículo analiza cómo las aplicaciones actuales presentan oportunidades y retos sociales y tecnológicos. La revisión bibliográfica realizada muestra que el creciente interés y popularidad de las aplicaciones de quantified self contrasta con el limitado desarrollo de los esperados beneficios sociales y tecnológicos que estos fenómenos generan. A pesar de ser difícil hacer previsiones, se espera que los movimientos del lifelogging y quantified self pasen a ser prácticas sociales, efectivas, eficientes y habituales en los próximos años. Hoy en día, se identifican los beneficios individuales pero aún se desconoce el impacto que pueden tener desde una perspectiva global; por ejemplo, quedan aspectos poco claros como el nivel de interoperabilidad necesario entre aplicaciones y sistemas.
La popularización creciente de las aplicaciones de quantified self hace que, a corto plazo, una de las prioridades sea avanzar en la educación y formación en la gestión de la privacidad, seguridad y protección de datos de los usuarios; sobre todo si vamos hacia una sociedad que espera obtener y operar con datos masivos procedentes del ámbito personal. En estos momentos, los límites no están regulados y tenemos que ser nosotros mismos los que debemos proteger nuestros derechos y controlar los posibles usos no autorizados de nuestros datos.
Bibliografía
De Vicente, José Luis; Galdón, Gemma (2014). Anonimízate: manual de defensa electrónica = Anonymise yourself: electronic self-defence handbook. <http://issuu.com/cccb/docs/manual_de_defensa_-_cast_ang?e=1287205/9478560#/signin>. [Consulta: 17/04/2015].
Dodge, Martin; Kitchin, Rob (2007). «‘Outlines of a world coming into existence’: persuasive computing and the ethics of forgetting». Environmental and planning B: planning and design, vol. 34, no. 3, p. 431–435. <http://personalpages.manchester.ac.uk/staff/m.dodge/cv_files/epb_ethics_of_forgetting.pdf>. [Consulta: 17/04/2015].
Gordo López, Ángel; De Rivera, Javier; López Losada, Yago (2013). «Sociogénesis de las nuevas enfermedades tecnológicas y los dispositivos de auto-cuantificación». Quaderns de psicologia, vol. 15, núm. 1, p. 81–93. <http://www.quadernsdepsicologia.cat/article/view/1166>. [Consulta: 17/04/2015].
Gurrin, Canthal; Smeaton, Alan F.; Doherty, Aiden R. (2014). «LifeLogging: personal big data». Foundations and trends in information retrieval, vol. 8, no. 1, p. 1–107. DOI: 10.1561/1500000033.
Lee, Victor R. (2013). «The Quantified Self (QS) movement and some emerging opportunities for the educational technology field». Education technology. Fall 2013 (Nov.-Dec.), p. 39–42. <http://digitalcommons.usu.edu/itls_facpub/480/>. [Consulta: 17/04/2015].
Li, Ian.; Dey, Anind K.; Forlizzi, Jodi (2011). «Understanding my data, myself». Proceedings of the 13th international conference on Ubiquitous computing – UbiComp ’11. New York, USA: ACM Press, p. 405–414. DOI: 10.1145/2030112.2030166.
Mayer-Schönger, Viktor; Cukier, Kenneth (2013). Big data: la revolución de los datos masivos. Madrid: Turner.
McFedries, Paul (2013). «Tracking the quantified self: we are data-generating and language-generating machines». IEEE Spectrum. <http://spectrum.ieee.org/at-work/test-and-measurement/tracking-the-quantified-self>. [Consulta: 09/12/2014].
Nafus, Dawn; Sherman, Jamie (2014). «This one does not go up to 11: the quantified self movement as an alternative big data practice». International journal of communication, vol. 8, p. 1784–1794. <http://ijoc.org/index.php/ijoc/article/view/217>.[Consulta: 09/12/2014].
Nagy, Peter; Koles, Bernadett (2014). «The digital transformation of human identity: towards a conceptual model of virtual identity in virtual worlds». Convergence: the international journal of research into new media technologies, vol. 20, no. 3, p. 276–292. DOI: 10.1177/1354856514531532.
Serrano-Cobos, Jorge (2014). «Big data y analítica web. Estudiar las corrientes y pescar en un océano de datos». El Profesional de la informacion, vol. 23, n.º 6, p. 561–566. DOI: 10.3145/epi.2014.nov.0.1
Swan, Melanie (2012). «Sensor Mania! The Internet of things, wearable computing, objective metrics, and the quantified self 2.0». Journal of sensor and actuator networks, vol. 1, no. 3, p. 217–253. DOI: 10.3390/jsan1030217.
—— (2013). «The Quantified self: fundamental disruption in big data science and biological discovery!. Big Data, vol. 1, no. 2, p. 85–99. DOI: 10.1089/big.2012.0002.
«The quantified self: counting every moment» (2012). Technology Quarterly – The Economist, Mar 3rd. <http://www.economist.com/node/21548493>. [Consulta: 20/03/2015].
Wolf, Gary (2010a). «The Data-Driven Life». The New York Times magazine, April. <http://www.nytimes.com/2010/05/02/magazine/02self-measurement-t.html?_r=0>. [Consulta: 20/03/2015].
—— (2010b). «The quantified self». TED: Ideas worth spreading, June. <http://www.ted.com/talks/gary_wolf_the_quantified_self?language=en>. [Consulta: 20/03/2015].
Whitson, Jennifer R. (2013). «Gaming the quantified self». Surveillance & society, vol. 11, no. 1/2, p. 163–176. <http://click4it.org/images/1/1f/Gaming_the_Quantified_Self_Whitson.pdf>. [Consulta: 20/03/2015].
Notas
1 Viktor Mayer-Schönberger es profesor de regulación y gestión de Internet en la Oxford University y uno del os expertos más reconocidos internacionalmente en temas de datos masivos. La entrevista se publicó en el Diario.es (05/08/2013).
2 Big Data: what it is and what it matters.
3 Los meetup son charlas para discutir diferentes temas de interés. La del QS se realiza a escala mundial y tiene una muy buena acogida.
4 En la página personal de Nicholas Felton se pueden ver todos los gráficos y estadísticas elaboradas a partir de los datos que ha ido recogiendo sobre sí mismo.
5 El TED es una organización sin ánimo de lucro que difunde ideas dignas de ser difundidas. En una de estas charlas (junio de 2010), Gary Wolf presentaba qué era el quantified self y qué relación tenía con los datos masivos. <http://www.ted.com/talks/gary_wolf_the_quantified_self>.
6 Ron Lieber explica en The New York Times (15/04/2014) la experiencia con su aseguradora: «Lower your car insurance bill, at the price of some privacy«.
7 Entrevista a Kelly Barnes, responsable de salud de PriceWaterhouseCoopers a Forbes (19/06/2014): «Wearable tech is plugging into health insurance«.
8 Noticia publicada en El País (30/10/2011): «El Parlament frena el plan de Boi Ruiz para vender datos sanitarios«.
9 «Reglamento de protección de datos se aplicará en el 2018 según experto«. La Vanguardia (22/10/2014).
10 Noticia de The Independent (14/10/2014) sobre la fuga de información de passwords de Dropbox. «Dropbox passwords leak: Hundreds of accounts hacked after third-party security breach«.
11 La CNN (10/09/2014) se hace eco de la pérdida de credenciales que sufrió Gmail <http://money.cnn.com/2014/09/10/technology/security/gmail-hack/index.html>.
12 «Nueva vulnerabilidad 0-day afecta a casi todas las versiones de Windows» (22/10/2014) <http://www.welivesecurity.com/la-es/2014/10/22/nueva-vulnerabilidad-0-day-afecta-versiones-windows/>.
13 «Apple issues seven updates, fixes more than 40 vulnerabilities in iOS 8, OS X 10.9.5» (19/09/2014) <http://www.scmagazine.com/apple-issues-seven-updates-fixes-more-than-40-vulnerabilities-in-ios-8-os-x-1095/article/372680/>.
14 «Android Devices Are Leaking Location Data Over Wi-Fi: EFF Report» (04/07/2014) <http://gadgets.ndtv.com/mobiles/news/android-devices-are-leaking-location-data-over-wi-fi-eff-report-552897>.
15 «Apple Gives Epic And Mayo Bear Hug With HealthKit» (06/03/2014) <http://www.forbes.com/sites/danmunro/2014/06/03/apple-gives-epic-and-mayo-bear-hug-with-healthkit/>.
 licencia de Creative Commons de tipo «Reconocimiento-NoComercial-SinObraDerivada«. Esto significa que se pueden consultar y difundir libremente siempre que se cite el autor y el editor con los elementos que constan en la opción «Cita recomendada» que se indica en cada uno de los artículos, pero que no se puede hacer ninguna obra derivada (traducción, cambio de formato, etc.) sin permiso del editor. En este sentido, se cumple con la definición de open access de la Declaración de Budapest en favor del acceso abierto. La revista permite al autor o autores mantener los derechos de autor y retener los derechos de publicación sin restricciones.
licencia de Creative Commons de tipo «Reconocimiento-NoComercial-SinObraDerivada«. Esto significa que se pueden consultar y difundir libremente siempre que se cite el autor y el editor con los elementos que constan en la opción «Cita recomendada» que se indica en cada uno de los artículos, pero que no se puede hacer ninguna obra derivada (traducción, cambio de formato, etc.) sin permiso del editor. En este sentido, se cumple con la definición de open access de la Declaración de Budapest en favor del acceso abierto. La revista permite al autor o autores mantener los derechos de autor y retener los derechos de publicación sin restricciones.