
[Versió catalana][Versión castellana]
Alex Vitela Caraveo
Digital Strategist
IBM, Marketing Services Center
Cristóbal Urbano
Professor of the Department of Library Science, Documentation and Audiovisual Communication
University of Barcelona
Abstract
An overview is presented of resources and web analytics strategies useful in setting solutions for capturing usage statistics and assessing audiences for open access academic journals. A set of complementary metrics to citations is contemplated to help journal editors and managers to provide evidence of the performance of the journal as a whole, and of each article in particular, in the web environment. The measurements and indicators selected seek to generate added value for editorial management in order to ensure its sustainability. The proposal is based on three areas: counts of visits and downloads, optimization of the website alongside with campaigns to attract visitors, and preparation of a dashboard for strategic evaluation. It is concluded that, from the creation of web performance measurement plans based on the resources and proposals analysed, journals may be in a better position to plan the data-driven web optimization in order to attract authors and readers and to offer the accountability that the actors involved in the editorial process need to assess their open access business model.
Resum
Panoràmica de recursos i estratègies d’analítica web útils en la configuració de solucions de captació d’estadístiques d’ús i d’avaluació d’audiències en revistes acadèmiques d’accés obert. S’analitzen un conjunt de mètriques complementàries a les citacions per ajudar els editors i gestors de revistes a proveir mostres de l’acompliment de la revista en conjunt i de cada article en particular en l’entorn web. Mitjançant els mesuraments i els indicadors seleccionats es busca generar valor afegit a la gestió editorial per assegurar-ne la sostenibilitat. La proposta es configura al voltant de tres àmbits: recompte de consultes i descàrregues, optimització del lloc web o de les campanyes d’atracció de visites, i elaboració d’un quadre de comandament per a l’avaluació estratègica. Es conclou que, a partir de l’elaboració de plans de mesurament de l’acompliment web, basats en els recursos i propostes analitzades, les revistes poden estar en millors condicions d’abordar amb mostres la millora de la capacitat d’atracció d’autors i lectors, així com facilitar la rendició de comptes als actors implicats en el procés editorial de la publicació en accés obert.
Resumen
Panorámica de recursos y estrategias de analítica web útiles en la configuración de soluciones de captación de estadísticas de uso y de evaluación de audiencias en revistas académicas de acceso abierto. Se contempla un conjunto de métricas complementarias a las citas para ayudar a los editores y gestores de revistas a proveer evidencias del desempeño de la revista en conjunto y de cada artículo en particular en el entorno web. Mediante las mediciones y los indicadores seleccionados se busca generar valor añadido a la gestión editorial para asegurar su sostenibilidad. La propuesta se configura en torno a tres ámbitos: recuento de consultas y descargas, optimización del sitio web o de las campañas de atracción de visitas, y elaboración de un cuadro de mando para la evaluación estratégica. Se concluye que, a partir de la elaboración de planes de medición del desempeño web, basados en los recursos y propuestas analizadas, las revistas pueden estar en mejores condiciones de abordar con evidencias la mejora de la capacidad de atracción de autores y lectores, así como facilitar la rendición de cuentas a los actores implicados en el proceso editorial de la publicación en acceso abierto.
1 Introduction
Research results and academic publications delivered in open access mode are a trend that shows no signs of stopping. In a relatively short time, open access may be the dominant scientific publication model (Lewis, 2012), especially in terms of the volume of use of scientific literature (Piwowar; Priem; Orr, 2019). This will notably improve the functioning of scientific communication, as it increases the use and impact of content (Lawrence, 2001; Eysenbach, 2006; Lewis, 2018) and improves the transparency of research due to free access to information for all the actors involved (Abadal, 2012; Piwowar et al., 2018).
However, these advantages are accompanied by uncertainty about the sustainability of the enormous volume of journals publishing under this model that face a competitive, changing environment in the scientific communication ecosystem (Green, 2017a; 2017b). This is especially relevant for titles that do not charge authors an article processing charge (APC). Some authors call this open access mode “diamond OA” (Harrington, 2017). Others reserve this term for journals that consider they are a public good at the service of open scientific communication, and use licenses that limit commercial use and reuse for profit (Fuchs; Sandoval, 2013). Ultimately, these journals are supported by funding from their mother institutions, sometimes with external sponsorships that subsidize or fully assume the costs of personnel or technological resources. In many cases, they are also supported through unpaid work contributed by academic agents of all kinds.
In this battle for sustainability, open access journals try to diversify their sources of funding and explore new formulas. Above all, they need to retain institutional funding to ensure their sustainability (Villarroya et al., 2012; Holdcombe; Wilson, 2017; Pooley, 2017). However, return on investment analyses are more complex and intangible, as no economic income is generated from article publication charges (APC) or from subscriptions that allow returns to be analysed partially. The return on investments is social, as a public service to support scientific communication. Other returns are in the form of reputation for the publishing entity. Therefore, evidence is needed so that the journal’s performance can be evaluated within the framework of social values and the institutional objectives pursued with the publication.
Many elements should be considered to assess the performance of a publication. However, one vital element is the ability to attract authors and readers. The capture of new audiences, users’ loyalty to the journal’s website and the intensity with which they interact with the publication can all be the subject of standardized metrics. They can be useful indicators for making decisions about whether the social and reputational returns are adequate with respect to what is expected by the institution or the promoters of each journal.
Editors must pay constant attention to the performance of the journal’s website, along with other external bibliometric or altmetric indicators. Ultimately, an open access journal on the internet is a website in itself, or part of a broader website in the form of a portal. Consequently, the analysis of its search engine positioning, justification of the returns of campaigns to attract users, and visit tracking are fundamental requirements for website optimization, as they would be for most websites of any kind.
This study is justified by the need for evidence to optimize websites and improve the user experience, to calculate the return on investment (even if it is a social or reputational return rather than an economic one), and to increase the transparency of visit and download metrics for authors and readers. Therefore, the objective pursued by the study is to identify what added value can be brought to editorial management by an analysis of the use of a journal’s website with web analytics tools such as Google Analytics, and to clarify to what extent this technical approach complements the statistical reports offered by the content management systems (CMS) with which most academic journals are published, or those that can be obtained by analysing the logs of the servers that host the journals.
To carry out the study, we took Google Analytics as a reference because this tool is normally used in all types of websites and among open access journals. However, the proposal that is outlined could be used with any other client-side web analytics tool that uses tracking codes added in the HTML, such as Matomo, Siteimprove or others. The rapid development of open access in the field of scientific journals cannot be understood without considering the spread of free software such as Open Journal Systems (OJS) (Edgar; Willinsky, 2010), which has reduced the time and energy that editors spent on management and editing tasks. Therefore, throughout the study, journals managed with OJS1 have been considered in explorations of why a web analytics strategy should be implemented. However, much of what has been proposed can be applied regardless of the content manager used to manage and publish the journal.
2 The two key areas for evaluating the use of digital journals
Any academic journal that is committed to professional operation must face two challenges relating to the study of its users and the use of its contents: a standardized statistical count of the number of consultations and downloads of each of the articles published, and the evaluation and optimization of its website and the campaigns it carries out to attract users. These are two complementary areas, but they should not be confused: offering a standardized statistic on the use of articles is important but does not cover everything that is intended from web analytics. In addition to integrating the first area related to statistics, an evaluation should respond to what Avinash Kaushik calls Web 2.0 analytics and defines as “the analysis of qualitative and quantitative data from your website and competitors, to drive continuous improvement of the online experience that current and potential clients have and that translates into expected results (online and offline)” (Kaushik, 2010, p. 24). Whether we focus on one key area or the other, the principle that what is not measured cannot be improved is valid. Now, we must consider the difference between measurement and analysis: when something is measured but not analysed, it cannot be improved since analysing implies interpreting the data in a context and in accordance with the mission, the objectives and the raison d’être of the organization.
If we focus on the first area, we have to consider two developments that drive the methodological debate on compiling these data. The first is that publishers and libraries have come together to agree on the measurement of uses of digital collections through the development of the Project COUNTER2. The second is what is known as altmetrics, which offer new metrics for evaluating research that complement traditional ones, in which the impact factor has been of determining relevance to date.
The analysis of the use of journal articles or any other type of research output, mainly through the count of file downloads (PDF, EPUB or other formats) or the visualization of HTML pages, is a data source that must be considered within the set of what are known as altmetrics. These “alternative metrics” exploit data on the use, diffusion or notoriety of scientific publications, as a complement and alternative to the classic bibliometric indicators that are based mainly on the analysis of citations (Priem et al., 2010; Tananbaum, 2013; Borrego, 2014; Glänzel & Gorraiz, 2015). Usage metrics, whether on the journal’s own website or on external content aggregating or access platforms, provide evidence of articles’ performance. This information is increasingly demanded by authors, publishers and research funders.
With some exceptions, most open access journal editors focus on this first key area that we have discussed and on basic metrics such as the number of visits, page views or downloaded articles. These aspects have traditionally been considered in the justification of the editorial project and have been reinforced recently by the altmetrics discourse.
In contrast, the second key area we have referred to is based on a broader vision. It is aimed at improving the website, positioning and promoting website contents, attracting users and retaining them or increasing the number and quality of the manuscripts sent by the authors for consideration. Like any other website, a journal must set “conversion objectives” (what you want users to do within the website), and goals in terms of certain key indicators that can be achieved if the website features are tailored to users’ behaviour and needs.
In this second area, web analytics are just one more instrument, in addition to all kinds of qualitative evaluations, user tests and opinion surveys, to find out whether the journal fulfils its raison d’être, whether it is progressing and whether its existence is justified by data on its use, impact or the assessment of the academic community to which it is addressed. Furthermore, all websites must analyse the user experience and user needs that are at the centre of their continuous improvement. A digital journal is no exception.
There are very few references in the literature that correspond to this second key area. A bibliographic search on web analytics for scientific journals, in which we used the terms “web analytics” or “digital analytics” and “scientific journals” with their equivalents in other languages and with other related terms, returned an insignificant number of papers3. Generally, the papers that were found do not centrally raise conceptual and methodological aspects for this type of publication. They are mainly dedicated to showing the usage and download data of a specific journal (e.g. Watson, 2007) or explaining a functionality based on analytics data (e.g. an article recommendation system in Taraghi et al., 2013). They do not adopt a holistic approach to fully considered website analytics that could serve as a methodological guideline.
For this reason, in the search for references in the literature, we broadened the focus to websites that share characteristics with open access publications, such as those that offer scientific or cultural content and operate as non-profit entities (including libraries, portals of information resources, museums, archives, etc.). For this type of website, there are numerous studies from which good practices and an analysis of valid technical solutions can be obtained in the framework of scientific journals (e.g. Jansen, 2009; Fagan, 2014; Bragg et al., 2015; Prom, 2011). At the same time, it is useful to be informed about good practices and methodological concepts of analytics for business or service websites whose purpose is transactional or customer support. As Fagan (2014) says, the idea is to transfer concepts from the commercial web to libraries: “Web analytics have long been used by the commercial sector for studying online user behaviour and determining quickly how effective their virtual spaces are at achieving business goals” (p. 25). Thus, the first challenge for an open access journal will be to determine how to translate the concept of “business goals” into its non-profit model that is aligned with a scientific society, university or research institution.
Just because it is difficult to assess, we should not overlook the performance of a website that generates no income from the sale of advertising or payment for access to content. Ultimately, an increase in users and visits is still an objective that is designed to reduce the cost per visit or to retain users as a means of increasing the reputation of the journal and the publishing institution. In this user experience, it is as important to study the general reading public as the author, who would be the equivalent of a client in commercial websites. We could say that authors are the main target audience of an open access journal in terms of what Bourdieu calls “symbolic capital”. This is defined as the editorial prestige that conditions the lives of academics (Putnam, 2009; Salö, 2017), since a journal expects to receive manuscripts for publication and citations from them.
3 Elements of a comprehensive web analytics project
Based on an exploration of the potential and requirements of web analytics in journal management, this section proposes elements that editors should consider. The proposal aims to analyse the usefulness and feasibility of adapting certain web analytics practices that are generally defined for e-commerce websites, lead generation websites or content with marketing objectives to a context of open access scientific journals that do not charge authors for publishing. In such journals, it is not so easy to define what is meant by “conversion”; a term that in the web world means all interactions with the content that end with an action that a user wants to do, such as a make a purchase or fill in a form.
Applying web analytics to academic journals also entails focusing on pages that are not articles. Although these pages do not include scientific content, their usage is a holistic indicator of the journal’s performance, which is very relevant when most open access journal articles are published under licenses that allow redistribution of their content in institutional repositories, in journal aggregator portals or in academic social networks. It is understood that data on visits to the website that articles originally come from can be key to assessing the performance and positioning of the publication, which is conceived as an editorial entity that is more than a sum of articles.
In the world of scientific literature, the priority is often to analyse the performance of citable content, rather than other pages that in many cases lead to it. We need a broader approach if we really want to properly practice what we have defined as web analytics for a journal. Some authors classify pages without citable content as ancillary pages, whose analysis has limited value (O’Brien et al., 2017). However, the thesis of our work is that the circulation of visitors on these pages and their relationship with the downloading of citable content or with certain interactions, such as the number of manuscripts sent or journal alert subscriptions, are very important for the evaluation and improvement of the journal’s web presence. Given this perspective, in this article we refer to pages without citable content as informational pages rather than ancillary pages. We call pages that include downloadable or citable items “pages with citable content”.
In this proposal, we want to show a varied, open range of possibilities, so that each journal can decide its measurement and analysis priorities based on its evaluation and improvement objectives. The starting point for the proposal is the need to justify and organize the analytics project, to then focus on the main metrics and indicators involved in the four usual blocks of analysis of any project: analysis of the audience, acquisition, behaviour and conversion.
3.1 Need, context and organization of the project
Any web analytics project should be based on clear identification of stakeholders, definition of the website’s main objectives and determination of key performance indicators. At first, the best approach to this type of project is gradualist. Basic and core aspects of the analysis should be prioritized without getting lost in the forest of reports and metrics that can be obtained. However, the normal pattern is to evolve towards more elaborate planning. In both cases, we must have a clear idea of why and for whom we are carrying out the analysis. This will help to determine the tools that are used, the data we need to obtain and how to exploit it, and the people responsible for these tasks.
To get the most out of web analytics, someone in the journal (or in the portal that hosts it) must be responsible for analysing and interpreting the data that is collected. This person must be clear about some basic aspects of the technological infrastructure and web architecture that make the digital operation of the journal possible, and they must also know the objectives and rationale of the publication. If required, they must have the technical support of the person who is responsible for configuring and maintaining the technological solution for capturing the data to be analysed. Finally, it is crucial to establish what information to offer and to whom. For this reason, the way the data is presented and interpreted will be key, as it is associated with who will use the “intelligence” generated by the analytics project and its utility in decision-making.
In short, beyond browsing the attractive statistical reports and data visualization offered by a tool like Google Analytics or its equivalents, a plan is required to determine the scope and real use and organization of the data that we hope to obtain. In this aspect, we must determine “who” (who will do the work), “for whom” (the recipients of the acquired intelligence) and “when” (with what regularity or in what situations the analysis must be carried out). In the web analytics strategy, it will be of utmost importance to focus on which measures to make according to the reports that are obtained, and not get lost in a sea of data. Once these actions have been taken, the results must be monitored to find out if new decisions need to be made.
3.2 Choice of web analytics tools
There are several technical options for obtaining data on visits and user interaction with content. They can be summarized in two types of tools: server-side and client-side. Each type has strengths and weaknesses. As we will see, the most complete solution would involve the complementarity of both types of tools. Moreover, the availability and viability of each solution will depend on the technical capacity of the journal or the catalogue of services offered by the portal where it is hosted. Let us examine the technical foundations of each type.
Each interaction of users with the website can be recorded as a file request (hit) in the log file of the server where the journal is hosted. In these file requests, information such as the user’s IP, the time, the name of the requested file and the reference URL from which the file is requested is stored, among other data. Server-side analytics tools are those that exploit server logs, but their use requires the technical assistance of the server administrators. The log files must be conveniently located and preserved, so that they can generate statistical reports using analytics tools such as log file analysers (for example AWStats). For various reasons, these solutions are used less and less. Data on the server side is also the source used by some ad hoc software developed especially for journal portals or fed by the statistics plug-ins integrated into the content management system used to manage the journal, as is the case with the COUNTER reports from the OJS Public Knowledge Project4. In both cases, a sustainable approach is required to capture, preserve, purify and anonymize the data collected in a log file. These analytics tools allow you to count files of all kinds requested from the server (and PDF files or other formats), even if they have been reached without going through the HTML page navigation structure (as happens when Google Scholar accesses a journal’s PDF directly, without it being framed on a web page).
In client-side solutions, of which Google Analytics represents the paradigm due to its high level of use on all types of websites, the user’s journey through the journal’s website is traced by activating a tracking tag embedded in a JavaScript code every time a web page is loaded or an event occurs from a page (such as clicking on a link to a PDF). In other words, the actual web traffic data is captured from the user’s browser, thus excluding the traffic of robots. When the browser reads the JavaScript code embedded in the web pages, it will send data from the file request of each page to the service provider’s servers and will associate them with the anonymous and permanent cookie that the provider places in the browser for identification as a unique user. These tracking codes are only present in HTML pages. Therefore, access to a PDF article could only be measured if the user visited it from a web page. This limits the measurement of queries, because if the user visits an article in this format directly from Google Scholar or some other general web search engine, this traffic to the PDF file will not be traced by any software on the client side (Obrien et al., 2016).
This type of software provides a high level of granularity in the treatment of the data and great versatility in the configuration of visualization reports. This means that very useful data can be gathered on visitors’ behaviour, with a level of detail that cannot be achieved in most of the server-side solutions that are commonly used. We can identify indicators that represent the performance of the site, compare any type of chronological interval and segment the information by a multitude of cross characteristics of visits or users.
Google Analytics is a free service that can be used to outsource the collection, storage, exploitation and visualization of users’ browsing data. Beyond creating an account and tagging the web pages that you want to trace, it does not require any installation. There is a paid version of Google Analytics and other commercial providers that offer this type of services, such as Adobe Analytics or Matomo Cloud. If we want to have a client-side solution that controls the data on our servers, we can use free software such as Matomo On-Premise, which offers data exploitation and visualization similar to Google Analytics but requires our own computing resources to install the software and store the data to be exploited. Choosing one of the externalizable options, such as the free version of Google Analytics, is the most common solution when the journal does not have technological infrastructure.
The data a client-side analytics tool can provide gives a very complete idea about the interactions of users with informational pages (not citable) but only a partial idea of queries on the citable content in its different formats. Therefore, together with a detailed analysis of the interaction with the website offered by a client-side solution, it will always be necessary in the case of journals with non-HTML citable content to obtain the information from a statistics connector or a log file analyser to determine precisely, regardless of origin, the queries to quotable content in PDF, EPUB or equivalent format. In addition, data from the analytics provider on the client side would help us to determine the interactions with HTML content, whether they are information pages or citable content located by browsing the journal’s website.
This complementarity is considered by most content management systems, which facilitate the configuration of Google Analytics through a connector that drastically simplifies the task of adding the tracking code to all journal pages. OJS has this option, so the Public Knowledge Project (PKP) recognizes the value that these third-party services have in terms of overall site management. They complement the robustness of download tracking of articles by exploiting logs or the internal statistics of the content management system.
3.3 Time windows and key performance indicators (KPIs) for trend analysis
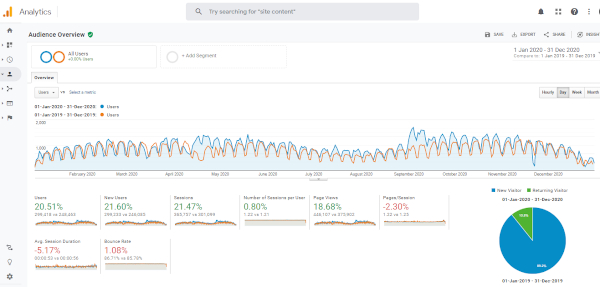
The absolute figures of the metrics offered by an analytics tool should be taken as an approximation, since for various reasons the data that are collected never reflect the reality one hundred percent. However, the relative values, ratios and variations of these indicators (that are consistently obtained over time) are more robust and can help us in decision-making and in evaluating the journal’s performance. Internal comparison of the website over time, for example by comparing consecutive years (Figure 1) interpreted in light of the editorial management that has been carried out in each period, is true operational knowledge that can help make a difference.
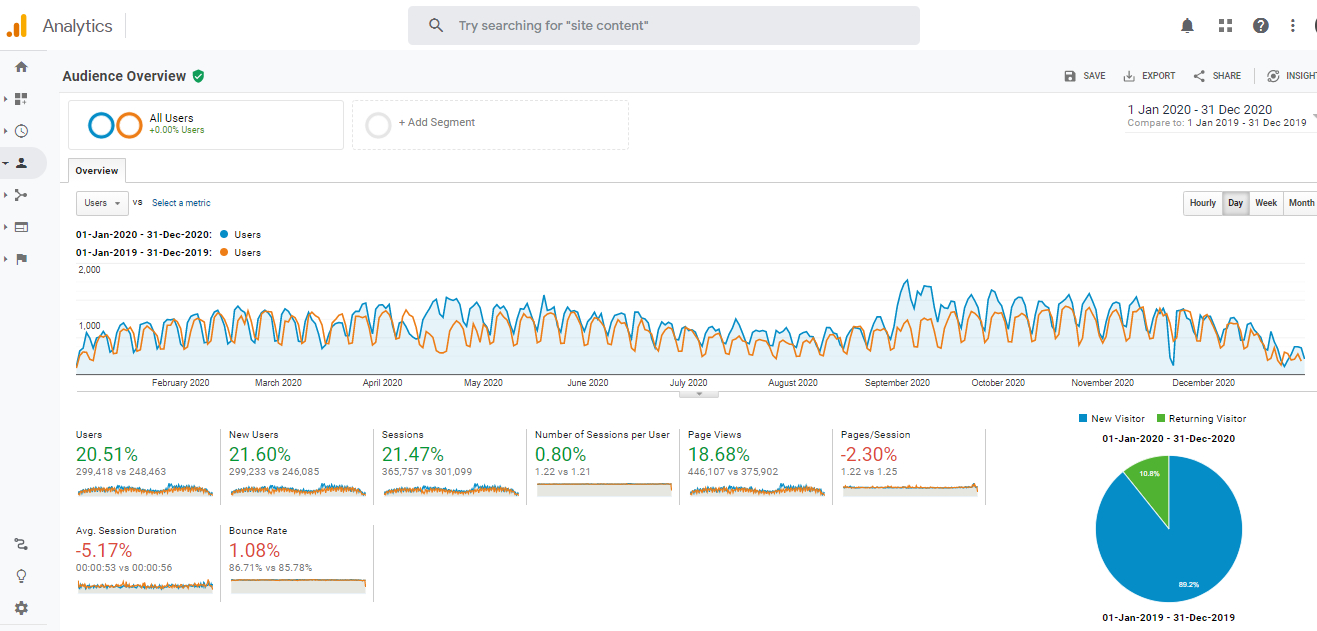
Figure 1. Overview of the audience of the BiD journal for 2020 compared to 2019. Source: Google Analytics account for BiD
The value of analytical information lies in the indicators and especially in the key performance indicators (KPI). Basic metrics by themselves are of little use without a context that allows us to interpret the evolution as a percentage of variation or proximity to a goal set in advance. In other words, the “when” of analysis is often linked to the “what” and the “why”. For example, we can compare a period in which the last call for papers was launched with the immediately previous launch period or with a period without a call for papers and analyse its impact. If a journal decides to internationalize and begins to publish content in English, we could compare the before and after, analyse the data and interpret it to determine whether the change was significantly beneficial or not.
3.4 Scope of analysis
Given that the proposal is focused mainly on usage reports obtained with Google Analytics, we must warn of the enormous range of metrics and reports that can be obtained under the various display boards of the analytics tool. Furthermore, each of these can give rise to many presentations with more specific information, due to the combinations of dimensions and segments that the tool offers as standard or those that the user can configure. Such a range of views and data could overwhelm any observer. Therefore, in this proposal we have selected some specific analyses from the many possible ones, and we have grouped them by area (Figure 2) with the metrics selected for each of them. This is a selection of reports that can be applied to open access academic journals, assuming that the use of data must be prioritized beyond mere statistical curiosity. It makes no sense to spend time and effort on data that does not serve the purpose of the web analytics project.

Figure 2. Areas of web analytics in scientific journals
In any case, it should be remembered that the data offered by web analytics tools help to formulate hypotheses about when a certain evolution of the website takes place or, more specifically, why users do not react as expected to the navigation design or the calls to action (CTA). To get a more accurate answer to questions about a journal’s functioning, we should not neglect other ways of capturing the voice of readers, authors, reviewers, editors and other actors who are involved. The Google Analytics reports by themselves do not give us the definitive answer to why users behave in certain ways. To obtain this information, surveys, interviews or other qualitative research methods are required.
3.4.1 Audience analysis: who visited us and with what intensity or quality?
In principle, the most normal configuration of an analytics tool like Google Analytics for an open access journal is to trace the traffic received anonymously but identify unique users through persistent cookies. As we have already said, ethical aspects and the preservation of privacy are relevant issues and should be considered when the configuration of client-side analytics software is established. The degree of access to data from the users’ profile depends on the configurations referred to in Section 3.2. In any case, with no greater problem than the good practice of notifying users of the use of anonymous cookies for the statistical analysis of the website, this type of software allows us to generate interesting reports on our audience. Some aspects are highlighted below.
a) Volume of visits and users
Visits, also called sessions, are all consecutive interactions with the pages of a website in which the time between loading one page and the next does not exceed the maximum time for the delimitation of sessions, which is usually set at thirty minutes. Visits are traced from the information sent by web browsers that are supposed to be used by real users. The same person can generate several visits on the same day for various reasons. For example, you may have accessed the same web page twice from the same browser on a desktop computer, at intervals greater than the time set as the limit for defining sessions. You may then have used another browser on the same computer, a tablet and finally a mobile phone. This will count as five visits from four users (as the software identifies the user as a browser with a specific cookie). The platform detects that there are four of the same users using four browsers and identifies as two visits by a user those visits that were made with the same desktop computer browser. That is, the user count corresponds to the number of unique browsers identified with the ID of the cookie deposited by the analytics software the first time a website is visited, which functions as an identifier for the web client. Unlike what happens in visits, if the person accesses the website again from the same browser, the platform will consider that it is a repeat user within the time frame that we apply to the reports. As can be seen in Figure 3, Google Analytics remembers that the user who performed four sessions on 20 December 2019 entered for the first time with that cookie on 12 December 2019. In the terms of web analytics, user is closest to the colloquial concept of visitor person. However, the terms are not one hundred percent synonymous, since the same person can visit us from different browsers or devices and will count as different users.
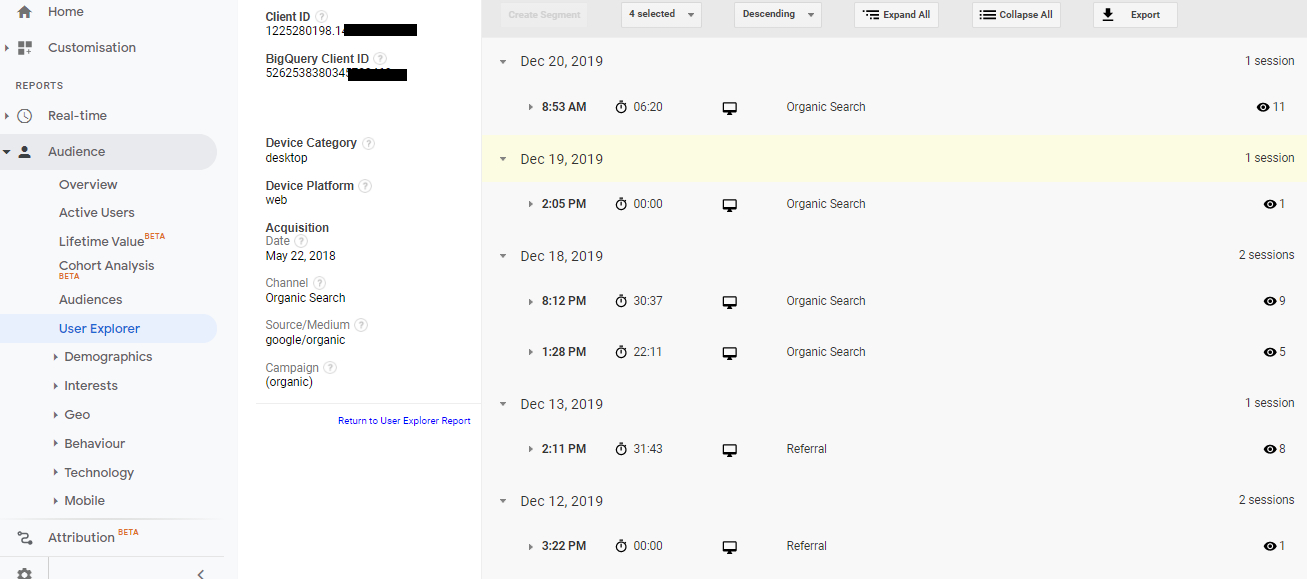
Figure 3. Analysis of the sessions of the same user identified with a cookie on a specific day through the “User exploration” report. Source: Google Analytics account for BiD
b) Bounce rate
The bounce rate is a metric that reports the relative number of visits in which the user only requested one page through which they entered the journal’s website (known as a landing page), without any further action. If the landing page corresponds to non-citable informative content, and the bounce is high, the congruence of the content and the navigation from that page should be analysed in relation to what we expect from users at that point in the web architecture.
If the landing page corresponds to an article, we will be able to assess how much its content caught the user’s attention. We will also be able to evaluate the navigation system’s ability to attract navigation to related content, or to display content that guides the new visitor in the landing page that contains the article that they are seeing for the first time.
Bounce is one of the few metrics for which it is generally better to decrease the percentage than to increase it. If we notice that the journal’s bounce rate has increased compared to a previous period and that this increase occurs in various traffic acquisition channels, we should consider that some of the changes we have made have had a negative effect or that the contents we are offering are not as interesting to the public as before.
c) Interaction: number of pages per visit and session duration
In addition to the bounce rate, these metrics reveal the inclination of users to continue browsing a site. Navigation beyond consultation of an individual article can be an indicator of good or bad functioning of the article recommendation system offered by the journal, for example, based on patterns of reader activity (Taraghi et al., 2013), proximity to the keywords or the bibliographic overlap with other articles. One objective of every journal is for the website to invite the user to continue viewing more articles or to learn how the publication process works. Therefore, a reduction in the bounce rate and an increase in sessions of more than 180 seconds should be the logical result of all these improvements in navigation, the internal hypertextuality of the writing, or the design of calls to action (CTA). Reports such as that in Figure 4 will allow this monitoring to be carried out, delimiting specific dates that may be significant to the improvements.
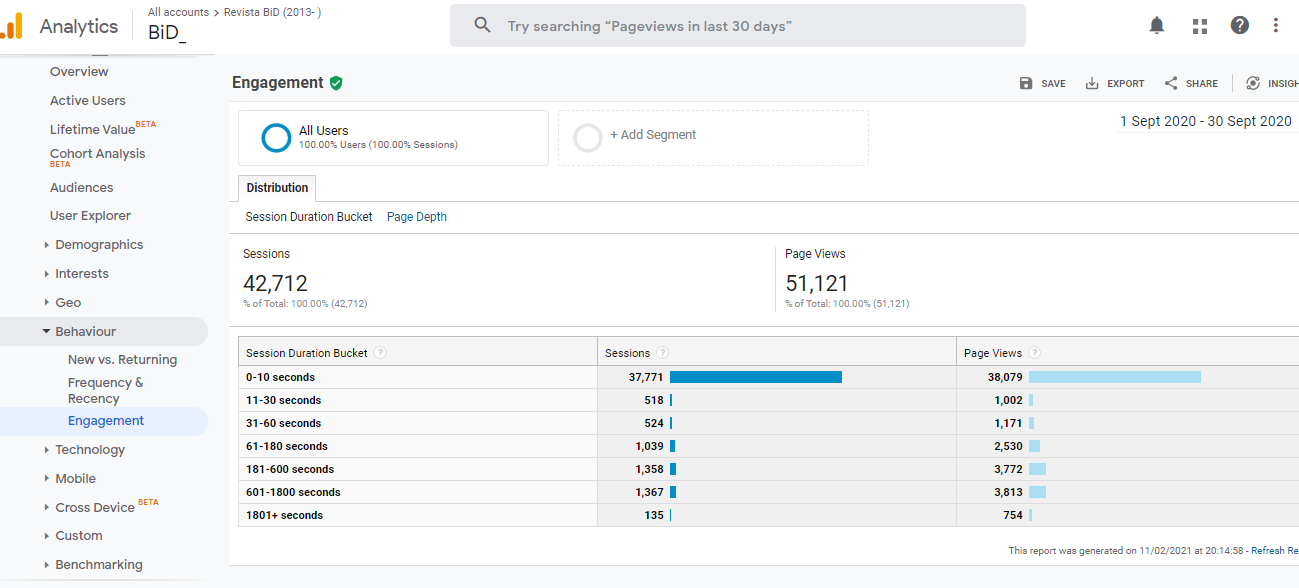
Figure 4. Analysis of sessions by ranges of their duration for September 2020. Source: Google Analytics account for BiD
However, a single report is often not sufficient to determine the problems or the performance that an improvement in the journal may have had. Thus, general reports of the audience with the bounce rate or the session duration should be studied in a very granular way, for example, by considering all the visits that access the journal through a page with a clear navigation goal, such as the home page. Figure 5 shows that the “Behaviour” report group can be used to determine the bounce rate and the session duration when users start their navigation on a specific landing page. Their behaviour is differentiated by the user journey, that is, whether they typed the URL directly to access the website or they came from a search engine, a link from an external website or social media.
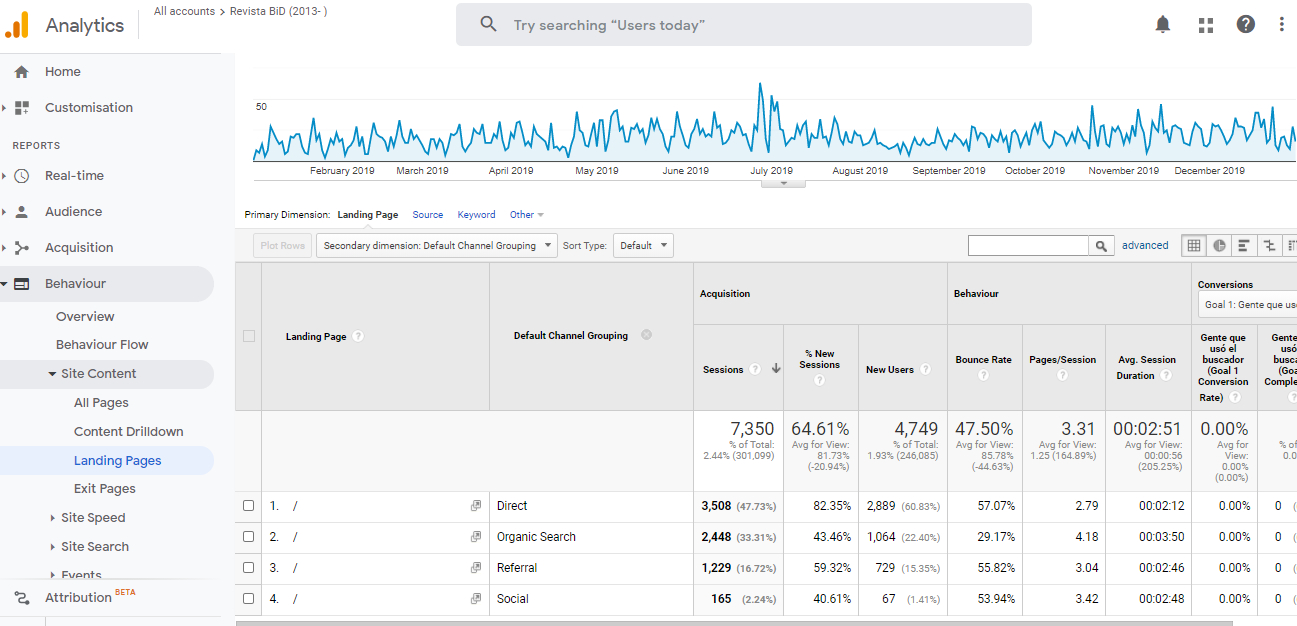
Figure 5. Analysis of the performance of the homepage of the BiD journal as a landing page during 2019. Source: Google Analytics account for BiD
Beyond the metrics that inform us of the depth and quality of visits, the analytics tool will help us to map the user journey and identify what is most interesting to them. The navigation time shown by the tool may not be accurate, since sometimes users leave their browser open without any activity, which will cause Google Analytics to statistically consider the end of the session. Despite this, recent periods of time should be compared with previous periods to see if there is an improvement.
d) Recurring users
Measuring recurring users who access the journal more than once in a given period and the intensity in the repetition of their visits will help us to capture customer loyalty, that is, the degree of loyalty generated by our website. This information will give us an idea of the intensity with which the journal was positioned in the mind of the reader. If the experience was good, they will likely return. It is important to constantly publish new content to maintain readers’ interest. Sending information newsletters from a database of registered users can help to achieve this. The effectiveness of these actions can be measured by reports on user recurrence.
e) Geographic distribution
The data display by countries and cities allows us to reflect on the scope of the contents at global and local level. The geographical distribution of users provides very valuable information for a journal, since the comparison of data can lead us to formulate explanatory hypotheses that help discover keys like internationalization. By segmenting the data obtained in any of the hundreds of reports that Google Analytics offers by zones, we can gain a very powerful granular view of how traffic is evolving. This is especially necessary if the journal or some of its contents are aimed at certain geographically defined target audiences. The ability of tools such as Google Analytics to go into city-level detail (Figure 6) and compare the quality of visits based on the time evolution and the source of traffic can help us discover positive situations that occur in users who come from a certain locality and through a certain link, for example. This information could be extrapolated to other geographic areas.
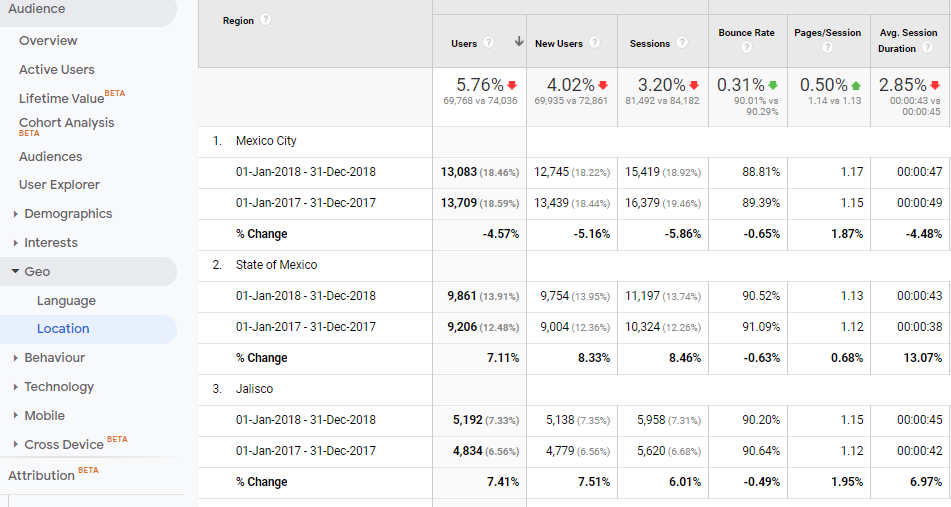
Figure 6. Analysis by cities of the decrease in visits from Mexico in 2018 to the BiD journal. Source: Google Analytics account for BiD
Likewise, we can use this level of granularity by cities to better identify a decrease in visits from a relevant country among our audience. For example, as can be seen, in 2018 the BiD journal had a 3.2 % decrease in visits received from Mexico (Figure 6), which could be explained almost entirely by the decrease observed in Mexico City (-5.86 %), so perhaps more localized promotional solutions could be sought.
f) Internet access providers (IAP)
We can segment visits by whether they are through commercial or institutional access providers. Among institutional access providers, we can identify visits from universities, research centres or public administrations linked to the scientific and academic world. Analysing the interest generated by the content in certain universities and segmenting this information according to the reference URL through which the content was reached can help to discover prescription actions of the articles or of the journal.
g) Device category
Analysing which devices visits come from helps us to determine whether the use of the journal corresponds to the global growth trend in the use of mobile devices to navigate online content. If usage on mobiles and tablets is low, it may mean that the users’ experience of the site is not positive. This could be because the site’s design does not adapt to screen size or the elements that help users to navigate are not easily displayed.
In these cases, responsive design should be implemented. This means that a single website has the same code for desktop computers and mobile devices, but the elements are displayed differently. Another option is to create a mobile version of the site in which the code is different. In other words, from its root (HTML code) the sizes and distribution of the elements are different for the mobile version and the desktop version. This option is not recommended for journal web positioning purposes, since it implies that there are different sites with different URLs, a factor that can affect the ranking of the journal in search engines.
3.4.2 Acquisition analysis: how is our website discovered or reached?
Knowledge of the action that brought a user to our journal is essential to plan strategies to attract readers. Through the referrer field of logs and the labelling of links to our journal in emails or on social networks, we can get an idea of the distribution of the visits that are received from certain channels. Visits may come from different sources: the results of a query in a search engine such as Google (“Organic Search” channel); direct access by entering the requested URL in a browser’s address bar (“Direct” channel); a click on a link on any other website that is neither a search engine nor a social network, for example a bibliographic database such as Dialnet (“Referral” channel); a click on a link in a Twitter post (“Social” channel); or a link in newsletter emails sent to subscribers (“Email” channel), among others. In the BiD journal (Figure 7), the organic channel and specifically Google are important in attracting visits. By configuring this report to compare chronological ranges, we can detect a problem. In this case, a significant decrease in visits from Google coincided with changes in the search engine’s indexing policy, to which the journal is gradually adapting.
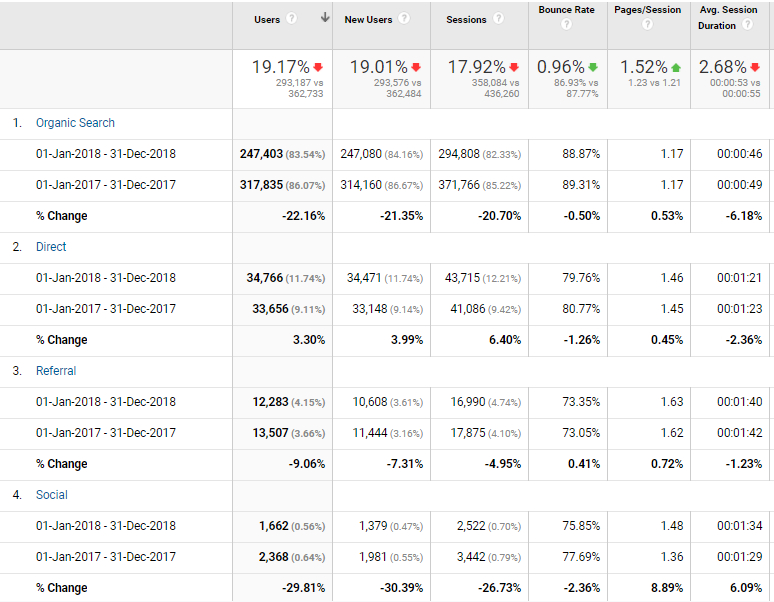
Figure 7. Example of user distribution according to the acquisition channel of the visits to the BiD journal in 2018 compared to 2017. Source: Google Analytics account for BiD
a) Organic traffic
In web analytics, “organic traffic” refers to visits that land on a website from a page of natural results in a search engine, that is, clicks on links that are not paid ads. For the vast majority of websites, this is the most important source of traffic, so improving and monitoring web positioning, also called search engine optimization (SEO), is a key routine for a digital journal. To measure organic performance, data is required on the volume and quality of traffic from search engines. As far as possible, it is also important to know what keywords and queries these visits are associated with. Optimizing the pages of scientific journals from an SEO perspective (Park, 2018) increases the chances that users will visit the site more, download more articles or even cite them. Using the information provided by web analytics, we can make a first diagnosis of the positioning. Above all, it will help us to evaluate the result of the actions taken.
When the keywords that users put in search engines to access the journal’s site are analysed, we find that Google Analytics does not provide all these search terms by default, since a large percentage of them are classified as “not provided”. The reason for this limitation is that, for user privacy reasons, Google Analytics does not collect this information when the person using the search engine has logged into a Google account. Consequently, the website’s Google Analytics account should be linked with the Google Search Console service (Figure 8) to obtain more complete information about the number of times a certain article has appeared in Google search results, its average position, the Clicks generated or keywords in searches that caused the journal content to be displayed in the search engine results page. Although some data from Search Console can be integrated into Google Analytics (Figure 8), for a more in-depth analysis the reports have to be accessed directly in the service’s interface (Figure 9).
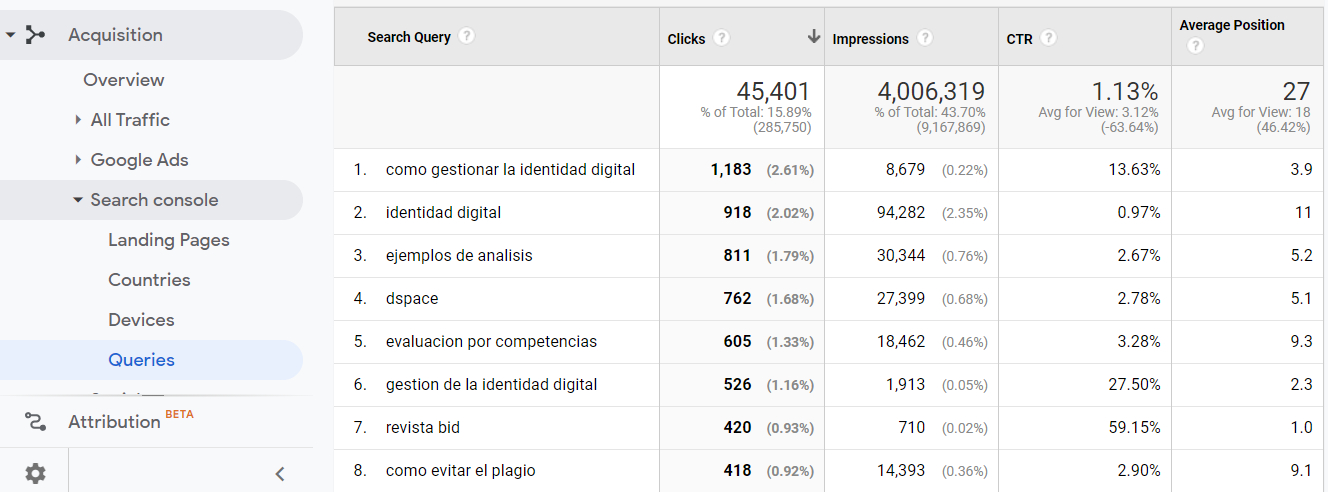
Figure 8. Report of queries in Google resulting from the integration of Google Analytics with Google Search Console. Source: Google Analytics account for BiD
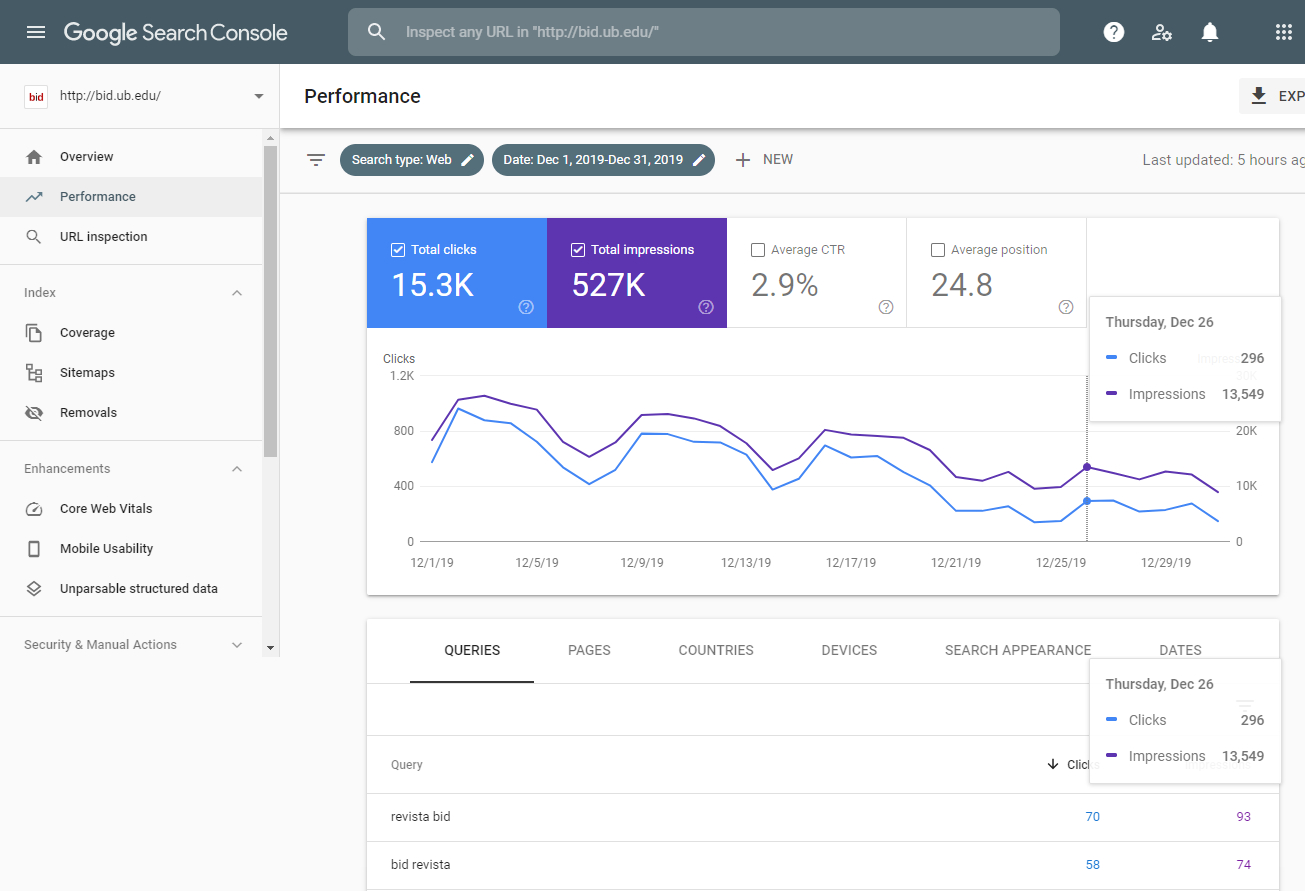
Figure 9. Google Search Console full report with the performance of BiD journal’s ranking in Google searches. Source: Google Analytics account for BiD
To optimize search engine positioning, there are good practice guides in SEO areas known as on-site and off-site (Codina, 2019). On-site factors are related to optimizations carried out within the journal’s own site, such as the length of texts, the keywords used and the page load time. Off-site factors are more closely related to the volume and quality of websites that have hyperlinks that point to the journal and to the repercussion and influence of the journal in social networks.
In terms of traffic from search engines, we might think that Google Scholar is classified as organic traffic in Google Analytics. This is not the case as it is considered referral traffic. This point will be explained in more detail in the following section. However, from the perspective of SEO work, it is pertinent to jointly analyse how to gain a good rank in general and academic search engines. While inbound links largely determine the PageRank of pages in Google Search (e.g. the general search engine Google.com), the citations received are the main ranking factor in the ordering of Google Scholar results. Some factors are similar in Google Search and Google Scholar, such as the relevance of content, the citations or links received, the reputation of the author and the reputation of the publication or domain. However, since they are different tools, journals should consider the specificities of each of them (Rovira; Guerrero-Solé; Codina, 2018).
b) Referral traffic
Referral traffic can be consulted to determine from which websites users reach the journal. Google Analytics reports provide data on which URLs were activated to reach citable content and information pages. A large volume of referral traffic can improve ranking in the search engine results page.
In addition to Google Analytics and Google Search Console, platforms such as SEMRush or BrightEdge, among others, can give us a perspective of the inventory of inbound links to our site. Web analytics tools are important to constantly search for the best links to our website, an activity known as link building.
When we analyse data from scientific journals in a web analytics tool such as Google Analytics, Google Scholar may be present in the referral traffic, since in this search engine there are links to articles in different possible formats, including HTML pages of citable contents. However, clicks on Google Scholar pages that lead directly to the journal’s PDF will not be traced.
c) Social traffic
Our presence in social networks can help to generate an echo on the web. Without a doubt, it can be a good way to attract visitors, for example by posting new articles that are published. It also gives a voice to a journal in the digital conversation that can take place on certain topics, on which the journal can contribute by mentioning articles published in the past, which can be refreshed if they go viral in the discussion. It is important that the link to be placed in the article is communicated in DOI format, since this ensures traceability in the altmetric tools of services such as PlumX or Altmetrics.com. To facilitate the presence of journal articles on social networks, the “Share” option should be at the top of the article and the bottom, which is where users go when they finish reading the text. Content management systems like OJS provide the option to add free plugins with this feature. In any case, knowing the statistics of the traffic that is generated in each social network (Figure 10) can help focus the effort of the journal’s community manager and assess whether the activity that was carried out in a given period responds to the expectations generated by this effort.
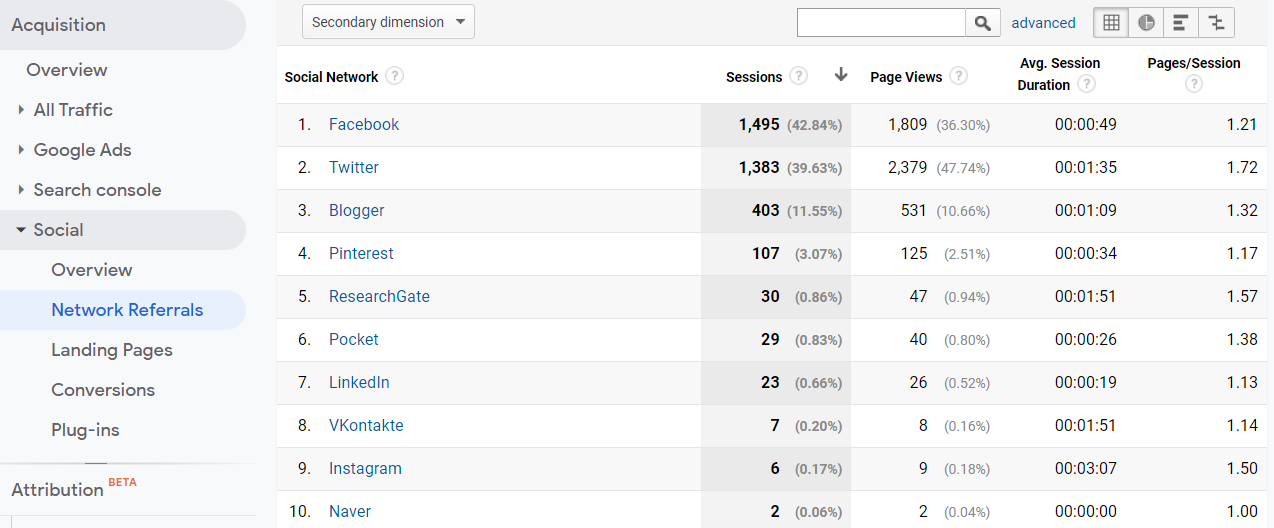
Figure 10. Distribution of visits to BiD according to the social network of origin during the first half of 2019. Source: Google Analytics account for BiD
d) Newsletter campaigns
A basic task for keeping a community of readers and authors active and loyal is the action of sending newsletters. Giving visibility to new posts of articles in these emails takes advantage of the database of users who previously provided us with their email address. These email campaigns (as they are known in marketing) will help us drive traffic to the journal’s original website. Although the articles may be present in repositories or other portals, these do not provide information for authors. Consequently, it is beneficial to attract users to the journal’s website and thus promote more complete interaction than the simple individual reading of articles.
Journals that use OJS can implement the announcements functionality to notify users of the publication of new journal content. In the OJS 3 version, a checkbox is provided on the registration form where the user can choose to subscribe to notifications. The content of the email should be brief but provide enough detail for the recipient to determine at a glance what the articles are about. It is extremely important to include call-to-action (CTA) buttons. Below the article summaries, you can add buttons with the following texts: “See more”, “Read article”, etc.
3.4.3 Behaviour analysis: how do users navigate around the journal website? What do they do? What do they visit?
a) Most visited pages
Two aspects should be examined in analyses of the most visited pages. The first is the entire stock of articles that has been accumulating over time. Among these, we can detect true “successes” of visits that do not decline over time, and thus identify the type of article that we should focus on, given the interest of the public. Second, we can analyse the reception of the new articles that are published continuously, or of new issues when they are completed and promoted. This analysis can help to assess the task of promoting and launching new content, something that can be adapted based on early usage data.
When page views are analysed, we should consider the difference between page views and unique pageviews. Page views are counted every time a page is loaded, regardless of whether it is by the same person. Each time the page is accessed it will count as a page viewed. In the case of unique pageviews, if a user accesses the same page twice in the same session, it will count as a single view.
b) Consultations or downloads of non-HTML articles
The downloads of PDFs or complementary materials in other formats (XLS, CVS, etc.) should be measured because this indicates a high degree of user interest. According to a study by Allen, Stanton, Di Pietro and Moseley (2013), the fact that these files are downloaded increases the possibility of using the content. To analyse data from downloads of non-HTML content, Google Analytics has the event tracking functionality (see Section 3.4.3f), which allows you to trace clicks from HTML pages on links to the journal’s non-HTML files, such as PDFs. For a more complete, real perspective, we should consider all data on requested non-HTML files that have been recorded in statistical reports of the content management system or the log analyser of the journal portal in which our publication is distributed, as some users directly access citable content that is not HTML.
In the case of the journal Anuari de l’Observatori de Biblioteques, Llibres i Lectura, this alternative generated from a portal managed with OJS (Figure 11) is essential, since the data obtained via Google Analytics ignores direct transit to the PDF. This is shown in Figure 12, in which data on the journal’s most consulted article is compared. While RACO offers a value for the number of consultations that is more faithful to the reality of use, Google Analytics offers a variety of metrics and dimensions that are not present in RACO.
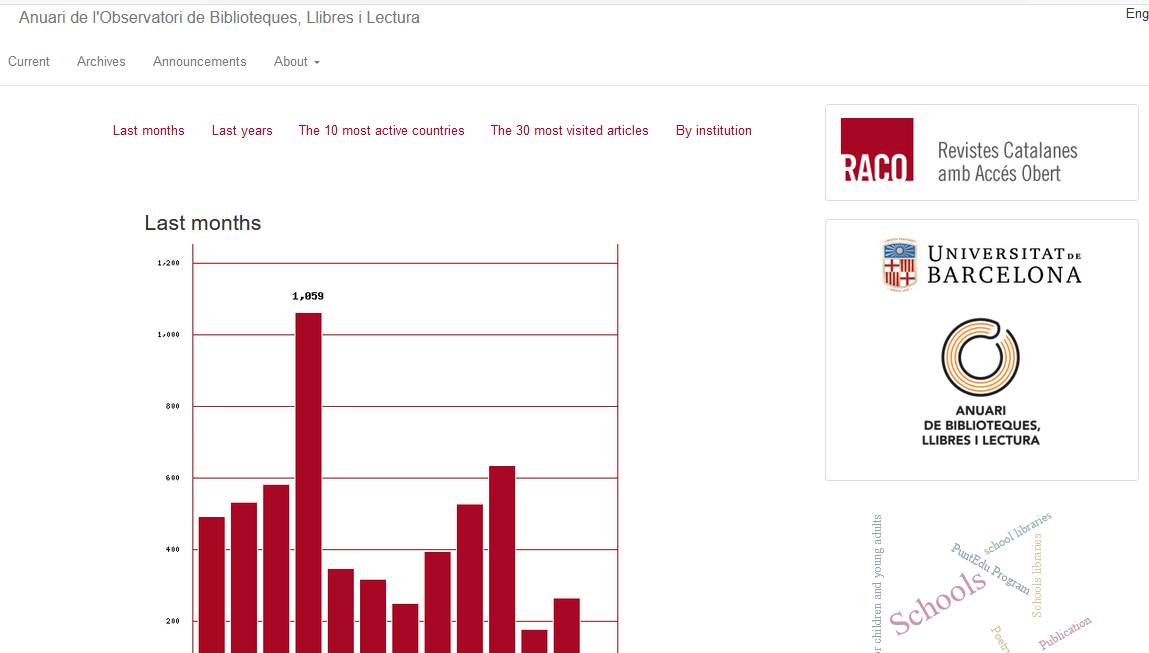
Figure 11. Statistics for journals hosted on the RACO portal: Revistes Catalanes amb Accés Obert. Source: Anuari de l’Observatori de Biblioteques, Llibres i Lectura
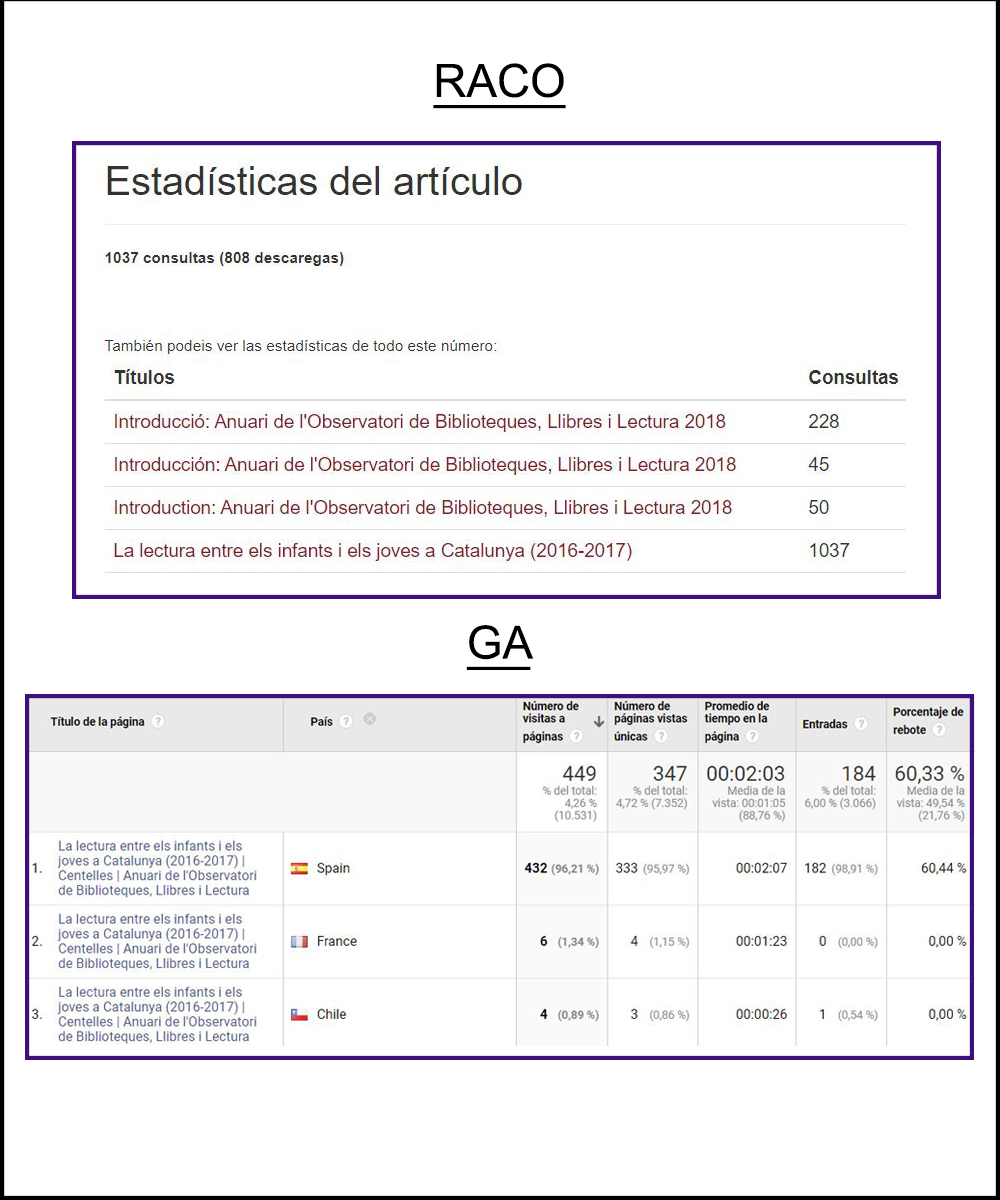
Figure 12. Difference in the number of consultations of the article of the Anuari de l’Observatori de Biblioteques, Llibres i Lectura that was most consulted in 2018, according to Google Analytics and RACO statistics
c) Landing pages
One of the most important and useful analyses is that of the pages through which users enter the journal. This can help us determine the degree of relevance of the content of some pages over others. It can also help us to assess how well visitor attraction campaigns that target specific pages are working. It is a good idea to plan different destinations for your journal website as your landing page. For example, if an information newsletter is sent in which there is a call to action with information for authors on a certain page, we should take advantage of the metrics that allow us to evaluate its operation, to optimize its design or content.
It is also important to analyse users’ behaviour on the home page (see Figure 5) when this is the landing page. If the landing page has a high bounce rate, we must consider whether we can improve elements of it that would help a greater number of users navigate from that point to other contents of the journal, whether they are citable or not. For example, we could ask ourselves if the navigation menu labels are adequate, if we have calls to action in the form of clear and attractive banners, etc. The bounce rate on landing pages is a relevant metric to consider, since some of these pages are designed to invite you to delve into other sections of the web. A high bounce rate implies a possible problem that we must consider, to adopt improvement measures.
d) Exit pages
This report shows us on which pages users decide to leave the site. Once we have seen the results, we should ask ourselves the following questions: Are these pages convincing enough? Is the content what the user expected? Should we reduce the page load time of the site? Are we adding enough links that connect the pages to each other? In a journal, many visits will end in a specific article and many will be sessions in which the user only visited one article. Consequently, it is not easy to interpret these reports for the citable contents of a journal. However, we must consider that, in the navigation logic of a digital journal, certain informative or transaction pages are designed to give way to successive pages if the message or function is to be completed. For example, to subscribe to the journal, the user will surely have to transit through several intermediate pages. A high number of exits from any of these pages should be cause for investigation.
e) Clickthrough to key pages
Site architecture and navigation design are very important to achieve quality visits, user retention and conversion. For this reason, we need to develop the website from a study of user experience. A first source of basic information is the analysis of the route users take to reach citable content. Although the architecture of places created with content management systems such as OJS is very well defined, there is room for optimizing the look and feel of the site. Some aspects that can be improved are the menu labels that support navigation or the links and calls to action to the website contained in each of the HTML pages or in PDFs.
However, by site navigation we do not only mean how readers use the site. We are also referring to how it is used by visitors who are looking for information about the journal as potential candidates to become its authors. The first impression that the site gives to potential author users is essential. Google Analytics could help us to measure the number of authors who registered in the journal. For this, we need to know the volume and characteristics of visits received by pages such as the presentation for authors on the scope and characteristics of the publication or the instructions for submitting manuscripts.
f) Interaction with content through event tracking
Google Analytics provides us with facilities to measure interactions with social networks or sites to which we link (outbound links). In some way, this is an additional indicator of interest in the content. Indeed, the degree of interest and involvement with the content can be related to its presence on social networks. Therefore, apart from the analytics offered by the profile management modules in social networks, programs such as Google Analytics allow us to trace interactions with our content that lead to content sharing from our pages (Figure 13).
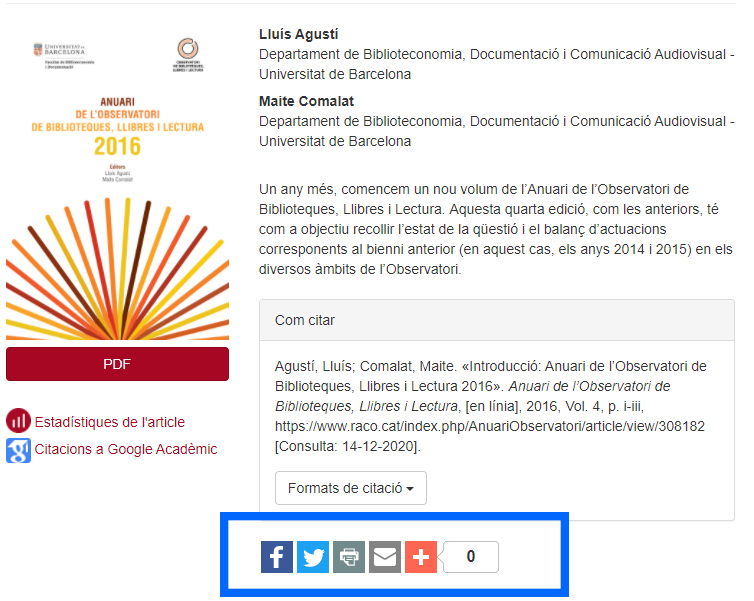
Figure 13. Social sharing bar offered by OJS. Source: AOBLL journal article
To measure how many clicks there have been on share buttons, we should activate event tracking in Google Analytics. This is an additional configuration of the tracking code that cannot be implemented when the Google Analytics connector is added in OJS, but it does exist in others content management systems like Drupal. The report will provide data on the clicks that have occurred on sharing links with this functionality (Figure 14).
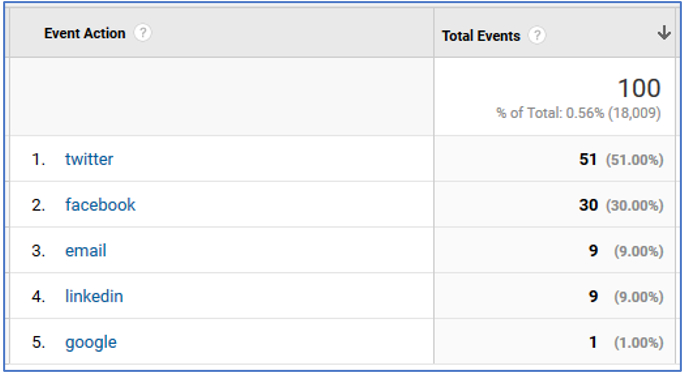
Figure 14. Statistics obtained through event tracking in Google Analytics. Source: Google Analytics account for BiD
In addition, with the creation of events we can find out how many downloads there were of citable content in PDF from the “Download” button presented on the article page. Events are interactions with elements of the page that are not necessarily the loading of a page itself. They could be the click of a button, the reproduction of a video, etc.
3.4.4 Conversion analysis: Do they do what we expect them to do?
Conversion rates measure the percentage of visitors who complete a transaction or take specific actions. Despite not having a commercial focus, we must be clear that conversion objectives can be defined in an open access journal. While conversions will not yield an economic return like commercial websites, they will have a positive social impact. The establishment of objectives and targets regarding their level of achievement is essential to get an idea of “exploitation results”.
a) Visit to the presentation page
A relevant number of users who reach a journal’s website do so without previously knowing of its existence. Perhaps they have followed a link to an article from a bibliographic reference in another article, a link on a social network or on a search engine results page. Consequently, it is very important to know how many people then access the presentation pages of the journal. This allows us to approximate users’ level of interest regarding the reason for the existence of the website.
b) Subscriptions
Although all content in an open access journal must be accessible without requiring any type of password, alerts and other value-added services require registration, which is a good method of getting leads and loyalty. When someone visits the page to subscribe and the visit ends up being a conversion (that is, they provide their email), it means that the visitor will know about new articles that are published in the future. In turn, this will lead to more consultations and downloads of the articles. One way to improve the number of subscriptions is to make sure that the user knows how to subscribe and that there is easy access to this option. Hence, analytics of navigation of the journal’s informative pages are important.
c) Registration of authors
When we refer to site navigation, we are not only talking about visitors’ use of the site, but also visitors who are looking for information about the journal and are potential candidates to become its authors. For example, a visit tracking tool such as Google Analytics could help us anticipate the future evolution of manuscript submissions and their origin, based on the navigation data of visits that go through the pages of instructions to authors. These are understood as “micro conversions” that precede submission of manuscripts for evaluation, an action that is considered full final “conversion”. This conversion would be based on measuring the percentage of people who signed up as authors. The goal will be to constantly increase this number. This rate can be measured, as when you click on the button to complete the registration process, a specific URL is displayed that helps to detect the conversion.
d) Visits of more than n pages
We will have achieved one of our objectives when a user exceeds a threshold of page views that we consider would correspond to an intense visit, in which the user’s interest in remaining on the site is demonstrated. The best way to determine the threshold would be to check the history of the page views per session.
3.5 Towards a dashboard: measure to monitor strategically
Once we have analysed the usage of our website from a discovery perspective and have made progress towards an overall assessment of its performance, perhaps in the form of an exploratory and “impressionistic” approach, we can consider some kind of dashboard based on a measurement plan. A measurement plan allows us to define more clearly what we want to achieve with the website, put it in relation to the key performance indicators (KPI), and set goals. To choose the key performance indicators in any web analytics strategy, certain prior goals must be defined. First, we establish the need to start from general objectives of the business or, in this case, of the non-profit organization that publishes the journal. This is about putting in writing objectives that answer the questions: What do the journal stakeholders want to achieve? What needs does the publication wish to cover?
Subsequently, based on the previous approaches, website objectives must be established that are consistent with the key performance indicators (KPI). The organization’s objectives should be formulated in a way that is as concise as possible and aligned with the precept of encompassing the raison d’être of the journal in general. In contrast, the website’s objectives must be more specific, since their function is to establish what we want to happen in users’ interactions with the journal. The key performance indicators measure the performance of the site on a day-to-day basis. Tools such as Google Analytics offer a large number of metrics. However, in our measurement plan, we seek to focus on metrics that enable us to find out enough to adopt improvement measures.
When editors have to analyse the performance of scientific journal sites, they often focus on basic usage metrics such as the number of global visits, the number of visits to each article or citations. These metrics can provide a general idea of the scope of the site and the publications. However, they are not enough to draw conclusions from which we can improve the web and achieve what the journal seeks. We need to periodically measure key performance/ indicators and pursue constant improvement of them. We must be clear about the reasons why we want to increase or decrease the numbers. That is, the numbers must be well aligned with the goals of our measurement plan. We must detect anomalies, deduce why they are positive or negative and try to understand the user as much as possible. When a dashboard is used, the information can be analysed including additional filters called segments, which help us to identify where any of the phenomena that we are observing in the key performance indicators occur. We can find out about behaviours performed from a specific geographic point, device or source of traffic. Knowing these behaviours with a segmented approach will make it easier for us to optimally apply the necessary improvements. As an example, a dashboard (Figure 15) and a table with recommended segments (Figure 16) are presented below.
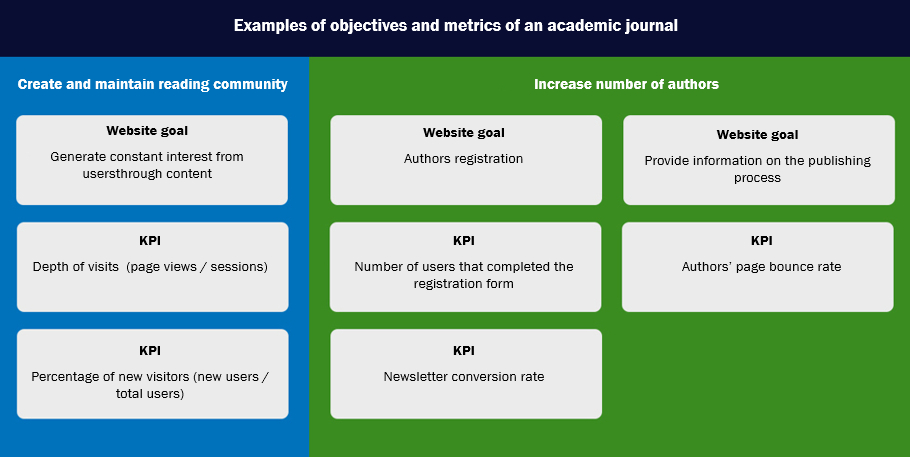
Figure 15. Example of a dashboard where objectives and key performance indicators (KPI) are defined
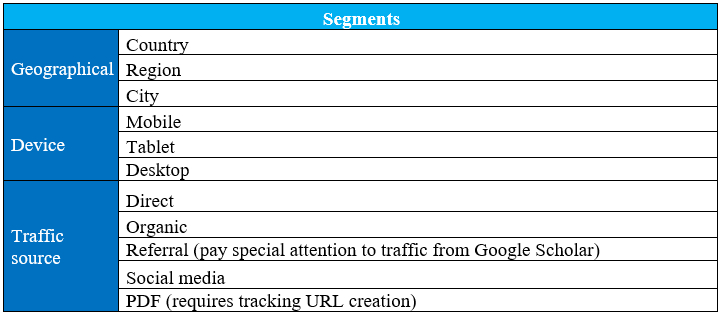
Figure 16. Example of segments
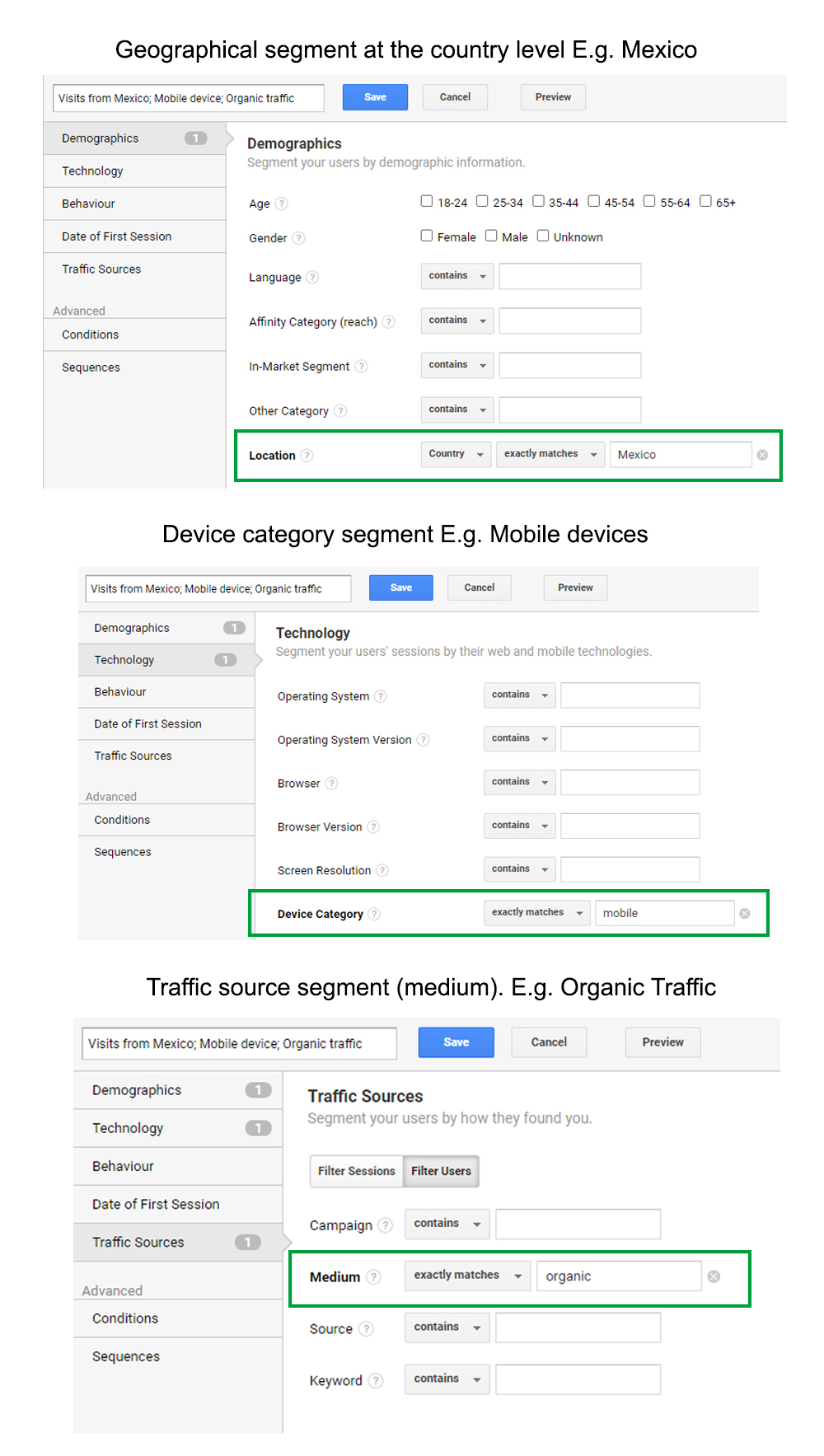
Figure 17. Geographic, device and media segments. Source: Google Analytics account for BiD
Figure 17 shows the section in which segments with different types of configuration are specified. Figure 18 shows the graph that is generated when the filters are applied, the number of users who visit the site, the sessions, bounce rate, pages per session and average duration per session.
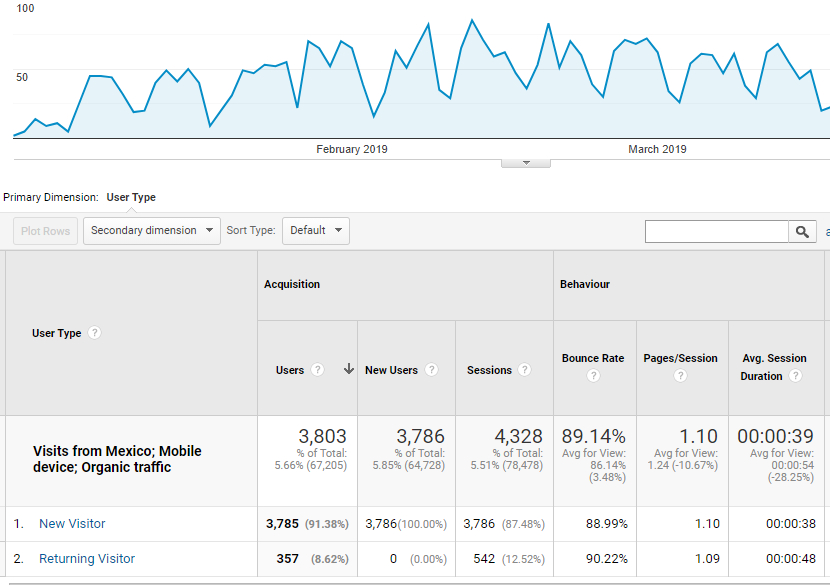
Figure 18. Report on metrics by user type limited to a segment of visits coming from Mexico through the organic channel with a mobile phone as device
The geographical segmentation can be analysed at different levels. We can find out the city and country from which users visit us. We can also combine segmentations if necessary. For example, we can determine that the traffic from a certain city has visited us from a particular type of device or has visited us from a particular traffic source.
The segment “Device” presented in the table of recommended segments allows us to differentiate data based on whether users used a mobile phone, tablet or desktop computer to access the site. It is very useful to know this information, as it gives us an idea of the context in which users read the content, which helps us to adopt measures to optimize the usability of the website designed for specific devices.
In the section “Traffic source” we can include paid, direct, organic, referral, social and PDF traffic. Paid traffic is common on e-commerce or for-profit websites. However, it is not usual on scientific journal pages, since it is rare for publishers to invest in advertising campaigns online.
When referral traffic is analysed, we should consider traffic from Google Scholar to assess our positioning in this search engine, which is specialized in scientific literature. Wikipedia is included in this section because it is starting to be relevant in measurement plans for scientific journals. Wikipedia citations seem to show an impact worth measuring as there are those who call them “public citations”. In addition, Mendeley, the popular bibliographic reference manager that allows readers to organize, share and discover scientific publications, should be considered. The volume of visits from the Mendeley platform and the number of readers who have incorporated journal articles into their personal libraries in this bibliographic manager can be taken into account. The volume of articles in a journal saved in Mendeley is considered an indicator of qualified, explicit use in the context of the community of users of this platform. Along with consolidated researchers, trainee researchers and university students from advanced courses have a large presence on Mendeley. Consequently, metrics associated with Mendeley give an idea of the impact of articles and are an alternative to citations from other journals (Ortega, 2020; Pooladian; Borrego, 2017).
For scientific journals, it is important to know how much traffic comes from PDFs, since users may directly access articles in PDF that are indexed in search engines. For this purpose, a tracking URL can be added to find out how many users come from these files. This URL can be created manually or by using the URL Campaign Builder tool.
It is very important to exploit the data by applying different segments. The information that is obtained can vary considerably depending on the filter (segment) that is applied. For example, users who visited the journal from Mexico, mobile devices and organic traffic may have a specific bounce rate that will be different if we apply different filters. A segment that groups traffic from an English-speaking country, desktop computers and the e-mail medium may have an entirely different bounce rate. The behaviour of academic bibliography readers in different areas of the world and from different devices are not uniform, so a view without sufficient granularity can give a misleading image. Having different perspectives will give us a broader idea of what is happening on our site.
4 Conclusions
The metrics, analytical priorities and key performance indicators that have been discussed in this article can be useful for any scientific journal site. However, you should always start from the context of the journal and its objectives to configure an internal web analytics guideline. Whatever the configuration of the web analytics routines, the importance of providing coherence and consistency to the analysis must be emphasized. Continuity over time is necessary. It does not make much sense to collect data if no improvement measures will be taken. We can obtain a lot of data and metrics about the operation of a journal, we can offer them to the entire editorial board or the institution that finances us, with a colourful presentation of the information, but the real challenge will be to interpret that information to continuously improve and evaluate the returns for the publishing institution.
When we talk about the elements for a proposal, we mean that a single, valid formula cannot be given to any journal. The circumstances of each editorial committee, each editor-in-chief, publishing institutions, etc. will determine what information needs there are and how the analytics are going to be used. To take a serious approach to editorial management based on data, it is important to establish routines for generating reports, an inventory of data and metrics, and a list of recipients of these reports. In other words, the journal’s management mechanisms and annual meetings should integrate this information according to a certain plan. Furthermore, someone must assume responsibility for interpreting the data to help the team make decisions. It will be essential to constantly search for good practices in terms of SEO, alerts to users, offering statistics, links between pages and content writing. In addition, it will be very important to structure the analyses, following a measurement plan based on objectives, strategies, tactics and key performance indicators.
By applying a plan, whatever the size, and with the firm will to detect the needs of site visitors, it will be possible to make decisions that add value to the journal content and services. Bearing this in mind and keeping up to date with the functionalities of the analytics tools, the door is opened to maintaining a functional website that makes people visit it repeatedly and even recommend it.
Bibliography
Abadal, E. (2012). Acceso abierto a la ciencia. Barcelona: Editorial UOC. <http://eprints.rclis.org/16863/1/2012-acceso-abierto-epi-uoc-vfinal-autor.pdf>. [Consulta: 05/05/2020].
Allen, H. G.; Stanton, T. R.; Di Pietro, F.; Moseley, G. L. (2013). “Social media release increases dissemination of original articles in the clinical pain sciences”. PLoS ONE, vol. 8, no. 7. <https://doi.org/10.1371/journal.pone.0068914>. [Consulta: 05/05/2020].
Borrego, Á. (2014). “Altmétricas para la evaluación de la investigación y el análisis de necesidades de información”. El profesional de la información, vol. 23, n.o 4, p. 352–358. <https://doi.org/10.3145/epi.2014.jul.02>. [Consulta: 05/05/2020].
Bragg, M.; Cahpman, J.; DeRidder, J., Johnston, R.; Kyrillidou, M.; Stedfeld, E. (2015). Best Practices for Google Analytics in Digital Libraries. Digital Library Federation. <https://doi.org/10.17605/OSF.IO/CT8BS>. [Consulta: 05/05/2020].
Codina, L. (2019, junio). “SEO: Guía de herramientas de análisis y tutoriales de posicionamiento web”. Lluís Codina: comunicación y documentación. <https://www.lluiscodina.com/periodismo-documentacion-medios/recursos-seo/>. [Consulta: 05/05/2020].
Edgar, B. D.; Willinsky, J. (2010). “A survey of scholarly journals using Open Journal Systems”. Scholarly and research communication, vol. 1, no. 2. <https://doi.org/10.22230/src.2010v1n2a24>. [Consulta: 05/05/2020].
Eysenbach, G. (2006). “Citation Advantage of Open Access Articles”. PLOS Biology, vol. 4, no. 5. <https://doi.org/10.1371/journal.pbio.0040157>. [Consulta: 05/05/2020].
Fagan, J. C. (2014). “The suitability of web analytics key performance indicators in the academic library environment”. The journal of academic librarianship, vol. 40, no. 1, p. 25–34. <https://doi.org/10.1016/j.acalib.2013.06.005>. [Consulta: 05/05/2020].
Fuchs, C.; Sandoval, M. (2013). “The diamond model of open access publishing: why policy makers, scholars, universities, libraries, labour unions and the publishing world need to take non-commercial, non-profit open access serious”. TripleC: communication, capitalism & critique, vol. 11, no. 2, p. 428–443. <https://doi.org/10.31269/triplec.v11i2.502>. [Consulta: 05/05/2020].
Glänzel, W.; Gorraiz, J. (2015). “Usage metrics versus altmetrics: confusing terminology?”. Scientometrics, vol. 102, no. 3, p. 2.161–2.164. <https://doi.org/10.1007/s11192-014-1472-7>. [Consulta: 05/05/2020].
Greene, J. W. (2017). “Developing COUNTER standards to measure the use of open access resources”. Qualitative and quantitative methods in libraries, vol. 6, no. 2, p. 315–320. <http://www.qqml-journal.net/index.php/qqml/article/view/410>. [Consulta: 05/05/2020].
Green, T. (2017a). “We’ve failed: pirate black open access is trumping green and gold and we must change our approach”. Learned publishing, vol. 30, no. 4, p. 325–329. <https://doi.org/10.1002/leap.1116>. [Consulta: 05/05/2020].
— (2017b, 24 de octubre). “It’s time for ‘pushmi-pullyu’ open access: servicing the distinct needs of readers and authors”. LSE impact blog. <http://blogs.lse.ac.uk/impactofsocialsciences/2017/10/24/its-time-for-pushmi-pullyu-open-access-servicing-the-distinct-needs-of-readers-and-authors/>. [Consulta: 05/05/2020].
Harrington, R. (2017, 1 de junio). “Diamond open access, societies and mission”. The scholarly kitchen. <https://scholarlykitchen.sspnet.org/2017/06/01/diamond-open-access-societies-mission/>. [Consulta: 05/05/2020].
Holdcombe, A.; Wilson, M. C. (2017, 23 de octubre). “Fair open access: returning control of scholarly journals to their communities”. LSE impact blog.
<http://blogs.lse.ac.uk/impactofsocialsciences/2017/10/23/fair-open-access-returning-control-of-scholarly-journals-to-their-communities/>. [Consulta: 05/05/2020].
Jansen, B. J. (2009). Understanding user-web interactions via web analytics. Williston: Morgan & Claypool Publishers. <https://doi.org/10.2200/S00191ED1V01Y200904ICR006>. [Consulta: 05/05/2020].
Kaushik, A. (2010). Analítica Web 2.0: el arte de analizar resultados y la ciencia de centrarse en el cliente. Barcelona: Gestión 2000.
Lawrence, S. (2001). “Free online availability substantially increases a paper’s impact”. Nature, vol. 411, no. 6.837, p. 521–522. <https://doi.org/10.1038/35079151>. [Consulta: 05/05/2020].
Lewis, C. (2018). “The open access citation advantage: does it exist and what does it mean for libraries?”. Information technology and libraries, vol. 37, no. 3, p. 50–65. <https://doi.org/10.6017/ital.v37i3.10604>. [Consulta: 05/05/2020].
Lewis, D. (2012). “The inevitability of open access”. College & research libraries,vol. 73, no. 5, p. 493–506. <https://doi.org/10.5860/crl-299>. [Consulta: 05/05/2020].
OBrien, P.; Arlitsch, K.; Mixter, J.; Wheeler, J.; Sterman, L. B. (2017). “RAMP: The Repository Analytics and Metrics Portal”. Library Hi Tech, vol. 35, no. 1, p. 144–158. <https://doi.org/10.1108/LHT-11-2016-0122>. [Consulta: 05/05/2020].
Obrien, P.; Arlitsch, K.; Sterman, L.; Mixter, J.; Wheeler, J.; Borda, S. (2016). “Undercounting file downloads from institutional repositories”. Journal of library administration, vol. 56, no. 7, p. 854–874. <https://doi.org/10.1080/01930826.2016.1216224>. [Consulta: 05/05/2020].
Ortega, J. L. (2020). “Altmetrics data providers: a meta-analysis review of the coverage of metrics and publications”. El profesional de la información, vol. 29, n.o 1. <https://doi.org/10.3145/epi.2020.ene.07>. [Consulta: 05/05/2020].
Park, M. (2018). “SEO for an open access scholarly information system to improve user experience”. Information discovery and delivery, vol. 46, no. 2, p. 77–82. <https://doi.org/10.1108/IDD-08-2017-0060>. [Consulta: 05/05/2020].
Piwowar, H.; Priem, J.; Larivière, V.; Alperin, J. P.; Matthias, L.; Norlander, B.; Farley, A.; West, J.; Haustein, S. (2018). “The state of OA: a large-scale analysis of the prevalence and impact of open access articles”. PeerJ, vol. 6. <https://doi.org/10.7717/peerj.4375>. [Consulta: 05/05/2020].
Piwowar, H.; Priem, J.; Orr, R. (2019). “The future of OA: a large-scale analysis projecting open access publication and readership”. BioRxiv, preprint no. 795.310. <https://doi.org/10.1101/795310>. [Consulta: 5/5/2020].
Public Knowledge Project [PKP] (s. d.). “Statistics”. En: PKP administrator guide. PKP Docs website. <https://docs.pkp.sfu.ca/admin-guide/en/statistics>. [Consulta: 05/05/2020].
Pooladian, A.; Borrego, Á. (2017). “Twenty years of readership of library and information science literature under Mendeley’s microscope”. Performance measurement and metrics, vol. 18, no. 1, p. 67–77. <https://doi.org/10.1108/PMM-02-2016-0006>. [Consulta: 05/05/2020].
Pooley, J. (2017, 15 de agosto). “Scholarly communications shouldn’t just be open, but non-profit too”. LSE impact blog. <http://blogs.lse.ac.uk/impactofsocialsciences/2017/08/15/scholarly-communications-shouldnt-just-be-open-but-non-profit-too/>. [Consulta: 05/05/2020].
Priem, J.; Taraborelli, D.; Groth, P.; Neylon, C. (2010). Altmetrics: a manifesto. <http://altmetrics.org/manifesto/>. [Consulta: 05/05/2020].
Prom, C. J. (2011). “Using web analytics to improve online access to archival resources”. American archivist, vol. 74, no. 1, p. 158–184. <https://doi.org/10.17723/aarc.74.1.h56018515230417v>. [Consulta: 05/05/2020].
Putnam, L. L. (2009). “Symbolic capital and academic fields”. Management communication quarterly, vol. 23, no. 1, p. 127–134. <https://doi.org/10.1177/0893318909335420>. [Consulta: 05/05/2020].
Rovira, C.; Guerrero-Solé, F.; Codina, L. (2018). “Received citations as a main SEO factor of Google Scholar results ranking”. El profesional de la información, vol. 27, n.o 3, p. 559–569. <https://doi.org/10.3145/epi.2018.may.09>. [Consulta: 05/05/2020].
Salö, L. (2017). “Pierre Bourdieu: view points and entry points”. En: The sociolinguistics of academic publishing. Palgrave Macmillan, p. 29–42. <https://doi.org/10.1007/978-3-319-58940-4_3>. [Consulta: 05/05/2020].
Tananbaum, G. (2013). Article‐Level metrics: a SPARC primer. SPARC. <https://sparcopen.org/wp-content/uploads/2016/01/SPARC-ALM-Primer.pdf>. [Consulta: 05/05/2020].
Taraghi, B.; Grossegger, M.; Ebner, M.; Holzinger, A. (2013). “Web analytics of user path tracing and a novel algorithm for generating recommendations in Open Journal Systems”. Online information review, vol. 37, no. 5, p. 672–691. <https://doi.org/10.1108/OIR-09-2012-0152>. [Consulta: 05/05/2020].
Urbano, C. (2013). “Cuenta atrás para las estadísticas de recursos-e: Counter 4”. Anuario ThinkEPI, vol. 7, p. 101–105. <https://recyt.fecyt.es/index.php/ThinkEPI/article/view/30340/0>. [Consulta: 05/05/2020].
Villarroya, A.; Claudio-González, M.; Abadal, E.; Melero, R. (2012). “Modelos de negocio de las editoriales de revistas científicas: implicaciones para el acceso abierto”. El profesional de la información, vol. 21, n.o 2, p. 129–135. <https://doi.org/10.3145/epi.2012.mar.02>. [Consulta: 05/05/2020].
Vitela, A. (2017). Propuesta de mejora de estadísticas del portal de revistas e-RACO. Trabajo final de máster disponible en el Dipòsit Digital de la Universitat de Barcelona. <http://hdl.handle.net/2445/117725>. [Consulta: 05/05/2020].
Watson, A. B. (2007). “Measuring demand for online articles at the Journal of Vision”. Journal of vision, vol. 7, no. 7, p. 1–3. <https://doi.org/10.1167/7.7.i>. [Consulta: 05/05/2020].
Notes
1 This article is partially derived from the final project of the master’s degree in Digital Content Management at the University of Barcelona, by Alex Vitela (2017) on the management of statistics and analytics in portals with OJS.
2 COUNTER Code of Practice emerged as a space for convergence between commercial publishers and libraries to agree on the standardization of statistics on the use of digital resources (Urbano, 2013). In the field of open access publishing, the use of COUNTER metrics has few incentives and many complications for its regulatory application. Consequently, its strict monitoring is low, although it serves as a reference framework for the definitions of metrics of use. The fact that the OJS statistics module integrates reports according to COUNTER metrics in its latest versions highlights its recognition as a metric framework beyond commercial publishers that offer subscription content (Greene, 2017).
3 Queries carried out in WoS, Scopus and Google Scholar on 30 October 2019.
4 This would be the case for certain statistical reports that are offered on some journal portals, such as those published with OJS. On example is the RACO reports: Revistes Catalanes amb Accés Obert.
 Creative Commons licence (Attribution-Non-Commercial-No Derivative works). They may be consulted and distributed freely provided that the author and publisher are quoted (in accordance with the “Recommended citation” section in each of the articles). However, no derivative works (translation, change of format, etc.) may be made without the publisher’s permission. Therefore, it meets the definition of open access form the Budapest Open Access Initiative declaration. The journal allows the author(s) to hold the copyright without restrictions and to retain publishing rights without restrictions.
Creative Commons licence (Attribution-Non-Commercial-No Derivative works). They may be consulted and distributed freely provided that the author and publisher are quoted (in accordance with the “Recommended citation” section in each of the articles). However, no derivative works (translation, change of format, etc.) may be made without the publisher’s permission. Therefore, it meets the definition of open access form the Budapest Open Access Initiative declaration. The journal allows the author(s) to hold the copyright without restrictions and to retain publishing rights without restrictions.