Objectius: aquest article reflexiona sobre el sorgiment dels fenòmens lifelogging i quantified self com una forma de viure a través de les dades personals generades pel mateix usuari. S’analitza la perspectiva social i tecnològica fent èmfasi en la gestió de les dades, i es descriu com els principis de les dades massives permeten entendre les oportunitats i complexitats que generen aquests fenòmens.
Metodologia: s’ha revisat la bibliografia publicada sobre els fenòmens lifelogging i quantified self des de l’aparició fins als nostres dies. La recerca bibliogràfica s’ha fet mitjançant bases de dades bibliogràfiques pels articles i cercadors generalistes per a la informació dels productes i aplicacions, així com per les notícies d’actualitat aparegudes a la premsa local i internacional.
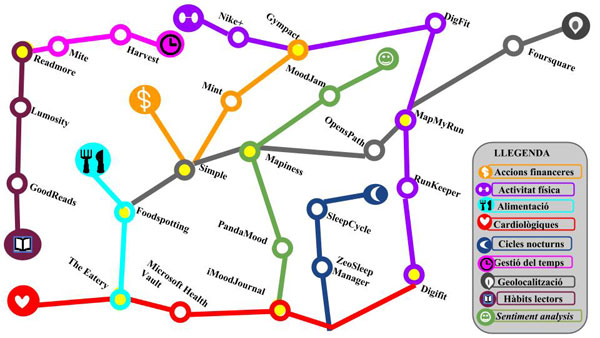
Resultats: el resultat és una taxonomia d’usos, aplicacions i eines de lifelogging i quantified self. Es conclou que un factor determinant en la seva evolució serà la capacitat de generar informació de qualitat a partir de les dades generades per l’usuari. En els dos casos es veu necessari establir estàndards i protocols que permetin una estructuració, gestió i anàlisi de les dades per tal d’optimitzar els potencials impactes positius que pot generar el fenomen del quantified self a la societat. — Objetivos: este artículo reflexiona sobre el surgimiento de los fenómenos lifelogging y quantified self como una forma de vivir a través de los datos personales generados por el propio usuario. Se analizan la perspectiva social y tecnológica haciendo énfasis en la gestión de los datos, y se describe cómo los principios de la inteligencia de datos (big data) permiten entender las oportunidades y complejidades que generan estos fenómenos.
Metodología: se ha revisado la bibliografía publicada sobre los fenómenos lifelogging y quantified self desde su aparición hasta nuestros días. La búsqueda bibliográfica se ha realizado en bases de datos bibliográficas para los artículos y mediante buscadores generalistas para la información de los productos y aplicaciones, así como para las noticias de actualidad aparecidas en la prensa local e internacional.
Resultados: el resultado es una taxonomía de usos, aplicaciones y herramientas de lifelogging y quantified self. Se concluye que un factor determinante en su evolución será la capacidad de generar información de calidad a partir de los datos generados por el usuario. En ambos casos se ve necesario establecer estándares y protocolos que permitan una estructuración, gestión y análisis de los datos con el fin de optimizar los potenciales impactos positivos que puede generar el fenómeno del quantified self a la sociedad. — Objectives: This paper uses data generated by users to reflect on the emergent paradigm of lifelogging or quantified self as a lifestyle. It analyses the social and technological aspects of this phenomenon, focusing on data management, and it describes how the principles of big data enable us to understand the opportunities and complexities that quantified self is responsible for.
Methodology: The paper revises the bibliography published on lifelogging and quantified self from its beginnings to the present. The bibliographic search was completed using bibliographic databases for the articles and general search engines for information on products and applications and for news articles in the local and international press.
Results: The result is a taxonomy of uses, applications and tools for lifelogging and quantified self. The researchers conclude that the ability to generate quality information from user-generated data will be key in the development of this paradigm. It will also be necessary to establish standards and protocols to organize, manage and analyse the data so that the potentially positive impact of quantified self on society can be optimized.