Cuantificarse para vivir a través de los datos: los datos masivos (big data) aplicados al ámbito personal
Objectives: This paper uses data generated by users to reflect on the emergent paradigm of lifelogging or quantified self as a lifestyle. It analyses the social and technological aspects of this phenomenon, focusing on data management, and it describes how the principles of big data enable us to understand the opportunities and complexities that quantified self is responsible for.
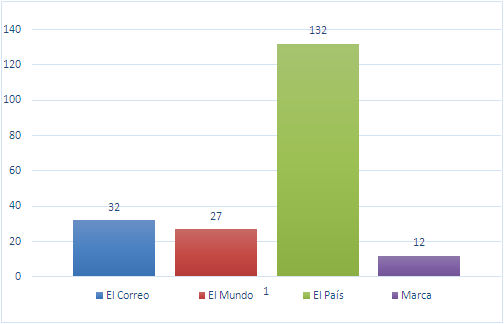
Methodology: The paper revises the bibliography published on lifelogging and quantified self from its beginnings to the present. The bibliographic search was completed using bibliographic databases for the articles and general search engines for information on products and applications and for news articles in the local and international press.
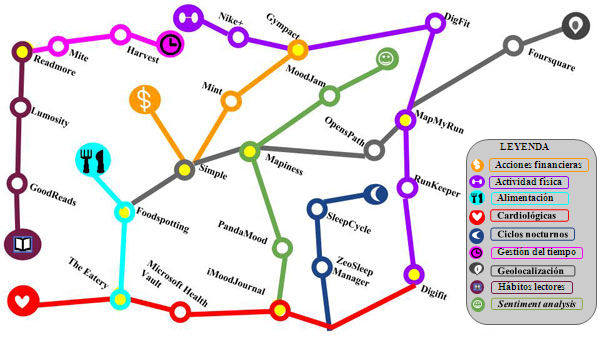
Results: The result is a taxonomy of uses, applications and tools for lifelogging and quantified self. The researchers conclude that the ability to generate quality information from user-generated data will be key in the development of this paradigm. It will also be necessary to establish standards and protocols to organize, manage and analyse the data so that the potentially positive impact of quantified self on society can be optimized.