
Virginia Bazán Gil
Responsable de proyectos
Fondo Documental de RTVE
Ricardo Guerrero Gómez-Olmedo
Científico de datos
BEEVA
Resumen
Objetivo: determinar la madurez de los sistemas de video-to-text para la descripción automática de imágenes en un archivo de televisión.
Metodología: se realiza una prueba de concepto mediante un sistema de video-to-text desarrollado ad hoc. La prueba se articuló en tres fases o iteraciones distintas entre junio de 2016 y enero de 2017. En las dos primeras iteraciones el sistema analizó un número determinado de contenidos procedentes del archivo de RTVE, las descripciones se valoraron para establecer la tasa de acierto del sistema o, en otras palabras, cómo de cercana era dicha descripción a la que podía haber suministrado un ser humano. En una tercera fase, y previamente al análisis de los contenidos, se entrenó al sistema utilizando técnicas de aprendizaje profundo con el objetivo de mejorar los resultados.
Resultados: los resultados obtenidos ponen de manifiesto que se trata de una tecnología prometedora, si bien resulta fundamental profundizar más en los mecanismos que serían necesarios para su puesta en producción en los archivos de televisión.
Resum
Objectiu: determinar la maduresa dels sistemes de video-to-text per a la descripció automàtica d'imatges en un arxiu de televisió.
Metodologia: es fa una prova de concepte mitjançant un sistema de video-to-text desenvolupat ad hoc. La prova es va articular en tres fases o iteracions diferents entre juny de 2016 i gener de 2017. En les dues primeres iteracions el sistema va analitzar un nombre determinat de continguts procedents de l'arxiu de RTVE, les descripcions es van valorar per establir la taxa d'encert del sistema o, en altres paraules, com de propera era aquesta descripció a la que podia haver subministrat un ésser humà. En una tercera fase, i prèviament a l'anàlisi dels continguts, es va entrenar el sistema utilitzant tècniques d'aprenentatge profund amb l'objectiu de millorar els resultats.
Resultats: els resultats obtinguts posen de manifest que es tracta d'una tecnologia prometedora, si bé resulta fonamental aprofundir més en els mecanismes que serien necessaris per a la seva posada en producció en els arxius de televisió.
Abstract
Objective: To assess the deep learning capability of a video captioning model for automated image description in a television archive.
Methodology: Our proof of concept tested an ad hoc video-captioning model in three iterations between June 2016 and January 2017. In the first and second iterations the model was used to analyse a selection of content from the archives of the Spanish Radio and Television Corporation (RTVE) and the descriptions it generated were evaluated to determine the model’s success rate, i.e., how close it came to providing human-like image descriptions. In the third iteration and before the content was analysed, the model was trained using deep learning techniques to optimise the results.
Results: The results indicate that the model has potential, although further development will be required to customise its use in television archives.
1 Introducción
Desde la década de los ochenta del siglo xx los archivos audiovisuales han experimentado una constante evolución tecnológica que afecta no solo a los formatos en los que los contenidos se almacenan, sino también a su propia esencia. Los archivos han dejado de ser "silos protegidos" para convertirse en un espacio para la interacción con la producción y los usuarios (Teruggi, 2018). La digitalización no solo ha diluido la frontera entre la producción y el archivo, sino que también ha provocado la transformación tanto de los flujos de trabajo como de los perfiles profesionales, cuestiones ambas que han sido profundamente analizadas (Aguilar; López de Solís, 2010; Giménez Rayo, 2012; Caldera Serrano; Arranz, 2013; Giménez Rayo; Guallar, 2014). Al mismo tiempo, y como consecuencia de la multiplicación de los canales de distribución y de emisión, se está produciendo un aumento exponencial de los contenidos audiovisuales y, por tanto, un aumento proporcional de la necesidad de metadatos para garantizar su recuperación y preservación digital (López de Quintana, 2014; Sound and Vision et al., 2017; Pastor; Escribano, 2018).
La sobreabundancia de contenidos empuja a los archivos a la incorporación de tecnologías que conviertan el etiquetado en tiempo real en una solución viable (Teruggi, 2018). Este interés se pone de manifiesto en "MAM Survey", una encuesta que la Federación Internacional de Archivos de Televisión (FIAT/IFTA) distribuye anualmente entre sus miembros, con el fin de conocer sus expectativas y grado de familiaridad respecto a tecnologías como las del habla o la descripción automática de imágenes. De los resultados de la última MAM Survey, presentada en Lugano en junio de 2017 (FIAT/IFTA, 2017), se desprende que tanto la descripción de escenas (día-noche, interior-exterior, etc.) como el reconocimiento de imágenes (logos, edificios, caras) se consideran herramientas potencialmente útiles para el 69 % de los archivos, si bien solo tienen experiencia en su aplicación un porcentaje muy pequeño de organizaciones, como la finlandesa YLE (Selkälä, 2017), la italiana RAI (Pandolfi; Desirello, 2017), la holandesa Sound and Vision (Manders, 2018) o la española RTVE (Bazán et al., 2018).
Si nos centramos en los archivos que han tenido algún contacto con este tipo de herramientas, comprobamos que solo el 2 % ha incorporado el reconocimiento de escenas a su trabajo diario, el 6 % pretende incorporarlo a medio o corto plazo y el 9 % considera que no está suficientemente maduro como para implementarlo en producción. El reconocimiento de objetos (logos, edificios, caras) no se emplea por el momento en ninguno de los archivos que participaron en la encuesta, si bien el 4 % de los que lo han probado quiere incorporarlo a sus procesos en el futuro, frente a un 15 % que considera que no es una tecnología suficientemente madura.
Como es lógico, los proveedores tecnológicos no son ajenos a los intereses del sector de los medios de comunicación. Actualmente existen en el mercado distintas herramientas que incorporan muchas de las tecnologías antes mencionadas. Algunas de estas soluciones están desarrolladas específicamente para el entorno de emisión de contenidos, como es el caso de la Etiqmedia (2018) o de VSNExplorer (VSN, 2018). La primera es una herramienta específicamente orientada a la catalogación automatizada supervisada, mientras que VSNExplorer es un sistema de gestión y archivo de contenidos audiovisuales (MAM —media asset management—) capaz de integrar los metadatos generados por motores de indexación como Azure de Microsoft (2018), Watson de IBM (2018) o Google Cloud Video Intelligence (Google, 2018). Estos son solo algunos ejemplos orientados a los archivos de televisión. Sin embargo, el crecimiento exponencial de contenidos audiovisuales, al que antes hacíamos referencia, ha hecho que grandes compañías como IBM, Microsoft o Google hayan entrado con paso firme de lleno en este negocio, aportando su experiencia al sector de los medios de comunicación e incluso estableciendo alianzas estratégicas con organismos de radiodifusión, como es el caso de Google, que participa junto con Telefónica, VSN y Watchity en el Journalism Innovation Hub de RTVE, un proyecto que pretende explorar nuevas formas de comunicación innovando en todo el proceso de producción y en el que Google aporta su tecnología de la nube (RTVE, 2018; 24h, 2018).
Desde el punto de vista tecnológico los tres pilares sobre los que se sustentan estas herramientas son: visión artificial, tecnologías del habla y procesamiento del lenguaje natural (Lleida, 2018). Veámoslos con mayor detenimiento:
La visión artificial proporciona el reconocimiento de imágenes, caras, objetos, edificios y logos. Permite la agrupación de imágenes por escenas y su segmentación, al tiempo que facilita realizar un seguimiento de las personas y los objetos que aparecen en el vídeo. Por su parte, las tecnologías del habla se ocupan de la información que procede del audio. El reconocimiento automático del habla (automatic speech recognition) es el primer paso para la transcripción de la locución a texto (speech to text), mientras que la diarización de hablantes (speaker diarization) permite la identificación e indexación de las personas que hablan y de sus discursos, la estructuración del contenido de los documentos, así como el análisis de sentimientos para la descripción enriquecida de contenidos (Anguera et al., 2012). Por último, el procesamiento del lenguaje natural, y más concretamente la semántica distribucional, es la tecnología que permite unificar imagen, texto y audio de tal forma que sea posible la detección de entidades, la descripción de imágenes en lenguaje natural, la generación de resúmenes y la detección y segmentación por temas.
La inteligencia artificial, por tanto, tiene un importante campo de aplicación en los archivos audiovisuales, ya sea de forma continuista, es decir, manteniendo los mismos procesos, pero ayudados por algoritmos que permitan automatizar el trabajo; ya sea de forma disruptiva, buscando realizar trabajos que se habían descartado por no ser rentables (Carillo; González, 2018). En el modelo continuista, los conjuntos de datos —es decir, los archivos— son fundamentales, así como el papel de los documentalistas que validan y corrigen los algoritmos. El enfoque rupturista, por su parte, permite, a partir de la experiencia adquirida, construir modelos que antes no se contemplaban ya que tienen en cuenta los intereses o gustos de los usuarios, con independencia de si estos coinciden con el interés general o no. De esta forma se rentabilizan contenidos que antes no se consideraban económicamente rentables. Cualquiera que sea el enfoque, el aprendizaje automático (machine learning) es una pieza clave ya que permite, usando grandes conjuntos de datos, que los algoritmos aprendan de manera autónoma y sean capaces de predecir el futuro sobre la base de experiencias pasadas, simulando así el aprendizaje del cerebro (Carrillo; González, 2018; García, 2018).
Desde el punto de vista de la inteligencia artificial, la descripción automática de imágenes se considera un problema fundamental que conecta la visión artificial con el procesamiento del lenguaje natural. En los últimos años la comunidad investigadora se ha centrado en la clasificación de imágenes (Guerrero, 2017) o en el reconocimiento de objetos, sin embargo, generar descripciones automáticas de imágenes, empleando frases bien formadas con la adecuada sintaxis y ortografía, es una tarea mucho más compleja. La descripción no solo se refiere a un objeto contenido en una imagen, sino que debe expresar, también, cómo se relacionan los objetos entre ellos, así como sus atributos y las actividades en las que están implicados. Este conocimiento semántico debe expresarse en un idioma determinado, generalmente el inglés, de ahí que sea necesario un modelo lingüístico además de comprensión visual (Vinyals et al., 2015; Karpathy; Fei-Fei, 2016).
Una de las primeras aproximaciones existentes para resolver este reto ha sido NeuralTalk, un proyecto llevado a cabo por el científico Andrej Karpathy (2015) en un intento de aplicar los últimos avances de investigación en aprendizaje profundo (deep learning) y especialmente en redes neuronales multimodales, con el objetivo de desarrollar un prototipo funcional y abierto a todo el público. Este proyecto consiste en un software que recibe como entrada una imagen y cuya salida es una descripción en lenguaje natural de su contenido, de forma similar a la que podría haber realizado una persona que viera la misma imagen. Liberar el código y los modelos entrenados para esta tarea ha dado lugar a que artistas e ingenieros de todo el mundo, partiendo de este trabajo, crearan otros proyectos o vídeos demostrativos de los avances de la tecnología (McDonald, 2015). Tras el impacto generado por NeuralTalk, por tanto, han ido surgiendo otros proyectos que lo continúan y mejoran como NeuralTalk2 (Karpathy, 2016) o Show and Tell (Vinyals et al., 2015; Shallue, 2016). Desde el punto de vista de la investigación, el número de publicaciones relacionadas con esta temática ha tenido un crecimiento exponencial (Vinyals; Toshev; Bengio, 2016) y esta tecnología se ha adaptado incluso a otros campos más diversos, como es el de las imágenes médicas (Wang, 2018).
2 Metodología
En este contexto BEEVA y el Fondo Documental de RTVE acordaron realizar una prueba de concepto (POC), entendiendo como tal la implementación resumida de un sistema de video-to-text con el fin de valorar la viabilidad de esta tecnología como una solución para la descripción automática de brutos en un entorno de producción. La prueba de concepto se articuló en tres iteraciones o fases diferenciadas que se llevaron a cabo entre los meses de julio de 2016 y enero de 2017.
La primera iteración se realizó en julio de 2016 sobre un total de diez contenidos (entre rodajes originales y piezas del Telediario) sobre el Salón del Manga de Barcelona. La temática escogida respondió al propósito de establecer cierta conexión entre esta prueba de concepto y la experiencia de catalogación automatizada que se estaba realizando con otras empresas tecnológicas en el contexto del Observatorio para la Innovación de los Informativos en la Sociedad de la Información Digital de RTVE.
Tras analizar los resultados obtenidos en esta primera fase, se decidió continuar trabajando con los rodajes originales generados por los programas diarios no informativos que integran la redacción digital de Prado del Rey: La mañana, Corazón, España Directo, Aquí la Tierra y Aquí hay trabajo. Estos brutos constituyen la base del archivo de producción, están metadatados de forma exhaustiva y no presentan ninguna limitación desde el punto de vista de los derechos de explotación. La segunda iteración se desarrolló entre los meses de agosto y septiembre de 2016 y se procesaron veintidós rodajes con sus correspondientes minutados.
Durante la tercera y última iteración, realizada entre octubre de 2016 y enero de 2017, se procesaron trescientos sesenta rodajes originales y sus respectivos minutados. Con el objetivo de mejorar los resultados en la fase de procesamiento, se consideró relevante establecer una tipología temática básica del material producido por cada programa con el fin de entrenar al sistema con una muestra suficientemente representativa de cada tipo (en cuanto a cantidad y temática) y, finalmente, poder determinar la utilidad de la descripción automática de imágenes para cada una de las temáticas identificadas.
Todos los rodajes analizados habían sido realizados entre enero de 2015 y julio de 2016. La tabla 1 muestra la distribución por temas, la duración media y el tipo de material característico de cada programa.
|
Programa
|
Duración medida
|
Tipo de material
|
Temáticas
|
|---|---|---|---|
| Aquí hay trabajo |
50 minutos
|
Entrevistas Recursos |
Actividad laboral Oficinas Industria Comercios Laboratorios Trabajos agrícolas Ganadería Aulas de formación |
| La mañana |
30 minutos
|
Entrevistas Recursos |
Pruebas médicas Ensayos clínicos Laboratorios Gimnasios |
| Corazón |
30 minutos
|
Entrevistas /declaraciones Photocall |
Personas Eventos |
| España Directo |
41 minutos
|
Recursos | Gastronomía Parajes naturales Urbanismo |
| Aquí la Tierra |
15 minutos
|
Recursos | Parajes naturales Campos de cultivo |
| Comando actualidad |
30 minutos
|
Recursos | Parajes naturales Urbanismo Gastronomía |
| Informativos |
12 minutos
|
Recursos | Sociedad |
Tabla 1. Distribución de temáticas por programas, duración media, tipo de material
y temáticas incluidas en los rodajes analizados
Una vez establecida la temática del material producido por cada programa, se determinó que la descripción automática era potencialmente útil para los rodajes de Aquí hay trabajo, La mañana, España Directo y Aquí la Tierra, en los que predominaban los planos de recurso tanto en interiores como en exteriores y en los que las declaraciones eran menos relevantes. Se descartaron los rodajes del programa Corazón, cuya forma habitual suele ser la entrevista y en los que es especialmente importante tanto la identificación del personaje entrevistado como el contenido de sus declaraciones. Para este tipo de rodajes se consideran potencialmente útiles las herramientas de reconocimiento del habla y de reconocimiento facial.
Se partió de una muestra inicial de mil quinientos veinticuatro contenidos, entre los que se comenzó seleccionando los que incluían un mayor número de descripciones útiles para entrenar el modelo. Entendiendo por útiles frases cortas y ajustadas a la descripción de la imagen sin elementos inferibles a partir del contexto del programa o del audio.
Por último, y para completar la muestra, se seleccionaron brutos procedentes de la Redacción Digital de Informativos (Torrespaña), rodajes realizados entre febrero y octubre de 2016, archivados en la categoría de "sociedad", realizados en su mayoría en exteriores, que contenían fundamentalmente parajes naturales y ciudades, cuyos brutos tenían una duración media de doce minutos.
Desde el punto de vista técnico, en las dos primeras iteraciones se utilizó únicamente el material visual. Se midió si la descripción proporcionada por el modelo era una descripción plausible que podría haber dado un ser humano.
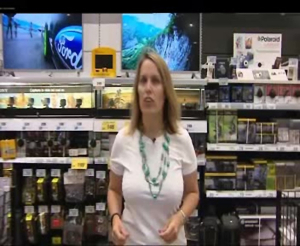 |
 |
|
a woman standing in front of a counter in a store
|
a man riding a wave on top of a surfboard
|
Figura 1. Descripciones suministradas por el sistema en la primera iteración
En la tercera iteración el procedimiento fue distinto, puesto que lo que se buscaba era entrenar un modelo nuevo usando los materiales generados por RTVE.
Se realizó una adaptación de los minutados a las imágenes para obtener una descripción potencialmente útil. Habitualmente los minutados suelen agrupar planos de temática similar, por lo que el equipo de desarrollo consideró necesario extraer la primera imagen de cada intervalo incluido en el minutado, tras comprobar experimentalmente que se trata de la imagen que tiene una mayor correlación con dicha descripción.
Además, y de forma previa al procesamiento de las imágenes, fue necesario preprocesar los contenidos, eliminando tecnicismos habitualmente presentes en los minutados de los contenidos, tales como las abreviaturas empleadas para describir los tipos de planos (PG, PM, PP) o expresiones recurrentes como "recursos de". La figura 2 muestra un minutado tras la eliminación de tecnicismos.

Figura 2. Contenido preprocesado para la eliminación de tecnicismos
Durante el preprocesamiento se decidió también identificar y sustituir los nombres propios más habituales por los nombres comunes "hombre" o "mujer", ya que el sistema debe ser capaz de identificar hombres y mujeres, pero no quiénes son esas personas a título individual. Para llevar a cabo este proceso se tomó como referencia la lista de nombres propios más frecuentes publicada por el Instituto Nacional de Estadística. Esta sustitución afectaba directamente a los nombres de organismos, instituciones o lugares que incluían en su denominación un nombre propio, tal y como muestra la figura 3, si bien el equipo de desarrollo consideró que tenía poca incidencia en la tasa de acierto.

Figura 3. Sustitución de nombres propios por nombres comunes durante el preprocesado de los contenidos
Durante esta fase se detectaron algunos errores ortográficos en los textos. Tras evaluar soluciones, tipo Aspell, que sustituyen la palabra errónea por la palabra correcta más probable y dada la necesidad de proceder después a una desambiguación por contexto, se decidió eliminar las palabras erróneas del conjunto de datos para el entrenamiento.
Finalmente, y dado que el modelo que se estaba empleando para desarrollar el sistema de video-to-text era nativo en inglés, fue necesario realizar una traducción de todos los minutados preprocesados. Para esta tarea se optó por el traductor de Yandex vía API por ser gratuito y fácil de utilizar. Todo el proceso descrito se muestra en la figura 4.

Figura 4. Procedimiento empleado para entrenar el modelo final con el material cedido por RTVE
Así pues, partiendo del minutado de la tabla 2 como ejemplo demostrativo, se obtuvo el texto preprocesado de la tabla 3, que posteriormente fue introducido en un servicio en línea de traducción automática de textos y se obtuvo la cadena de texto de la tabla 4, que se usó después para alimentar el software NeuralTalk.
|
00:08:38–00:08:39: PL DE PAULA GONZÁLEZ REALIZANDO
DECLARACIONES SOBRE CUÁL ES EL PRODUCTO QUE MÁS VENDE Y CUÁL ES SU SECRETO PARA EL ÉXITO |
Tabla 2. Minutado original
|
mujer gonzález realizando declaraciones sobre cuál es el producto que más vende y cuál es su secreto para el éxito
|
Tabla 3. Minutado tras el preprocesado
|
woman gonzalez making statements about which is the product most sold, and what is your secret to success
|
Tabla 4. Minutado traducido
Una vez que se adaptaron los datos a los formatos requeridos por NeuralTalk, se realizó el proceso llamado entrenamiento, consistente en generar un modelo matemático capaz de aprender y emparejar características visuales de las imágenes con características del texto. Para ello se utilizó una función de coste, es decir, una métrica que indica cómo de bien está aprendiendo el modelo. De esta forma, una vez alcanzado un mínimo satisfactorio, se puede obtener la versión final del modelo de descripción.
Finalizada la fase de entrenamiento, podemos empezar la fase de test o predicción,consistente en utilizar el modelo previamente calculado para usarlo sobre nuevas imágenes y así obtener descripciones de estas lo más parecidas a como lo haría un ser humano.
3 Resultados
Los primeros resultados obtenidos para la descripción de los contenidos generados durante la cobertura del 22 Salón del Manga de Barcelona arrojaban una tasa de acierto cercana al 21 %. Es importante tener en cuenta que, ya en el conjunto de datos de partida, no todas las descripciones proporcionadas eran útiles: aproximadamente el 30 % contenían información que no se podía inferir a partir de la información visual contenida únicamente en las imágenes. Se identificaron errores repetitivos derivados de las carencias del modelo utilizado, concretamente micrófonos y pizarras se confundieron con teléfonos móviles y portátiles o tabletas, tal y como muestra la figura 5.
 |
 |
|
a woman holding a cell phone in her hand
|
a woman sitting at a table with a laptop
|
Figura 5. Errores recurrentes derivados de la falta de ejemplos en el modelo empleado
En la segunda iteración se obtuvieron resultados dispares, con una tasa de acierto de entre el 0 % y el 23 %. Un examen detallado de los resultados demuestra que las descripciones menos útiles se producen en escenas de paisajes en las que no hay objetos ni presencia humana, tal y como muestra la figura 6. En cambio, las mejores descripciones se obtienen en escenas en las que hay grupos de personas interactuando, tal y como muestra la figura 7.
 |
 |
 |
|
a view of a large clock tower in the sky
|
a large body of water with a bridge in the background
|
a close up of an orange and a banana
|
Figura 6. Muestra de los resultados negativos obtenidos en la segunda iteración de la prueba de concepto
 |
 |
 |
|
a man in a suit and tie standing in front of a store
|
a group of people sitting on top of a hill
|
a man is standing in a field with a mountain in the background
|
Figura 7. Muestra de los resultados positivos obtenidos en la segunda iteración de la prueba de concepto
En la tercera y última iteración los resultados no solo no mejoraron, sino que sorprendentemente, y de forma recurrente, el sistema fue incapaz de describir correctamente cualquier imagen, y la tasa de acierto cayó a porcentajes cercanos al 0 %. Una muestra de los resultados se puede ver en la figura 8.
 |
 |
 |
|
statements of man UNK director of the UNK
|
UNK of UNK
|
statements of man UNK director of the UNK of the UNK
|
Figura 8. Muestra de los resultados de la tercera iteración
El equipo de desarrollo identificó tres factores para este descenso tan brusco en la tasa de acierto:
- Imágenes fallidas: son aquellos pares (imagen más descripción) que no se corresponden por no estar correctamente sincronizados. Es decir, la primera imagen del intervalo definido en el minutado no tiene correlación alguna con la descripción del intervalo, tal y como muestra la figura 9.
 |
 |
|
Pl recurso de barbero atendiendo a chico joven con barba. El barbero aconseja sobre el tratamiento y comienza el tratamiento
|
Pls de la tienda. Paula en la tienda oliendo un recipiente. Trabajadores colocando jabones
|
Figura 9: Ejemplo de imagen fallida por falta de sincronía
- Información adicional: a menudo, los documentalistas emplean en la descripción de los contenidos audiovisuales información que no se infiere directamente de la imagen, como, por ejemplo, los nombres propios de las personas que aparecen en la imagen. Las descripciones recogidas en la figura 10 son un buen ejemplo de ello.
 |
 |
|
Recurso de Angelines una cerda que fue abandonada. Esta cerda tiene muchos fans en redes sociales y se han hecho camisetas y tazas con su imagen
|
Recursos ambiente en la localidad de Pioz (Guadalajara) y la urbanización "La Arboleda", días después de que la Guardia Civil hallara muertos a los cuatro miembros de una familia brasileña en el interior de un chalet
|
Figura 10. Ejemplo del uso de información adicional en la descripción de imágenes
- Palabras fuera del vocabulario: se consideran palabras fuera del vocabulario aquellas que aparecen menos de cinco veces en el conjunto de entrenamiento. Durante el procesamiento el sistema sustituye esas palabras desconocidas por la ocurrencia UNK (unknown). El equipo de desarrollo detectó que más del 70 % del vocabulario de los minutados no superaba ese umbral, y se identificó como factores relevantes la presencia de nombres propios, abreviaturas y erratas en los textos.
4 Limitaciones
Las principales limitaciones de esta prueba de concepto están relacionadas con los datos utilizados para el entrenamiento del modelo y muy especialmente con los minutados disponibles en el archivo. Estas descripciones cronológicas son adecuadas para la gestión de los contenidos en el entorno de producción de RTVE, pero han demostrado no ser útiles para entrenar un modelo de video-to-text. Como factores que hacen que estas descripciones no sean adecuadas para este propósito podemos identificar las siguientes:
- No son descripciones fotograma a fotograma y tienden a agrupar planos o escenas similares.
- Incorporan información que no se deduce únicamente de la imagen, generalmente procedente del audio.
- En entrevistas o declaraciones, el audio es el elemento protagonista y la descripción de la imagen se convierte en un elemento secundario.
- El contexto de la imagen, entendido como el programa o reportaje concreto para el que se ha realizado un rodaje, es fundamental para dotar de significado a la descripción de los planos y aportar detalles significativos a esta descripción.
Veamos algunos ejemplos que ilustran las limitaciones de los minutados empleados para el entrenamiento del modelo. La figura 11 representa un grupo de personas sentadas en un banco y así lo ha descrito el sistema, sin embargo, la descripción manual realizada en el archivo incluía este fotograma concreto en un agrupamiento mayor de imágenes que correspondía a personas caminando por una calle peatonal.
 |
|
a group of people sitting on a bench
|
|
02:22:21–02:26:52: Recursos de gente andando por la calle
|
Figura 11. Comparativa de descripción obtenida por el sistema
y descripción manual con agrupación de planos
La figura 12 recoge el momento en el que un grupo de modelos se dispone a desfilar por una pasarela, la escena es descrita por el sistema de forma correcta como un grupo de personas en una sala, pero el sistema no es capaz de inferir que se trata de un grupo de modelos porque carece de información de contexto.
 |
|
a group of people standing in a room
|
|
01:28:38–01:55:51: Modelos saliendo a la pasarela para desfilar
|
Figura 12. Comparativa de la descripción obtenida por el
sistema sin información de contexto y descripción manual
De nuevo, la figura 13 es un claro ejemplo de la información adicional que contienen las descripciones realizadas en el archivo. En el primer caso el sistema es capaz de identificar a un grupo de personas andando por la calle, pero no puede inferir que es una calle de Guadalajara; la segunda imagen corresponde a un televisor, pero no es posible determinar, mediante un automatismo, que ese televisor es de una marca concreta y que se encuentra ubicado en un hipermercado.
 |
 |
|
a group of people walking down a street
|
a picture of a tv on a table
|
|
02:17:48–02:19:58: Pl recurso de tráfico en una calle de Guadalajara
|
00:09:02-00:11:07: Pls recurso hipermercado, sección de textil y de librería
|
Figura 13. Comparativa de descripción automática y descripción manual con información
que no se puede inferir directamente de la imagen
La figura 14 es un ejemplo todavía más evidente. La descripción manual no solo es capaz de identificar a las personas que intervienen, con nombres y apellidos, sino que muy probablemente incluye un resumen del contenido de sus palabras. En este sentido, los sistemas de reconocimiento facial y de reconocimiento de imágenes tendrían que complementarse con información obtenida a partir de soluciones de speech-to-text.
 |
 |
|
a group of people standing around a building
|
a man in a suit and tie standing in front of a group of people
|
|
00:00:20–00:01:01: DP de los asistentes al "Salón del Manga" haciendo cola para entrar al recinto de "La Farga". Algunos de ellos disfrazados de personajes de comics
|
00:06:51–00:07:42: Se repite parte de la entrevista a Carles Santamaria en catalán
|
Figura 14. Comparativa de descripción automática y descripción manual con información relativa al audio
El contexto, entendido como el programa o reportaje para el que se ruedan las imágenes, es fundamental para dotar a las escenas de un significado completo. La figura 15 muestra una descripción automática más o menos correcta de la que no se puede deducir, salvo por la información de contexto, que se trata de un paraje determinado. En concreto estas imágenes fueron rodadas para un reportaje sobre senderismo en Peñalara para el programa España Directo emitido el 16 de junio de 2016 por La 1 de TVE.
 |
 |
|
a man standing in a field with a mountain in the background
|
a group of people sitting on top of a hill
|
|
00:16:42–00:29:50: PLS montañeros en el Parque Natural de Peñalara
|
00:40:13–00:51:21: Laguna de Peñalara
|
Figura 15. Comparativa de descripción automática y descripción manual. Ejemplo de
imagen que incorpora información de contexto obtenida del programa
Por último, cabe destacar que la ambigüedad del lenguaje natural es un reto importante para la inteligencia artificial. Esta prueba de concepto nos ha demostrado la dificultad de asociar palabras polisémicas cuyo significado no es unívoco a una descripción visual determinada. Fijémonos en el siguiente ejemplo de minutado: "entrevista a Nieves, una joven disfrazada que acude al Salón del Manga de Barcelona". Si durante la fase de preprocesado el nombre propio "Nieves" no se hubiera sustituido por el nombre común "mujer", se hubiera asociado la imagen de una mujer al concepto nieve en el modelo de entrenamiento. Eso hubiera generado un conflicto al aplicar el mismo nombre a la descripción de paisajes con nieve. Por este motivo las primeras aplicaciones de la tecnología de video-to-text utilizan modelos especializados para cada temática, de forma que se limitan las distorsiones y sesgos y mejora la precisión obtenida frente a modelos generalistas.
5 Conclusiones
Los resultados obtenidos en esta prueba de concepto son prometedores y demuestran que la tecnología ha avanzado lo suficiente como para que, en un futuro cercano, sea viable integrar un sistema de video-to-text en un entorno de producción en un archivo de televisión, siempre con supervisión humana. Una estimación basada en el número de publicaciones sobre descripción automática de imágenes en congresos científicos (Computer Vision and Pattern Recognition, International Conference on Computer Vision, European Conference on Computer Vision, etc.) nos hace suponer que, en un plazo aproximado de tres años, tendremos sistemas capaces de realizar descripciones automáticas de manera más fiable para colecciones temáticas acotadas. De esta forma, podríamos emplear distintos modelos adaptados a las temáticas más comunes: un modelo especializado en eventos multitudinarios tipo Salón del Manga, otro modelo especializado en paisajes al aire libre para contenidos similares a los producidos por el programa Aquí la Tierra, etc.
Los resultados obtenidos ponen de manifiesto que las soluciones de video-to-text no son adecuadas para contenidos audiovisuales en los que la información relevante se concentra en el audio, como es el caso de entrevistas y declaraciones y en las que la identificación del personaje es un factor clave. Si bien podrían aplicarse como tecnología complementaria a sistemas speech-to-text o reconocimiento facial para enriquecer los resultados.
Finalmente, podemos concluir que estas soluciones están condicionadas por dos factores fundamentales, la calidad de los datos que se emplean en la fase de entrenamiento y la ambigüedad del lenguaje natural. Este segundo factor refuerza la idea de la necesidad de construir modelos especializados para temáticas concretas que permitan eliminar distorsiones y sesgos en el modelo, para mejorar la precisión en las descripciones.
Bibliografía
24h (2018). Presentación del Journalism Innovation HUB de @rtve en el @BIT_audiovisual. [Vídeo]. <https://www.periscope.tv/24h_tve/1dRKZeZBAjoxB>. [Consulta: 08/06/2018].
Agirreazaldegi, T. (2007). "Claves y retos de la documentación digital en televisión". El profesional de la información, v. 16, n.o 5, p. 433–442. <http://dx.doi.org/10.3145/epi.2007.sep.05>. [Consulta: 10/06/2018].
Aguilar, M.; López de Solís, I. (2010). "Nuevos modos de trabajo de una redacción digital integrada: el caso de los servicios informativos de TVE". El profesional de la información, vol. 19, n.o 4, p. 395–403. <http://dx.doi.org/10.3145/epi.2010.jul.09>. [Consulta: 10/06/2018].
Anguera, X. et al. (2012). "Speaker diarization: A review of recent research". IEEE Transactions on audio, speech, and language processing, vol. 20, no. 2, p. 356–370.
Bazán, V. et al. (2018). Semantics, automatic metadata and audiovisual contents. A case of study: Barcelona International Manga Fair. <https://es.slideshare.net/fiatifta/semantics-automatic-metadata-and-audiovisual-contents-a-case-of-study-the-barcelona-international-manga-fair-bazn-gil-virginia-matas-pascual-roberto-gmez-zotanomanuel-pastor-sanchez-rtve-spain>. [Consulta: 06/06/2018].
Caldera Serrano, J.; Arranz, P. (2013). Documentación audiovisual en televisión. Barcelona: Editorial UOC.
Carrillo, J.; González, A. (2018). La inteligencia artificial aplicada a los archivos de televisión. <http://www.rtve.es/contenidos/documentos/instituto/5_Jornada_Archivos_tv.pdf>. [Consulta: 04/06/2018].
Etiqmedia (2018). Catalogación automática en entornos audiovisuales. [Vídeo]. <https://www.youtube.com/watch?v=f9j2OhOe5tA>. [Consulta: 08/06/2018].
FIAT/IFTA Media Management Commission (2017). FIAT/IFTA MAM Survey 2017: Highlights from the results analysis. <https://es.slideshare.net/fiatifta/2nd-mam-survey-declercq>. [Consulta: 04/06/2018].
García, J. (2018). Machine Learning aplicado en el sector media. <http://www.rtve.es/contenidos/documentos/instituto/7_Jornada_Archivos_tv.pdf >. [Consulta: 04/06/2018].
Giménez Rayo, M. (2012). "La documentación audiovisual en televisión en el mundo 2.0: retos y oportunidades". Trípodos, n.o 31, p. 79–97.
Giménez Rayo, M.; Guallar, J. (2014). "Centros de documentación en televisión y productos documentales". El profesional de la información, vol. 23, n.o 1, p. 13–25. <https://doi.org/10.3145/epi.2014.ene.02>. [Consulta: 10/06/2018].
Google (2018). Cloud Video Intelligence. <https://cloud.google.com/video-intelligence/>. [Consulta: 08/06/2018].
Guerrero, R. (2017). Introducción al Deep Learning y su uso en clasificación de imágenes. [Vídeo]. <https://www.youtube.com/watch?v=r6PsfQh05xA>. [Consulta: 04/06/2017].
IBM (2018). Watson. <https://www.ibm.com/watson/>. [Consulta: 08/06/2018].
Karpathy, A. (2015). "NeuralTalk is a Python+numpy project for learning Multimodal Recurrent Neural Networks that describe images with sentences". <https://github.com/karpathy/neuraltalk>. [Consulta: 10/06/2018].
— (2016). "Efficient Image Captioning code in Torch, runs on GPU". <https://github.com/karpathy/neuraltalk2>. [Consulta: 10/06/2018].
Karpathy, A.; Fei-Fei, L. (2016). "Deep Visual-Semantic Alignments for Generating Image Descriptions". IEEE Transactions on pattern analysis and machine intelligence, vol. 39, no. 4 (April 1 2017). <https://doi.org/10.1109/TPAMI.2016.2598339>. [Consulta: 10/06/2018].
Lleida, E. (2018). Tecnologías para el análisis y metadatado de contenidos audiovisuales. <http://www.rtve.es/rtve/20180202/jornadas-archivos-television/1672420.shtml>. [Consulta: 04/06/2018].
López de Quintana, E. (2014). "Rasgos y trayectorias de la documentación audiovisual: logros, retos y quimeras". El profesional de la información, vol. 23, n.o 1, p. 5–12. <https://doi.org/10.3145/epi.2014.ene.01>. [Consulta: 10/06/2018].
Manders, T. (2018). It's all about data. <https://es.slideshare.net/fiatifta/its-all-about-data-media-management-information-management-at-nisv-manders-and-van-arkel>. [Consulta: 06/06/2018].
McDonald, K. (2015). NeuralTalk and walk. [Vídeo]. <https://vimeo.com/146492001>. [Consulta: 07/06/2018].
Microsoft (2018). Video Indexer. <https://azure.microsoft.com/es-es/services/cognitive-services/video-indexer/>. [Consulta: 08/06/2018].
Pandolfi, F. M.; Desirello, D. (2017). A framework for visual search in broadcast archives. <https://es.slideshare.net/fiatifta/a-framework-for-visual-search-in-broadcasting-companies-multimedia-archives>. [Consulta: 06/06/2018].
Pastor, J.; Escribano, M. (2018). Descripción semántica de escenas ¿El esperanto de las búsquedas?. <http://www.rtve.es/contenidos/documentos/instituto/6_Jornada_Archivos_tv.pdf>. [Consulta: 08/06/2018].
RTVE (2018). Google se suma al proyecto "Journalism Innovation HUB" de RTVE. <http://www.rtve.es/rtve/20180531/google-se-suma-proyecto-journalism-innovation-hub-rtve/1742823.shtml>. [Consulta: 08/06/2018].
Selkälä, E. (2017). Automated metadata generation. Projects at YLE. <https://es.slideshare.net/fiatifta/automated-metadata-generation-projects-at-yle-2017-selkala-elina>. [Consulta: 06/06/2018].
Shallue, C. (2016). Show and tell: image captioning open sourced in TensorFlow. <https://ai.googleblog.com/2016/09/show-and-tell-image-captioning-open.html>. [Consulta: 08/06/2018].
Sound and Vision; Waag Society; Amsterdam Museum; University of Amsterdam (2017). Freeze! A manifesto for safeguarding and preserving born-digital heritage. <https://waag.org/sites/waag/files/public/freeze-manifesto.pdf>. [Consulta: 01/02/2017].
Teruggi, D. (2018). Preservación audiovisual: ¿Qué queda por hacer y qué podemos llegar a hacer?. <http://www.rtve.es/contenidos/documentos/instituto/1_Jornada_Archivos_tv.pdf>. [Consulta: 08/06/2018].
Vinyals, O.; Toshev, A.; Bengio, S. (2016). "Show and Tell: Lessons Learned from the 2015 MSCOCO Image Captioning Challenge". IEEE Transactions on pattern analysis and machine intelligence,p. 625–663.
Vinyals, O. et al. (2015). "Show and tell: A neural image caption generator". IEEE Conference on computer vision and pattern recognition (CVPR), p. 3.156–3.164.
VSN (2018). VSNExplorer Artificial Intelligence. <https://vsninternal.cloud4tv.com/Storage/Downloads/Online/Videos%20Demo/DEMO%20-%20VSNEXPLORER%20A_7928/7607/DEMO%20-%20ARTIFICIAL%20INTELLIGENCE%20(voiceover).mp4?file=5781>. [Consulta: 08/06/2018].
Wang, X. (2018). "TieNet: Text-Image Embedding Network for Common Thorax Disease Classification and Reporting in Chest X-rays". <https://arxiv.org/abs/1801.04334>. [Consulta: 10/06/2018].
 licencia de Creative Commons de tipo «
licencia de Creative Commons de tipo «