
[Versió catalana | Versión castellana]
Andreu Sulé
Lecturer at the Faculty of Library and Information Science
University of Barcelona
Abstract
In this article, we describe the main characteristics of Schema.org, the vocabulary developed in 2011 by Google, Bing, Yahoo! and Yandex to mark up webpage content and thus make data recognizable and understandable to search. We present the main application of Schema.org today, which is to enhance information about a webpage that is displayed in a search engine’s results. We then look at the main principles of the structure of Schema.org (classes, properties, values, etc.) and the coding formats that it accepts. In addition, we explain how to mark up webpage content with Schema.org, and describe who uses, maintains and develops this vocabulary today. Finally, we briefly assess the advantages of using Schema.org, as well as the potential applications of this vocabulary in the improvement of searches and search engine results (greater accuracy, more functionalities, etc.); the development of web semantics; and the area of website ranking (search engine optimization, SEO).
Resum
Es descriuen les principals característiques de l’Schema.org, el vocabulari creat el 2011 per Google, Bing, Yahoo! i Yandex per marcar el contingut de les pàgines web i, d’aquesta manera, fer recognoscibles i comprensibles les seves dades als cercadors. Se n’exposa la principal aplicació avui dia, l’enriquiment de la informació que mostren els cercadors de cada pàgina web en els seus resultats, així com els fonaments de la seva estructura (entitats, propietats, valors, etc.) i dels formats de codificació que accepta. També s’explica com marcar el contingut d’una pàgina web amb l’Schema.org, qui fa servir avui dia aquest vocabulari, i qui el manté i desenvolupa. Finalment, es valora breument la conveniència o no d’utilitzar l’Schema.org, així com les possibles aplicacions d’aquest vocabulari en la millora de les cerques i dels resultats dels cercadors (més precisió, més funcionalitats, etc.), en el desenvolupament del web semàntic i, fins i tot, en el posicionament de les pàgines web en els cercadors (SEO).
Resumen
Se describen las principales características de Schema.org, el vocabulario creado en 2011 por Google, Bing, Yahoo! y Yandex para marcar el contenido de las páginas web y, de este modo, hacer reconocibles y comprensibles sus datos a los buscadores. Se expone su principal aplicación a día de hoy, el enriquecimiento de la información que muestran los buscadores de cada página web en sus resultados, así como los fundamentos de su estructura (entidades, propiedades, valores, etc.) y de los formatos de codificación que acepta. También se explica cómo marcar el contenido de una página web con Schema.org, quién usa actualmente este vocabulario, y quién lo mantiene y desarrolla. Por último, se valora brevemente la conveniencia o no de utilizar Schema.org, así como las posibles aplicaciones de este vocabulario para mejorar las búsquedas y los resultados de los buscadores (más precisión, más funcionalidades, etc.), en el desarrollo de la web semántica e, incluso, en el posicionamiento de las páginas web en los buscadores (SEO).
1 What is Schema.org and what is it for?
Who wouldn’t want to increase the number of visitors to their webpages? Who wouldn’t want users of Google, Yahoo!, Bing or Yandex1 to choose their website over other search results? Who wouldn’t like to be able to show more data in Google search results, to give users more information about the content of their webpages? Well, all of this is what, directly or indirectly, Google, Yahoo!, Bing and Yandex say will happen if HTLM web content is marked up with Schema.org: a vocabulary created and maintained by these major search engines since 2011.
As an example, if we search for “apple pie recipe” on Google.com, we will probably obtain results similar to these:
Figure 1. Rich snippet in Google search results for “apple pie recipe”
As you can see highlighted in red, some search results are more attractive because they have been enriched with data (rich snippets) that Google has extracted from the HTML content of webpages. How can Google identify these data within the HTML code? They will have been marked up by the website administrator (or somebody else with responsibility for this task) using the Schema.org vocabulary that Google recognizes and understands.
For a basic idea of this system (later on we will go into much greater detail), a comparison of the two boxes below illustrates what it means to mark up web content using Schema.org, and how easy it is for Google to then identify which data should be used to enrich information in the search results. The first box shows some of the webpage2 content from the first result of the above search, without the Schema.org markup:

Figure 2. Webpage content without the Schema.org markup
The second box shows the same content with the Schema.org markup:

Figure 3. Webpage content with the Schema.org markup
In the second case, different parts of the content are identified semantically, using specific HTML attributes (itemscope, itemprop, etc.) and values for these attributes (ratingValue, reviewCount, cookTime, etc.) that enable Google “to understand” the meaning of the data and consequently select which information it wants to use to enrich the webpage listing in the search results. It is this complex, and this simple.
2 Schema.org in a little more detail
The proposal of Google, Yahoo!, Bing and Yandex is based on a collection of vocabularies (or metadata schemas) that define properties that can be used to mark up webpage content. For example, Movie includes properties for describing films, such as actor, director, duration, etc.
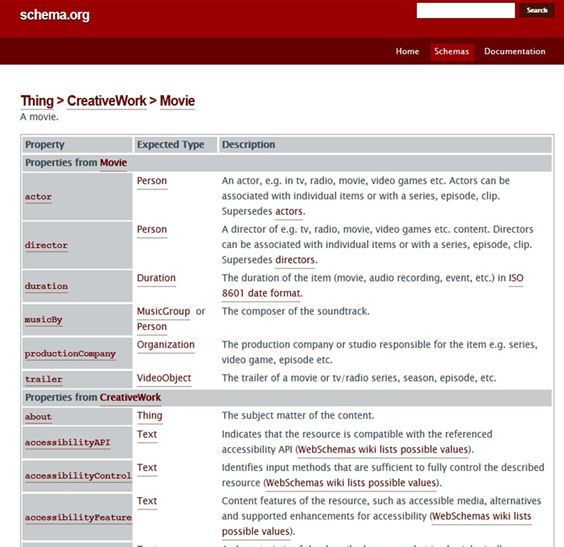
Figure 4. Properties from Movie
In 2014, there were four-hundred and twenty-eight classes (broadly speaking, physical and non-physical types of things) and five-hundred and eighty-one properties (Tort; Olivé, 2014). These figures continue to rise every year, and give an idea of the level of detail with which web content can be marked-up using Schema.org.
To make it easier to identify properties, Schema.org groups them depending on the class that they are designed to represent, and organizes them hierarchically:
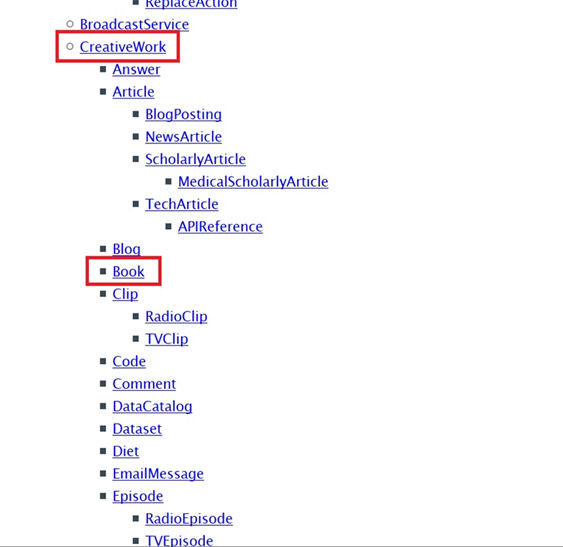
Figure 5. Hierarchical organization of classes in Schema.org
So, for example, the vocabulary for books, Book, is a subclass of the vocabulary CreativeWork and this, in turn, is a subclass of Thing, which is the most generic class within Schema.org.
This hierarchical structure means that a class inherits the properties of the classes that are above it in the hierarchy. If we apply this to the above example, we can use properties from the class of Book, CreativeWork or Thing to mark up information about a book on a webpage.
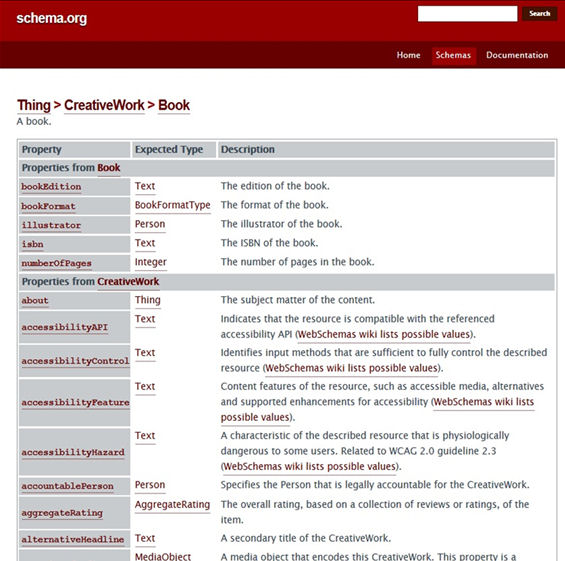
Figure 6. Properties of Book
In general, Schema.org is not highly specific about criteria for applying properties or the nature of their values. In fact, it only establishes the type of data that each property can contain (Expected Type) and its scope (Description).
The type of data a property can contain may be a value, an enumeration or a class. The types of values are defined in DataType (Boolean, Date, DateTime, Number, Text, Time, etc.). The enumerations (Enumerations) are closed lists of possible values that in some cases contain subcategories (for example, Anesthesia is a subcategory of MedicalSpecialty). More surprising is the fact that the content of a property can be a class. For example, the Festival vocabulary includes the property Organizer that can be used to mark up information about the person or company organizing the festival. Schema.org indicates that the type of data in this property could be the class Organization or the class Person.

Figure 7. Property of Organizer in the class Festival
So, to mark up information on the organizer of a festival, we can use all the properties of the class Organization or the class Person. For example, information about the company Mas i Mas (name, telephone number, fax and email) that organized the Twelfth San Miguel Mas i Mas Festival August’14 could be marked up as follows:

Figure 8. Markup of information about the Twelfth San Miguel Mas i Mas Festival August’14, organized by the company Mas i Mas
The name, telephone number, fax and email of the company Mas i Mas are grouped together in the code corresponding to the class Organization (<div itemprop=”organizer” itemscope itemtype=”http://schema.org/Organization”>).
As mentioned above, the second piece of information that Schema.org provides for each property is its scope (Description). Here, in addition to the definition of the property, we can occasionally find application criteria, such as morphological syntax (for example, the ISO 8601 standard for the endDate and the IETF BCP 47 standard for the inLanguage, both of which are properties of the class TVSeries) or lists of possible values (for example, WebSchemas/Accessibility for the property accessibilityControl of the class Article).
3 What formats are used for Schema.org markup?
As shown on its website, Schema.org can be used in combination with Microdata, RDFa and JSON-LD formats. Each of these formats has strengths and weaknesses, depending on the application scenario.
Microdata (the main format promoted by Schema.org, and the one used in the examples in this article) and RDFa are both specifications of HTML attributes (for exemple, <span itemprop in Microdata or <span property in RDFa). Microdata is less complex than RDFa. However, due to its complexity, RDFa can offer more functionalities; for example, different vocabularies can be combined in the same document. The formats have been created and maintained by different institutions: the Web Hypertext Application Technology Working Group (which also developed HTML5) in the case of Microdata, and W3C in the case of RDFa. In principle, this means that RDFa has a greater degree of standardization, although some studies seem to suggest that the use of Microdata is increasing (Bizer [et al.] 2013; Meusel, Petrovski, Bizer, 2014).
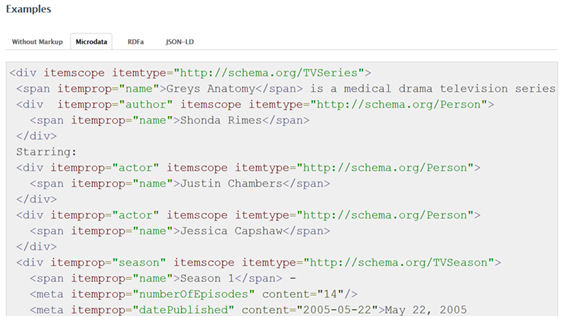
Figure 9. Example of markup of the class TVSeries using Microdata
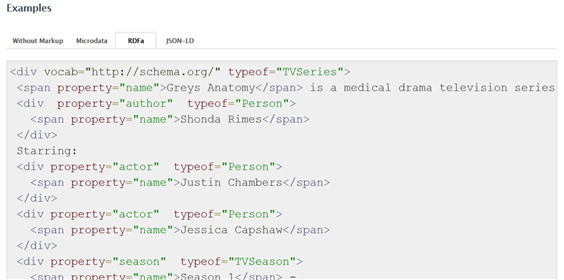
Figure 10. Example of markup of the class TVSeries using RDFa
In contrast, JSON-LD does not mark up web content as part of the HTML content, but using the JavaScript syntax. This use of the most popular web programming language facilitates the reuse of marked-up data in many other web applications (for example, exporting event data to a calendar).
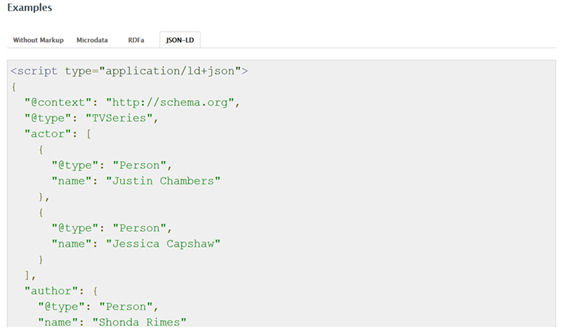
Figure 11. Example of markup of the class TVSeries using JSON-LD
4 Are there any other tools like Schema.org?
Before Schema.org emerged, other vocabularies had been designed to give a semantic value to web content, and some of these are still used today. One of them is Data-Vocabulary.org that, in many respects, is considered the predecessor of Schema.org.
Like Schema.org, Data-Vocabulary.org is comprised of classes (item type) and each class is made up of properties. Examples of classes are Person, Product,Organization, Review, etc. At its peak, this vocabulary was the most widely used to mark up web content (Bradley, 2013). However, it has now been replaced by Schema.org. In fact, the Data-Vocabulary.org webpage only contains references and links to Schema.org.
Another vocabulary for marking up web content is Microformats. This is a community development project that began in 2005 and is promoted under the banner of its simplicity, especially compared to other more complex alternatives such as XML. One of the main characteristics of this simplicity is the use of HTML elements (particularly the class attribute) to mark up properties. Microformats is a set of vocabularies, each of which contains the properties required to mark up a specific kind of content. For example, h-card is used for people and organizations; h-event for events; h-review for reviews, etc. However, there are fewer vocabularies in microformats than in Schema.org.
In a study carried out in 2012 (Bizer [et al.] 2013; Meusel, Petrovski, Bizer, 2014), Microformats were the most widely used markup vocabulary, ahead of Data-Vocabulary.org and Schema.org. However, this situation could be affected by Google’s explicit support for the use of Schema.org.
5 In practice, how is web content marked up using Schema.org?
It is true that Schema.org is a relatively simple vocabulary conceptually, and it is also fairly easy to mark up content by hand, directly in the source code. However, manually entering the information contained in a website that has dozens or hundreds of pages could be very costly in worker hours. Therefore, in practice, content is usually marked up automatically by applying the specific templates of the content management systems that were used to design the webpages, or by converting data to Schema.org in the case of dynamic webpages created when a user makes a database request. However, the entire content of a webpage is not generally marked up: the web manager will only select relevant information to appear in the rich snippets in search results (Schema.org, unlike Microformats, does not specify that any property is obligatory in any class).
Examples of content management systems include Drupal, WordPress and Joomla!. All of these systems have developed specific templates for annotating page content using Schema.org.
An example of dynamic coding is WorldCat. Since 2012, OCLC has been adding descriptive data annotated with Schema.org to bibliographic record webpages (Murphy, 2012). The following example shows the bibliographic record for Harry Potter and the deathly hallows marked up with Schema.org (in the drop-down tab “Linked Data” at the bottom of the page):
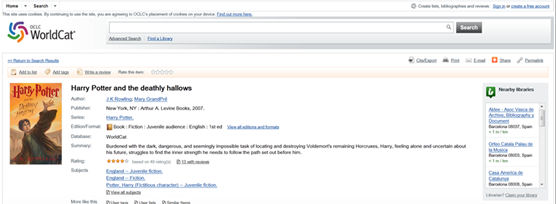
Figure 12. Bibliographic record of Harry Potter and the deathly hallows on WorldCat, marked up with Schema.org
In addition to these tools, online help is available in the form of simple templates for Schema.org markup. Examples are the Structured data markup helper, Schema Creator and Schema.org Generator | Microdata Generator. These tools are very easy to handle and a lot of guidance is provided, but they are only useful if you need to mark up the content of some webpages.
Finally, the Google webpage Promote Your Content with Structured Data Markup contains a lot of information about Schema.org, as well as markup recommendations and the characteristics of the main classes.
6 What is Schema.org used for today?
It is true that the number of webpages whose content is marked up with Schema.org is negligible in comparison with the total number of pages on the Internet (Homoceanu [et al.] 2013; Schema.org…, 2014). However, it is equally true that major companies and organizations, leaders in their sectors, are marking up their websites using Schema.org. Below are some examples:
- Library catalogues: WorldCat
- E-commerce: eBay, Sears, Mango, Macy’s
- Music: Last.fm, Myspace
- Film and video: IMDb, FilmAffinity, YouTube
- Job search portals: Indeed, SimplyHired, Monster.com
- Press: The Wall Street Journal, The New York Times, The Guardian, BBC, Fox News, ABC News, CBSSports.com, Los Angeles Times
- Restaurants: Allmenus.com, Urbanspoon
- Ticket sales: Ticketmaster, Eventful
- Social networks: Meetup.com, Google+
So, regardless of whether many or few pages are currently marked up, the prestige of the entities that are currently using Schema.org indicates that its level of implementation will continue to increase in volume and importance in the near future.
7 Who maintains and develops Schema.org?
The developers of Schema.org (Microsoft, Yahoo!, Google and Yandex) have been clear from the outset that the classes included in the vocabulary are selected according to business logic. In other words, we cannot mark up everything at present. Nevertheless, Schema.org is a ‘living’ vocabulary, in constant expansion, and this development is often carried out in close collaboration with prestigious organizations and institutions in each sector, such as:
- GoodRelations for the development and maintenance of all vocabularies related with e-commerce.
- BBC and International Press Telecommunications Council (through their SportsML standard) to improving the markup of information about athletes, organizations and sports events.
- Schema Bib Extend Community Group to improve the markup of bibliographic information.
- Learning Resource Metadata Initiative for the description of educational resources.
- United States Office of Science and Technology Policy for the development of the class JobPosting.
To get an idea of the degree of involvement of major corporations, the Panel: Schema.org at the Semantic Technology & Business Conference of 2012 included representatives of W3C, the New York Times Company, the Disney Interactive Media Group and Microsoft.
In addition to these institutional collaborations, Schema.org invites anybody who wants to give their opinion, ask a question or collaborate in the development and maintenance of the vocabularies to do so through the Schema.org Community Group portal or the public-vocabs@w3.org discussion list (http://lists.w3.org/Archives/Public/public-vocabs/).3 In addition, Schema.org has two public wikis as part of the W3C consortium: WebSchemas and GitHub schemaorg, where the state of proposals to expand and improve the vocabularies can be consulted.
Finally, in the field of Linked Data, those responsible for Schema.org are working to adapt the vocabularies to the semantic web. One example of this is the adoption of RDFa Lite as a markup format (Brickley, 2011). RDFa Lite is a simplified version of RDFa, a coding syntax for web content developed by W3C. What is Schema.RDFS.org? is a website in the same field of facilitating the interoperability of data. The site contains information on Linked Data, as well as tools (programming languages, editors, etc.) and mappings of other web vocabularies to Schema.org (DBpedia, Dublin Core, FOAF, GoodRelations, SIOC, Bibliographic Ontology and WordNet).
8 What are the future opportunities of Schema.org?
The official webpage of Schema.org states that the main benefit of the system is the improved display of search results. However, there are some indications that in the near future (or even in the present) web content markup will have other applications.
Right at the outset of Schema.org, Wailes (2011) and CodexM (2011) noted that if search engines can understand information on webpages, the user’s search experience can be enhanced by: improving the accuracy of results, as the meaning of data can be identified; incorporating filters to restrict searches (see the demonstration for recipes at Slice and dice your recipe search results); and establishing new criteria for ranking results (for example, by user voting); among other factors.
A second opportunity is the association of Schema.org with the semantic web to help machines (not just search engines) to understand web content. The acceptance of RDFa as a coding syntax, the joint work with the W3C, and the efforts to develop and use Schema.org in the paradigm of Linked Data are all clear evidence of this.
Finally, although Google denies any relation between Schema.org and webpage ranking, many SEO companies, publications and portals (Higher Visibility, Moz, iProspect, Search Engine Journal, etc.) are devoting considerable resources to finding out and disseminating the benefits of the new vocabulary in terms of search engine positioning.
9 Conclusions
In light of the above, it seems clear that Schema.org is a vocabulary that professionals in the sector should consider carefully. Some may believe that the improved display of results is too small an advantage to justify the added cost of marking up web content. However, Schema.org should be evaluated not only for what it represents today, but also for what it could become in the future. Perhaps this future will be influenced more by criteria of support, and specifically by Google’s role in the development, use and application of Schema.org, than by strictly technical criteria. Whether or not you like it, today everything that is associated with Google should be of interest to information and documentation professionals.
References
Bizer, Christian [et al.] (2013). “Deployment of RDFa, microdata, and microformats on the web: a quantitative analysis”. En: The Semantic Web – ISWC 2013: 12th International Semantic Web Conference, Sydney, NSW, Australia, October 21–25, 2013, Proceedings, Part II. Berlin: Springer, p. 17–32. <http://hannes.muehleisen.org/Bizer-etal-DeploymentRDFaMicrodataMicroformats-ISWC-InUse-2013.pdf>. [Accessed: 05/03/2015].
Bradley, Aaron (2013). Basic vocabulary for schema.org and structured data. SEOSkeptic. <http://www.seoskeptic.com/basic-vocabulary-for-schema-org-and-structured-data/>. [Accessed: 05/03/2015].
Brickley, Dan (2011). Using RDFa 1.1 Lite with Schema.org. Schema blog. <http://blog.schema.org/2011/11/using-rdfa-11-lite-with-schemaorg.html>. [Accessed: 05/03/2015].
CodexM (2011). Schema.org and Microdata Markups for SEO. Seochat. <http://www.seochat.com/c/a/search-engine-optimization-help/schema-org-and-microdata-markups-for-seo/>. [Accessed: 05/03/2015].
García-Marco, Francisco-Javier (2012). “Schema.org: la catalogación revisitada”. Anuario ThinkEPI, v. 7, p. 169–172 <http://www.thinkepi.net/schema-org-catalogacion-revisitada>. [Accessed: 05/03/2015].
Homoceanu, Silviu [et al.] (2013). “Any suggestions? Active Schema Support for Structuring Web Information”. En: International Conference on Database Systems for Advanced Applications. Database systems for advanced applications: 19th International Conference, DASFAA 2014: proceedings, part II. Berlin: Springer, p. 251–265. <http://www.ifis.cs.tu-bs.de/sites/default/files/DASFAA14_conference_105.pdf>. [Accessed: 05/03/2015].
Meusel, Robert; Petrovski, Petar; Bizer, Christian (2014). “The WebDataCommons Microdata, RDFa and microformat data set series”. En: The Semantic Web – ISWC 2014: 13th International Semantic Web Conference, Riva del Garda, Italy, October 19–23, 2014. Proceedings, Part I. Berlin: Springer, p. 277–292.
Murphy, Bob (2012). OCLC adds Linked Data to WorldCat.org. OCLC.org <http://www.oclc.org/news/releases/2012/201238.en.html>. [Accessed: 05/03/2015].
Pastor Sánchez, Juan Antonio (2012). “Prospectiva de la web semántica: divergencia tecnológica y creación de mercados Linked Data”. Anuario ThinkEPI, v. 6, p. 269–275. <http://www.thinkepi.net/prospectiva-de-la-web-semantica-divergencia-tecnologica-y-creacion-de-mercados-linked-data>. [Accessed: 05/03/2015].
Ronallo, Jason (2012). “HTML5 Microdata and Schema.org”. Code4Lib Journal, Issue 16. <http://journal.code4lib.org/articles/6400>. [Accessed: 05/03/2015].
Schema.org in Google search results. Searchmetrics, 2014. <http://pages.searchmetrics.com/rs/searchmetricsgmbh/images/Searchmetrics_Schemaorg_Study_2014.pdf>. [Accessed: 05/03/2015].
Tort, Albert; Olivé, Antoni (2014). “A computer-guided approach to website Schema.org design”. En: Conceptual Modeling: 33rd International Conference, ER 2014, Atlanta, GA, USA, October 27-29, 2014. Proceedings. Springer International Publishing, p. 28–42. Doi 10.1007/978-3-319-12206-9_3.
Use structured data for rich search results. Google, 2015. <https://support.google.com/webmasters/topic/4598337?hl=en&ref_topic=3309300>. [Accessed: 05/03/2015].
Wailes, Pete (2011). Semantic data, Schema.org & the future of search. Strategy Digital. <http://www.strategydigital.co.uk/blog/semantic-data-schema-org-the-future-of-search/>. [Accessed: 05/03/2015].
Notes
1 Yandex is the largest search engine in Russia.
2 Consulted on 23/02/2015.
3 At the time of writing this article, the discussion on the list was about how to provide approximate data on resources (for example, the approximate year of publication of a manuscript).
 Creative Commons licence (Attribution-Non-Commercial-No Derivative works). They may be consulted and distributed freely provided that the author and publisher are quoted (in accordance with the “Recommended citation” section in each of the articles). However, no derivative works (translation, change of format, etc.) may be made without the publisher’s permission. Therefore, it meets the definition of open access form the Budapest Open Access Initiative declaration. The journal allows the author(s) to hold the copyright without restrictions and to retain publishing rights without restrictions.
Creative Commons licence (Attribution-Non-Commercial-No Derivative works). They may be consulted and distributed freely provided that the author and publisher are quoted (in accordance with the “Recommended citation” section in each of the articles). However, no derivative works (translation, change of format, etc.) may be made without the publisher’s permission. Therefore, it meets the definition of open access form the Budapest Open Access Initiative declaration. The journal allows the author(s) to hold the copyright without restrictions and to retain publishing rights without restrictions.