
Jordi Ardanuy
Professor de la Facultat de Biblioteconomia i Documentació
Universitat de Barcelona
Resum
El segle XXI ha dut la irrupció significativa de les tecnologies de la informació en la recerca desenvolupada a l’àrea de les humanitats. La intervenció de les unitats d’informació, especialment de les biblioteques universitàries, ha tingut —i ha de tenir encara— un paper significatiu en processos com la digitalització, però també en la formació i divulgació dels recursos. El folklore, com a disciplina d’humanitats, no està exempt d’aquesta evolució. En aquest context s’analitza el MOMFER, un recurs en línia que millora substancialment l’ús del Thompson’s Motif-Index of Folk Literature. Això no obstant, atès l’ambiciós objectiu perquè l’eina sigui la base d’un índex complet universal, caldrà capacitat de lideratge, i, segurament, habilitar o desenvolupar espais vinculats de col·laboració virtual.
Resumen
El siglo XXI ha llevado a la irrupción significativa de las tecnologías de la información en la investigación desarrollada en el área de las humanidades. La intervención de las unidades de información, especialmente de las bibliotecas universitarias, ha tenido —y debe tener todavía— un papel significativo en procesos como la digitalización, pero también en la formación y divulgación de los recursos. El folclore, como disciplina en el campo de las humanidades, no está exento de esta evolución. En este contexto se analiza el MOMFER, un recurso en línea que mejora sustancialmente el uso del Thompson’s Motif-Index of Folk Literature. No obstante, dado el ambicioso objetivo en que la herramienta sea la base de un índice completo universal, será necesario una fuerte capacidad de liderazgo, y, seguramente, habilitar o desarrollar espacios vinculados a la colaboración virtual.
Abstract
The twentieth century has brought significant emergence of information technology in research carried out in the area of the humanities. The intervention of information units, especially university libraries, has played -and must still have- a significant role in processes such as scanning, but also in training and dissemination of resources. Folklore as a discipline of humanities is not exempt from this evolution. This is the context where MOMFER is analyzed, an online resource that substantially improves the use of Thompson’s Motif-Index of Folk Literature. However, considering the ambitious goal for which the tool forms the basis of a comprehensive universal index, leadership will be required; and surely, to enable or to develop linked spaces of virtual collaboration.
1 Introducció: les humanitats digitals
Es defineixen habitualment les humanitats digitals com l’aplicació de les eines i processos informàtics a la recerca en les humanitats (Schreibman; Siemens; Unsworth, 2004; John Burdick et al. 2012).
L’ús de l’expressió anglesa digital humanities es remunta a l’any 2001, quan es discutia el títol de la col·lecció de llibres que s’acabaria anomenant Companion to Digital Humanities, publicats per Blackwell. La primera idea era utilitzar humanities computing, que era el terme emprat més comunament, però s’acabà imposant el criteri del consumat especialista i bibliotecari universitari John Unsworth (Kirschenbaum, 2010). L’expressió s’ha acabat utilitzat àmpliament i manllevat a altres llengües.1
Les humanitats digitals, que alguns han considerat que representen per si mateixes «una manera de raonar» per la postura epistemològica que implica l’expressió a través d’artefactes tecnològics (Unsworth 2002), tenen els orígens en els primers usos dels ordinadors aplicats a les humanitats. En aquest sentit cal citar el sacerdot italià Roberto Busa que als anys 1950 posà en marxa un projecte per lematitzar les obres de Tomàs d’Aquino (Busa, 1980; Smith, 2002; Hockey, 2004). Publicat en 49 volums entre 1974 i 1979, l’Index Thomisticus es convertí en paradigma, alhora que en una eina de gran importància per a teòlegs, filòsofs, historiadors de la cultura, medievalistes, llatinistes i lingüistes (Burton, 1984).
La irrupció de la tecnologia en el camp de les humanitats ha proporcionat motius de reflexió que han abastat la filosofia, la teoria narrativa, l’estètica o la política (Bolter, 1991; Lanham, 1993; Landow, 1994). S’han forjat grans esperances davant les possibilitats del text electrònic tant per a l’expressió creativa com per a la recerca acadèmica (McGann, 1996; 2001). També s’han generat tensions i han aparegut discursos crítics i nostàlgics (Birkerts, 1994; Duguid, 2007). Però, a banda d’alguns projectes experimentals i d’avantguarda, el cert és que a principis del segle actual les humanitats es mantenien relativament no informatitzades (Drucker, 2002; 2006). Els avenços en l’àrea no eren utilitzats pels acadèmics i l’existència de revistes com Computers in the Humanities (1966-2004), durant anys bandera de la disciplina, transcorria sense gairebé impacte (Juola, 2008). Altrament, molts dels recursos digitals que s’havien generat en humanitats, tot i trobar-se disponibles a Internet, resultaven de difícil localització per als lectors potencials, atesa la pobresa descriptiva i la manca d’una informació sistematitzada (Dunning, 2006; Pappa et al., 2006). Tanmateix, la situació sembla que està canviant amb l’aparició d’un nombre considerable de recursos, un dels quals, MOMFER, un motor de cerca específic que explora motius del folklore, es presenta aquí.
2 El cas del folklore
A diferència del que succeeix en les ciències experimentals, en humanitats els objectes d’estudi són d’habitud fonts d’informació primàries, com ara llibres, manuscrits, documents històrics, diaris, imatges, etc. D’aquí la importància que Susan Hockey atorga, en la seva història de les humanitats digitals, a la creació l’any 1987 de la TextEncoding Initiative (TEI)2 amb la finalitat de desenvolupar i mantenir un estàndard per a la representació de textos en format digital, la primera versió de la qual aparegué l’any 1994 (Hockey, 2004). La codificació de text és una de les eines més utilitzades dins de les humanitats digitals i un camp on les biblioteques universitàries tenen un paper rellevant en la creació, ús i difusió (Gallina-Russell, 2012; Green, 2014). Però com també assenyala Hockey, amb l’adveniment de la xarxa d’Internet i la sofisticació de les tecnologies de publicació electrònica s’ha passat de la simple digitalització de textos impresos a la creació nativa de recursos directament electrònics, que permeten presentar, manipular, explotar i visualitzar continguts acadèmics en formes inèdites, que faciliten emprendre recerques que abans no eren possibles i, potser, de vegades ni tan sols imaginables.
En el camp concret del folklore, abans de l’ús generalitzat dels ordinadors, els treballs quantitatius s’havien limitat a confeccionar llistes dels fets estudiats, a comptar el nombre d’aparicions i fer càlculs força simples, com ara el recompte de percentatges. Als anys 1960 i 1970 alguns folkloristes començaren a utilitzar ordinadors per examinar agrupacions temàtiques. La tecnologia de l’època, tal com passava amb l’Index Thomisticus, obligava a l’ús de targetes perforades per processar una gran quantitat de dades, com ara col·leccions regionals sobre supersticions i narrativa popular sobrenatural (Weingart; Jorgensen, 2013).
Més recentment, Tim Tangherlini ha utilitzat eines informàtiques per analitzar estadísticament els components dels textos (1998) i sistemes d’informació geogràfica per crear mapes de xarxes dels narradors (2010). Per la seva banda, Kathleen Ragan (2009) ha analitzat les xarxes de relació que es formen entre el gènere sexual del personatge i el dels editors, recol·lectors d’històries i narradors, i Weingart i Jorgensen (2013) han explotat una base de dades de contes de fades creada ad hoc en la qual es recull la percepció del cos o de les seves parts, analitzant així quantitativament la percepció social des d’una perspectiva d’edat i de gènere.
3 L’índex de motius de la literatura popular
Un dels pilars fonamentals de la disciplina del folklore és la necessitat d’una classificació exhaustiva de tot tipus de materials de la narrativa tradicional. Per això s’han desenvolupat diverses eines, com l’índex de motius de la literatura popular de Thompson (TMI, sigla de l’anglès Thompson’s Motif-Index of Folk Literature), que s’ha convertit en una eina indispensable per als estudiosos del folklore (Dundes, 2007). En aquest cas no es tracta d’un recurs primari sobre el qual es fa recerca, com un manuscrit, sinó d’una eina que la facilita. Però la mida i estructura n’han condicionat l’ús i el manteniment, problemes que, ara, gràcies a la tecnologia, poden estar en vies de solució.
3.1 Característiques del TMI
El TMI és una eina de classificació i indexació de motius com ara personatges, accions o fets que apareixen a la literatura popular, inclosos els contes de fades, les balades, els mites, les faules, els exempla, els romanços medievals, les llegendes locals, els reculls d’acudits i endevinalles, etc. L’índex classifica els motius en categories generals i inclou crides a peces de la literatura on apareixen aquests motius.
El TMI conté més de quaranta-cinc mil motius distribuïts al llarg de cinc volums. Els motius estan jeràrquicament ordenats en una estructura d’arbre. N’hi ha vint-i-tres de nivell superior, etiquetats alfabèticament (A-Z, sense I ni Y). Els continguts van des de motius mitològics (categoria A) a motius relacionats amb trets decaràcter (W) o l’humor (X). Cadascuna d’aquestes categories de nivell superior es divideix en diverses subcategories. Així, per exemple, la categoria sobre la mort (E) es divideix en: Ressuscitation, (E0-E199), Ghosts and other revenants (E200-599), Reincarnation (E600-E699) i the Soul (E700-E799). Cadascuna d’elles, al seu torn també es ramifica i així successivament, si escau. En els nodes terminals es localitzen les expressions més concretes d’un motiu folklòric particular, per exemple, Soul in animal form (E730). La figura 1 és una mostra parcial de l’arbre jeràrquic del TMI.
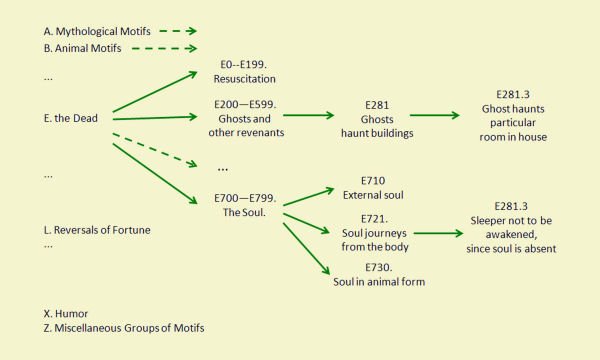
Figura 1. Esquema parcial de l’arbre jeràrquic del TMI
L’organització jeràrquica no respon a un pla preconcebut d’organització de motius, sinó que és el resultat d’una evolució gradual, com el mateix autor afirmà (Thompson 1955–1958, p. 19). Això comporta una distribució desigual dels motius dins les categories superiors, de manera que les categories A-K contenen el 78 % de tots els motius. I el que és pitjor, l’aparició de setanta-dos motius dues vegades, sota diferents hiperònims, que constitueixen, en realitat, cent quaranta-quatre motius únics.
Una de les característiques significatives d’aquesta eina és que els motius recuperats no es limiten al terme introduït i a la seva posició jeràrquica, ja que s’han expandit semànticament. D’aquesta manera, quan l’usuari cerca un terme simple o compost de diverses paraules, el sistema retorna, no solament els motius en els quals el terme apareix explícitament, sinó també els motius connectats conceptualment amb un grau més gran o més petit d’especificitat. Per exemple, una cerca amb l’equació object AND size recupera, entre d’altres, el motiu Tree so large that it darkens whole world. Per poder fer això el sistema utilitza WordNet, una base de dades lèxica en anglès que agrupa paraules en conjunts de sinònims anomenats synsets i emmagatzema les relacions semàntiques jeràrquiques entre termes. Així, per exemple, una paraula com canine està vinculada a hipònims o termes més específics com ara dog o wolfi a hiperònims com carnivore i, finalment, entity, que etiqueta tots els motius. Per qüestions pràctiques el MOMFER recupera en cada cas només les dues relacions de parentiu cap amunt i cap avall respecte del terme cercat. Així si un usuari cerca pel terme dog, el sistema també buscarà tot allò que cau sota la categoria de canine i carnivore, per exemple wolf, i cat. Els motius recuperats gràcies a aquesta cerca ampliada es presenten ordenats en posicions inferiors en el rànquing de resultats dels que contenen els termes de cerca inicials, atesos els pesos assignats als diferents camps de cerca.
Aquesta expansió semàntica facilita enormement la recuperació de termes. Per exemple, un terme relativament recent com occultist, aparegut el darrer quart del segle xix, no apareix cap cop al TMI. Malgrat això actualment és molt possible que l’usuari vulgui recuperar expressions en termes com druids, enchanters, magicians, sorcerers, witches, wizards, etcètera, que denoten significats propers.
Per construir l’índex sobre el qual es fan les cerques, cadascun dels motius del TMI s’ha processat i dividit en quatre camps: l’identificador alfanumèric únic, que informa sobre el seu lloc jeràrquic; la descripció principal; la descripció secundària, que no sempre és present, i, les referències bibliogràfiques, que poden incloure localització. Per exemple:

Quan l’usuari consulta una cerca, l’índex recupera els primers resultats que, després de la ponderació, són presentats a l’usuari. Aquest rànquing, a més de considerar l’expansió semàntica tal com s’ha dit, pondera el camp on apareix el terme. Per exemple, si el terme de cerca és book, es considera més rellevant que aparegui a la descripció que no pas a la bibliografia. Així, el sistema assigna pesos en ordre decreixent des del camp de descripció principal fins a la informació bibliogràfica (vegeu la taula 1). Si el terme apareix en més d’un camp s’acumulen els pesos, per la qual cosa ocupa un lloc més prominent en els resultats.
| Ordre de rellevància | Camp o situació en què es localitza |
|---|---|
|
1 |
Descripció principal |
|
2 |
Descripció secundària |
|
3 |
Expansió semàntica de WordNet |
|
4 |
Referències i localització |
Taula 1. Ordre de rellevància segons el camp on apareix el terme cercat
El resultats obtinguts es poden exportar en un fitxer TXT que es genera automàticament (vegeu la figura 5) prement una icona que apareix al costat del quadre de cerca quan es mostren els resultats (vegeu la figura 6).

Figura 5. Fragment del contingut del fitxer d’exportació generat en fer la cerca book
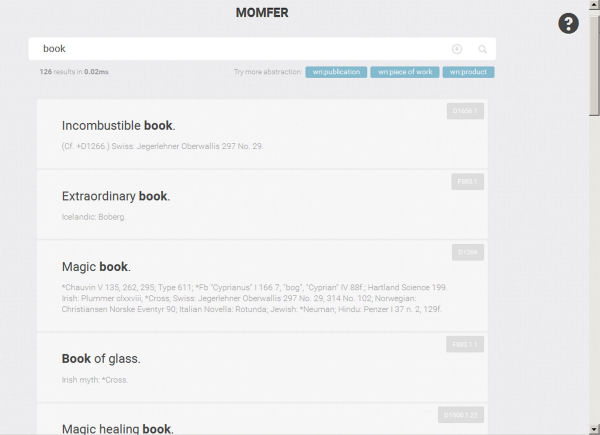
Figura 6. Interfície de resposta del MOMFER amb els primers resultats de la cerca book. S’aprecia l’aparició de la icona per generar el fitxer d’exportació a la dreta de la quadre de cerca.
Finalment, ens ocuparem de les eines de cerca. La cerca més simple funciona a partir de la introducció d’un terme al quadre de cerca. Els resultats es presenten ordenats jeràrquicament segons rellevància tal com ja s’ha explicat. Si l’usuari introdueix més d’un terme, per defecte el sistema ho interpreta com una operació lògica amb un «o inclusiu» (OR). Així, per exemple, per a les paraules book i ghost, l’índex cerca tots els motius recuperables amb el terme book i amb el terme ghost (o ambdós alhora, naturalment). El resultat és equivalent si s’utilitza explícitament l’operador OR. Per forçar que el sistema recuperi els motius que alhora corresponguin als dos termes, cal utilitzar l’operador d’intersecció (AND), que es pot estendre a tants termes com requereixi l’usuari. Si cal excloure algun terme cal excloure’l amb l’operador de negació (AND NOT).
Els operadors de Boole es complementen amb el de frase exacta, truncament per la dreta i substitució d’un caràcter (vegeu la taula 2). Malgrat que no està documentat, el sistema suporta l’ús de parèntesi.
|
Operador |
Representació |
Exemple |
Resultat |
|---|---|---|---|
| O inclusiu |
Per defecte o bé OR |
book ghost book OR ghost |
Inclusió dels resultats de les cerques independents amb book i amb ghost |
| I |
AND |
book AND ghost |
Intersecció dels resultats de les cerques independents amb book i amb ghost |
| No |
AND NOT |
book AND NOT ghost |
Resultats de la cerca amb el terme book que no coincideixen amb els de la cerca amb ghost |
| Frase exacta |
Termes entre cometes |
«black cat» |
Motius amb l’expressió black cat en alguns dels camps. |
| Truncament per la dreta |
Asterisc |
cat* |
Motius començats per cat: cats, catapulc, catastrophes, caterpillar, etc. |
| Substitució d’un caràcter |
Signe d’interrogació |
c?t |
cat, cot i cut |
Taula 2. Operadors lògics disponibles al MOMFER
També és possible cercar per camps (vegeu la taula 3). Per exemple, per recuperar motius que mencionin una referència a Graham es pot escriure l’equació location:Graham, on el terme ve precedit per l’expressió references: De manera similar amb wn:colour s’obtenen motius amb paraules que recullen el concepte color, però no la paraula colour pròpiament.
|
Camp |
Representació |
Exemple |
Resultats |
|---|---|---|---|
| Motiu |
motif: |
motif:H659.7.3 |
Recupera exactament el motiu que es correspon amb l’identificador H659.7.3: What is the greatest?; Charity. Spanish Exempla: Keller |
| Descripció principal |
description: |
description:magic |
Motius que contenen el terme magic en la descripció principal |
| Descripció secundària |
addicional: |
additional:dragon |
Cerca el terme dragon en la descripció secundària |
| Expansió semàntica |
wn: |
wn:instrument |
Recupera motius que continguin termes associats al concepte instrument |
| Referències |
references: |
references:Graham |
Recupera motius en què el terme Graham forma part de la informació bibliogràfica. Tant serveix per a fonts com per a països d’origen, si s’indiquen en el TMI |
| Localització |
location: |
location:spain |
Recupera els motius del TMI en els quals la informació està basada en Espanya |
Taula 3. Camps sobre els quals es poden fer cerques específiques al MOMFER
6 MOMFER: breu discussió
El MOMFER és sens dubte una eina de gran interès per a estudiosos i aficionats al folklore. En aquests moments, resulta força satisfactòria quant a la millora d’efectivitat en l’ús del TMI respecte de productes com la mera versió en línia o StorySearch. El fet que el motor de cerca treballi fent una expansió semàntica millora enormement la possibilitat de recuperar motius.
El MOMFER, com qualsevol altra eina de recuperació de la informació, és susceptible de millora. Per exemple, actualment cerca a partir d’un únic quadre. Resultaria còmode disposar d’una cerca avançada que permetés disposar termes en quadres diferents i combinar-los amb els operadors lògics existents. D’altra banda, malgrat que les instruccions són prou clares, estaria bé que aquests quadres de cerca permetessin desplegar el camp (motiu, descripció principal, referències, etc.) sobre el qual es vol cercar. Aquestes són eines habituals en els sistemes de recuperació de la informació.
El MOMFER no incorpora mecanismes que el facin tolerant als errors. Atès que l’eina està dirigida sobretot a especialistes, no sembla pas que aquest fet hagi de ser un problema. A més, aquest tipus d’eines tendeixen a augmentar el nivell de soroll i la barreja amb l’expansió semàntica potser podria ser ben contraproduent.
Respecte dels resultats, seria útil dotar el MOMFER d’una eina de contextualització. Així seria convenient que cada instància obtinguda contingués un enllaç que permetés visualitzar-lo en la seva posició dins de l’arbre jeràrquic de motius, i facilités la navegació per aquest arbre i retornar des de qualsevol punt al motor de cerca. Aquesta prestació es podria estendre als diferents camps que formen cada motiu. Per exemple, navegar entre referències procedents d’un mateix país. El fet d’introduir aquestes prestacions permetria una explotació completa del TMI en afegir eines de navegació a les de cerca de les quals ja disposa.
Una limitació de naturalesa força diferent que el MOMFER presenta en aquests moments està relacionada amb els objectius de l’eina. Actualment no disposa ni té vinculat cap instrument de col·laboració, malgrat que els mateixos autors proposen explícitament (Karsdorp et al., 2015) que un dels objectius fonamentals de l’eina és aconseguir un índex de motius complet. I això necessita inexcusablement col·laboració internacional. És evident que ha d’haver-hi un control estricte respecte al manteniment i actualització de l’índex, perquè, deixant de banda d’altres problemes intrínsecs a la classificació del TMI, qualsevol proposta d’introducció d’un nou motiu s’ha de fer sota les màximes garanties que aquest element no està ja representat a l’índex. Però el sistema que permeti gestionar-lo hauria d’incorporar les eines de xarxa social que existeixen pel que fa a les propostes, debats, consens i resolució.
I encara un altre aspecte directament relacionat amb l’anterior. Per mostrar empíricament algunes de les noves possibilitats de recerca que permet el MOMFER, Karsdorp i els seus col·laboradors ofereixen alguns exemples: distribució geogràfica mundial d’observacions de monstres; freqüència d’aparicions de colors en els motius del TMI, i, estudi de gènere. Però és fàcil comprendre que si es volen fer estudis amb un nivell de detall important cal ser absolutament exhaustius en la incorporació de referències i localitzacions associades a cada motiu.
D’altra banda el TMI en certa manera és com una imatge fixa dels motius del folklore «tradicional» per la dificultat de poder-ne destriar els canvis produïts durant l’evolució cultural dels pobles. Malgrat això, sí que són susceptibles de ser recollides les versions actuals —sovint conegudes sota el paraigua de llegendes urbanes (Brunvand, 1981; Brednich, 1994; Sánchez Carretero, 2001)—, i incorporar-ne un vector temporal. Una tasca d’aquesta magnitud també ha de ser col·laborativa i potser necessita l’ajuda d’aficionats, atès el volum reduït de mitjans de la disciplina, si es compara amb d’altres, fins i tot, d’humanitats (Dundes, 2005; Widdowson, 2010). De nou, les eines tecnològiques col·laboratives semblen imprescindibles.
7 Conclusions
La tecnologia del segle xxi està introduint canvis significatius en els mètodes i formes de treballar de les humanitats. Fidel a la tradició d’aquestes disciplines potser els canvis no són accelerats i s’hagi de parlar més d’una evolució que no d’una revolució. Com ja han apuntat diversos autors, una part de la tasca tant pels processos implicats com per la formació, però també la divulgació, recau en el món de les biblioteques universitàries.
En aquest context d’humanitats digitals s’ha desenvolupat el MOMFER, una eina en línia que millora de manera molt considerable l’ús del TMI. Ara bé, per assolir un dels objectius marcats pels autors, que no és altre que aconseguir bastir un índex complet universal, caldrà una capacitat de lideratge significativa capaç d’endegar la col·laboració internacional. Per facilitar-la, sembla necessari el desenvolupament d’eines o espais de xarxes socials específics i vinculats directament al MOMFER.
8 Bibliografia
Birkerts, Sven (1994). The Gutenberg Elegies: The Fate of Reading in an Electronic Age. Boston: Faber & Faber.
Bolter, Jay David (1991). Writing Space: The Computer, Hypertext, and the History of Writing: Hillsdale: Lawrence Erlbaum Associates. [2a edició ampliada de 2001. New York: Routledge].
Brunvand, Jan Harold (1981). The Vanishing Hitchhiker, American urban legends and their meanings, Nova York: W. W. Norton & Company.
Burdick, Anne; Drucker, Johanna; Lunefield, Peter; Presner, Todd; Schnapp, Jeffrey (2012). Digital_Humanities. Cambridge: MIT Press.
Burton, Dolores M. (1984). «Reviews. Index Thomisticus: Sancti Thomae Aquinatis operum indices et concordantiae Roberto Busa». Speculum: A Journal of Medieval Studies, vol. 59, núm. 4, p. 901–894.
Busa, Roberto (1980). «The annals of humanities computing: the Index Thomisticus». Computers and the Humanities, vol. 14, núm. 2, p. 83–90.
Drucker, Johanna (2002). «Theory as praxis: the poetics of electronic textuality». Modernism/modernity, vol. 9, núm. 4, p. 683–691.
Drucker, Johanna (2006). «Humanities Games and the Market in Digital Futures». Criticism, vol. 47, núm. 2, p. 241–247.
Duguid, Paul (2007). «Inheritance and loss? A brief survey of Google Books». First Monday, vol. 12, núm. 8. <http://www.firstmonday.org/ojs/index.php/fm/article/view/1972/1847>. [Consulta 18 de març de 2016).
Dundes, Alan (2005). «Folkloristics in the Twenty-First Century (AFS Invited Presidential Plenary Address, 2004)». Journal of American Folklore, vol. 118, núm. 470, p. 385–408.
Dundes, Alan (2007). «The Motif-Index and the Tale Type Index: A Critique». Journal of Folklore Research, vol. 34, núm. 3, p. 195–202.
Dunning, Alastair (2006). «The Tasks of the AHDS: Ten Years on». Ariadne, núm. 48. <http://www.ariadne.ac.uk/issue48/dunning>. [Consulta: 18 març 2016).
Galina-Russell, Isabel (2012). Retos para la elaboración de recursos digitales en humanidades». El profesional de la información, vol. 21, núm. 2, p. 185–189.
Green, Harriett E. (2014). «Facilitating communities of practice in Digital Humanities: librarian collaborations for research and training in text encoding». Library Quarterly: Information, Community, Policy, vol. 84, núm. 2, p. 219–234.
Hockey, Susan (2004). «The History of Humanities Computing». En: Schreibman S.; Siemens, R.; Unsworth, J. (eds.). Companion to digital humanities. Oxford: Blackwell, 2004, p. 3–19.
Juola, Patrick (2008). «Killer Applications in Digital Humanities». Literary and Linguistic Computing, vol. 23, núm. 1, p. 73.83.
Karsdorp, Folgert; van der Meulen, Marten; Meder, Theo; van den Bosch, Antal (2015). «MOMFER: A Search Engine of Thompson’s Motif-Index of Folk Literature, Folklore». Folklore, vol. 126, núm. 1, p. 37–52.
Kirschenbaum, Matthew G. (2010). «What Is Digital Humanities and What’s It Doing in English Departments?». ADE Bulletin, núm. 150.
Landow, George P. (ed.) (1994). Hyper/Text/Theory. Baltimore: The Johns Hopkins University Press.
Lanham, Richard A. (1993). The Electronic Word: Democracy, Technology, and the Arts. Chicago: University of Chicago Press.
McGann, Jerome (1996). Radiant Textuality. <http://www2.iath.virginia.edu/public/jjm2f/radiant.html> [Consulta: 18 març 2016].
McGann, Jerome (2001). Radiant Textuality: Literary Studies after the World Wide Web. New York: Palgrave.
Pappa, Nikoleta; Warwick, Claire; Terras, Melissa; Huntington, Paul (2006). «The (in)visibility of digital humanities resources in academic contexts». En: Sun, C.; Menasri,S.; Ventura,J. (ed.). Digital humanities 2006. The First ADHO International Conference. Université Paris – Sorbonne. July 5th – July 9th. Conference Abstracts. Paris: Université de Paris-Sorbonne, Paris IV. Centre de Recherche Cultures Anglophones et Technologies de l’Information, p. 333–336.
Ragan, Kathleen. (2009). «What happened to the heroines in folktales? An analysis by gender of a multicultural sample of published folktales collected from storytellers». Marvels & Tales, vol 23, núm. 2, p. 227–247.
Rolf Wilhem Brednich (1994). «L’aranya a la iuca. Llegendes urbanes d’avui». Revista d’etnologia de Catalunya, núm. 4, p. 32–43.
Sánchez Carretero, Cristina (2001). «Llegendes urbanes i minories». Revista d’etnologia de Catalunya, núm. 19, p. 86–99.
Schreibman, Susan; Siemens, Ray; Unsworth, John (2004) «The Digital Humanities and Humanities Computing: An Introduction». En: Companion to digital humanities. Oxford: Blackwell, 2004, p. XXIII–XXVII.
Smith, Allen (1995). «JAL Guide to Software, Courseware and CD-ROM: Stith Thompson’s Motif-Index of Folk Literature». Journal of Academic Librarianship, vol. 20, núm. 4, p. 255.
Smith, Martha Nell (2002). «Computing: What’s American Literary Study Got to Do with IT?». American Literature vol. 74, núm. 4, p. 833–857.
Tangherlini, Timothy R. (1998). «Who Ya Gonna Call?’: Ministers and the mediation of ghostly threat in Danish legend tradition». Western Folklore, vol. 57, núm. 2–3, p. 153–178.
Tangherlini, Timothy R. (2010). «Legendary performances: folklore, repertoire, and mapping». Ethnographia Europaea, vol. 40, núm. 2, p. 103–115.
Thompson, Stith (1955-1958). Motif-Index of Folk-Literature: A Classification of Narrative Elements in Folktales, Ballads, Myths, Fables, Mediaeval Romances, Exempla, Fabliaux, Jestbooks, and Local Legends. Revised and enlarged. Bloomington: Indiana University Press
Unsworth, John (2002). What Is Humanities Computing and What Is Not?. <http://computerphilologie.uni-muenchen.de/jg02/unsworth.html>. [Consulta: 18 març 2016).
Weingart, Scott; Jorgensen, Jeana (2013). «Computational analysis of the body in European fairy tales». Literary and Linguistic Computing, vol. 28, núm. 3, p. 404–416.
Widdowson, John David Allison (2010). «Folklore Studies in English Higher Education: Lost Cause or New Opportunity?». Folklore, vol. 121, núm. 2, p. 125–142.
Notes
1 Pel que fa al català, la primera referència escrita que hem trobat a l’ús d’aquesta expressió traduïda és de maig de 2010 i obra del catedràtic de química i física de la UdG Miquel Duran Portas. En una entrada al seu blog Edunomia titulada «E-ciència en humanitats digitals», aquest professor comentava el número de tardor de 2009 de Digital Humanities Quarterly que estava dedicat a la l’e-Ciència en el domini de les arts i de les ciències humanes.
2 TEI: Text Encoding Initiative. <http://www.tei-c.org/index.xml>. [Consulta: 18 març 2016].
3 Thompson, Stith. Motif-Index of Folk-Literature: A Classification of Narrative Elements in Folktales, Ballads, Myths, Fables, Mediaeval Romances, Exempla, Fabliaux, Jestbooks, and Local Legends. Bloomington: Indiana University Press, 1993. CD-ROM.
4 <http://www.ruthenia.ru/folklore/thompson>. [Consulta: 18 març 2016]. També és possible baixar-se tot el contingut de cop en un sol fitxer HTML sense cap tipus d’eina de navegació incorporada.
5 <http://catalog.hathitrust.org/Record/001276245>. [Consulta: 18 març 2016].
6 <http://storyseeds.org/storysearch>. [Consulta: 18 març 2016].
7 El Meertens Instituut és un institut de recerca depenent de la Koninklijke Nederlandse Akademie van Wetenschappen.
 Llicència Creative Commons de tipus Reconeixement-NoComercial-SenseObraDerivada. Aquest article es pot difondre lliurement sempre que se’n citi l’autor i l’editor amb els elements que consten en la secció «Citació recomanada». No se’n pot fer, però, cap obra derivada (traducció, canvi de format, etc.) sense el permís de l’editor. Així, BiD compleix amb la definició d’open access de la Declaració de Budapest a favor de l’accés obert. La revista també permet que els autors mantinguin els drets d’autor i els de publicació sense restriccions.
Llicència Creative Commons de tipus Reconeixement-NoComercial-SenseObraDerivada. Aquest article es pot difondre lliurement sempre que se’n citi l’autor i l’editor amb els elements que consten en la secció «Citació recomanada». No se’n pot fer, però, cap obra derivada (traducció, canvi de format, etc.) sense el permís de l’editor. Així, BiD compleix amb la definició d’open access de la Declaració de Budapest a favor de l’accés obert. La revista també permet que els autors mantinguin els drets d’autor i els de publicació sense restriccions.