
Rubén Alcaraz Martínez
EINA, Centre Universitari de Disseny i Art de Barcelona. Arxiu
Resum
Es presenten les característiques principals del CollectiveAccess, un sistema de gestió i difusió de col·leccions digitals per a museus, arxius i biblioteques. Se’n descriuen els components principals, el procés d’instal·lació, l’estructura interna del sistema i es mostren alguns exemples de casos d’ús. Les versions analitzades del sistema són la 1.4 del Providence i la 2.0 del Pawtucket.
Resumen
Se presentan las principales características de CollectiveAccess, un sistema de gestión y difusión de colecciones digitales para museos, archivos y bibliotecas. Se describen sus principales componentes, el proceso de instalación, la estructura interna del sistema y se muestran algunos ejemplos de casos de uso. Las versiones analizadas del sistema son la 1.4 de Providence y la 2.0 de Pawtucket.
Abstract
This paper describes the main features of CollectiveAccess, a collections management and presentation system for the digital collections of museums, archives and libraries. The paper describes the main features of the system and explains how to install and configure the package. It also examines CA’s internal structure and gives examples of how it can be used. The system analyzed in the paper uses Version 1.4 of the core cataloguing application Providence and Version 2.0 of the public web-access tool Pawtucket.
1 Introducció
El CollectiveAccess (en endavant CA) és un sistema de gestió i difusió de col·leccions de museus, arxius i biblioteques. El programa l’ha desenvolupat i el manté l’empresa Whirl-i-Gig, amb la col·laboració de diferents institucions associades dels Estats Units i d’Europa com ara l’Institute of Museum and Library Services, el National Endowment for the Humanities, el New York State Council for the Arts o el Kulturstiftung des Bundes, entre d’altres. L’origen de l’aplicació es remunta a l’any 2003, tot i que la primera versió estable no es va alliberar fins al 2007, primer sota el nom d’OpenCollection, fins que al 2008 va canviar per l’actual CollectiveAccess. Des que va aparèixer s’ha implementat en més de cent projectes en diferents àmbits com ara les belles arts, la història oral, els fons d’arxiu institucionals o diverses col·leccions especials de diferents tipologies d’unitats d’informació. El CA és programari lliure que es distribueix sota un llicència GNU GPL v3.1
En aquest article s’analitzen les versions 1.4 del Providence i la versió 2.0 del Pawtucket, les últimes versions estables disponibles dels dos components principals del sistema en el moment d’escriure aquest article.
2 Components
Com acabem d’avançar, el CA el formen dos components de programari independents: el Providence i el Pawtucket, encarregats respectivament de la part de gestió i de difusió dels continguts.
2.1 El Providence
El Providence és la part central i més important del CA. El formen una base de dades, un entorn de treball capaç de gestionar els formats principals de fitxers digitals2 i una interfície d’usuari per a la catalogació, cerca i gestió de les col·leccions i els objectes digitals del repositori. Qualsevol instal·lació del CA necessita, com a mínim, disposar d’una instància del Providence. La resta de components del sistema, inclòs el Pawtucket, són opcionals i requereixen aquest component per funcionar.
Les característiques principals del mòdul de gestió del CA són:
- Interfície de catalogació altament configurable a partir de diferents perfils de metadades.
- Possibilitat de crear llistes i vocabularis controlats associats a camps dels esquemes de metadades i a altres funcions del sistema.
- Categorització i etiquetatge de continguts.
- Geolocalització d’objectes.
- Motor de cerca configurable (MySQL o Solr).
- Eines administratives orientades a gestionar la col·lecció (adquisicions, préstecs, lots d’objectes, localització, estats de conservació, etc.).
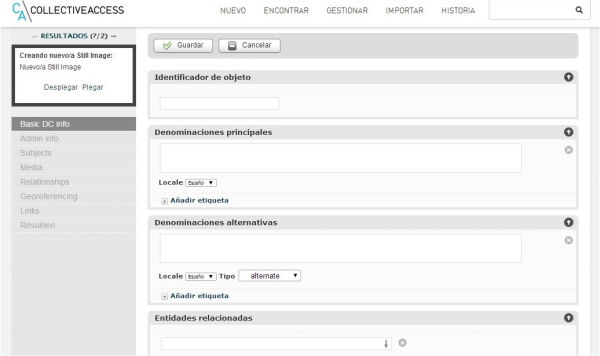
Figura 1. Fragment del formulari de catalogació disponible en una instal·lació amb el perfil de metadades Dublin Core
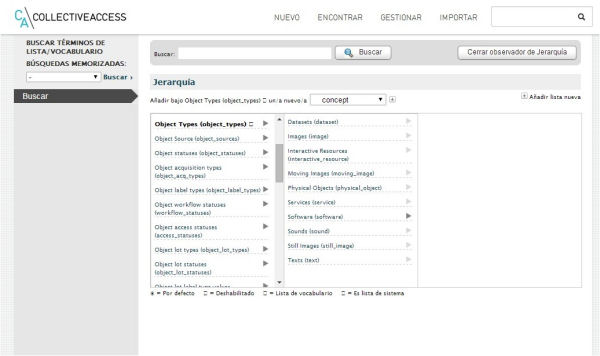
Figura 2. Editor de llistes i vocabularis del CA
Els serveis web subjacents a aquestes funcionalitats i a d’altres de disponibles out of the box són els de:
- El Google Maps per a la generació de mapes i la traducció d’adreces formatades en coordenades mitjançant l’API de codificació geogràfica d’aquest servei.
- El servei de noms geogràfics de GeoNames que integra cerques sobre aquesta base de dades geogràfica i permet enllaçar-los amb els registres del CA.
- El motor de cerca Apache Solr, que es pot fer servir en comptes del motor de cerca basat en el MySQL configurat per defecte.
- Els serveis web de la Library of Congress Subject Headings.
- Integració amb l’Amazon S3 storage per replicar l’emmagatzematge.
- Etc.
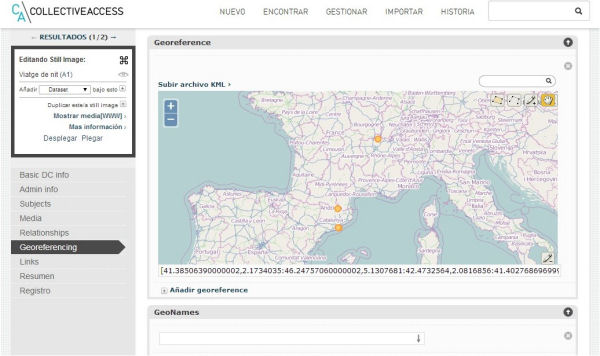
Figura 3. Servei de georeferenciació i vincle amb el GeoNames
El CA també permet tant recol·lectar com exposar metadades via el protocol OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting).
2.2 El Pawtucket
El Pawtucket és el component encarregat de proporcionar un frontend o interfície pública al sistema. La plantilla per defecte és molt simple, però adaptativa i totalment personalitzable mitjançant els fitxers CSS i PHP.
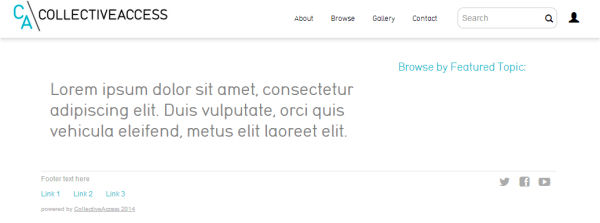
Figura 4. Pàgina d’inici de la plantilla per defecte acabada d’instal·lar
Com alternativa al Pawtucket es podria fer servir qualsevol frontend capaç d’obtenir informació de la base de dades del sistema.3 Pràcticament no existeixen experiències en aquest camp més enllà d’un mòdul per al sistema de gestió de continguts Drupal,4 només compatible amb versions del CA anteriors a la 1.3, o alguns exemples d’ús d’Omeka com a frontend per a l’aplicació. Un bon exemple de la convergència CA/Drupal la trobem al James Ensor Online Museum. En el cas d’Omeka trobem un parell d’exemples als repositoris Religieus Erfgoed Online del Centrumvoor Religieuze Kunst en Cultuur de Bèlgica i al Het Virtual Land del Centrum Agrarische Geschiedenis del mateix país. Més enllà de la integració amb terceres aplicacions, també es coneixen experiències amb desenvolupaments propis, un bon exemple de les quals és el Philaplace de la Historical Society of Pennsylvania.
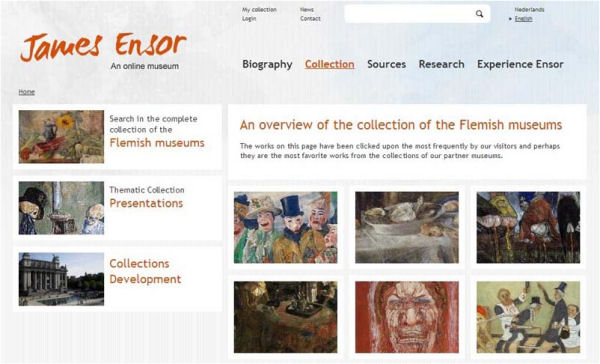
Figura 5. Pàgina d’inici del James Ensor Online Museum

Figura 6. Pàgina d’inici del Religieus Erfgoed Online
3 Instal·lació i requeriments mínims
3.1 Requeriments mínims
- Servidor HTTP Apache 1.3, 2.0 o 2.2.
- PHP 5.3.6 o superior (amb els mòduls mbstring, JSON, mysql, iconv, zlib, libXML, DOM, PCRE i Process Control).
- MySQL 5.0, 5.1 o 5.5 amb suport per a taules InnoDB.
3.2 Instal·lació i components addicionals
El CA és un programari multiplataforma desenvolupat en PHP i que requereix d’un entorn AMP (Apache, MySQL i PHP) per funcionar. Per tant, en primer lloc hem de crear una base de dades MySQL i un usuari amb tots els permisos al nostre servidor. A continuació podem descarregar el paquet del Providence des del web oficial del CA o des del seu perfil al GitHub. A l’arrel de l’aplicació trobarem un fitxer anomenat setup.php-dist que ens permetrà connectar la nostra aplicació amb la base de dades que hem creat anteriorment (vegeu la figura 7). L’obrim i editem com a mínim les línies 25, 29, 33 i 37, que es corresponen amb el nom del nostre host, el nom de l’usuari de la base de dades, la contrasenya per a aquest usuari i el nom de la base de dades respectivament. També podem modificar la zona horària (línia 84) o l’idioma de la instal·lació (línia 116), entre altres aspectes. Un cop hem editat el fitxer, el desem amb el nom setup.php, pugem el paquet al nostre servidor i carreguem el procés d’instal·lació accedint a l’URL on es troba l’aplicació.
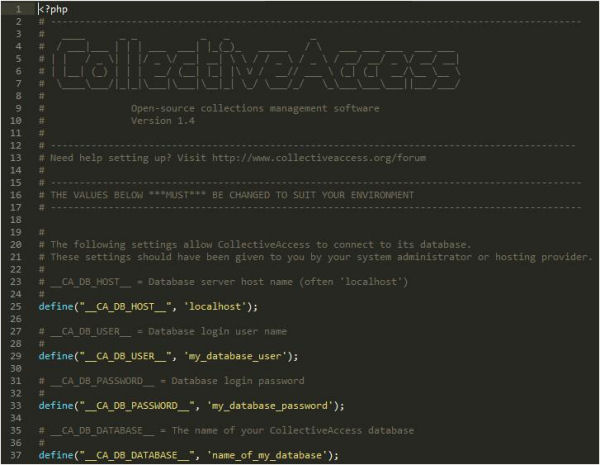
Figura 7. Detall del fitxer setup.php-dist
Un cop finalitzada la instal·lació convé eliminar el directori install per motius de seguretat.
Segons els tipus de fitxers amb què es vulgui treballar, el CA necessita altres biblioteques de programari o eines de suport addicionals. Per exemple, si volem treballar amb imatges el nostre servidor ha de tenir l’ImageMagick o el GDlibrary; en el cas que el nostre repositori estigui format per fitxers d’àudio o de vídeo, necessitarem l’FFmpeg; si volem treballar amb PDF potser ens caldran eines com el Ghostscript o el PDFToText. La llista completa de biblioteques que pot necessitar el CA es troba al wiki del projecte.5
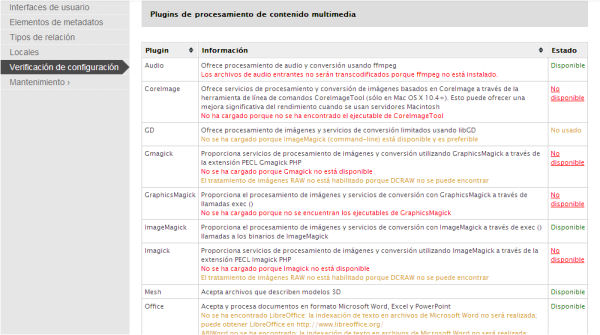
Figura. 8. Des de la interfície del sistema podem veure quines biblioteques tenim disponibles al servidor
Per instal·lar el Pawtucket és necessari disposar prèviament d’una instància del Providence. Un cop descarregada l’aplicació, hem de crear un subdirectori dins del Providence on pujarem el Pawtucket. Entre els fitxers que formen aquesta altra aplicació, en trobem un amb nom setup.php-dist, com en el cas del Providence. També, com en el cas anterior, hem d’editar-lo, tot indicant els valors de la nostra base de dades. Les dues aplicacions fan servir la mateixa base de dades i usuari. Un cop editat el fitxer ja podem accedir a la interfície pública a partir del nom del directori on hem instal·lat el Pawtucket (tipus: http://www.el-meu-web.cat/pawtucket). Perquè el Pawtucket pugui tenir accés als fitxers continguts al directori media del Providence hem de crear un enllaç simbòlic entre els directoris media de les dues aplicacions.
4 Catalogació i estàndards de metadades
Els desenvolupadors del CA prefereixen definir el seu programa com un framework altament configurable per a la catalogació, davant d’altres definicions com la de sistema de gestió de col·leccions digitals. I és que el CA ens permet triar entre un ampli ventall d’esquemes de metadades o, fins i tot, crear-ne un de nou completament des de zero, així com definir els tipus d’objectes digitals que formaran el nostre repositori. Durant la instal·lació del Providence haurem de triar un dels diferents perfils d’instal·lació disponibles. Un perfil d’instal·lació no és res més que un conjunt de valors preconfigurats en un fitxer XML, segons les necessitats particulars de cada centre o tipus de projecte. Dins del web del CA, a la secció Configuration Library, trobem una selecció de perfils d’instal·lació aportats per diferents institucions.6 No tots els perfils disponibles poden considerar-se com a models de bon disseny sinó que, en molts casos, es tracten de configuracions que responen a les necessitats de migració des d’un altre programari, o a uns requeriments molt específics que potser no són aplicables a altres situacions. No obstant això, aquests fitxers ens poden servir per entendre millor l’estructura i la sintaxi d’aquest element tan important. Si optem per triar un dels estàndards disponibles per defecte (el Dublin Core, el DACS, el PB Core, l’SPECTRUM, etc.) no hem de fer res més que seleccionar-lo en el moment de la instal·lació (vegeu la figura 9). En canvi, tant si decidim fer servir un dels perfils d’exemple disponibles al web del CA com si en creem un de nou, l’haurem d’importar al directori install/profiles/xml, perquè estigui disponible en el moment de la instal·lació. Un perfil d’instal·lació ens permet establir, entre d’altres:
- Els elements de l’esquema de metadades, és a dir, els diferents camps del nostre esquema (títol, autor, data, etc.). Es poden definir també els tipus de camps (text, numèric, etc.) o el mètode d’entrada de dades (formulari de text, desplegable amb una llista de valors, etc.), entre d’altres.
- Els tipus d’objectes digitals i ocurrències disponibles al sistema.
- Els tipus de relacions que es poden establir entre els diferents objectes digitals (documents, persones, llocs, etc.).
- Les interfícies d’usuari que necessitem per entrar les dades.
- Les llistes i els vocabularis que ens permeten definir les llistes controlades del sistema associades als diferents camps, els valors permesos, etc.
Entre els perfils disponibles actualment trobem alguns dels estàndards de metadades més comuns, com poden ser el Dublin Core, l’SPECTRUM, el VRA Core, el PB Core, el PREMIS o el DACS, entre d’altres.
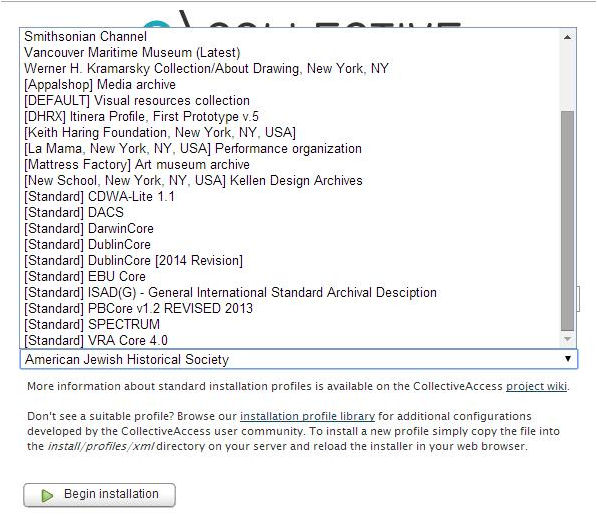
Figura 9. Perfils d’instal·lació disponibles amb el paquet Providence 1.4
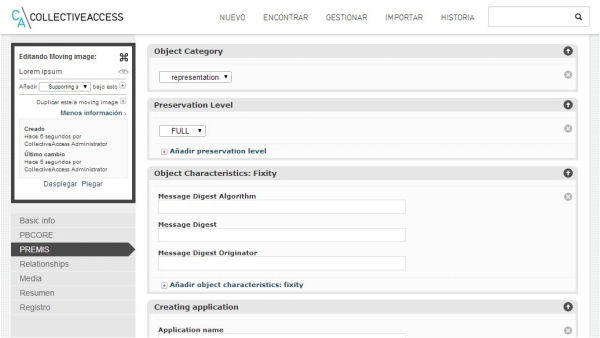
Figura 10. Formulari d’entrada de dades del perfil d’instal·lació de l’Academy of Motion Picture Arts & Sciences de Hollywood, amb els estàndards de metadades del PB Core i el PREMIS
Com hem vist fins ara, el CA es caracteritza per la seva gran flexibilitat a l’hora de triar l’estructura de dades del sistema. L’estructura general de la base de dades del CA presenta catorze entitats, tot i que podem afegir-ne d’altres segons les nostres necessitats (per exemple, per gestionar processos interns com diferents tipus de préstec, restauracions, etc.). Les entitats per defecte que trobem dins del CA són:
- Els objectes digitals (objects) o ítems dels repositoris (documents de text, imatges, recursos interactius, enregistraments sonors, de vídeo, etc.).
- Les entitats (entities) o persones i organitzacions responsables de la creació, publicació, etc., dels objectes de la col·lecció. Es poden reutilitzar en diferents objectes, col·leccions, etc.
- Llocs (places) o localitzacions físiques que es poden reutilitzar com les entitats.
- Ocurrències (occurrences) o esdeveniments com ara exposicions, publicacions, estrenes, etc.
- Col·leccions (collections) o grups d’objectes que comparteixen unes característiques comunes.
- Lots (lots) que permeten agrupar conjunts d’objectes amb característiques comunes, normalment relacionades amb la seva procedència, data de recepció, etc.
- Conjunts (sets) o grups d’objectes definits per a un propòsit específic. A diferència de les col·leccions que responen a grups relacionats intel·lectualment, en aquest cas es fan servir amb propòsits operacionals, com, per exemple, un grup d’objectes seleccionats per a una exposició.
- Elements de conjunt (set items) o registres assignats a un conjunt determinat que hi permeten afegir dades catalogràfiques addicionals.
- Representacions (representations). Són els fitxers d’imatge, de vídeo, d’àudio, de PDF, etc., associats als objectes digitals. Un mateix objecte pot tenir associades diverses representacions o fitxers.
- Llocs d’emmagatzematge (storage locations). Les ubicacions físiques on es troben els objectes de la col·lecció. Es poden jerarquitzar i tenir associades restriccions d’accés, coordenades i altres informacions.
- Llistes (lists) que es poden fer servir per restringir el valor d’un atribut, com a vocabularis controlats associats als objectes, entitats, etc., i com a llistes del sistema, els valors de les quals ens poden permetre personalitzar el CA.
- Elements de les llistes (list items). Cadascuna de les entrades que formen una llista.
- Esdeveniments dels objectes (object events). Un esdeveniment en el cicle de vida d’un objecte (moviments, accions relacionades amb la seva conservació, préstecs, etc.).
- Esdeveniments dels lots (lot events). Un esdeveniment en el cicle de vida d’un lot.
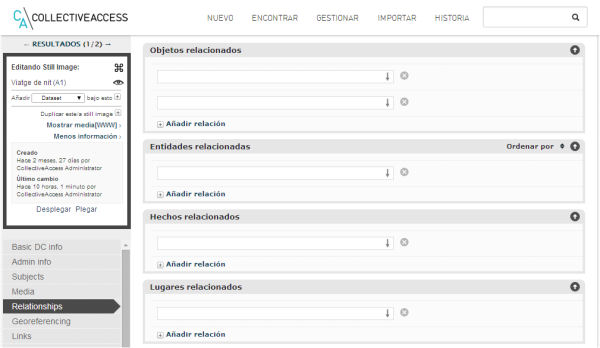
Figura 11. Formulari per establir relacions entre objectes, entitats, esdeveniments i llocs
5 Gestió d’usuaris
El CA disposa d’un sistema interessant de gestió de perfils d’usuari que permet establir els permisos de cada tipus d’usuari amb un alt nivell de granularitat. Com a administradors podem crear tants usuaris com sigui necessari. Cadascun d’aquests usuaris pot pertànyer a un grup o més d’un, que podem crear de manera personalitzada segons les nostres necessitats. Cada grup té associat un perfil d’accés diferent, des del qual es pot establir quines accions poden o no poden fer (per exemple, configurar elements de metadades, exportacions, crear nous grups d’usuaris, editar llistes i vocabularis, etc.), i quins són els permisos (lectura, lectura i escriptura o sense accés) relacionats amb els diferents elements dels esquemes de metadades associats als objectes, les entitats, els llocs, les col·leccions, els préstecs, etc.
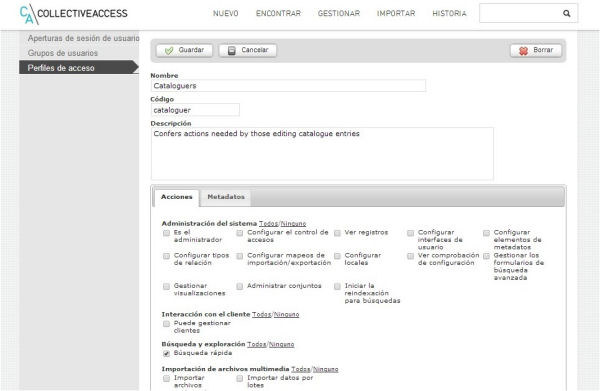
Figura. 12. Fragment de les accions associades al perfil d’accés del grup d’usuaris «Cataloguers»
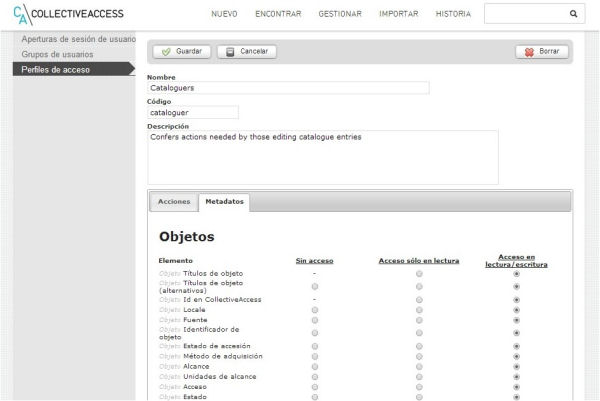
Figura. 13. Fragment dels permisos associats als elements de l’esquema de metadades
Des d’aquesta mateixa interfície també podem determinar les accions disponibles per als usuaris que es registren al sistema des de la interfície pública en el cas que fem servir el Pawtucket com a frontend. Algunes de les accions disponibles són la possibilitat o no de descarregar fitxers, compartir objectes via correu electrònic o xarxes socials, etc.
El CA també permet establir un control d’accés fitxer a fitxer des de la interfície de catalogació del sistema (vegeu la figura 14).
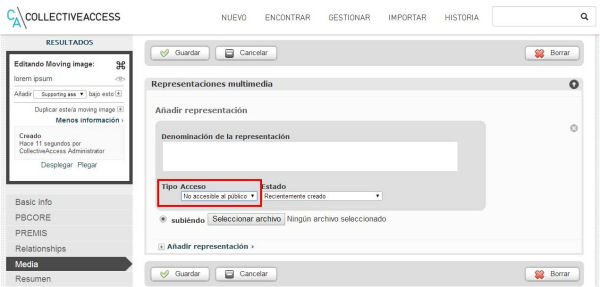
Figura. 14. Cada fitxer associat a un objecte digital pot tenir un tipus d’accés diferent
6 Localitzacions
Actualment, el CA es troba disponible en diferents idiomes. Les traduccions a l’anglès i a l’alemany són oficials i mantingudes per l’equip de traductors del Whirl-i-Gig. La resta d’idiomes disponibles, entre els quals l’espanyol, són obra de diferents membres de la comunitat d’usuaris del CA i no estan sotmesos al mateix nivell de revisió. De moment no hi ha una traducció disponible en català. No obstant això, abordar la traducció de l’aplicació és relativament fàcil de fer i no calen gaires coneixements tècnics. Per disposar d’una interfície en català per al Providence, hem de crear una carpeta amb el nom del nou idioma segons l’ISO-639-1 (ca, en el cas del català) sota el directori /app/locale/. Per no començar des de zero, podem fer servir com a model el fitxer messages.po disponible en l’idioma en_US. Mitjançant un programa d’edició de fitxers PO, com ara el Poedit, només haurem de traduir cadascuna de les cadenes de text disponibles. Un cop finalitzada la traducció guardarem aquest fitxer al directori citat anteriorment amb el nom de ca.po. També haurem d’actualitzar la línia 116 del fitxer setup.php com s’ha comentat a l’apartat 3.2. Si el que volem és actualitzar o millorar la traducció a l’espanyol, només haurem d’accedir al fitxer messages.po del directori app\locale\es_ES i actualitzar-lo com hem explicat anteriorment.
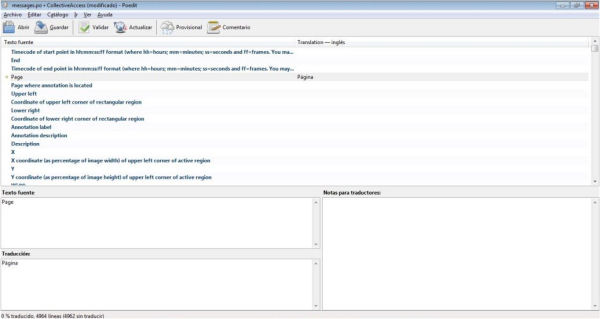
Figura. 15. Interfície del Poedit
Des de la secció Manage > Administration > Locales del CA, podem activar el nou idioma perquè estigui disponible per qualificar els valors de cadascun dels elements de l’esquema de metadades que estem fent servir (per exemple, <dc:creator xml:lang=»ca»>Nom de l’autor</dc:creator>).
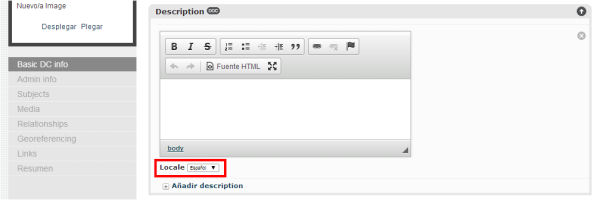
Figura. 16. Una vegada activats els diferents idiomes des de l’administració del sistema, els podrem seleccionar a les diferents instàncies de cada element de l’esquema de metadades
7 Llocs que utilitzen el CollectiveAccess
Entre els usuaris del CA trobem principalment institucions nord-americanes. Alguns exemples representatius són el Queens Memory Project de la Queens Library de Nova York, el New Museum’s Digital Archive del New Museum de Nova York, el Parrish East end Stories del Parrish Art Museum també de Nova York, el Van Alen Institute’s Design Archive del Van Alen Institute, o el repositori del Jewish Museum de Praga.
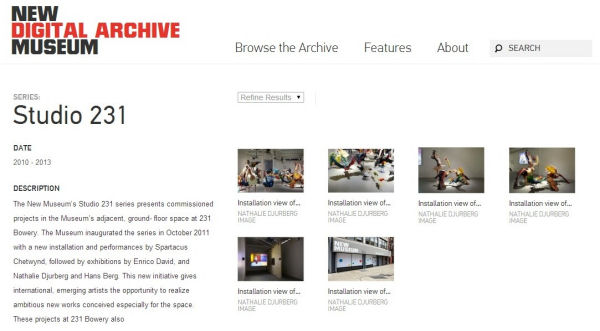
Figura. 17. New Museum’s Digital Archive

Figura. 18. Pàgina dedicada a Mary Abbott al Parrish East end Stories
Al nostre territori trobem la Kutxateka, de l’Obra Social de la Kutxa, com l’exemple més representatiu. Es tracta d’un portal que recull els diferents fons fotogràfics de l’entitat, així com algunes obres d’art. De moment, es poden consultar els fons fotogràfics de Fotocar i Marín, dues col·leccions que reflecteixen el desenvolupament social, polític i cultural de Guipúscoa des de començaments del segle xx fins als nostres dies.
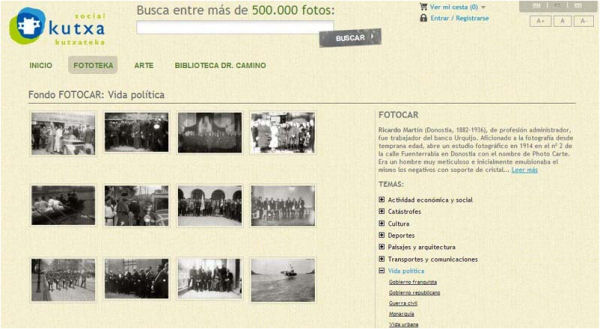
Figura. 19. Detall de la col·lecció Fotocar de la Kutxateka
A la secció Clients dins del web del CA trobem una llista amb més de cent exemples d’implementacions, organitzada segons el tipus d’institució (museus, biblioteques, institucions acadèmiques, etc.).
8 El CollectiveAccess i els seus competidors
Actualment disposem d’una gran quantitat de solucions de programari lliure per gestionar col·leccions digitals i crear repositoris i portals per difondre el patrimoni d’arxius, de museus i de biblioteques. Deixant de banda les solucions propietàries, destaquen el Dspace, l’Eprints i l’Invenio en l’àmbit dels repositoris institucionals, l’ICA-AtoM (o l’actual AtoM)7 i l’Archon pel que fa als fons i col·leccions d’arxiu, el Fedora Commons i els seus derivats (l’Islandora i l’Hydra) per a repositoris que requereixen un alt grau d’exigència i personalitzacions i, finalment, un conjunt d’aplicacions especialment centrades en la comunicació de les col·leccions i la creació de productes de valor afegit, entre els quals destaca l’Omeka.
El CA es troba a mig camí entre algunes d’aquestes aplicacions. Per les seves característiques, el seu competidor principal en l’àmbit de les biblioteques i els museus el trobaríem en l’Omeka i, en el cas de les institucions d’arxiu, en l’ICA-AtoM. La possibilitat d’integrar qualsevol esquema de metadades i la capacitat per gestionar diferents tipus de fitxers, fa que el sistema sigui interessant per a qualsevol tipus de projecte o d’institució, fins i tot les que disposen de diferents col·leccions especials i necessiten un sistema que els permeti descriure cada tipus de fons segons les pròpies normatives, però oferint un punt d’accés únic. Això suposa un model molt més integrador que el que estem acostumats a veure als projectes del nostre territori (Estivill, 2008).
En comparació a l’Omeka, resulta relativament més senzill integrar diferents esquemes de metadades al sistema. En part, perquè els fitxers de configuració dels llenguatges principals ja hi són disponibles. La gestió d’usuaris i la possibilitat de personalitzar l’aplicació també són superiors. Per la seva banda, l’Omeka presenta una corba d’aprenentatge menys pronunciada per a l’usuari administrador i ofereix un major conjunt d’eines per crear nous productes documentals com ara exposicions virtuals, línies de temps o mapes, mòduls que, a més, resulten més fàcils d’instal·lar.
Pel que fa a l’ICA-AtoM, es tracta d’un sistema centrat en la descripció i l’accés a fons i col·leccions d’arxiu. El fet de tractar-se d’una aplicació tan especialitzada en limita el mercat, però a la vegada, la pot fer més atractiva per a institucions d’arxiu que volen una aplicació d’aquestes característiques i no tenen els coneixements necessaris per personalitzar el CA.
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
History and New Media, Department of History and Art History de la GeorgeMason University. |
|
|
|
|
|
|
|
|
|
|
|
|
|
Cerques facetades de sèrie. |
|
|
|
|
Exportació en EAD, DC, MODS i SKOS. |
Altres esquemes via connectors que requereixen desenvolupaments propis. |
|
|
|
|
|
|
|
Exportació: XML, MARC21 i CSV |
|
Exportació: XML, JSON, Atom i RSS2 |
|
|
|
|
|
|
|
|
|
|
|
de treball |
|
|
|
|
i de processos administratius |
|
|
|
|
de la interfície pública |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Taula 1. Comparativa entre el CA, l’AtoM i l’Omeka
9 Conclusions
El CA destaca per la gran flexibilitat a l’hora de dissenyar un sistema a mida per gestionar les nostres col·leccions digitals. Salvant les distàncies i amb altres tecnologies al darrere, ens recorda el Fedora Commons per la capacitat d’integrar diferents esquemes de metadades, tipus d’objectes, relacions, usuaris, etc. Aquesta gran flexibilitat també suposa un major temps de configuració previ a la instal·lació i posada en marxa del sistema i requereix d’uns coneixements mínims d’XML i de l’estructura interna de l’aplicació. És important destacar, però, que per defecte trobem moltes configuracions disponibles que poden servir perfectament a la majoria de centres del nostre entorn.
Pel que fa als requeriments, el CA es tracta d’un programa interessant tant per a petites institucions com per a grans, ja que, en la línia d’altres aplicacions com ara l’Omeka, resulta fàcil d’instal·lar i mantenir però, a la vegada, és suficientment escalable i extensible com per abordar grans projectes.
Bibliografia
CollectiveAcess documentation (2014). <http://docs.collectiveaccess.org/>. [Consulta: 28/05/2014].
Estivill, Assumpció (2008). «Els fons i les col·leccions d’arxiu a les biblioteques: models per al seu control i accés». BiD: textos universitaris de biblioteconomia i documentació, núm. 21 (desembre). <https://bid.ub.edu/21/estiv1.htm>. [Consulta: 26/06/2014].
Higgins, Jessica [et al.] (2012). «Enhancing educational access to art». 2012 Conference on Digital Libraries. <http://hdl.handle.net/2249.1/57161>. [Consulta: 25/06/2014].
Pedersen, Isabel; Baarbé, Jeremiah (2013). «Archiving the ‘Fabric of Digital Life'». IEEE International Symposium on Mixed and Augmented Reality – Arts, Media, and Humanities (ISMAR-AMH).
Rehberger, Dean (2013). «Getting oral history online: collections management applications». Oral history review, vol. 40, no. 1 (Winter-Spring), p. 83–94.
Spiro, Lisa (2009). Archival management software: a report to the Council on Library and Information Resources. Washington, D. C.: Council on Library and Information Resources. <http://www.clir.org/pubs/resources/reports/spiro2009.html>. [Consulta: 24/05/2014].
Notes
1 GNU General Public Licence. Version 3, 29 June 2007. <http://www.gnu.org/copyleft/gpl.html>. [Consulta: 23/05/2014].
2 La llista completa de formats d’arxiu admesos es pot consultar a: http://docs.collectiveaccess.org/wiki/Supported_Media_File_Formats.
3 A la secció Getting data de la documentació oficial s’expliquen els diferents mètodes per accedir a la base de dades: http://wiki.collectiveaccess.org/index.php?title=API:Getting_Data.
4 Es pot descarregar des de: https://drupal.org/project/collectiveaccess.
5 Llista completa de biblioteques addicionals: http://wiki.collectiveaccess.org/index.php?title=Installation_(Providence).
6 Disponible a: http://www.collectiveaccess.org/configuration.
7 L’AtoM (Access to Memory) és un sistema de gestió de fons d’arxiu desenvolupat per Artefactual Systems, els mateixos responsables de l’ICA-AtoM, a partir de les primeres versions d’aquesta aplicació. Més informació a: https://www.accesstomemory.org/es/.
 Llicència Creative Commons de tipus Reconeixement-NoComercial-SenseObraDerivada. Aquest article es pot difondre lliurement sempre que se’n citi l’autor i l’editor amb els elements que consten en la secció «Citació recomanada». No se’n pot fer, però, cap obra derivada (traducció, canvi de format, etc.) sense el permís de l’editor. Així, BiD compleix amb la definició d’open access de la Declaració de Budapest a favor de l’accés obert. La revista també permet que els autors mantinguin els drets d’autor i els de publicació sense restriccions.
Llicència Creative Commons de tipus Reconeixement-NoComercial-SenseObraDerivada. Aquest article es pot difondre lliurement sempre que se’n citi l’autor i l’editor amb els elements que consten en la secció «Citació recomanada». No se’n pot fer, però, cap obra derivada (traducció, canvi de format, etc.) sense el permís de l’editor. Així, BiD compleix amb la definició d’open access de la Declaració de Budapest a favor de l’accés obert. La revista també permet que els autors mantinguin els drets d’autor i els de publicació sense restriccions.