

[Versió catalana] [English version]
Alex Vitela Caraveo
Estratega digital IBM
IBM, Marketing Services Center, Guadalajara (Mèxic)
Cristóbal Urbano
Profesor del Departamento de Biblioteconomía, Documentación y Comunicación Audiovisual
Universitat de Barcelona
Resumen
Panorámica de recursos y estrategias de analítica web útiles en la configuración de soluciones de captación de estadísticas de uso y de evaluación de audiencias en revistas académicas de acceso abierto. Se contempla un conjunto de métricas complementarias a las citas para ayudar a los editores y gestores de revistas a proveer evidencias del desempeño de la revista en conjunto y de cada artículo en particular en el entorno web. Mediante las mediciones y los indicadores seleccionados se busca generar valor añadido a la gestión editorial para asegurar su sostenibilidad. La propuesta se configura en torno a tres ámbitos: recuento de consultas y descargas, optimización del sitio web o de las campañas de atracción de visitas, y elaboración de un cuadro de mando para la evaluación estratégica. Se concluye que, a partir de la elaboración de planes de medición del desempeño web, basados en los recursos y propuestas analizadas, las revistas pueden estar en mejores condiciones de abordar con evidencias la mejora de la capacidad de atracción de autores y lectores, así como facilitar la rendición de cuentas a los actores implicados en el proceso editorial de la publicación en acceso abierto.
Resum
Panoràmica de recursos i estratègies d'analítica web útils en la configuració de solucions de captació d'estadístiques d'ús i d'avaluació d'audiències en revistes acadèmiques d'accés obert. S'analitzen un conjunt de mètriques complementàries a les citacions per ajudar els editors i gestors de revistes a proveir mostres de l'acompliment de la revista en conjunt i de cada article en particular en l'entorn web. Mitjançant els mesuraments i els indicadors seleccionats es busca generar valor afegit a la gestió editorial per assegurar-ne la sostenibilitat. La proposta es configura al voltant de tres àmbits: recompte de consultes i descàrregues, optimització del lloc web o de les campanyes d'atracció de visites, i elaboració d'un quadre de comandament per a l'avaluació estratègica. Es conclou que, a partir de l'elaboració de plans de mesurament de l'acompliment web, basats en els recursos i propostes analitzades, les revistes poden estar en millors condicions d'abordar amb mostres la millora de la capacitat d'atracció d'autors i lectors, així com facilitar la rendició de comptes als actors implicats en el procés editorial de la publicació en accés obert.
Abstract
An overview is presented of resources and web analytics strategies useful in setting solutions for capturing usage statistics and assessing audiences for open access academic journals. A set of complementary metrics to citations is contemplated to help journal editors and managers to provide evidence of the performance of the journal as a whole, and of each article in particular, in the web environment. The measurements and indicators selected seek to generate added value for editorial management in order to ensure its sustainability. The proposal is based on three areas: counts of visits and downloads, optimization of the website alongside with campaigns to attract visitors, and preparation of a dashboard for strategic evaluation. It is concluded that, from the creation of web performance measurement plans based on the resources and proposals analysed, journals may be in a better position to plan the data-driven web optimization in order to attract authors and readers and to offer the accountability that the actors involved in the editorial process need to assess their open access business model.
1 Introducción
La puesta a disposición en acceso abierto de los resultados de investigación y de las publicaciones académicas constituye, en la actualidad, una tendencia que no parece tener vuelta atrás, por lo que en un plazo relativamente breve se piensa que será el modelo de publicación científica dominante (Lewis, 2012), especialmente desde el punto de vista del volumen de uso de la bibliografía científica (Piwowar; Priem; Orr, 2019). Supone una mejora notable del funcionamiento de la comunicación científica, pues incrementa el uso y el impacto de los contenidos (Lawrence, 2001; Eysenbach, 2006; Lewis, 2018) y mejora la transparencia de la investigación por el libre acceso a la información para todos los actores implicados (Abadal, 2012; Piwowar [et al.], 2018). Ahora bien, dichas ventajas vienen acompañadas de la incertidumbre en cuanto a la sostenibilidad del enorme caudal de revistas que publican bajo dicho modelo y que se enfrentan a un entorno competitivo y cambiante del ecosistema de la comunicación científica (Green, 2017a; 2017b). Esto es especialmente relevante para aquellos títulos que no cobran a los autores cuota de procesamiento por publicar (APC, por el término inglés article processing charge). Se trata de una modalidad de acceso abierto que algunos autores denominan "diamond OA" (Harrington, 2017), pese a que otros reservan dicho término para aquellas revistas que, además, apuestan por la consideración de las revistas como un bien público al servicio de la comunicación científica abierta, mediante licencias de uso que limitan el uso comercial y la reutilización con finalidades lucrativas (Fuchs; Sandoval, 2013). En definitiva, se trata de revistas que se sostienen con el financiamiento de sus instituciones madre —con patrocinios externos en ocasiones— que subvencionan o asumen en su totalidad costes de personal o de recursos tecnológicos, y en muchas ocasiones también gracias a la aportación del trabajo no remunerado que asumen agentes académicos de todo tipo.
En esa batalla por la sostenibilidad, las revistas de acceso abierto tratan de diversificar sus fuentes de financiación y exploran nuevas fórmulas, pero por encima de todo necesitan retener el financiamiento institucional para asegurar su sostenibilidad (Villarroya [et al.], 2012; Holdcombe; Wilson, 2017; Pooley, 2017). En este sentido, el análisis del retorno de la inversión se vuelve más complejo, más intangible, al no generarse ingresos económicos por la cuota de procesamiento por publicar (APC) o por suscripciones que permitan analizar en parte ese retorno. Estamos hablando de un retorno social de la inversión en cuanto que servicio público de apoyo a la comunicación científica, así como de un retorno en forma de reputación para la entidad editora. Se trata de contar con evidencias que permitan una evaluación del desempeño de la revista en el marco de los valores sociales y los objetivos institucionales que se persiguen con la publicación.
Son muchos los elementos que deben considerarse en la evaluación del desempeño de una publicación, pero, entre otros, cabría destacar la capacidad de atracción de autores y lectores como algo esencial. Así, la captación de nuevos públicos, la fidelización de esos usuarios al sitio web de la revista y la intensidad con la que interaccionan con la publicación, si son objeto de métricas normalizadas, pueden devenir indicadores útiles para la toma de decisiones sobre si el retorno social y el reputacional son adecuados respecto de lo esperado por la institución o el grupo promotor de cada revista.
Para lograrlo, los editores deberán poner atención constante en el rendimiento del sitio web de la revista, junto con otros indicadores externos de tipo bibliométrico o altmétrico. En último término, una revista de acceso abierto en Internet es un sitio web en sí misma, o parte de un sitio web más amplio en forma de portal, por lo que el análisis de su posicionamiento en buscadores, la justificación del retorno de las campañas de atracción de usuarios y el seguimiento de las visitas que recibe son requisitos fundamentales para la optimización del sitio web, como lo serían para la mayoría de los sitios web de cualquier otra naturaleza.
Esta necesidad de contar con evidencias para la gestión optimizada del web, para mejorar la experiencia de usuario, para calcular el retorno de la inversión (aunque se trate de un retorno social o reputacional, no económico) o para transparentar ante autores y lectores métricas de consulta y descargas de artículos es lo que justifica el presente trabajo. Por tanto, el objetivo perseguido con el estudio es identificar qué valor añadido puede aportar a la gestión editorial el análisis del uso del sitio web de una revista con programas de analítica web como Google Analytics, y clarificar en qué medida ese enfoque técnico es complementario de los informes estadísticos que ofrecen los sistemas de gestión de contenidos (SGC) con los que mayoritariamente se publican las revistas académicas, o los que se pueden obtener acudiendo al análisis de los logs (registros) de los servidores que alojan las revistas.
Para realizar el trabajo hemos usado como referente Google Analytics, dado su uso mayoritario en todo tipo de sitios web, así como entre las revistas de acceso abierto, si bien la propuesta esbozada se contempla como útil con cualquier otra herramienta de analítica web del lado del cliente (client-side) que utilice códigos de seguimiento añadidos en el HTML, como por ejemplo Matomo, Siteimprove u otras. También hemos tenido en cuenta que el gran desarrollo del acceso abierto en el ámbito de las revistas científicas no se entendería sin la gran extensión que ha alcanzado la utilización de un software libre como el Open Journal Systems (OJS) (Edgar; Willinsky, 2010), que ha reducido también el tiempo y la energía que dedicaban los editores a tareas de administración y edición. Por ello, a lo largo de este artículo, cuando se exploran las razones para implementar una estrategia de analítica web, se ha tenido en mente el caso de revistas gestionadas con OJS,1 si bien buena parte de lo planteado puede ser aplicado con independencia del gestor de contenidos utilizado para gestionar y publicar la revista.
2 Los dos ejes de la evaluación del uso de revistas digitales
Cualquier revista académica que apueste por un funcionamiento profesional ha de hacer frente a dos retos en relación con el estudio de sus usuarios y del uso de sus contenidos: por una parte, el recuento estadístico normalizado del número de consultas y descargas de cada uno de los artículos que publica; por otra, la evaluación y optimización de su sitio web, así como de las campañas que realiza para atraer usuarios a este. Son dos ejes complementarios, pero que no se deben confundir: el hecho de ofrecer una estadística normalizada del uso de los artículos, aun siendo importante, no abarca todo lo que se pretende desde la analítica web, ya que, además de integrar ese primer eje estadístico básico, debería responder a lo que Avinash Kaushik denomina "analítica Web 2.0" y define como "el análisis de datos cualitativos y cuantitativos de su sitio web y de la competencia, para impulsar una mejora continua de la experiencia online que tienen tanto los clientes habituales como los potenciales y que se traduce en unos resultados esperados (online y offline)" (Kaushik, 2010, p. 24). Tanto si nos situamos en un eje como en el otro, resulta válido el principio de que lo que no se mide no se puede mejorar. Ahora bien, hemos de tener muy presente la diferencia entre medición y análisis: cuando se mide y no se analiza, tampoco se puede mejorar, ya que analizar implica, además, interpretar los datos en un contexto y de acuerdo con la misión, los objetivos y la razón de ser de la organización.
Si nos situamos en el primer eje, hemos de contemplar dos líneas de desarrollo que impulsan el debate metodológico sobre su elaboración. Por una parte, la convergencia entre editores y bibliotecas para acordar la medición de los usos de las colecciones digitales mediante el desarrollo del Project COUNTER.2 Por otra, las denominadas altmetrics, con las que se quiere disponer de nuevas métricas para la evaluación de la investigación, complementarias a las tradicionales, en las que hasta el presente ha tenido un peso determinante el factor de impacto.
El análisis del uso de los artículos de revistas, o de cualquier otro tipo de output de investigación, principalmente manifestado mediante el recuento de las descargas de ficheros (PDF, EPUB o en otros formatos) o de la visualización de páginas HTML, se contempla como una fuente de datos que debe tenerse en consideración dentro del conjunto de las denominadas altmetrics. Estas "métricas alternativas" explotan datos de uso, difusión o notoriedad de las publicaciones científicas, en cuanto que complemento y alternativa a los indicadores bibliométricos clásicos basados principalmente en el análisis de citas (Priem [et al.], 2010; Tananbaum, 2013; Borrego, 2014; Glänzel; Gorraiz, 2015). Así pues, las métricas de uso, ya sea en el propio sitio web de la revista, ya sea en plataformas externas agregadoras de contenido o de acceso, proveen evidencias del desempeño de los artículos. Se trata de una información que cada vez es más demandada por los autores, pero que también necesitan editores y financiadores de la investigación.
Con algunas excepciones, la mayoría de los editores de revistas de acceso abierto atiende a este primer eje que hemos comentado y focaliza su atención en métricas básicas como el número de visitas, las páginas vistas o los artículos descargados, tradicionalmente consideradas en la justificación del proyecto editorial y que, además, últimamente se han visto reforzadas por el discurso de las altmetrics.
Por el contrario, el segundo eje al que nos referimos se apoya en una visión más amplia, orientada a mejorar el sitio web, así como el posicionamiento y la promoción de sus contenidos, captar usuarios y fidelizarlos o aumentar el número y la calidad de los manuscritos que envían los autores para ser tomados en consideración. Se ha de tener presente que, como cualquier otro sitio web, una revista debe trazar "objetivos de conversión" (aquello que se desea que hagan los usuarios dentro del sitio web), así como metas en cuanto a determinados indicadores clave, las cuales se pueden alcanzar mejor si las características del sitio web se ajustan al comportamiento y las necesidades de los usuarios.
Dentro de este segundo eje que contemplamos, la analítica web ha de ser un instrumento más —junto con todo tipo de evaluaciones cualitativas, test de usuarios, encuestas de opinión, etc.— para saber si la revista cumple con su razón de ser, si progresa y si su existencia se justifica en unos datos de uso, de repercusión o de valoración por parte de la comunidad académica a la que se dirige. Además, cualquier sitio web debe tener en el centro de su mejora continua el análisis de la experiencia del usuario y de sus necesidades, y una revista digital no es una excepción.
Ahora bien, existen pocos referentes en la bibliografía que se correspondan con este segundo eje que comentamos. Así, una búsqueda bibliográfica sobre analítica web para revistas científicas, en la que hemos usado los términos "analítica web" o "analítica digital" y "revistas científicas" con sus equivalentes en otras lenguas y con otros términos relacionados, retorna un número insignificante de trabajos,3 que en general no plantean de forma central aspectos conceptuales y metodológicos para este tipo de publicaciones. Se trata de trabajos dedicados principalmente a mostrar el perfil de uso y los datos de descargas de una revista concreta (p. ej. Watson, 2007) o a explicar una funcionalidad basada en datos de analítica (p. ej. un sistema de recomendación de artículos en Taraghi [et al.], 2013), pero sin un enfoque holístico de la analítica del sitio web integralmente considerado que pueda servir de pauta metodológica.
Por ello, en la búsqueda de referentes en la bibliografía hemos ampliado el foco a sitios web que comparten características con las publicaciones de acceso abierto, como por ejemplo aquellos webs que ofrecen contenido científico o cultural y que funcionan sin ánimo de lucro (léase bibliotecas, portales de recursos de información, museos, archivos, etc.). Para ese tipo de sitios web se pueden estudiar un buen número de referentes en los que se pueden obtener buenas prácticas y análisis de soluciones técnicas válidas en el marco de las revistas científicas (p. ej. Jansen, 2009; Fagan, 2014; Bragg [et al.], 2015; Prom, 2011). También serían de utilidad los trabajos sobre buenas prácticas y conceptos metodológicos de la analítica para sitios web del ámbito empresarial o de servicios, pero cuyo propósito es transaccional o de apoyo al cliente. Como dice Fagan (2014), se trata de trasladar conceptos del ámbito web comercial a las bibliotecas: "Web analytics have long been used by the commercial sector for studying online user behavior and determining quickly how effective their virtual spaces are at achieving business goals" (p. 25). Así pues, el primer reto para una revista de acceso abierto será determinar cómo traducir el concepto "business goals" a su modelo no lucrativo pero alineado con alguna sociedad científica, universidad o institución de investigación.
La dificultad de evaluar el rendimiento de sitios web que no generan ingresos por venta de publicidad o de pago por acceso a los contenidos no ha de significar ignorancia del rendimiento del sitio web: en último extremo, el incremento de usuarios y de visitas no deja de ser un objetivo destinado a que el coste por visita sea menor cada vez o a fidelizar usuarios como medio para incrementar la reputación de la revista y de la institución editora. En esa experiencia de usuario es tan importante estudiar el público lector en general como el "cliente" autor: podríamos decir que los autores son el principal público objetivo de una revista de acceso abierto en términos de lo que Bourdieu denomina "capital simbólico", entendido como prestigio editorial que condiciona la vida de los académicos (Putnam, 2009; Salö, 2017), ya que de ellos una revista espera recibir manuscritos para su publicación y también citas.
3 Elementos para un proyecto integral de analítica web
A partir de la exploración del potencial y los requisitos de analítica web en la gestión de una revista, formulamos este apartado como una propuesta de elementos que los editores deben considerar. Se trata de una propuesta que pretende analizar la utilidad y viabilidad de la adaptación de ciertas prácticas de analítica web que generalmente están definidas para sitios de comercio electrónico, de generación de contactos (lead generation) o de contenido con objetivos de marketing a un contexto de revistas científicas de acceso abierto que no cobran a los autores por publicar, en las que no es tan fácil definir qué se entiende por "conversión", término con el que en el mundo web se etiquetan todas aquellas interacciones con el contenido que finalizan con una acción que se desea haga un usuario, como una compra o la cumplimentación de un formulario, entre otras.
Por otra parte, es importante destacar que aplicar la analítica web con una visión integral en el caso de las revistas implica prestar también atención a aquellas páginas que no son artículos. El uso que se le da a estas páginas, a pesar de no incluir el contenido científico, es un indicador holístico del desempeño de la revista, algo muy relevante cuando la mayoría de los artículos de revista en acceso abierto se publican bajo licencias que permiten la redistribución del contenido en repositorios institucionales, en portales agregadores de revistas o en redes sociales académicas. Se entiende que los datos de visitas al sitio web del que proceden originariamente los artículos pueden ser claves para valorar el desempeño y el posicionamiento de la publicación, concebida como entidad editorial que va más allá de ser una suma de artículos.
Si bien es común que en el mundo de la publicación de contenidos científicos se dé prioridad al análisis del desempeño de contenidos citables, y no a otras páginas que en muchos casos conducen a ellos, necesitamos un enfoque más amplio si se desea realmente practicar en propiedad lo que hemos definido como analítica web para una revista. Algunos autores califican las páginas sin contenido citable como páginas secundarias —en inglés ancillary pages— cuyo análisis tiene un valor limitado (OBrien [et al.], 2017), pero la tesis de nuestro trabajo es que la circulación de los visitantes por esas páginas y la relación de estas con la descarga de los contenidos citables o con determinadas interacciones, como el envío de manuscritos o la suscripción a las alertas de la revista, son muy importantes para la evaluación y la mejora de la presencia web de la revista. Dado este punto de vista, es importante mencionar entonces que en este artículo nos referiremos a las páginas sin contenido citable como páginas informativas y no como secundarias. A las páginas que sí incluyen los ítems descargables o citables las llamaremos páginas con contenido citable.
Planteamos esta propuesta como un abanico variado y abierto de posibilidades, sobre el que cada revista puede decidir prioridades de medición y análisis en función de sus objetivos de evaluación y mejora. La propuesta partirá en primer lugar de la necesidad de establecer la justificación y la organización del proyecto de analítica, para centrarnos luego en las métricas e indicadores principales implicados en los cuatro bloques de análisis habituales de todo proyecto: el análisis de la audiencia, de la adquisición, del comportamiento y de la conversión.
3.1 Necesidad, contexto y organización del proyecto
Cualquier proyecto de analítica web se debería sustentar en la identificación clara de las partes interesadas en el proyecto (los stakeholders), la definición de los objetivos principales del sitio web y la determinación de los indicadores clave de rendimiento. Pese a que en un primer momento la mejor aproximación a este tipo de proyectos sea gradualista, priorizando aspectos básicos y nucleares del análisis sin perdernos en el bosque de informes y métricas que se pueden obtener, lo normal es evolucionar hacia una planificación más elaborada. En ambos casos hemos de tener una base clara de para qué y para quién realizamos el análisis. Tener esa base ayudará a determinar las herramientas que se utilizarán, los datos que necesitamos obtener y cómo explotarlos, y muy especialmente las personas responsables de esas tareas.
Por otra parte, para poder sacar el máximo provecho a la analítica web, alguien en la revista (o en el portal que la aloja) deberá responsabilizarse del análisis e interpretación de los datos recogidos, para lo cual ha de tener claros algunos aspectos básicos de la infraestructura tecnológica y la arquitectura web que hacen posible el funcionamiento digital de la revista, pero también deberá saber de los objetivos y razón de ser de la publicación. Además, si la persona responsable del análisis lo necesita, deberá contar con el apoyo técnico de alguien responsable de configurar y mantener la solución tecnológica para la captura de los datos que se analizarán. Finalmente, un tema no menor será establecer qué información ofrecer y a quién, por ello la forma de presentación de los datos y de su interpretación será clave: esto es, quién usará la "inteligencia" que genera el proyecto de analítica y qué utilidad reportará en la toma de decisiones.
En síntesis, más allá de curiosear los atractivos informes estadísticos y la visualización de datos que ofrece un programa como Google Analytics, o sus equivalentes, es necesario contar con un plan para determinar el alcance, la utilidad real que esperamos obtener y cómo lo organizaremos, aspecto en el que destacará determinar el "quién" (hará ese trabajo), "para quién" (los destinatarios de la "inteligencia" adquirida) y el "cuándo" (con qué regularidad o en qué situaciones no regulares por hechos o circunstancias excepcionales). En la estrategia de analítica web será de suma importancia centrarse en las medidas que deberán adoptarse según los informes obtenidos y no perderse en un mar de datos. Una vez tomadas esas acciones será necesario monitorear los resultados para saber si se toman nuevas decisiones.
3.2 Elección de las herramientas de analítica web
Existen diversas opciones técnicas para obtener datos sobre las visitas y la interacción de los usuarios con el contenido, pero se pueden resumir en dos tipos de herramientas: del lado del servidor (server-side) y del lado del cliente. Cada una de ellas presenta fortalezas y debilidades, de tal forma que, como veremos, la solución más completa pasaría necesariamente por la complementariedad entre ellas. Por otra parte, la disponibilidad y la viabilidad de cada solución dependerán de la capacidad técnica con la que cuente la revista o del catálogo de servicios que ofrezca el portal en el que se aloje, si es ese el caso. Veamos los fundamentos técnicos de cada una de ellas.
Cada interacción que el usuario realiza con el sitio web se puede registrar como una petición de archivo (hit) en el fichero de logs del servidor en el que se aloja la revista. En estas peticiones de archivo se almacena información como la IP del usuario, la hora, el nombre del fichero solicitado y la URL de referencia desde la que se solicita el fichero, entre otros datos. Los programas de analítica del lado del servidor son aquellos que explotan los logs de servidor, pero su utilización requiere de la asistencia técnica de los administradores del servidor: se precisa que los ficheros de logs estén convenientemente localizados y preservados, para que así se puedan generar informes estadísticos mediante programas del tipo log file analyzers, como por ejemplo AWStats, soluciones que por diversas razones cada vez son menos usadas. Ahora bien, los datos del lado del servidor son también la fuente que utilizan algunos programas ad hoc desarrollados especialmente para portales de revistas o que alimentan los conectores (plug-ins) de estadísticas integrados en el sistema de gestión de contenidos usados para gestionar la revista, como sucede con los informes COUNTER de OJS (Public Knowledge Project, s. d.).4 En ambos casos, se requiere un planteamiento sostenible de captura, preservación, depuración del tráfico de robots y anonimización de los datos que se recogen en un fichero de logs. Estas herramientas permiten contabilizar ficheros de todo tipo solicitados al servidor (también ficheros PDF u otros formatos), aunque se haya llegado a ellos sin pasar por la estructura de navegación de páginas HTML (como sucede cuando desde Google Scholar se accede a un PDF de una revista de forma directa, sin que aparezca enmarcado en una página web).
En las soluciones del lado del cliente, de las que Google Analytics representa el paradigma por su elevado nivel de uso en todo tipo de sitios web, se traza el recorrido del usuario a lo largo del sitio web de la revista mediante la activación de una etiqueta de seguimiento inserto en un código JavaScript cada vez que se carga una página web o se produce un evento a partir de una página (como por ejemplo hacer clic en un enlace a un PDF); esto es, se capturan los datos del tráfico web efectivo desde el navegador del usuario, con lo que queda excluido el tráfico de robots. El navegador al leer el código JavaScript incrustado en las páginas web enviará a los servidores del proveedor del servicio datos de la petición de archivo de cada página y los asociará con la cookie anónima y permanente que el proveedor deposita en dicho navegador para su identificación como usuario único. Estos códigos de seguimiento solo pueden estar presentes en las páginas HTML. Por ello, solo se podría medir el acceso a un artículo en PDF si el usuario lo visitó desde una página web. Esto representa una limitación en cuanto a la medición de las consultas, pues si el usuario visita un artículo en dicho formato directamente desde Google Scholar o algún otro buscador web general ese tráfico al fichero PDF no quedará trazado por ningún programa del lado del cliente (Obrien [et al.], 2016).
Ahora bien, como punto más destacado hay que señalar que este tipo de programas brindan un elevado nivel de granularidad en el tratamiento de los datos y una gran versatilidad en la configuración de los informes de visualización, lo que permite conocer datos muy útiles sobre la conducta de los visitantes, con un nivel de detalle que no se puede conseguir en la mayoría de las soluciones del lado del servidor que se utilizan habitualmente. Podemos conocer indicadores que representan el desempeño del sitio, comparando cualquier tipo de intervalo cronológico y segmentando la información por multitud de características cruzadas de las visitas o de los usuarios.
En el caso de Google Analytics se trata de un servicio gratuito que permite externalizar la recogida, almacenamiento, explotación y visualización de los datos de navegación de los usuarios, por lo que más allá de crear la cuenta y etiquetar las páginas web que se desea trazar, no requiere instalación alguna. Existe una versión de pago de Google Analytics, así como otros proveedores comerciales que ofrecen este tipo de servicios, como Adobe Analytics o Matomo Cloud. Si queremos disponer de una solución del lado del cliente con control de los datos en nuestros servidores, se pueden usar programas gratuitos, como Matomo On-Premise, que ofrecen una explotación y visualización de datos similar a Google Analytics, pero que requiere de recursos informáticos propios para instalar el programa y almacenar los datos que se van a explotar. Elegir alguna de las opciones externalizables, como la versión gratuita de Google Analytics, viene siendo lo más habitual cuando la revista no cuenta con infraestructura tecnológica.
Podemos decir que los datos que nos puede proveer una herramienta de analítica del lado del cliente nos dan una idea muy completa sobre las interacciones de los usuarios con las páginas informativas (no citables), pero una idea parcial de las consultas de los contenidos citables en sus distintos formatos. Por eso, junto con el análisis detallado de la interacción con el web que ofrece una solución del lado del cliente, siempre será necesario en el caso de revistas con contenidos citables no HTML contar con la información de un conector de estadísticas o de un log file analyzer, para conocer con precisión, y sin importar de dónde vengan, las consultas a contenidos citables en PDF, EPUB o equivalentes. Por otro lado, los datos del proveedor de analítica del lado del cliente nos servirían para conocer las interacciones con contenidos HTML, ya sean páginas informativas o contenidos citables localizados navegando por el sitio web de la revista.
Esta complementariedad se puede considerar que está formalmente contemplada por la mayoría de los sistemas de gestión de contenidos, que facilitan la configuración de Google Analytics mediante un conector que simplifica drásticamente la tarea de añadir el código de seguimiento a todas las páginas de las revistas. OJS, por ejemplo, cuenta con esta opción, por lo que el Public Knowledge Project (PKP) reconoce el valor que tienen estos servicios de terceros en cuanto a la gestión global del sitio, ya que vienen a complementar la robustez del seguimiento de las descargas de artículos mediante la explotación de logs o las estadísticas internas del sistema de gestión de contenidos.
3.3 Ventanas temporales e indicadores clave de rendimiento (KPI) para el análisis de tendencias
Las cifras absolutas de las métricas que ofrece un programa de analítica se han de tomar como una aproximación, dado que por diversas razones los datos recogidos nunca reflejan la realidad al ciento por ciento. Ahora bien, los valores relativos, las ratios y las variaciones de esos indicadores (consistentemente obtenidos a lo largo del tiempo) tienen más solidez y nos pueden ayudar en la toma de decisiones y en la evaluación del desempeño de la revista. La comparación interna del sitio web a lo largo del tiempo, por ejemplo, comparando años consecutivos (figura 1), interpretada a la luz de la gestión editorial que se haya llevado a cabo en cada periodo, es el verdadero conocimiento operativo que puede ayudar a marcar la diferencia.
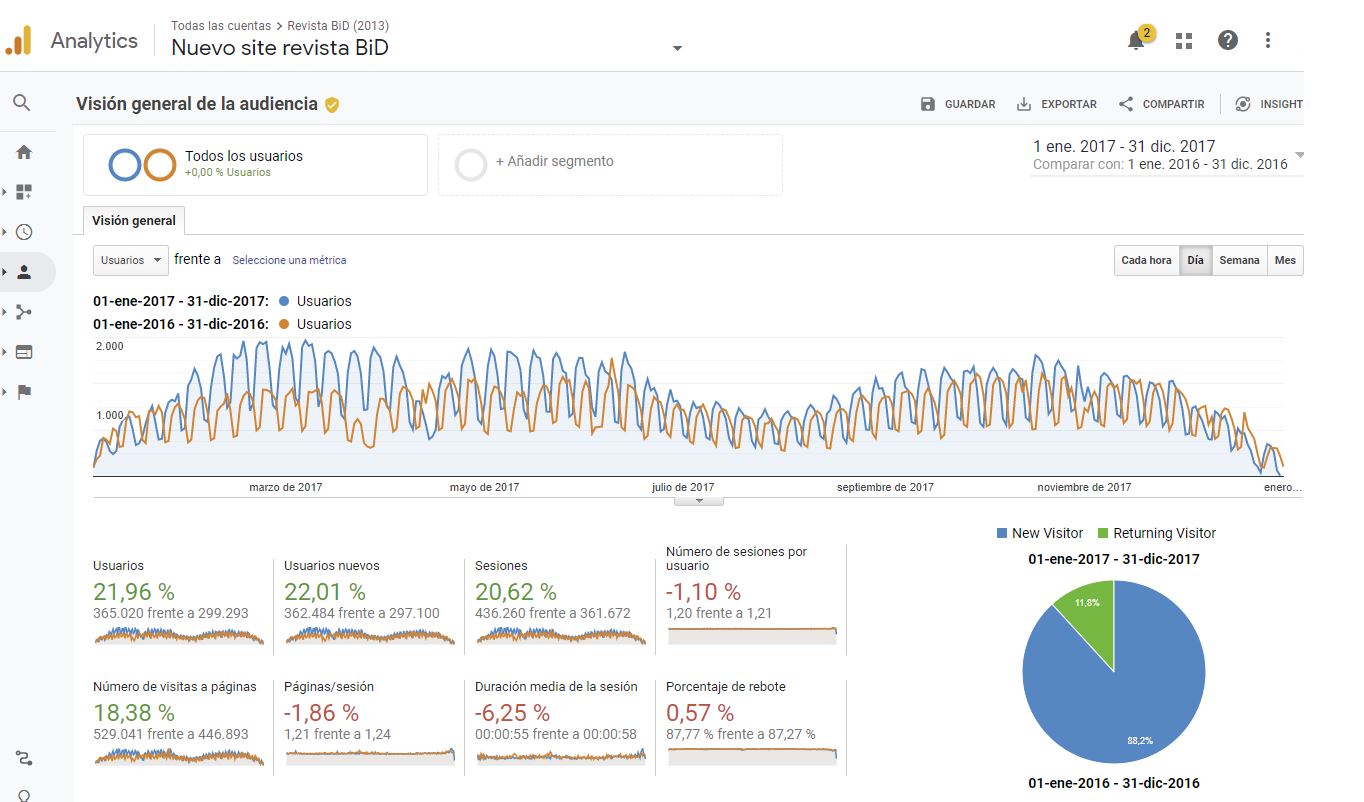
Figura 1. Visión general de la audiencia de la revista BiD para 2017 comparada con 2016. Fuente: Cuenta de Google Analytics para BiD
Esta consideración nos lleva a poner de relieve que el valor de la información de analítica está en los indicadores y especialmente en los indicadores clave de rendimiento (KPI, key performance indicators); las métricas básicas, por sí mismas, sin un contexto que permita interpretar la evolución en forma de porcentaje de variación o de proximidad a una meta fijada de antemano, tienen poca utilidad. Esto es, el "cuándo" del análisis está con frecuencia vinculado con el "qué" y el "para qué". Por ejemplo, podemos comparar algún periodo en el que se haya lanzado la última solicitud de ponencias (call for papers) con el llamamiento inmediatamente anterior en el tiempo o con un periodo en el que no se haya hecho, y analizar su repercusión. Por poner otro caso, si la revista decide internacionalizarse y empieza a publicar contenidos en inglés, podríamos comparar el antes y el después, analizar los datos e interpretarlos para saber si fue significativamente beneficioso o no.
3.4 Ámbitos de análisis
Dado que en la propuesta se quiere incidir principalmente en informes de uso obtenidos con Google Analytics, hemos de advertir del enorme abanico de métricas y de informes que se pueden obtener bajo los diversos tableros de visualización de dicho programa. Además, cada uno de ellos puede dar lugar a muchas presentaciones diferentes con información más específica, gracias a las combinaciones de dimensiones y segmentos que el programa ofrece de serie o a las que el propio usuario puede configurar. Semejante variedad de vistas y de datos puede llegar a abrumar a cualquier observador. Por ello, en esta propuesta hemos seleccionado algunos análisis concretos entre otros muchos posibles y los hemos agrupado por ámbitos (figura 2), con las métricas seleccionadas para cada uno de ellos. Se trata de una selección de informes que se pueden aplicar a revistas académicas de acceso abierto, asumiendo que hay que priorizar el uso de los datos más allá de la mera curiosidad estadística: no tiene sentido dedicar tiempo y esfuerzo a aquellos datos que no sirvan al propósito del proyecto de analítica web.
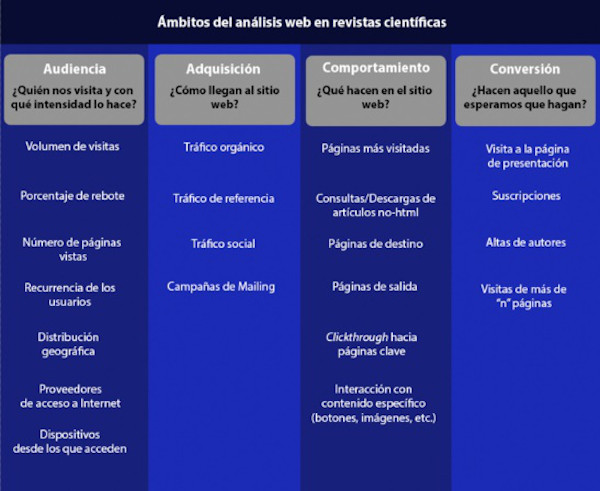
Figura 2. Ámbitos del análisis web en revistas científicas
En todo caso, conviene recordar que los datos que ofrecen las herramientas de analítica web ayudan a plantear hipótesis sobre por qué se produce una determinada evolución del sitio web a lo largo del tiempo o, por ejemplo y de forma más específica, por qué los usuarios no responden como esperamos al diseño de navegación o a las llamadas a la acción (call to action, CTA) en forma de propuestas de acción que les presentamos. Para tener una respuesta más certera a las preguntas sobre el funcionamiento de una revista no deberíamos dejar de lado otras vías de captación de la voz de lectores, autores, revisores, editores y otros actores involucrados con la revista. Los informes de Google Analytics por sí solos no nos dan la respuesta definitiva del porqué del comportamiento de los usuarios, para lo cual deberían utilizarse encuestas, entrevistas o algún otro método de investigación cualitativa.
3.4.1 Análisis de la audiencia: ¿quiénes nos visitan y con qué intensidad o calidad lo hacen?
En principio, lo más normal en la configuración de un programa del tipo de Google Analytics para una revista de acceso abierto es trazar el tráfico recibido de forma anónima, pero individualizando los usuarios únicos mediante cookies persistentes. Como ya hemos dicho, los aspectos éticos y de preservación de la privacidad no son temas menores y deben considerarse en el momento de decidir la configuración de un programa de analítica del lado del cliente, por lo que el grado de acceso a datos del perfil de los usuarios dependerá de las configuraciones a las que hemos hecho referencia en el apartado 3.2. En todo caso, sin mayor problema que la buena práctica de avisar a los usuarios del uso de cookies anónimas para el análisis estadístico del sitio web, este tipo de programas permite generar interesantes informes sobre nuestra audiencia. Destacamos los siguientes:
a) Volumen de visitas y de usuarios
Las visitas, también llamadas sesiones, son todas aquellas interacciones consecutivas con páginas de un sitio web en las que el tiempo entre la carga de una página y la siguiente no supera un tiempo máximo para la delimitación de sesiones, que habitualmente se establece en treinta minutos. Las visitas se trazan a partir de la información que envían navegadores web que se supone utilizan usuarios reales. Es importante mencionar que una misma persona puede generar en un mismo día varias visitas por causas diversas. Por ejemplo, puede acceder a una misma página web dos veces desde un mismo navegador en un ordenador de sobremesa, en intervalos superiores al tiempo marcado como límite para la definición de sesiones; además, también puede haber utilizado otro navegador en ese mismo ordenador, después una tableta y por último un teléfono móvil: esto contará como cinco visitas de cuatro usuarios diferentes (ya que para el programa el usuario se identifica como un navegador con una cookie concreta). La plataforma detecta que son cuatro usuarios basándose en que se están utilizando cuatro navegadores diferentes, e identifica como dos visitas diferentes de un mismo usuario las que se realizaron con el mismo navegador del ordenador de sobremesa. Esto es, el recuento de usuarios se corresponde al número de navegadores únicos identificados con la ID de la cookie que deposita el programa de analítica la primera vez que se visita un sitio web, que funciona como identificador del cliente web. A diferencia de lo que sucede en las visitas, si la persona vuelve a acceder al sitio web desde el mismo navegador, la plataforma considerará que se trata de un mismo usuario reincidente dentro del marco temporal que apliquemos a los informes. Como se puede ver en la figura 3, Google Analytics recuerda que el usuario que realiza cuatro sesiones el día 20 de junio de 2018 entró por primera vez con esa cookie el 19 de febrero de 2018. De los términos de analítica web, usuario es el que más se acerca al concepto coloquial de persona visitante, sin embargo, no al ciento por ciento, puesto que una misma persona puede visitarnos desde diferentes navegadores o dispositivos y contará como usuarios diferentes.
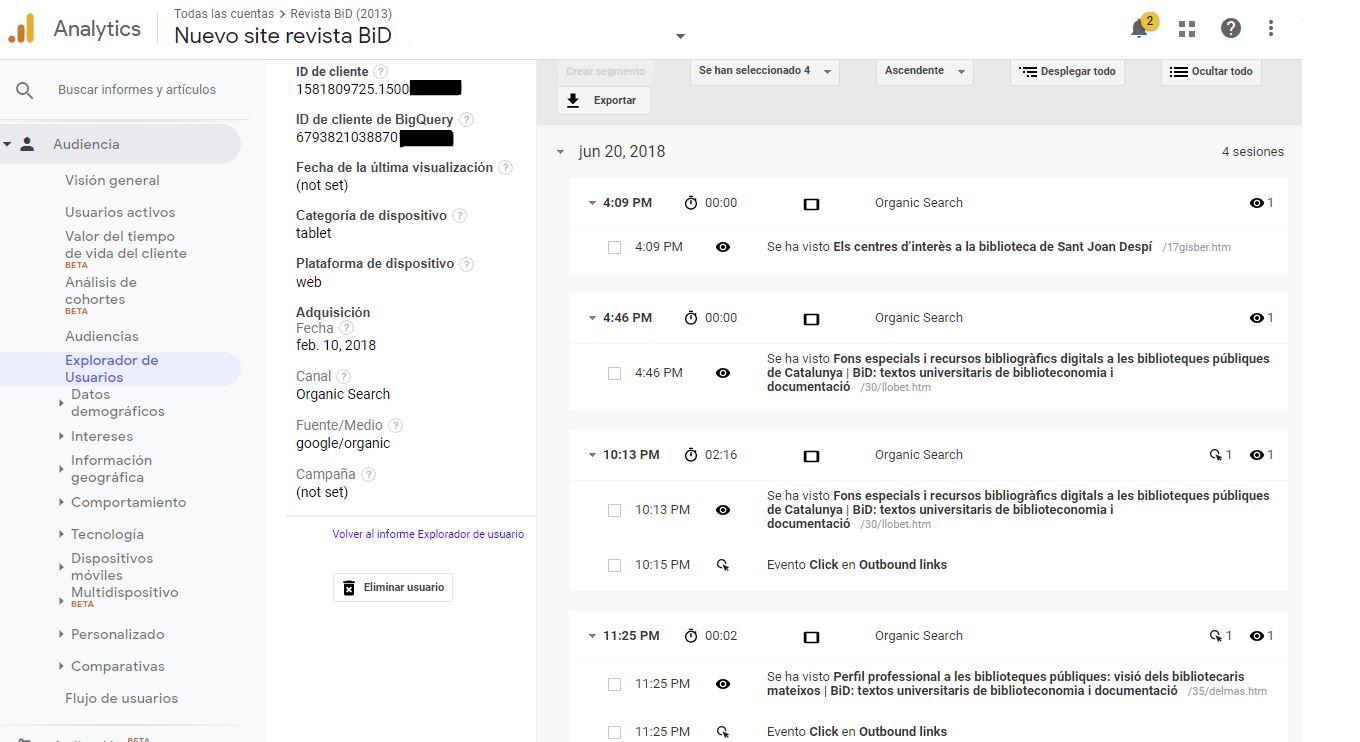
Figura 3. Análisis de las sesiones de un mismo usuario identificado con una cookie en un día concreto mediante el informe "Exploración de usuarios". Fuente: Cuenta de Google Analytics para BiD
b) Rebote
El porcentaje de rebote es una métrica que informa del número relativo de visitas en las que el usuario únicamente solicitó una página por la que entró a la revista (conocida como página de destino o landing page), sin ninguna acción ulterior con el sitio web. Si la página de aterrizaje corresponde a contenido informativo no citable, y el rebote es elevado, sería necesario analizar la congruencia del contenido y la navegación desde esa página en relación con lo que nosotros esperamos de los usuarios en dicho punto de la arquitectura del web.
Si la página de aterrizaje corresponde a un artículo, no solo podremos valorar qué tanto llamó su contenido la atención del usuario, sino también la capacidad que tiene el sistema de navegación de atraer a la consulta hacia contenido relacionado, o de mostrar contenido informativo del web que ayude a situar al usuario que desconoce la publicación y que llega a ella por primera vez aterrizando en un artículo.
El rebote es una de las pocas métricas en las que en la mayoría de los casos es mejor disminuir el porcentaje que aumentarlo. Si notamos que el porcentaje de rebote de la revista ha aumentado respecto a un periodo anterior y que ese incremento se produce en los diversos canales de adquisición de tráfico, deberíamos considerar que alguno de los cambios que hemos realizado ha tenido un efecto negativo o que los contenidos que estamos ofreciendo no están resultando tan interesantes para el público como antes.
c) Interacción: número de páginas por visita y duración
De forma complementaria a la tasa de rebote, estas métricas nos permiten saber de la inclinación de los usuarios a seguir navegando en el sitio. Esa navegación más allá de la consulta de un artículo individual puede ser un indicador del buen o mal funcionamiento del sistema de recomendación de artículos que ofrece la revista, por ejemplo, basados en patrones de actividad del lector (Taraghi [et al.], 2013), en proximidad con las palabras clave o en solapamiento bibliográfico con otros artículos. Recordemos que un objetivo de toda revista es que el propio sitio web invite al usuario a seguir viendo más artículos o a conocer el funcionamiento de la publicación. Por ello, la reducción del porcentaje de rebote y el aumento de sesiones de más de ciento ochenta segundos, por ejemplo, deberían ser el resultado lógico de todas aquellas mejoras en la navegación, la hipertextualidad interna de la redacción o en el diseño de las llamadas a la acción (CTA). Informes como el de la figura 4 permitirán hacer ese seguimiento acotando a fechas concretas que puedan ser significativas en esas mejoras.
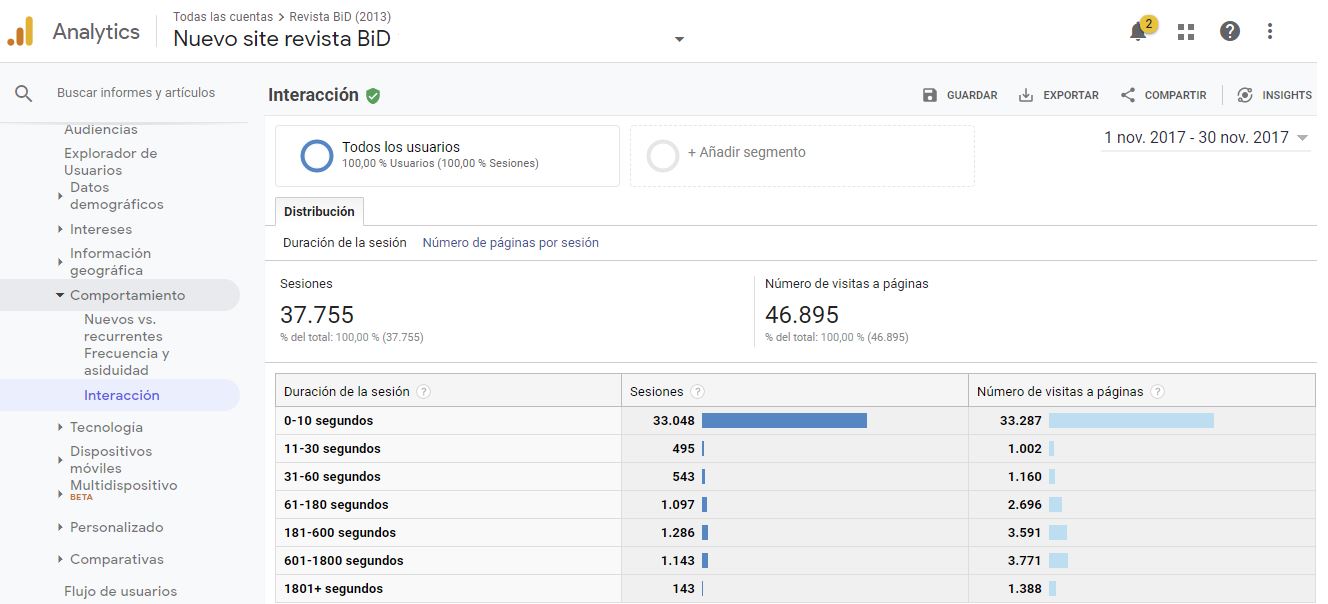
Figura 4. Análisis de las sesiones por rangos de duración de estas para noviembre de 2017. Fuente: Cuenta de Google Analytics para BiD
De todas formas, con frecuencia un único informe no será suficiente para determinar problemas o el desempeño que pueda haber tenido una mejora en la revista. Así, los informes generales de la audiencia con el rebote o con la duración de las sesiones se deberían estudiar de forma muy granular, por ejemplo, tomando en consideración todas las visitas que accedan a la revista por una página claramente pensada para la navegación como la página inicial (home page). Como podemos ver en la figura 5, desde el grupo de informes "Comportamiento" se puede ver lo que sucede con el rebote y la duración de la sesión cuando los usuarios inician su visita en una página de destino concreta, diferenciando el comportamiento según el usuario haya entrado directamente la dirección de la página o bien proceda de la página de resultados de un buscador, del enlace a la revista en otro sitio web o del enlace presente en una red social.
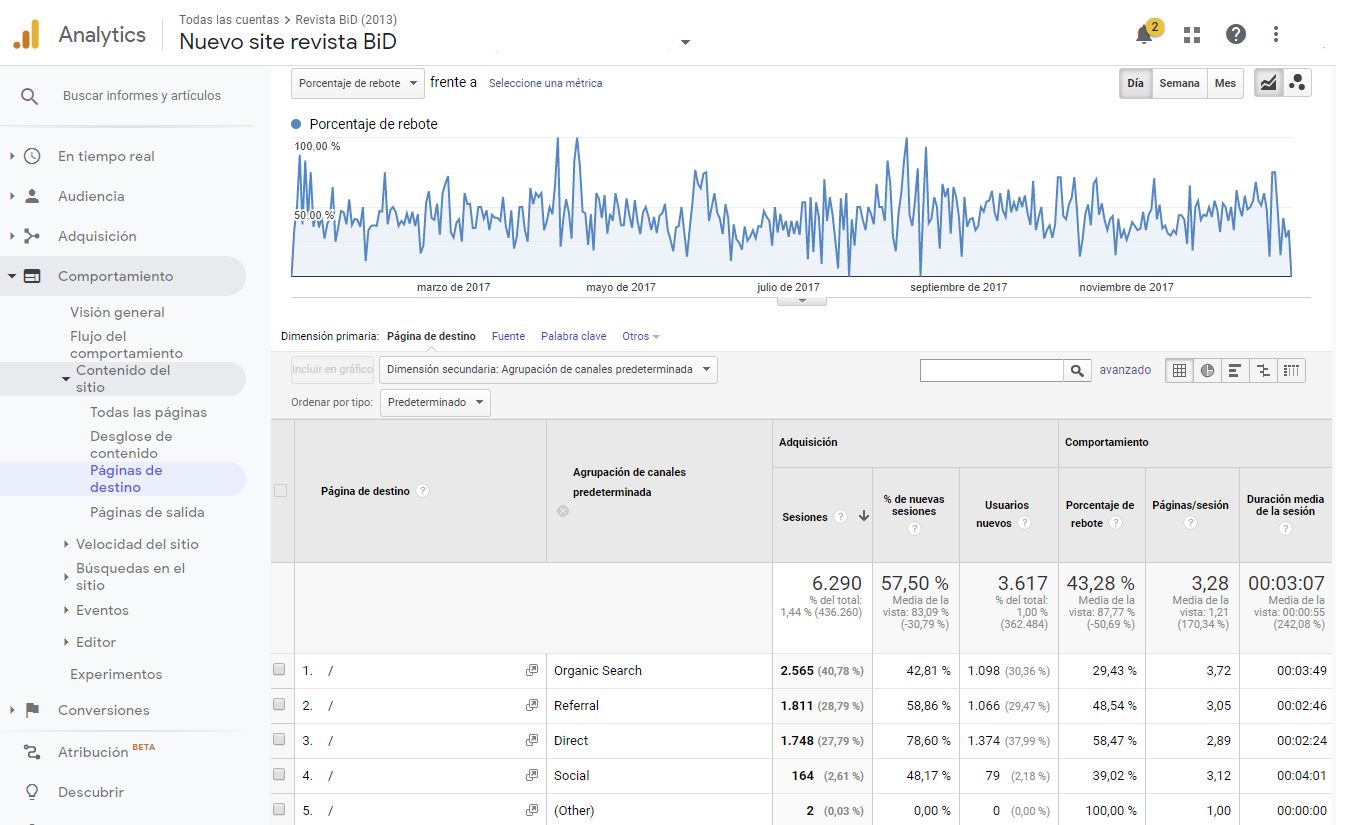
Figura 5. Análisis del desempeño de la página inicial de la revista BiD como página de destino durante 2017. Fuente: Cuenta de Google Analytics para BiD
Más allá de las métricas que nos informan de la profundidad y la calidad de las visitas, el programa de analítica nos ayudará a mapear los itinerarios efectivamente recorridos por los usuarios e identificar lo que más les interesa. Cabe mencionar que el tiempo de navegación que muestra la herramienta puede no ser preciso, puesto que a veces el usuario deja su navegador abierto sin actividad alguna, lo cual causará que Google Analytics considere estadísticamente el final de la sesión. A pesar de eso, es necesario comparar periodos de tiempo recientes con periodos anteriores para ver si hay mejora.
d) Recurrencia de los usuarios
Medir los usuarios recurrentes que acceden a la revista más de una vez en un periodo determinado, así como la intensidad en la reiteración de sus visitas, nos ayudará a captar el customer loyalty, esto es, el grado de fidelización que genera nuestro sitio web. Tener esta información nos permitirá tener una idea de la intensidad con que la revista quedó posicionada en la mente del lector. Si su experiencia fue buena, es probable que vuelva. Es importante publicar contenidos nuevos constantemente para mantener el interés del lector. Enviar boletines de información a partir de una base de datos de usuarios registrados puede ayudar a lograrlo. La eficacia de dichas acciones se puede medir mediante los informes sobre la recurrencia de los usuarios.
e) Distribución geográfica
La distribución por países y ciudades permite reflexionar sobre el alcance de los contenidos a nivel global y local. La distribución geográfica de usuarios aporta una información muy valiosa para una revista, ya que el contraste de datos nos puede llevar a formular hipótesis explicativas que nos ayuden a descubrir claves de internacionalización, por ejemplo. Segmentando por zonas los datos obtenidos en cualquiera de los cientos de informes que ofrece Google Analytics, podemos tener una visión granular muy potente sobre cómo evoluciona el tráfico. Esto es especialmente necesario si la revista o algunos de sus contenidos se orientan a determinados públicos diana definidos geográficamente. La capacidad de programas como Google Analytics de bajar al nivel de ciudades (figura 6) y comparar la calidad de visitas en función de la evolución temporal y de la fuente de tránsito puede ayudarnos a descubrir situaciones positivas que se producen en los usuarios que provienen de una determinada localidad y por medio de un determinado enlace, por ejemplo, y que podrían ser extrapoladas a otras zonas geográficas.
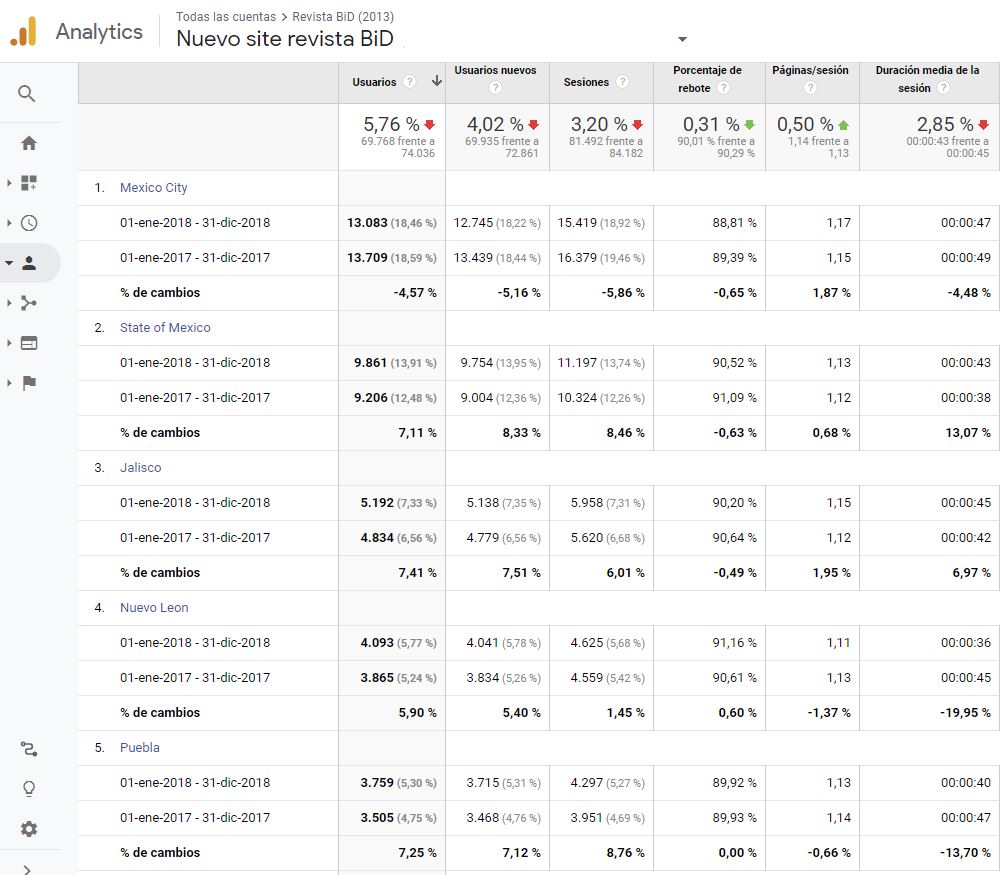
Figura 6. Análisis por ciudades del descenso de visitas en 2018 procedentes de México a la revista BiD. Fuente: Cuenta de Google Analytics para BiD
Asimismo, podremos ayudarnos de este nivel de granularidad por ciudades para localizar mejor el descenso de visitas procedentes de un país relevante entre nuestra audiencia. Por ejemplo, como se puede ver, en 2018 la revista BiD tuvo una disminución del 3,2 % en las visitas procedentes de México (figura 6), que se puede explicar de forma casi íntegra por el descenso observado en Ciudad de México (–5,86 %), por lo que quizás así se podrían buscar soluciones de promoción más localizadas.
f) Proveedores de acceso a Internet (ISP)
Podemos segmentar las visitas según se trate de proveedores de acceso comerciales o institucionales. Entre estos últimos podemos destacar la identificación de las visitas que provienen de universidades, centros de investigación o administraciones públicas vinculadas con el mundo científico y académico. Analizar el interés que generan los contenidos en determinadas universidades y segmentar esta información según la URL de referencia por la que se ha llegado al contenido puede ayudar a descubrir acciones de prescripción de los artículos o de la revista en su conjunto.
g) Dispositivos con los que acceden los usuarios
Analizar de qué dispositivos provienen las visitas nos ayudará a ver si el uso de la revista corresponde a la tendencia de crecimiento de uso de dispositivos móviles para navegar en contenidos en línea. Si el uso en móviles y tabletas es bajo, puede significar que la experiencia que el usuario tiene con el sitio no es positiva. Esto puede ser porque el diseño del sitio no se adapta al tamaño de las pantallas o porque los elementos que ayudan a navegar al usuario no se visualizan fácilmente.
Lo recomendable en esos casos es implementar el diseño adaptativo (responsive design). Esto significa que es un solo sitio web en el que un mismo código funciona tanto para ordenadores de escritorio como para dispositivos móviles, pero los elementos se visualizan de forma distinta. Es una opción también crear una versión móvil del sitio en la que el código sea diferente, es decir, desde su raíz (código HTML) los tamaños y la distribución de los elementos están pensados de forma distinta para la versión móvil y la versión de escritorio. Esta opción no es recomendable para fines de posicionamiento web de revista, puesto que implica que sean distintos sitios con diferentes URL, factor que puede afectar al ranking en el posicionamiento web de la revista en buscadores.
3.4.2 Análisis de la adquisición: ¿cómo descubren nuestro sitio web o llegan a él?
Saber la acción que atrajo a un usuario a nuestra revista es fundamental para planificar estrategias de captación de lectores, pues, gracias al campo referrer de los logs y al etiquetado de enlaces hacia nuestra revista en mensajes de correo o en redes sociales, podemos tener una idea de la distribución de las visitas recibidas según procedan de un determinado canal. Como ejemplos podemos destacar visitas que se originan en fuentes diversas: los resultados de una consulta en un buscador como Google (canal "Organic search"); en la introducción directa de la URL solicitada en un navegador (canal "Direct"); un clic en un enlace en cualquier otro sitio web que no sea ni un buscador ni una red social, por ejemplo en una base de datos bibliográfica como Dialnet (canal "Referral"); un clic en un enlace presente en una entrada de Twitter (canal "Social"); o seguimiento de un enlace presente en el correo electrónico con el que se avisa a los suscriptores de las novedades (canal "Email"), entre otros. En el caso de la revista BiD (figura 7) se puede observar la importancia del canal orgánico y en concreto Google en la captación de visitas. Configurando ese informe mediante la comparación de rangos cronológicos, podemos detectar algún problema, como sucede en este caso con el descenso significativo de visitas desde Google, que coincidió con cambios en la política de indización del buscador a los que se está adaptando poco a poco la revista.
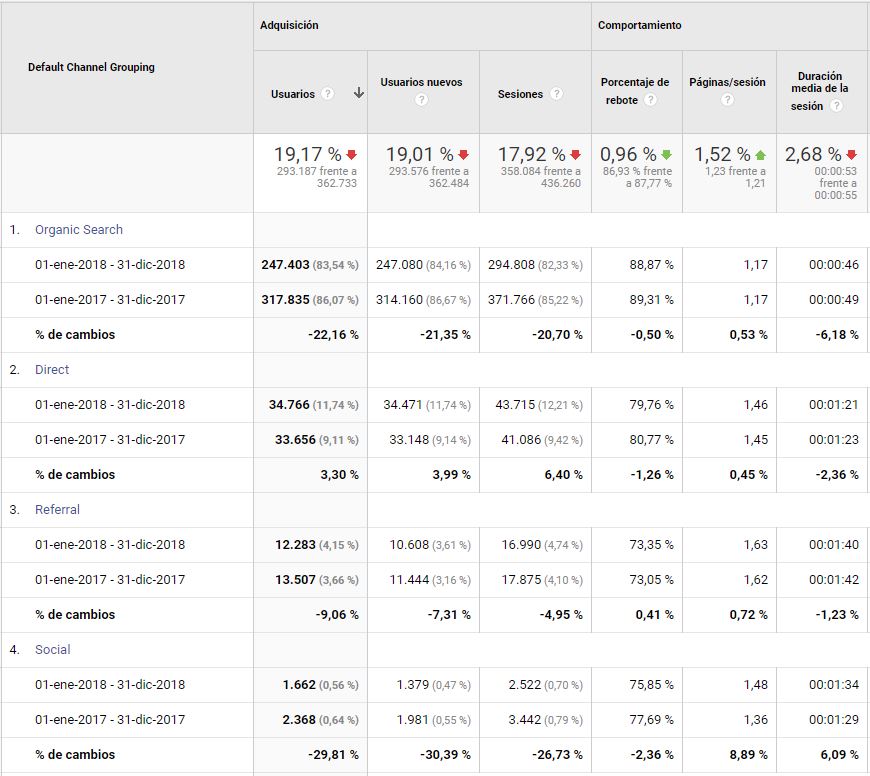
Figura 7. Ejemplo de distribución de los usuarios según el canal de adquisición de las visitas a la revista BiD en 2018 frente a 2017. Fuente: Cuenta de Google Analytics para BiD
a) Tráfico orgánico
En analítica web se denomina "tráfico orgánico" a las visitas que aterrizan en un sitio web procedentes de una página de resultados naturales en un buscador, esto es, clics en enlaces que no son anuncios pagados. Para la gran mayoría de los sitios web constituye la fuente más importante de tráfico, por lo que la mejora y monitorización del posicionamiento web, también llamado SEO, es también una de las rutinas clave para una revista digital. Para medir el desempeño orgánico es necesario disponer de datos con el volumen y la calidad del tráfico que llega desde motores de búsqueda, y en la medida de lo posible saber a qué palabras clave y consultas se asocian esas visitas. Optimizar las páginas de las revistas científicas desde una perspectiva de SEO (Park, 2018) aumenta las posibilidades de que los usuarios visiten más el sitio, descarguen más los artículos o incluso los citen. La información que nos suministra la analítica web nos permitirá elaborar un primer diagnóstico del posicionamiento, pero sobre todo nos ayudará a evaluar el resultado de las acciones adoptadas.
Al analizar las palabras clave que los usuarios utilizan en buscadores para acceder al sitio de la revista, nos encontraremos con la limitación de que Google Analytics no provee predeterminadamente todos estos términos de búsqueda, ya que un gran porcentaje de ellos se clasifican como not provided. Esto se debe a que, por cuestiones de privacidad de los usuarios, Google Analytics no recoge esta información cuando las personas que utilizan el buscador tienen iniciada su sesión en una cuenta de Google. Por ello, se recomienda ligar la cuenta de Google Analytics del sitio web con el servicio Google Search Console (figura 8) para obtener información más completa sobre las veces que un determinado artículo ha aparecido en resultados de búsquedasen Google, su posición promedio, los clics que ha generado o las palabras clave en búsquedas que han provocado que se muestre contenido de la revista en el buscador. Si bien algunos datos de Search Console se pueden integrar en Google Analytics (figura 8), para un análisis más a fondo se tiene que acceder directamente a los informes en la interfaz propia de servicio (figura 9).
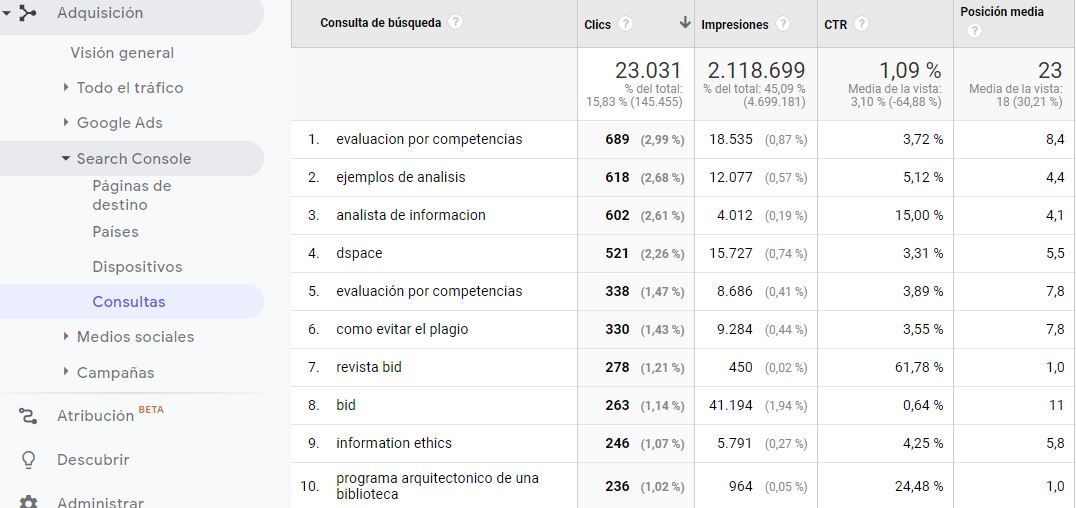
Figura 8. Informe de consultas en Google resultado de la integración de Google Analytics con Google Search Console. Fuente: Cuenta de Google Analytics para BiD
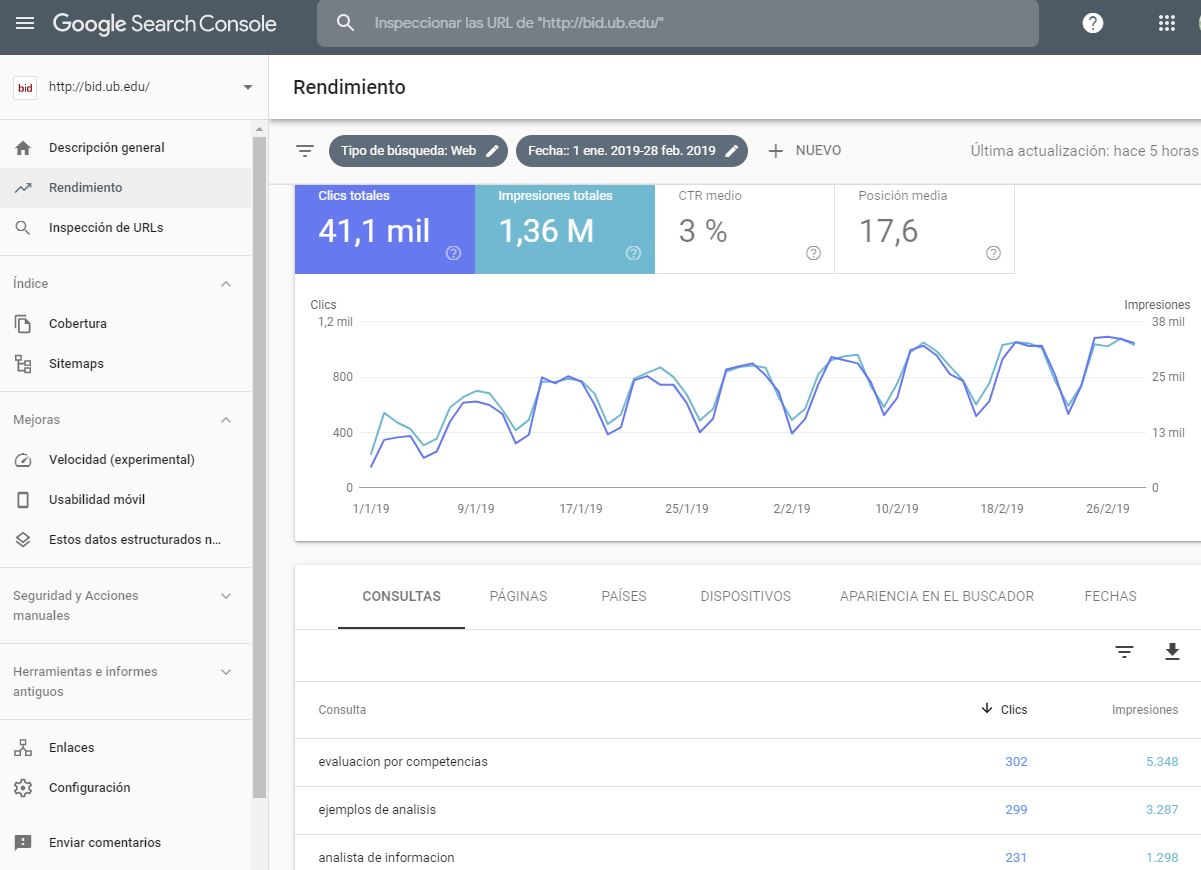
Figura 9. Informe completo de Google Search Console con el rendimiento del posicionamiento de la revista BiD en búsquedas de Google. Fuente: Cuenta de Google Analytics para BiD
Para optimizar el posicionamiento en buscadores existen guías de buenas prácticas en los ámbitos SEO conocidos como on-site y off-site (Codina, 2019). Los factores on-site están relacionados con las optimizaciones que se realicen dentro del propio sitio de la revista, como la longitud de los textos, las palabras clave que se utilizan, el tiempo de carga del sitio, entre otros. Los factores off-site están más relacionados con el volumen y la calidad de los sitios web que tienen hipervínculos que apuntan hacia la revista; también a la repercusión e influencia que se está teniendo en redes sociales.
Hablando del tráfico procedente de buscadores, podríamos llegar a pensar que Google Scholar está clasificado como tráfico orgánico en Google Analytics, sin embargo, no es así, ya que se considera como tráfico de referencia (referral). Veremos detalles en el siguiente epígrafe, si bien, desde el punto de vista de las labores de SEO, resulta pertinente analizar conjuntamente cómo posicionar tanto en buscadores generalistas como en los académicos: mientras que los enlaces entrantes determinan en gran medida el PageRank de las páginas en Google Search (p. ej. el buscador general Google.com), las citas recibidas son el principal factor de posicionamiento en la ordenación de resultados de Google Scholar. Existen factores que son similares en Google Search y en Google Scholar, como la relevancia del contenido, las citas o los enlaces recibidos, la reputación del autor y la reputación de la publicación o del dominio, pero, al tratarse de instancias diferentes, es importante que las revistas tomen en consideración las especificidades de cada una de ellas (Rovira; Guerrero-Solé; Codina, 2018).
b) Tráfico de referencia
Consultar el tráfico de referencia nos permite conocer desde qué otros sitios web están llegando los usuarios a la revista. Los informes de Google Analytics nos dan el dato de qué enlaces específicamente fueron accionados para llegar tanto a contenidos citables como a páginas informativas. Tener un gran volumen de tráfico referenciado puede favorecer el ranking en el posicionamiento web de buscadores.
Además de Google Analytics y Google Search Console existen otras plataformas como SEMRush o BrightEdge, entre otras, que pueden darnos una perspectiva del inventario de enlaces entrantes (inbound links) hacia nuestro sitio. Los programas de analítica web son una herramienta importante en el trabajo de búsqueda constante de los mejores enlaces hacia nuestro sitio web, una actividad que se conoce en inglés como link building.
Cuando analizamos los datos de revistas científicas en una herramienta de analítica web como Google Analytics, es común que en el tráfico de referencia esté presente Google Scholar, puesto que en este motor de búsqueda académico aparecen enlaces a artículos en los diferentes formatos posibles, incluyendo las páginas HTML de los contenidos citables. Ahora bien, se ha de recordar que no quedarán trazados los clics sobre páginas de Google Scholar que lleven directamente al PDF de la revista.
c) Tráfico social
La presencia en redes sociales puede ayudar a generar eco en la web. Sin duda puede ser un canal más de captación de visitas, por ejemplo, dando a conocer los nuevos artículos publicados. También dará una voz a la revista en la conversación digital que se pueda producir sobre ciertos temas, respecto de los cuales la revista pueda aportar artículos publicados en el pasado, que pueden revitalizarse si se viralizan en la discusión. Tanto en un caso como en otro, es importante que el enlace que se colocará en el artículo se comunique en formato DOI, ya que eso asegura la trazabilidad en herramientas altmétricas de servicios como PlumX o Altmetrics.com. Para facilitar la presencia de los artículos de la revista en redes sociales, es recomendable que la opción de "Compartir" no solo esté en la parte superior del artículo, sino también en la parte inferior, que es a donde los usuarios llegan cuando terminan de leer el texto. Gestores de contenido como OJS dan la opción de añadir conectores gratuitos con esta funcionalidad. En todo caso, conocer las estadísticas del tráfico que se genera en cada red social (figura 10) puede ayudar a focalizar el esfuerzo del gestor de comunidades de la revista y a evaluar si la actividad desarrollada en un determinado periodo está respondiendo a las expectativas generadas por dicho esfuerzo.
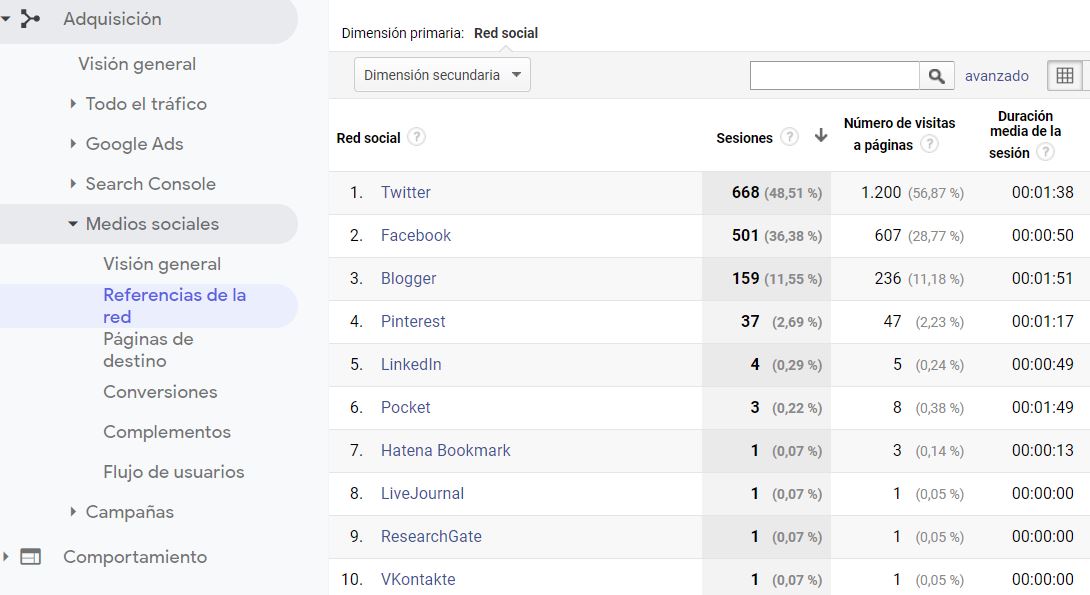
Figura 10. Distribución de las visitas a BiD según la red social de procedencia durante el primer semestre de 2019. Fuente: Cuenta de Google Analytics para BiD
d) Campañas de buzoneo digital
Una tarea básica para mantener activa y fidelizar una comunidad de lectores y autores es el envío de boletines de información. Dar visibilidad a las nuevas publicaciones de artículos en estos mensajes electrónicos significa sacar provecho de la base de datos de usuarios que nos proporcionaron su dirección de correo electrónico previamente. Estas campañas de buzoneo (llamadas así en el ámbito del marketing) nos ayudarán a llevar tráfico al sitio web original de la revista. Si bien los artículos pueden tener presencia en repositorios u otros portales, en ellos no se brinda la información para los autores, por lo que interesa atraer usuarios al web de la revista y así potenciar una interacción más completa que la simple lectura individual de artículos.
Aquellas revistas que utilizan OJS pueden emplear la funcionalidad announcements para notificar a los usuarios la publicación de nuevos contenidos de la revista. En la versión OJS 3, en el formulario de registro se ofrece una casilla de selección en la que el usuario puede elegir suscribirse a las notificaciones. Es recomendable que el contenido del mensaje electrónico sea breve, pero que dé los suficientes detalles para que el destinatario sepa a primera vista de qué tratan los artículos incluidos. Es de suma importancia incluir botones de llamada a la acción (CTA). Debajo de los resúmenes de los artículos se pueden poner botones con los siguientes textos: "Ver más", "Leer artículo", etc.
3.4.3 Análisis del comportamiento: ¿cómo se mueven por la revista?, ¿qué hacen?, ¿qué consultan?
a) Páginas más visitadas
Al analizar las páginas más visitadas debemos tener una doble mirada. Por un lado, a todo el stock de artículos que se ha ido acumulando a lo largo del tiempo, entre los cuales podemos detectar verdaderos "éxitos" de consultas, que no decaen con el tiempo, y que nos pueden indicar el tipo de trabajos sobre los que quizás conviene insistir dado el interés del público. Por otro, interesa analizar la recepción de los nuevos artículos publicados en forma continua, o de los nuevos fascículos cuando se cierran y se difunden. Este análisis puede ayudar a valorar la tarea de difusión y de lanzamiento de los nuevos contenidos, algo que se puede llegar a modular en función de los primeros datos de uso.
Al analizar las páginas vistas será necesario conocer la diferencia entre páginas vistas y páginas únicas. Las páginas vistas se contabilizan cada vez que se carga la página, sin importar que sea la misma persona: cada vez que se acceda contará como una página vista. En el caso de vistas únicas de página, si un usuario accede dos veces a una misma página en la misma sesión, contará como una única visualización.
b) Consultas o descargas de artículos no HTML
Resulta importante medir las descargas de los PDF o de materiales complementarios en otros formatos (XLS, CVS, etc.), porque nos indica un alto grado de interés por parte del usuario. Según el estudio de Allen, Stanton, Di Pietro y Moseley (2013), el hecho de que descarguen estos ficheros aumenta la posibilidad de uso del contenido. Para analizar datos de descargas de contenidos que no son HTML, Google Analytics dispone de la funcionalidad de seguimiento de eventos (véase el apartado 3.4.3f), que permite trazar los clics que desde páginas HTML se hacen en enlaces a ficheros no HTML de la propia revista, como por ejemplo los PDF. Ahora bien, para una perspectiva más completa y real, habría que considerar todos los datos de ficheros no HTML solicitados que hayan quedado registrados en informes estadísticos del sistema de gestión de contenidos o del analizador de logs del portal de revistas en el que se distribuya nuestra publicación, pues es normal que algunos usuarios accedan directamente a contenidos citables que no son HTML.
En el caso de la revista Anuari de l'Observatori de Biblioteques, Llibres i Lectura esta alternativa generada desde un portal gestionado con OJS (figura 11) es fundamental, ya que los datos que se obtienen por vía Google Analytics ignoran el tránsito directo al PDF, como se puede observar en la figura 12, en la que se comparan los datos para el artículo más consultado de la revista: mientras que RACO ofrece un valor del número de consultas más fiel a la realidad del uso, Google Analytics ofrece una diversidad de métricas y de dimensiones totalmente ausentes en RACO.
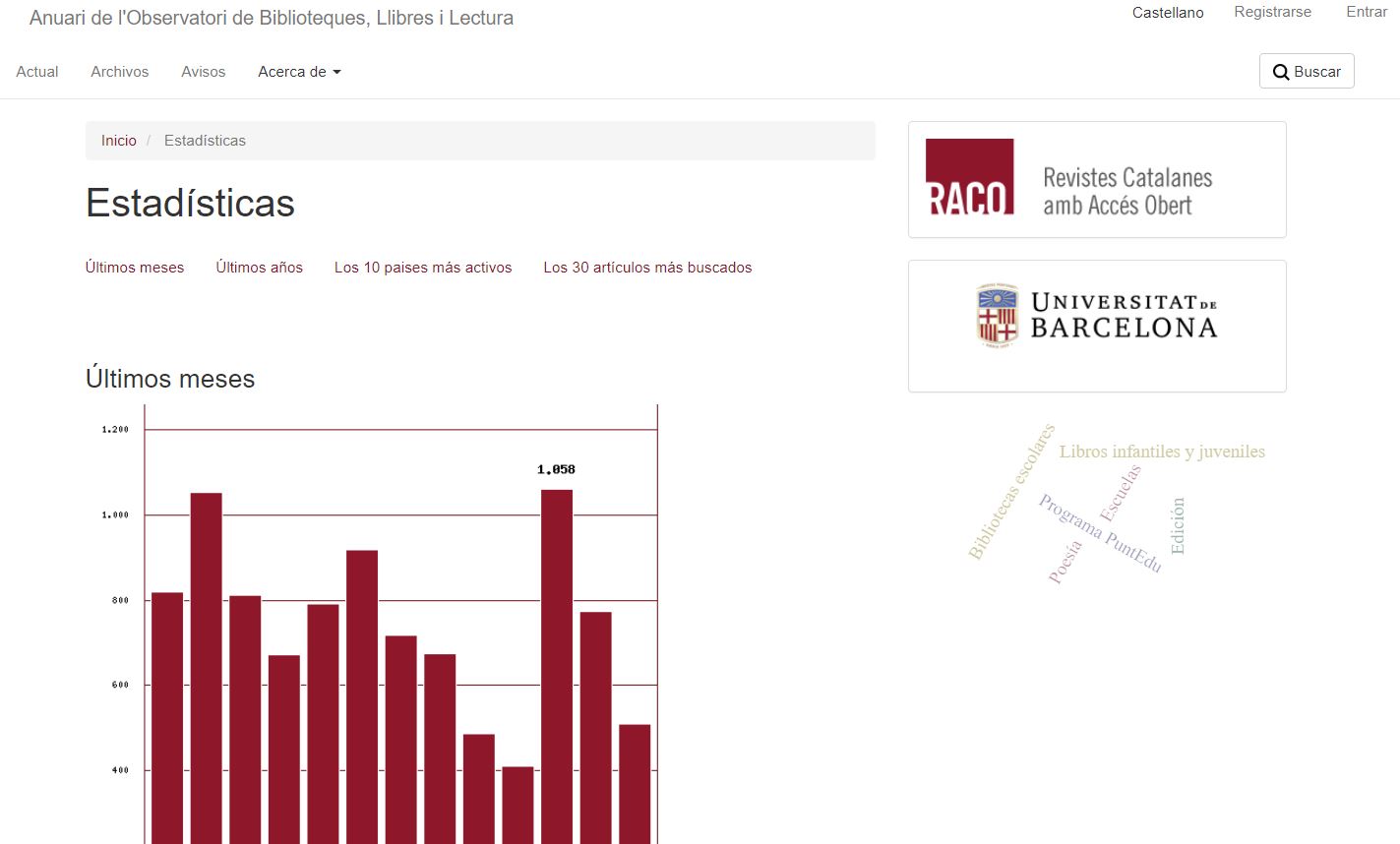
Figura 11. Estadísticas para revistas alojadas en el portal RACO: Revistes Catalanes amb Accés Obert. Fuente: Anuari de l'Observatori de Biblioteques, Llibres i Lectura
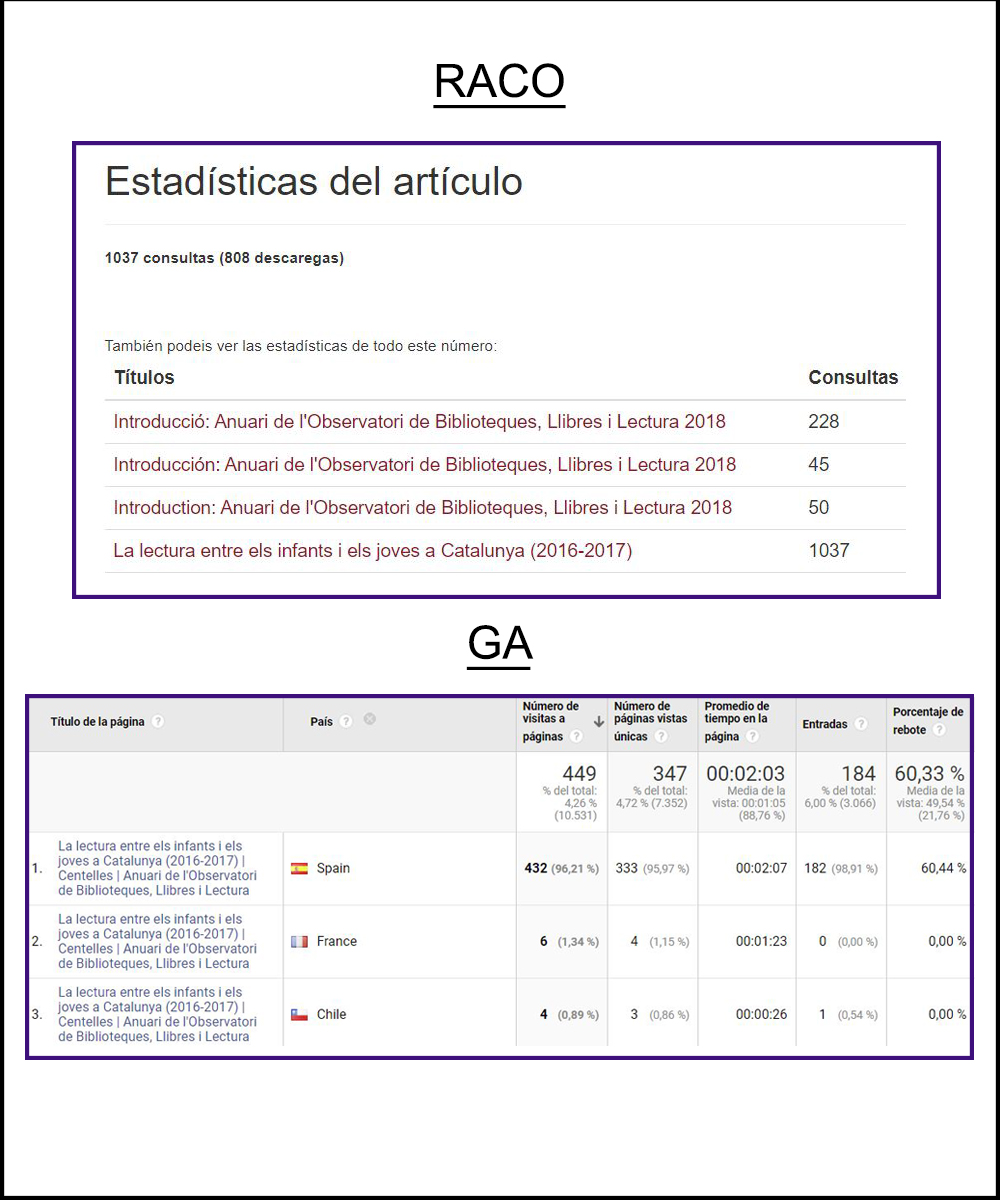
Figura 12. Diferencia en el número de consultas del artículo del Anuari de l'Observatori de Biblioteques, Llibres i Lectura> más consultado en 2018, según Google Analytics y estadísticas RACO.
c) Páginas de destino (landing pages)
El análisis de las páginas por las que entran los usuarios a la revista es uno de los más importantes y útiles, ya que nos puede ayudar a determinar el grado de relevancia de contenidos de unas páginas sobre otras. También nos puede ayudar a saber en qué medida las campañas de atracción de visitas que apuntan a páginas concretas están funcionando. Es conveniente planificar como página de aterrizaje diferentes destinos del sitio web de la revista. Por ejemplo, si se envía un boletín de información donde hay una llamada a la acción con información para autores en una determinada página, es conveniente aprovechar las métricas que nos permiten evaluar su funcionamiento para optimizar su diseño o su contenido.
Es importante también analizar el comportamiento de los usuarios en la página inicial (véase la figura 5) cuando es la página de entrada. En caso de que la página inicial tenga un porcentaje de rebote alto, nos hemos de plantear si podemos mejorar elementos de esta que puedan ayudar a que un mayor número de usuarios naveguen desde ese punto hacia otros contenidos de la revista, citables o no citables. Por ejemplo, nos podríamos preguntar si las etiquetas del menú de navegación son las adecuadas, si tenemos llamadas a la acción en forma de banners claros y atractivos, etc. El porcentaje de rebote en las páginas de destino es una métrica que resulta relevante tomar en cuenta, ya que el diseño de algunas de estas páginas está pensado para invitar a profundizar en otras secciones del web. Un alto rebote implica un posible problema al que debemos prestar atención para adoptar medidas de mejora.
d) Páginas de salida (exit pages)
Este informe nos muestra en qué páginas los usuarios deciden abandonar el sitio. Una vez viendo los resultados, tenemos que hacernos las siguientes preguntas: ¿estas páginas son lo suficientemente convincentes?, ¿el contenido es lo que el usuario esperaba?, ¿debemos reducir los tiempos de carga del sitio?, ¿estamos agregando enlaces suficientes que conecten a las páginas entre sí? En una revista, buena parte de las visitas finalizarán en un artículo concreto y muchas de ellas serán sesiones que habrán visitado únicamente un artículo concreto, por lo que no es fácil interpretar estos informes para los contenidos citables de una revista. Sin embargo, hemos de considerar que, en la lógica de navegación de una revista digital, determinadas páginas informativas o de transacción están pensadas para dar paso a páginas sucesivas si se quiere completar el mensaje o la función. Por ejemplo, para hacer una suscripción a la revista, seguramente el usuario deberá realizar un tránsito por diversas páginas intermedias, por lo que un alto número de salidas en alguna de ellas deberá ser motivo de estudio.
e) Pulsación pasante (clickthrough) hacia páginas clave
La arquitectura del sitio y el diseño de navegación son muy importantes para conseguir visitas de calidad, así como la retención y la conversión del usuario. Por ello necesitamos desarrollar el sitio a partir del estudio de la experiencia de usuario, y una primera fuente de información de base proviene del análisis de la ruta que toman para llegar a los contenidos citables. Si bien la arquitectura de lugares creados con sistemas de gestión de contenidos como OJS está muy definida, hay espacio para la optimización del look and feel del sitio, como por ejemplo las etiquetas de menú que apoyan la navegación o los enlaces y las llamadas a la acción que figuran en cada una de las páginas HTML, o incluso en las PDF.
Ahora bien, cuando nos referimos a navegación del sitio, no solo hablamos del uso que dan los visitantes lectores, sino también aquellos visitantes que buscan información sobre la revista en cuanto que candidatos potenciales para convertirse en autores de esta. La primera impresión que el sitio ofrece a ese usuario potencial autor es fundamental. Google Analytics nos podría ayudar, por ejemplo, a medir el número de autores que se dieron de alta en la revista. Para ello necesitamos conocer el volumen y las características de las visitas que recibieron páginas como la de presentación a los autores sobre el alcance y las características de la publicación o la de instrucciones para enviar manuscritos.
f) Interacción con el contenido mediante seguimiento de eventos
Google Analytics nos brinda facilidades para medir las interacciones con redes sociales o sitios hacia los que enlazamos (outbound links), lo que de alguna forma es un indicador añadido de interés por dichos contenidos. En efecto, el grado de interés e implicación con el contenido se puede llegar a relacionar con la presencia de esos contenidos en redes sociales. Por ello, al margen de la analítica propia que ofrecen los módulos de gestión de perfiles en redes sociales, programas como Google Analytics permiten trazar las interacciones con nuestro contenido que llevan a compartir contenido desde nuestras páginas (figura 13).
Figura 13. Barra para compartir que ofrece OJS. Fuente: Artículo de la revista AOBLL
Para medir cuántos clics hubo en los botones de compartir, deberíamos activar el seguimiento de eventos en Google Analytics, una configuración adicional del código de seguimiento que no se puede hacer al añadir en el conector de Google Analytics en OJS, pero que sí existe en otros sistemas de gestión de contenidos como Drupal. El informe nos dará los datos de los clics que se han producido en los enlaces de compartir con esta funcionalidad (figura 14).
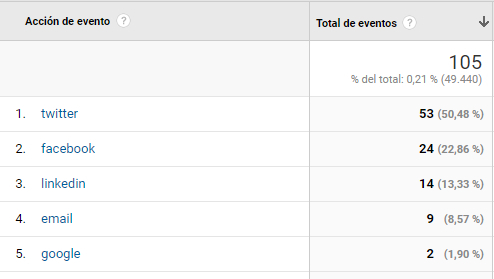
Figura 14. Estadísticas obtenidas gracias al seguimiento de eventos en Google Analytics. Fuente: Cuenta de Google Analytics para BiD
Además, con la creación de eventos podemos saber cuántas descargas hubo de los contenidos citables en PDF desde el botón "Descargar" presentada en la página del artículo. Los eventos son interacciones con elementos de la página que no necesariamente son la carga de una página en sí, puede ser el clic a un botón, la reproducción de un video, etc.
3.4.4 Análisis de la conversión: ¿Hacen aquello que esperamos que hagan?
Las tasas de conversión miden el porcentaje de visitantes que completan una transacción o realizan acciones específicas. Es fundamental que, pese a no disponer de un enfoque comercial, tengamos claro que en una revista de acceso abierto se pueden definir objetivos de conversión. Si bien con las conversiones no se obtendrá un retorno económico como en los sitios web comerciales, se tendrá una repercusión social positiva. El establecimiento de objetivos y metas respecto a su nivel de consecución es fundamental para poder tener una cierta idea de "resultados de explotación".
a) Visita a la página de presentación
Una parte importante de los usuarios que llegan al web de la revista lo hacen sin saber de su existencia. Quizás han seguido el enlace a un artículo a partir de una referencia bibliográfica en otro artículo, un enlace en una red social o en una página de resultados de un buscador, por lo que puede resultar muy relevante saber cuántos acceden posteriormente a visitar esas páginas de presentación de la revista. Sin duda permite aproximarnos al nivel de interés de los usuarios en cuanto a la razón de la existencia del sitio.
b) Suscripciones
Si bien en una revista de acceso abierto se ha de poder acceder a todos los contenidos sin ningún tipo de contraseña, las alertas y otros servicios de valor añadido requieren un registro que viene a ser un buen método de conseguir leads y fidelización. Cuando alguien visita la página para suscribirse y esa visita termina siendo una conversión (cuando proporcionan su correo electrónico), significa que en un futuro ese visitante podrá conocer los nuevos artículos publicados, lo cual representará más consultas y descargas de los artículos. Una forma de mejorar el resultado del número de suscripciones es asegurarnos de que el usuario sepa cómo suscribirse y que haya acceso fácil a esta opción; de ahí la importancia de la analítica de la navegación de las páginas informativas de la revista.
c) Altas de autores
Cuando nos referimos a navegación del sitio, no solo hablamos del uso que dan los visitantes lectores, sino también a aquellos visitantes que buscan información sobre la revista que sean candidatos potenciales para convertirse en autores de esta. Por ejemplo, un programa de seguimiento de las visitas como Google Analytics nos podría ayudar a anticipar la evolución futura de los envíos de manuscritos y su procedencia, partiendo de los datos de navegación de visitas que pasan por las páginas de instrucciones a los autores, entendidas como "microconversiones" que anteceden a envíos de manuscritos para su evaluación, entendida esta acción como "conversión" final plena. Esta conversión se basaría en medir el porcentaje de personas que se suscribieron como autores. El objetivo será incrementar este número constantemente. Esta tasa se puede medir gracias a que en el momento de clicar en el botón para concluir el proceso de registro se visualiza una URL específica que será la que nos ayudará a detectar la conversión.
d) Visitas de más de n páginas
Habremos conseguido uno de nuestros objetivos cuando un usuario supere un umbral de páginas vistas que consideremos se correspondería con una visita intensa, en la que se demuestra un interés del usuario por permanecer en el sitio. La mejor forma de determinar el umbral sería consultar los historiales de las páginas vistas por sesión.
3.5 Hacia un cuadro de mando: medir para monitorizar estratégicamente
Una vez superado un primer periodo de descubrimiento de los usos y usuarios de nuestro sitio web, y de haber avanzado hacia una valoración de conjunto de su desempeño, quizás en forma de una aproximación exploratoria e "impresionista", podemos pensar en algún tipo de cuadro de mando basado en un plan de medición. Un plan de medición permite definir con mayor claridad qué queremos conseguir con el sitio web, ponerlo en relación con los indicadores clave de rendimiento (KPI) y marcarnos unas metas. Para poder elegir los indicadores clave de rendimiento, en cualquier estrategia de analítica web es necesario definir ciertas metas previas.
En primer lugar, se establece la necesidad de partir de objetivos generales del negocio o, en este caso, de la organización sin ánimo de lucro que publica la revista. Se trata de conseguir poner negro sobre blanco objetivos que respondan a las preguntas: ¿qué se pretende conseguir con la revista?, ¿qué necesidades se desean cubrir con la publicación?
Posteriormente, a partir de los planteamientos anteriores, se requiere establecer objetivos del sitio web consistentes con los indicadores clave de rendimiento (KPI). Buscamos que la formulación de los objetivos de la organización sea lo más concisa posible y que se alinee con el precepto de abarcar la razón de ser de la revista en general. Los objetivos del sitio web, en cambio, se focalizan en ser más específicos, pues tienen como función establecer qué queremos que suceda en la interacción de los usuarios con la revista. Los indicadores clave de rendimiento tienen la función de medir día con día el rendimiento del sitio. Programas como Google Analytics ofrecen una gran cantidad de métricas, sin embargo, en nuestro plan de medición, buscamos enfocarnos a aquellas que nos permitan conocer lo suficiente para adoptar medidas de mejora.
Cuando tienen que analizar el desempeño de los sitios de revistas científicas, sus editores suelen prestar atención a métricas de uso básicas como el número de visitas globales, el número de consultas de cada artículo o las citas. Estas métricas pueden ayudar a dar una idea global del alcance del sitio y las publicaciones, sin embargo, no resultan suficientes para extraer conclusiones a partir de las cuales podamos mejorar el web y conseguir lo que la revista persigue. Es necesario medir periódicamente los indicadores clave de rendimiento y perseguir la mejora constante de ellos. Debemos tener claras las razones de por qué queremos aumentar o disminuir los números arrojados. Esto es, estar bien alineados con las metas de nuestro plan de medición, detectar anomalías, deducir por qué son positivas o negativas y tratar de entender al usuario en la medida de lo posible. Al utilizar un cuadro de mando es recomendable analizar la información incluyendo filtros adicionales llamados segmentos, los cuales nos ayudan a identificar en dónde se está presentando cualquiera de los fenómenos que estamos observando en los indicadores clave de rendimiento. Podemos conocer los comportamientos realizados desde un punto geográfico, un dispositivo o una fuente de tráfico específicos. Conociendo estas conductas con un enfoque segmentado, se nos facilitará aplicar de forma óptima las mejoras necesarias. A modo de ejemplo, se presenta un cuadro de mando (figura 15) y un cuadro con los segmentos recomendados (figura 16).
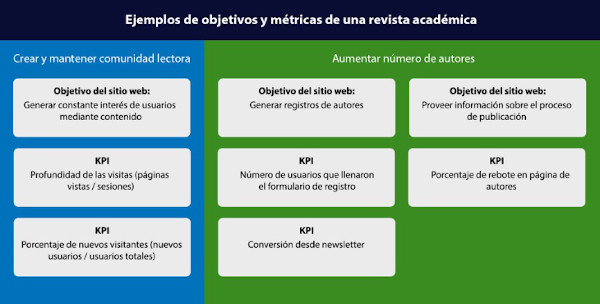
Figura 15. Ejemplo de cuadro de mando donde se definen los objetivos y los indicadores clave de rendimiento (KPI)
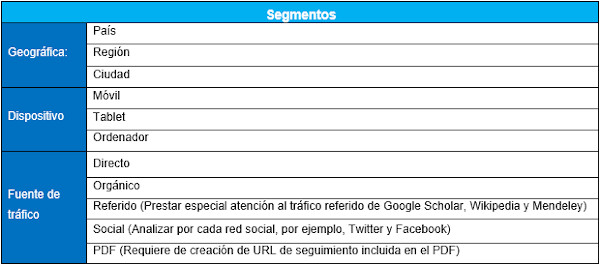
Figura 16. Ejemplo de segmentos posibles
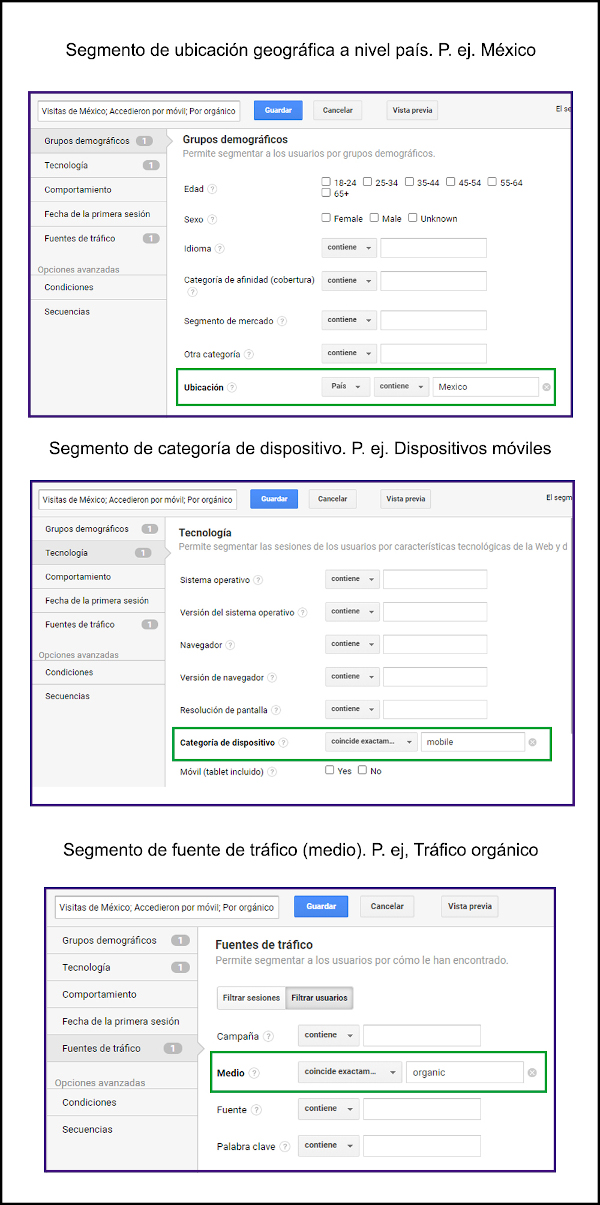
Figura 17. Segmentos geográficos, de dispositivo y de medio. Fuente: Cuenta de Google Analytics para BiD
En la figura 17 hemos visto cómo luce la sección en la que se configuran los segmentos donde se especifican distintos tipos de configuración. En la figura 18 se puede visualizar la gráfica que se genera cuando se aplican los distintos filtros, además de ver la cantidad de usuarios que visitan el sitio, podremos ver las sesiones, el porcentaje de rebote, las páginas por sesión y la duración media por sesión.
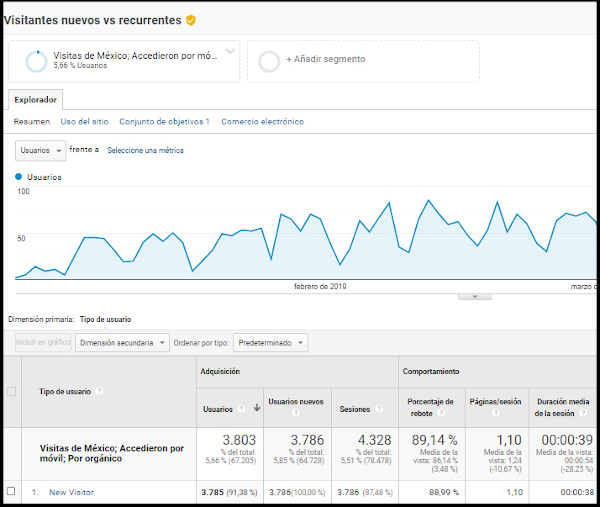
Figura 18. Gráfica que se muestra al aplicar en conjunto los segmentos geográficos, de dispositivo y de medio. Fuente: Cuenta de Google Analytics para BiD
Las segmentaciones geográficas pueden ser analizadas en distintos niveles, podemos conocer desde la ciudad hasta el país desde el que nos visitan. Es importante mencionar que es posible realizar combinaciones de segmentaciones en caso de ser necesario. Por ejemplo, podemos conocer el tráfico proveniente de cierta ciudad que nos haya visitado desde un tipo de dispositivo en particular o que nos haya visitado desde una fuente de tráfico en particular.
El segmento "Dispositivo" presentado en el cuadro de segmentos recomendados nos permitirá discriminar los datos en función de si los usuarios utilizaron para acceder al sitio un móvil, una tableta o un ordenador de escritorio. Conocer esta información es muy útil, ya que nos da una idea del contexto en el que los usuarios leen los contenidos, lo cual nos ayuda a adoptar medidas de optimización de la usabilidad del sitio web pensado en dispositivos específicos.
En la sección "Fuente de tráfico" se puede incluir el tráfico de pago, directo, orgánico, referido, social y PDF. El tráfico de pago es común en sitios web de comercio electrónico o de empresas con fines de lucro, en cambio, no es usual en páginas de revistas científicas, puesto que es raro que sus editores inviertan contratando campañas publicitarias en línea.
Cuando se analiza el tráfico referido es importante prestar atención al tráfico que viene de Google Scholar, pues permite valorar nuestro posicionamiento en dicho buscador especializado en literatura científica. Wikipedia está incluida en esta sección, porque empieza a ser relevante en planes de medición para el caso de revistas científicas: las citas en Wikipedia parecen demostrar un impacto que vale la pena medir pues hay quienes las llaman "las citas del público". Asimismo, se debe contemplar Mendeley, el popular gestor de referencias bibliográficas que permite a los lectores organizar, compartir y descubrir publicaciones científicas. Se puede tomar en consideración tanto el volumen de visitas desde la plataforma Mendeley como el número de lectores que han incorporado artículos de la revista a sus bibliotecas personales en dicho gestor bibliográfico. El volumen de artículos de una revista salvados en Mendeley se considera un indicador de uso cualificado y explícito en el contexto de la comunidad de usuarios de dicha plataforma, en la que junto con investigadores consolidados tienen una gran presencia los investigadores en formación y los estudiantes universitarios de cursos avanzados, lo que permite tener una imagen de la repercusión de los trabajos, alternativa a las citas desde otras revistas (Ortega, 2020; Pooladian; Borrego, 2017).
Para revistas científicas es importante conocer cuánto tráfico proviene de los PDF, ya que en ocasiones los usuarios acceden directamente a los artículos en PDF que son indexados en buscadores. Para ello, se puede agregar una URL de seguimiento para saber cuántos usuarios provienen de estos archivos. Esta URL se puede crear manualmente o mediante la herramienta llamada URL Campaign Builder.
Resulta de suma importancia explotar los datos aplicando distintos segmentos; la información que se obtiene puede ser totalmente diferente dependiendo del filtro (segmento) aplicado. Por ejemplo, los usuarios que visitaron la revista desde México, desde dispositivos móviles y desde tráfico orgánico, pueden tener una tasa de rebote específica, que será diferente si aplicamos filtros distintos; por ejemplo, un segmento que agrupe tráfico de país de habla inglesa, desde ordenadores de sobremesa y desde el medio correo electrónico, puede tener una tasa de rebote totalmente distinta. Las conductas de los lectores de bibliografía académica en distintas zonas del mundo y desde los diversos dispositivos no son uniformes, por lo que una visión sin la suficiente granularidad puede dar una imagen equívoca. Tener diferentes perspectivas nos dará una idea más amplia de lo que sucede en nuestro sitio.
4 Conclusiones
Las métricas, las prioridades analíticas, los indicadores clave de rendimiento que se han comentado en este trabajo pueden resultar útiles para cualquier sitio de revistas científicas, pero siempre se deberá partir del contexto de la revista y de sus objetivos para configurar una pauta interna de analítica web. En todo caso, sea cual sea la configuración de las rutinas de analítica web, hay que destacar la importancia de dotar de coherencia y consistencia al análisis: es necesaria la continuidad en el tiempo y saber que no tiene mucho sentido recopilar los datos si al final no se van a adoptar medidas de mejora. Podemos tener muchos datos y métricas sobre el funcionamiento de una revista, podemos ofrecerlos al conjunto del consejo editorial o de la institución que nos financia, con una vistosa presentación de la información, pero el verdadero reto será la interpretación de esa información en clave de mejora continuada y de evaluación del retorno que aporte a la institución editora.
Cuando hablamos de elementos para una propuesta nos referimos a que no se puede dar una única receta válida para cualquier revista. Las circunstancias de cada comité editorial, de cada editor jefe, de las instituciones editoras, etc., condicionarán qué necesidades de información se tienen y qué uso de la analítica se va a realizar. Ahora bien, en todo caso, para hablar de un planteamiento serio de gestión editorial basada en los datos, se deberán establecer unas rutinas de generación de informes, un inventario de datos y métricas, un listado de destinatarios de esos informes, etc. Esto es, la revista en sus mecanismos de gestión y especialmente en las reuniones anuales deberá integrar esa información de acuerdo a una cierta planificación, con alguien que asuma la responsabilidad de leer los datos para ayudar al equipo a tomar decisiones. Será fundamental estar en una constante búsqueda de buenas prácticas en cuanto a SEO, alertas a los usuarios, ofrecimiento de estadísticas, enlaces entre páginas y redacción de los contenidos. Además, tendrá gran importancia mantener estructurada la forma de analizar, siguiendo el plan de medición basado en objetivos, estrategias, tácticas e indicadores clave de rendimiento.
Con la aplicación de un plan, sea de la dimensión que sea, y con la firme voluntad de detectar necesidades de los visitantes del sitio, se logrará tomar decisiones que aporten valor al contenido y a los servicios de la revista. Teniendo presente esto, y manteniéndose al día en cuanto a funcionalidades de las herramientas de analítica, se abre la puerta al mantenimiento de un sitio web funcional que haga que los visitantes lo visiten reiteradamente y que incluso lo recomienden
Bibliografia
Abadal, E. (2012). Acceso abierto a la ciencia. Barcelona: Editorial UOC. <http://eprints.rclis.org/16863/1/2012-acceso-abierto-epi-uoc-vfinal-autor.pdf>. [Consulta: 05/05/2020].
Allen, H. G.; Stanton, T. R.; Di Pietro, F.; Moseley, G. L. (2013). ";Social media release increases dissemination of original articles in the clinical pain sciences";. PLoS ONE, vol. 8, no. 7.
<https://doi.org/10.1371/journal.pone.0068914>. [Consulta: 05/05/2020].
Borrego, Á. (2014). ";Altmétricas para la evaluación de la investigación y el análisis de necesidades de información";. El profesional de la información, vol. 23, n.o4, p. 352–358. <https://doi.org/10.3145/epi.2014.jul.02>. [Consulta: 05/05/2020].
Bragg, M.; Cahpman, J.; DeRidder, J., Johnston, R.; Kyrillidou, M.; Stedfeld, E. (2015). Best Practices for Google Analytics in Digital Libraries. Digital Library Federation. <https://doi.org/10.17605/OSF.IO/CT8BS>. [Consulta: 05/05/2020].
Codina, L. (2019, junio). ";SEO: Guía de herramientas de análisis y tutoriales de posicionamiento web";. Lluís Codina: comunicación y documentación.
<https://www.lluiscodina.com/periodismo-documentacion-medios/recursos-seo/>. [Consulta: 05/05/2020].
Edgar, B. D.; Willinsky, J. (2010). ";A survey of scholarly journals using Open Journal Systems";. Scholarly and research communication, vol. 1, no. 2. <https://doi.org/10.22230/src.2010v1n2a24>. [Consulta: 05/05/2020].
Eysenbach, G. (2006). ";Citation Advantage of Open Access Articles";. PLOS Biology, vol. 4, no. 5. <https://doi.org/10.1371/journal.pbio.0040157>. [Consulta: 05/05/2020].
Fagan, J. C. (2014). ";The suitability of web analytics key performance indicators in the academic library environment";. The journal of academic librarianship, vol. 40, no. 1, p. 25–34. <https://doi.org/10.1016/j.acalib.2013.06.005>. [Consulta: 05/05/2020].
Fuchs, C.; Sandoval, M. (2013). ";The diamond model of open access publishing: why policy makers, scholars, universities, libraries, labour unions and the publishing world need to take non-commercial, non-profit open access serious";. TripleC: communication, capitalism & critique, vol. 11, no. 2, p. 428–443. <https://doi.org/10.31269/triplec.v11i2.502>. [Consulta: 05/05/2020].
Glänzel, W.;Gorraiz, J. (2015). ";Usage metrics versus altmetrics: confusing terminology?";. Scientometrics, vol. 102, no. 3, p. 2.161–2.164. <https://doi.org/10.1007/s11192-014-1472-7>. [Consulta: 05/05/2020].
Greene, J. W. (2017). ";Developing COUNTER standards to measure the use of open access resources";. Qualitative and quantitative methods in libraries, vol. 6, no. 2, p. 315–320. <http://www.qqml-journal.net/index.php/qqml/article/view/410>. [Consulta: 05/05/2020].
Green, T. (2017a). ";We've failed: pirate black open access is trumping green and gold and we must change our approach";. Learned publishing, vol. 30, no. 4, p. 325–329. <https://doi.org/10.1002/leap.1116>. [Consulta: 05/05/2020].
— (2017b, 24 de octubre). ";It's time for 'pushmi-pullyu' open access: servicing the distinct needs of readers and authors";. LSE impact blog. <http://blogs.lse.ac.uk/impactofsocialsciences/2017/10/24/its-time-for-pushmi-pullyu-open-access-servicing-the-distinct-needs-of-readers-and-authors/>. [Consulta: 05/05/2020].
Harrington, R. (2017, 1 de junio). ";Diamond open access, societies and mission";. The scholarly kitchen.
<https://scholarlykitchen.sspnet.org/2017/06/01/diamond-open-access-societies-mission/>. [Consulta: 05/05/2020].
Holdcombe, A.; Wilson, M. C. (2017, 23 de octubre). ";Fair open access: returning control of scholarly journals to their communities";. LSE impact blog.
<http://blogs.lse.ac.uk/impactofsocialsciences/2017/10/23/fair-open-access-returning-control-of-scholarly-journals-to-their-communities/>. [Consulta: 05/05/2020].
Jansen, B. J. (2009). Understanding user-web interactions via web analytics. Williston: Morgan & Claypool Publishers.
<https://doi.org/10.2200/S00191ED1V01Y200904ICR006>. [Consulta: 05/05/2020].
Kaushik, A. (2010). Analítica Web 2.0: el arte de analizar resultados y la ciencia de centrarse en el cliente. Barcelona: Gestión 2000.
Lawrence, S. (2001). ";Free online availability substantially increases a paper's impact";. Nature, vol. 411, no. 6.837, p. 521–522.
<https://doi.org/10.1038/35079151>. [Consulta: 05/05/2020].
Lewis, C. (2018). ";The open access citation advantage: does it exist and what does it mean for libraries?";. Information technology and libraries, vol. 37, no. 3, p. 50–65. <https://doi.org/10.6017/ital.v37i3.10604>. [Consulta: 05/05/2020].
Lewis, D. (2012). ";The inevitability of open access";. College & research libraries,vol. 73, no. 5, p. 493–506. <https://doi.org/10.5860/crl-299>. [Consulta: 05/05/2020].
OBrien, P.; Arlitsch, K.; Mixter, J.; Wheeler, J.; Sterman, L. B. (2017). ";RAMP: The Repository Analytics and Metrics Portal";. Library Hi Tech, vol. 35, no. 1, p. 144–158. <https://doi.org/10.1108/LHT-11-2016-0122>. [Consulta: 05/05/2020].
Obrien, P.; Arlitsch, K.; Sterman, L.; Mixter, J.; Wheeler, J.; Borda, S. (2016). ";Undercounting file downloads from institutional repositories";. Journal of library administration, vol. 56, no. 7, p. 854–874. <https://doi.org/10.1080/01930826.2016.1216224>. [Consulta: 05/05/2020].
Ortega, J. L. (2020). ";Altmetrics data providers: a meta-analysis review of the coverage of metrics and publications";. El profesional de la información, vol. 29, n.o 1. <https://doi.org/10.3145/epi.2020.ene.07>. [Consulta: 05/05/2020].
Park, M. (2018). ";SEO for an open access scholarly information system to improve user experience";. Information discovery and delivery, vol. 46, no. 2, p. 77–82. <https://doi.org/10.1108/IDD-08-2017-0060>. [Consulta: 05/05/2020].
Piwowar, H.; Priem, J.; Larivière, V.; Alperin, J. P.; Matthias, L.; Norlander, B.; Farley, A.; West, J.; Haustein, S. (2018). ";The state of OA: a large-scale analysis of the prevalence and impact of open access articles";. PeerJ, vol. 6. <https://doi.org/10.7717/peerj.4375>. [Consulta: 05/05/2020].
Piwowar, H.; Priem, J.; Orr, R. (2019). ";The future of OA: a large-scale analysis projecting open access publication and readership";. BioRxiv, preprint no. 795.310. <https://doi.org/10.1101/795310>. [Consulta: 5/5/2020].
Public Knowledge Project [PKP] (s. d.). ";Statistics";. En: PKP administrator guide. PKP Docs website. <https://docs.pkp.sfu.ca/admin-guide/en/statistics>. [Consulta: 05/05/2020].
Pooladian, A.; Borrego, Á. (2017). ";Twenty years of readership of library and information science literature under Mendeley's microscope";. Performance measurement and metrics, vol. 18, no. 1, p. 67–77. <https://doi.org/10.1108/PMM-02-2016-0006>. [Consulta: 05/05/2020].
Pooley, J. (2017, 15 de agosto). ";Scholarly communications shouldn't just be open, but non-profit too";. LSE impact blog.
<http://blogs.lse.ac.uk/impactofsocialsciences/2017/08/15/scholarly-communications-shouldnt-just-be-open-but-non-profit-too/>. [Consulta: 05/05/2020].
Priem, J.; Taraborelli, D.; Groth, P.; Neylon, C. (2010). Altmetrics: a manifesto. <http://altmetrics.org/manifesto/>. [Consulta: 05/05/2020].
Prom, C. J. (2011). ";Using web analytics to improve online access to archival resources";. American archivist, vol. 74, no. 1, p. 158–184. <https://doi.org/10.17723/aarc.74.1.h56018515230417v>. [Consulta: 05/05/2020].
Putnam, L. L. (2009). ";Symbolic capital and academic fields";. Management communication quarterly, vol. 23, no. 1, p. 127–134. <https://doi.org/10.1177/0893318909335420>. [Consulta: 05/05/2020].
Rovira, C.; Guerrero-Solé, F.; Codina, L. (2018). ";Received citations as a main SEO factor of Google Scholar results ranking";. El profesional de la información, vol. 27, n.o3, p. 559–569. <https://doi.org/10.3145/epi.2018.may.09>. [Consulta: 05/05/2020].
Salö, L. (2017). ";Pierre Bourdieu: view points and entry points";. En: The sociolinguistics of academic publishing. Palgrave Macmillan, p. 29–42.
<https://doi.org/10.1007/978-3-319-58940-4_3>. [Consulta: 05/05/2020].
Tananbaum, G. (2013). Article‐Level metrics: a SPARC primer. SPARC. <https://sparcopen.org/wp-content/uploads/2016/01/SPARC-ALM-Primer.pdf>. [Consulta: 05/05/2020].
Taraghi, B.; Grossegger, M.; Ebner, M.; Holzinger, A. (2013). ";Web analytics of user path tracing and a novel algorithm for generating recommendations in Open Journal Systems";. Online information review, vol. 37, no. 5, p. 672–691. <https://doi.org/10.1108/OIR-09-2012-0152>. [Consulta: 05/05/2020].
Urbano, C. (2013). ";Cuenta atrás para las estadísticas de recursos-e: Counter 4";. AnuarioThinkEPI, vol. 7, p. 101–105. <https://recyt.fecyt.es/index.php/ThinkEPI/article/view/30340/0>. [Consulta: 05/05/2020].
Villarroya, A.; Claudio-González, M.; Abadal, E.; Melero, R. (2012). ";Modelos de negocio de las editoriales de revistas científicas: implicaciones para el acceso abierto";. El profesional de la información, vol. 21, n.o2, p. 129–135. <https://doi.org/10.3145/epi.2012.mar.02>. [Consulta: 05/05/2020].
Vitela, A. (2017). Propuesta de mejora de estadísticas del portal de revistas e-RACO. Trabajo final de máster disponible en el Dipòsit Digital de la Universitat de Barcelona. <http://hdl.handle.net/2445/117725>. [Consulta: 05/05/2020].
Watson, A. B. (2007). ";Measuring demand for online articles at the Journal of Vision";. Journal of vision, vol. 7, no. 7, p. 1–3. <https://doi.org/10.1167/7.7.i>. [Consulta: 05/05/2020].
Notes
1 Por otra parte, el presente artículo deriva parcialmente del trabajo final del Máster de Gestión de Contenidos Digitales de la Universitat de Barcelona realizado por Alex Vitela (2017), sobre la gestión de las estadísticas y la analítica en portales gestionados con OJS.
2 El COUNTER Code of Practice surgió como espacio de convergencia entre editores comerciales y bibliotecas para acordar la normalización de las estadísticas de uso de recursos digitales (Urbano, 2013). En el ámbito de la edición en acceso abierto el uso de las métricas COUNTER cuenta con pocos incentivos y muchas complicaciones para su aplicación normativa, por lo que su seguimiento estricto es bajo, aunque está sirviendo como marco de referencia para las definiciones de las métricas de uso. El hecho de que el módulo de estadísticas de OJS integre en sus últimas versiones informes según métricas COUNTER pone de relieve su reconocimiento como marco de referencia métrico más allá de los editores comerciales que ofrecen contenidos bajo suscripción (Greene, 2017).
3 Búsquedas realizadas en WoS, Scopus y Google Scholar el 30/11/2019.
4 Este sería el caso de determinados informes estadísticos que se ofrecen en algunos portales de revistas, como las que se publican con OJS. Como muestra podríamos mencionar los informes de RACO: Revistes Catalanes amb Accés Obert.
 licencia de Creative Commons de tipo «
licencia de Creative Commons de tipo «