
[Versión castellana | English version]
Mireia Alcalá Ponce de León
Graduada en Informació i Documentació
Universitat de Barcelona
Resum
En els últims anys, la participació social per mitjà de la xarxa ha esdevingut essencial en alguns àmbits. En aquest treball es fa referència a aquest tipus de moviment anomenat “crowdsourcing” o de “proveïment participatiu”, a la figura del voluntariat i a les motivacions que el porten a participar-hi. A més, es mostra un recull dels principals projectes de “crowdsourcing” sobre transcripcions massives realitzats a les institucions de la memòria (biblioteques, arxius, museus i les galeries) a nivell internacional. Mitjançant l’anàlisi d’aquests projectes, se’n revisen les característiques a través d’uns indicadors creats especialment per aquests tipus d’iniciatives i, a partir d’aquí, es proposen unes bones pràctiques que cal preveure en el disseny de projectes de transcripcions massives.
Resumen
En los últimos años, la participación social a través de la red se ha convertido en esencial en algunos ámbitos. En este trabajo se hace referencia a este tipo de movimientos llamados “crowdsourcing” o de “abastecimiento participativo”, a la figura del voluntariado y a las motivaciones que le llevan a participar. Además, se muestra una recopilación de los principales proyectos de «crowdsourcing» sobre transcripciones masivas realizados en las instituciones de la memoria (bibliotecas, archivos, museos y las galerías) a nivel internacional. Mediante el análisis de estos proyectos, se revisan las características a través de unos indicadores creados especialmente para este tipo de iniciativas y, a partir de aquí, se proponen unas buenas prácticas que se deben de contemplar en el diseño de proyectos de transcripciones masivas.
Abstract
In recent years, the growth of web-based social participation and the open source movement have prompted a number of initiatives, including the movement known as crowdsourcing . This paper examines crowdsourcing as a volunteering phenomenon and considers what motivates individuals to participate in crowdsourcing. In addition, the paper reviews the main projects in mass transcription being made in memory institutions worldwide (libraries, archives, museums and galleries), briefly introducing each project and analyzing its main features. Finally, a selection of best practices is offered to guide institutions in the implementation of mass transcription projects.
1 Introducció
L’augment els últims anys de les digitalitzacions per part de les institucions de la memòria ha vingut propiciada per la consolidació i la millora de les tecnologies de la informació i la comunicació (TIC). Aquestes institucions de la memòria conformades per les biblioteques, els arxius, els museus i les biblioteques (citades en el món anglosaxó com els GLAM, Galleries, Libraries, Archives and Museums) van iniciar aquests grans projectes per ampliar l’accés a les seves col·leccions (servei les 24 hores, amb sessions multiusuaris, etc.), transformar els serveis oferts i augmentar la preservació i conservació dels documents físics (l’IFLA i la ICA van crear unes directrius per a projectes de digitalització).1 Tot i així, aquest panorama es veu frenat entre el 2007 i 2008 amb la crisi econòmica, quan els recursos humans i materials comencen a minvar.
No obstant això, és en aquest moment en el qual destaca el moviment de l’accésobert (open source) i la participació social per mitjà de les xarxes; no solament en l’àmbit que tractem, sinó a escala global. Així, doncs, l’aportació i la col·laboració mitjançant la xarxa entre les grans institucions, com també entre aquestes últimes i els seus usuaris fa que neixin projectes com els de crowdsourcing. El TERMCAT (2012) va aprovar proveïment participatiu per a crowdsourcing i l’entén com una crida oberta per tal de «proveir-se de serveis, idees o continguts».
Les institucions de la memòria també han pres part en aquest tipus de projectes de què formen part iniciatives com ara les transcripcions massives, ja que resolien certs tipus de limitacions (cost i personal), milloraven l’accés a les col·leccions i involucraven els usuaris creant comunitats.
2 Crowdsourcing o proveïment participatiu
El terme crowdsourcing va aparèixer per primera vegada l’any 2006 en la revista Wired en l’article «The rise of crowdsourcing» de l’escriptor Jeff Howe. El terme agrupa dues paraules independents com són: crowd (que fa referència a la multitud) i sourcing (que ho vincula amb la font, l’obtenció de matèria primera), i ho defineix com l’acte en el qual una organització traspassa una funció que anteriorment duien a terme els empleats cap a una àmplia xarxa de persones, en forma de desafiament obert, a canvi d’una recompensa.
Tot i que el terme apareix en aquest moment, anteriorment ja existien diferents accions que s’hi poden relacionar. Pierre Lévy (1997) parla de com la intel·ligència col·lectiva pot emergir en el món del ciberespai; dos anys més tard, Tim Berners-Lee i Mark Fischetti (2000) apostaven pel terme intercreativitat, que cercava la creació d’elements a la xarxa mitjançant la intervenció i col·laboració de diverses persones. En la mateixa línia, Howard Rheingold (2003) parlava de les smart mobs o multituds intel·ligents com a revolució social.
Existeixen diferents classificacions de crowdsourcing però una de les més consolidades, després d’analitzar-ne diferents classificacions, és la proposada per Estellés-Arolas i González-Ladrón-de-Guevara (2012).
![Classificació dels diferents tipus de crowdsourcing [elaboració pròpia a partir d'Estellés-Arolas i González-Ladrón-de-Guevara (2012)]](https://bid.ub.edu/wp-content/uploads/2015/11/alcala1.jpg)
Figura 1. Classificació dels diferents tipus de crowdsourcing [elaboració pròpia a partir d’Estellés-Arolas i González-Ladrón-de-Guevara (2012)]
Els autors distingeixen cinc grans tipologies segons el tipus de tasca que es duu a terme en cadascuna. En el crowdcasting es fa una crida a resoldre un problema oferint una recompensa a qui ho resolgui abans o de la millor manera possible. En el crowdcontent la gent aporta la seva mà d’obra i coneixement per crear contingut. El crowdcontent se subdivideix en crowdsearching (cerca massiva a Internet sobre un tema concret), crowdanalysing (variació de l’anterior on la cerca es fa en documentació multimèdia) i crowdproduction (creació de contingut de manera individual o col·lectiva; els projectes de transcripció massiva s’inclouen aquí.). En el crowdfunding es busca finançament per mitjà de petites aportacions i en el crowdopinion s’intenta conèixer l’opinió de la multitud sobre un tema o un producte nou. Finalment, el crowdcollaboration és idèntic al crowdcontent exceptuant que no hi ha comunicació entre els individus ni s’ofereix cap tipus de recompensa. Aquest últim se subdivideix en crowdstorming (pluja d’idees) i crowdsupport (solució de dubtes).
2.1 El voluntariat
Els projectes de crowdsourcing no es poden entendre sense la figura del voluntariat. Caroline Haythornthwaite (2009) discerneix dos patrons diferenciats no sols en diferents projectes sinó en un mateix: la «multitud» (crowd) i la «comunitat» (community). Pel que fa als primers, comparteixen experiències i el sentiment de pertinença té un termini més curt o, fins i tot, només lligat a un projecte (sense poder esperar res a posteriori). En canvi, la comunitat comparteix valors, experiències i objectius a llarg termini, fet que comporta una crida molt més efectiva.
Thomas Knoll (2011) va captar les diferències entre els dos patrons, que es mostren en la taula 1.
|
|
|
|---|---|
| Motivació per orgull. | Motivació per a fins. |
| S’alimenten de la inspiració. | S’alimenten per la influència. |
| Volen beneficis. | Volen pertànyer. |
| Necessiten sentir-se connectats. | Simpulsen a través de la col·laboració. |
| Necessiten aconseguir quelcom. | Els agrada aportar. |
| Se sustenten en el servei. | Les sosté la història. |
Taula 1. Principals diferències entre multitud i comunitat segons T. Knoll (elaboració pròpia)
3 Les transcripcions massives
Tal com s’ha mencionat anteriorment, les transcripcions massives s’engloben dins la categoria de crowdcontent o creació de contingut.
S’entén per transcripció massiva l’acció d’escriure un text en un altre format com a simple representació del mateix document o d’introduir-se en una base de dades com a dades de recerca. Molts dels projectes de transcripcions massives es creen amb l’objectiu de generar informació descriptiva i textual que pugui servir de punt d’accés cercable a documents històrics.
Els projectes de transcripció massiva es poden dividir segons si se’ls aplica un reconeixement òptic de caràcters (OCR), mitjançant un programari específic, o si no se’ls aplica aquest tipus de programari. En els primers, el programari identifica símbols o caràcters que conformen un alfabet determinat i crea un arxiu de text amb les dades obtingudes. El voluntari corregeix els errors ortogràfics que hagi pogut ocasionar el mal reconeixement dels caràcters (símbols estranys, lletres no reconegudes, etc.).

Figura 2. Exemple d’aplicació OCR amb correcció d’errors al Proofreaders. Font: Lardinois (2008)
En el segon cas, el voluntari ha de transcriure el document des de zero, ja que hi ha tot un ventall de documents que, a hores d’ara, encara no es poden sotmetre a l’OCR, com ara la documentació manuscrita.
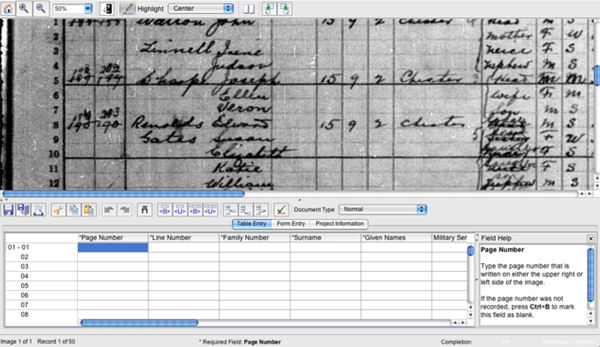
Figura 3. Exemple de transcripció des de zero al FamilySearch Indexing
3.1 Workflow en les transcripcions massives
Molts dels projectes de crowdsourcing segueixen el mateix workflow o mapa de processos. Abans de començar, cal que els manuscrits que volem transcriure estiguin digitalitzats i carregats al repositori digital de la institució perquè les persones hi tinguin accés lliure a través de la xarxa.
El repositori digital ha de permetre la transcripció dels documents i, per això, cal tenir-hi instal·lada una eina de transcripció (que pot ser de programari lliure o de pagament). Aquesta eina permet que el voluntari interactuï amb les imatges que s’han de transcriure i, una vegada acabada alguna de les transcripcions proposades, la mateixa eina l’exporta a un format d’arxiu fàcil de llegir per màquina.
Aquestes metadades seran validades o no pel personal encarregat del projecte i passaran a formar part del repositori digital, com un element més que enriquirà les cerques.
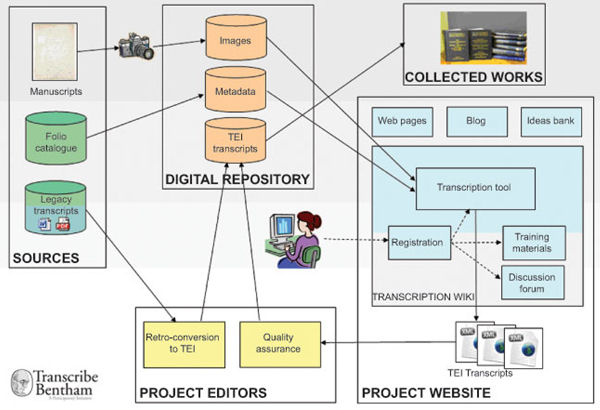
Figura 4. Mapa dels processos duts a terme en un projecte de transcripció massiva. Font: Moyle, Tonra i Wallace (2011)
4 Anàlisi de projectes de transcripció massiva
En aquest apartat es mostra l’anàlisi de vint projectes de transcripció massiva. Cadascun dels projectes analitzats segueix el mateix esquema: una petita introducció del projecte del qual es destaquen certs elements significatius (com ara el nom del projecte, la institució que se n’encarrega, entre altres) i, posteriorment, una anàlisi a partir de diferents indicadors creats segons les pautes proposades per Codina (2000) i Barrueco et. al. (2014), i altres d’elaborades de nou tenint present la particularitat dels projectes a analitzar.
L’elecció d’aquests vint projectes es basa principalment en el fet que es troben actualment en actiu i, per tant, permeten verificar-los en primera persona. A més, es busca que siguin d’àmbit internacional i que tractin la transcripció massiva des de temàtiques variades.
4.1 Projectes
4.1.1 Distributed Proofreaders
L’any 2000 neix el projecte Distributed Proofreaders vinculat a la biblioteca digital Project Gutenberg.2
Mitjançant una plataforma wiki i a través d’una caixa blanca (vegeu la figura 5) els voluntaris han de corregir els textos digitalitzats que s’havien sotmès a l’OCR, però que no havien assolit el nivell de qualitat desitjat.
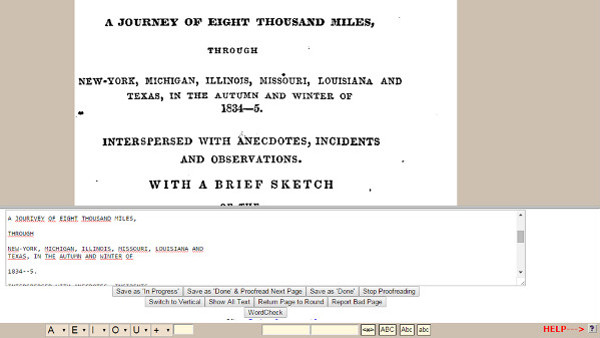
Figura 5. Mostra de la caixa blanca per corregir textos al Proofreaders
En la pantalla inicial es mostren els objectius assolits fins al moment i els que es volen arribar a assolir (vegeu la figura 6).

Figura 6. Mostra del progrés de documents completats, en progrés i que s’estan processant al Proofreaders
Un altre element destacat és que es posen a disposició dels voluntaris unes directrius per corregir els documents i tutorials amb proves d’avaluació que s’han de dur a terme abans d’iniciar la transcripció (vegeu la figura 7).
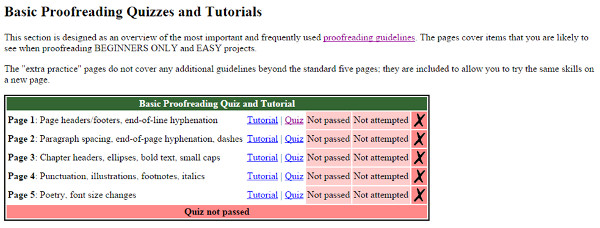
Figura 7. Tutorials i proves d’avaluació al Proofreaders
4.1.2 FamilySearch Indexing
L’any 2000 es crea el FamilySearch Indexing per transcriure milers de registres genealògics conservats i digitalitzats per The Genealogical Society of Utah.3
Per mitjà d’un programari de propietat de la institució podem instal·lar el paquet de transcripció i començar a transcriure segons projectes, idioma o nivell dels documents (vegeu la figura 8).
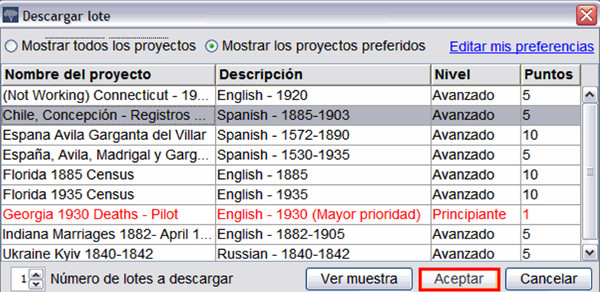
Figura 8. Panell de selecció de lots al FamilySearch Indexing
El tipus de transcripció és força guiada i amb força eines de suport i formació d’usuaris. Una vegada transcrit el document, el programa aplica un petit control de qualitat en les transcripcions que considera poc clares (vegeu la figura 9).
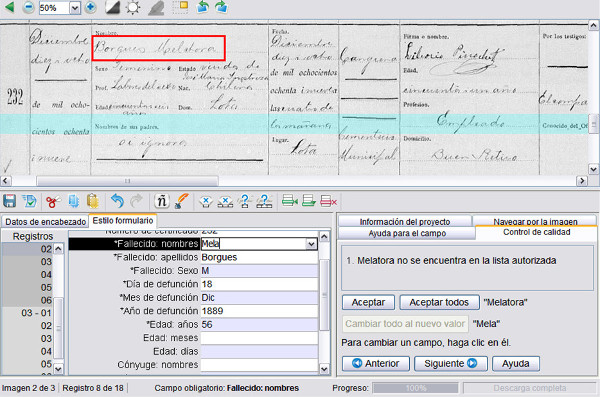
Figura 9. Mostra del control de qualitat al FamilySearch Indexing
4.1.3 Australian Newspaper Digitization Program
La National Library of Australia va crear l’any 2008 la plataforma web Trove, amb API pròpia, per tal de corregir les transcripcions resultants de l’aplicació de l’OCR a la premsa australiana digitalitzada des de 1800.
La pantalla principal del projecte mostra clarament la institució a la qual pertany, què s’hi pot trobar i les diferents maneres de contribuir-hi (vegeu la figura 10).
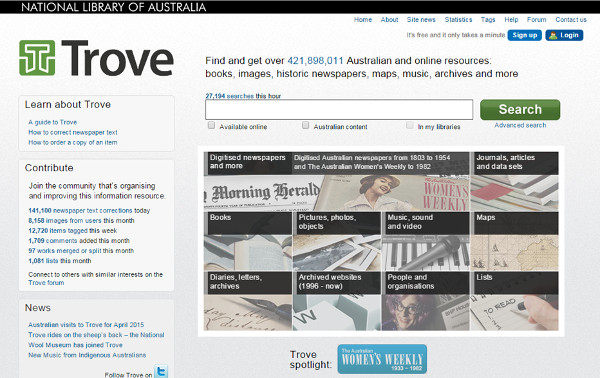
Figura 10. Pantalla principal del projecte Australian Newspapers Digitalisation Program al Trove
La interfície de correcció mostra la imatge digitalitzada i el text sorgit de l’OCR. A través d’una caixa blanca, el voluntari corregeix tots els errors tipogràfics que troba (vegeu la figura 11).
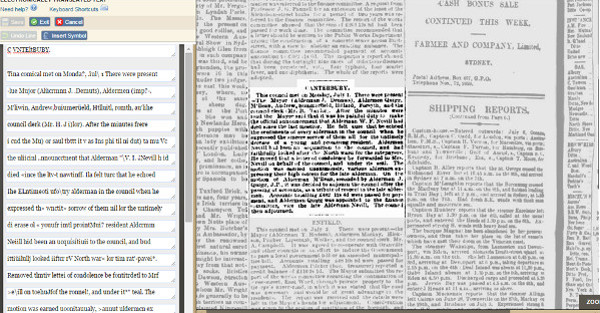
Figura 11. Interfície de correcció de textos a l’Australian Newspapers Digitisation Program
4.1.4 Old Weather
Es tracta del projecte de digitalització i transcripció dels registres de bord de diferents vaixells americans del segle xix que es va llançar l’octubre del 2010 dins la plataforma Zooniverse.4
En qualsevol dels projectes del Zooniverse, abans d’iniciar la transcripció cal fer un petit tutorial per tal de familiaritzar-se amb la interfície, la documentació, el tipus de transcripció, etc.
La transcripció és guiada, ja que es mostra la pàgina a transcriure i s’obre un quadre de diàleg amb els diferents camps que s’han de transcriure (vegeu la figura 12).
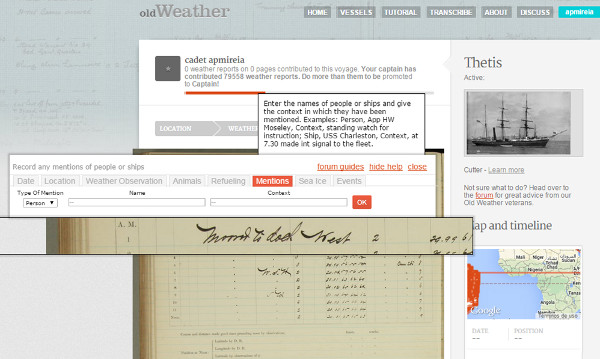
Figura 12. Mostra de la transcripció guiada a l’Old Weather
El registre del voluntari és obligatori i això permet consultar historials de transcripció, subscriure’s a newsletters, comentar als fòrums del projecte i que s’atorguin categories segons l’activitat de cada voluntari (vegeu la figura 13).
Figura 13. Mostra de les diferents categories segons els documents transcrits a l’Old Weather
4.1.5 Citizen Archivist Dashboard
Els National Archives and Records Administration (NARA) dels EUA van crear el 2011 una plataforma web, amb una API pròpia, anomenada Citizen Archivist Dashboard on aplegaven diferents projectes de crowdsourcing, en què els voluntaris podien etiquetar, transcriure o escriure nous articles (vegeu la figura 14).
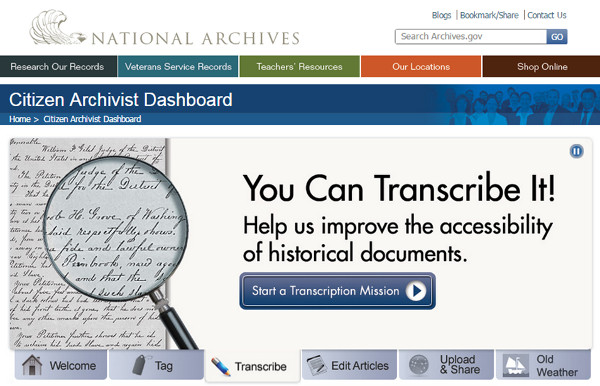
Figura 14. Pantalla inicial del Citizen Archivist Dashboard amb les diferents accions que es poden fer
4.1.6 What’s the Score at the Bodleian?
L’any 2011 la Bodleian Library and Radcliffe Camera de la University of Oxford va crear aquest projecte englobat en la plataforma Zooniverse, l’objectiu del qual era transcriure més de 4.000 partitures digitalitzades des de 1860.
El tipus d’interfície i de transcripció segueix el mateix patró que tots els projectes del Zooniverse. Com a element destacat, a la pantalla principal trobem un element significatiu: la barra de progrés del projecte (vegeu la figura 15).
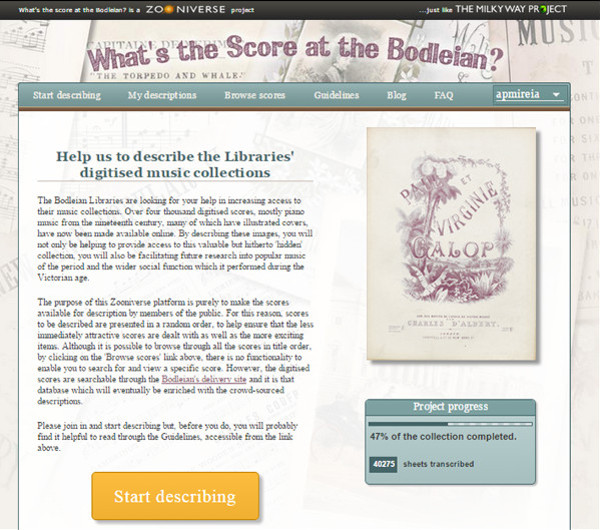
Figura 15. Pantalla inicial del projecte What’s the Score at the Bodleian?
4.1.7 What’s on the Menu?
A final d’abril del 2011 la New York Public Library (NYPL) posa en marxa el projecte What’s on the Menu? per tal de transcriure plats i preus i geoetiquetar locals de més de 45.000 cartes de menús des de 1840 fins a l’actualitat (vegeu la figura 16).
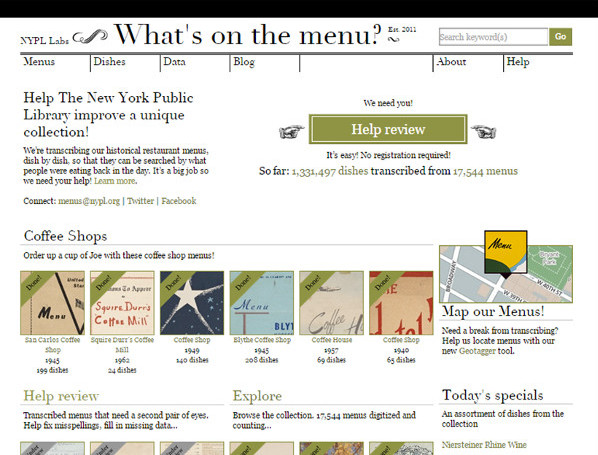
Figura 16. Pantalla inicial del What’s on the Menu? de la NYPL
El tipus de transcripció és parcialment guiada, ja que ofereix una caixa blanca per transcriure el text, però també permet afegir el preu en un altre camp (vegeu la figura 17).
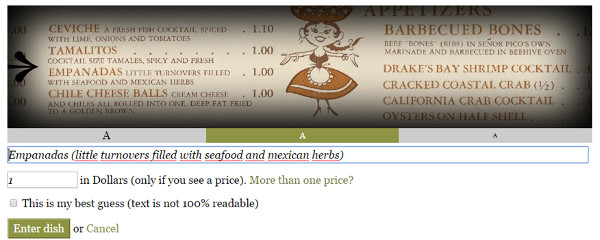
Figura 17. Mostra de la transcripció al What’s on the Menu? de la NYPL
Destaca d’aquest projecte la secció «Today’s specials» on diàriament se seleccionen receptes transcrites per compartir-les a les xarxes socials.

Figura 18. Mostra de comunicació a través de xarxes socials dels plats transcrits al What’s on the Menu?
4.1.8 Transcribe Bentham
La University Collage of London amb altres institucions va crear el 2010 aquest projecte per transcriure els documents manuscrits de Jeremy Bentham, filòsof i polític anglès.
La plataforma d’accés al projecte és des d’un wiki i s’anomena Transcription Desk. A banda de la barra de progrés també hi trobem el Benthamometer, que mostra les diferents fases que es volen assolir quant a escaneig, pujada a la plataforma i transcripció (vegeu la figura 19).
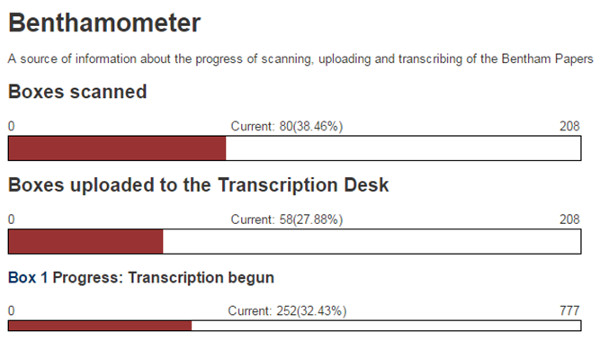
Figura 19. Mostra del Benthamometer sobre l’estat del projecte
En aquest projecte els voluntaris van sumant punts segons les tasques que duen a terme i, d’aquesta manera, van pujant d’esglaó en el rànquing de transcriptors (vegeu la figura 20).
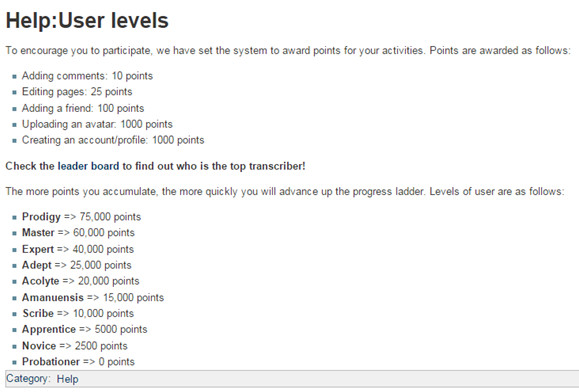
Figura 20. Punts associats a tasques al Transcribe Bentham
Un altre dels punts forts d’aquest projecte és la iniciativa d’aprenentatge educatiu associat, és a dir, els estudiants, de diferents nivells d’edat, poden aprendre mitjançant la recerca en els manuscrits històrics originals (vegeu la figura 21).

Figura 21. Pàgina on es mostra com estudiants participen en el projecte Transcribe Bentham
4.1.9 DIY History
El DIY History sorgeix de l’ampliació del projecte inicial de les University of Iowa Libraries on es volien transcriure els diaris de guerra per a la commemoració del 150è aniversari de la Guerra Civil americana.
La plataforma s’ha creat amb el programari lliure Omeka i engloba múltiples col·leccions a transcriure. D’aquesta manera, és necessari mostrar de manera gràfica el progrés del procés i es poden veure una barra de la col·lecció i, a la vegada, també de cada document (vegeu la figura 22).
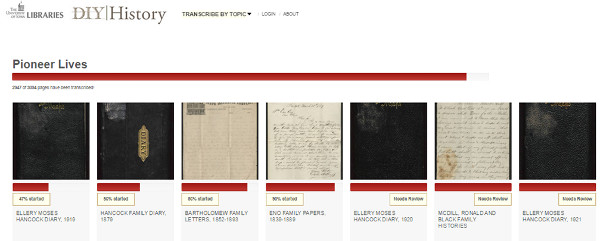
Figura 22. Barra de progrés de la col·lecció i dels documents en particular al DIY History
4.1.10 Ancient Lives
L’Ancient Lives forma part del Zooniverse i té com a objectiu la transcripció de milers de papirs grecs. Ateses les característiques pròpies d’aquests documents, aquest projecte té unes directrius i guies de transcripció i ús de la plataforma força desenvolupades (vegeu la figura 23).
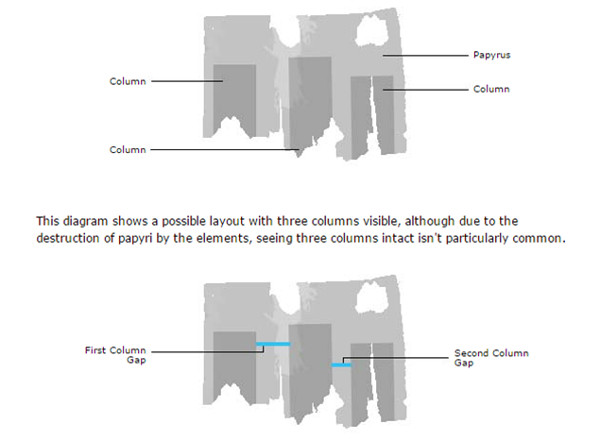
Figura 23. Mostra de com es determinen les mesures en els papirs a l’Ancient Lives
De la mateixa manera, el tipus de transcripció és particular. Es mostra el papir que s’ha de transcriure i també un teclat amb els diferents caràcters per tal de seleccionar-los directament (vegeu la figura 24).
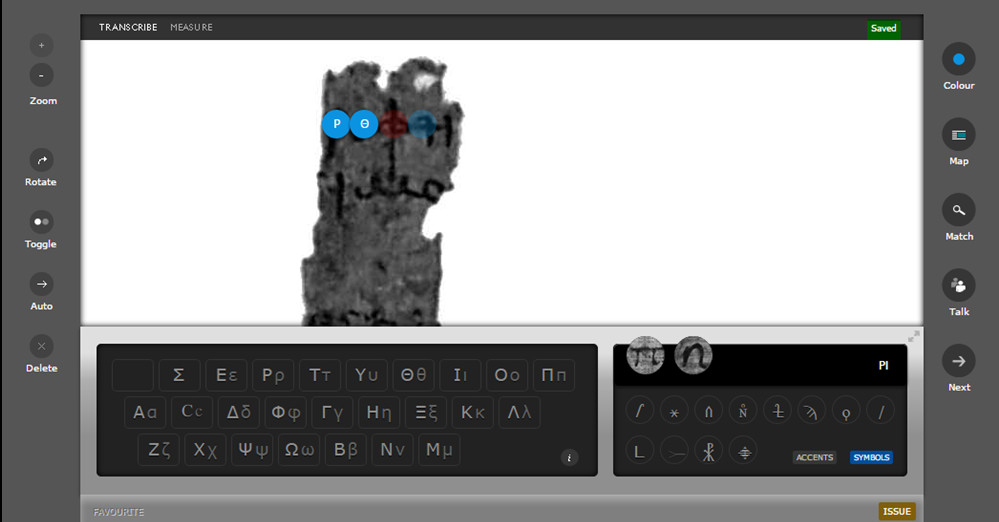
Figura 24. Mostra de la transcripció que s’utilitza a l’Ancient Lives
També destaca l’apartat «Talk»: es tracta d’una mena de fòrum on els diferents voluntaris poden compartir les seves experiències, demanar consell, ajudar-ne d’altres, etc. (vegeu la figura 25).
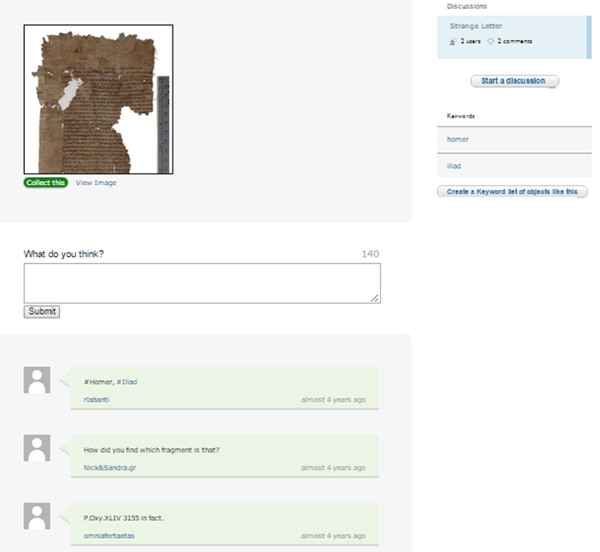
Figura 25. Mostra del fòrum «Talk» a l’Ancient Lives
4.1.11 Genealogy Vertical File Transcription Projec
Es tracta d’una iniciativa sorgida dins el projecte de North Carolina Family Records Online de la State Library and State Archives of North Carolina (EUA) que pretenia posar a disposició del públic diferents materials conservats en aquesta institució.
La particularitat d’aquest projecte és que usa la xarxa social Flickr, que mostra les imatges a transcriure i els voluntaris només cal que afegeixin un comentari amb el text transcrit (vegeu la figura 26).
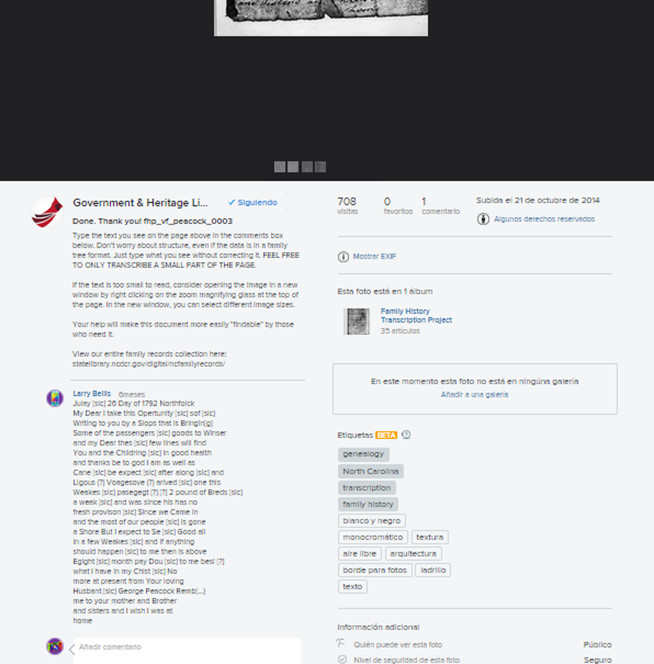
Figura 26. Mostra de la xarxa social Flickr i les transcripcions mitjançant comentaris al Genealogy Vertical File Transcription Project
4.1.12 Edvard Munch’s Writings
El Munch Museum’s projectes va crear el 2011 i vol posar a disposició del públic unes 13.000 pàgines corresponents a documentació manuscrita que es conserva del pintor.
Es tracta d’un projecte amb moltes similituds amb el Transcribe Bentham, ja que van rebre suport d’aquest últim.
Un element molt potenciat és l’apartat de comunicacions, tant entre els administradors com entre els voluntaris, les xarxes socials, els fòrums, etc. (vegeu la figura 27).

Figura 27. Mostra dels diferents canals de comunicació a l’Edvard Munch’s Writings
4.1.13 Transcribe ScotlandPlaces
L’any 2012 es va llançar el Transcribe ScoltlandPlaces, un portal web que té com a objectiu transcriure informació de més de 150.000 pàgines de documentació històrica, datada entre 1645 i 1880, per identificar els llocs actuals i també localitzar personatges de la història d’Escòcia.
El voluntari cal que es registri i seleccioni les diferents col·leccions en les quals vol participar. Un cop transcorregut un període de setanta-dues hores, els administradors donen accés a la transcripció (vegeu la figura 28). D’aquesta manera es vol aconseguir un major control, però també pot representar una pèrdua de voluntaris.
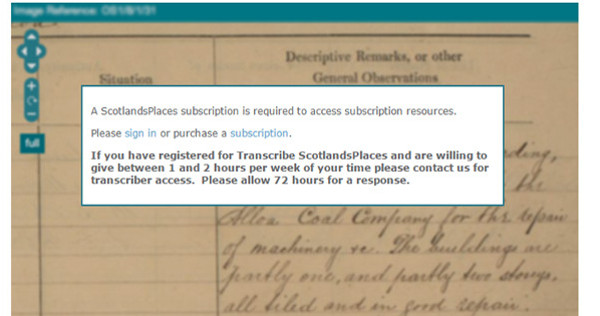
Figura 28. Mostra del missatge d’espera de setanta-dues hores per començar a transcriure
Destaca el fet que s’han ofert més de cinquanta xerrades i tallers a tot Escòcia per promoure la participació de la gent.
4.1.14 The arcHIVE
Els National Archives of Australiadins el projecte National Archives’ Labs Environment5 van crear una plataforma web anomenada The arcHIVE, que pretén que diferents voluntaris els ajudin a fer els seus registres més accessibles.
Seguint el mateix esquema que al Trove —citat anteriorment—, es mostra una caixa blanca per transcriure els documents una vegada se’ls hi ha aplicat l’OCR.
La cerca i el filtratge documental té moltes possibilitats, ja que permet seleccionar la dificultat, l’estat de progrés del document o la col·lecció a transcriure (vegeu la figura 29).

Figura 29. Mostra de les diferents possibilitats de cerca al The arcHIVE
El registre de l’usuari és voluntari, tot i que el fet de registrar-se comporta que quedin inventariades les tasques dutes a terme i sumin punts, tant per al rànquing de transcriptors com per poder intercanviar-ho per una recompensa (vegeu la figura 30).
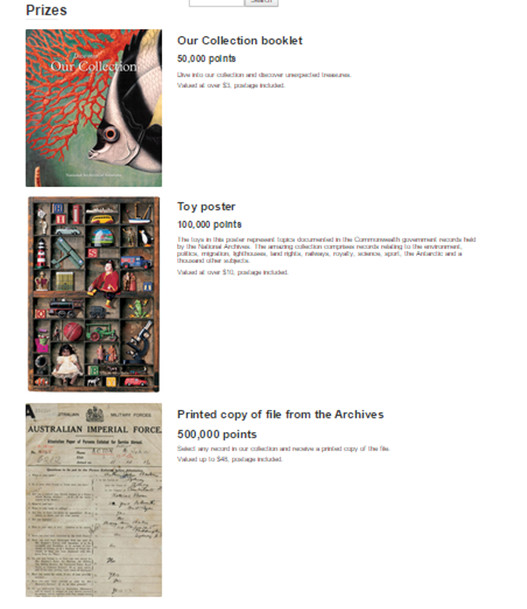
Figura 30. Recompenses al The arcHIVE
4.1.15 Smithsonian Digital Volunteer: Transcription Center
El juliol del 2013 va posar-se en marxa el Transcription Center de l’Smithsonian Digital Volunteer. El projecte volia transcriure milers de documents provinents d’aproximadament unes trenta col·leccions de diferents museus, arxius i biblioteques de la Smithsonian Institution.6
Per tal de seleccionar el document que es vol transcriure, es mostra una codificació de colors (verd, groc i vermell) segons l’estat del document i la tasca que vulgui fer el voluntari (vegeu la figura 31).

Figura 31. Estat del progrés del document al Smithsonian
4.1.16 Ensemble
La New York Public Library for the PerformingArts va iniciar el 2013 aquest projecte per transcriure els diferents elements (nom del teatre, la ubicació, el títol, els personatges, etc.) que apareixen als programes de teatre, dansa o concerts.
D’aquest projecte destaca el tipus de transcripció guiada, ja que amb el document original en pantalla, cal seleccionar els diferents elements a transcriure i, una vegada seleccionats, s’ha d’indicar el camp que hauria d’omplir-se (vegeu la figura 32). A més, una vegada seleccionat el camp se’ns ofereixen llistes d’autoritats per a un major control de la qualitat.
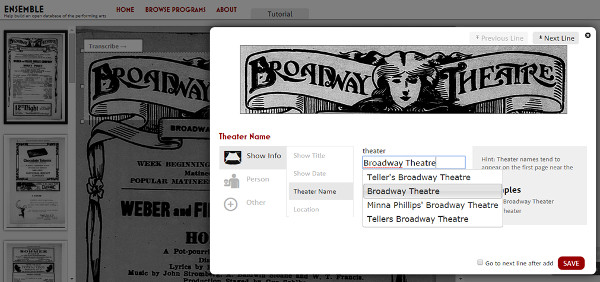
Figura 32. Mostra de transcripció guiada a l’Ensemble
4.1.17 Transcriu-me!!
L’any 2013 la Biblioteca de Catalunya amb el Consorci de Serveis Universitaris de Catalunya impulsen el projecte Transcriu-me!! per tal de millorar l’accés a la seva documentació. Més endavant, altres institucions com la Filmoteca de Catalunya o la Universitat de Barcelona també van sumar-se al projecte.
La transcripció es fa mitjançant una caixa blanca i es mostren les normes de descripció a la mateixa pantalla (vegeu la figura 33).

Figura 33. Mostra de la tipologia de transcripció i les directrius al Transcriu-me!!
4.1.18 Letters of 1916
Es tracta d’un projecte iniciat el 2013 per diferents institucions d’Irlanda per recopilar i transcriure cartes provinents de l’època de l’Easter Rising.7
Els documents que s’han de transcriure es mostren en diferents col·leccions segons temàtiques, sense determinar el percentatge de documents transcrits o la dificultat de nivell (vegeu la figura 34).

Figura 34. Mostra de les diferents col·leccions al Letters of 1916
4.1.19 MicroPasts: Crowdsourcing
L’octubre de 2013 va néixer el projecte MicroPasts de la British Library, la University College of London i l’Arts and Research Council. A través d’una plataforma lliure i de codi obert (Pybossa) es volen recollir massivament dades de qualitat de diferents temàtiques com l’arqueologia, la història o el patrimoni.
El tipus de transcripció és guiada, ja que cal transcriure el document en diferents camps, es pot visualitzar la imatge a una resolució més gran per mitjà de Flickr i permet geolocalitzar les obres a través d’un mapa de Google (vegeu la figura 35).
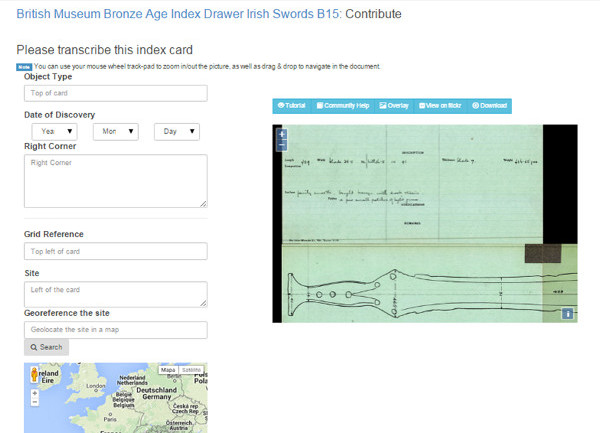
Figura 35. Mostra de la transcripció guiada del MicroPasts
4.1.20 Cynefin: Mapping Wales’ sense of Place
El 2014 es va posar en marxa aquest projecte per tal de recollir informació rellevant de la localització de les balenes al Regne Unit.
Per tal de seleccionar un document apareix un mapa i el voluntari pot escollir la zona del país on vol transcriure i geolocalitzar els documents (vegeu la figura 36).
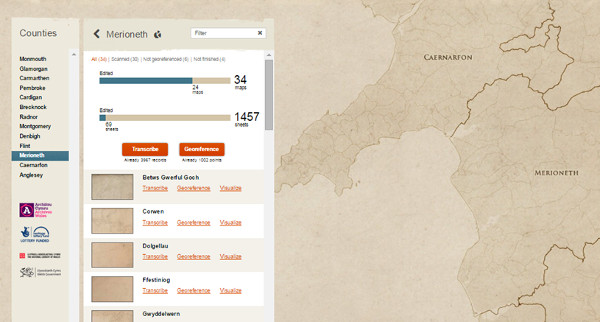
Figura 36. Mostra dels documents a transcriure dins d’una col·lecció al Cynefin
Cal destacar el fet que per agilitzar el procés del registre, el voluntari pot utilitzar qualsevol de les xarxes socials principals (vegeu la figura 37).
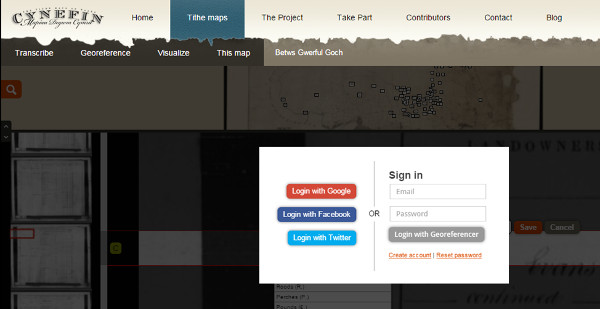
Figura 37. Mostra de la varietat de maneres de registrar-se al Cynefin
4.1.22 Quadre resum
A continuació es mostra un quadre resum dels diferents projectes amb la puntuació resultant per a cada indicador.
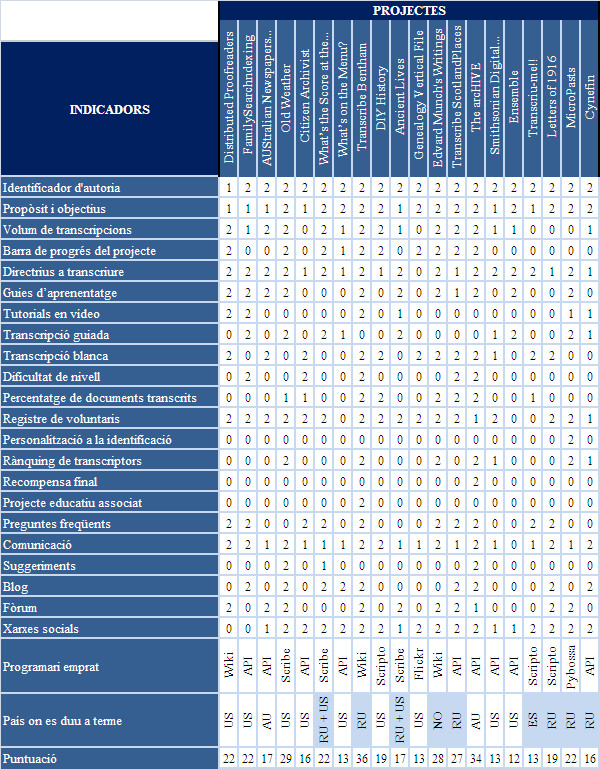
Taula 2. Quadre resum dels diferents projectes analitzats
En resum, podem comprovar que hi ha certs indicadors que es compleixen gairebé a tots els projectes, com ara la identificació de l’autoria que fa el projecte o quins són els objectius que es volen aconseguir. També el fet d’incloure al projecte les directrius de com transcriure i demanar als voluntaris un registre per participar al procés. Finalment, l’ús de les xarxes socials és bàsic per donar a conèixer el projecte i fer-lo extensiu.
D’altra banda, hi ha tres grans grups diferenciats segons el grau d’acompliment dels indicadors estudiats. Tenint present que el màxim de puntuació que podia assolir cada projecte era de 44 punts, en la posició més alta, i amb una puntuació de 36 i 34, respectivament, trobem el Transcribe Bentham i el The arcHIVE. Posteriorment, en un esglaó per sota trobem l’Old Weather (amb 29 punts), l’Edvard Munch’s Writing (amb 28) i el Transcribe ScotlandPlaces (amb 27). I, finalment, la resta de projectes obtenen una puntuació igual o menor a 22 punts.
Per tant, podem concloure que es duen a terme molts projectes de transcripció massiva a escala internacional, però que tan sols alguns són la punta de llança d’aquest tipus d’iniciatives.
5 Bones pràctiques en projectes de transcripció massiva
Tenint present el quadre resum dels diferents projectes analitzats, podem determinar un conjunt de bones pràctiques que s’han de tenir en compte en el disseny d’un projecte de transcripció massiva.
- Descripció del projecte, com s’origina, a quina institució pertany i què pretén aconseguir. Fixar tot aquest tipus d’informació aporta seguretat al voluntari i li permet tenir una idea clara del que pot representar la seva aportació.
- Mostra d’una barra de progrés del procés. És un element que tècnicament no representa cap tipus de complicació ni esforç a la institució i que pot ajudar un voluntari dubtós a participar-hi o no segons quin sigui l’estat del procés. Aquesta barra de progrés pot desglossar-se en diferents si el projecte inclou diferents col·leccions.
- Fixació de directrius de transcripció i utilització de guies d’aprenentatge i tutorials per adaptar-se a l’entorn. Fixar unes directrius de transcripció, que es mostrin de manera fàcil a l’hora de transcriure, pot ajudar el voluntari a resoldre dubtes en les seves aportacions. Tot i així, revisar una guia d’aprenentatge o veure un tutorial sempre és més agraït que no haver de llegir dos fulls on s’explicita com es transcriuen els documents.
- Utilització fàcil i senzilla de l’eina per transcriure. Apostar per una interfície senzilla fa que no hi hagi fractura digital per al voluntari novell i dóna les mateixes oportunitats a tothom.
- Aposta per la transcripció guiada i determinar el nivell de dificultat de cada document. Cal apostar per la transcripció guiada a la caixa blanca perquè ajuda el voluntari a fer la tasca més ràpidament i de manera més correcta. A més, la classificació dels documents segons el nivell de dificultat permet als principiants començar a transcriure els documents més adaptats al seu nivell.
- Identificació del voluntari per personalitzar l’entorn. A banda d’aquesta personalització, fa agafar un compromís al voluntari si les transcripcions que va fent queden registrades i pot veure també la seva evolució.
- Creació de rànquings de participació i oferiment d’una recompensa final. Es tracta de fidelitzar els voluntaris i premiar la seva dedicació en la transcripció de documents.
- Vinculació de les transcripcions a projectes educatius. Cal vincular aquest tipus de projectes a altres de caràcter més educatiu per fer entendre la història i el patrimoni d’una manera més experimental.
- Ús de les xarxes socials, els fòrums i els blogs per mantenir la comunicació amb els voluntaris. Es tracta d’un element bàsic per tal de fidelitzar els usuaris i, a la vegada, que puguin difondre allò que fan. Això pot ajudar a «enganxar» nous usuaris.
Bibliografia
Barrueco Cruz, J. et al. (2014). Guía para la evaluación de repositorios institucionales de investigación [en línia]. 2a ed. Recolecta, FECYT–CRUE–REBIUN <http://recolecta.fecyt.es/sites/default/files/contenido/documentos/GuiaEvaluacionRecolecta_v.ok_0.pdf>. [Consulta: 21 maig 2015].
Berners-Lee, T.; Fischetti, M. (2000). Tejiendo la red: el inventor del world wide web nos descubre su origen. Madrid: Siglo XXI de España editores. ISBN 8432310409.
Codina, L. (2000). Evaluación de recursos digitales en línea: conceptos, indicadores y métodos. Revista española de documentación científica [en línia]. <http://redc.revistas.csic.es/index.php/redc/article/viewFile/315/479>. [Consulta: 5 maig 2015].
Estellés-Arolas, E.; González-Ladrón-de-Guevara, F. (2012). «Towards an integrated crowdsourcing definition». Journal of Information Science, vol. 38, no. 2, p. 189–200. <http://www.crowdsourcing-blog.org/wp-content/uploads/2012/02/Towards-an-integrated-crowdsourcing-definition-Estell%C3%A9s-Gonz%C3%A1lez.pdf>. [Consulta: 10 gener 2015].
Haythornthwaite, C. (2009). «Crowds and communities: Light and heavyweight models of peer production». System Sciences, 2009. HICSS’09. 42nd Hawaii International Conference on. IEEE. p. 1–10.
Howe, J. (2006). «The Rise of Crowdsourcing». Wired magazine, no. 14.06. <http://archive.wired.com/wired/archive/14.06/crowds.html>. [Consulta: 10 gener 2015].
Knoll, T. (2011). «Are Your Customers a Crowd or a Community? «. SXSW Interactive 2011. <http://lanyrd.com/2011/sxsw/scqyt/>. [Consulta: 23 maig 2015].
Lévy, P. (1997). Collective intelligence: Mankind’s Emerging World in Cyberspace. New York and London: Plenum Press. ISBN 978-0-306-45635-0.
Rheingold, H. (2003). Smart mobs. De Boeck Supérieur, vol. 1, p. 75–87. ISSN 0765-3697. <http://www.cairn.info/resume.php?ID_ARTICLE=SOC_079_0075>. [Consulta: 5 maig 2015].
TERMCAT (2012). Crowdsourcing en català [en línia]. Generalitat de Catalunya. Departament de Cultura <http://www.termcat.cat/ca/Comentaris_Terminologics/Finestra_Neologica/142/>. [Consulta: 30 maig 2015].
Notes
* Aquest article té com a origen un treball final del grau d’Informació i Documentació de la Facultat de Biblioteconomia i Documentació de la Universitat de Barcelona, defensat el juliol de 2015 amb la tutorització de Ciro Llueca i Fonollosa.
1 Directrius per a projectes de digitalització de col·leccions i fons de domini públic, en especial els de biblioteques i arxius (2006) [en línia]. Barcelona: Col·legi Oficial de Bibliotecaris-Documentalistes de Catalunya. ISBN 8486972221. <http://www.cobdc.org/publica/directrius/sumaris.html>. [Consulta: 20 maig 2015].
2 Institució sense ànim de lucre fundada l’any 1971 per Michal S. Hart. L’objectiu és crear la biblioteca digital amb textos complets de domini públic més gran del món i es manté gràcies a l’esforç de voluntaris i el microfinançament.
3 Societat vinculada estretament l’església de Jesucrist dels Sants dels Últims Dies, coneguda com l’església mormona.
4 El Zooniverse és un portal web de ciència ciutadana creat i mantingut per la Citizen Science Alliance. Els diferents partners d’aquesta aliança són l’Adler Planetarium (EUA), la Johns Hopkins University (EUA), la University of Minnesota (EUA), el NationalMaritime Museum (UK), la University of Nottingham (UK), l’Oxford University (UK) i el Vizzuality. L’objectiu principal és crear projectes de crowdsourcing que puguin promoure una investigació científica a posteriori, en diferents disciplines com ara l’astronomia, l’ecologia, la biologia cel·lular, les humanitats o la climatologia. El projecte original va ser el Galaxy Zoo, on els voluntaris classificaven galàxies segons les seves característiques. Segons dades del 2014, la comunitat del Zooniverse ja havia superat el milió d’usuaris registrats i havia promogut més de setanta articles científics.
5 Laboratori d’entorns referents al National Archives of Australia. Per tal de millorar l’accés a la col·lecció es creen diferents prototips que poden arribar a desenvolupar serveis de producció o poden quedar-se en un estat de prova pilot.
6 Institució finançada pel Govern dels EUA que té com a objectiu l’augment i la difusió del coneixement. Està conformada per dinou museus de diferents àmbits (artístics, zoològics o històrics, entre altres) i diferents centres de recerca (arxius, instituts de recerca o biblioteques).
7 L’Easter Rising, també coneguda com la Rebel·lió de la Pasqua, va ser un aixecament que va dur a terme el consell militar de la Irish Republican Brotherhood (republicans d’Irlanda) durant la Pasqua de 1916 per posar fi a la dominació britànica i separar-se del Regne Unit.
 Llicència Creative Commons de tipus Reconeixement-NoComercial-SenseObraDerivada. Aquest article es pot difondre lliurement sempre que se’n citi l’autor i l’editor amb els elements que consten en la secció «Citació recomanada». No se’n pot fer, però, cap obra derivada (traducció, canvi de format, etc.) sense el permís de l’editor. Així, BiD compleix amb la definició d’open access de la Declaració de Budapest a favor de l’accés obert. La revista també permet que els autors mantinguin els drets d’autor i els de publicació sense restriccions.
Llicència Creative Commons de tipus Reconeixement-NoComercial-SenseObraDerivada. Aquest article es pot difondre lliurement sempre que se’n citi l’autor i l’editor amb els elements que consten en la secció «Citació recomanada». No se’n pot fer, però, cap obra derivada (traducció, canvi de format, etc.) sense el permís de l’editor. Així, BiD compleix amb la definició d’open access de la Declaració de Budapest a favor de l’accés obert. La revista també permet que els autors mantinguin els drets d’autor i els de publicació sense restriccions.