L’Omeka S com a alternativa per al desenvolupament de col·leccions digitals i projectes d’humanitats digitals
Objectius: es presenta una descripció detallada de les principals característiques i funcionalitats de l’Omeka S, un sistema de gestió de continguts de programari lliure per a la creació de repositoris i biblioteques digitals, utilitzat àmpliament en projectes d’humanitats digitals d’índole diversa.
Metodologia: l’anàlisi de les característiques de l’Omeka S s’ha realitzat a partir d’una revisió de la literatura publicada, la informació disponible en el lloc web i la documentació oficial de l’aplicació, i també mitjançant la seva instal·lació, ús i anàlisi. La descripció de l’aplicació es complementa amb una recopilació de diversos casos d’ús de caràcter internacional en l’àrea de les humanitats digitals que mostren la versatilitat de l’eina. Finalment, s’ofereix una comparativa amb cinc aplicacions més de programari lliure disponibles al mercat: Omeka Classic, CollectiveAccess, Mukurtu, ResearchSpace i Arches.
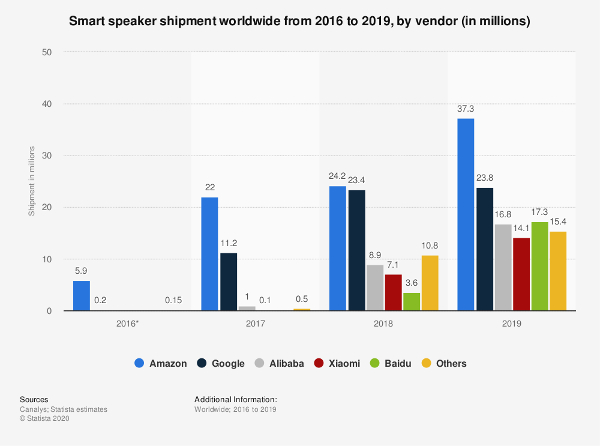
Resultats: entre els principals punts forts de l’Omeka S, destaca la seva facilitat d’instal·lació, manteniment i ús, la seva arquitectura multilloc, la facilitat per integrar vocabularis del web semàntic com ontologies, la seva flexibilitat per crear plantilles de descripció per als objectes digitals, la llibertat en el disseny de les pàgines que formen la interfície pública, o la seva integració nativa amb altres sistemes de gestió de repositoris com DSpace o Fedora Commons, amb la qual cosa es pot implementar com a plataforma per a la gestió i publicació de recursos derivats del repositori, o com a capa d’accés públic als seus objectes digitals, respectivament. D’altra banda, la gestió d’un projecte amb l’Omeka S requereix un esforç inicial més gran derivat de la seva gran flexibilitat. Finalment, el sistema es mostra menys competent en l’accés a la base de dades, el qual no és possible de manera nativa per mitjà de consultes SPARQL.